FERRAMENTAS DE PESQUISA DE DOCUMENTOS USANDO TÉCNICAS DE MINERAÇÃO DE TEXTO: UMA APLICAÇÃO NO CONSELHO. Ferramenta de busca documental utilizando técnicas de mineração de texto: uma aplicação ao Conselho Regional de Contabilidade de Santa Catarina.

PROBLEMATIZAÇÃO
Formulação do Problema
Além da mineração de textos, a busca por documentos implica a necessidade de aplicação de métodos de recuperação e indexação de informações. Os processos de recuperação de informações geralmente são baseados em buscas por palavras-chave ou por similaridade (KAMBER & HAN, 2001).
Solução Proposta
OBJETIVOS
Objetivo Geral
Objetivos Específicos
METODOLOGIA
Também foi realizado um levantamento de ferramentas de mineração de textos livres para encontrar referências para o desenvolvimento do trabalho. Na quinta fase foi realizada uma análise da eficácia do sistema utilizando métricas para verificar a cobertura e precisão do sistema para verificar se os resultados desejados foram alcançados.
ESTRUTURA DO TRABALHO
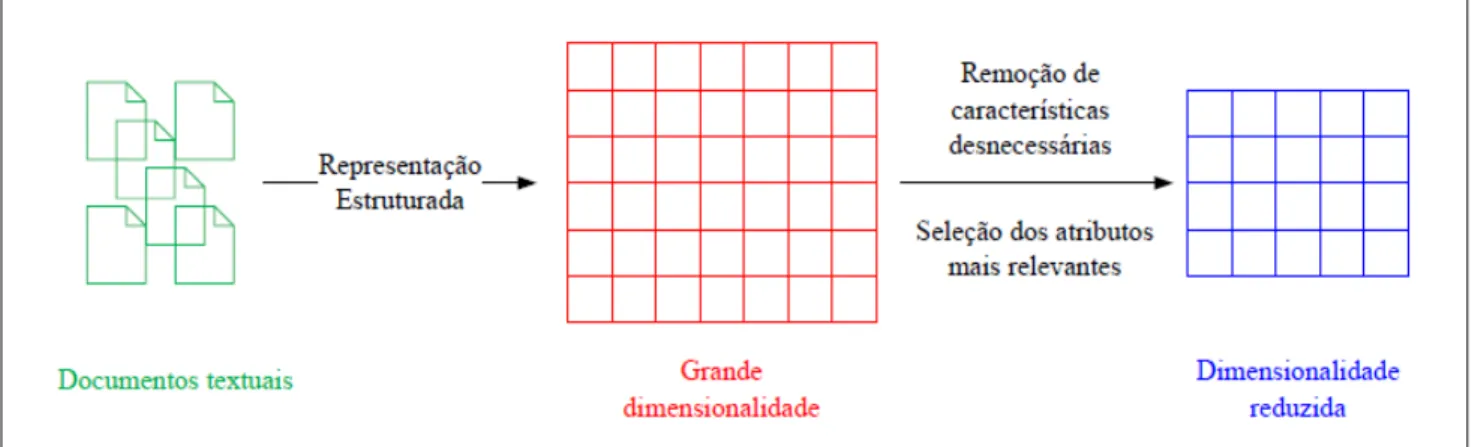
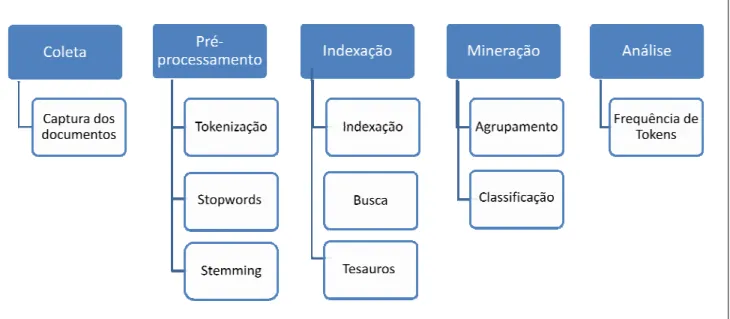
Foi revisada a bibliografia de todas as etapas da mineração de textos, incluindo coleta de documentos, pré-processamento, indexação, mineração e análise dos resultados. A seguir foram detalhados aspectos do desenvolvimento do sistema, as ferramentas utilizadas, os problemas encontrados e as soluções desenvolvidas, bem como uma análise dos resultados obtidos.
MINERAÇÃO DE TEXTOS
Coleta de Dados
Na web, com o incontável número de páginas pessoais e institucionais, artigos e diversas outras fontes caracterizadas por uma heterogeneidade de informações, a coleta de dados torna-se um desafio maior. A coleta de dados em pastas, que serão utilizadas neste trabalho, é a forma mais natural de armazenar documentos em formato digital (ARANHA, 2007).
Pré-processamento
- Tokenização
- Remoção de stopwords
- Stemming
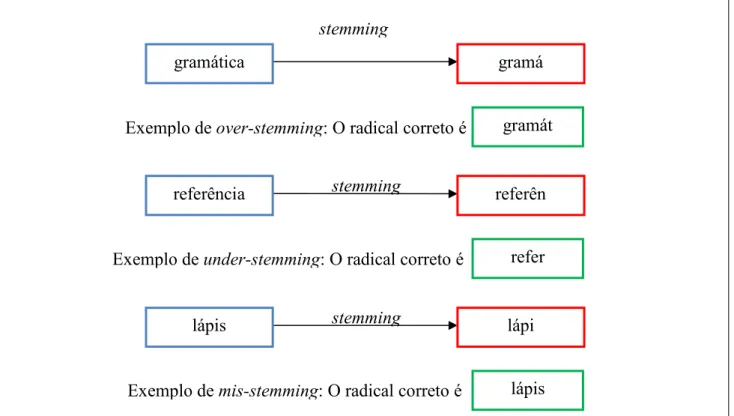
Abaixo na Figura 7 você pode ver um exemplo do processo de tokenização seguido da remoção de stopwords. Reduzir as variantes de uma palavra ao mesmo radical comum (radical) é muito útil para melhorar o desempenho na recuperação de documentos, e tem como efeito secundário a redução do tamanho da estrutura do índice (BAEZA-YATES & RIBEIRO NETO, 1999).
Indexação
- Medidas de similaridade
- Tesauros
- Listas invertidas
Considerando que os documentos são encontrados pelos termos neles contidos, a localização de um documento solicitado pelo usuário ocorre com base na semelhança entre os termos fornecidos pelo usuário e os termos que identificam os documentos nas bases de dados. Para cada token encontrado em ambos os documentos, é calculado um bônus de 1/df(j), onde df(j) é o número de documentos em que ocorre o token j.

Processamento de linguagem natural
O principal objetivo dos sistemas de recuperação de informação é melhorar a velocidade de processamento de uma consulta solicitada por um usuário. Finalmente, os procedimentos envolvidos no processamento de linguagem natural são normalmente limitados a uma determinada língua.
Recuperação clássica da informação
- Modelo booleano
- Modelo vetorial
- Modelo probabilístico
Para ordenar os documentos resultantes de uma pesquisa, são utilizados os valores de semelhança entre uma expressão de pesquisa e cada um dos documentos da coleção. Geralmente, no modelo vetorial, os resultados da pesquisa são ordenados de acordo com o grau de semelhança entre a expressão de pesquisa e os documentos da coleção. Esta ordenação permite limitar o número de documentos recuperados, definindo um limite mínimo para o valor de similaridade. Após reenviar a expressão de busca (Tabela 4), juntamente com os documentos selecionados, o sistema calculará um novo valor de similaridade para cada documento utilizando a Equação 5.

Mineração
- Classificação
- Agrupamento
No modelo binário, assume-se que cada documento é representado por um vetor de atributos binários, de forma que cada atributo indica a ocorrência ou não de um evento no documento. No modelo multinomial, assume-se que cada documento é representado por um vetor de atributos inteiros que caracteriza o número de vezes que cada token aparece no documento. Basicamente, a ideia do algoritmo é classificar um determinado conjunto de documentos em um determinado número de clusters (K-clusters) que são determinados previamente.
Avaliação e interpretação dos resultados
A Figura 22 representa graficamente os conjuntos de itens relevantes e irrelevantes recuperados ou não por um sistema de busca. Existe um conjunto de documentos do acervo documental que são relevantes para o processo de pesquisa. A cobertura para um determinado conjunto de itens detectados é definida como a razão entre o número de itens relevantes detectados e o número total de itens relevantes no sistema em questão. A medida de desempenho de cobertura pode ser realizada utilizando a Equação 14.

FERRAMENTAS DE MINERAÇÃO DE TEXTOS
- TMSK – Text Miner Software Kit
- Text Mine
- Intext
- Vivíssimo/Clusty
- Análise das ferramentas
Das ferramentas apresentadas nos parágrafos anteriores, nenhuma é aplicável ao objetivo deste trabalho, pois não são ferramentas voltadas para textos em português. Abaixo segue uma comparação (Tabela 5) das ferramentas listadas em termos de processamento de texto durante o pré-processamento, os algoritmos de mineração de texto realizados e as linguagens suportadas. Além das ferramentas examinadas não serem focadas na língua portuguesa, nenhuma delas utiliza tesauros, o que significa perdas de desempenho na recuperação e indexação de documentos.

REQUISITOS FUNCIONAIS
RF014 – O sistema deve permitir uma busca para recuperar documentos que contenham todas as palavras da expressão de busca, respeitando a ordem entre elas. RF016 – O sistema deve permitir a busca por documentos semelhantes a partir de um documento retornado por uma busca. RF020 – O sistema deverá permitir especificar o tipo de arquivo que deseja pesquisar.
REQUISITOS NÃO-FUNCIONAIS
CASOS DE USO
Pesquisar todas as palavras: permite que usuários administradores e usuários regulares pesquisem documentos com todas as palavras pertencentes à expressão de pesquisa; Pesquisa com relação à ordem das palavras: permite que usuários administradores e usuários regulares pesquisem documentos que contenham a ordem exata das palavras da expressão de pesquisa; Pesquisa pela ordem exata das palavras: permite que usuários administradores e usuários regulares pesquisem documentos que contenham as palavras exatas e sua ordem contida na expressão de pesquisa;
ARQUITETURA GERAL DO SISTEMA
Coletar documentos: responsável por buscar arquivos no diretório e mapeá-los para a classe Document; PreProcessing: responsável por executar as etapas de pré-processamento, utilizando para isso as classes Stopword, Dictionary e Stemming. Uma lista de resultados é então retornada para a classe controladora, que a envia para a classe de agrupamento para agrupar os resultados e, em seguida, retorna a consulta ao usuário.
MÓDULO DE COLETA
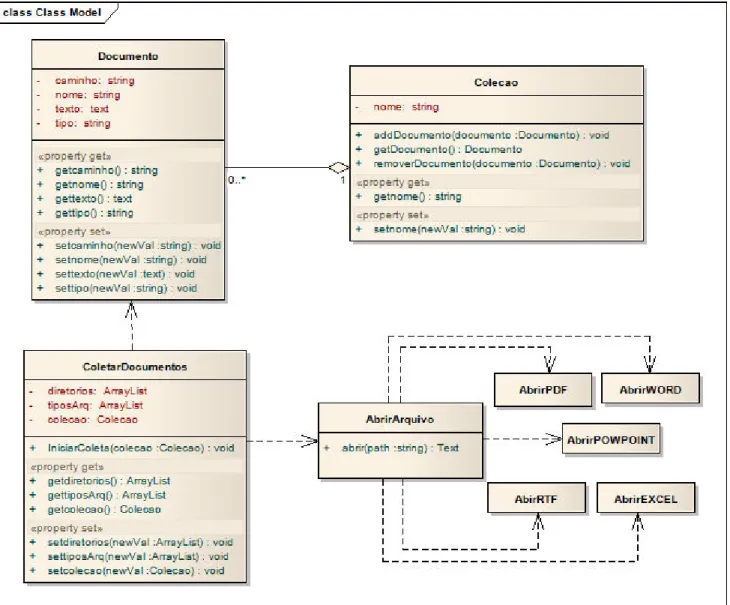
Cada documento coletado é mapeado para um objeto da classe Documento através da classe ColetarDocumentos, utilizando as classes apropriadas para cada tipo de arquivo encontrado na pasta. A Figura 29 apresenta o diagrama de sequência da fase de coleta de documentos, mostrando que o sistema pesquisa cada pasta definida e captura todos os tipos de arquivos indicados. O texto do arquivo é então obtido através da classe AbrirArquivo, que coleta as informações do arquivo e então cria um objeto da classe Document que é adicionado à classe Colecao.
MÓDULO DE PRÉ-PROCESSAMENTO
Para melhor compreensão, a Figura 31 apresenta o diagrama de sequência da fase de tokenização. Os processos de remoção de palavras irrelevantes, lematização e dicionário de sinônimos são opcionais, ou seja, após a fase de tokenização, a fase de indexação pode ser realizada diretamente. O diagrama de sequência mostrado na Figura 33 mostra que a etapa de pré-processamento só pode ser realizada para a coleção desejada e não é obrigatória para todas as coleções.
MÓDULO DE INDEXAÇÃO
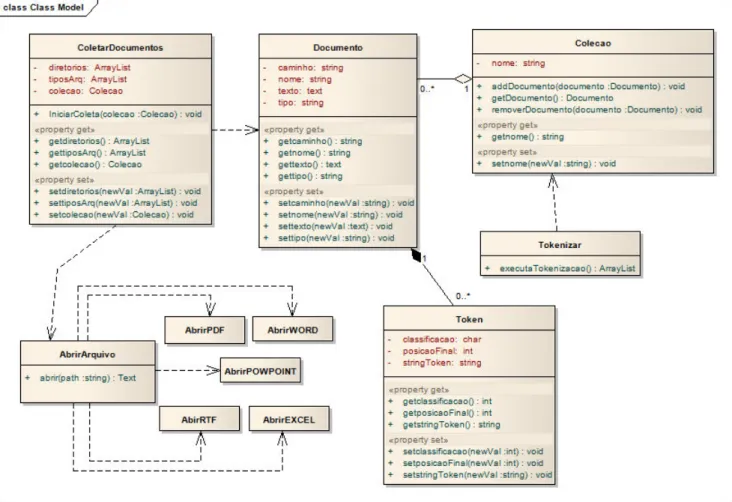
Na Figura 35 você pode analisar o comportamento da classe Indexing, que pode ser implementada separadamente para cada coleção de documentos. Podemos observar também que a classe Thesaurus é verificada para verificar o termo ideal para inserir no índice. Devido ao grande número de documentos, a classe Thesaurus é importante porque reduz o tamanho do índice e evita que palavras com o mesmo significado sejam indexadas.
MÓDULO DE MINERAÇÃO
A classificação é utilizada quando o usuário solicita a recuperação de documentos semelhantes selecionando um documento resultante de uma pesquisa. O agrupamento é realizado após uma pesquisa do usuário, pois os resultados obtidos são agrupados em um determinado número de clusters, gerados pelo sistema.
MÓDULO DE ANÁLISE
Na classe Análise é implementado o método "frequenciaTokens", que retorna uma lista com a frequência dos tokens de uma coleção. Este capítulo apresenta os detalhes da implementação e desenvolvimento da ferramenta de busca, bem como as soluções criadas para os problemas encontrados durante a execução do projeto. Seguindo o desenvolvimento proposto no projeto do instrumento, os aspectos de implementação serão detalhados em módulos: coleta, pré-processamento, indexação, mineração e análise.
VISÃO GERAL DA SOLUÇÃO
O operador “AND” pode ser utilizado para indicar que a palavra deve estar contida nos documentos, ou o operador “-” ou “NOT” também pode ser utilizado, indicando que a palavra não deve estar contida em nenhum dos documentos retornados de a pesquisa. Permite pesquisar documentos que contenham qualquer uma das palavras, podendo ser utilizados espaços no lugar do operador. A busca por documentos semelhantes pode ser realizada a partir de um documento retornado pela busca clicando em “Pesquisar Similares”.

FERRAMENTAS AGREGADAS
- Apache Tika
- Apache Lucene
- Luke
- Limo
- Carrot2
A Figura 44 apresenta os resultados de uma busca pela palavra-chave “RESOLUTION 1.081” e, neste caso, apenas um resultado foi encontrado. Luke foi utilizado no desenvolvimento para verificar e validar os resultados da indexação, detalhando os documentos contidos nos índices. Esta biblioteca organiza os resultados da pesquisa em tópicos, de forma totalmente automática e sem necessidade de treinamento prévio e construção de taxonomias.
COLETA
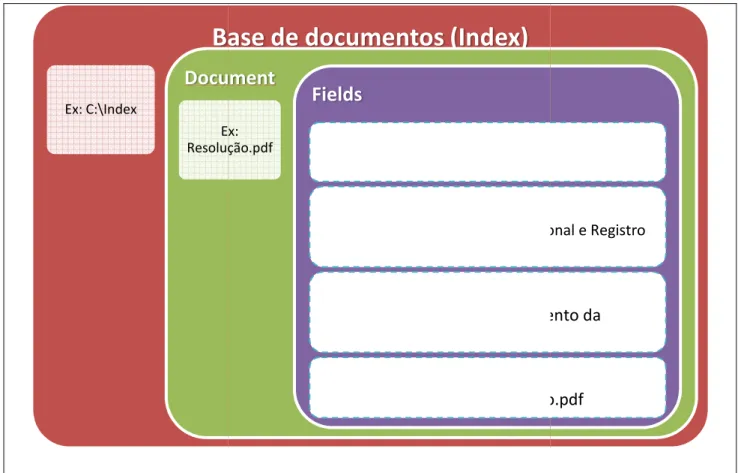
Essa lista é enviada para o módulo Extract Data, que, para cada documento, faz uma chamada à API Apache Tika, que por fim retorna o texto e os metadados do documento analisado. Resumo: contém os primeiros 350 caracteres do texto do documento salvo para exibir uma amostra do texto nos resultados da pesquisa; Os campos selecionados para serem analisados são submetidos a um analisador que converte o texto em argumentos, que são submetidos a operações de remoção de palavras irrelevantes, lematização e tesauro.
PRÉ-PROCESSAMENTO
Após a tokenização, o processo de remoção de stop word inicia-se com o objetivo de reduzir a alta dimensionalidade dos tokens através da remoção de palavras com baixo conteúdo semântico. Quanto ao processo de remoção de banimentos de palavras, a lista de banimentos ideal deve ser construída considerando o domínio da aplicação. Além desta operação, também são realizadas algumas outras, como a remoção de caracteres especiais, etc.) e a remoção de sufixos.

INDEXAÇÃO
Melhorando desempenho da indexação
Ao indexar pequenas coleções de documentos, a indexação funciona bem na configuração padrão do Lucene. Por exemplo, pode haver milhares de documentos a serem indexados e você deseja acelerar o processo para minutos em vez de horas. O parâmetro mergeFactor permite controlar o número de documentos armazenados na memória antes de gravá-los no disco.
Agendamento de indexação
Verifica-se que ambas as operações de indexação iniciaram às 14h00min47s, enquanto a última terminou às 14h01min09s, o que significa que o processo de indexação das duas coleções demorou 22.027 milissegundos. Conforme mostrado no gráfico da Figura 66, pode-se observar uma redução de 11% no tempo de indexação utilizando o escalonador multithread. Portanto, para indexar todos os 74,60 GB de documentos CRCSC, seriam necessárias aproximadamente 5 horas de processamento utilizando um agendador multi-threaded que tem uma velocidade de indexação de 273 MB por minuto, enquanto com o agendador single-thread isso seria necessário.

MINERAÇÃO
A classe mostrada na Figura 69 recebe como parâmetro uma lista de documentos mapeados pela classe Document do indexador Lucene, classe incompatível com a classe exigida pelo algoritmo de clusterização. Após os dados serem mapeados em uma classe compatível com aquela exigida pelo algoritmo de clustering, o processo de mineração de dados começa. No código mostrado na Figura 71, os dados processados pelo algoritmo de agrupamento são recebidos pela classe ProcessingResult. A lista de agrupamentos gerados é retirada desta estrutura.

RESULTADOS RELEVANTES
Stopwords
Dentro dos clusters estão os documentos dos quais os dados exibidos ao usuário são extraídos.
Stemming
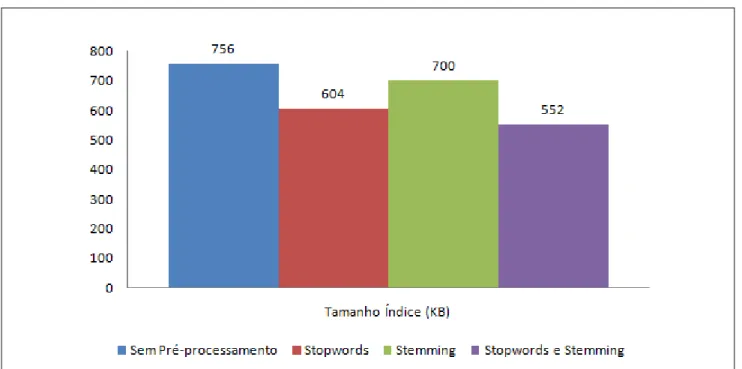
Tamanho do índice
Desta forma, os tamanhos dos índices foram analisados de acordo com os procedimentos de pré-processamento realizados, conforme mostrado na Figura 74. Para documentos de 30 MB, o tamanho do índice sem procedimentos de pré-processamento foi de 756 KB, ou seja, 2,5% do tamanho total do documento. Dos testes realizados, pode-se concluir que a utilização do pré-processamento de texto tem grande influência no tamanho dos índices, o que confirma a tese de Aranhe (2007) de que um bom pré-processamento de texto é fundamental para o sucesso da mineração de dados. textos do sistema, tanto na redução da dimensionalidade das expressões quanto no tamanho dos índices.
PROBLEMAS ENCONTRADOS
Conversão dos documentos
Durante a indexação dos documentos, algumas exceções foram observadas nos logs de indexação durante a conversão do conteúdo do documento em texto simples e a extração de seus metadados. Ao extrair o texto, o erro ocorria devido a documentos que não continham texto em seu corpo, ou seja, documentos cujo conteúdo consistia apenas em imagens, problema que é muito frequentemente encontrado em arquivos PDF que foram digitalizados ou criados a partir de imagens, tornando é impossível através da API Apache Tika transformar seu conteúdo em texto, resultando em um erro de conversão. Apesar de tratar as exceções criadas para este tipo de situação, o problema não foi resolvido; Seria necessário, para tais documentos, realizar um OCR (Optical Character Recognition) ou processo similar para extrair seu conteúdo textual.
Tratamento dos textos
Quanto aos erros encontrados na extração de metadados, trata-se de falta de dados no campo título de alguns documentos. A solução ideal seria algo como uma lista de parada, onde quando cadeias de caracteres indesejadas são reconhecidas, o usuário pode registrá-las através da interface do sistema para que sejam ignoradas quando os dados forem extraídos.
Classificação dos documentos
Com o desenvolvimento deste trabalho pode-se concluir que diversas ferramentas podem ser encontradas para a área de mineração de textos. Porém, atuam principalmente especificamente em processos de mineração de texto. Uma Abordagem de Pré-processamento Automático para Mineração de Texto em Português: Da Perspectiva da Inteligência Computacional.