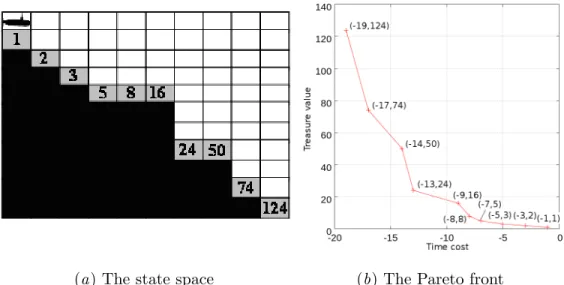
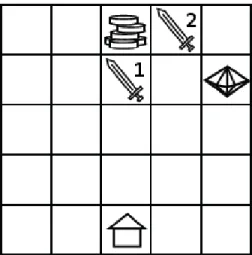
However, in the general case of antagonistic objectives (e.g., simultaneously minimizing the cost and risk of a production process), two policies may be incomparable (e.g., the cheapest process for a fixed firm; the cheapest process robust to a fixed cost): the solutions are partially ranked, and the set of optimal solutions according to this partial ranking is referred to as the Pareto front (more in Section 2). The hypervolume indicator of these solutions at the r.t reference point in the lower left corner is the surface of the shaded region. Additional heuristics are considered, mainly to prevent overexploration when the number of acceptable weapons is large compared to the number of simulations (the so-called multi-armed bandit problem (Wang et al., 2008)).
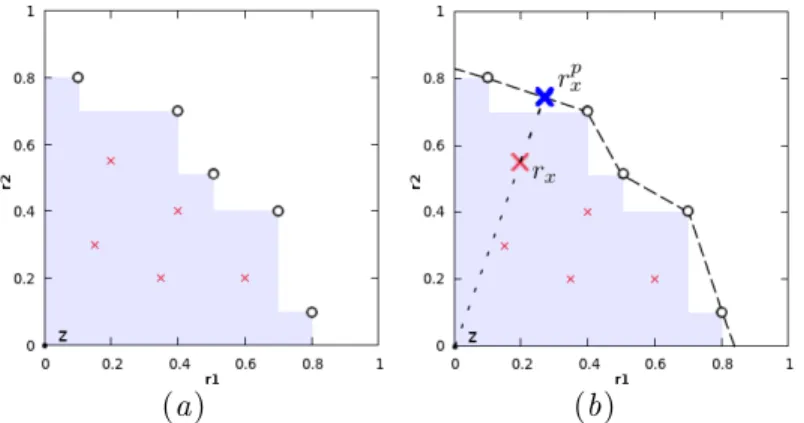
The hypervolume indicator (Zitzler and Thiele, 1998) provides a scalar measure for solution sets in multi-objective space as follows. LetB represents the average branching factor in the MOMCTS-hv tree, and letN represents the number of tree walks. Since each tree walk adds a new node, the number of nodes in the tree by construction is N+ 1.
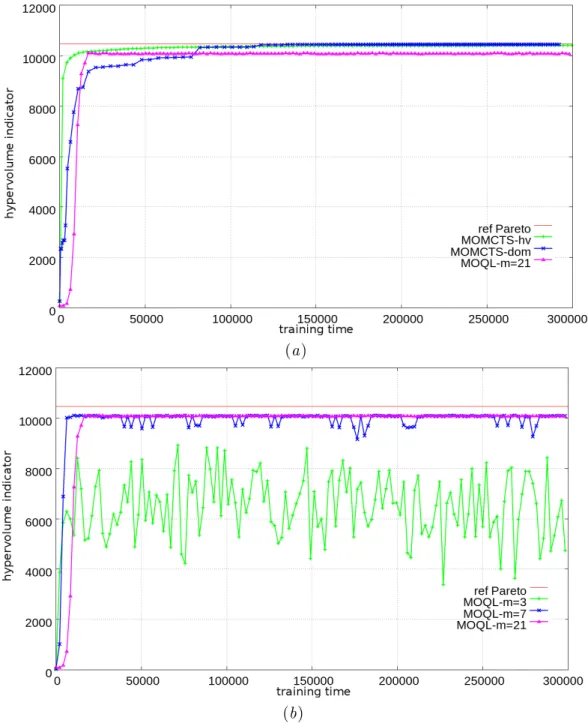
Keeping the notations B, N and |P| the same as above, since the dominance test at the end of each tree walk is linear (O(d|P|)), the complexity of each tree walk in MOMCTS-dom is O(BlogN+d|P|), linear w.r.t. number of targets. In the following, MOMCTS-dom is compared with multi-objective Q-Learning (MOQL) (Vamplew et al. Figure 3 shows the performance of the hypervolume indicator MOMCTS-hv, MOMCTS-dom and MOQL form= 3.7, 21 in a deterministic setting (η= 0).
On the positive side, it turns out that MOMCTS approaches can find solutions that lie in the non-convex regions of the Pareto front, unlike linear scalarization-based methods. RG's action field includes the same four actions (up, down, left, and right) as in the DST problem. The non-dominated vector rewards form a convex Pareto front in three-dimensional space (Fig. 8).
In the RG problem, the MOMCTS approaches are compared with the MOQL algorithm, which independently optimizes the weighted sums of the three objective functions. The reference point z used in the calculation of the hypervolume indicator is set to where -0.33 represents the maximum penalty for the enemy, averaged in each time step of the episode, and the. In the remainder of Section 4.4, two objectives will be considered: the makespan and the cost of the solution.
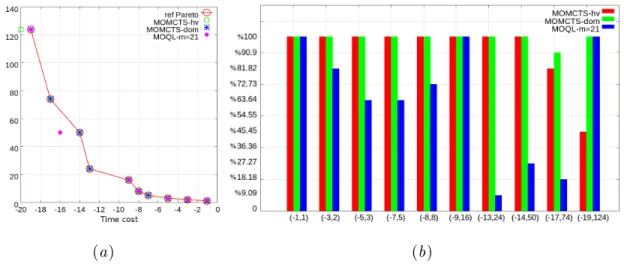
Due to the lack of the real Pareto front in the considered problems, we use a reference Pareto front P∗ that collects all non-dominated vectorial rewards obtained in all runs of all three algorithms to find the real Pareto front to replace. The performance indicators are defined by the generation distance (GD) and the inverse generation distance (IGD) between the actual Pareto front P found in the run and the reference Pareto front P∗. In the grid planning experiment, the IGD indicator plays a similar role as the hypervolume indicator in DST and RG problems.
Meanwhile, they yield better IGD performance than the baselines, indicating that on average, a single run of MOMCTS approximations achieves a better approximation of the real Pareto front.
Discussion
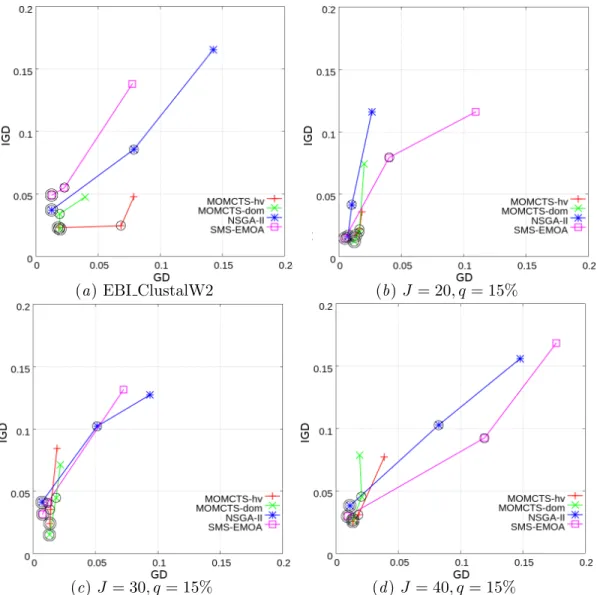
Fig.15 shows GD and IGD for MOMCTS-hv, MOMCTS-dom, NSGA-II and SMS-EMOA on EBI ClustalW2 workflow planning and on artificial jobs with a number J of tasks ranging from 20,30 and 40 with graph density q = 15 %. 16 shows the Pareto front discovered by MOMCTS-hv, MOMCTS-dom, NSGA-II and SMS-EMOA on the EBI ClustalW2 workflow after N and 10000 policy evaluations (tree walks), compared to the reference Pareto front. In all problems considered, the MOMCTS approaches outperform the baselines in terms of the GD indicator, while quickly finding good solutions, they do not discover the reference Pareto front.
The computational costs of MOMCTS-hv and MOMCTS-dom are respectively 5 and 2.5 times higher than those of NSGA-II and SMS-EMOA4. The strength of the single policy approach is its simplicity; its long-known limitation is that it cannot detect politics in non-convex regions of the Pareto front (Deb, 2001). In the case of multiple policies, multiple Pareto optimal vector rewards can be obtained by optimizing different scalarized RL problems at different weight settings.
In the case where the Pareto front is known, designing the weight settings is easier - provided the Pareto front is convex. When the Pareto front is unknown, an alternative provided by Barrett and Narayanan (2008) is to maintain Q vectors instead of Q values for each (state, action) pair. Through an adaptive selection of weight settings corresponding to the vectorial rewards on the boundary of the convex set of the current Q vectors, this algorithm narrows the set of selected weight settings at the cost of a higher complexity of value iteration in each state : O(|S ||A|) the complexity of standard Q-learning is multiplied by a factor O(nd), where the number of points on the convex hull of the Q-vectors and d is the number of targets.
Based on the assumption of convexity and partial linearity on the convex hull form of the Q vectors, Lizotte et al. (2012) extends (Barrett and Narayanan, 2008) narrowing the range of points that lie on the convex hull, thus keeping the value under control. On the one hand, this complexity is lower than that of value iteration in Barrett and Narayanan (2008) (taking into account that the size of the archive P is comparable to the number n of non-dominated Qvectors). On the other hand, this complexity is higher than that of MOMCTS-dom, where the dominance test has to be calculated only at the end of each tree walk, i.e. with linear complexity in the number of objectives and tree walks.
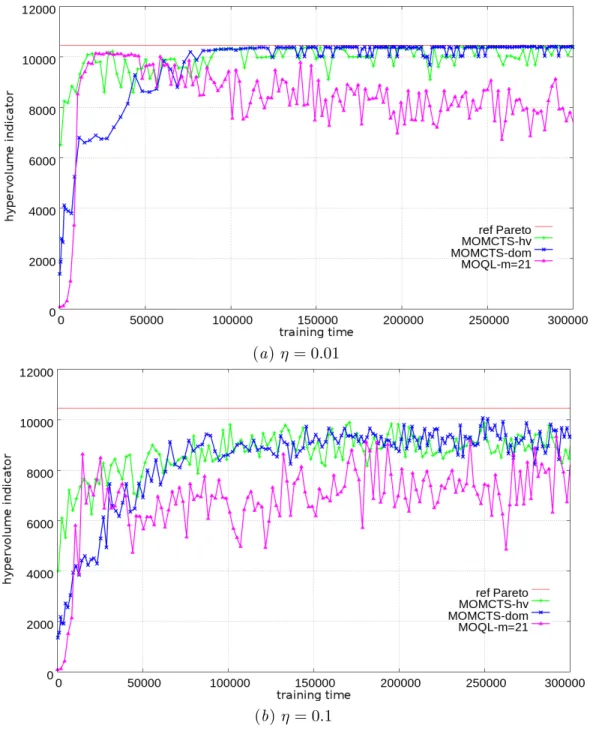
The price to be paid for the improved scalability of MOMCTS-dom is that the dominance reward may favor Pareto archive diversity less than the hypervolume indicator: each non-dominated point has the same dominance reward while the hypervolume indicator of non-dominated points . in sparsely populated regions of the Pareto archive is higher. As shown in the Resource Pooling problem, MOMCTS approaches have difficulty finding "risky" policies by visiting nodes with many low-reward nodes in their neighborhood. A tentative explanation for this fact is given since, as already noted by Coquelin and Munos (2007), it may take an exponential time for the UCT algorithm to converge to the optimal node if this node is hidden by low-reward nodes.
Conclusion and perspectives
Natarajan and Tadepalli (2005) show that the efficiency of MOQL can be improved by sharing information between different weight settings. A hot topic in multi-policy MORL is how to design the weight settings and share information between the different scalarized RL problems. The experimental results on DWT confirm a major merit of the proposed approaches, their ability to discover policies that lie in the non-convex regions of the Pareto front.
First, as shown in the grid scheduling problem, complex problems require some domain knowledge to enforce efficient random-phase exploration. Second, as can be seen from the resource pooling problem, the presented approaches hardly detect "risky" policies lying in an unpromising region (the proverbial needle in a haystack). These first results, however, provide proof of concept for MOMCTS approaches, noting that these approaches provide comparable performance to the state-of-the-art (non-RL-based), albeit at the cost of higher computational cost.
The main theoretical perspective concerns the properties of the cumulative discounted reward mechanism in the general (single-objective) dynamic optimization context. On the applicative side, we plan to refine the RAVE heuristic used in the grid scheduling problem, e.g. We are grateful to the anonymous reviewers for their many comments and suggestions on an earlier version of the paper.
A general polynomial result of MOO was proposed by Chatterjee (2007), who claims that for all irreducible MDP with multiple long-term average objectives, the Pareto front can be approximated in time polynomial in . However, this claim rests on the assumption that finding some Pareto optimal point can be reduced to the optimization of a single objective: optimize a convex combination of objectives using a set of positive weights (page 2, Chatterjee (2007)), which does not hold for non-convex Pareto fronts. Furthermore, the approach relies on the approximation of the Pareto front proposed by Papadimitriou and Yannakakis (2000), which assumes the existence of an oracle that tells for each vectorial reward whether it is Pareto-dominated (Thm.