MODELOS DE SOBREVIVˆ
ENCIA COM
FRA ¸
C ˜
AO DE CURA E
OMISS ˜
AO NAS COVARI ´
AVEIS
Renata Santana Fonseca
Disserta¸c˜ao apresentada ao Corpo Docente do Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıs-tica - CCET - UFRN, como requisito parcial para obten¸c˜ao do t´ıtulo de Mestre em Matem´atica Aplicada e Estat´ıstica.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica Orientador: Profa Dra Dione Maria Valen¸ca
Modelos de Sobrevivˆencia com Fra¸c˜
ao de Cura e
Omiss˜
ao nas Covari´
aveis
Este exemplar corresponde `a reda¸c˜ao final da disserta¸c˜ao devidamente corrigida, defendida por Renata Santana Fonseca e aprovada pela comiss˜ao julgadora.
Natal, mar¸co de 2009
BANCA EXAMINADORA:
Profa Dra Dione Maria Valen¸ca (orientadora) - DEST - UFRN
Profa Dra Jeanete Alves Moreira - DEST - UFRN
Prof. Dr. Dami˜ao N´obrega da Silva - DEST - UFRN
Profa Dra Silvia Maria de Freitas - DEMA - UFC
Dedicat´
oria
Dedico este trabalho a todos aqueles que choraram saudades junto comigo.
Agradecimentos
Tudo ´e do Pai, toda Honra e toda Gl´oria, ´e dele a vit´oria alcan¸cada em minha vida.
Agrade¸co `a minha orientadora, Dione pela orienta¸c˜ao, paciˆencia e por ter me mostrado o prazer de se fazer um trabalho como este.
Tenho muito que agradecer aos meus pais, Antonio e Edneide pelos valores trans-mitidos em todo o percurso da minha vida e pelo apoio incondicional em todas as horas.
Ao meu eterno amigo, companheiro e, mais do que nunca, grande amor, Gilmar pela compreens˜ao, enorme paciˆencia e dedica¸c˜ao que me foram mostrados ao longo destes dois anos.
Meus irm˜aos, Liu, Nando e Bia, sobrinha, Pam, cunhados, Tom e J´u e amigas C´ıntia, Nivea, Mar´ılia, Mariese e Relva, obrigada pelos momentos de descontra¸c˜ao em Salvador, boas recargas de ˆanimo pra continuar a jornada.
Aos amigos de Natal. Allan, Cec´ılio, Manass´es, Patr´ıcia e Renatinha. Sem vocˆes eu n˜ao seria nada, n˜ao teria chegado at´e o fim. Obrigada pelo apoio nas horas em que pensava em desistir, pelas poucas, por´em gostosas farras que fizemos e pela ver-dadeira amizade. Com vocˆes aprendi muito sobre convivˆencia e respeito, mas n˜ao posso esquecer de pedir desculpas pelas grosserias.
Aos professores da UFRN, Dami˜ao, Jeanete, Pledson, Carla e Paulo pela recep-tividade, pelos conselhos, dicas e principalmente por acreditarem no meu potencial e me incentivarem a continuar com os estudos.
Aos colegas do PPGMAE, Hermes, pela enciclop´edia que carrega e sempre tem uma resposta pra todas as perguntas, Lenilson, Neto, Daniel, Tatiana, Enai, Camila, Aparecida e Mois´es pelos consolos, pelas solu¸c˜oes de exerc´ıcios e programas.
Ao secret´ario Rafael e ex-secret´ario Paulo pela disposi¸c˜ao em ajudar e esclarecer d´uvidas, e a todos os funcion´arios do CCET.
Ao professor Heleno Bolfarine pela sugest˜ao do tema. `
A Cristiane Fernandes (Cris), a primeira pessoa que conheci em Natal, que mesmo sem saber quem eu era, me orientou e ajudou nos primeiros dias.
E `a CAPES pelo apoio financeiro.
Resumo
Neste trabalho estudamos o modelo de sobrevivˆencia com fra¸c˜ao de cura proposto por Yakovlev et al. (1993) que possui uma estrutura de riscos competitivos. Covari´a-veis s˜ao introduzidas para modelar o n´umero m´edio de riscos e permitimos que algumas destas covari´aveis apresentem omiss˜ao. Consideramos apenas os casos em que as cova-ri´aveis omissas s˜ao categ´oricas e as estimativas dos parˆametros s˜ao obtidas atrav´es do algoritmo EM ponderado. Apresentamos uma s´erie de simula¸c˜oes para confrontar as estimativas obtidas atrav´es deste m´etodo com as obtidas quando se exclui do banco de dados as observa¸c˜oes que apresentam omiss˜ao, conhecida como an´alise de casos comple-tos. Avaliamos tamb´em atrav´es de simula¸c˜oes, o impacto na estimativa dos parˆametros quando aumenta-se o percentual de curados e de censura entre indiv´ıduos n˜ao curados. Um conjunto de dados reais referentes ao tempo at´e a conclus˜ao do curso de estat´ıstica na Universidade Federal do Rio Grande do Norte ´e utilizado para ilustrar o m´etodo.
Palavras - chave: An´alise de Sobrevivˆencia; Fra¸c˜ao de cura; vari´aveis omissas;
Abstract
In this work we study the survival cure rate model proposed by Yakovlev (1993) that are considered in a competing risk setting. Covariates are introduced for modeling the cure rate and we allow some covariates to have missing values. We consider only the cases by which the missing covariates are categorical and implement the EM algorithm via the method of weights for maximum likelihood estimation. We present a Monte Carlo simulation experiment to compare the properties of the estimators based on this method with those estimators under the complete case scenario. We also evaluate, in this experiment, the impact in the parameter estimates when we increase the proportion of immune and censored individuals among the not immune one. We demonstrate the proposed methodology with a real data set involving the time until the graduation for the undergraduate course of Statistics of the Universidade Federal do Rio Grande do Norte.
Sum´
ario
1 Introdu¸c˜ao 1
1.1 Conceitos b´asicos de an´alise de sobrevivˆencia . . . 1
1.2 Fra¸c˜ao de cura . . . 4
1.3 O Problema de dados omissos . . . 7
1.3.1 Mecanismos de omiss˜ao . . . 9
1.4 Objetivos . . . 10
1.5 Estrutura da disserta¸c˜ao . . . 11
2 Modelo com Fra¸c˜ao de Cura 12 2.1 Formula¸c˜ao do modelo . . . 12
2.2 Fun¸c˜ao de verossimilhan¸ca . . . 15
2.3 Modelo param´etrico Weibull . . . 18
3 Modelo com Fra¸c˜ao de Cura e Omiss˜ao nas Covari´aveis 21 3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM . . . 21
3.1.1 Algoritmo EM ponderado . . . 23
3.1.2 Modelando a distribui¸c˜ao das covari´aveis . . . 27
4 Estudo de Simula¸c˜ao 29 4.1 Obten¸c˜ao dos dados simulados . . . 29
4.2 Resultados para os dados simulados . . . 32
4.2.1 Resultados para amostras completamente observadas . . . 32
4.2.2 Efeito das omiss˜oes nas estimativas dos parˆametros . . . 34
5 Aplica¸c˜ao 43
5.1 Ajuste do modelo aos dados de evas˜ao escolar . . . 43
6 Considera¸c˜oes Finais 48
6.1 Conclus˜ao . . . 48 6.2 Pesquisas futuras . . . 49
A Obten¸c˜ao da Fun¸c˜ao de Verossimilhan¸ca 51
A.1 Verossimilhan¸ca . . . 51 A.2 Verossimilhan¸ca marginal . . . 53
B Aspectos Computacionais 55
Cap´ıtulo 1
Introdu¸
c˜
ao
Neste trabalho abordamos aspectos te´oricos, computacionais e aplicados de an´alise estat´ıstica para modelar dados de sobrevivˆencia extra´ıdos de uma popula¸c˜ao na qual uma parcela dos indiv´ıduos est´a imune `a ocorrˆencia do evento (ou s˜ao conside-rados cuconside-rados). Al´em disso, estudamos um procedimento para tratar a ocorrˆencia de omiss˜ao em covari´aveis.
Faremos neste cap´ıtulo, uma breve introdu¸c˜ao aos conceitos b´asicos de an´alise de sobrevivˆencia, `a modelagem para dados com fra¸c˜ao de cura e ao problema de dados omissos, seguida de uma revis˜ao bibliogr´afica com algumas propostas encontradas na literatura para tratar de dados com tais caracter´ısticas.
1.1
Conceitos b´
asicos de an´
alise de sobrevivˆ
encia
A an´alise de sobrevivˆencia ´e um conjunto de t´ecnicas estat´ısticas que servem para analisar dados correspondentes ao tempo at´e ocorrˆencia de determinado evento; como, por exemplo, o tempo at´e a morte ou o tempo at´e a cura de um paciente, ou ainda, o tempo at´e a falha de um equipamento eletrˆonico.
Estes m´etodos foram originalmente designados para estudos de mortalidade, ex-plicando, portanto, o nome “sobrevivˆencia”. No entanto, a aplicabilidade destas t´ecni-cas se estende a diversas ´areas do conhecimento. Na engenharia, onde recebe o nome
1.1 Conceitos b´asicos de an´alise de sobrevivˆencia 2
de “confiabilidade”, busca-se estudar o tempo at´e a falha de um equipamento, na crimi-nologia o interesse pode ser o tempo at´e um ex-detento reincidir no crime, na educa¸c˜ao, o tempo at´e a conclus˜ao de um curso. Na literatura refere-se a este tempo comotempo de falha.
Seja T uma vari´avel aleat´oria cont´ınua n˜ao negativa representando o tempo de vida, f(t) a sua correspondente fun¸c˜ao densidade eF(t) a fun¸c˜ao distribui¸c˜ao acumu-lada. Em an´alise de sobrevivˆencia, existe um especial interessse na probabilidade de um indiv´ıduo sobreviver pelo menos at´e o tempot, conhecida como fun¸c˜ao de sobrevivˆencia que ´e dada por
S(t) =P(T > t) =
∞
t
f(u)du= 1−F(t), para t >0. (1.1)
Esta ´e uma fun¸c˜ao mon´otona decrescente com as seguintes propriedades:
(i) S(0) = 1;
(ii) lim
t→∞S(t) = 0.
Fun¸c˜oes de sobrevivˆencia que n˜ao satisfazem `a propriedade (ii) s˜ao denominadas fun¸c˜oes de sobrevivˆencia impr´oprias ou com fra¸c˜ao de cura, ou ainda de longa dura¸c˜ao (Rodrigues, Cancho, & Castro 2008) e s˜ao objeto de estudo desta disserta¸c˜ao.
Outra fun¸c˜ao de interesse na an´alise de sobrevivˆencia ´e a fun¸c˜ao risco, que es-pecifica a taxa de falha instantˆanea no tempot, definida como
h(t) = lim Δt→0+
P(t < T ≤t+ Δt|T > t)
Δt (1.2)
As fun¸c˜oes de densidade, de sobrevivˆencia e de risco s˜ao matematicamente rela-cionadas. Assim, conhecendo uma delas pode-se obter as outras atrav´es das seguintes rela¸c˜oes:
h(t) =−dlogS(t)
dt =
f(t)
S(t), (1.3)
f(t) =−dS(t)
1.1 Conceitos b´asicos de an´alise de sobrevivˆencia 3
Uma propriedade da fun¸c˜ao risco que define uma importante classe de modelos ´e a proporcionalidade dos riscos, ou seja, para duas unidades observacionais distintas i
e j, a raz˜ao entre os riscoshi(t)/hj(t) =k, sendo k constante para todo tempo t. Por exemplo, se k = 3 , dizemos que o risco (de falha) do indiv´ıduo i ´e trˆes vezes o risco do indiv´ıduo j em todo o per´ıodo de acompanhamento. Um modelo cuja fun¸c˜ao risco satisfaz esta condi¸c˜ao ´e chamado de modelo de riscos porporcionais.
A principal caracter´ıstica de dados de sobrevivˆencia ´e a presen¸ca de censura, que ´e uma observa¸c˜ao parcial da resposta (tempo de falha). Isto ocorre devido a perda de acompanhamento do indiv´ıduo, seja porque o paciente morreu de causa diferente da estudada, mudou de cidade, ou porque, ao final do estudo, o evento n˜ao foi observado. Sem a presen¸ca de censura, as t´ecnicas estat´ısticas cl´assicas, como an´alise de regress˜ao e planejamento de experimento, poderiam ser utilizadas na an´alise deste tipo de dados, provavelmente usando uma transforma¸c˜ao para a resposta. No entanto, se houver censuras, tais t´ecnicas n˜ao podem ser utilizadas (Colosimo & Giolo 2006). Neste caso, sabe-se que o tempo entre o in´ıcio do estudo e a ocorrˆencia do evento ´e maior do que o observado, o que caracteriza censura `a direita. No entanto, o tempo durante o qual o indiv´ıduo esteve em observa¸c˜ao ´e aproveitado. Dentre os mecanismos de censura existentes podemos citar:
• acensura tipo Iem que experimento ´e realizado em um per´ıodo de tempo
pr´e-fixado, de forma que o tempo de vida do indiv´ıduo ´e conhecido apenas se ocorrer antes do final do estudo;
• a censura tipo II em que o estudo ´e realizado at´e que o evento ocorra um
n´umero pr´e-estabelecido de vezes e
• a censura alet´oria, que ´e a mais freq¨uente em estudos reais, caracteriza-se
1.2 Fra¸c˜ao de cura 4
vari´aveis aleat´orias. Quando a distribui¸c˜ao da censura n˜ao envolve parˆametros de interesse ao estudo, dizemos que a censura ´e n˜ao infomativa.
1.2
Fra¸
c˜
ao de cura
Em modelos tradicionais de tempos de falha, assume-se que em dado momento o evento de interesse ir´a ocorrer para todos os indiv´ıduos observados ap´os um espa¸co de tempo razo´avel, isto ´e, todos os indiv´ıduos est˜ao em risco durante a realiza¸c˜ao do estudo.
No entanto, em determinados experimentos, alguns indiv´ıduos podem nunca apre-sentar o evento pois est˜ao curados ou s˜ao consideradosimunes ao evento. Se, por exem-plo, o evento de interesse ´e a recorrˆencia de determinado tipo de cˆancer, ap´os aplica¸c˜ao de tratamentos, uma parte dos indiv´ıduos em estudo pode n˜ao apresentar o retorno da doen¸ca (da´ı a denomina¸c˜ao “fra¸c˜ao de cura”). Dados com estas caracter´ısticas podem surgir em outros contextos. Por exemplo, em estudos na ´area de criminologia um pos-s´ıvel evento de interesse ´e o tempo at´e um ex-detento reincidir no crime, entretanto, alguns deles estar˜ao reabilitados e n˜ao apresentar˜ao tal evento. Na demografia, em estudos sobre tempo at´e o div´orcio, alguns casais podem nunca experimentar o evento. Modelar estes dados ignorando a existˆencia de uma parcela de curados ou imunes na popula¸c˜ao pode conduzir o pesquisador a conclus˜oes distorcidas, ao passo que quando esta caracter´ıstica ´e incorporada no modelo, pode-se saber, por exemplo, qual tratamento resulta em uma maior propor¸c˜ao de curados, ou que tratamento ´e mais eficiente para determinado perfil de paciente.
1.2 Fra¸c˜ao de cura 5
pela experiˆencia do pesquisador.
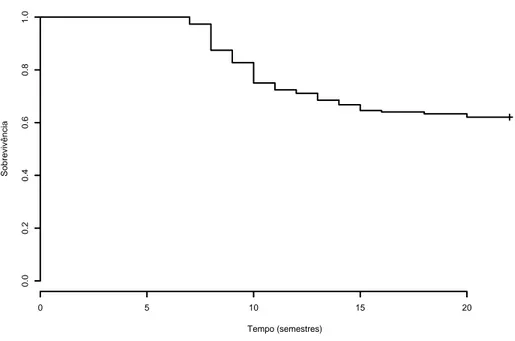
A presen¸ca de imunes na popula¸c˜ao pode ser identificada atrav´es do gr´afico da fun¸c˜ao de sobrevivˆencia emp´ırica conhecida como Kaplan-Meier ou estimador produto-limite (Kaplan & Meier 1958). Se a cauda direita apresenta um n´ıvel aproximadamente constante e estritamente maior do que zero durante um per´ıodo de tempo razo´avel, caracterizando uma fun¸c˜ao de sobrevivˆencia impr´opria (fun¸c˜ao que n˜ao converge para zero a medida que o tempo cresce), h´a ind´ıcios da presen¸ca de imunes.
A Figura 1.1 mostra a curva de sobrevivˆencia estimada para um conjunto de dados reais referente ao tempo at´e a conclus˜ao do curso de gradua¸c˜ao em Estat´ıstica da UFRN. Observa-se que a cauda direita alcan¸ca um patamar acima de zero por um per´ıodo consider´avel, o que retrata o comportamento de uma fun¸c˜ao de sobrevivˆencia impr´opria.
0 5 10 15 20
0.0
0.2
0.4
0.6
0.8
1.0
Tempo (semestres)
Sobrevivência
Figura 1.1: Fun¸c˜ao de Sobrevivˆencia estimada para os dados de tempo at´e a conclus˜ao do curso de gradua¸c˜ao em Estat´ıstica da UFRN no per´ıodo de 1997 a 2004. Amostra com n= 414 alunos.
1.2 Fra¸c˜ao de cura 6
da popula¸c˜ao n˜ao curada e outra ´e dada por uma distribui¸c˜ao degenerada com tempos infinitos para os imunes (Boag 1949; Berkson & Gage 1952). Neste modelo, conhecido como modelo de mistura padr˜ao, ´e assumido que uma fra¸c˜ao π (0< π < 1) da popu-la¸c˜ao est´a curada, e a restante 1−π, n˜ao est´a curada. Utilizando uma parti¸c˜ao em imunes (I) e n˜ao imunes (NI), comP(I) =πeP(NI) = 1−πa fun¸c˜ao de sobrevivˆencia para a popula¸c˜ao, denotada por Spop(t) para este modelo, ´e dada por
Spop(t) = P(T > t)
= P(T > t|I)P(I) +P(T > t|NI)P(NI)
= π+ (1−π)S∗(t), (1.5)
em que P(T > t|NI) = S∗(t) denota a fun¸c˜ao de sobrevivˆencia para a popula¸c˜ao n˜ao
imune e P(T > t|I) = 1 para todot >0.
Algumas desvantagens deste modelo s˜ao apontadas por Chen, Ibrahim, & Sinha (1999). Na presen¸ca de covari´aveis relacionadas com o parˆametro π, o modelo de mis-tura padr˜ao n˜ao possui a propriedade de riscos proporcionais. Al´em disso, no contexto bayesiano, as distribui¸c˜oes a priori n˜ao informativas impr´oprias implicam, em geral, em distribui¸c˜oes a posteriori impr´oprias.
Neste trabalho, discutimos um modelo alternativo com estrutura de riscos com-petitivos1 proposto por Yakovlev et al. (1993) e Chen, Ibrahim, & Sinha (1999), que ´e referido em Rodrigues, Cancho, & Castro (2008) comomodelo de tempo de promo¸c˜ao. Este modelo supera tais desvantagens e ser´a descrito com detalhes no Cap´ıtulo 2.
Modelos de sobrevivˆencia com fra¸c˜ao de cura tˆem sido extensivamente discutidos e aplicados a dados reais na literatura estat´ıstica por v´arios autores nos ´ultimos anos. T´ecnicas bayesianas para estima¸c˜ao dos parˆametros do modelo de tempo de promo¸c˜ao s˜ao dadas em Ibrahim, Chen, & Sinha (2001). Utilizando o modelo de tempo de promo¸c˜ao, Zaider et al. (2001) estudam o efeito de diferentes doses de radia¸c˜ao sobre a fra¸c˜ao de curados em pacientes com cˆancer de pr´ostata. A proposta de Yin & Ibrahim
1
1.3 O Problema de dados omissos 7
(2005) consiste em uma classe de modelos que naturalmente liga uma fam´ılia de fun¸c˜oes de sobrevivˆencia pr´oprias e impr´opras. Um modelo unificado, que inclui o modelo de mistura padr˜ao e o modelo de tempo de promo¸c˜ao como dois casos especiais, ´e discutido em Rodrigues & Louzada-Neto (2006). O modelo de tempo de promo¸c˜ao foi estendido por Mizoi (2007) para a situa¸c˜ao em que h´a erro de medi¸c˜ao nas covari´aveis. Uma abordagem semiparam´etrica que permite utilizar dados correlacionados no modelo de mistura padr˜ao ´e discutida em Peng et al. (2007). Um teste para avaliar a suficiˆencia do tempo de acompanhamento em uma ampla classe de modelos de fra¸c˜ao de cura foi proposto por Klebanov & Yakovlev (2007).
A inclus˜ao de informa¸c˜oes concomitantes no modelo de fra¸c˜ao de cura ´e de grande importˆancia para descrever a heterogeneidade da popula¸c˜ao. Unidades com caracter´ıs-ticas diferentes certamente apresentar˜ao tempos de sobrevida e chance de cura dife-rentes. Contudo, algumas destas informa¸c˜oes podem n˜ao ser observadas para todos os indiv´ıduos, resultando em algumas lacunas na matriz de dados. Na pr´oxima se¸c˜ao, descrevemos o problema e caracter´ısticas importantes em dados com omiss˜oes nas co-vari´aveis.
1.3
O Problema de dados omissos
A presen¸ca de omiss˜ao em covari´aveis ´e um problema frequente na an´alise es-tat´ıstica e pode ser causada por diversos fatores, como por exemplo, a recusa de um indiv´ıduo a fornecer alguma informa¸c˜ao ou a morte de um paciente antes de realizar todos os exames. Em um experimento industrial, algumas covari´aveis podem n˜ao ser observadas em equipamentos quebrados devido a causas n˜ao relacionadas ao processo experimental.
1.3 O Problema de dados omissos 8
percentual de dados omissos, pode causar perda de informa¸c˜ao e resultar em estimativas tendenciosas e ineficientes. Portanto, ´e importante o desenvolvimento de m´etodos que incorporem os dados omissos nas an´alises. Uma revis˜ao sobre os m´etodos existentes para ajustar modelos de regress˜ao utilizando este tipo de dado ´e abordada em Little (1992), que destaca maior eficiˆencia dos m´etodos de imputa¸c˜ao m´ultipla.
Muitas propostas vˆem sendo discutidas para tratar dados omissos em diversos con-textos. Diversas t´ecnicas para an´alise de dados que apresentam omiss˜ao s˜ao abordadas por Roderick, Little, & Rubin (1987). Quando as covari´aveis omissas s˜ao categ´oricas, Ibrahim (1990) prop˜oem utilizar o algoritmo EM ponderado (Dempster et al. 1977) para obter estimativas dos parˆametros em modelos lineares generalizados. Esta t´ecnica foi extendida por Ibrahim, Chen, & Lipsitz (1999) para covari´aveis cont´ınuas ou mistas (cont´ınuas e categ´oricas), em que ´e implementada a vers˜ao Monte Carlo do algoritmo EM (Tanner 1996). O algoritmoEM ponderado ´e descrito em detalhes por Horton & Laird (1999) que, por meio de exemplos, ilustram sua aplica¸c˜ao discutindo vantagens e limita¸c˜oes. Na ´area de sobrevivˆencia, modelos com fra¸c˜ao de cura, efeitos aleat´orios permitindo omiss˜ao n˜ao-ignor´avel nas covari´aveis ´e discutido por Herring & Ibrahim (2002).
1.3 O Problema de dados omissos 9
1.3.1
Mecanismos de omiss˜
ao
Para analisar dados omissos deve-se levar em conta o processo que causa as omiss˜oes, conhecido como mecanismos de omiss˜ao, originalmente descritos em Rubin (1976). Em particular, ´e necess´ario considerar se a omiss˜ao nas covari´aveis est´a rela-cionada com as vari´aveis no conjunto de dados.
Seja X a matrix de covari´aveis, T o vetor de tempos at´e a falha e C o vetor de tempos de censura. Se houver omiss˜ao, pode-se particionar a matriz de covari´aveis X
em (Xobs,Xmis), em queXmis ´e uma matriz de covari´aveis com omiss˜ao e Xobs ´e uma matriz de covari´aveis completamente observadas.
Considere que, para a j-´esima covari´avel,j = 1, . . . , p, tem-se a vari´avel aleat´oria indicadora de omiss˜ao Rj, que vale 1 se Xj ´e omissa e 0 caso contr´ario.
O mecanismo de omiss˜ao ´e caracterizado pela distribui¸c˜ao condicional deRj dado (X,T,C), digamos P(Rj|X,T,C;τ), sendoτ um vetor de parˆametros desconhecidos. Se as omiss˜oes n˜ao dependem dos valores de (X,T,C), omissos ou observados, isto ´e, se
P(Rj =rj|X,T,C,τ) = P(Rj =rj|τ),
os dados s˜ao classificados como MCAR (missing completely at random). Em outras palavras, supor que os dados s˜ao MCAR significa supor que os indiv´ıduos com dados omissos tˆem o mesmo perfil que os indiv´ıduos completamente observados. Se, por exemplo, um indiv´ıduo entrou tardiamente no estudo e n˜ao realiza todos os exames antes de findar o per´ıodo de observa¸c˜ao, esta suposi¸c˜ao ´e adequada.
O mecanismo conhecido por omiss˜ao aleat´oria ou MAR (missing at random) sup˜oe que as probabilidades condicionais de omiss˜ao dependem apenas do que ´e obser-vado, isto ´e
P(Rj =rj|X,T,C,τ) =P(Rj =rj|Xobs,T,C,τ).
1.4 Objetivos 10
todos os exames, indicando que a omiss˜ao est´a relacionada aos tempos de falha, ent˜ao, o mecanismo de omiss˜ao aparentemente ´e MAR.
Se as probabilidades condicionais de omiss˜ao dependem tamb´em das quantidades n˜ao observadas e n˜ao podem ser completamente explicadas pelos dados observados, a omiss˜ao ´e chamada n˜ao aleat´oria (missing not at random) - MNAR ou n˜ao ignor´avel. Em termos de probabilidade, o mecanismo MNAR pode ser representado comoP(Rj =
rj|X,T,C,τ) e n˜ao pode ser simplificada. ´
E importante salientar que ao excluir as observa¸c˜oes omissas, pressup˜oe-se que a omiss˜ao ´e do tipo MCAR, ou seja, que os indiv´ıduos com covari´aveis completamente observadas constituem uma subamostra aleat´oria da amostra original, o que n˜ao ´e razo´avel na maioria das circunstˆancias.
1.4
Objetivos
O objetivo deste trabalho ´e implementar um procedimento de estima¸c˜ao dos parˆametros do modelo com fra¸c˜ao de cura em que algumas observa¸c˜oes apresentam omiss˜ao em pelo menos uma das covari´aveis. A proposta de Chen & Ibrahim (2001) consiste em implementar a vers˜ao Monte Carlo do algoritmo EM, permitindo que as covari´aveis sejam cont´ınuas, categ´oricas ou mistas. Nossa proposta difere desta pois utilizamos uma verossimilhan¸ca marginal, que elimina as vari´aveis latentes, simplifi-cando o uso do algoritmo EM, que ser´a empregado para imputar somente os dados omissos. Al´em disso, consideramos apenas os casos em que as covari´aveis omissas s˜ao categ´oricas, assim, podemos utilizar o algoritmoEM ponderado proposto por Ibrahim (1990).
1.5 Estrutura da disserta¸c˜ao 11
indiv´ıduos n˜ao imunes em amostras completamente observadas e amostras com omis-s˜ao, bem como o quanto o percentual de dados omissos pode interferir nos resultados das an´alises.
1.5
Estrutura da disserta¸
c˜
ao
Cap´ıtulo 2
Modelo com Fra¸
c˜
ao de Cura
Neste cap´ıtulo, descrevemos a formula¸c˜ao do modelo com fra¸c˜ao de cura proposto por Yakovlev et al. (1993), bem como as fun¸c˜oes de verossimilhan¸ca e verossimilhan¸ca marginal associadas, supondo que os tempos de promo¸c˜ao seguem uma distribui¸c˜ao Weibull.
2.1
Formula¸
c˜
ao do modelo
SejaM uma vari´avel aleat´oria (v.a.) representando o n´umero de causas ou riscos de ocorrˆencia de um particular evento de interesse. ´E assumido queM tem distribui¸c˜ao
P oisson(θ). Dado M =m, sejam Zj, j = 1, . . . , m, vari´aveis aleat´orias cont´ınuas n˜ao negativas, independentes e identicamente distribu´ıdas com fun¸c˜ao distribui¸c˜ao acumu-lada F(·) = 1−S(·) e independentes de M, representando o tempo de ocorrˆencia do evento devido `a j-´esima causa ou risco, ou o tempo de promo¸c˜ao do evento. O tempo at´e a ocorrˆencia do evento de interesse ´e definido como Y = min{Zj; 0≤j ≤M}
comP (Z0 =∞) = 1, pois se M = 0 n˜ao existem causas ou riscos para a ocorrˆencia do evento de interesse. As vari´aveisM eZj s˜ao vari´aveis latentes, ou seja, n˜ao observ´aveis eY ´e uma v.a. observ´avel que pode ser censurada `a direita. Para este modelo a fun¸c˜ao
2.1 Formula¸c˜ao do modelo 13
de sobrevivˆencia para a popula¸c˜ao ´e dada por
Sp(y) = P(Y > y) =Pmin{Z0, Z1, ..., ZM}> y
,
que usando a lei da probabilidade total (Magalh˜aes, 2006; p. 29) pode ser escrita como
Sp(y) =
∞
k=0
Pmin{Z0, Z1, ..., ZM}> y|M =k
P (M =k)
= P(Z0 > y)P(M = 0) +
∞
k=1
Pmin{Z1, . . . , Zk}> y
θk
k!e
−θ
= e−θ+
∞
k=1
PZ1 > y, ..., Zk > y
θk
k!e
−θ,
poisP(Z0 > y) = 1, para todo y. Agora, dadoM =k, parak = 1, . . . ,∞, as vari´aveis aleat´oriasZj,j = 1, . . . , M s˜ao independentes e identicamente distribu´ıdas com fun¸c˜ao de sobrevivˆenciaS(y), ent˜ao, segue que
Sp(y) = e−θ+
∞
k=1
S(y)kθ k
k!e
−θ
= e−θ
∞
k=0
S(y)kθk
k! = e−θeθS(y)
= exp [−θ(1−S(y))],
e portanto,
Sp(y) = exp [−θF(y)], (2.1)
em queF(y), a fun¸c˜ao de distribui¸c˜ao acumulada deZj,j = 1. . . , M ´e uma fun¸c˜ao de distribui¸c˜ao pr´opria. Consequentemente,
lim
2.1 Formula¸c˜ao do modelo 14
ou seja, Sp(y) ´e uma fun¸c˜ao de sobrevivˆencia impr´opria e exp(−θ) = P(M = 0) representa a fra¸c˜ao de cura induzida pelo modelo.
Pode-se observar que `a medida que θ cresce, a fra¸c˜ao de cura, exp(−θ) decresce, o que ´e bastante intuitivo, j´a que θ ´e o valor esperado para a vari´avel latente M, que representa o n´umero de causas ou riscos de ocorrˆencia do evento. Consequentemente, o indiv´ıduo que apresenta um elevado n´umero de causas para ocorrˆencia do evento ter´a baixa fra¸c˜ao de cura. O raioc´ınio para θ decrescente ´e an´alogo.
Atrav´es das rela¸c˜oes entre as fun¸c˜oes de sobrevivˆencia, risco e densidade, dadas em (1.3) e (1.4), ´e poss´ıvel obter a fun¸c˜ao de densidade correspondente a (2.1) como sendo
fp(y) = θf(y) exp{−θF(y)}, y >0, (2.2)
com f(y) = dF(y)/dy uma fun¸c˜ao densidade pr´opria. A fun¸c˜ao risco (taxa de falha instantˆanea) para a popula¸c˜ao ´e
hp(y) = fp(y)
Sp(y) =θf(y). (2.3)
Quando relacionamos covari´aveis ao parˆametro θ, a fun¸c˜ao risco em (2.3) possui uma estrutura de riscos proporcionais, que ´e uma propriedade desej´avel na an´alise de sobrevivˆencia. Isto ocorre devido `a suposi¸c˜ao de que a vari´avel latente M, que repre-senta o n´umero de riscos ou causas para a ocorrˆencia do evento, segue uma distribui¸c˜ao de Poisson (Rodrigues, Cancho, & Castro 2008).
A fun¸c˜ao de sobrevivˆencia para a popula¸c˜ao n˜ao curada ´e dada por
S∗(y) = P(Y > y|M ≥1) = P(Y > y, M ≥1)
P(M ≥1)
= exp{−θF(y)} −exp(−θ)
1−exp(−θ) . (2.4)
2.2 Fun¸c˜ao de verossimilhan¸ca 15
de promo¸c˜ao atrav´es da rela¸c˜ao
Sp(y) = exp(−θ) + [1−exp(−θ)]S∗(y),
em que S∗(y) ´e dada por (2.4) e a fra¸c˜ao de cura ´e π = exp(−θ). Isto mostra que
o modelo (2.1) pode ser escrito como o modelo de mistura padr˜ao com uma fam´ılia espec´ıfica de fun¸c˜oes de sobrevivˆencia S∗(y) dada em (2.4).
2.2
Fun¸
c˜
ao de verossimilhan¸
ca
Considere uma amostra aleat´oria denindiv´ıduos de uma determinada popula¸c˜ao. Define-se portanto, as seguintes vari´aveis:
• Mi - vari´avel latente representando o n´umero de causas para a ocorrˆencia do evento no i-´esimo indiv´ıduo, com Mi ∼P oisson(θi), i= 1, . . . , n;
• Zij s˜ao os tempos, n˜ao observ´aveis, at´e a ocorrˆencia do evento devido `a j-´esima causa ou risco, com j = 1, . . . , Mi para o i-´esimo indiv´ıduo, com fun¸c˜ao dis-tribui¸c˜ao acumulada F(·|λ) = 1−S(·|λ) que n˜ao depende de Mi, sendo λ um vetor de parˆametros desconhecidos;
• yi = min{Ti, Ci} , tempo de falha observado, com Ti = min{Zij; 0≤j ≤Mi} e
Ci tempo de censura do i-´esimo indiv´ıduo;
• δi - indicador de censura, com δi igual a 1, seTi ≤Ci, e igual a zero, se Ti > Ci;
• x′
i = (xi1, ..., xip) vetor p-dimensional de covari´aveis associado ao i-´esimo indiv´ı-duo;
Considere os vetores n-dimensionais
2.2 Fun¸c˜ao de verossimilhan¸ca 16
δ = (δ1, δ2, . . . , δn)′
M= (M1, M2, . . . , Mn)′, e a matriz de covari´aveis de dimens˜ao n×p
X=
⎛
⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝
x′
1
x′
2 ...
x′
n
⎞
⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠
,
denotamos o conjunto dos dados completos (que inclui os dados observados e as vari´a-veis latentes) porDc = (n,y,δ,M,X) e os dados observados porD= (n,y,δ,X).
Covari´aveis s˜ao introduzidas no parˆametro θ atrav´es da rela¸c˜ao θ ≡ θ(x′β) = exp(x′β), com β = (β1, ..., βp)′ representando o vetor de coeficientes de regress˜ao, de maneira que a fra¸c˜ao de cura para o indiv´ıduo i ´e
π(xi) = exp(−θi) = exp{−exp(x′iβ)}. (2.5) Denotando a densidade conjunta de (yi, δi, Mi) por
f(yi, δi, Mi) = f(yi, δi|Mi)f(Mi),
temos, conforme mostrado em (A.1), que
f(yi, δi|Mi) =S(yi|λ)Mi−δi[Mif(yi|λ)] δi
, (2.6)
e portanto,
f(yi, δi, Mi) =S(yi|λ)Mi−δi[Mif(yi|λ)]δi
e−θθMi
Mi! .
Sendo φ= (β′,λ′)′ o vetor de parˆametros desconhecidos, a fun¸c˜ao de
2.2 Fun¸c˜ao de verossimilhan¸ca 17
L(φ;Dc) =
n
i=1
S(yi|λ)Mi−δi[Mif(yi|λ)]δi
×exp
n
i=1
[Mix′iβ−ln(Mi!)−exp(x
′
iβ)]
. (2.7)
O logar´ıtmo da fun¸c˜ao de verossimilhan¸ca ´e
ℓ(φ;Dc) = logL(φ;Dc) =
n
i=1
[(Mi−δi) lnS(yi|λ) +δilnMi+δilnf(yi|λ)] +
n
i=1
[Mix′iβ−ln(Mi!)−exp(x
′
iβ)]. (2.8)
Visto que (2.8) n˜ao ´e observ´avel, j´a que depende das vari´aveis latentes Mi, i = 1, . . . , n, pode-se trabalhar com o logar´ıtmo da fun¸c˜ao de verossimilhan¸ca marginal, que pode ser obtida fazendo-se o somat´orio nas vari´aveis Mi. Como mostrado no Apˆendice A.2, a verossimilhan¸ca marginal ´e dada por
L(φ;D) = n
i=1
[x′iβf(yi|λ)] δi
exp−exp(x′iβ)
1−S(yi|λ)
, (2.9)
e o logar´ıtmo da fun¸c˜ao de verossimilhan¸ca marginal ´e
ℓ(φ;D) = n
i=1
δi(x′iβ+ lnf(yi|λ))−exp(x′iβ)
1−S(yi|λ)
. (2.10)
2.3 Modelo param´etrico Weibull 18
(2008).
Para grandes amostras, o estimador de m´axima verossimilhan¸ca ˆφ´e tal que √
n( ˆφ−φ) ˙∼ N0,I−1(φ) em que I(φ) ´e a matriz de informa¸c˜ao de Fisher dada por
I(φ) = −E[¨ℓ(φ)] com
¨
ℓ(φ) = ∂
2ℓ(φ;D)
∂φ∂φ′ .
Como o c´alculo de I(φ) n˜ao ´e poss´ıvel devido `a presen¸ca de censuras, pode-se utilizar a matriz −ℓ¨(φ) avaliada emφ= ˆφque ´e uma estimativa consistente de I(φ), conhecida como matriz de informa¸c˜ao observada que ser´a denotada aqui por Iobs( ˆφ). Assim, pode-se realizar inferˆencias, como intervalos de confian¸ca e testes de hip´oteses, para os parˆametros de interesse.
2.3
Modelo param´
etrico Weibull
Suponha agora que os tempos de promo¸c˜aoZijs˜ao independentes e identicamente distribu´ıdos (i.i.d.) e seguem uma distribui¸c˜ao Weibull com parˆametros λ = (ρ, γ)′,
j = 1, . . . , Mi, i = 1, . . . , n, com densidade f(z) = ρzρ−1exp(γ −zρeγ) e fun¸c˜ao de sobrevivˆenciaS(z) = exp(−zρeγ). Neste caso, o logar´ıtmo da fun¸c˜ao de verossimilhan¸ca dos dados completos em (2.8) ser´a dada por
ℓ(φ;Dc) = n
i=1
−Miyρie γ+δ
iln(Miρyiρ−1e γ)
+ n
i=1
[Mix′iβ−ln(Mi!)−exp(x
′
2.3 Modelo param´etrico Weibull 19
O logar´ıtmo da verossimilhan¸ca marginal em (2.10) toma a forma
ℓ(φ;D) = n
i=1
δi
xi′β+γ+ ln(ρyiρ−1)−yiρeγ −
n
i=1
exp(x′iβ) [1−exp(−y ρ ie
γ)]. (2.12)
Para o modelo (2.12), a matriz de informa¸c˜ao observada, Iobs( ˆφ), fica
Iobs( ˆφ) =
⎛ ⎜ ⎜ ⎜ ⎝ ¨
ℓββ ℓ¨βρ ℓ¨βγ ¨
ℓρρ ℓ¨ργ ¨ ℓγγ ⎞ ⎟ ⎟ ⎟ ⎠
φ= ˆφ
(2.13)
sendo as submatrizes com elementos
¨
ℓββk,l = ∂
2ℓ(φ;D)
∂βl∂βk =−
n
i=1
xilxikexp(x′iβ) [1−exp(−y ρ ie
γ)], l, k= 1, . . . , p,
¨
ℓβlρ = ∂
2ℓ(φ;D)
∂βl∂ρ
=− n
i=1
xilyiρe
γln(yi) exp(x′
iβ−y ρ ie
γ), l= 1, . . . , p,
¨
ℓβlγ = ∂
2ℓ(φ;D)
∂βl∂γ
=− n
i=1
xily ρ ie
γ
exp(x′iβ−y ρ ie
γ
), l= 1, . . . , p,
¨
ℓρρ = ∂
2ℓ(φ;D)
∂ρ∂ρ =−
n
i=1
δi
ρ2 +y ρ ie
γ
(ln(yi))2δi+ exp(x′iβ−y ρ ie
γ
) [1−yρie γ
],
¨
ℓργ = ∂
2ℓ(φ;D)
∂ρ∂γ =−
n
i=1
yiρe γ
ln(yi)δi+ exp(x′iβ−y ρ ie
γ
) [1−yρie γ
],
¨
ℓγγ = ∂2ℓ(φ;D)
∂γ∂γ =−
n
i=1
yiρeγδ
i+ exp(x′iβ−y ρ ie
γ) [1
−yρieγ].
Testes estat´ısticos podem ser realizados para o vetor de parˆametros β, sendo
λ= (ρ, γ) tratados como parˆametros de perturba¸c˜ao.
Considere as hip´oteses H0 :β =β0 versus H1 :β =β0 e seja ˜λ a estimativa de
2.3 Modelo param´etrico Weibull 20
λ para β=β0 fixado. Ent˜ao, a estat´ıstica da raz˜ao de verossimilhan¸cas ´e dada por
ξRV =−2
ℓ(β0,λ˜,D)−ℓ(φˆ,D),
Cap´ıtulo 3
Modelo com Fra¸
c˜
ao de Cura e
Omiss˜
ao nas Covari´
aveis
Neste cap´ıtulo descrevemos o procedimento de estima¸c˜ao dos parˆametros e erros padr˜ao para o modelo com fra¸c˜ao de cura na situa¸c˜ao em que algumas covari´aveis categ´oricas n˜ao s˜ao observadas para todos os indiv´ıduos na amostra. Apresentamos a verossimilhan¸ca marginal (com respeito `as vari´aveis latentes) sob a suposi¸c˜ao de que o mecanismo gerador das omiss˜oes ´e MAR e o algoritmo EM ponderado ser´a utilizado para imputar valores para as covari´avieis omissas.
3.1
Estima¸
c˜
ao de m´
axima verossimilhan¸
ca via
algo-ritmo EM
Suponhamos que o mecanismo gerador da omiss˜ao ´e do tipo MAR, ou seja, a omiss˜ao n˜ao depende dos valores omissos, mas talvez dependa dos valores observa-dos. Assumimos tamb´em que os tempos de falha e censura s˜ao sempre observaobserva-dos. Neste caso, ´e necess´ario considerar um modelo param´etrico para as covari´aveis omis-sas, p(xi;α), em que α ´e um vetor de parˆametros desconhecidos, vistos aqui como parˆametros de perturba¸c˜ao, pois nosso principal interesse ´e realizar inferˆencias sobre o
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 22
vetor de coeficientes de regress˜ao do modelo, β.
Considere que, para a i-´esima unidade amostral, ´e poss´ıvel particionar o vetor
xi em xi = (x′mis,i, x′obs,i)′ com xmis,i um vetor de dimens˜ao qi de covari´aveis omissas e
xobs,i um vetor de dimens˜ao p−qi de covari´aveis completamente observadas.
Seja agoraDobs = (n,y,δ,Xobs) o conjunto de dados observados, comXobs a ma-triz de covari´aveis observadas eψ = (β′,λ′,α′)′, o vetor de parˆametros desconhecidos.
Ent˜ao o logar´ıtmo da fun¸c˜ao de verossimilhan¸ca dos dados completos ´e dada por
ℓ(ψ;Dc) = n
i=1
[(Mi −δi) lnS(yi|λ) +δilnMi+δilnf(yi|λ)] +
n
i=1
[Mix′iβ−ln(Mi!)−exp(x′iβ)] +
n
i=1
ln[p(xi;α)] = ℓ(φ;Dc) +
n
i=1
ln[p(xi;α)] (3.1)
Para eliminar as vari´aveis latentes efetua-se o somat´orio em (3.1) sobre todos os valores poss´ıveis de Mi, de forma an´aloga ao caso sem omiss˜ao, e assim obt´em-se
ℓ(ψ;D) = n
i=1
[δi(x′iβ+ lnf(yi|λ))−exp(x′iβ) (1−S(yi|λ))] + n
i=1
ln[p(xi;α)] = ℓ(φ;D) +
n
i=1
ln[p(xi;α)]. (3.2)
O logar´ıtmo da fun¸c˜ao de verossimilhan¸ca em (3.2) pode ser maximizado atrav´es do algoritmo EM que ´e um procedimento iterativo composto de dois passos a cada itera¸c˜ao: o passo E (Expectation) e o passo M (Maximization), por isso, o algoritmo foi chamado Algoritmo EM por Dempster et al. (1977) e ´e uma poderosa ferramenta para obter estimativas de m´axima verossimilhan¸ca quando existem covari´aveis n˜ao observ´aveis (latentes) ou omissas.
da-3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 23
dos evidentemente incompletos (dados omissos, distribui¸c˜oes truncadas, observa¸c˜oes censuradas ou truncadas), mas tamb´em uma ampla variedade de problemas onde a falta de dados n˜ao ´e natural ou evidente. A desvantagem do algoritmoEM ´e que sua taxa de convergˆencia pode ser extremamente lenta quando existe uma grande fra¸c˜ao de informa¸c˜ao omissa. Nesta disserta¸c˜ao, o algoritmo EM ´e utilizado para encontrar estimativas de m´axima verossimilhan¸ca quando covari´aveis n˜ao s˜ao observadas para todos indiv´ıduos.
Consideramos ψ(k) = (β′(k),λ′(k),α′(k))′ as estimativas de ψ na k-´esima
iter-a¸c˜ao do algoritmo. Para os dados referentes `a i-´esima observa¸c˜ao, os dados sem as vari´aveis latentes s˜ao representados por Di = (yi, δi, xi), e os dados observados por Dobs,i = (yi, δi, xobs,i). No passo E, calcula-se a esperan¸ca condicional de ℓ(ψ|Di) dado a estimativa atualψ(k) e os dados observadosDobs,i, parai= 1, . . . , n. Denotando essa esperan¸ca por Qi(ψ|ψ(k)), o passo E para a i-´esima observa¸c˜ao na k-´esima itera¸c˜ao pode ser escrito como
Qi(ψ|ψ(k)) =Eℓ(ψ,Di)|Dobs,i,ψ(k)
(3.3)
A seguir, descrevemos a obten¸c˜ao deQi(ψ|ψ(k)) para covari´aveis omissas categ´ori-cas utilizando o algorimoEM ponderado.
3.1.1
Algoritmo
EM
ponderado
No caso em que as covari´aveis omissas s˜ao todas categ´oricas, uma t´ecnica ´util para obter etimativas de m´axima verossimilhan¸ca ´e o algoritmo EM ponderado, proposto por Ibrahim (1990) que ´e descrito em detalhes em Horton & Laird (1999).
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 24
o valor x(j)mis,i s˜ao os pesos denotados porw(k)ij , sendo
wij(k)=p(x (j)
mis,i|xobs,i, yi, δi,ψ(k)) =
L(ψ(k);D(j)i )f(x (j) i |α(k)) J
j=1
L(ψ(k);Di(j))f(x(j)i |α(k))
, (3.4)
Para tornar mais clara a obten¸c˜ao de Qi(ψ|ψ(k)), vamos reportar o c´alculo de uma esperan¸ca condicional. Considerando V uma vari´avel aleat´oria discreta e U uma vari´avel aleat´oria qualquer, a esperan¸ca de V dadoU ´e dada por
E[V|U] = j
vjp(vj|u). (3.5)
Agora, fazendo V =ℓ(ψ,Di(j)) e U = (Dobs,i,ψ(k)) tem-se
Qi(ψ|ψ(k)) =E[V|U] = j
vjp(vj|u) = J
j=1
ℓ(ψ,Di(j))w(k)ij .
Assim, para o modelo com fra¸c˜ao de cura, e considerando o logar´ıtmo da fun¸c˜ao de verossimilhan¸ca em (3.2), o passoE para a i-´esima observa¸c˜ao assume a forma
Qi(ψ|ψ(k)) = J
j=1
w(k)ij δi
ln [f(yi|λ)] +x(j
′) i β − J j=1
w(k)ij exp(x (j′)
i β) [1−S(yi|λ)] +
J
j=1
wij(k)ln
p(x(j)i |α)
= Q1i(β,λ|ψ(k)) +Q2i(α|ψ(k)) (3.6) sendo,Q1i(β,λ|ψ(k)) =
J
j=1
w(k)ij δi
ln [f(yi|λ)] +x(j
′)
i β
−exp(x(ji ′)β) [1−S(yi|λ)]
e Q2i(α|ψ(k)) = J
j=1
w(k)ij ln
p(x(j)i |α)
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 25
Note que J
j=1
w(k)ij = 1, para todo k e i, e que se todas as covari´aveis para o
i-´esimo indiv´ıduo s˜ao observadas, ent˜ao wij(k) = 1. A express˜ao (3.6) pode ser escrita como a soma entre Q1i(β,λ|ψ(k)) e Q2i(α|ψ(k)), sendo que a primeira n˜ao envolve o parˆametro α e a segunda n˜ao envolve os parˆametros β e λ. Assim, na etapa de maximiza¸c˜ao (passo M) podemos maximiz´a-las separadamente com respeito a (β,λ) e α, respectivamente.
O passo E para todas as observa¸c˜oes ´e portanto dado por
Q(ψ|ψ(k)) = n
i=1
Q1i(β,λ|ψ(k)) + n
i=1
Q2i(α|ψ(k))
= Q1(β,λ|ψ(k)) +Q2(α|ψ(k)). (3.7) O passo M consiste na maximiza¸c˜ao de (3.7) com respeito a ψ, que pode ser feita atrav´es de um m´etodo iterativo, como Newton-Raphson. A fun¸c˜ao Q(ψ|ψ(k)) ´e atualizada usando a estimativa atual ψ(k+1), e o algoritmo ´e repetido at´e que seja satisfeito um crit´erio de parada estabelecido. Adotamos aqui, como crit´erio a condi¸c˜ao
ψ(k+1)−ψ(k) < ε
com ψ(k) = (β′(k),λ′(k),α′(k)
)′ e ε > 0 em que ||a−b|| denota a distˆancia Euclidiana
entre os pontos a eb.
Para ilustrar a implementa¸c˜ao do algoritmoEM ponderado, adaptamos um exem-plo dado em Horton & Laird (1999). Considere um conjunto de dados hipot´etico com duas covari´aveis dicotˆomicas (x1, x2), a resposta (y) e a vari´avel incadora de falha (δ). A Tabela 3.1 mostra os dados com algumas observa¸c˜oes omissas e a Tabela 3.2 exibe os correspondentes dados aumentados, em que wij(k) s˜ao os pesos estimados para o indiv´ıduo i na k-´esima itera¸c˜ao. Por exemplo, w31(k) = P(x2 = 0|x1 = δ = 1, y =
y3,ψ(k)) e w(k)31 +w (k) 32 = 1.
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 26
Tabela 3.1: Conjunto de dados original (hipot´etico).
i y δ x1 x2
1 y1 0 0 0 2 y2 0 0 1 3 y3 1 1 -4 y4 1 0 1 5 y5 0 -
-Tabela 3.2: Conjunto de dados aumentados.
i y δ x1 x2 w(k)
1 y1 0 0 0 1 2 y2 0 0 1 1 3 y3 1 1 0 w(k)31 3 y3 1 1 1 w(k)32 4 y4 1 0 1 1 5 y5 0 0 0 w(k)51 5 y5 0 0 1 w(k)52 5 y5 0 1 0 w(k)53 5 y5 0 1 1 w(k)54
que ´e baseado no vetor gradiente (matriz de primeiras derivadas parciais) e na matriz Hessiana (matriz de segundas derivadas) de Q(ψ|ψ(k)).
Sejam o vetor gradiente e a matriz Hessiana deQi(ψ|ψ(k)), respectivamente dados por
˙
Qi( ˆψ) = ∂Qi(ψ∂β|ψ(k))′ ∂Qi(ψ∂λ|ψ(k))′ ∂Qi(∂ψα|ψ(k))′
′
,
¨
Qi( ˆψ) =
⎡
⎢ ⎢ ⎢ ⎣
∂2Qi(ψ|ψ(k))
∂β∂β′
∂2Qi(ψ|ψ(k))
∂β∂λ
∂2Qi(ψ|ψ(k))
∂β∂α
∂2Qi(ψ|ψ(k))
∂λ∂λ′
∂2Qi(ψ|ψ(k))
∂λ∂α
∂2Qi(ψ|ψ(k))
∂α∂α′ ⎤
⎥ ⎥ ⎥ ⎦
,
de acordo com Louis (1982), a matriz de informa¸c˜ao observada ´e dada por
ILouis( ˆψ) = n
i=1
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 27
Se as covari´aveis omissas s˜ao categ´oricas tem-se que
Eℓ˙( ˆψ,Di) ˙ℓ( ˆψ,Di)′ = J
j=1
w(k)ij ℓ˙( ˆψ,D(j)i ) ˙ℓ( ˆψ,Di(j))′,
assim, a equa¸c˜ao (3.8) assume a forma
ILouis( ˆψ) = n
i=1
−Q¨i( ˆψ) + J
j=1
wij(k)ℓ˙( ˆψ,D (j)
i ) ˙ℓ( ˆψ,D (j)
i )′−Q˙i( ˆψ) ˙Qi( ˆψ)′
. (3.9)
Deste modo, a variˆancia asssint´otica de ˆψ ´e dada por
V ar( ˆψ) =ILouis( ˆψ)−1
ent˜ao, pode-se realizar inferˆencias sobre o vetor de parˆametros β.
3.1.2
Modelando a distribui¸
c˜
ao das covari´
aveis
3.1 Estima¸c˜ao de m´axima verossimilhan¸ca via algoritmo EM 28
condicionais unidimensionais da seguinte forma
p(xi1, ..., xip|α) = p(xip|xi1, ..., xi(p−1),αp)...p(xi2|xi1,α2)p(xi1|α1) (3.10) em que αj ´e um vetor de parˆametros para a j-´esima distribui¸c˜ao condicional, α = (α′1,α′2, . . . ,α′p)′. ´E importante ressaltar que a equa¸c˜ao (3.10) precisa ser especificada
apenas para as covari´aveis omissas.
Se as covari´aveis omissas s˜ao todas categ´oricas dicotˆomicas, uma sequˆencia de modelos log´ısticos (ou liga¸c˜oes probito e complemento log-log) podem ser modelados para cadap(xij|xi1, ..., xi(j−1),αj),j = 1, . . . , p. Para covari´aveis categ´oricas com mais de dois n´ıveis, podemos considerar um modelo log´ıstico multinomial (Agresti 2002). Se as covari´aveis consistem de contagem, ´e poss´ıvel modelarp(xij|xi1, ..., xi(j−1),αj) como um modelo de regress˜ao Poisson.
Cap´ıtulo 4
Estudo de Simula¸
c˜
ao
Neste cap´ıtulo apresentamos estudos de simula¸c˜ao para comparar propriedades do estimador de m´axima verossimilhan¸ca sob o modelo de fra¸c˜ao de cura e omiss˜ao nas covari´aveis pela an´alise de casos completos e pela imputa¸c˜ao dos dados faltantes com o algoritmoEM. Para este estudo, utilizamos o ambiente R (vers˜ao 2.7.2).
Como a metodologia mais comumente empregada na pr´atica ´e a an´alise de casos completos, nosso principal objetivo aqui ´e comparar as estimativas obtidas por este m´etodo com as estimativas de m´axima verossimilhan¸ca obtidas atrav´es do algoritmo EM. Investigamos tamb´em as propriedades assint´oticas das estimativas de m´axima ve-rossimilhan¸ca para o modelo com fra¸c˜ao de cura quando as amostras s˜ao completamente observadas.
4.1
Obten¸
c˜
ao dos dados simulados
Consideramos uma situa¸c˜ao com trˆes covari´aveis associadas a cada indiv´ıduo (x1, x2, x3). Para i = 1, . . . , n, assumimos para cada i que (xi1, xi2) s˜ao sempre obser-vadas, sendo xi1 e xi2 independentes, com valores xi1 obtidos por amostragem i.i.d. da distribui¸c˜ao normal padr˜ao e xi2 obtidos por amostragem i.i.d. da distribui¸c˜ao de Bernoulli com probabilidade de sucesso 0,6 e que xi3 pode ser omissa. Consideramos que, dado xi1 e xi2, a covari´avel com omiss˜ao xi3 tem distribui¸c˜ao de Bernoulli com
4.1 Obten¸c˜ao dos dados simulados 30
parˆametroαi, ent˜ao
p(xi3|xi1, xi2, αi) =αixi3(1−αi) 1−xi3
com xi1 ∈R, xi2 = 0,1 e xi3 = 0,1 sendo
αi =
exp(α1xi1+α2xi2) 1 + exp(α1xi1+α2xi2)
,
com α = (α1, α2) = (−0,5; 1) e as distribui¸c˜oes condicionais s˜ao independentes para cada i.
Para cada indiv´ıduo foram gerados valores para Mi como uma amostra i.i.d. da distribui¸c˜ao de Poisson com m´edia θi = exp(x′iβ), representando o n´umero de riscos para a ocorrˆencia do evento, com β = (β1, β2, β3). O valor fixado para o vetor β determina o percentual de indiv´ıduos com mi = 0, ou seja, o percentual de imunes na amostra.
Para cada indiv´ıduo n˜ao imune, (mi > 0), foram geradas amostras de tamanho
mi para Zij ∼W eibull(ρ, γ), com ρ= 2 eγ =−2 log 4. Assim, os tempos de falha s˜ao
ti = min{zij;j = 1, . . . , mi}.
Geramos tamb´em censuras aleat´orias a partir de uma distribui¸c˜ao uniforme no intervalo (0, u), sendo que a mudan¸ca no valor de u afeta a propor¸c˜ao de censuras na amostra. Consideramos aqui a propor¸c˜ao de censuras calculada com respeito ao total de indiv´ıduos sujeitos ao evento, com o intuito de avaliar separadamente o efeito do aumento da propor¸c˜ao de censuras entre n˜ao curados e de imunes na estima¸c˜ao dos parˆametros. Assim, considerando os eventos: A ≡ curados; ¯A ≡ n˜ao curados e
B ≡ censurados ou imunes. A propor¸c˜ao de censura entre n˜ao imunes utilizada nesta simula¸c˜ao (denotada pc1) representa a frequˆencia relativa de B dado ¯A, ou seja,
pc1 =
n´umero de indiv´ıduos em B∩A¯
n´umero de indiv´ıduos em ¯A ,
4.1 Obten¸c˜ao dos dados simulados 31
´e interpretado simplesmente como a propor¸c˜ao de censuras, pode ser representado por
pc2 =
n´umero de indiv´ıduos em B
n´umero de indiv´ıduos na popula¸c˜ao.
Denotando por π a propor¸c˜ao de imunes, pode-se verificar, pelo uso de pro-priedades de frequencia relativa, a seguinte rela¸c˜ao entre estas duas quantidades:
pc2 =pc1(1−π) +π. (4.1)
Os tempos observados ser˜ao yi = min{ti, ci} e, associado a cada tempo, tem-se
δi = 1 seti ≤ci e δi = 0 seti > ci.
Os dados omissos para xi3 foram gerados com um mecanismo de omiss˜ao que n˜ao depende dexi3, e portanto, os dados s˜ao MAR, sendo que mecanismo de omiss˜ao dos dados pode ser ignorado na estima¸c˜ao dos parˆametros. Para simular omiss˜ao, adaptamos a id´eia de Ibrahim, Chen, & Lipsitz (1999). A vari´avel indicadora de omiss˜ao foi especificada como descrito na Se¸c˜ao 1.3.1, sendori3 = 0 se a vari´avelxi3´e observada eri3 = 1 se xi3 ´e omissa, i= 1, . . . , n. A distribui¸c˜ao assumida para ri3 ´e dada por
P(Ri3 =r|Dobs, τ) =τir(1−τi) 1−r,
com
τi =
exp(τ30+τ31xi1+τ32xi2+τ33yi+τ34δi) 1 + exp(τ30+τ31xi1+τ32xi2+τ33yi+τ34δi)
e o valor considerado para o vetor τ3 = (τ30, τ31, τ32, τ33, τ34)′ controla o percentual de omiss˜ao na amostra.
4.2 Resultados para os dados simulados 32
4.2
Resultados para os dados simulados
Nesta se¸c˜ao apresentamos os resultados obtidos para amostras simuladas em diferentes situa¸c˜oes. A Tabela 4.1 resume os casos considerados nas simula¸c˜oes:
Tabela 4.1: Situa¸c˜oes consideradas para simula¸c˜ao.
Caso Omiss˜ao % Imunes % Censura Tamanho da Amostra Se¸c˜ao 1
sem variando 0 variando 4.2.1
2 variando variando fixo (n= 300)
3
com variando 0 fixo (n= 300) 4.2.2
4 fixo (45%) variando fixo (n= 300)
4.2.1
Resultados para amostras completamente observadas
A partir da Tabela 4.2 observamos que, para amostras moderadas (n = 50) n˜ao apresentando omiss˜ao nas covari´aveis nem censuras entre os n˜ao imunes (caso 1), as estimativas dos parˆametros apresentam vieses, especialmente no parˆametro γ, para diferentes propor¸c˜oes de imunes (10%, 45% e 65%), no entanto, aumentando-se o tamanho da amostra este problema ´e aparentemente sanado.
Na Tabela 4.3, que mostra os resultados para amostras em que as covari´aveis n˜ao apresentam omiss˜ao mas apresentam censura entre os n˜ao imunes (caso 2), podemos ver que o percentual de censuras na amostra, afeta sensivelmente as estimativas dos parˆametros. Observamos vieses e erros quadr´aticos m´edios acentuados nas estimativas dos parˆametros quando o percentual de censuras ´e alto (50%). Por exemplo, na Tabela 4.2 para 65% de imunes (que, na pr´atica, aparecem no conjunto de dados como ob-serva¸c˜oes censuradas) todos os parˆametros s˜ao bem estimados. No entanto, a Tabela 4.3 mostra que, em uma situa¸c˜ao similar, quando o percentual de imunes ´e de 45% e o percentual de censuras entre os n˜ao imunes ´e de 30%, o que resulta em um percentual de censuras entre imunes e n˜ao imunes de aproximadamente 62%1, as estimativas para os parˆametros β2 eγ apresentam vi´es acentuado.
1
Com base na rela¸c˜ao (4.1), tem-se na Tabela 4.3 que com pc1 = 0,3 e π = 0,45 obtem-se
4.2 Resultados para os dados simulados 33
Tabela 4.2: Estimativas (m´edia), erros-padr˜ao (EP) e raiz dos erros quadr´aticos m´edios (REQM) dos parˆametros em 1500 r´eplicas considerando amostras sem omiss˜ao e sem censura entre os n˜ao imunes, variando o tamanho da amostra e o percentual de imunes.
10% de imunes
Parˆametro n= 50 n= 150 n= 300
m´edia EP REQM m´edia EP REQM m´edia EP REQM
β1= 2.0 2.154 0.3202 0.3552 2.050 0.1635 0.1709 2.021 0.1119 0.1139
β2= 3.0 3.219 0.5261 0.5697 3.064 0.2768 0.2840 3.033 0.1774 0.1804
β3= 2.0 2.145 0.4352 0.4589 2.046 0.2230 0.2276 2.019 0.1531 0.1543
ρ= 2.0 2.149 0.2535 0.2915 2.041 0.1311 0.1374 2.019 0.0905 0.0924
γ=−2.8 -2.962 0.5232 0.5565 -2.830 0.2735 0.2795 -2.799 0.1846 0.1865 45% de imunes
β1= 1.5 1.634 0.3444 0.3691 1.547 0.1698 0.1763 1.519 0.1185 0.1200
β2=−1.5 -1.608 0.4807 0.4927 -1.534 0.2710 0.2731 -1.514 0.1813 0.1818
β3= 1.0 1.095 0.4210 0.4315 1.031 0.2224 0.2247 1.012 0.1570 0.1575
ρ= 2.0 2.161 0.3453 0.3812 2.048 0.1783 0.1847 2.019 0.1221 0.1235
γ=−2.8 -3.001 0.5395 0.5887 -2.854 0.2856 0.2970 -2.804 0.2004 0.2029 65% de imunes
β1=−0.5 -0.511 0.3261 0.3263 -0.503 0.1719 0.1719 -0.497 0.1426 0.1426
β2=−1.5 -1.605 0.6953 0.7033 -1.516 0.4078 0.4081 -1.490 0.3467 0.3470
β3=−0.2 -0.201 0.5495 0.5495 -0.220 0.3003 0.3009 -0.213 0.2590 0.2594
ρ= 2.0 2.189 0.5322 0.5648 2.047 0.2911 0.2948 2.022 0.2595 0.2604
γ=−2.8 -3.054 0.8098 0.8574 -2.851 0.4355 0.4426 -2.813 0.3993 0.4014
Tabela 4.3: Estimativas (m´edia), erros-padr˜ao (EP) e raiz dos erros quadr´aticos m´edios (REQM) dos parˆametros em 1500 r´eplicas, amostras de tamanhon= 300 sem omiss˜ao nas covari´aveis, variando o percentual de censura entre os n˜ao imunes e de imunes.
10% de imunes
Parˆametro 10% de censura 30% de censura 50% de censura
m´edia EP REQM m´edia EP REQM m´edia EP REQM
β1= 2.0 2.023 0.1203 0.1224 2.027 0.1311 0.1339 2.127 0.1660 0.2092
β2= 3.0 2.979 0.1937 0.1948 2.935 0.2364 0.2453 3.363 0.3584 0.5099
β3= 2.0 1.948 0.1667 0.1746 1.840 0.1895 0.2481 2.097 0.2656 0.2826
ρ= 2.0 2.028 0.0956 0.0996 2.024 0.1083 0.1108 1.944 0.1351 0.1463
γ=−2.8 -2.690 0.2065 0.2222 -2.573 0.2587 0.3269 -3.357 0.4063 0.7119 45% de imunes
β1= 1.5 1.529 0.1184 0.1219 1.505 0.1370 0.1371 1.686 0.1816 0.2598
β2=−1.5 -1.587 0.1847 0.2041 -1.765 0.1967 0.3302 -1.779 0.2626 0.3830
β3= 1.0 0.939 0.1583 0.1697 0.727 0.1687 0.3211 1.025 0.3082 0.3092
ρ= 2.0 2.040 0.1258 0.1320 2.167 0.1516 0.2258 1.815 0.2168 0.2852
γ=−2.8 -2.729 0.1984 0.2032 -2.502 0.2238 0.3510 -2.914 0.3898 0.4144 65% de imunes
β1=−0.5 -0.523 0.1088 0.1111 -0.531 0.1235 0.1274 -0.557 0.1353 0.1468
β2=−1.5 -1.600 0.2221 0.2434 -1.722 0.2391 0.3264 -1.973 0.2892 0.5545
β3=−0.2 -0.303 0.1721 0.2006 -0.446 0.1925 0.3122 -0.749 0.2063 0.5868
ρ= 2.0 2.024 0.1587 0.1606 2.061 0.1842 0.1941 2.240 0.2563 0.3512
4.2 Resultados para os dados simulados 34
4.2.2
Efeito das omiss˜
oes nas estimativas dos parˆ
ametros
Analisando a Tabela 4.4, que mostra os resultados para o caso 3, observa-se que as estimativas dos parˆametros obtidas atrav´es do algoritmo EM, em geral, apresentam com desempenho, mesmo quando o percentual de omiss˜ao ´e alto. O mesmo n˜ao ´e observado para as estimativas obtidas com a an´alise de casos completos (ACC), que apresentam vicios crescentes de acordo o percentual de omiss˜ao. Observa-se tamb´em que as estimativas obtidas com ACC s˜ao ainda piores quando o percentual de imunes ´e m´edio ou alto (45% e 60%).
A Tabela 4.5 mostra que, na presen¸ca de censura para n˜ao imunes (caso 4), o algoritmo EM, em geral, n˜ao apresenta bom desempenho quanto `a estimativa dos parˆametros. No entanto, as estimativas referentes `a an´alise de casos completos apre-sentam resultados muito piores e grandes vieses para todos os parˆametros envolvidos no modelo, mesmo quando os percentuais de omiss˜ao e de censura s˜ao baixos.
Mesmo para o caso sem omiss˜ao, foram obtidos resultados insatisfat´orios quanto `a estimativa dos parˆametros na presen¸ca de censura entre os n˜ao imunes. Portanto, os vieses encontrados nas estimativas obtidas atrav´es do algoritmo EM na Tabela 4.5 podem ser devido `a presen¸ca de censuras e n˜ao a dados omissos.
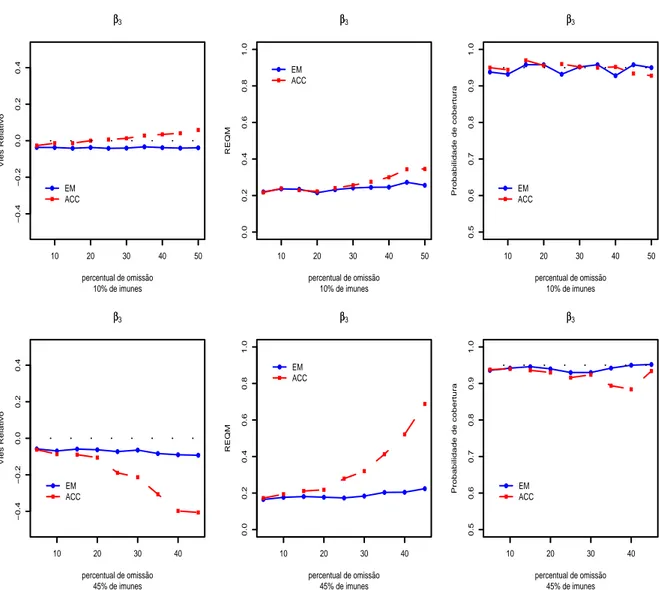
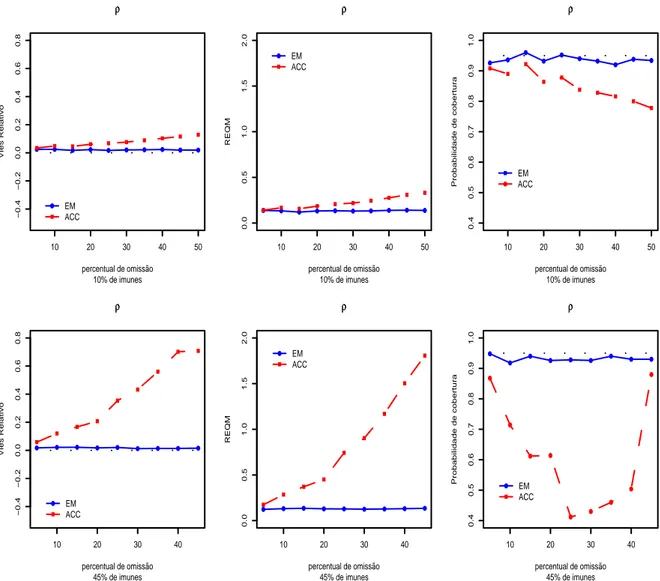
Para visualizar o efeito das omiss˜oes nas estimativas dos parˆametros, na ra´ız quadrada dos erros quadr´aticos m´edios e nas probabilidades de cobertura2 a um n´ıvel nominal de 95%, variamos o percentual de dados omissos entre 5 e 50%. Os resultados s˜ao mostrados nas Figuras (4.1), (4.2), (4.3), (4.4) e (4.5). Podemos ver que, para os parˆametros β1, ρ e γ, o uso do algoritmo EM resulta em vieses relativos3 bem pr´oximos de zero, erros quadr´aticos m´edios constantes em fun¸c˜ao do percentual de omiss˜ao e probabilidades de cobertura pr´oximas ao valor nominal de 95%, enquanto o m´etodo ACC fornece vieses e erros quadr´aticos m´edios crescentes em fun¸c˜ao do percentual de omiss˜ao e probabilidades de cobertura insatisfat´orias, principalmente
2
Probabilidade de cobertura: Percentual de intervalos de confian¸ca que cont´em o verdadeiro valor do parˆametro.
3
4.2 Resultados para os dados simulados 35
Tabela 4.4: Estimativas (m´edia), erros-padr˜ao (EP) e raiz dos erros quadr´aticos m´edios (REQM) dos parˆametros em 1500 r´eplicas, amostras de tamanho n= 300 sem censura entre n˜ao imunes, variando o percentual de omiss˜ao e de imunes.
10% de imunes
Parˆametro M´etodo 15 % de omiss˜ao 30% de omiss˜ao 50% de omiss˜ao
m´edia EP REQM m´edia EP REQM m´edia EP REQM
β1= 2.0 EM 2.020 0.1164 0.1180 2.030 0.1280 0.1314 2.026 0.1416 0.1440
ACC 2.169 0.1269 0.2112 2.018 0.1590 0.1599 1.969 0.2082 0.2105
β2= 3.0 EM 3.033 0.1839 0.1869 3.037 0.2051 0.2083 3.027 0.2081 0.2099
ACC 3.108 0.1970 0.2244 3.134 0.2468 0.2807 3.179 0.2940 0.3440
β3= 2.0 EM 2.020 0.1624 0.1636 2.029 0.1715 0.1739 2.038 0.1868 0.1907
ACC 2.079 0.1689 0.1864 2.068 0.1956 0.2070 2.060 0.2404 0.2477
ρ= 2.0 EM 2.018 0.0932 0.0949 2.027 0.0964 0.0999 2.024 0.1009 0.1037 ACC 2.082 0.1024 0.1311 2.104 0.1181 0.1575 2.173 0.1520 0.2305
γ=−2.8 EM -2.800 0.1948 0.1967 -2.809 0.2082 0.2115 -2.808 0.2150 0.2179 ACC -2.979 0.2048 0.2907 -3.004 0.2365 0.3309 -3.191 0.2796 0.5028
α1=−0.5 EM -0.509 0.1406 0.1409 0.508 0.1676 0.1678 -0.506 0.1890 0.1891
ACC - - -
-α2= 1.0 EM 1.015 0.1856 0.1862 1.030 0.2092 0.2113 1.019 0.2444 0.2452
ACC - - -
-45% de imunes
β1= 1.5 EM 1.524 0.1185 0.1210 1.526 0.1206 0.1232 1.521 0.1320 0.1337
ACC 1.535 0.1399 0.1441 1.288 0.1864 0.2820 0.977 0.4977 0.7222
β2=−1.5 EM -1.531 0.1788 0.1815 -1.524 0.1924 0.1939 -1.535 0.2300 0.2327
ACC -1.635 0.1985 0.2398 -1.707 0.2567 0.3301 -2.060 1.1000 1.2344
β3= 1.0 EM
1.024 0.1575 0.1593 1.016 0.1749 0.1756 1.143 1.3709 1.3783 ACC 1.010 0.16941 0.1697 0.855 0.2263 0.2687 0.873 1.5335 1.5387
ρ= 2.0 EM 2.031 0.1150 0.1191 2.029 0.1216 0.1250 2.020 0.1463 0.1476 ACC 2.104 0.1355 0.1708 2.810 0.2671 0.8529 2.542 1.8625 1.9398
γ=−2.8 EM -2.821 0.1896 0.1957 -2.810 0.1978 0.2014 -2.923 1.3629 1.3713 ACC -2.998 0.2216 0.3164 -4.355 0.4059 1.6332 -6.579 2.6387 4.6316
α1=−0.5 EM -0.510 0.1518 0.1521 -0.517 0.1882 0.1890 -0.514 0.2316 0.2321
ACC - - -
-α2= 1.0 EM 1.003 0.1781 0.1781 1.014 0.1988 0.1992 1.022 0.2437 0.2447
ACC - - -
-65% de imunes
β1=−0.5 EM
-0.506 0.1075 0.1077 -0.511 0.1099 0.1105 -0.513 0.1146 0.1153 ACC -0.881 0.1617 0.4139 -1.128 0.2727 0.6843 -0.118 0.5238 0.6486
β2=−1.5 EM
-1.526 0.2160 0.2175 -1.526 0.2187 0.2202 -1.525 0.2365 0.2378 ACC -1.827 0.2956 0.4411 -2.064 0.5273 0.7717 -2.247 1.2015 1.4150
β3=−0.2 EM -0.190 0.1892 0.1895 -0.198 0.2000 0.2000 -0.233 0.7143 0.7150
ACC -0.621 0.2586 0.4942 -0.858 0.6418 0.9185 -1.013 1.0366 1.3173
ρ= 2.0 EM 2.027 0.1542 0.1566 2.035 0.1571 0.1609 2.035 0.1504 0.1543 ACC 2.657 0.3441 0.7412 2.621 1.1807 1.3339 1.909 0.9150 0.9195
γ=−2.8 EM -2.809 0.2511 0.2537 -2.826 0.2531 0.2587 -2.818 0.2497 0.2538 ACC -4.243 0.5275 1.5620 -5.446 1.1924 2.9274 -3.715 0.9534 1.3402
α1=−0.5 EM
-0.509 0.1473 0.1476 -0.505 0.1596 0.1596 -0.514 0.2156 0.2160
ACC - - -
-α2= 1.0 EM
1.006 0.1887 0.1888 1.021 0.1922 0.1933 1.010 0.2711 0.2713
-4.2 Resultados para os dados simulados 36
Tabela 4.5: Estimativas (m´edia), erros-padr˜ao (EP) e raiz dos erros quadr´aticos m´edios (REQM) dos parˆametros em 1500 r´eplicas, amostras de tamanho n = 300 sem censura entre os n˜ao imunes, com 45% de imunes e variando o percentual de censura e de omiss˜ao.
10% de censura
Parˆametro M´etodo 15 % de omiss˜ao 30% de omiss˜ao 50% de omiss˜ao
m´edia EP REQM m´edia EP REQM m´edia EP REQM
β1= 1.5 EM
1.516 0.1144 0.1155 1.511 0.1181 0.1186 1.512 0.1176 0.1182 ACC 1.669 0.1443 0.2219 1.817 0.1737 0.3613 1.778 0.2033 0.3441
β2=−1.5 EM
-1.586 0.2106 0.2274 -1.580 0.2068 0.2217 -1.579 0.2196 0.2333 ACC -1.740 0.2417 0.3408 -1.920 0.2771 0.5033 -1.997 0.3236 0.5927
β3= 1.0 EM 0.897 0.1501 0.1820 0.894 0.1541 0.1873 0.891 0.1711 0.2031
ACC 0.859 0.1702 0.2212 0.685 0.1959 0.3706 0.647 0.2287 0.4205
ρ= 2.0 EM 2.045 0.1182 0.1266 2.042 0.1227 0.1298 2.044 0.1155 0.1235 ACC 2.316 0.1596 0.3538 2.193 0.1779 0.2627 2.148 0.2049 0.2529
γ=−2.8 EM -2.708 0.1902 0.2008 -2.704 0.1948 0.2064 -2.703 0.1977 0.2096 ACC -3.282 0.2460 0.6245 -3.224 0.2942 0.5391 -3.060 0.3489 0.4520
α1=−0.5 EM
-0.511 0.1509 0.1514 -0.497 0.1479 0.1479 -0.499 0.1772 0.1772
ACC - - -
-α2= 1.0 EM
1.007 0.2408 0.2409 0.984 0.2478 0.2484 0.978 0.2845 0.2854
ACC - - -
-30% de censura
β1= 1.5 EM 1.503 0.1314 0.1314 1.491 0.1330 0.1333 1.456 0.1030 0.1121
ACC 1.672 0.1533 0.2305 1.927 0.2370 0.4881 2.364 0.5565 1.0278
β2=−1.5 EM -1.737 0.2081 0.3150 -1.698 0.2204 0.2962 -1.604 0.1832 0.2106
ACC -1.895 0.2334 0.4584 -2.320 0.3270 0.8823 -2.779 0.8282 1.5237
β3= 1.0 EM 0.735 0.1773 0.3186 0.693 0.2049 0.3692 0.582 0.1899 0.4594
ACC 0.726 0.1905 0.3341 0.555 0.2741 0.5231 0.499 0.9670 1.0891
ρ= 2.0 EM 2.140 0.1474 0.2029 2.130 0.1483 0.1974 2.092 0.1111 0.1442 ACC 2.390 0.1864 0.4326 2.573 0.2955 0.6448 2.723 1.4720 1.6400
γ=−2.8 EM -2.519 0.2198 0.3354 -2.491 0.2241 0.3596 -2.419 0.1687 0.3921 ACC -2.997 0.2624 0.3449 -3.547 0.4467 0.8937 -5.589 1.2442 3.0785
α1=−0.5 EM -0.510 0.1438 0.1442 -0.523 0.1651 0.1666 -0.581 0.1624 0.1813
ACC - - -
-α2= 1.0 EM 0.972 0.1790 0.1812 0.906 0.1980 0.2192 0.792 0.1778 0.2736
-4.2 Resultados para os dados simulados 37
para os parˆametros β1 eρ.
O parˆametro β2 ´e bem estimado pelo algoritmo EM para amostras com pe-queno percentual de imunes (10%), mas quando o percentual de imunes ´e maior (45%), observa-se um pequeno vi´es que permanece constante em fun¸c˜ao do percentual de omis-s˜ao. Quando o m´etodo utilizado ´e a ACC, observa-se que as estimativas, bem como probabilidade de cobertura pioram com o aumento do percentual de omiss˜ao.
Curiosamente, os resultados obtidos com os dois m´etodos para o parˆametro β3, que ´e o coeficiente associado `a covari´avel omissa, s˜ao equivalentes para o caso em que h´a 10% de imunes na amostra. No entanto, apesar do vi´es relativo para a estimativa ACC estar sempre mais pr´oximo de zero, do que as estimativasEM, pode-se notar que esta quantidade apresenta uma tendˆencia crescente com o aumento do percentual de omiss˜ao. Al´em disso, os vieses observados com a ACC ´e negativo quando o percentual de omiss˜ao ´e de no m´aximo 15% e positivo para percentuais de omiss˜ao maior do que 15%, enquanto o algoritmo EM apresenta vieses sempre negativos. Quando o percentual de imunes ´e de 45%, as estimativas EM apresentam vi´es acentuado, por´em constante, enquanto as estimativas ACC apresentam vieses muito maiores e crescentes segundo o percentual de omiss˜ao.
4.2 Resultados para os dados simulados 38
● ● ● ● ● ● ● ● ● ●
10 20 30 40 50
−0.4 −0.2 0.0 0.2 0.4 ββ1
10% de imunes percentual de omissão
Viés Relativo
● EM
ACC ● ●
● ● ● ● ● ● ● ●
10 20 30 40 50
0.0 0.2 0.4 0.6 0.8 1.0 ββ1
10% de imunes percentual de omissão
REQM ● EM ACC ● ● ● ● ● ● ● ● ● ●
10 20 30 40 50
0.5 0.6 0.7 0.8 0.9 1.0 ββ1
10% de imunes percentual de omissão
Probabilidade de cobertura ● EM
ACC
● ● ● ● ● ● ● ● ●
10 20 30 40
−0.4 −0.2 0.0 0.2 0.4 ββ1
45% de imunes percentual de omissão
Viés Relativo
● EM
ACC
● ● ● ● ● ● ● ● ●
10 20 30 40
0.0 0.2 0.4 0.6 0.8 1.0 ββ1
45% de imunes percentual de omissão
REQM ● EM ACC ● ● ● ● ● ● ● ● ●
10 20 30 40
0.5 0.6 0.7 0.8 0.9 1.0 ββ1
45% de imunes percentual de omissão
Probabilidade de cobertura ● EM
ACC
4.2 Resultados para os dados simulados 39
● ● ● ● ● ● ● ● ● ●
10 20 30 40 50
−0.4 −0.2 0.0 0.2 0.4 ββ2
10% de imunes percentual de omissão
Viés Relativo ● EM ACC ● ● ● ● ● ● ● ● ● ●
10 20 30 40 50
0.0 0.2 0.4 0.6 0.8 1.0 ββ2
10% de imunes percentual de omissão
REQM
● EM ACC
10 20 30 40 50
0.5 0.6 0.7 0.8 0.9 1.0 ββ2
10% de imunes percentual de omissão
Probabilidade de cobertura
● ● ● ● ● ● ● ● ● ● ● EM ACC ● ● ● ● ● ● ● ● ●
10 20 30 40
−0.4 −0.2 0.0 0.2 0.4 ββ2
45% de imunes percentual de omissão
Viés Relativo
● EM
ACC ● ●
●
● ● ● ● ● ●
10 20 30 40
0.0 0.2 0.4 0.6 0.8 1.0 ββ2
45% de imunes percentual de omissão
REQM
● EM
ACC
10 20 30 40
0.5 0.6 0.7 0.8 0.9 1.0 ββ2
45% de imunes percentual de omissão
Probabilidade de cobertura
●
● ● ●
● ● ● ● ●
● EM
ACC