Universidade Federal do Rio Grande do Norte
Centro de Ciˆencias Exatas e da Terra
Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica
H´
erica Priscila de Ara´
ujo Carneiro
Testes de Hip´
oteses em Modelos de Sobrevivˆ
encia
com Fra¸c˜
ao de Cura
H´erica Priscila de Ara´
ujo Carneiro
Testes de Hip´
oteses em Modelos de Sobrevivˆ
encia
com Fra¸c˜
ao de Cura
Trabalho apresentado ao Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Orientadora:
Prof
a. Dr
a. Dione Maria Valen¸ca
Co-orientadora:
Prof
a. Dr
a. Silvia L. P. Ferrari
!
" #$ % &'
( )* + + , , + - #$
% &' . " /01/ 22 - 3
4 3 -5 6 5 6 7 8
. 3 -5 6 5 , 9
6 :7 ; ! , <
+ * .< + 7 += %)
>
1 % = , , ! 6 / ! 6 ?
! 6 @ 7 A ! 6 B 7 - !
6 8 " 6 7 " , 9 >
H´erica Priscila de Ara´
ujo Carneiro
Testes de Hip´
oteses em Modelos de Sobrevivˆ
encia
com Fra¸c˜
ao de Cura
Trabalho apresentado ao Programa de P´ os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Aprovado em: / /
Banca Examinadora:
Profa
. Dra
. Dione Maria Valen¸ca Departamento de Estat´ıstica - CCET/UFRN
Orientadora
Profa. Dra. Silvia L. P. Ferrari
Departamento de Estat´ıstica - IME/USP Co-orientadora
Prof. Dr. Bernardo Borba de Andrade Departamento de Estat´ıstica - CCET/UFRN
Examinador Interno Prof. Dr. Gauss M. Cordeiro
Dedicat´
oria
`
A Trindade Santa.
Agradecimentos
Ao divino amigo, Jesus Cristo, que sempre me impulsiona a prosseguir na caminhada mesmo quando tudo me parece imposs´ıvel.
`
A minha fam´ılia, em especial `a minha m˜ae, Ribˆania, por todo o amor, apoio e dedica¸c˜ao. Ao meu pai, Ary Carneiro Sobrinho (in memoriam), pelo verdadeiro amor de pai que dedicou a mim. `A minha querida irm˜a, Cris, pelas palavras de for¸ca e incentivo e `a minha av´o pelas ora¸c˜oes e exemplo de mulher guerreira.
`
A professora Dione Maria Valen¸ca, pela orienta¸c˜ao, amizade, dedica¸c˜ao e principal-mente, por ter confiado e acreditado em mim para a realiza¸c˜ao deste trabalho. Sou grata tamb´em pela sua contribui¸c˜ao em minha forma¸c˜ao acadˆemica e pessoal.
`
A professora Silvia L. P. Ferrari, pela co-orienta¸c˜ao e contribui¸c˜ao significativa para o desenvolvimento deste trabalho.
Aos professores Bernardo e Joanlise pelas v´arias sugest˜oes e coment´arios feitas no exame de qualifica¸c˜ao.
Ao professor Gauss Cordeiro pela participa¸c˜ao na banca e pelas sugest˜oes feitas. Aos professores da gradua¸c˜ao, em especial aos professores: Rubens Le˜ao, Jaques, Gabriela, Ronaldo, Viviane, Andr´e Gustavo, Fagner e J´ulia. Obrigada pelo apoio e pela imensa contribui¸c˜ao em minha forma¸c˜ao acadˆemica.
Aos professores do PPGMAE, especialmente `a professora Carla e aos professores Formiga, Pledson e Paulo pelos primeiros ensinamentos estat´ısticos.
`
As professoras Jeanete e Ivone pela torcida e amizade.
Aos amigos Mois´es, Hermes, Alysson e Ivanildo pelas dicas e ajudas com as progra-ma¸c˜oes.
Aos colegas do PPGMAE n˜ao s´o da minha turma (Mariana, C´atia, Elvis, Paulinho, Thiago Jefferson, Carlos e Solange), mas tamb´em das turmas anteriores e das turmas mais recentes, foi um prazer conhece-los!
Ao amigo Alex pelas boas gargalhadas que nos fez dar mesmo nos momentos mais “tensos” (v´esperas de provas! Rsr).
Enfim, a todas as amizades que fiz na academia ao longo desses seis anos, em especial aos amigos da minha turma de gradua¸c˜ao em matem´atica de 2006 por tudo que vivemos.
Aos funcion´arios do CCET: Alderi, Val´eria, Liandra, Severino e especialmente ao
Russinho (meu primo! Rsr).
Ao Paulinho por toda paciˆencia, incentivo e apoio nos momentos dif´ıceis.
`
A CAPES pelo apoio financeiro.
”Deus nos fez perfeitos e n˜ao escolhe os capacitados, capacita os escolhidos. Fazer ou n˜ao fazer algo s´o depende de nossa vontade e perseveran¸ca.”
Resumo
Modelos de sobrevivˆencia tratam do estudo do tempo at´e a ocorrˆencia de um evento. Contudo em algumas situa¸c˜oes, uma propor¸c˜ao da popula¸c˜ao pode n˜ao estar mais su-jeita a ocorrˆencia deste evento. Modelos que tratam desta abordagem s˜ao chamados de modelos de fra¸c˜ao de cura. Existem poucos estudos na literatura sobre testes de hip´oteses aplicados a modelos de fra¸c˜ao de cura. Recentemente foi proposta uma nova estat´ıstica de teste, denominada estat´ıstica gradiente que possui distribui¸c˜ao assint´otica equivalente a das estat´ısticas usuais. Alguns estudos de simula¸c˜ao vˆem sendo desenvol-vidos no sentido de explorar caracter´ısticas dessa nova estat´ıstica e comparar com as estat´ısticas cl´assicas, aplicadas a diferentes modelos. Este trabalho tem como principal objetivo estudar e comparar o desempenho do teste gradiente e do teste da raz˜ao de ve-rossimilhan¸cas, em modelos de fra¸c˜ao de cura. Para isso descrevemos caracter´ısticas do modelo e apresentamos os principais resultados assint´oticos dos testes. Consideramos um estudo de simula¸c˜ao com base no modelo de tempo de promo¸c˜ao com distribui¸c˜ao Weibull, para avaliar o desempenho dos testes em amostras finitas. Uma aplica¸c˜ao ´e realizada para ilustrar os conceitos estudados.
Palavras-chave: An´alise de sobrevivˆencia; Fra¸c˜ao de cura; Modelo unificado; Teste Gradiente.
Abstract
Survival models deals with the modeling of time to event data. However in some situations part of the population may be no longer subject to the event. Models that take this fact into account are called cure rate models. There are few studies about hypothesis tests in cure rate models. Recently a new test statistic, the gradient statistic, has been proposed. It shares the same asymptotic properties with the classic large sample tests, the likelihood ratio, score and Wald tests. Some simulation studies have been carried out to explore the behavior of the gradient statistic in finite samples and compare it with the classic statistics in different models. The main objective of this work is to study and compare the performance of gradient test and likelihood ratio test in cure rate models. We first describe the models and present the main asymptotic properties of the tests. We perform a simulation study based on the promotion time model with Weibull distribution to assess the performance of the tests in finite samples. An application is presented to illustrate the studied concepts.
Keywords: Survival analysis; Cure rate; Unified model; Gradient test.
Sum´
ario
1 Introdu¸c˜ao 1
Objetivos . . . 2
Organiza¸c˜ao dos Cap´ıtulos . . . 2
2 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura: Abordagem Unifi-cada 4 Introdu¸c˜ao `a An´alise de Sobrevivˆencia . . . 4
Modelos Param´etricos . . . 6
Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura . . . 7
Modelo Unificado . . . 8
Verossimilhan¸ca para o Modelo Unificado . . . 11
3 Testes Cl´assicos e o Teste Gradiente 14 Descri¸c˜ao dos Testes . . . 14
Testes para Hip´otese Simples . . . 16
Testes para Hip´otese Composta . . . 17
Interpreta¸c˜ao Geom´etrica dos Testes . . . 19
Testes para Grandes Amostras e Modelos de Sobrevivˆencia . . . 23
Testes para o Modelo de Tempo de Promo¸c˜ao Weibull . . . 24
4 Estudo de Simula¸c˜ao 27 Obten¸c˜ao dos Dados Simulados . . . 27
Realiza¸c˜ao dos Testes . . . 28
Resultados . . . 29
5 Aplica¸c˜ao 37 Introdu¸c˜ao . . . 37
Descri¸c˜ao das Covari´aveis . . . 38
6 Considera¸c˜oes Finais e Estudos Futuros 42
Conclus˜oes . . . 42
Pesquisas Futuras . . . 43
A Obten¸c˜ao da Fun¸c˜ao de Verossimilhan¸ca 44 Verossimilhan¸ca . . . 44
Verossimilhan¸ca Marginal . . . 47
B Aspectos Computacionais 48 Caso p=3 . . . 48
Caso p=4 . . . 56
Caso p=5 . . . 63
Aplica¸c˜ao . . . 71
Cap´ıtulo 1
Introdu¸c˜
ao
Modelos de sobrevivˆencia tratam do estudo do tempo at´e a ocorrˆencia de determi-nado evento (morte de um paciente, falha de um item, entre outros). Na literatura este tempo ´e conhecido como tempo de vida, de sobrevivˆencia, ou ainda, tempo at´e a falha. Os modelos usuais de sobrevivˆencia consideram que ´e poss´ıvel observar o evento de interesse em todos os indiv´ıduos no estudo, desde que o tempo de acompanhamento seja suficiente. Contudo em algumas situa¸c˜oes, uma propor¸c˜ao da popula¸c˜ao pode n˜ao estar mais sujeita a ocorrˆencia deste evento e, por mais longo que seja o tempo de ob-serva¸c˜ao, o evento nunca ocorrer´a para esta parte da popula¸c˜ao. Modelos que tratam desta abordagem s˜ao chamados de modelos de fra¸c˜ao de cura ou de longa dura¸c˜ao (long term).
Os modelos com fra¸c˜ao de cura mais populares s˜ao o modelo de mistura padr˜ao (Berkson e Gage, 1952)[2] e omodelo de tempo de promo¸c˜ao (Yakovlev et al., 1993)[35]. A id´eia de utilizar modelos de mistura na an´alise de dados de sobrevivˆencia com fra¸c˜ao de cura foi dada inicialmente por Boag (1949)[3] e desenvolvida logo depois por Berkson e Gage (1952)[2]. Este modelo consiste na mistura de duas distribui¸c˜oes: uma represen-tando a sobrevivˆencia dos indiv´ıduos n˜ao curados a outra uma distribui¸c˜ao degenerada que permite tempos infinitos para os indiv´ıduos curados. Um modelo alternativo foi proposto por Yakovlev et al. (1993)[35], estendido por Chen et al. (1999)[7] e referido em Rodrigues et al. (2008)[30] comomodelo de tempo de promo¸c˜ao. Este modelo possui uma estrutura de riscos competitivos, caracter´ıstica desej´avel em dados de sobrevivˆen-cia. Um modelo mais gen´erico que inclui estes dois modelos como casos especiais foi proposto por Rodrigues et al. (2009)[31].
Neste trabalho, o interesse encontra-se em testar hip´oteses sobre parˆametros de modelos de sobrevivˆencia com fra¸c˜ao de cura. A maioria dos testes de hip´oteses, em problemas envolvendo grandes amostras, s˜ao baseados nas estat´ısticas da raz˜ao de
1.0 Objetivos 2
rossimilhan¸cas (Wilks, 1938)[34], Wald (Wald, 1943)[33] ou escore (Rao, 1948)[27]. No entanto, recentemente uma nova estat´ıstica de teste foi proposta por Terrell (2002)[32], denominada estat´ıstica gradiente. Esta, assim como as estat´ısticas usuais, possui as-sintoticamente uma distribui¸c˜ao qui-quadrado. A nova estat´ıstica foi obtida a par-tir da estat´ıstica escore de Rao e da estat´ıstica do teste de Wald modificada (ver Hayakawa, 1985; Lemonte, 2010)[15, 18]. Em seu artigo, Rao (2005)[28] comenta sobre a simplicidade do c´alculo e importˆancia do estudo de tal estat´ıstica. Com base nesse coment´ario, alguns estudos vˆem sendo realizados em Lemonte e Ferrari (2011,a,b,2012,a,b)[19, 20, 21, 22] no sentido de explorar caracter´ısticas desta nova es-tat´ıstica e comparar com as cl´assicas, aplicadas a diferentes modelos. Os estudos de simula¸c˜ao mostram que o teste da raz˜ao de verossimilhan¸cas tende a ser muito liberal em amostras pequenas ou mesmo de tamanho moderado. Em outras palavras, este teste tende a ter probabilidade de erro de tipo I maior que o n´ıvel nominal adotado. O teste gradiente, por outro lado, tende a ter probabilidade de erro de tipo I mais pr´oxima do n´ıvel nominal.
Objetivos
Tendo em vista o desempenho superior que o teste gradiente tem mostrado em amos-tras pequenas com rela¸c˜ao ao teste da raz˜ao de verossimilhan¸cas nos estudos desenvol-vidos por Lemonte e Ferrari (2011)[20] mesmo quando se considera dados censurados, e considerando a simplicidade de c´alculo da estat´ıstica da raz˜ao de verossimilhan¸cas e ainda o fato de n˜ao termos encontrado na literatura nenhum estudo de simula¸c˜ao, en-volvendo o teste gradiente nem mesmo o teste da raz˜ao de verossimilhan¸cas em modelos com fra¸c˜ao de cura, o presente trabalho tem por objetivo estudar o desempenho dos mesmos e compar´a-los, via estudo de simula¸c˜ao, considerando a abordagem unificada proposta em Rodrigues et al. (2009)[31] no caso particular do modelo de tempo de promo¸c˜ao.
Organiza¸c˜
ao dos Cap´ıtulos
1.0 Organiza¸c˜ao dos Cap´ıtulos 3
Cap´ıtulo 2
Modelos de Sobrevivˆ
encia com
Fra¸c˜
ao de Cura: Abordagem
Unificada
Neste cap´ıtulo fazemos uma breve introdu¸c˜ao aos principais conceitos de an´alise de sobrevivˆencia e aos modelos de sobrevivˆencia com fra¸c˜ao de cura, levando em conta a abordagem unificada introduzida por Rodrigues et al. (2009)[31].
Introdu¸c˜
ao `
a An´
alise de Sobrevivˆ
encia
A an´alise de sobrevivˆencia consiste em um conjunto de t´ecnicas estat´ısticas utili-zadas para analisar dados em estudos em que a vari´avel resposta representa o tempo at´e a ocorrˆencia de um evento de interesse, por exemplo, o tempo at´e a morte de um paciente, o tempo at´e a recidiva de um tumor, ou ainda o tempo at´e uma lˆampada queimar. Na literatura esse tempo ´e geralmente denominado como tempo de vida. Podem-se encontrar aplica¸c˜oes da an´alise de sobrevivˆencia em diversas ´areas do conhecimento, por exemplo, na engenharia, onde recebe o nome de “confiabilidade”, em que o interesse est´a no estudo do tempo at´e a falha de equipamentos, ou na criminologia, onde o interesse pode ser a avalia¸c˜ao do tempo at´e um ex-detento reincidir no crime, ou ainda no ˆambito empresarial onde se deseja estudar o tempo at´e a falˆencia de uma empresa, entre outras ocorrˆencias.
ConsidereT uma vari´avel aleat´oria cont´ınua e n˜ao negativa representando o tempo at´e a ocorrˆencia de um evento, sendof(t) sua fun¸c˜ao densidade de probabilidade eF(t) sua fun¸c˜ao de distribui¸c˜ao acumulada. Para analisar dados de sobrevivˆencia relaciona-dos a esta vari´avel, duas fun¸c˜oes s˜ao usadas frequentemente, a fun¸c˜ao de sobrevivˆencia
2.0 Introdu¸c˜ao `a An´alise de Sobrevivˆencia 5
e a fun¸c˜ao de taxa de falha (ou risco). As mesmas s˜ao apresentadas a seguir.
i) Fun¸c˜ao de Sobrevivˆencia
A fun¸c˜ao de sobrevivˆencia para a vari´avel aleat´oria T (mencionada anteriormente) ´e definida como,
S(t) =P(T > t) =
Z ∞
t
f(u)du= 1−F(t), para t >0. (2.1)
Note que S(t) ´e mon´otona decrescente e tem as seguintes propriedades: (i) S(0) = 1;
(ii) limt→∞S(t) = 0.
Fun¸c˜oes de sobrevivˆencia que n˜ao satisfazem `a propriedade (ii) s˜ao denominadas fun¸c˜oes impr´oprias ou com fra¸c˜ao de cura, ou ainda de longa dura¸c˜ao (Rodrigues et al., 2009)[31].
ii) Fun¸c˜ao Taxa de Falha ou Fun¸c˜ao Risco
A fun¸c˜ao taxa de falha ou fun¸c˜ao risco, denotada por h(t) ´e definida como,
h(t) = lim
∆t→0+
P(t < T ≤t+ ∆t|T > t)
∆t . (2.2)
Pode-se mostrar que
h(t)≥0 e
Z ∞
0
h(t)dt=∞.
A fun¸c˜ao risco especifica a taxa de falha instantˆanea a um tempo t, dado que o indiv´ıduo sobreviveu at´e o tempot.
Rela¸c˜oes entre as Fun¸c˜oes
Para a vari´avel aleat´oriaT cont´ınua e n˜ao negativa, tem-se, em termos das defini¸c˜oes (2.1) e (2.2) dadas anteriormente, algumas rela¸c˜oes matem´aticas entre as fun¸c˜oesf(t),
S(t) e h(t):
h(t) = f(t)
S(t) =−
dlog(S(t))
dt ; (2.3)
f(t) =−dS(t)
2.0 Introdu¸c˜ao `a An´alise de Sobrevivˆencia 6
Assim, o conhecimento de uma dessas fun¸c˜oes leva ao conhecimento das demais.
Censura
Uma caracter´ıstica marcante em dados de sobrevivˆencia ´e a presen¸ca de censura, que ´e a observa¸c˜ao parcial da resposta (tempo at´e a falha), e ocorre quando algum acon-tecimento impede que o tempo at´e a ocorrˆencia do evento de interesse seja observado em todos os indiv´ıduos. Por exemplo, alguns pacientes podem desistir do tratamento ou morrer por uma causa diferente da estudada, ou o estudo pode acabar antes que o evento ocorra para todos os pacientes. Nestes casos o que se sabe ´e que o tempo de vida ´e maior que o tempo observado.
Existem v´arios mecanismos de censura, dentre os quais podemos citar a censura ale-at´oria que ´e a mais frequente na pr´atica e caracteriza-se pela ocorrˆencia de interrup¸c˜oes aleat´orias no acompanhamento dos indiv´ıduos (por exemplo, a perda de acompanha-mento do paciente que se mudou ou que morreu por outra causa). Neste caso os tempos de censuras tamb´em s˜ao representados por vari´aveis aleat´orias. Quando a distribui¸c˜ao da censura n˜ao envolve parˆametros de interesse ao estudo, dizemos que a censura ´e n˜ao informativa.
Censura `a Direita
Este mecanismo de censura caracteriza-se pelo fato, do tempo de ocorrˆencia do evento de interesse est´a `a direita do tempo registrado, ou seja, a falha ocorre ap´os o in´ıcio do estudo. Outras duas formas de censura podem ocorrer: censura `a esquerda e censura intervalar, por´em, estas n˜ao ser˜ao consideradas neste trabalho. Por este motivo, as mesmas n˜ao s˜ao definidas.
Modelos Param´
etricos
Distribui¸c˜ao Weibull
A fun¸c˜ao densidade de probabilidade para a vari´avel aleat´oria tempo de falha T
com distribui¸c˜ao Weibull ´e dada por
f(t) = a
bat a−1
exp
−
t b
a
, para t≥0, (2.5)
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 7
Podemos usar (2.1) e (2.3) para obter as fun¸c˜oes de sobrevivˆencia e de risco dadas respectivamente por
S(t) = exp
− t b a
e h(t) = a
bat a−1
. (2.6)
Distribui¸c˜ao de Valor Extremo
Uma distribui¸c˜ao que ´e bastante relacionada `a distribui¸c˜ao Weibull ´e a distribui¸c˜ao valor extremo (ou Gumbel). SeT tem distribui¸c˜aoW eibull(a, b) ent˜aoY = log(T) tem distribui¸c˜ao valor extremo com parˆametros µ = log(b) e σ = a−1
e fun¸c˜ao densidade de probabilidade dada por
f(y) = 1
σexp
y−µ σ
−exp
y−µ σ
, (2.7)
em que y e µ ∈ ℜ e σ > 0. Os parˆametros µ e σ s˜ao parˆametros de posi¸c˜ao e escala respectivamente.
Modelos de Sobrevivˆ
encia com Fra¸c˜
ao de Cura
Nos modelos usuais de an´alise de sobrevivˆencia, sup˜oe-se que o evento de interesse pode ser observado em todos os indiv´ıduos, desde que o tempo de acompanhamento seja suficientemente grande. No entanto, existem situa¸c˜oes em que o evento de interesse pode n˜ao ocorrer para todos os indiv´ıduos. Por exemplo, se o evento de interesse ´e a recidiva de uma doen¸ca, pode ser que uma parte da popula¸c˜ao esteja curada e n˜ao apresente o retorno da doen¸ca (a recidiva). Se o interesse ´e o tempo at´e um ex-presidi´ario reincidir no crime, podem existir criminosos reabilitados que n˜ao tornar˜ao a cometer crimes. Estes indiv´ıduos s˜ao considerados imunes ao evento de interesse e dizemos que o conjunto de dados referente a eles possui uma fra¸c˜ao de cura (ou de curados).
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 8
um intervalo de tempo razo´avel, caracterizando uma fun¸c˜ao de sobrevivˆencia impr´opria (fun¸c˜ao que n˜ao tende a zero `a medida que o tempo cresce).
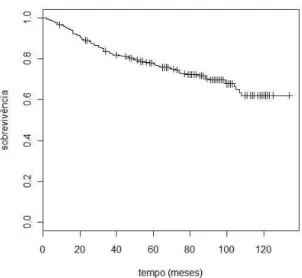
Figura 2.1: Kaplan-Meier dos dados referentes ao tempo at´e a recidiva do cˆancer de mama.
A Figura 2.1 mostra a curva de sobrevivˆencia estimada para um conjunto de da-dos, referente ao tempo at´e a recidiva do cˆancer de mama em pacientes que passaram por determinados tratamentos. Observa-se que, a medida que o tempo passa o gr´afico permanece em um valor bem acima do zero por um per´ıodo de tempo consider´avel. Isto caracteriza o comportamento de uma fun¸c˜ao de sobrevivˆencia impr´opria e acon-tece por causa do grande n´umero de observa¸c˜oes censuradas ao fim do estudo. Este comportamento parece indicar a existˆencia de indiv´ıduos imunes na popula¸c˜ao.
Modelo Unificado
O modelo unificado ´e uma extens˜ao do modelo de Chen et al. (1999)[7] e possui como casos particulares os principais modelos de longa dura¸c˜ao. A especifica¸c˜ao desta unifica¸c˜ao ´e dada a seguir.
Fun¸c˜ao de Sobrevivˆencia de Longa Dura¸c˜ao
Suponha que existam n indiv´ıduos em um determinado estudo e que associadas a um indiv´ıduo est˜ao as seguintes vari´aveis aleat´orias:
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 9
evento de interesse; com distribui¸c˜ao de probabilidade pm =Pθ(M =m), sendo
θ o parˆametro da distribui¸c˜ao;
• Zk ≡ tempo at´e a ocorrˆencia do evento devido `a k-´esima causa. Dado M = m
temos que Z1, Z2, . . . , Zm s˜ao vari´aveis aleat´orias i.i.d. (independentes e
identi-camente distribu´ıdas) e independentes de M, com fun¸c˜ao de distribui¸c˜ao comum
F(t) = 1−S(t);
• T ≡ tempo at´e a ocorrˆencia do evento, definido como
T =min{Z0, Z1, . . . , Zm},
sendo que P(Z0 = ∞) = 1, pois quando M = 0 n˜ao existem causas ou riscos
para a ocorrˆencia do evento, ou seja, esta suposi¸c˜ao permite a ocorrˆencia de um “tempo de vida infinito” para os indiv´ıduos imunes.
As vari´aveis aleat´oriasZk eM s˜ao vari´aveis latentes, enquanto a vari´avel aleat´oria
T ´e uma vari´avel observ´avel. Para este modelo a fun¸c˜ao de sobrevivˆencia ´e dada por:
Sp(t) = P(T > t)
= P(T > t, M = 0) +P(T > t, M ≥1)
= P(T > t|M = 0)P(M = 0) +P(T > t|M ≥1)P(M ≥1) = p0+
∞
X
m=1
pmS(t)m, (2.8)
em que, P(T > t|M = 0) = 1 e P(M = 0) = p0. A fun¸c˜ao de sobrevivˆencia S(t), dos
indiv´ıduos em risco, ´e uma fun¸c˜ao de sobrevivˆencia pr´opria, isto ´e, limt7→∞S(t) = 0,
sendo assim a fun¸c˜ao de sobrevivˆenciaSp(t) ´e uma fun¸c˜ao de sobrevivˆencia impr´opria,
ou seja, limt7→∞Sp(t)>0.
A fun¸c˜ao de sobrevivˆencia de longa dura¸c˜ao, Sp(t), pode ser interpretada como
uma combina¸c˜ao linear infinita de distribui¸c˜oes Lehmann tipo II (Rodrigues et al., 2011; Alexander et al., 2012)[29, 1].
A fra¸c˜ao de cura ´e definida da seguinte forma (Rodrigues et al., 2009)[31],
lim
t7→∞Sp(t) = p0 =P(M = 0), (2.9)
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 10
A fun¸c˜ao de sobrevivˆencia (2.8) pode ser escrita como,
Sp(t) = p0+ (1−p0)S
∗
p(t), (2.10)
sendoS∗
p(t) = P∞
m=1p
∗
mS(t)m e p
∗
m=
pm
1−p0
.
As fun¸c˜oes de densidade e de risco para a vari´avel aleat´oriaT podem ser derivadas das rela¸c˜oes (2.3) e (2.4), suas formas s˜ao dadas por
fp(t) =f(t)
∞
X
m=1
mpm[S(t)] m−1
e hp(t) =
fp(t)
Sp(t)
. (2.11)
Uma breve apresenta¸c˜ao dos principais casos particulares do modelo unificado ´e feita a seguir.
Modelo de Mistura
Se a vari´avel aleat´oria M segue uma distribui¸c˜ao Bernoulli com parˆametro (1−θ) o modelo de sobrevivˆencia de longa dura¸c˜ao (2.10) resume-se ao modelo de mistura padr˜ao (Berkson e Gage, 1952)[2] dado por
Sp(t) =θ+ (1−θ)S(t) (2.12)
em que θ=Pθ(M = 0) =p0 e S(t) =P(T > t|M ≥1) ´e uma fun¸c˜ao de sobrevivˆencia
pr´opria. Consequentemente,Sp(t) ´e uma fun¸c˜ao de sobrevivˆencia impr´opria, isto ´e,
lim
t7→∞Sp(t) =θ > 0, (2.13)
em queθ =Pθ(M = 0) representa a fra¸c˜ao de cura, induzida pelo modelo. As fun¸c˜oes
de densidade e de risco s˜ao dadas por
fp(t) = (1−θ)f(t) e hp(t) =f(t)
(1−θ)
θ+ (1−θ)S(t). (2.14) Modelo de Tempo de Promo¸c˜ao
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 11
Chen et al., 1999)[35, 7]. De (2.10) segue
Sp(t) = exp{−θ[1−S(t)]}, (2.15)
em queS(t), a fun¸c˜ao de sobrevivˆencia dos tempos Zk,k = 1, . . . , M, ´e uma fun¸c˜ao de
sobrevivˆencia pr´opria, isto ´e, limt7→∞S(t) = 0. Logo,
lim
t7→∞Sp(t) = exp (−θ), (2.16)
ou seja,Sp(t) ´e uma fun¸c˜ao de sobrevivˆencia impr´opria e a fra¸c˜ao de cura induzida pelo
modelo ´ep0 = exp (−θ). As fun¸c˜oes de densidade e de risco s˜ao dadas por
fp(t) = θf(t) exp (−θF(t)) e hp(t) = θf(t). (2.17)
Verossimilhan¸ca para o Modelo Unificado
Para derivar a fun¸c˜ao de verossimilhan¸ca do modelo unificado, considere ainda
Yi = min{Ti, Ci} o tempo observado para o indiv´ıduo i, que pode ser censurado `a
direita, sendo Ti = min{Zi0, Zi1, . . . , Zimi}, Ci o tempo de censura (aleat´oria e n˜ao
informativa) independente de Ti e δi o indicador de censura, sendo δi = 1 se Yi =Ti e
δi = 0 seYi =Ci. DadoMi =mi, as vari´aveisZi1, Zi2, . . . , Zimi s˜aoi.i.d.e representam
o tempo que cada causa noi-´esimo indiv´ıduo leva para provocar o evento de interesse, todas com fun¸c˜ao de distribui¸c˜aoF(z|λ) e fun¸c˜ao de sobrevivˆenciaS(z|λ) = 1−F(z|λ). Seja pθi(mi) = Pθi(Mi = mi) a fun¸c˜ao de probabilidade de Mi. Considere tamb´em
xi = (xi1, xi2, . . . , xip)
′
o vetor de covari´aveis associado ao i-´esimo indiv´ıduo e X uma matrizn por p que cont´em esses vetores.
Dessa forma, tˆem-se os seguintes vetores
y = y1 y2 ... yn , δ = δ1 δ2 ... δn , M= M1 M2 ... Mn
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 12 X = x′ 1 x′ 2 ... x′ n .
Denotamos o conjunto dos dados completos por Dc = (n,y,δ,M,X) e os dados
observ´aveis (n˜ao inclui as vari´aveis latentes) por D = (n,y,δ,X). As covari´aveis s˜ao inclu´ıdas no modelo atrav´es do parˆametro de cura, θ, por meio de alguma rela¸c˜ao
θ ≡ θ(x′β), sendo β ´e um vetor de parˆametros de regress˜ao correspondente `a x.
Considere que as covari´aveis s˜ao inclu´ıdas no modelo atrav´es do parˆametro associado `a distribui¸c˜ao deMi. Dessa forma tem-se um parˆametro θi diferente associado a cada
indiv´ıduoi, i= 1,2, . . . , n.
Neste caso, denotamos a fun¸c˜ao de probabilidade deMi como
pθi(mi) =Pθi(Mi =mi), (2.18)
em quepθi(0) representa a fra¸c˜ao de cura.
A rela¸c˜ao geralmente usada para relacionar o parˆametro θi com as covari´aveis no
modelo de mistura padr˜ao ´e dada pelo modelo log´ıstico (ver por exemplo Maller e Zhou, 1996)[24],
θi =
exp x′iβ
1 + exp x′iβ
. (2.19)
Note que, neste caso a fra¸c˜ao de cura tamb´em fica relacionada com as covari´aveis atrav´es da express˜ao (2.19) uma vez que pθi(0) =Pθi(Mi = 0) =θi.
Quando se trata do modelo de tempo de promo¸c˜ao em geral a rela¸c˜ao assumida entre as covari´aveis e θi ´e da forma
θi = exp
x′iβ
. (2.20)
A fra¸c˜ao de cura ´e ent˜ao dada por
pθi(0) = exp h
−expx′iβ
i
. (2.21)
Seja φ = (β′,λ′)′
2.0 Modelos de Sobrevivˆencia com Fra¸c˜ao de Cura 13
Apˆendice A) que a fun¸c˜ao de verossimilhan¸ca de φ correspondente ao conjunto dos dados completosDc ´e dada por
L(φ;Dc) = n Y
i=1
[mif(yi|λ)] δi[S(y
i|λ)] mi−δip
θi(mi). (2.22)
Dessa forma o logaritmo da fun¸c˜ao de verossimilhan¸ca ´e dado por
ℓ(φ;Dc) = log(L(φ;Dc))
=
n X
i=1
[δilog(mi) +δilogf(yi|λ) + (mi−δi) logS(yi|λ)]
+
n X
i=1
log (pθi(mi)). (2.23)
Como (2.22) e (2.23) n˜ao s˜ao observ´aveis, j´a que dependem das vari´aveis latentes
Mi, utiliza-se na pr´atica uma verossimilhan¸ca marginal, obtida fazendo o somat´orio
nas vari´aveis Mi. A fun¸c˜ao ent˜ao fica dada por
L∗
(φ;D) =
n Y
i=1
[fp(yi|λ, θ)]δi[Sp(yi|λ, θ)]1
−δi
(2.24)
(ver Apˆendice A.2). Portanto, o logaritmo da fun¸c˜ao de verossimilhan¸ca marginal ´e dado por
ℓ∗
(φ;D) =
n X
i=1
Cap´ıtulo 3
Testes Cl´
assicos e o Teste Gradiente
No cap´ıtulo anterior descrevemos o modelo unificado proposto por Rodrigues et al. (2009)[31] apresentamos os principais casos particulares desse modelo (modelo de mistura e modelo de tempo de promo¸c˜ao) e sua fun¸c˜ao de verossimilhan¸ca. Neste cap´ıtulo apresentamos a forma dos testes da raz˜ao de verossimilhan¸ca, Wald, escore e gradiente, tanto para o caso em que a hip´otese ´e simples quanto para o caso em que ela ´e composta, juntamente com alguns resultados assint´oticos. Apresentamos ainda uma interpreta¸c˜ao geom´etrica dos testes com o objetivo de facilitar a compreens˜ao dos mesmos e fazer rela¸c˜ao entre eles. Algumas referˆencias s˜ao fornecidas a fim de garantir a validade dos resultados assint´oticos dos testes para modelos de sobrevivˆencia. Por fim, descrevemos a forma dos testes para o modelo de tempo de promo¸c˜ao Weibull.
Descri¸c˜
ao dos Testes
Considere Y1, Y2, . . . , Yn, uma amostra aleat´oria de uma distribui¸c˜ao com f.d.p
f(·;φ) sendo φ = (φ1, φ2, . . . , φp)T um vetor de parˆametros desconhecidos tomando
valores em Θ. A fun¸c˜ao de verossimilhan¸ca paraφ pode ser escrita como
L(φ) =
n Y
i=1
f(yi;φ). (3.1)
Denotando por ℓ(φ) = logL(φ), o logaritmo da fun¸c˜ao de verossimilhan¸ca, defini-mosU(φ) = ∂
∂φℓ(φ),K(φ) = E
h
U(φ)U(φ)TieJ(φ) respectivamente, o vetor escore, a matriz de informa¸c˜ao de Fisher e a matriz de informa¸c˜ao observada relativas aφ.
Considere que o interesse ´e testar hip´oteses sobre o vetor de parˆametros φ. Os
3.0 Descri¸c˜ao dos Testes 15
testes mais comuns (testes cl´assicos) usados para este fim s˜ao baseados nas estat´ısticas da raz˜ao de verossimilhan¸cas (RV), Wald ou escore, propostas por (Wilks, 1938)[34], (Wald, 1943)[33] e (Rao, 1948)[27], respectivamente. No entanto, uma nova estat´ıs-tica denominadaestat´ıstica gradiente, foi recentemente proposta por Terrell (2002)[32]. Esta estat´ıstica apresenta uma f´ormula mais simples de ser calculada, quando com-parada com as estat´ısticas de Wald e escore, pois n˜ao necessita do c´alculo nem da invers˜ao da matriz de informa¸c˜ao de Fisher. Em seu artigo, Terrell demonstra uma s´erie de propriedades da nova estat´ıstica de teste.
Alguns estudos vˆem sendo realizados por Lemonte e Ferrari (2011,a,b, 2012,a,b)[19, 20, 21, 22] no sentido de explorar caracter´ısticas desta nova estat´ıstica e comparar com as cl´assicas, aplicadas a diferentes modelos. Um trabalho com dimens˜ao te´orica, por exemplo, comparando o poder local do teste gradiente com o poder local dos testes cl´assicos (raz˜ao de verossimilhan¸cas, Wald e escore) ´e desenvolvido em Lemonte e Fer-rari (2012b)[22]. Neste trabalho, verifica-se que o teste gradiente ´e competitivo com rela¸c˜ao aos outros testes, no sentido que nenhum dos testes se apresenta uniforme-mente superior aos demais, quando se considera poder local. Em Lemonte e Ferrari (2011b)[20] ´e realizado um extenso estudo de simula¸c˜ao de Monte Carlo para comparar o desempenho do teste gradiente com o da raz˜ao de verossimilhan¸cas. Na simula¸c˜ao s˜ao consideradas amostras finitas com censura `a direita do tipo II, para testar hip´oteses sobre os dois parˆametros da distribui¸c˜ao Birnbaum- Saunders. O estudo mostra que o teste RV rejeita a hip´otese nula, quando esta ´e verdadeira, com mais frequˆencia que o teste gradiente (isto ´e, o teste RV ´e mais liberal). Algumas aplica¸c˜oes s˜ao apresentadas. Outro estudo de simula¸c˜ao Monte Carlo ´e realizado em Lemonte e Ferrari (2011a)[19] com o objetivo de comparar os quatro testes rivais (RV, Wald, escore e gradiente) tes-tando os parˆametros do modelo de regress˜ao Birnbaum- Saunders em amostras finitas. Conclui-se com o trabalho que o teste escore ou o teste gradiente devem ser escolhidos para realizar inferˆencias sobre os parˆametros do modelo. Uma an´alise an´aloga ´e feita em Lemonte e Ferrari (2012a)[21] considerando a classe dos modelos de dispers˜ao. Em todos esses trabalhos, o poder local de cada um dos testes envolvidos ´e comparado.
3.0 Descri¸c˜ao dos Testes 16
da raz˜ao de verossimilhan¸cas ajustada. As simula¸c˜oes favoreceram esta ´ultima. Nos resultados das simula¸c˜oes considerando a classe de modelos de regress˜ao valor-extremo o teste gradiente obteve desempenho superior ao teste da raz˜ao de verossimilhan¸cas.
A seguir s˜ao apresentados resultados sobre os testes, tanto para o caso em que a hip´otese nula ´e simples, ou seja, define de forma ´unica a distribui¸c˜ao dos dados, quanto para o caso em que ela ´e composta.
Testes para Hip´
otese Simples
No caso em que a hip´otese nula ´e simples o interesse est´a em testar a seguinte hip´otese,
H0 :φ=φ0 versus H1 :φ6=φ0 (3.2)
em queφ0 = (φ10, φ20, . . . , φp0) T
´e um vetor de valores especificados paraφ.
As trˆes estat´ısticas comumente usadas para testar (3.2) s˜ao: a da raz˜ao de verossi-milhan¸cas, dada por
SRV = 2 h
ℓ(φb)−ℓ(φ0) i
, (3.3)
a estat´ıstica de Wald
SW =
b
φ−φ0 T
K(φb)φb−φ0
, (3.4)
e a estat´ıstica escore de Rao
SR= [U(φ0)] T
K(φ0) −1
U(φ0). (3.5)
As formas das estat´ısticas de Wald e escore podem ser deduzidas, respectivamente, dos seguintes resultados (Cordeiro, 1999)[8]:
√
nφb −φ0 D
→Np 0, [k(φ0)] −1
, (3.6)
e
1
√nU(φ0) D
→Np(0, k(φ0)). (3.7)
3.0 Descri¸c˜ao dos Testes 17
Dessa forma, pode-se mostrar que sobH0 e condi¸c˜oes gerais de regularidade (ver
Ca-sella e Berger, 2002, se¸c˜ao 10.3)[6] as trˆes estat´ısticas acima possuem uma distribui¸c˜ao qui-quadrado com pgraus de liberdade.
A hip´otese nulaH0ser´a rejeitada para valores grandes deSRV,SW eSRcomparados
com o quantil de ordem 1−αda distribui¸c˜ao qui-quadrado (neste caso com p graus de liberdade) para um n´ıvel de significˆancia nominal α fixado.
A forma da estat´ıstica gradiente para testar (3.2) ´e dada por
SG =U(φ0)T(φb−φ0). (3.8)
Assim como as estat´ısticas cl´assicas, a estat´ıstica gradiente, SG, possui sob H0 e
condi¸c˜oes gerais de regularidade, uma distribui¸c˜ao aproximadamente qui-quadrado com
pgraus de liberdade (Terrell, 2002)[32].
Testes para Hip´
otese Composta
No caso em que a hip´otese nula ´e composta, ou seja, quando h´a parˆametros de perturba¸c˜ao, o interesse se resume em testar uma hip´otese nula do seguinte tipo:
H0 :φ1 =φ10, φ2 =φ20, . . . , φr=φr0, (3.9)
em quer < p. Para simplificar a nota¸c˜ao defina
λ1 = (φ1, φ2, . . . , φr) T
eλ2 = (φr+1, φr+2, . . . , φp) T
,
de forma que
φ= (λ1,λ2)T e H0 :λ1 =λ10 versus H1 :λ1 6=λ10 (3.10)
sendo λ10 = (φ10, φ20, . . . , φr0) T
. Note que λ1 ´e o vetor parˆametro de interesse e λ2,
um vetor de parˆametros de perturba¸c˜ao.
A parti¸c˜ao do vetor de parˆametrosφ= (λ1,λ2)T induz as seguintes parti¸c˜oes
U(φ) =
"
Uλ1(φ)
Uλ2(φ)
#
, K(φ) =
"
Kλ1λ1(φ) Kλ1λ2(φ)
Kλ2λ1(φ) Kλ2λ2(φ)
#
3.0 Descri¸c˜ao dos Testes 18
K(φ)−1
=
"
Kλ1λ1
(φ) Kλ1λ2 (φ)
Kλ2λ1
(φ) Kλ2λ2 (φ)
#
,
sendoKλ1λ1
=Kλ1λ1 −Kλ1λ2Kλ2λ2
−1
Kλ1λ2T
−1
.
Dessa forma, as estat´ısticas cl´assicas (RV, Wald e escore) para testar (3.10) podem ser escritas respectivamente como
SRV = 2 h
ℓλb1,λb2
−ℓλ10,λ˜2 i
(3.11)
SW = (λb1−λ10)T [K
λ1λ1
(φb)]−1 (λb1−λ10), (3.12)
SR= h
Uλ1(φ˜)
iT
Kλ1λ1(φ˜)U
λ1(φ˜). (3.13)
As formas das estat´ısticas (3.12) e (3.13) s˜ao baseadas, respectivamente, nos se-guintes resultados (Cordeiro, 1999)[8]
√
nλb1−λ10 D
→Nr
0,kλ1λ1(λ
10,λ˜2)
(3.14)
e
1
√nUλ1(φ˜)
D
→Nr(0,[k
λ1λ1 (φ˜)]−1
) (3.15)
sendok a matriz informa¸c˜ao relativa a uma ´unica observa¸c˜ao,K(φ) = nk(φ).
Assim, supondo que a hip´otese nula verdadeira e sob condi¸c˜oes gerais de regula-ridade, temos que as estat´ısticas (3.12) e (3.13) possuem uma distribui¸c˜ao aproxima-damente qui-quadrado com r graus de liberdade. Pode-se mostrar que (3.11) tamb´em possui distribui¸c˜ao aproximadamente qui-quadrado com r graus de liberdade sob H0,
(Wilks, 1938)[34].
A estat´ıstica gradiente neste caso ´e dada por
SG=Uλ1(φ˜)T(λb1−λ10) (3.16)
3.0 Descri¸c˜ao dos Testes 19
com r graus de liberdade, (ver Lemonte, 2010, se¸c˜ao 5.1)[18].
A hip´otese nula H0 ser´a rejeitada, para grandes valores das estat´ısticas (3.11),
(3.12), (3.13) e (3.16) comparados com o quantil de ordem 1−α da distribui¸c˜ao qui-quadrado (neste caso comr graus de liberdade) para um n´ıvel de significˆancia nominal
α fixado.
Interpreta¸c˜
ao Geom´
etrica dos Testes
Nesta se¸c˜ao ´e apresentada uma id´eia geom´etrica dos testes da raz˜ao de verossimi-lhan¸cas (RV), Wald e escore, fundamentada em Buse (1982)[5]. O mesmo ´e feito para o teste gradiente, com fundamento no trabalho de Montoril (2010)[25].
Considere uma situa¸c˜ao simples em que o vetor de parˆametros de interesse ´e formado por um ´unico elemento e o interesse ´e testar as seguintes hip´oteses,
H0 :φ =φ0 versus H1 :φ6=φ0 (3.17)
sendoφ0 um escalar.
i) A estat´ıstica RV neste caso ´e dada por
SRV = 2 h
ℓ(φb)−ℓ(φ0) i
.
A hip´otese nula H0 ´e rejeitada, para valores grandes de SRV comparados com o
valor cr´ıtico obtido da distribui¸c˜ao qui-quadrada (neste caso, χ2
(1)) para um n´ıvel de
significˆancia nominalα fixado.
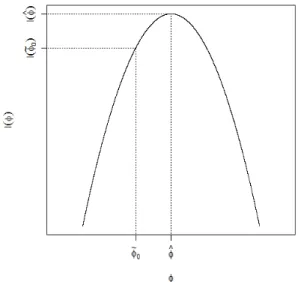
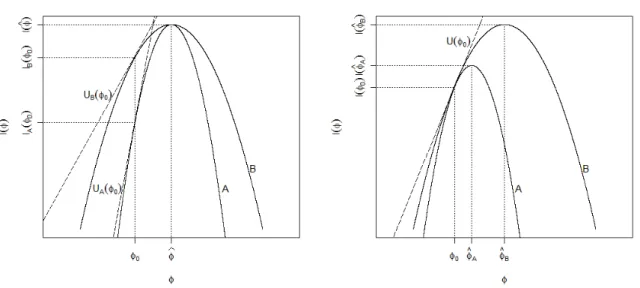
Na Figura 3.1, note que a distˆancia entre as log-verossimilhan¸cas, [ℓ(φb)−ℓ(φ0)],
depende tanto da distˆancia entre φb e φ0 quanto da curvatura da fun¸c˜ao em φb, C(φ)
avaliada emφ=φb, a qual ´e definida por
C(φ) = − d
2
dφ2ℓ(φ).
3.0 Descri¸c˜ao dos Testes 20
(φb− φ0), maior ser´a a distˆancia [ℓ(φb) − ℓ(φ0)] e, portanto, maior ser´a o valor da
estat´ıstica SRV. Por outro lado, para uma distˆancia (φb−φ0) fixa temos que, quanto
maior a curvaturaC(φb) maior ser´a a distˆancia [ℓ(φb)−ℓ(φ0)].
Figura 3.1: Teste da raz˜ao de verossimilhan¸ca
ii) A equa¸c˜ao da estat´ıstica Wald neste caso ´e dada por
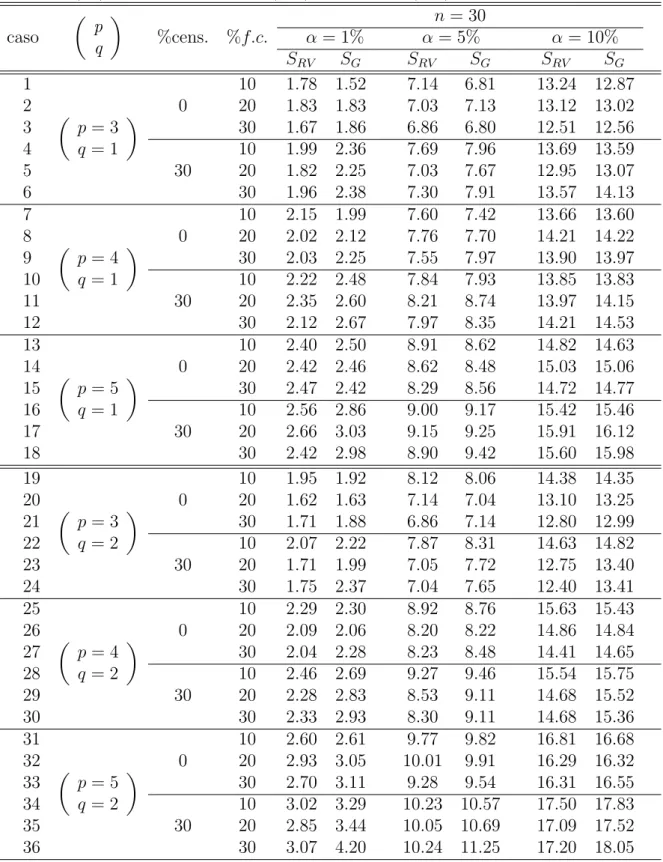
SW = (φb−φ0)2I(φb).
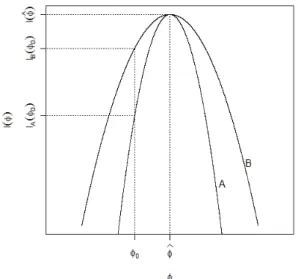
Intuitivamente, seH0 em (3.17) ´e falsa esperamos queφ0esteja distante deφb. Como
podemos ver na f´ormula da estat´ıstica de Wald, essa distˆancia ´e considerada atrav´es de (φb−φ0)2. Note que a estat´ıstica Wald n˜ao est´a baseada somente nesta distˆancia pois
podem existir dois conjuntos de dados A e B (ver Figura 3.2) produzindo a mesma distˆancia (φb−φ0)2, sendo um deles (neste caso o conjunto A, que produz uma
log-verossimilhan¸ca mais curvada) menos favor´avel `a hip´otese nula, baseado na estat´ıstica
RV. Assim, a estat´ıstica SW tamb´em deve considerar a curvatura, C(φb), da fun¸c˜ao.
Por esse motivo sua f´ormula ´e ponderada porI(φb) que ´e definida como
I(φ) =−E
d2 dφ2ℓ(φ)
3.0 Descri¸c˜ao dos Testes 21
Podemos considerar a estat´ıstica Wald ponderada tanto porC(φb) quanto por I(φb), poisC(φb) ´e um estimador consistente de I(φ) (Buse, 1982[5]).
Figura 3.2: Teste de Wald
iii)A equa¸c˜ao da estat´ıstica escore neste caso ´e dada por
SR =
[U(φ0)]2
I(φ0)
. (3.18)
Note que a estat´ıstica escore usa o vetorU(φ) avaliado emφ0 para ”medir”a distˆancia
entre φ0 e φbvisto que, quanto mais pr´oximo de φbestiver φ0, mais pr´oximo do vetor
nulo estar´a o vetor U(φ0), j´a que U(φb) = 0 (φb ´e o ponto de m´aximo). Todavia,
como mostra a Figura 3.3, podem existir dois conjuntos de dados dando origem a log-verossimilhan¸cas com diferentes curvaturas e produzindo o mesmo valor para U(φ0),
sendo por´em, a distˆancia (φb−φ0) maior para o conjunto de dados B (que possui
uma log-verossimilhan¸ca menos curvada) que para o conjunto de dados A. Como j´a vimos, quanto maior essa distˆancia, maior a distˆancia entre ℓ(φb) e ℓ(φ0). Assim, a
distˆancia [U(φ0)]2 em (3.18) deve ser ponderada pelo inverso da curvatura da fun¸c˜ao
3.0 Descri¸c˜ao dos Testes 22
Figura 3.3: Teste escore
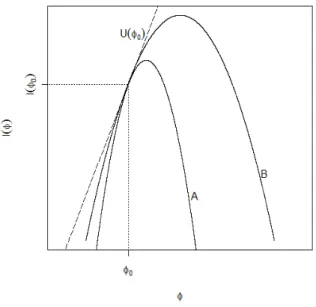
iv) A equa¸c˜ao da estat´ıstica gradiente neste caso ´e dada por
SG=U(φ0)(φb−φ0).
Note que, assim como a estat´ıstica de Wald a estat´ıstica gradiente tamb´em leva em conta a distˆancia entre as estimativas de m´axima verossimilhan¸ca. No entanto ela n˜ao considera a distˆancia quadr´atica, mas somente a diferen¸ca (φb−φ0). Uma forma de
contornar o problema do sinal dessa diferen¸ca seria ponder´a-la porU(φ0). Perceba que
U(φ0) ´e proporcional `a curvatura (ver Figura 3.4), isto ´e, quanto maior a curvatura
C(φb) maior ser´a o valor deU(φ0) em m´odulo, para uma distˆancia (φb−φ0) fixa. Neste
caso quanto maior o valor de U(φ0) em m´odulo, mais ind´ıcios temos contra a hip´otese
nula. Por outro, como na formula¸c˜ao da estat´ıstica escore, podemos ter dois conjuntos de dados produzindo o mesmo valor para U(φ0) (ver Figura 3.5). Neste caso, uma
alternativa para “fugir” do sinal negativo seria ponderar pela distˆancia (φb−φ0). Dessa
forma, quanto maior for essa distˆancia mais ind´ıcios temos contra a hip´otese nula, segundo a estat´ıstica da raz˜ao de verossimilhan¸ca.
3.0 Testes para Grandes Amostras e Modelos de Sobrevivˆencia 23
Figura 3.4: Wald e gradiente Figura 3.5: Escore e gradiente
Testes para Grandes Amostras e Modelos de
Sobre-vivˆ
encia
Nas se¸c˜oes anteriores foram apresentados alguns testes, com resultados assint´oticos que dependem da teoria assint´otica dos estimadores de m´axima verossimilhan¸ca. O objetivo desta se¸c˜ao ´e apresentar algumas referˆencias que garantam a validade dos resultados descritos na se¸c˜ao 3.1, para modelos de sobrevivˆencia.
Embora a abordagem considerada aqui seja com respeito a vari´aveis aleat´orias inde-pendentes e identicamente distribu´ıdas, de acordo com Lawless (2003)[17] os resultados assint´oticos dados acima se aplicam a situa¸c˜oes mais gerais como no caso de amostras censuradas e com covari´aveis. Maller e Zhou (1996)[24] demonstram alguns resultados sobre testes para grandes amostras e normalidade assint´otica do estimador de m´axima verossimilhan¸ca em um modelo param´etrico exponencial com covari´aveis, para dados de sobrevivˆencia censurados (censura n˜ao informativa) com e sem fra¸c˜ao de cura. Estes autores argumentam que, al´em das condi¸c˜oes de regularidade usuais (ver, por exemplo, Cox e Hinkley, 1974; Casella e Berger, 2002) uma condi¸c˜ao adicional para validar os resultados assint´oticos, n˜ao apenas para os casos particulares considerados, mas tam-b´em para modelos mais complexos, ´e que o percentual de censura na amostra n˜ao deve ser t˜ao alto, ou seja, P(δi = 1) n˜ao deve ser muito pequeno. Outra discuss˜ao sobre o
3.0 Testes para Grandes Amostras e Modelos de Sobrevivˆencia 24
Weibull.
Neste trabalho consideramos o modelo de tempo de promo¸c˜ao, descrito no cap´ı-tulo anterior, assumindo a distribui¸c˜ao Weibull para os tempos de vida. A seguir s˜ao apresentadas as estat´ısticas dos testes para este modelo.
Testes para o Modelo de Tempo de Promo¸c˜
ao Weibull
No modelo de tempo de promo¸c˜ao Weibull assume-se que os tempos de falha dos indiv´ıduos suscet´ıveis seguem uma distribui¸c˜aoW eibull(ρ, γ). ´E comum encontrarmos a distribui¸c˜ao Weibull parametrizada de diferentes formas. Uma delas, utilizada na disserta¸c˜ao de Fonseca (2009)[12], ´e tal que as fun¸c˜oes de densidade de probabilidade e de sobrevivˆencia s˜ao dadas por
f(t) = ρtρ−1
exp (γ−tρeγ) e S(t) = exp (−tρeγ), (3.19)
em queρ >0 e γ ∈R.
Dessa forma, a fun¸c˜ao de sobrevivˆencia de longa dura¸c˜ao (2.15), ´e dada por
Sp(t) = exp{−θ[1−exp (−tρeγ)]}, (3.20)
o que implica, por (2.17), que
fp(t) =θρtρ
−1
exp (γ−tρeγ) exp{−θ[1−exp (−tρeγ)]}. (3.21)
Por raz˜oes computacionais reparametrizamos (3.19) tomando ρ = exp (ρ∗
). Como no R (software utilizado neste trabalho para o desenvolvimento da aplica¸c˜ao e estudo de simula¸c˜ao) a parametriza¸c˜ao usada por padr˜ao ´e a (2.5) dada no Cap´ıtulo 2, relaciona-mos os parˆametros dessa parametriza¸c˜ao com os parˆametros da nossa reparametriza¸c˜ao e encontramos,
ρ∗
= log(a) e γ =−alog(b) (3.22)
em que a > 0 e b > 0 s˜ao parˆametros de forma e escala respectivamente. Portanto,
ρ∗
∈Re γ ∈R.
Considerando uma amostra den indiv´ıduos e denotando, como na subse¸c˜ao 2.2.2, o conjunto D= (n,y,δ,X) de dados observ´aveis e o vetor de parˆametros φ= (β′,λ′)′
3.0 Testes para Grandes Amostras e Modelos de Sobrevivˆencia 25
deseja-se expressar o logaritmo da fun¸c˜ao de verossimilhan¸ca marginal para este mo-delo. Substituindo (3.20) e (3.21) em (2.25) e incluindo covari´aveis atrav´es da rela¸c˜ao
θ= exp x′iβ
, apresentada na subse¸c˜ao 2.2.1, tem-se
ℓ∗
(φ;D) =
n X i=1 δi h xi ′
β+γ+ log ρyρ−1
i
−yiρeγi
−
n X
i=1
expx′iβ
[1−exp (−yiρeγ)]. (3.23)
Considerando em (3.23) a reparametriza¸c˜ao ρ = exp{ρ∗
} e derivando com rela¸c˜ao ao vetor de parˆametros φ, obtemos o vetor escore,
U(φ) = ∂ℓ
∗
(φ;D)
∂φ =
∂ℓ∗
(φ;D)
∂β
∂ℓ∗
(φ;D)
∂ρ∗
∂ℓ∗
(φ;D)
∂γ
1x(p+2)
= Pni=1
xi 0 0 0 1 0 0 0 1
(p+2)x3
si1(φ)
si2(φ)
si3(φ)
3x1
sendo
si1(φ) = δi−θi h
1−exp−yieρ∗e γi
,
si2(φ) = δi h
1 +eρ∗log(yi)
1−yeiρ∗eγi−θiexp
ρ∗
+γ−yieρ∗eγyeiρ∗log(yi)
e si3(φ) = δi
1−yieρ∗eγ−θiexp
γ−yieρ∗eγyeiρ∗.
Denotando porXia matriz
xi 0 0
0 1 0 0 0 1
(p+2)x1
e porsi(φ) o vetor (si1(φ), si2(φ), si3(φ))
′
de dimens˜ao 3x1, podemos escrever o vetor escore como
U(φ) =
n
X
i=1
3.0 Testes para Grandes Amostras e Modelos de Sobrevivˆencia 26
SejaJ(φ) a matriz de informa¸c˜ao observada dada por
J(φ) =−∂
2ℓ∗
(φ;D)
∂φ∂φ′ =−
∂2ℓ∗
(φ;D)
∂β∂β′
∂2ℓ∗
(φ;D)
∂β∂ρ
∂2ℓ∗
(φ;D)
∂β∂γ
∂2ℓ∗
(φ;D)
∂ρ∂β′
∂2ℓ∗
(φ;D)
∂ρ2
∂2ℓ∗
(φ;D)
∂ρ∂γ
∂2ℓ∗
(φ;D)
∂γ∂β′
∂2ℓ∗
(φ;D)
∂γ∂ρ
∂2ℓ∗
(φ;D)
∂γ2 .
Utilizamos a matriz de informa¸c˜ao observada J(φ), para calcular o erro padr˜ao na aplica¸c˜ao realizada no Cap´ıtulo 5. Calculamos da seguinte forma,
ep=pdiag(J(φ)−1
) (3.25)
em que ep =erro padr˜ao e diag(J(φ)−1
) significa a diagonal da inversa da matriz observada.
Considere a parti¸c˜ao φ= (λ1,λ2) ′
em que as dimens˜oes de λ1 e λ2 s˜ao r e (p−r)
respectivamente. As estat´ısticas da raz˜ao de verossimilhan¸cas e gradiente para testar a hip´otese nula composta
H0 :λ1 =0 versus H1 :λ1 6=0,
s˜ao dadas por
SRV = 2 h
ℓ(φb)−ℓ(φ˜)i e SG =Uλ1(φ˜)Tλb1, (3.26)
em que φb=λb1,λb2 ′
e φ˜= 0,λ˜2 ′
s˜ao os estimadores de m´axima verossimilhan¸ca irrestrito e restrito a hip´otese nula. Sob H0 e condi¸c˜oes gerais de regularidade SRV e
SG tˆem distribui¸c˜ao aproximadamente χ2(r).
Cap´ıtulo 4
Estudo de Simula¸c˜
ao
Neste cap´ıtulo apresentamos os resultados dos estudos de simula¸c˜ao realizados com o objetivo de avaliar e comparar o desempenho dos testes da raz˜ao de verossimilhan¸cas e gradiente para testar parˆametros de um modelo de sobrevivˆencia com fra¸c˜ao de cura. Foram considerados para a realiza¸c˜ao dos testes os n´ıveis de significˆancia nominais
α = 1%,5% e 10%. Para a realiza¸c˜ao dos estudos consideramos o modelo de tempo de promo¸c˜ao Weibull discutido no cap´ıtulo anterior. As simula¸c˜oes foram realizadas no software R (R Development Core Team (2010)). A fun¸c˜ao de otimiza¸c˜ao optim foi utilizada com o m´etodo BFGS para maximizar a fun¸c˜ao de log-verossimilhan¸ca.
Obten¸c˜
ao dos Dados Simulados
Para a gera¸c˜ao dos dados consideramos casos com trˆes, quatro e cinco covari´aveis associadas a cada indiv´ıduo (x1, x2, x3, x4, x5) com o objetivo de avaliar tamb´em o
efeito do aumento de parˆametros de pertuba¸c˜ao no desempenho dos testes. Para cada
i= 1,2, . . . , ncom nfixado (n= 30,40 e 100) temos quexi1, xi2, xi3, xi4 exi5 s˜ao i.i.d.
com valores obtidos da distribui¸c˜ao de Bernoulli com probabilidades de sucesso 0.49, 0.5, 0.51, 0.52 e 0.53 respectivamente. Esses valores foram tomados pr´oximos de 0.5 com o objetivo de se obter uma quantidade semelhante de informa¸c˜oes para cada n´ıvel dos fatoresx1, x2, x3, x4, x5.
Para cada indiv´ıduo foram gerados valores para Mi como uma amostra aleat´oria
da distribui¸c˜ao Poisson com m´edia θi = exp (xiβ). Os valores fixados para o vetor
β foram escolhidos de forma que quando combinados com as covari´aveis, a m´edia das fra¸c˜oes de cura, pθi(0) = exp(−θi), i = 1, . . . , n, fossem em torno de 10%, 20% e 30%
para cada situa¸c˜ao considerada.
Para cada indiv´ıduo n˜ao imune (Mi >0) foi gerada uma amostra de tamanho mi a
4.0 Realiza¸c˜ao dos Testes 28
partir de uma distribui¸c˜ao Weibull(a, b), coma= 2 eb = 4. Dessa forma, os tempos de falha s˜ao obtidos tomando o m´ınimo da amostra gerada, ti = min{zik;k = 1, . . . , mi}.
Geramos ainda censuras aleat´orias a partir de uma distribui¸c˜ao Uniforme(0, u), em que o valor de u afeta inversamente a propor¸c˜ao de censuras na amostra. A fim de avaliar separadamente o efeito do aumento do percentual de censuras entre os curados (f.c.) e n˜ao curados no desempenho dos testes, consideramos que a propor¸c˜ao de censuras calculada apenas com rela¸c˜ao ao total de indiv´ıduos suscet´ıveis ao evento. Assim como em Fonseca et al. (2011)[13] consideramos os seguintes eventos, A ≡ curados, A≡n˜ao curados e B≡censurados ou imunes a partir dos quais s˜ao definidas a propor¸c˜ao de censuras dentre os n˜ao curados, denotada por pc1 e calculada como
pc1 =
no de indiv´ıduos em B∩A
no de indiv´ıduos em A (4.1)
e a propo¸c˜ao de censurados ou imunes (denotada por pc2) calculada como
pc2 =
no de indiv´ıduos em B
no de indiv´ıduos na popula¸c˜ao. (4.2)
Em aplica¸c˜oespc2´e visto apenas como sendo o percentual de censuras da popula¸c˜ao.
Uma rela¸c˜ao entre essas duas quantidades, apresentada em Fonseca et al. (2011)[13], ´e
pc2 =pc1(1−p0) +p0, (4.3)
em quep0 representa a propor¸c˜ao de imunes.
Ent˜ao, uma vez gerada a censura, os tempos observados s˜ao obtidos fazendo-se
yi = min{ti, ci}. Associado a cada tempo observado temos um indicador de falha,
δi = 1 se ti ≤ci e δi = 0 se ti > ci. No caso em que o indiv´ıduo ´e curado (Mi = 0) o
tempo observado recebe infinito (valor suficientemente grande) e o indicador de falhas recebe zero. Os comandos em R para a gera¸c˜ao dos dados como descritos acima, s˜ao mostrados no Apˆendice B.
Realiza¸c˜
ao dos Testes
Para a realiza¸c˜ao dos testes tomamos a fun¸c˜ao densidade Weibull dada em (3.19) considerando a reparametriza¸c˜ao (3.22). Essa parametriza¸c˜ao permite que os parˆame-tros ρ∗
4.0 Resultados 29
(fp(y) e Sp(y)) e obter portanto a fun¸c˜ao de log-verossimilhan¸ca marginal (3.23) em
queρ= exp(ρ∗
). O vetor escore ´e obtido derivando-se essa log-verossimilhan¸ca e pode ser escrito como mostrado em (3.24).
Para calcular as estat´ısticas da raz˜ao de verossimilhan¸cas e gradiente faz-se neces-s´ario ainda encontrar os estimadores de m´axima verossimilhan¸ca irrestrito e restrito `a hip´otese nula, ou seja, encontrar o vetor de parˆametros, φ, que maximiza a fun¸c˜ao de log-verossimilhan¸ca. Em situa¸c˜oes mais simples esse vetor pode ser encontrado de forma explicita, como solu¸c˜ao da equa¸c˜ao
U(φ) = ∂ℓ
∗
(φ,D)
∂φ =0. (4.4)
Em outras situa¸c˜oes, a solu¸c˜ao da equa¸c˜ao (4.4) ´e obtida atrav´es de procedimentos num´ericos. Em nossa simula¸c˜ao utilizamos uma rotina pronta de otimiza¸c˜ao para a maximiza¸c˜ao das fun¸c˜oes.
Uma vez encontrados os estimadores de m´axima verossimilhan¸ca, os testes s˜ao re-alizados e os valores das estat´ısticas s˜ao ent˜ao comparados com os respectivos quantis (6.635) 1%, (3.841) 5% e (2.706) 10% da distribui¸c˜ao qui-quadrado para testar a hip´o-tese nulaH00 :β1 = 0 (q= 1) ou com (9.210) 1%, (5.991) 5% e (4.605) 10% para testar
a hip´oteseH01:β1 =β2 = 0 (q= 2). Consideramos r = 10.000 r´eplicas e estimamos a
propor¸c˜ao de vezes em que as hip´oteses H00 eH01 foram rejeitadas.
Os resultados desse procedimento s˜ao dados abaixo e os algoritmos das simula¸c˜oes s˜ao apresentados no Apˆendice B.
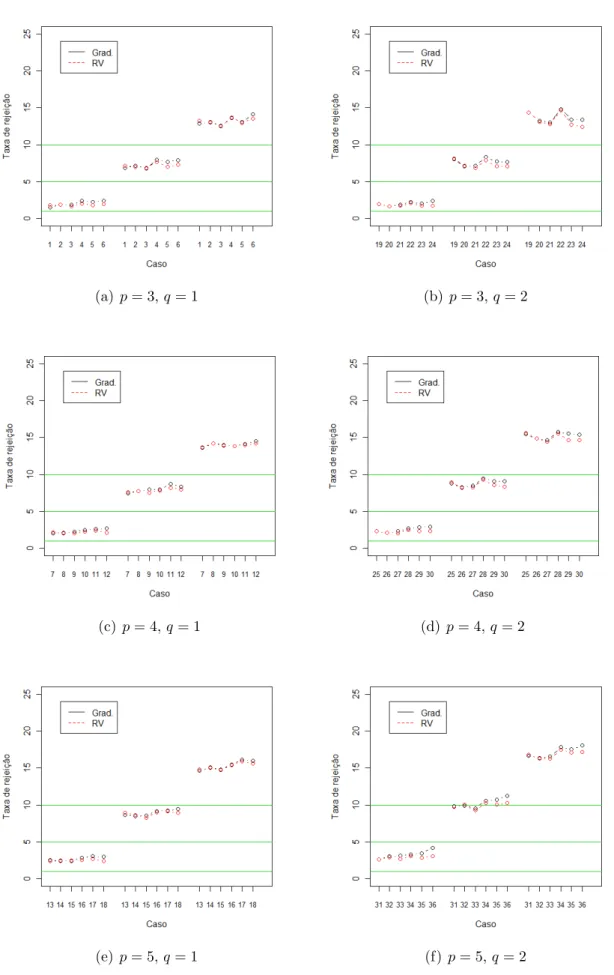
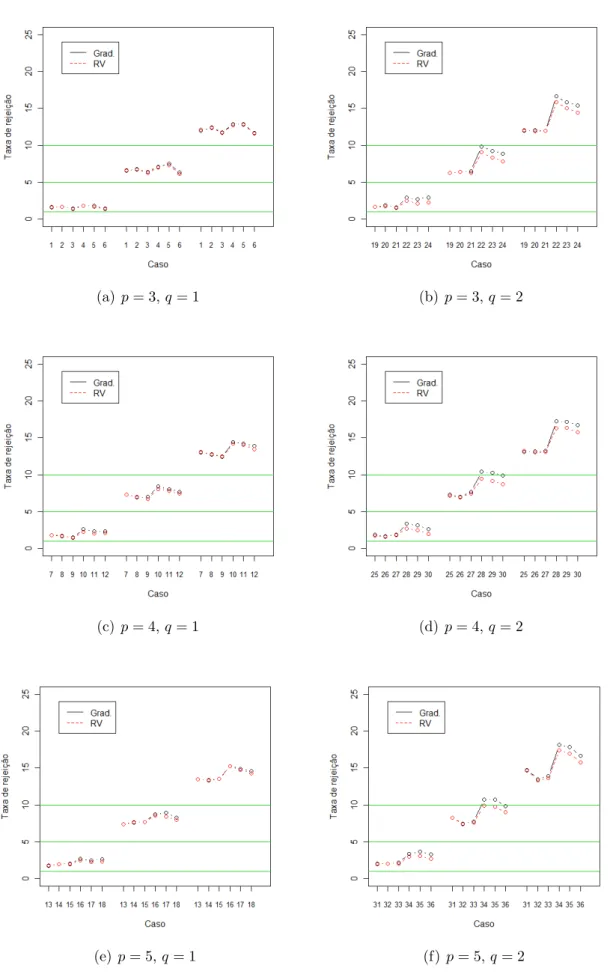
Resultados
Apresentamos aqui os resultados obtidos nas simula¸c˜oes, realizadas para analisar e comparar o desempenho dos testes da raz˜ao de verossimilhan¸cas e gradiente em modelos com fra¸c˜ao de cura para testar hip´oteses sobre alguns parˆametros do vetorβ
(relacionados `a fra¸c˜ao de cura).
As Tabelas 4.1, 4.2 e 4.3 apresentam as taxas de rejei¸c˜ao (em porcentagem) dos testes baseados nas estat´ısticas SRV e SG para testar as hip´oteses nula H00 : β1 = 0
(q = 1) e H01 :β1 =β2 = 0 (q= 2). Em cada tabela consideramos n´ıveis nominais de
1%, 5% e 10% e propor¸c˜oes de censuras e fra¸c˜ao de cura de 0% e 30% e 10%,20% e 30%, respectivamente. Cada tabela corresponde a amostras de tamanhos n = 30,40 e 100, respectivamente.
4.0 Resultados 30
de rejei¸c˜ao se distancia do n´ıvel nominal considerado) `a medida que p (n´umero de parˆametros) aumenta, considerando os tamanhos de amostra n = 30 e 40, e o teste da raz˜ao de verossimilhan¸cas se apresenta um pouco melhor que o teste gradiente nos casos em que temos 30% de censura. Para n = 100 quase n˜ao se percebe mudan¸ca no desempenho dos testes com o aumento de p, al´em disso os testes apresentam um desempenho equivalente (a taxa de rejei¸c˜ao dos testes RV e gradiente s˜ao pr´oximas). Resultados an´alogos s˜ao notados no caso em que q= 2 a n˜ao ser no caso n = 100 em que a piora dos testes com o aumento dep ocorre apenas nos casos sem censura.
Quando o n´umero de parˆametros testados aumenta (q = 1 para q = 2) nota-se que os testes pioram basicamente no caso com censura, sendo o teste gradiente mais sens´ıvel a censura em todos os tamanhos de amostras considerados.
De maneira geral, nota-se que, `a medida que o tamanho da amostra cresce os testes melhoram (se aproximam mais do n´ıvel nominal) no caso em queq= 1 sem considerar censura. J´a no caso em queq= 2 h´a uma melhora nos casos sem censura, no entanto nos casos com censura os testes tendem a piorar.
Como se podem notar, nos casos sem censura a medida que o tamanho da amostra cresce, com era esperado, as taxas de rejei¸c˜ao v˜ao convergindo para as taxas verda-deiras. Contudo estes resultados n˜ao s˜ao observados nos casos com censura, princi-palmente nas situa¸c˜ao em que q = 2, e parecem contrariar aspectos te´oricos sobre os testes. Estes fatos aparentemente estariam indicando situa¸c˜oes especiais em que estas estat´ısticas (RV e G) deveriam ser usadas com cautela para testar modelos com fra¸c˜ao de cura. Tendo em vista a limita¸c˜ao de tempo para a conclus˜ao deste trabalho, n˜ao foi poss´ıvel a investiga¸c˜ao detalhada destes resultados. Pretendemos investigar melhor essas situa¸c˜oes em estudos futuros.
Com rela¸c˜ao ao desempenho dos teste da raz˜ao de verossimilhan¸cas e gradiente, temos, que eles apresentam desempenho equivalente nos casos em que n˜ao se tem censura e o n´umero de parˆametros testados ´e q = 1. Nesses casos `a medida que o tamanho da amostra cresce, as diferen¸cas entre os testes diminuem. Por outro lado quando testamos dois parˆametros, q = 2, e consideramos censura o teste da raz˜ao de verossimilhan¸cas se mostra visivelmente melhor. O desempenho dos dois testes em alguns casos parece melhorar `a medida que a fra¸c˜ao de cura aumenta.
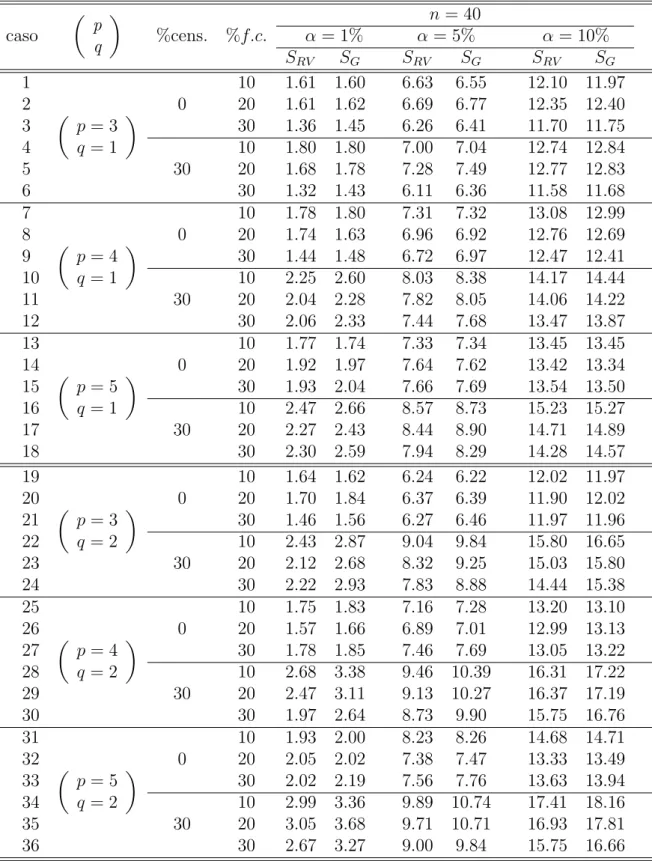
4.0 Resultados 31
Tabela 4.1: Taxa de rejei¸c˜ao da hip´otese nula (%) para os testes da raz˜ao de verossimilhan¸cas (SRV)
e gradiente (SG) para testar H00:β1= 0 (q=1) eH01:β1= 0 (q=2);p ≡n o
de parˆametros.
caso
p q
%cens. %f.c.
n = 30
α = 1% α= 5% α= 10%
SRV SG SRV SG SRV SG
1 2 3 4 5 6
p= 3
q= 1
0
10 1.78 1.52 7.14 6.81 13.24 12.87 20 1.83 1.83 7.03 7.13 13.12 13.02 30 1.67 1.86 6.86 6.80 12.51 12.56 30
10 1.99 2.36 7.69 7.96 13.69 13.59 20 1.82 2.25 7.03 7.67 12.95 13.07 30 1.96 2.38 7.30 7.91 13.57 14.13 7 8 9 10 11 12
p= 4
q= 1
0
10 2.15 1.99 7.60 7.42 13.66 13.60 20 2.02 2.12 7.76 7.70 14.21 14.22 30 2.03 2.25 7.55 7.97 13.90 13.97 30
10 2.22 2.48 7.84 7.93 13.85 13.83 20 2.35 2.60 8.21 8.74 13.97 14.15 30 2.12 2.67 7.97 8.35 14.21 14.53 13 14 15 16 17 18
p= 5
q= 1
0
10 2.40 2.50 8.91 8.62 14.82 14.63 20 2.42 2.46 8.62 8.48 15.03 15.06 30 2.47 2.42 8.29 8.56 14.72 14.77 30
10 2.56 2.86 9.00 9.17 15.42 15.46 20 2.66 3.03 9.15 9.25 15.91 16.12 30 2.42 2.98 8.90 9.42 15.60 15.98 19 20 21 22 23 24
p= 3
q= 2
0
10 1.95 1.92 8.12 8.06 14.38 14.35 20 1.62 1.63 7.14 7.04 13.10 13.25 30 1.71 1.88 6.86 7.14 12.80 12.99 30
10 2.07 2.22 7.87 8.31 14.63 14.82 20 1.71 1.99 7.05 7.72 12.75 13.40 30 1.75 2.37 7.04 7.65 12.40 13.41 25 26 27 28 29 30
p= 4
q= 2
0
10 2.29 2.30 8.92 8.76 15.63 15.43 20 2.09 2.06 8.20 8.22 14.86 14.84 30 2.04 2.28 8.23 8.48 14.41 14.65 30
10 2.46 2.69 9.27 9.46 15.54 15.75 20 2.28 2.83 8.53 9.11 14.68 15.52 30 2.33 2.93 8.30 9.11 14.68 15.36 31 32 33 34 35 36
p= 5
q= 2
0
10 2.60 2.61 9.77 9.82 16.81 16.68 20 2.93 3.05 10.01 9.91 16.29 16.32 30 2.70 3.11 9.28 9.54 16.31 16.55 30
4.0 Resultados 32
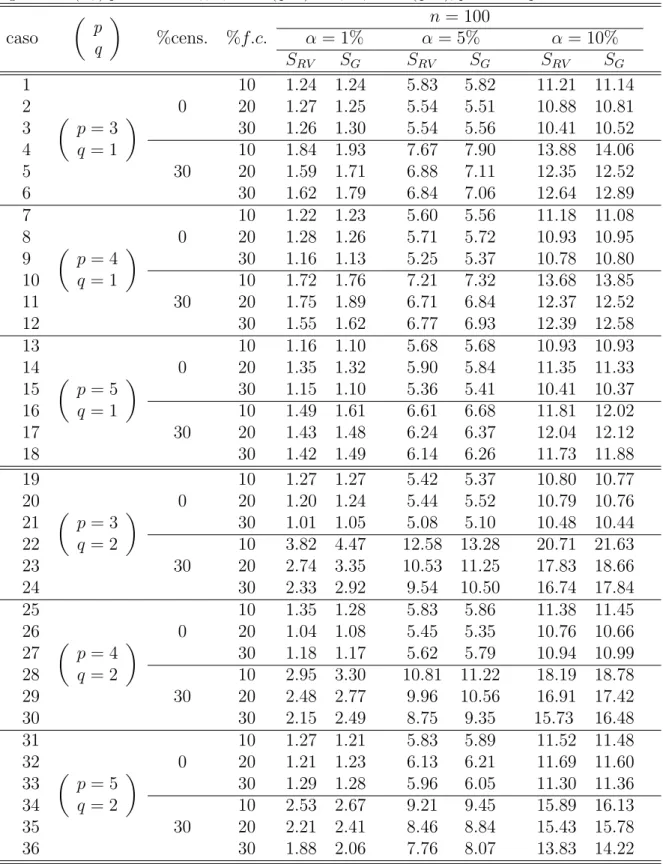
Tabela 4.2: Taxa de rejei¸c˜ao da hip´otese nula (%) para os testes da raz˜ao de verossimilhan¸cas (SRV)
e gradiente (SG) para testar H00:β1= 0 (q=1) eH01:β1= 0 (q=2);p ≡n o
de parˆametros.
caso
p q
%cens. %f.c.
n = 40
α= 1% α= 5% α= 10%
SRV SG SRV SG SRV SG
1 2 3 4 5 6
p= 3
q= 1
0
10 1.61 1.60 6.63 6.55 12.10 11.97 20 1.61 1.62 6.69 6.77 12.35 12.40 30 1.36 1.45 6.26 6.41 11.70 11.75 30
10 1.80 1.80 7.00 7.04 12.74 12.84 20 1.68 1.78 7.28 7.49 12.77 12.83 30 1.32 1.43 6.11 6.36 11.58 11.68 7 8 9 10 11 12
p= 4
q= 1
0
10 1.78 1.80 7.31 7.32 13.08 12.99 20 1.74 1.63 6.96 6.92 12.76 12.69 30 1.44 1.48 6.72 6.97 12.47 12.41 30
10 2.25 2.60 8.03 8.38 14.17 14.44 20 2.04 2.28 7.82 8.05 14.06 14.22 30 2.06 2.33 7.44 7.68 13.47 13.87 13 14 15 16 17 18
p= 5
q= 1
0
10 1.77 1.74 7.33 7.34 13.45 13.45 20 1.92 1.97 7.64 7.62 13.42 13.34 30 1.93 2.04 7.66 7.69 13.54 13.50 30
10 2.47 2.66 8.57 8.73 15.23 15.27 20 2.27 2.43 8.44 8.90 14.71 14.89 30 2.30 2.59 7.94 8.29 14.28 14.57 19 20 21 22 23 24
p= 3
q= 2
0
10 1.64 1.62 6.24 6.22 12.02 11.97 20 1.70 1.84 6.37 6.39 11.90 12.02 30 1.46 1.56 6.27 6.46 11.97 11.96 30
10 2.43 2.87 9.04 9.84 15.80 16.65 20 2.12 2.68 8.32 9.25 15.03 15.80 30 2.22 2.93 7.83 8.88 14.44 15.38 25 26 27 28 29 30
p= 4
q= 2
0
10 1.75 1.83 7.16 7.28 13.20 13.10 20 1.57 1.66 6.89 7.01 12.99 13.13 30 1.78 1.85 7.46 7.69 13.05 13.22 30
10 2.68 3.38 9.46 10.39 16.31 17.22 20 2.47 3.11 9.13 10.27 16.37 17.19 30 1.97 2.64 8.73 9.90 15.75 16.76 31 32 33 34 35 36
p= 5
q= 2
0
10 1.93 2.00 8.23 8.26 14.68 14.71 20 2.05 2.02 7.38 7.47 13.33 13.49 30 2.02 2.19 7.56 7.76 13.63 13.94 30
4.0 Resultados 33
Tabela 4.3: Taxa de rejei¸c˜ao da hip´otese nula (%) para os testes da raz˜ao de verossimilhan¸cas (SRV)
e gradiente (SG) para testar H00:β1= 0 (q=1) eH01:β1= 0 (q=2);p ≡n o
de parˆametros.
caso
p q
%cens. %f.c.
n= 100
α = 1% α= 5% α= 10%
SRV SG SRV SG SRV SG
1 2 3 4 5 6
p= 3
q= 1
0
10 1.24 1.24 5.83 5.82 11.21 11.14 20 1.27 1.25 5.54 5.51 10.88 10.81 30 1.26 1.30 5.54 5.56 10.41 10.52 30
10 1.84 1.93 7.67 7.90 13.88 14.06 20 1.59 1.71 6.88 7.11 12.35 12.52 30 1.62 1.79 6.84 7.06 12.64 12.89 7 8 9 10 11 12
p= 4
q= 1
0
10 1.22 1.23 5.60 5.56 11.18 11.08 20 1.28 1.26 5.71 5.72 10.93 10.95 30 1.16 1.13 5.25 5.37 10.78 10.80 30
10 1.72 1.76 7.21 7.32 13.68 13.85 20 1.75 1.89 6.71 6.84 12.37 12.52 30 1.55 1.62 6.77 6.93 12.39 12.58 13 14 15 16 17 18
p= 5
q= 1
0
10 1.16 1.10 5.68 5.68 10.93 10.93 20 1.35 1.32 5.90 5.84 11.35 11.33 30 1.15 1.10 5.36 5.41 10.41 10.37 30
10 1.49 1.61 6.61 6.68 11.81 12.02 20 1.43 1.48 6.24 6.37 12.04 12.12 30 1.42 1.49 6.14 6.26 11.73 11.88 19 20 21 22 23 24
p= 3
q= 2
0
10 1.27 1.27 5.42 5.37 10.80 10.77 20 1.20 1.24 5.44 5.52 10.79 10.76 30 1.01 1.05 5.08 5.10 10.48 10.44 30
10 3.82 4.47 12.58 13.28 20.71 21.63 20 2.74 3.35 10.53 11.25 17.83 18.66 30 2.33 2.92 9.54 10.50 16.74 17.84 25 26 27 28 29 30
p= 4
q= 2
0
10 1.35 1.28 5.83 5.86 11.38 11.45 20 1.04 1.08 5.45 5.35 10.76 10.66 30 1.18 1.17 5.62 5.79 10.94 10.99 30
10 2.95 3.30 10.81 11.22 18.19 18.78 20 2.48 2.77 9.96 10.56 16.91 17.42 30 2.15 2.49 8.75 9.35 15.73 16.48 31 32 33 34 35 36
p= 5
q= 2
0
10 1.27 1.21 5.83 5.89 11.52 11.48 20 1.21 1.23 6.13 6.21 11.69 11.60 30 1.29 1.28 5.96 6.05 11.30 11.36 30
4.0 Resultados 34
(a)p= 3,q= 1 (b)p= 3,q= 2
(c) p= 4,q= 1 (d)p= 4,q= 2
(e) p= 5,q= 1 (f) p= 5,q= 2
4.0 Resultados 35
(a) p= 3,q= 1 (b)p= 3,q= 2
(c) p= 4,q= 1 (d)p= 4,q= 2
(e) p= 5,q= 1 (f) p= 5,q= 2
4.0 Resultados 36
(a) p= 3,q= 1 (b)p= 3,q= 2
(c) p= 4,q= 1 (d)p= 4,q= 2
(e) p= 5,q= 1 (f) p= 5,q= 2
Cap´ıtulo 5
Aplica¸c˜
ao
Introdu¸c˜
ao
Com o objetivo de ilustrar os conceitos apresentados neste trabalho, realizamos uma aplica¸c˜ao considerando um conjunto de dados referentes ao tempo at´e a recidiva do cˆancer de mama em 355 pacientes diagnosticadas e previamente tratadas no Hospital Prof. Dr. Luiz Antˆonio, Unidade I da Liga Contra o Cˆancer (Natal-RN), no per´ıodo de 1991 a 1995. Estes dados foram analisados originalmente por Macedo e Valen¸ca (2009)[23], que utilizaram o modelo de regress˜ao de Cox (Cox, 1972)[9] com o objetivo de avaliar o efeito das covari´aveis relacionadas ao cˆancer de mama, sobre o tempo em que as pacientes permaneciam livres da doen¸ca, ap´os terem passado por tratamentos convencionais e n˜ao terem apresentado met´astase.
A Figura 2.1 apresentada no Cap´ıtulo 2, representa o gr´afico da fun¸c˜ao de sobre-vivˆencia emp´ırica (Kaplan-Meier) desses dados. Note que a fun¸c˜ao parece estabilizar em um n´ıvel bem acima de zero, devido ao alto percentual de censura encontrado nos dados (pc2 = 73%). Este comportamento revela a poss´ıvel existˆencia de indiv´ıduos
curados na popula¸c˜ao.
Dessa forma, omodelo de tempo de promo¸c˜ao foi ajustado aos dados com o objetivo de avaliar e testar o efeito das covari´aveis relacionadas ao cˆancer de mama, sobre a fra¸c˜ao de cura das pacientes envolvidas no estudo. As covari´aveis foram inclu´ıdas no modelo atrav´es do parˆametroθ, por meio da rela¸c˜ao (2.20). Supomos que os tempos de vida das pacientes suscet´ıveis,Zik, seguem uma distribui¸c˜aoW eibull(ρ, γ),i= 1, . . . , n
ek = 1, . . . , Mi.
5.0 Descri¸c˜ao das Covari´aveis 38
Descri¸c˜
ao das Covari´
aveis
Os fatores considerados neste estudo forampropor¸c˜ao de linfonodos axilares compro-metidos (PLC) com trˆes n´ıveis (sem comprometimento, at´e 50% de linfonodos axilares comprometidos e acima de 50% dos linfonodos comprometidos) etratamento n˜ao cir´ ur-gico (TNC) com dois n´ıveis (com hormˆonioterapia e sem hormˆonioterapia). Definimos ent˜ao as seguintes vari´aveis indicadoras P LC1 em que P LC1 = 1 se existem at´e 50% linfonodos comprometidos e zero caso contr´ario, P LC2 em que P LC2 = 1 se exis-tem mais de 50% dos linfonodos comprometidos e zero caso contr´ario e T N C1 em que T N C1 = 0 se o tratamento inclui hormˆonioterapia e T CN1 = 1 se o tratamento n˜ao inclui hormˆonioterapia. Para facilitar a leitura resumimos estas informa¸c˜oes nas Tabelas (5) e (5).
Tabela 5.1: N´ıveis do fator PLC: dados cˆancer de mama.
PLC Vari´aveis Indicadoras
PCL1 PCL2
0% 0 0
de 0 at´e 50% 1 0
maior que 50% 0 1
Tabela 5.2: N´ıveis do fator TNC: dados cˆancer de mama.
TNC Vari´avel Indicadora TCN1
c/ hormˆonio terapia 0 s/ hormˆonio terapia 1
No trabalho de Macedo e Valen¸ca (2009)[23] uma quantidade maior de covari´aveis relacionadas ao cˆancer de mama s˜ao consideradas. No mesmo trabalho s˜ao fornecidos mais detalhes sobre os conceitos cl´ınicos envolvidos.
A forma gr´afica do estimador de Kaplan-Meier para os fatores PLC e TNC s˜ao apresentadas nas Figuras (5.1) e (5.2), respectivamente.