Available Online at www.ijecse.org ISSN: 2277-1956
Enhancing Text Clustering Using Concept-based
Mining Model
Lincy Liptha R.1, Raja K.2 , G.Tholkappia Arasu3
1 PG Scholar,Department of CSE, Adhiyamaan College of Engineering, Hosur, TamilNadu, India.
2Professor, Department of CSE,Adhiyamaan College of Engineering, Hosur, TamilNadu, India.
2 Principal, Jayam college of Engineering and Technology, Dharmapuri, TamilNadu, India.
Abstract-
Text Mining techniques are mostly based on statistical analysis of a word or phrase. The statistical analysis of a term frequency captures the importance of the term without a document only. But two terms can have the same frequency in the same document. But the meaning that one term contributes might be more appropriate than the meaning contributed by the other term. Hence, the terms that capture the semantics of the text should be given more importance. Here, a new concept-based mining is introduced. It analyses the terms based on the sentence, document and corpus level. The model consists of sentence-based concept analysis which calculates the conceptual term frequency (ctf), document-based concept analysis which finds the term frequency (tf), corpus-based concept analysis which determines the document frequency (df) and concept-based similarity measure. The process of calculating ctf, tf, df, measures in a corpus is attained by the proposed algorithm which is called Concept-Based Analysis Algorithm. By doing so we cluster the web documents in an efficient way and the quality of the clusters achieved by this model significantly surpasses the traditional single-term-base approaches.
I. INRTODUCTION
Text Mining is a flourishing new field that attempts to draw meaningful information from language text. In other words it is the process of analyzing text that is useful for particular purposes [1].
Clustering is a traditional data mining technique that attempts to organize un-clustered text documents into groups or clusters of text document in such a way that the clusters exhibit high intracluster similarity and low intercluster similarity. In general, text clustering methods try to separate the documents into groups in which each group represents a topic that is different from the other groups [2].
Decision trees [3], clustering based on data summarization [4], rule-based systems[5], statistical analysis[6], neural nets [7] are some of the methods that are used for text clustering. The most important aspect in text mining is that the output of the clustering algorithm depends on the features that have been selected [8]. Furthermore, the result of the clustering algorithm is based on the weights of the selected features.
The Vector Space Model [9],[10] is widely used document clustering method and represents data for text classification and clustering. The terms in the document is represented as a feature vector. The terms can be words or phrases. Each feature vector is assigned a term weight based on the term frequency of the terms in the documents. Similarity measures that rely on the feature vector is used to find the similarity between the documents (Cosine measures and the Jaccard measure).
Generally in text mining techniques, we compute the term frequency of the terms in the document to find the importance of the term in the document. On the other hand, two terms can have the same term frequency in their documents, yet the meaning contributed by one term is more suitable to the meaning of the sentence than the meaning contributed by the other term.
Hence, in the proposed model, the semantic structure of each term is captured rather than the frequency of the term within the document only. In this model, the concepts are analyzed on the sentence, document and corpus level. A concept-based similarity is used to determine the similarity among the documents and is based on the outcomes of the concept analysis on the sentence, document and corpus levels.
document is introduced, the designed system scans the new document and extracts matching concepts between the document and all the previously processed documents.
The concept-based similarity measure used in the proposed system outperforms other similarity measures. The similarity between documents depends on the concept analysis on the sentence, document and the corpus levels. The quality of clusters produced is influenced by the similarity measure used as it is insensitive to noise while calculating the similarity. This is because the concepts are analysed in the sentence, document and corpus levels and hence the probability to find a concept match between unrelated documents is very small.
The important terms used in this paper are given below:
• Verb Argument structure: (e.g.: Adam plays the guitar). “hits” is the verb. “Adam” and “the guitar” are the
arguments of the verb “hits”.
• Label: An argument is assigned a label (e.g.: Adam plays the guitar). ”Adam” has subject label and “the guitar” has object label.
• Term: It is either an argument or a verb. It can also be a word or a phrase.
• Concept: The concept is a labelled term.
II. THEMATIC ROLES
The study of roles associated with verbs is referred to as case role analysis or thematic role analysis. Usually, the semantic structure of a sentence is characterized by using a form of verb argument structure. This verb argument structure allows a bond between the verb arguments of the input text and semantic roles associated with it. Moreover, this verb argument structure generates a meaning representation from the meaning of the concepts in the sentence.
Consider the example: Adam plays the guitar. The sentence has the semantic structure Noun Phrase plays Noun Phrase (NP). Some facts can be determined for the verb “plays”:
1. The verb plays has two arguments associated with it. 2. Both the arguments are Noun Phrases.
3. “Adam” is the first argument and is preverbal. It plays the role of a subject.
4. “the guitar” is the second argument and is post verbal. It plays the role of the direct object.
Fillmore [11] first suggested that thematic roles are categories which help characterize the verb arguments by providing a shallow semantic language.
In recent times, thematic roles in sentences have been tried to be labelled automatically. The first was proposed by Gildea and Jurafsky [12]. They applied a statistical learning technique to the FrameNet Database. The model presented a discriminative method for determining the probable role of the constituent given the predicator, frame and certain other features. These probabilities were trained on the FrameNet database. They depend on the verb, the voice of the verb, the grammatical functions and other such features. An addition to the work in [12] proposed a machine learning algorithm for shallow semantic parsing. It was based on Support Vector Machines (SVM). It resulted in improved performance than the classifier produced by Gildea and Jurafsky. Shallow semantic parsing is formulated as a multiclass classification problem. Support Vector Machines are used to identify the arguments of a given verb in a sentence and also to classify them by the semantic roles that they play like AGENT, THEME, and GOAL.
III. CONCEPT-BASED ANALYSIS ALGORITHM
The proposed concept-based mining algorithm is composed of the sentence-based concept analysis, document-based concept analysis, the corpus-based concept analysis and the concept-based similarity measure.
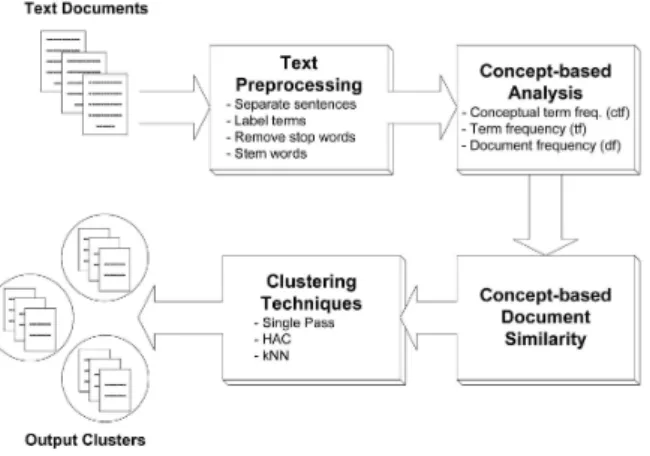
Figure 1.The concept based mining model
A raw document with well defined sentence boundaries is given as input to the proposed system. According to the PropBank notations [13], each of the sentence in the document is labelled automatically. The sentences in the document may have one or more labelled verb argument structures. The amount of information in the sentence influences the number of verb argument structures generated by the labeller. The output of the labeller and the labelled verb argument structures are captured and analyzed by the concept based analysis model on the sentence, document and corpus levels.
The word term is used to indicate both the verb and the argument. A term can have more than one semantic role in the same sentence. This implies that a single term can be an argument to more than one verb in the same sentence. Such terms are said to play more important roles that contribute to the meaning of the sentence. In concept-based mining model, the term concept is used to describe a labelled term. A term can be either a phrase or a word.
A. Sentence-Based Concept Analysis
In the sentence-based concept analysis, each concept at the sentence level is analyzed and a new measure called the conceptual term frequency (ctf) is used. The ctf of a concept c in a sentence s and document d is calculated as follows:
1) Calculating ctf of concept c in Sentence s
The number of occurrences on a concept c in the verb argument structures of the sentence s is called the ctf. Here, the ctf is a local measure on the sentence level. The concept c that appears in different verb argument structures of the same sentence has s, has the principal role of contributing to the meaning of s.
2) Calculating ctf of concept c in document d
A document d can have a concept c that can have many ctf values in different sentences. Hence, the ctf value of a concept c in a document d is calculated by:
(1)
where the total number of sentences in a document d that contain the concept c is denoted by sn. The importance of a concept c to a document d is measured by taking the average of the ctf values of the concept. If a concept is found to have ctf values in many sentences of a document, it is said to have a major contribution to the meaning of the sentences. Hence it leads to the discovery of the topic of the document.
Therefore, calculating the average of the ctf values measures the overall importance of the concept to the semantics of the sentence in the document.
B. Document-Based Concept Analysis
IN ORDER to analyze each concept at the document level, the concept based term frequency tf is calculated. The tf is calculated as the number of occurrences of a concept (word or phrase) c in the original document d. The tf is a local measure on the document level.
C. Corpus-Based Concept Analysis
The concept-based document frequency df, the number of documents containing concept c, is calculated to find the concepts that can differentiate between documents. The df is a global measure on the corpus level. This measure is used to reward the concepts that only appear in a small number of documents as these concepts can discriminate their documents among others.
The process of calculating ctf, tf , and df measures in a corpus is attained by the proposed algorithm which is called Concept-based Analysis Algorithm.
D. Concept-Based Analysis Algorithm
The concept-based analysis algorithm consists of the following steps: 1. ddoci is a new Document
2. L is an empty List
3. sdoci is a new sentence in ddoci 4. Build concepts list Cdoci from sdoci 5. for each concept ci ЄCi do 6. compute ctfiof ci in ddoci 7. compute tfiof ci in ddoci 8. compute dfi of ci in ddoci 9. dk is seen document, where
k={0,1,..., doc-1} 10. sk is a sentence in dk
11. Build concepts list Ck from sk 12. for each concept cjЄ Ck do 13. if (ci == cj) then
14. update dfi of ci
15. compute ctfweight = avg(ctfi, ctfj) 16. add new concept matches to L 17. end if
18. end for 19. end for
20. output the matched concepts list L
The proposed concept-based analysis algorithm describes the process of calculating the ctf, tf , and df of the matched concepts in the documents. The procedure begins with processing a new raw document (at line 1) which has well defined sentence boundaries. Each sentence is semantically labeled according to [13]. The lengths of the matched concepts and their verb argument structures are stored for the concept-based similarity calculations.
previous documents. The concept list L holds the entry for each of the previous documents that shares a concept with the current document.
After processing, L contains all the matching concepts between the current document and any previous document that shares at least one concept with the new document. Finally, L is output as the list of documents with the matching concepts and the necessary information about them. The concept-based analysis algorithm is capable of matching each concept in a new document d with all the previously processed documents in O(m) time, where m
is the number of concepts in d.
E. A Concept-Based Similarity Measure
The similarity measure used here is based on the matching concepts at the sentence, document and the corpus levels. The concept based similarity measure depends on three critical aspects:
1. The analyzed labelled terms are the concepts that capture the semantic structure of each sentence. 2. The frequency of a concept is used to measure the contribution of the concept to the meaning of the sentence, as well as to the main topics of the document.
3. The number of documents that contains the analyzed concepts is used to discriminate among documents in calculating the similarity.
The proposed concept-based similarity measure measures the importance of each concept at the sentence level by the ctf measure, document level by the tf measure, and corpus level by the df measure. The similarity between the documents is better evaluated by using the information from the concept based analysis algorithm. This similarity measure is a function of the following factors:
1. The number of matching concepts, m, in the verb argument structures in each document d, 2. The total number of sentences, sn, that contain
matching concept ci in each document d,
3. The total number of the labelled verb argument structures, v, in each sentence s,
4. The ctfiof each concept ci in s for each document d, where i=1,2, . . . ,m, as mentioned in Sections 3.1.1and 3.1.2,
5. The tfi of each concept ci in each document d, where i= 1,2, . . . ,m. 6. The dfiof each concept ci, where i =1,2,. . .,m.
7. The length, l, of each concept in the verb argument structure in each document d, 8. The length, Lv, of each verb argument structure which contains a matched concept, and 9. The total number of documents, N, in the corpus.
The matching between concepts can be exact or partial matching. Exact match means that the concepts have the same words. If one concept includes all the words in the other concept, it is said to exhibit a partial match.
To understand it better, consider the following concepts, c1=”w1w2w3” and c2=”w1w2” where c1 and c2 are concepts and w1, w2, w3 are the individual words. After removing the stop words if c1 ʗ c2 it indicates that c1 holds more conceptual information than c2.
In such cases, the length of c1is used in the similarity measure between c1 and c2. It is essential to observe that this length is used only for the comparison between two concepts and has nothing to do identify the importance of the concept. The importance of a concept with respect to the sentence is identified with the help of the conceptual term frequency (ctf), the concept based term frequency (tf) as described in sections 3.1 and 3.2.
Given two documents d1 and d2, the concept-based similarity is calculated by:
• In (3), the tf weighti value presents the weight of concept i in document d at the document level.
• In (3), the ctf weighti value presents the weight of the concept i in document d at the sentence level based on the contribution of concept i to the semantics of the sentences in d.
• In (3), the value rewards the weight of the concept i on the corpus level, when the concept i
appears in a small number of documents.
• The sum between the two values of tf weighti and ctf weighti in (3) presents an accurate measure of the contribution of each concept to the meaning of the sentences and to the topics mentioned in a document. • The multiplication between value and (tf weighti+ ctf weighti) value in (3) finds the concepts that
can efficiently discriminate among documents of the entire corpus.
• Equation (2) assigns a higher score, as the matching concept length approaches the length of its verb argument
structure, because this concept tends to hold more conceptual information related to the meaning of its sentence.
• In (4), the tfijvalue is normalized by the length of the document vector of the term frequencytfijin document d,
where j =1,2,. . . , cn, and
(4)
• cn is the total number of the concepts which has a term frequency value in document d.
• In (5), the ctfij value is normalized by the length of the document vector of the conceptual term frequency ctfij in document d, where j =1,2,. . . , cn,and
(5)
where cndenotes the total number of concepts which has a conceptual term frequency value in the document d. For the single-term similarity measure, the cosine correlation similarity measure in [14] is adopted with the popular Term Frequency/Inverse Document Frequency (TF-IDF) [15] term weighting. The reason for choosing the cosine measure is due to its wide use in the document clustering literature. Accordingly, the single-term similarity measure (sims) is :
(6)
The vectors d1 and d2 are represented as single-term weights calculated by using the TF-IDF weighing scheme.
F. Mathematical Framework
The mathematical framework of the concept based mining model is explained below:
• A concept c is a string of words, c=” wi1,wi2,. . .,win ’’ where n is the total number of words in concept c.
• A sentence s is a string of concepts, s=”ci1,ci2,. . .,cim ’’ where m is the total number of concepts generated from the verb argument structures in sentence s.
• A document d is a string of words, d=” wi1,wi2,. . .,wit’’ where t is the total number of words in document d.
• The function freq(strsub, strtotal) is the number of times that substring strsub appears in string strtotal.
• The concept-based term frequency of document d is tf=freq(ci,d).
• The conceptual term frequency of sentence S is ctfs=freq(ci,s)
• The concept-based weighting of a concept is as in (3).
• The concept-based similarity between documents d1 and d2 using concepts is
IV. CONCLUSION
The proposed system consists of a new concept-based mining model which is composed of four components, is used to improve the text clustering quality. A better quality in clustering is achieved by exploiting the semantic structure of the sentences in documents. The first component analyzes the semantic structure of each sentence to capture the sentence concepts using the proposed conceptual term frequency ctf measure (sentence-based concept analysis). Then, the second component, analyzes each concept at the document level using the concept-based term frequency tf (document-based concept analysis). The third component analyzes concepts on the corpus level using the document frequency df global measure (corpus-based concept analysis). The fourth component is the concept-based similarity measure which allows measuring the importance of each concept with respect to the semantics of the sentence, the topic of the document, and the discrimination among documents in a corpus.
A concept-based similarity measure that is capable of the accurate calculation of pairwise documents is devised by combining the factors affecting the weights of concepts on the sentence, document, and corpus levels. This allows performing concept matching and concept- based similarity calculations among documents in a very robust and accurate way. The quality of text clustering achieved by this model is considerably better than the traditional single term-based approaches. Further research can be done in this paper to use the same model for text classification.
REFERENCES
[1] Ian H. Written, “Text Mining,” Computer Science, University of Waikato, Hamilton, New Zealand.
[2] K.J. Cios, W. Pedrycz, and R.W. Swiniarski, Data Mining Methods for Knowledge Discovery. Kluwer Academic Publishers, 1998.
[3] U.Y. Nahm and R.J. Mooney, “A Mutually Beneficial Integration of Data Mining and Information Extraction,” Proc. 17th Nat’l Conf. Artificial Intelligence (AAAI ’00), pp. 627-632, 2000.
[4] H. Jin, M.-L. Wong, and K.S. Leung, “Scalable Model-Based Clustering for Large Databases Based on Data Summarization,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 27, no. 11, pp. 1710-1719, Nov. 2005.
[5] S. Soderland, “Learning Information Extraction Rules for Semi- Structured and Free Text,” Machine Learning, vol. 34, nos. 1-3, pp. 233-272, Feb. 1999.
[6] T. Hofmann, “The Cluster-Abstraction Model: Unsupervised Learning of Topic Hierarchies from Text Data,” Proc. 16th Int’l Joint Conf. Artificial Intelligence (IJCAI ’99), pp. 682-687, 1999.
[7] T. Honkela, S. Kaski, K. Lagus, and T. Kohonen, “WEBSOM—Self- Organizing Maps of Document Collections,” Proc. Workshop Self- Organizing Maps (WSOM ’97), 1997.
[8] P. Mitra, C. Murthy, and S.K. Pal, “Unsupervised Feature Selection Using Feature Similarity,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 24, no. 3, pp. 301-312,Mar. 2002.
[9] G. Salton, A. Wong, and C.S. Yang, “A Vector Space Model for Automatic Indexing,” Comm. ACM, vol. 18, no. 11, pp. 112-117, 1975.
[10] G. Salton and M.J. McGill, Introduction to Modern Information Retrieval. McGraw-Hill, 1983. [11] C. Fillmore, “The Case for Case,” Universals in Linguistic Theory, Holt, Rinehart and Winston, 1968.
[12] D. Gildea and D. Jurafsky, “Automatic Labeling of Semantic Roles,” Computational Linguistics, vol. 28, no. 3, pp. 245-288, 2002. [13] P. Kingsbury and M. Palmer, “Propbank: The Next Level of Treebank,” Proc. Workshop Treebanks and Lexical Theories, 2003.
[14] A. Strehl, J. Ghosh, and R. Mooney, “Impact of Similarity Measures on Web-Page Clustering,” Proc. 17th Nat’l Conf. Artificial Intelligence: Workshop Artificial Intelligence for Web Search (AAAI), pp. 58-64, 2000.