Instituto de Ciênias Exatas
Programa de Pós-Graduação em Ciênia da Computação
VIRTUALIZAÇO DE GRANDES BASES DE DADOS
IRREGULARMENTE DISTRIBUÍDAS E REPLICADAS
Dissertação apresentada ao Curso de
Pós-GraduaçãoemCiêniadaComputaçãoda
Uni-versidadeFederalde MinasGeraisomo
requi-sitoparialparaaobtençãodograu deMestre
emCiênia da Computação.
DIÊGO LOPES NOGUEIRA
BeloHorizonte, MG
FOLHADE APROVAÇO
Virtualização de Grandes Bases de Dados Irregularmente Distribuídas e
Repliadas
DIÊGO LOPES NOGUEIRA
Dissertação defendidae aprovadapelabana examinadora onstituída por:
Ph. D. Renato Antnio Celso Ferreira Orientador
UniversidadeFederal de MinasGerais
Ph. D. Dorgival Olavo Guedes Neto Co-orientador
UniversidadeFederal de MinasGerais
Ph. D.Wagner Meira Jr.
UniversidadeFederal de MinasGerais
Grandes volumes de dados são gerados diariamente por experimentos, simulações e vários
outros tipos de apliações. É omum observar situações nas quais porções desses dados
são irregularmente repliadas e distribuídas em diferentes fontes de dados. A repliação e
distribuição irregulares se dão pela geração independente dos diferentes intervalos de dados
orrelaionadosepelafreqüenteausêniadeolaboraçãonoompartilhamentodepartedesses
volumesdedados.
Édesejávelserpossível lidarom essasvárias porçõesdedadosirregulares (repliadosou
não) omoum úniorepositório. A virtualizaçãode dados tornaisto possível eé o prinipal
foodestetrabalho. Nestadissertação, exploramosumsistemaapazdelidar omdados
irre-gularmenterepliados eriar umavisãovirtualúniaapartir dauniãodeporçõesirregulares
dosdados disponíveisem ada umadasfontes de dadosqueompõemo sistema.
Apresentamos uma modelagem geométria dos intervalos de dados que suporta a
virtu-alização de um repositório de dados irregularmente repliado e distribuído, assim omo um
meanismode indexaçãode meta-dadosquepermiteo proessamento deonsultas por
inter-valos dedados submetidasao repositório disponívelno sistemadevirtualização dedados.
Estadissertaçãotambémpropõe doisalgoritmosdeesalonamento defragmentosde
on-sultas baseados nasabordagens gulosa e reozimento simulado. Essesalgoritmossão
respon-sáveispelaseleçãode qual servidoré responsável por servir ada fragmento deuma onsulta
por intervalode dados. Os algoritmos busam minimizar o tempo de resposta dasonsultas
e balaneara argade trabalho entreosservidores onsiderandosuaapaidade deserviço e
arga de trabalho instantânea. A omparação de desempenho dosalgoritmos é baseada em
simulaçõeseosvaloresdosparâmetros utilizadosforamobtidos apartir daaraterizaçãoda
arga de trabalho de uma apliação real e fortemente dependente de dados (o Mirosópio
Large volumes of data are generated every day by experiments, simulations and all sorts
of appliations. It is ommon to observe situations where portions of data are irregularly
repliated anddistributedindierent datasoures. Theindependentgenerationoforrelated
data and lak of ollaboration on sharing these data result in an irregularly repliated and
distributed data set.
Itwouldbedesirableto beabletohandletheseseveralpieesofirregulardata(repliated
or not) as a unique large dataset. This is alled data virtualization and is thefous of this
work. Onthis dissertation, we explore a systemwhih is apable of dealing with irregularly
repliated data and is able to reate a virtual view of the union of the individual irregular
portionsof datahostedbyeah datasoure.
Wepresentageometrimodeltorepresentdataintervals. Themodelallowsfor
virtualiza-tionofanirregularly repliatedanddistributeddataset. Theworkalsopresentsameta-data
indexing mehanismto allowthesystemto proess rangedqueries submitted tothe dataset
availablethrough the datavirtualization system.
Two queryfragmentsheduling algorithmsareproposed, basedonthegreedyand
simula-ted annealingapproahes. Thesealgorithms areresponsiblefor theseletion of whih server
will be in harge of serving eah data query fragment. The algorithms try to minimize the
queries' responsetime and tobalane theloadbetween theservers, takinginto aount their
dierentservieapaitiesandtheworkloadtowhiheahserverissubmittedtoatanygiven
time. The performanes of thealgorithms areompared basedon simulation results and the
parameter values usedwere taken fromtheworkloadharaterization of areal data-oriented
Agradeçoenormementeaosmeuspais,WaldireZoraide,semosquaisnadadistoseriapossível.
Com o arinho e a total dediação à minha eduação, meajudaram de forma deisiva a dar
os passos ertos para hegar até aqui. São os melhores pais que alguém poderia sonhar em
ter, e por isso,muito obrigado. Por todoo apoioe ompanhia nos estudos,alegrias e etapas
difíeisdeminhavida,muitoobrigado. Nãopoderiadeixardeagradeer tambémminhairmã,
Samantha, pela torida, paiênia e apoio durante todosesses anos. Amo voês. Aos meus
familiares, muitoobrigado pelatorida!
Agradeço aosmeus professores e mestres Renato Ferreira, Wagner Meira Jr. e Dorgival
GuedesNeto,queumpriram umpapelimpresindívelemminhaformação aadêmia. Muito
obrigado pelas lições, pela amizade e por todo o apoio que me ofereeram. Muito obrigado
também ao Prof. Riardo Bianhini, queme reebeu na universidade Rutgers omo alunoe
amigo e, emtãopouo tempo,tanto meensinou.
Aos meus olegas do laboratório e-SPEED, obrigado pelo ompanheirismo, por toda a
ajuda que me ofereeram, pelo exelente trabalho em equipe e por manter o ambiente
des-ontraído mesmo nas époas mais atribuladas. Em espeial, muito obrigado a Bruno Diniz
e André Cardoso, sem a ajuda dos quais este trabalho não seria nalizado. Aos amigos do
Dark Lab, muitoobrigado porme aolheremtão bem.
Durante aminha passagempelaUFMG,zváriase valiosasamizadesqueaindahoje são
muito importantes paramim. Gostariade agradeer, emespeial, aosdesmaiados (Juliano
Santos,RobertPinto,StenioViveiros,LuasIssa,LeonardoRoha,IsabelaGuimarães,Gisele
CardosoeAndréGoddard)pelaindispensávelompanhiaeminontáveiseintermináveis
ns-de-semana e madrugadas de estudos. Foram eles quem me ensinaram o que era estudar de
verdade.
Agradeço também aos ompanheiros da Base2 Tenologia, por tudo que me ensinaram,
pelo apoio que me deram e pelo exelente trabalho que desenvolvemos juntos. Desejo-lhes
muito suesso!
Não poderia deixar de agradeeraos meus amigosdo peito,os hamados X-Men. Lele,
Gordão,Rom,BagueteeCabeção,muitoobrigadopelatorida,pelapaiêniaeompreensão
Gostariadeagradeer alguém muitoespeial, minha noiva,Vanessa.
Voê foi meunorte desdeosprimeiros passosdesta aminhada. Antes mesmoda esolha
doursouniversitário, jámemotivava eaompanhavanosestudos. Durantetodaatrajetória
dovestibular,esteve ao meulado, me impulsionando omsua inansáveltorida. E, sempre
daprimeira la, aplaudiu minhasonquistas.
Aminhadediação aosestudosnosprivoudemuitos momentosjuntos: osns-de-semana
no ICEx, as semanas em viagens a ongressos e até mesmo os meses de ausênia, em que
estudei emoutra universidade. Sarifíios demais, muitos disseram. Mas lá estava voê, na
primeira la,torendo.
Essaaminhadanão foifeitasóde onquistasealegrias. No entanto, tomboapóstombo,
sempreenontrei sua mãoestendida, queme guioupara retomarada passo perdido. Como
onseguiutudoissoenquantotraçavasuaprópriaaminhada,éimpossívelompreender. Saiba
quenenhumadessas onquistasseriapossível semo seuarinho, sem oseu apoio, sem a sua
paiênia. Esta vitória ésuatambém. Muitoobrigado por estarsempre aomeu lado.
Seiqueaaminhadanão terminaaqui,apenassetransforma. Seitambémquea próxima
etapanão será feita apenasde onquistas e alegrias. Nada medeixa maisfeliz do que saber
queesolhemosfazerdasnossasvidasumaúniatrajetória,juntos. Muitoobrigadoporexistir
emminha vida.
1 Introdução 1
1.1 Estruturada Dissertação. . . 4
2 Trabalhos Relaionados 5 2.1 Aesso a DadosAtravés daGrade . . . 5
2.2 Banos deDados Distribuídos . . . 6
2.3 Virtualizaçãode Dados. . . 7
3 Virtualização de DadosIrregularmente Repliados e Distribuídos 9 3.1 Indexaçãode Meta-dados . . . 10
3.2 Proessamento de Consultas . . . 14
3.3 Esalonamento de Consultas. . . 17
3.3.1 Esalonamento BaseadoemHeurístia Gulosa. . . 18
3.3.2 Esalonamento BaseadoemReozimento Simulado . . . 21
4 Implementação e Conguração das Simulações 25 4.1 Detalhesde Implementação . . . 25
4.2 Parâmetros de Simulação . . . 26
4.2.1 Geraçãoda Carga de Trabalho . . . 27
4.2.2 Geraçãoda Conguraçãodos Cenários deDados . . . 29
5 Resultados das Simulações 31 5.1 Análisede Balaneamento de Carga . . . 31
5.2 Análisede Desempenho . . . 36
6 Conlusão e Trabalhos Futuros 41 6.1 TrabalhosFuturos . . . 42
1.1 Conguração regular de dados. Os dados são distribuídos e repliados de
maneiraorganizada. Épossívelespeiarfunçõesquedesrevamadistribuição e
repliação dosdados. . . 2
1.2 Conguração irregular de dados. Não houve noção global entre os
gerado-res ou distribuidores de dados, o que resultou em uma repliação e distribuição
desorganizada dosdados. . . 3
3.1 Proesso deriação doíndie global. Asfontesdedadosenviaminformações
sobre osintervalos de dados disponíveis. Os meta-dados sãopré-proessados pelo
proessadorde onsultas paraariação deumíndie global. . . 12
3.2 Representação geométria de intervalos de dados. O proessador de
on-sultasrepresenta osintervalos de dadosomopoliedros. . . 13
3.3 Índieglobal. Oíndieglobalompreendeumonjunto debloosdedados,ada
umom umalistade servidoresassoiados. . . 14
3.4 Proessamento e esalonamento de onsultas. Asonsultas são
representa-dasgeometriamente e proessadasparaidentiar oonjunto de fontes dedados
aptas aproverosdadosrequisitados. . . 15
3.5 Representação geométria da onsulta. A onsulta por intervalos de dados
é mapeada para o mesmo espaço de oordenadas espaiais dos bloos de dados
presentesno índie global. . . 16
3.6 Fragmentos daonsulta. Oresultadodoproessoéumonjuntodefragmentos
da onsultaquepodem serrepassados individualmenteàsfontesde dados. . . 16
3.7 Ilustração dasdeisõesloais doalgoritmo de esalonamento guloso. . . 20
4.1 Distribuição umulativado tamanho dasonsultas,emesalalogarítmia. . . 28
5.1 Bytes transferidos por ada servidor em repositório submetido a uma taxa de
hegadade 274,5onsultas por hora. . . 32
5.2 Bytestransferidos por ada servidoremrepositório ompletamenterepliado (
x
ey
= 100%
) a umataxa de hegadade 274,5 onsultaspor hora. . . 335.3 Tempomédioneessárioparaserviradabyteporadaservidoremumrepositório
vez, alguns pouos intervalos de dados (menos de 0,001%) são requisitados em
maisde20%dasonsultas,hegandoaumextremo deaproximadamente42%das
onsultas. . . 35
5.5 Variaçãoentretemposderespostadosfragmentosdeumaonsultaaumentamom
a taxa de hegada de onsultas submetidasao sistema. Repositório om60%dos
dadosrepliados, omobertura de 60%(
x
ey
= 60%
). . . 365.6 Tempo médio de resposta em função da taxa de hegada de onsultas em um
repositório ompletamente repliado. (
x
ey
= 100%
). . . 375.7 Tempo médio de resposta em função da taxa de hegada de onsultas em um
repositório om 20% dos dados repliados, om obertura de 60%. (
x
= 20%
ey
= 60%
). . . 395.8 Tempo médio de resposta em função da taxa de hegada de onsultas em um
repositório om 80% dos dados repliados, om obertura de 20%. (
x
= 80%
ey
= 20%
). . . 394.1 Parâmetros desimulação parao Mirosópio Virtual . . . 26
4.2 Parâmetros para reozimento simulado utilizados na bibliotea GNU Sienti
Introdução
Diversas ategorias de apliações, omo simulações de fenmenos naturais e apliações
i-entías, dependem fortemente de dados e geram grandes quantidades de informação. F
re-quentemente, o volume de dados tratado por essasapliações é grande o suientepara que
seja neessário sua distribuição em diversos servidores. Em muitos asos, esses dados são
orrelaionados, aindaquepossivelmentegeradosporproessosindependentes. Por exemplo,
diferentesgruposdepesquisaemfísiapoderiamsimularo mesmofenmenofísioutilizando
diferentes intervalos de parâmetros, podendo gerar porções disjuntas de informação.
Possí-veisinterseçõesentreessesintervalosdeparâmetros permitemquedadosrepliados também
sejam gerados poresses proessosindependentes.
Como normalmente altos ustos omputaionais estão assoiados à geração dos dados
produzidos por essa ategoria de apliações, é desejável que diferentes organizações possam
ompartilhar suas porções dos dados, resultando na disponibilização de um repostiório de
dados únioe maisabrangente.
À medida que os dados das diferentes organizações são gerados independentemente,
in-tervalos desses dados sãorepliados sem qualquer noção global. Esta repliação de maneira
ompletamente desorganizada resulta em ongurações irregulares de dados sob o ponto de
vista deum repositório global.
Quandodistribuídos,diferentesporçõesdessesdadostendemaestararmazenadasatravés
de diferentes sistemas,omo banosde dadosou sistemas de arquivos. O gereniamento das
diferentes interfaes de aessoaosvários sistemas de armazenamento de dados setorna uma
tarefa muito omplexa para ser desempenhada por todos os usuários dos dados. Assim, é
importante que exista uma interfae que torne transparente a loalização dos dados, assim
omo seumeanismo de armazenamento. Esta interfae transparente de aessoaos dados é
provida por umserviço onheidoomo virtualizaçãode dados.
Para ompartilhar seus dadosatravésdos sistemas de virtualizaçãoonvenionais, as
or-ganizações preisariam delegar reursos extras de armazenamento, assim omo os dados a
serem ompartilhados. O sistema de virtualização, por sua vez, utilizaria esses reursos de
armazenamento para distribuir os dados de maneira organizada e otimizada, resultando em
organizações detentoras dos dados, a utilização desses sistemas impliaria na transferênia
de grandes quantidades de dados através da rede. Como a movimentação de dados entre
diferentes omputadores, interligados por redes loais ou remotas, é uma operação
ompu-taionalmente ara, é desejável que os repositórios de dados, ainda que distribuídos, sejam
aessadoseientemente.
AsFiguras1.1e1.2exibemumaabstraçãodeonguraçõesderepositóriosdedadosom
espaço de parâmetros bi-dimensional. Considerando que múltiplos servidores armazenam os
dados, a esala de ores nestas guras difereniam os grupos de servidores que armazenam
osintervalos de dados oloridos. Por exemplo, os dados oloridos de brano poderiam estar
disponíveisnosservidores
A
,C
eD
,enquanto osoloridos de pretoestariam disponíveis nosservidores
A
,D
,G
eH
.AFigura1.1ilustraumaonguraçãoregulardedados. Nessaonguração,adistribuição
erepliaçãodedadosfoirealizadadeformaorganizada. Paraariaçãodeonguraçõesomo
esta,éneessárioqueosreursosdearmazenamentosejamdelegadosparaumsistemaentral,
quedistribuiosdadosde maneiraoordenadadentre osservidoresdo repositório.
Dimensão 1
Dimensão 2
Figura 1.1: Conguração regular de dados. Os dados são distribuídos e repliados de
maneiraorganizada. Épossívelespeiarfunçõesquedesrevamadistribuição e repliação
dosdados.
Em ontraste, aFigura1.2ilustra umaonguração irregular de dados. Nessa
ongura-ção,nãohouvequalqueroordenaçãoentreosproessosnageraçãooudistribuiçãodosdados.
Nesteenário,nãoháaneessidadedetransferêniadosdadoseprovimentodereursosextras
dearmazenamento paraagregar osdadosao repositório virtual.
Ainda queexistaminúmeros estudossobre o provimento de aesso adados regularmente
distribuídose sobreproessamento distribuídodeonsultas,ainda éumdesaoprover
virtu-alizaçãoparadadosdistribuídos e repliados demaneira irregular.
Estetrabalho propõe umaarquiteturaque busaviabilizar o proessamento deonsultas
por intervalosde dadossubmetidasaumrepositório resultanteda uniãodeporçõesde dados
distribuídaserepliadasirregularmente,omplementandoesforçosanterioresemvirtualização
Dimensão 1
Dimensão 2
Figura1.2: Conguração irregularde dados. Nãohouvenoçãoglobal entreosgeradores
ou distribuidores de dados, o que resultou em uma repliação e distribuição desorganizada
dosdados.
dados orrelaionados e distribuídos em diferentes servidores e emum modelo de indexação
dosmeta-dados baseado emalgoritmos geométrios.
Esse modelo permite que um sistema de virtualização de dados opere em ongurações
de dados distribuídos e repliados de maneira irregular. O modelo também se estende ao
proessamento das onsultas em repositórios de dados om essas araterístias. Tanto as
porções de dados quanto as onsultas são representadas geometriamente e são utilizados
algoritmos de deomposição de polígonos [O'Rourke (1998 )℄ paragerar retângulos maximais
disjuntos, querepresentamintervalosde dadosarmazenadosem umou maisservidores. Este
trabalho não explora a representação de bases de dados baseadas em atributos através de
dimensões espaiais. Apesar do modelo não se restringir a bases de dados denidas através
de oordenadas espaiais,omoimagens ouobjetosgeorefereniados, estetrabalho apresenta
exemplosonretosapenasparaessaategoriadedados,umavezqueomapeamentodedados
baseados em atributosrequerum estudomaisaprofundado.
Uma vez identiados os servidores andidatos, é neessário que um algoritmo guie a
esolhade qualservidoratenderá,ompleta ouparialmente, ada onsultapor intervalosde
dados. Estetrabalho exploradoisalgoritmosdeseleçãodefontesdedadoseosontrastaom
algoritmosbásiosdeesalonamento previamenteestudados[Dinizetalia(2006 )℄. Oprimeiro
algoritmoexploradonestetrabalho ébaseadoemumaabordagemgulosaenquantoosegundo
se baseia na abstração de reozimento simulado (do inglês, simulated annealing) busando
minimizar o tempo de resposta das onsultas. Esses algoritmos tomam deisões om base
na arga instantânea imposta aos servidores e busam minimizar o tempo de resposta das
onsultas ebalaneara argaentreosservidoresonsiderando assuasdiferentesapaidades
de serviço.
Para avaliar o desempenho dosalgoritmos propostos, o trabalho faz uso de simulações e
variou uma vasta ombinação de parâmetros omo: taxa de hegada de onsultas, tamanho
do repositório, nível de repliação de dados e outros. Todosos parâmetros foram obtidos a
repositóriosde dados: o Mirosópio Virtual[Ferreira etalia (1997 )℄. Este estudo permite a
análisedosefeitos dessesalgoritmos, que poderiamser implementados e integradosa muitas
dasferramentasde virtualização de dadosexistentes[Weng etalia (2004 );Chervenaketalia
(1999 );MooreeBaru (2003 )℄,paraaresentarosuporteàdistribuiçãoerepliação irregular
de dados. As ferramentas apresentadas até então suportam apenas ongurações regulares
de distribuição e repliação de dados, assim ommo banos de dados distribuídos, de uma
maneirageral.
Aapliaçãodessaarquiteturanãoserestringeapenasavirtualizaçãodedadossobregrades
de dados[Chervenak etalia (1999 )℄. É possível apliar este oneitosobre qualquer sistema
distribuído no qual os dados são repliados ou distribuídos de maneira desorganizada (sem
uma noção global entre as fontes de dados) e que suporte um índie global de meta-dados.
Exemplos de apliações são índie para sistema de ahes distribuídos e redes de sensores
para disseminação de dados [Luoetalia (2005 )℄. O trabalho não onsidera operações de
atualizaçãodosdadosdorepositório,assumindoqueosdadosestãodisponíveissomentepara
leitura. Noentanto,nãoéompliadopermitiratualizaçõeseinserçõesdedadosàbase,omo
seráexpliado na Seção3.1.
1.1 Estrutura da Dissertação
Cino apítulos seguem esta introdução. O Capítulo 2 disutealguns trabalhos relaionados
e ontrasta suas ontribuições om as apresentadas neste trabalho. O Capítulo 3 apresenta
osoneitos relaionados a virtualização de dados, além do modelo proposto que permite a
indexação de meta-dados para enários de dados irregularmente repliados (Seção 3.1) e os
algoritmospropostosparaesalonamento deonsultas (Seção3.3 ). Emseguida, oCapítulo4
disute as deisões de implementação e os resultados do estudo de araterização de arga
realizado. OCapítulo 5apresentaosresultados obtidospelassimulaçõeseomparao
desem-penho dos algoritmospropostos ao desempenho de outros algoritmos básios. Finalmente, o
Trabalhos Relaionados
2.1 Aesso a Dados Através da Grade
Uma grade omputaional é omposta por vários omputadores interonetados, formando
um omputador virtual apaz de distribuir proessos entre seus omponentes. Essa
arqui-tetura é utilizada prinipalmente para soluionar problemas omputaionais de larga esala.
Nos últimos anos, alguns trabalhos foram desenvolvidos voltados para infra-estruturas em
grade[The GlobusAlliane(2005 )℄esoluçõeseapliaçõesbaseadasnaGradeomputaional.
Em [Chervenaketalia (1999)℄,osautores apresentaram umaarquiteturaparagereniamento
dedadosnaGrade. EssaarquiteturaébaseadanosServiçosparaDadosemGrade(doinglês,
Grid Data Servies ouGDS),quesãoextensõesdosonheidosGridServies. Parasuportar
aessoeintegração dedadosnaGrade,umgrupoinglêsrioua Open GridServies
Arhite-ture Data Aess and Integration(OGSA-DAI)
[Database Aessand Integration ServiesWorkingGroup (2005 )℄. Esta ébaseada na
arqui-tetura paragradededados(doinglês,data grid)[Chervenak et alia(1999 )℄eserveomobase
paraOGSA-DQP[Alpdemiretalia(2003 )℄,emqueosautores apresentam umarabouço
ba-seado em serviços que permite que onsultas sejam submetidas para dados distribuídos em
grade e disponíveis através dos GDS.[Watson (2005 )℄ explorou OGSA-DQP no ontexto de
loalidade e distribuição de dados. Todos esses trabalhos diferem do trabalho apresentado
nesta dissertação por não ataarem o problema de repliação de dados, além de assumirem
que osdadosestão organizadosem banosde dadosrelaionais.
Em [Alloketalia (2002 )℄, os autores tratam o problema de repliação de dados,
po-rém não lidam om a submissão de onsultas a esses dados. Eles apresentam uma solução
denominada GridFTP,que permite atransferênia de dadosentre nósde umagrade
ompu-taional. Além de não apresentarem suporte a onsultas, os autores assumem que os dados
estãorepliadosdeformaregular. [BaereWyko(2004 )℄apresentaramumaotimizaçãopara
o GridFTP que utiliza MPI-I/O paraa omuniação na grade. Um arabouço de
esalona-mento de tarefas em grade foi desrito por [Ranganathan e Foster (2002 )℄. Esse arabouço
desvinulaaomputaçãoeamovimentação dedadosdatarefasendoesalonadaeé apazde
A prinipal diferença entre os trabalhos de pesquisa em aessode dados em gradee este
trabalho é a não onsideração de enários de dados irregularmente repliados e a maioria
dosestudossupõe que osdados estão organizados embanos de dados relaionais e que são
passíveis de realoação entre os nodos da Grade. A arquitetura disutida nesta dissertação
suporta repositórios de dados irregularmente distribuídos e repliados e pode ser utilizada
sobrequaisquertiposdedados quepermitam onsultas por intervalos.
2.2 Banos de Dados Distribuídos
Ostrabalhosdepesquisarealizadossobrebanosdedadosdistribuídostambémserelaionam
om esse trabalho. Em sua maioria, os esforços nessa área vêm se onentrando no projeto
de um sistema de gerênia de banos de dados (do inglês, Data Base Management System
ou DBMS) baseado em aglomerados de omputadores, om dados possivelmente repliados
epotenial paraproessamento de onsultas. [DeWitte Gray (1992 )℄apresentaram ténias
utilizadas para implementar banos de dados distribuídos (hamados de banos de dados
paralelos).
O mais importante desao relaionado a banos de dados distribuídos é a habilidade de
proessar onsultas de maneira distribuída. Em [Epstein et alia (1978 ); Yu e Chang (1984 );
Kossman(2000 )℄,osautoresapresentamamaiorpartedosoneitosenvolvidosnoproessode
proessamento deonsultas,dadoqueosdadosestãodistribuídos embanosdedados
distin-tos. Em[Haas etalia(1997 )℄,osautoresintroduzemummiddlewarequeotimizaonsultasque
deveriamserservidasporfontesdedadosdistintas. Omiddleware permitequeada fontede
dados(servidordebano de dados)tenhaumaapaidade de atendimento de onsultas
dife-rente,eexploraestaheterogeneidadenoproessamentodasonsultas. Em[Kempere Wiesner
(2001 )℄, uma nova arquitetura é apresentada, baseada em híper-onsultas (do inglês, hyper
queries) para proessar onsultas distribuídas no ontexto de omério eletrnio entre
em-presas(doinglês, business-to-business ou B2B).[Kossman(2000 )℄apresentou umestudo que
desreve várias ténias de proessamento distribuído de onsultas, omo ténias de união
(join),téniasqueexploram paralelismointra-onsulta, téniasprojetadasparadiminuiros
ustosdeomuniação, entreoutras.
[Rahm eMarek(1995 )℄abordaram oproblemadebalaneamentodearganoontextode
sistemas de banos de dados paralelos, nos quaisa deisãode esalonamento de tarefasnão
ésimples. Oproblemade gereniamento de dadosdistribuídos é abordadoem[Bartal etalia
(1992 )℄. Osautores apresentamumaanáliseomparativade algoritmosparagereniaros
da-dosemumambientedistribuído,estudandoempartiulararepliaçãoealoaçãodearquivos.
Em [Gribbleetalia (2000 )℄, osautores apresentam umonjunto de abstraçõesenapsuladas
emumaamada om oobjetivo de simpliar a onstruçãode serviços deInternet baseados
em aglomerados de omputadores. Eles fazem uso de tabelas hash distribuídas (do inglês,
distributed hashtables ou DHT)paragereniar réplias e exeutarosserviços.
Trabalhos que tratam de proessamento distribuído de onsultas se assemelham a este
(virtualização dosdados). Noentanto,estetrabalho lidaomrepositóriosdedados
irregular-mentedistribuídos e repliados. Sistemas de banos de dados distribuídos normalmente
de-senadeiamrepliaçãodedadosparafavoreertolerâniaafalhasdevidoàredundâniaepara
alançar melhores tempos de resposta no atendimento de onsultas, omo em [Amzaetalia
(2003 );Soundararajan etalia(2005 )℄. Essarepliação,noentanto,aonteedemaneira
regu-lar, seguindo ritériosestabeleidospelousuário oupeloprópriosistemade banosdedados.
2.3 Virtualização de Dados
Algumas onquistasforam alançadasemvirtualização dedados [Weng etalia (2004 );
Narayanan etalia (2003 ); Mooree Baru (2003 )℄, porém todas assumem enários de dados
regularmente distribuídos. Além disso,algumas dassoluçõespropostas dependem de
espei-açõesinternas de representação dedados. Este trabalhoprovê virtualizaçãode dados,mas
nãoapresentaqualquerrestriçãoquantoàmaneiranaqualosdadosseenontramdistribuídos
ou repliados.
[Sarawagi e Stonebraker (1994 )℄ mostraram omo aessar trehos de vetores omo
obje-tos em banos de dadosobjeto-relaionais enquanto em [Stolteet alia (2002a,b)℄,os autores
lidam om esses vetores e informações multi-dimensionais omo ubos de dados. Um
exem-plode bano dedados omerialquelidaomdados multi-dimensionais podeserenontrado
em [Baumannetalia (1997 )℄. Este trabalho apresenta um modelo de indexação de dados
que também suporta repositórios multi-dimensionais. No entanto, o modelo permite que o
mapeamento entreosparâmetros quedenema basede dadose asdimensõesdo repositório
Virtualização de Dados Irregularmente
Repliados e Distribuídos
Algumas ategorias de apliações, prinipalmente apliações ientías ou simuladores de
fenmenos naturais, preisam aessare analisarenormes volumesde dados. As omunidades
ientíasque demandam aessoa esses reursos sãonumerosas e geograamente
distribuí-das, assim omo os reursos de armazenamento e omputação utilizados por essas
omuni-dades [Mooreetalia (1999 )℄. Os dados analisados por essas omunidades são volumosos o
suiente para quese torne inviável seu armazenamento em umúnio omponentede
hard-ware e, em muitos asos, em um únio domínio administrativo. As grades omputaionais
apresentamumaapaidadedearmazenamentovirtualmenteilimitadaeportantosãoos
prin-ipais ambientes utilizadosparaatender àsdemandas por grandes quantidades dedados. As
grades omputaionais,noentanto, têmaheterogeneidade dehardwareesoftwareomouma
de suasaraterístias prinipais,o quetornaum desaoo aessoa reursos deseus nodos.
Ahabilidadede organizaregereniardadosqueestãodistribuídos emdiferentes
loalida-dese domíniosadministrativoséprovida porgrades dedados, quesebaseiamnooneitode
virtualizaçãodedados. Avirtualizaçãodedadoséalançada atravésdainserçãodesoftwares
degereniamentodedadoseonversãodeonsultasentreasapliaçõesouserviçosdeusuários
e osrepositórios dedados, onde seenontram osdados. Osoftwarede gereniamento de
da-dosprovêidentiadores persistentesúniosparaadesobertaeaessoaosdadoseoperações
padronizadas parainteragir omossistemasde armazenamento [Mooree Baru(2003 )℄.
Os sistemas de virtualização até então propostos operam sobre um ambiente no qual os
dados são organizados de aordo om um ritério pré-denido. Os sistemas são ativos, no
sentidode quetêma autonomiaparadisparar proessosde repliação dedados, quebusam
favoreerumritériodedesempenhopré-estabeleidoparaoserviçodosdados. Essessistemas
busamdistribuirosdadosdemaneiraordenada,sendoassimpossíveldeterminaraloalização
deumaporçãodedadosatravésdeumafunção. Assim,ossistemasatéentãopropostoslidam
om ongurações regularesde repositórios dedados.
Nessesrepositórios,osdadossãogerados deformaindependente, semumanoção globale
10 Distribuídos
de dadosque o ompõe. Nesse aso, existe um senso de olaboração no sentido de quehá o
interessepor partede uma dasfontes de dadosque outrosusuários aessem osdados, masa
olaboraçãonãoneessariamenteseestendeaopontoemqueasfontesdedadosompartilham
seusreursoseonamosdadosaosistemaomoumtodo,permitindoqueporçõesdosdados
sejamremovidasde seurepositório ouque outras porçõesde dadossejam aresidasa ele.
[Chervenaketalia (1999)℄disuteospré-requisitos, emdiferentesníveis,paraseprojetar
uma arquitetura de grade de dados. Em um enário no qual se tem aesso irrestrito para
repliar,removeregravarnovosdadosnosnodosdagrade,otrabalho apresentaasprinipais
araterístiasdos serviçosfundamentais neessários para a implementação de umagradede
dados. Alguns desses serviços se relaionam diretamente om o serviço de virtualização de
dados, foo desta dissertação. Os dois serviçosfundamentais para a implementação de uma
gradededados são: aessoa dadose aessoameta-dados.
Oserviçodeaessoadadosdeveprovermeanismosparaaessar,gereniareiniiar
trans-ferêniasdedadospresentesemsistemasdearmazenamento. Oserviçodeaessoameta-dados
deve prover meanismos para aessar e gereniar informações sobre os dados presentes nos
sistemas de armazenamento. A distinção explíita entre armazenamento e meta-dados em
níveldearquiteturafavoreeaexibilidadenaimplementaçãodesistemasdearmazenamento
enquantominimizaoimpatoemimplementaçõesqueombinemaessosameta-dadose
aes-sosaossistemadearmazenamento. Permite,porexemplo,queoserviçodeaessoadadosnão
sejaafetado pela onguração irregular do repositório. Nesse aso, apenas o proessamento
demeta-dados seriaafetado. Omodelode indexaçãode meta-dados propostoneste trabalho
éapresentadona Seção3.1.
[Chervenaketalia (1999 )℄ apresenta gereniamento e seleçãode réplias omoos
ompo-nentesmaissigniativosdaamadademaisaltoníveldaarquiteturadeumagradededados.
Ogerente de réplias tem omo papelriar ou remover ópias de instânias de arquivos, ou
réplias,em determinadossistemas de armazenamento. Esseagente não seaplia ao enário
de distribuiçãode dados tratado nesta dissertação, no qual nenhumagenteentralizado tem
autoridadesobre osdados disponíveis na grade de dados, impedindo a riaçãoe remoção de
réplias nos nodos da grade. O serviço de seleção de réplias tem omo papelesolher uma
réplia dos dados que ofereerá a uma apliação om araterístias de aesso a dados que
otimizealgumritériodedesempenhodesejado,omotempoderesposta, ustoousegurança.
Nestetrabalho,aseleçãoderépliasé tratadaomoesalonamento deonsultaseédisutida
naSeção3.3 .
3.1 Indexação de Meta-dados
Quando uma onsulta é feita a um sistema de virtualização de dados o software de
geren-iamento de dados, neste trabalho hamado de proessador de onsultas, deve ser apaz de
identiar a que porção do repositório a onsulta se refere, qual(is) servidor(es) (ou fontes
de dados) possui(em) toda ou parte do onteúdo requisitado, além de informações sobre os
em termos dos ritérios de desempenho. Neste trabalho, os meta-dados são denidos omo
toda informação sobre os servidores, instânias de repositórios e tipos de meanismos de
armazenamento.
No entanto, não é viável que todas essasinformações sejam adquiridas pelo proessador
de onsultas sob demanda, a ada onsulta reebida. Os prinipais fatores que tornam essa
prátiainviávelsãodesempenhoelimitaçãodereursosderede. Assim,éneessárioquetodas
essasinformaçõessejamadquiridaspreviamentepeloproessadorde onsultas. Aindaassim,
essas informações preisariam ser proessadas todas as vezes que uma nova onsulta fosse
feita ao repositório de dados. Por esse motivo, os softwares de proessamento de onsultas
normalmenterealizamdeantemãotodooproessamentodemeta-dados,sumarizando-ospara
agilizar o proessamento dasonsultas por dados. A estepré-proessamento dosmeta-dados
dá-se o nomede indexação.
Na iniialização do sistema explorado neste trabalho, é neessário que todas as fontes
de dados enviem seus meta-dados, que onsistem em informações sobre os limites de ada
intervalo de dados disponível na fonte de dados e informações sobre a apaidade do nodo
para prover dados. A úniarestrição sobre amétria utilizada paraexpressartal apaidade
paraprovimento dedadoséquetodasasfontesdedadosdevemutilizara mesmamétria em
seus meta-dados. Esta métria deve representar um gargalo do sistema, omo por exemplo:
banda daonexãoderede, tempodeaessoadispositivosdearmazenamento de dados(omo
arranjos de disosrígidos), tempode proessamento de umaonsulta por um meanismode
armazenamento de dados (omo bano de dados), et. Nos experimentos realizados neste
trabalho, a métriautilizada foilargura de banda de redeparatransmissão dosdados.
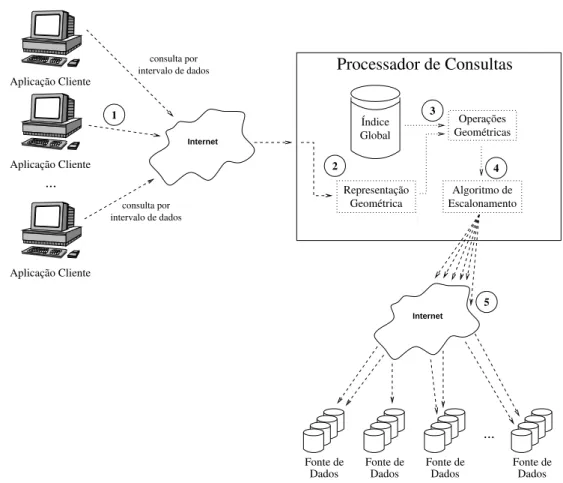
AFigura3.1esquematiza,demaneirageral,oproessodeindexaçãodosmeta-dadospara
a riação doíndie global. Em umprimeiro momento, todasasfontes de dadosenviamseus
meta-dados parao proessador de onsultas. Não háqualquer restrição quanto ao protoolo
deomuniaçãoentreasfontesdedadoseoproessadordeonsultas,desdequehajagarantia
de entregados dadosenviados naausênia defalhas de dispositivos.
Oproessador de onsultas deveráser apazde identiar intervalosde dados repliados
ao longo de todo o repositório, ainda que a repliação e distribuição desses dadosoorra de
maneira irregular. Para isto, este trabalho propõe uma modelagem geométria dos
meta-dados para ns de indexação e proessamento de onsultas por intervalos de dados. Uma
expliaçãodetalhada destamodelageme aomputaçãoassoiadaéapresentadamaisadiante
nesta seção. A transformaçãodemeta-dadosemsuarepresentaçãogeométriaéo queoorre
no segundo passoesquematizado na Figura3.1.
O tereiro passo onsiste na realização de uma série de operações geométrias sobre as
representações dos meta-dados de ada um dos intervalos de dados. Dentre as operações
geométrias estãooperaçõesde veriação, omointerseção esubtraçãode poliedros,e uma
operaçãode deomposição de poliedros emsub-poliedros retos,queserádesrita emdetalhes
posteriormente. Oresultado desse proesso é um onjunto de poliedros maximais disjuntos,
queunidosrepresentamtodoorepositóriodedados. Cadaumdessespoliedrosrepresenta um
12 Distribuídos
Internet
Índice
Global
Operações
Geométricas
Representação
Geométrica
Processador de Consultas
Fonte de
Dados
Fonte de
Dados
Fonte de
Dados
Fonte de
Dados
...
meta−dados
meta−dados
2
3
4
1
Figura3.1: Proessoderiaçãodoíndieglobal. Asfontesdedadosenviaminformações
sobreosintervalosdedadosdisponíveis. Osmeta-dadossãopré-proessadospeloproessador
deonsultas para ariação deumíndie global.
Paraqueasoperaçõesgeométriassejamrealizadasentreosváriospoliedroseparaqueos
poliedros resultantes possam serunidos para representar todoo repositório, éneessário que
exista um mapeamento entre osparâmetros ou atributos que denem osdados e dimensões
espaiais. Estatarefaétrivialquandoosparâmetros dorepositóriosetratamdeoordenadas
espaiais,omo noaso deimagens oubases de dadosde geoproessamento. Repositóriosde
dadosdenidosatravésde atributos,omoembanos de dadosrelaionais, fazemdessa uma
tarefamaisomplexa querequerum estudomaisaprofundado.
Paramelhordetalharoproessodeindexaçãodosmeta-dados,podemossupor um
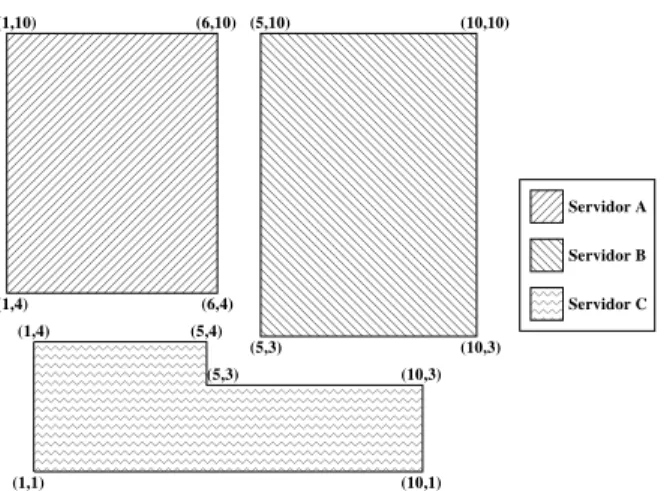
reposi-tóriodedadosformadoporapenas3servidores,oufontesdedados,
A
,B
eC
. Essesservidoresenviam para o proessador de onsultas informações sobre sua apaidade de prover dados.
Além disto, ada servidor informa os limites dos intervalos de dados que hospedam. Neste
exemplo, dois parâmetros denem os limites de um intervalo de dados. O proessador de
onsultasmapeia esseslimitesem oordenadasespaiais erepresenta ada umdosintervalos
de dados omo um poliedro, omo ilustrado na Figura 3.2 . Como no exemplo o espaço de
dadosébi-dimensional, osintervalos dedados sãorepresentados omopolígonos.
A primeira rodada de operações geométrias a ser realizada é a deomposição de todos
ospoliedros não retos no menor número possível de poliedros retos que unidos ompõem o
poliedrooriginal. Noasoilustrado,opolígonoquerepresentaointervalodedadoshospedado
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
(1,4)
(1,10)
(6,4)
(6,10) (5,10)
(10,10)
(5,3)
(10,3)
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
(1,4)
(5,4)
(5,3)
(10,3)
(10,1)
(1,1)
000
000
000
000
111
111
111
111
Servidor C
000
000
111
111
Servidor B
Servidor A
000
000
111
111
Figura 3.2: Representação geométria de intervalos de dados. Oproessador de
on-sultas representa osintervalos de dadosomo poliedros.
realizada para permitiralgumassimpliaçõesno algoritmo de deomposição de poliedros.
Nestetrabalho, assume-sequetodosospoliedros eporonsequêniatodososintervalos
de dados são retos, ou seja, apresentam apenas ângulos retos entre lados adjaentes. Esta
premissaé assumidaparasimpliar osalgoritmos geométriosutilizadosna implementação,
e não é fruto de limitação do modelo de indexação e proessamento de onsultas propostos
neste trabalho. O impato dessa simpliação no âmbito da apliação do sistema é que os
intervalos de dados sejam sempre limitados por pares de valoresatribuídos a parâmetros ou
atributos quedeverãoserortogonais emseumapeamento para oordenadas espaiais.
Napróximarodada,todosospoliedros sãotomadosaospares. Se doispoliedrospossuem
uma interseção não nula, a porção omum a ambos é subtraída e as partes restantes são
submetidas àdeomposição em poliedros retos. A porção omumse tornaumnovo poliedro
(reto) a ser tratado e a lista de servidores dos dois poliedros originais é ombinada para
riar a lista de servidores da porção omum. O novo poliedro também é tomado par-a-par
om osdemais, om exeçãodo par que o originou. No repositório de exemplo, ospolígonos
relaionados aos intervalos de dados dos servidores
A
eB
se intersetariam e a interseçãoseriasubtraídadospolígonosoriginais. Oresultadode
B
−
(A
∩
B
)
não seriaumretânguloeteria entãoque serdeomposto.
Essa operação oorre até que nenhum par de poliedros se intersete. O resultado é um
onjunto de poliedros retos maximais disjuntos, que serão daqui em diante referidos omo
bloos de dados. Cada bloo de dados representa um intervalo de dados hospedado por um
grupo de fontes de dados. Um bloo de dados assoiadoa múltiplos servidores é umindíio
derepliação norepositório. Oonjuntodetodososbloosdedadosonstituioíndieglobal,
exempliadonaFigura3.3 . Auniãodetodosospoliedrosretosmaximaisdisjuntosmapeados
no mesmo espaçode oordenadas forma arepresentação geométriade todoo repositório de
dados disponívelatravés dosistemade virtualização.
Através da Figura 3.3 é possível observar que o polígono referente ao intervalo de dados
14 Distribuídos
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
000
000
000
000
000
000
000
000
000
000
000
000
000
000
000
111
111
111
111
111
111
111
111
111
111
111
111
111
111
111
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
0000000000000
0000000000000
0000000000000
1111111111111
1111111111111
1111111111111
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
(1,4)
(1,10)
(5,10)
(6,10)
(10,10)
(10,4)
(10,3)
(10,1)
(1,1)
(1,3)
(5,4)
(6,4)
(5,3)
00
00
00
00
00
11
11
11
11
11
Servidor C
00
00
00
11
11
11
Servidor B
00
00
00
11
11
11
Servidor A
Figura 3.3: Índie global. O índie global ompreende um onjunto de bloos de dados,
ada umom umalistade servidores assoiados.
retângulos na primeira rodada do proesso de indexação. Na rodada seguinte, a interseção
dospolígonos referentes aosintervalos de dadosdosservidores
A
eB
gerou ariação de umnovo bloo dedados, omambososservidores emsualistade fontes dedados. Oquerestou
dopolígono referente aoservidor
B
foientãodeomposto emdois retângulos.Apesardenestetrabalhoosdadosteremsidoonsideradosdisponíveisapenasparaleitura,
nãoháqualquerrestriçãoqueimpeçaquenovosintervalosdedadossejaminseridosnosistema
ou que atualizações sejam feitas sobre os dados já presentes no índie global. No aso de
atualizações de dados, seria neessárioremoverdo índie global todasas entradas referentes
aoservidorquehospedaosdadosatualizados. Emseguida,osmeta-dadosdevemserenviados
novamente ao proessadorde onsultas,quedeve reinseriressasinformaçõesnoíndie global
atravésdaexeuçãodosalgoritmos geométriosdesritosnestaseção. Noasodeinserçãode
dados,éneessárioapenasqueosmeta-dados quedesrevemonovointervalode dadossejam
integradosao índieglobal. Noasode umíndie nãoentralizado,téniasonvenionaisde
sinronizaçãode índiesdistribuídos devemser apliadas [Özsue Valduriez (1999)℄.
Uma vez riado o índie global, o proessadorde onsultas está apto a reeber onsultas
porintervalosdedadosedesmembrá-lasemmúltiplasonsultasmenoresaseremdistribuídas
para as várias fontes de dados que ompõem o sistema. O algoritmo de proessamento de
onsultasé muitosemelhanteao de indexaçãode meta-dados eé desrito naSeção3.2 .
3.2 Proessamento de Consultas
Uma vez que o índie global esteja ompleto, o proessador de onsultas está pronto para
reeberonsultas. Oproessamentodeonsultasémuitosemelhanteaoproessodeindexação
de meta-dados apresentado. A Figura 3.4 esquematiza o proessamento e esalonamento de
onsultas.
Iniialmente, os lientes enviam onsultas por intervalos de dados para o proessador de
onsultas. Não háqualquer restriçãoquantoaoprotoolodeomuniaçãoentreasapliações
lientes eoproessadordeonsultas,desdequehajaumagarantiade entrega dasrequisições
Internet
Internet
consulta por
intervalo de dados
consulta por
intervalo de dados
Aplicação Cliente
Aplicação Cliente
Aplicação Cliente
...
1
2
3
4
5
Fonte de
Dados
Fonte de
Dados
Fonte de
Dados
Fonte de
Dados
...
Processador de Consultas
Representação
Geométrica
Índice
Global
Operações
Geométricas
Escalonamento
Algoritmo de
00
00
00
00
11
11
11
11
00
00
00
00
11
11
11
11
00
00
00
00
11
11
11
11
00000000
11111111
000
000
111
111
00000000
11111111
000
000
111
111
00000000
11111111
000
000
111
111
Figura 3.4: Proessamento e esalonamento de onsultas. Asonsultas são
represen-tadas geometriamente e proessadas para identiar o onjunto de fontes de dadosaptas a
prover osdadosrequisitados.
mesmoritériodemapeamentoparaoordenadasespaiaisutilizadonoproessodeindexação
e geraumarepresentaçãogeométriadaonsultapor intervalos(etapa2daFigura3.4 ). Essa
representação geométria pode resultar em múltiplos poliedros, aso os intervalos de dados
requisitados nãosejam adjaentes.
Aimplementaçãoapresentadanestetrabalhoassumeapremissadequetodasasonsultas
por intervalos de dadosresultam em poliedros retos quando representadas geometriamente,
assim omoparaosintervalos dedados disponíveis nasfontes dedados.
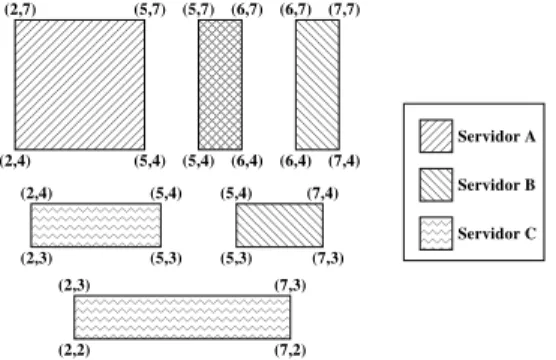
A Figura 3.5 ilustra uma onsulta por intervalo de dados no repositório suposto omo
exemplo na Seção 3.1 . Na gura, é realizada uma onsulta pelo intervalo de dados que,
quando mapeado para oordenadas espaiais, é limitado pelos valores 2 e 7 em ambas as
dimensões(atributos ouparâmetros dorepositório de dados).
A tereiraetapa doproessamento de onsultas (Figura 3.4)onsiste emposiionar a
re-presentaçãogeométriadaonsultanoespaçodeoordenadas,juntamenteomtodososbloos
de dados que formamo índie global. Então, os poliedros retos que representam a onsulta
sãofragmentados emsuasinterseçõesomosbloosdedados. Aadapoliedroresultanteda
interseção daonsultaomumbloode dadoséassoiadaalistadefontesdedados
16 Distribuídos
000
000
000
000
000
000
000
000
000
000
000
000
000
000
000
111
111
111
111
111
111
111
111
111
111
111
111
111
111
111
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
0000000000000
0000000000000
0000000000000
1111111111111
1111111111111
1111111111111
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
1111111111
0000000000
0000000000
0000000000
0000000000
0000000000
1111111111
1111111111
1111111111
1111111111
1111111111
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
00000000000000000000000
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
11111111111111111111111
(10,4)
(10,3)
(1,4)
(1,10)
(5,10)
(6,10)
(10,10)
(10,1)
(1,1)
(1,3)
(5,4)
(6,4)
(5,3)
(2,2)
(2,7)
(7,7)
(7,2)
Consulta
00
00
00
00
11
11
11
11
Servidor C
00
00
11
11
Servidor B
00
00
11
11
Servidor A
Figura3.5: Representação geométria da onsulta. Aonsulta por intervalos de dados
é mapeada para omesmo espaço de oordenadas espaiais dosbloos de dados presentes no
índie global.
e disjuntos) que unidos formama representação geométria da onsulta. A ada um desses
fragmentos está assoiada a lista de fontes de dados andidatas para prover aquela porção
dosdadosrequisitados. Esseonjunto depoliedrosretos representaosfragmentosdisjuntose
maximaisdaonsultaquepodemserrepassados,emgruposouseparadamente, paraasfontes
dedadosquehospedamosintervalosdedadosrequisitados. Essesfragmentosresultantes são
tratadosnestetrabalhoomofragmentosdaonsulta. AFigura3.6esquematizaesseresultado
paraosuposto repositório.
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
0000000000000
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
1111111111111
(2,2)
(7,2)
(2,3)
(7,3)
00000000
00000000
00000000
00000000
00000000
00000000
00000000
00000000
00000000
11111111
11111111
11111111
11111111
11111111
11111111
11111111
11111111
11111111
(2,7)
(5,4)
(2,4)
(5,7)
000
000
000
000
000
000
000
000
000
111
111
111
111
111
111
111
111
111
(6,7)
(6,4)
(5,4)
(5,7)
000
000
000
000
000
000
000
000
000
111
111
111
111
111
111
111
111
111
(7,7)
(6,7)
(6,4)
(7,4)
00000000
00000000
00000000
00000000
00000000
00000000
11111111
11111111
11111111
11111111
11111111
11111111
(5,4)
(5,3)
(2,4)
(2,3)
00000
00000
00000
00000
11111
11111
11111
11111
(7,4)
(5,4)
(5,3)
(7,3)
00
00
00
00
00
11
11
11
11
11
Servidor C
00
00
00
11
11
11
Servidor B
00
00
00
11
11
11
Servidor A
Figura3.6: Fragmentosdaonsulta. Oresultadodoproessoéumonjuntodefragmentos
daonsultaque podemserrepassados individualmente àsfontes dedados.
Na Figura3.6é possívelobservar queumdosseisfragmentos daonsulta possuimaisde
uma fonte de dados em sua lista (servidores
A
eB
). Como já menionado, esse fenmenoindia a presença de repliação de intervalos de dadosdentre asfontes de dados. O sistema
pode se beneiar dessa informação para busar um melhor desempenho no provimento de
dadospara asapliações lientes. Deposse de umalista de fontes de dadosaptas a atender
auma requisição por intervalo de dados e om informações instantâneas sobre a apaidade
deadaumdessesservidoresproverosdadosrequisitados, épossívelesalonarosfragmentos
daonsultadeformaafavoreerodesempenho,deaordoomumamétriapré-estabeleida.
proes-samento deonsultas, omo mostraa Figura3.4 . A Seção3.3 propõealguns meanismos de
esalonamento paraessem.
Todasas disussõese resultados apresentados neste trabalho se referem a abstrações
bi-dimensionais dos intervalos de dados e onsultas, omo em uma porção de uma imagem
visualizada utilizandooMirosópio Virtual[Ferreira et alia(1997 )℄. Algumasapliações
po-dem demandar maisdimensõespara representarseus meta-dados eonsultas. Osalgoritmos
utilizados podem ser failmente generalizados para lidar om mais de duas dimensões.
Na-turalmente, adiionar dimensões ao proessamento de onsultas e indexação de meta-dados
proporionaráumimpatonegativonotempodeexeuçãodosalgoritmos. Otempode
exeu-çãodeambososproessosédaordemde
O(p
2
v
2
)
,parap
representandoonúmerodepoliedrose
v
representandoonúmeromédiode vértiesporpoliedro. Oaumentono númerodedimen-sõesaarretaumaumentosigniativode
v
. Maisespeiamentenoasodaimplementaçãoutilizada neste trabalho (que selimita apolígonosretos), o aumento de dimensõesdobra
v
.3.3 Esalonamento de Consultas
Esta seção apresenta os algoritmos desenvolvidos para guiar o proessador de onsultas na
esolhadequalfonte dedadosseráresponsávelporserviradafragmentodaonsulta,gerado
através de operações geométrias entre o índie global e a onsulta por intervalos de dados.
Naturalmente,osalgoritmosdeesalonamentodeonsultasapenasseapliamaosfragmentos
de onsultaqueestão repliadosentreosservidores e,onseqüentemente,podemserservidos
por maisde umservidor.
Parans deomparação, osseguintesalgoritmos básios[Diniz et alia(2006 )℄serão
utili-zados:
Aleatório (AL): seleiona aleatoriamente o servidor responsável por atender a um
frag-mento de onsulta. Asprinipaislimitaçõesdesse algoritmo sãonãoonsiderar aarga
imposta aos servidores em qualquer instante e não onsiderar a apaidade de servir
dados de ada servidor. Esse algoritmo falha em manter um balaneamento de arga
quando osservidoressão heterogêneos.
Round-RobinPonderado (RRP): ada servidor possui uma la de requisições, e as
re-quisições são distribuídas proporionalmente entre os servidores, de aordo om sua
apaidade de atender onsultas. Esse algoritmo resulta emummelhorbalaneamento
de arga uma vez que servidores om maior apaidade tendem a ser mais
freqüente-mente seleionados. Apesar desse algoritmo onsiderar a apaidade de ada servidor,
a argainstantânea imposta aosservidoresnão é levada emonsideração.
É interessante onsiderar a apaidade dos servidores no esalonamento de onsultas. O
motivo para isto é que se espera que uma onsulta seja atendida maisrapidamente por um
servidorommaiorapaidadedeproverdados. Noentanto,pormaior quesejaaapaidade
18 Distribuídos
queo seudesempenho no atendimento de onsultas seja inferior ao desempenho que teria o
menosapazdentreosservidores. Comesta motivação, estetrabalho propõe doisalgoritmos
quebusam,atravésde diferentesabordagens,umompromissoentrea apaidade ea arga
instantânea dosservidorespara melhoresalonarasonsultas porintervalos de dados.
Paraque osalgoritmos de esalonamento possamonsiderar aarga instantâneaimposta
aosservidores,esse onheimento deve hegar atéo proessadorde onsultas. Umprotoolo
simplesdenotiaçãouni-direionaléapazdesupriressaneessidadedosistema. Sempreque
umservidoraabardeservirumfragmentodeumaonsulta,eledevenotiaroproessadorde
onsultasdoseunovonúmerodefragmentosdeonsultaspendentes. Onúmerodefragmentos
pendentesemada servidor,assimomoo onheimento préviodaapaidade deserviço dos
servidores, permite ao proessador de onsultas alular a apaidade de serviço disponível
emada um dosservidores. A métria de apaidade disponível
c(s, t)
de umservidors
noinstante
t
é denidaomo:c(s, t) =
C(s)
R(s, t) + 1
(3.1)onde
C(s)
é a apaidade absoluta (ou, não instantânea) do servidors
eR(s, t)
é aquantidade de requisições pendentes no servidor
s
no instantet
. Essa métria é utilizadapelos algoritmosque sãoapresentadosa seguirpararepresentar aarga instantânea imposta
aada servidornosistema. Ao seutilizar estamétria, assume-sequea apaidade absoluta
de um servidor é ompartilhada igualmente no serviço de ada requisição pendente. Por
exemplo,umservidorom apaidade paraprover dadosa 100 Mbps,aloaria 20Mbps para
ada umdos 5fragmentosde onsultaa elesubmetidos.
3.3.1 Esalonamento Baseado em Heurístia Gulosa
Oalgoritmodeesalonamentobaseadoemheurístiagulosa(GUL)utilizaumalógiasimples
para tentar garantir a aloação dos maiores fragmentos de onsulta para os servidores em
melhoresondiçõesparaprovê-los. Aoontráriodosdoisalgoritmosjáitados,essealgoritmo
onsidera não só a apaidade dos servidores para prover os dados omo também a arga
instantâneaimpostaaada servidor. Paratal,oalgoritmo onsidera aapaidadedisponível
dosservidores,omoexpliado aima.
Oalgoritmoreebeomoentradaosfragmentosdaonsultaaseresalonada, assimomo
a apaidade disponível em ada servidor andidato para prover os fragmentos da onsulta.
Combase nessasinformações, oalgoritmo segueosseguintespassos:
1. É riada uma lista om os fragmentos da onsulta. Essa lista é ordenada na ordem
deresente da quantidade dedados requisitadosemada fragmento daonsulta;
2. Uma outra listaé riada, omosservidores andidatos a proverosfragmentos da
on-sulta. Esta lista é ordenada em ordem deresente de apaidade disponível por ada
3. A listadefragmentosda onsultaéperorrida, omeçando pelomaior fragmento. Para
ada fragmento da lista:
a) A listade servidores andidatosé perorrida, omeçando peloservidorom maior
apaidade disponível. A varredura aontee atéque o primeiro servidorque
hos-peda oatual fragmento daonsulta sejaenontrado;
b) Ofragmento da onsultaé atribuídoao servidor;
) Aapaidadedisponíveldoservidorérealuladaealistadeservidoresandidatos
é reordenada, parasermantida naordem deresente deapaidade disponível;
d) Ofragmento da onsultaé esalonadoe removido da lista.
O objetivo do algoritmo é fazer om que o maior fragmento da onsulta sejaesalonado
para omaisrápido entre osservidoresandidatos. Oraioínio por trás desseobjetivo é que
todososfragmentosdeonsultasãoservidossimultaneamenteea onsultasóé atendidapor
ompleto quando o último byte do último fragmento pendente é servido. Quanto maior o
fragmento da onsulta, maior a hane desse ser o último fragmento pendente e portanto,
melhorseriaseessefragmentofosseesalonadoparaaomelhorservidorandidato,emtermos
deapaidade. Omesmoraioínioseapliaaosegundomaiorfragmentodaonsultaeassim
suessivamente.
AFigura 3.7ilustra asdeisõestomadaspelo algoritmo de esalonamento para um
repo-sitório hipotétio. Os dados de entrada para o algoritmo podem ser vistos na Figura3.7(a) .
Nesse repositório hipotétio, a onsultafoi dividida em3 fragmentos omtamanhos
diferen-tes. Os servidores 1, 3 e 4 são andidatos para prover os dados requisitados no fragmento
A da onsulta, enquanto para o fragmento B, os servidores andidatos são1, 2 e 3 e parao
fragmento C, servidores 2,3 e 4. Antesde qualquer fragmento da onsulta seresalonado, a
apaidade disponíveldosservidoreseram: servidores1e 2,100 Mbps;servidor3,50Mbpse
servidor 4,10 Mbps. Supõe-se queosservidores não têm fragmentos de onsultas pendentes
no estado iniial.
Começando pelofragmento A,maior fragmento da onsulta, o algoritmo busa pelo
ser-vidor andidato om maior apaidade disponível para servir o fragmento. A Figura 3.7(b)
mostra queo fragmento A seriaentãoesalonadopara o servidor1. Apósaseleçãodo
servi-dor, ainformaçãodeapaidade disponíveldo servidor1 éatualizada. Éimportantereforçar
que até este instante, o fragmento A seriaservido pelo servidor1 a 100 Mbps, a apaidade
anteriormente disponível. Onovovalorde apaidade disponívelserefere aqual seriaataxa
de serviço, por fragmento, asoumnovo fragmento da onsulta sejaaloado parao servidor
1.
Em seguida (Figura 3.7() ), o algoritmo segue para o segundo maior fragmento, o
frag-mento B,parao qual a melhoropção deesalonamento éo servidor2. Uma vez esalonado,