Revisiting the synthetic control estimator
Texto
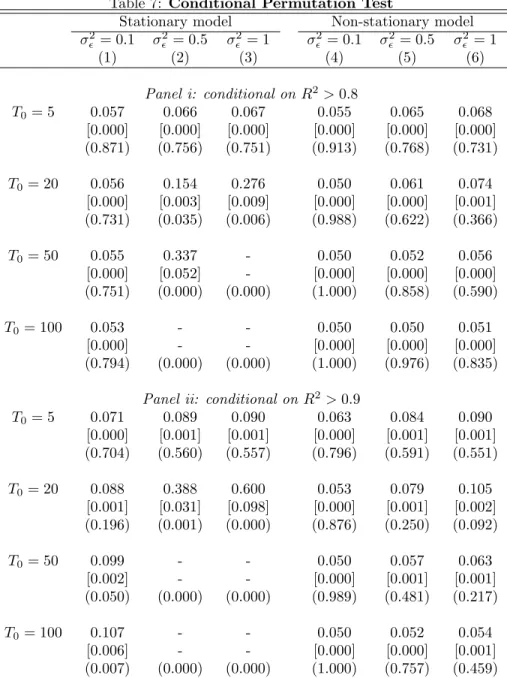
Imagem
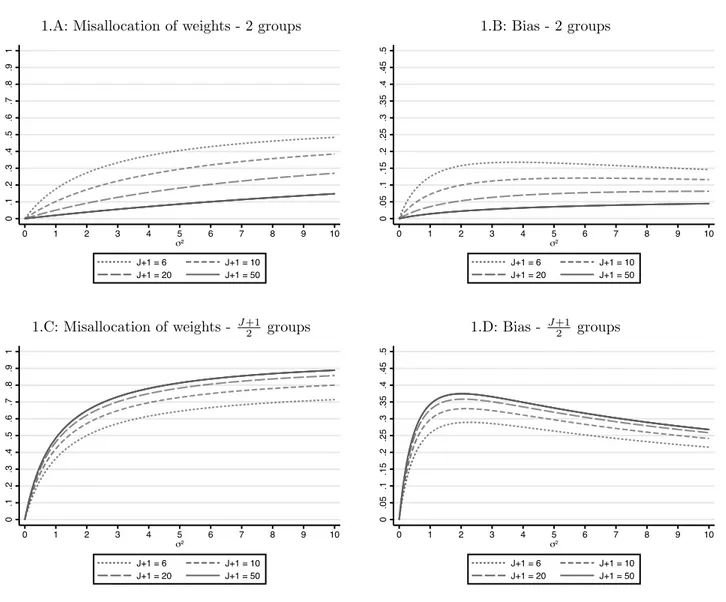
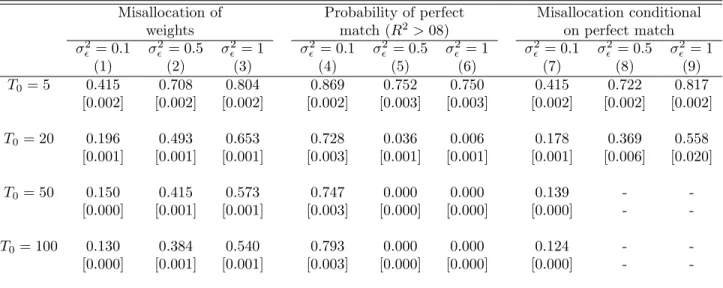
![Table 2: DID/SC ration of standard errors - stationary model σ 2 ǫ = 0.1 σ 2ǫ = 0.5 σ 2ǫ = 1 (1) (2) (3) T0 = 5 1.758 1.152 1.045 [0.014] [0.008] [0.006] T0 = 20 2.412 1.321 1.121 [0.013] [0.007] [0.005] T0 = 50 2.557 1.388 1.163 [0.014] [0.008] [0.006] T0](https://thumb-eu.123doks.com/thumbv2/123dok_br/15701129.119569/35.918.320.617.171.409/table-did-sc-ration-standard-errors-stationary-model.webp)
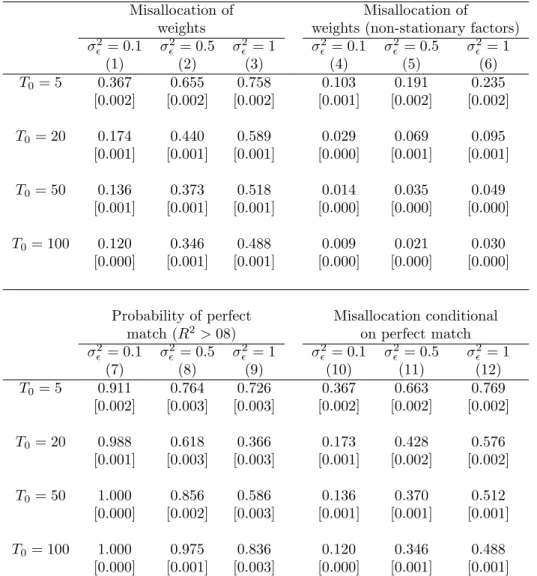
![Table 4: DID/SC ration of standard errors - non-stationary model σ 2 ǫ = 0.1 σ 2ǫ = 0.5 σ 2ǫ = 1 (1) (2) (3) T0 = 5 3.516 2.003 1.655 [0.029] [0.014] [0.010] T0 = 20 8.430 4.006 3.017 [0.061] [0.026] [0.021] T0 = 50 13.526 6.371 4.739 [0.116] [0.033] [0.03](https://thumb-eu.123doks.com/thumbv2/123dok_br/15701129.119569/37.918.320.606.173.407/table-did-sc-ration-standard-errors-stationary-model.webp)
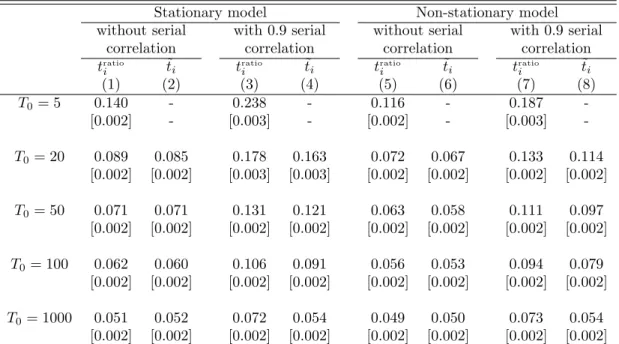
![Table 5: Permutation test with asymptotically biased estimator Stationary model E[λ 1 t|d1t = 1] = 1 E[λ 1 t |d1t = 1] = 2 σ 2 ǫ = 0.1 σ 2ǫ = 0.5 σ ǫ 2 = 1 σ ǫ 2 = 0.1 σ ǫ 2 = 0.5 σ 2ǫ = 1 (1) (2) (3) (4) (5) (6) T0 = 5 0.070 0.064 0.062 0.128 0.107 0.100](https://thumb-eu.123doks.com/thumbv2/123dok_br/15701129.119569/38.918.203.713.171.755/table-permutation-test-asymptotically-biased-estimator-stationary-model.webp)


Documentos relacionados
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
The probability of attending school four our group of interest in this region increased by 6.5 percentage points after the expansion of the Bolsa Família program in 2007 and
didático e resolva as listas de exercícios (disponíveis no Classroom) referentes às obras de Carlos Drummond de Andrade, João Guimarães Rosa, Machado de Assis,
Both fluconazole and itraconazole at 400 mg daily have been effective for various forms of coccidioidomycosis, including meningitis, although relapse after therapy is discontinued is
não existe emissão esp Dntânea. De acordo com essa teoria, átomos excita- dos no vácuo não irradiam. Isso nos leva à idéia de que emissão espontânea está ligada à
Conforme Borba (2006), uma das formas mais apropriadas para representar os relacionamentos entre as classes de fatos e as classes das dimensões é por meio de
This log must identify the roles of any sub-investigator and the person(s) who will be delegated other study- related tasks; such as CRF/EDC entry. Any changes to
Para a valorização desta empresa foram ainda utilizados os outros dois métodos já mencionados - método dos Múltiplos de Mercado e Múltiplos de Transacção.. 28
