Using predictive modelling to create the school dropouts' profile: a case study regarding elementary and high school students
Texto
Imagem
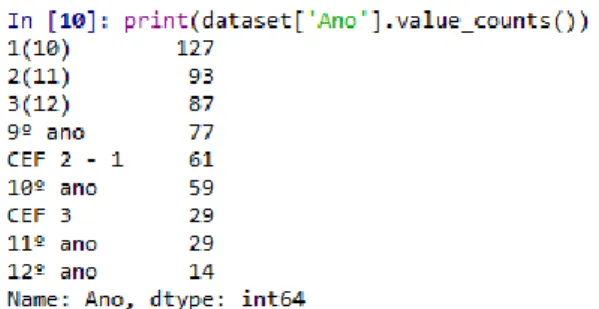
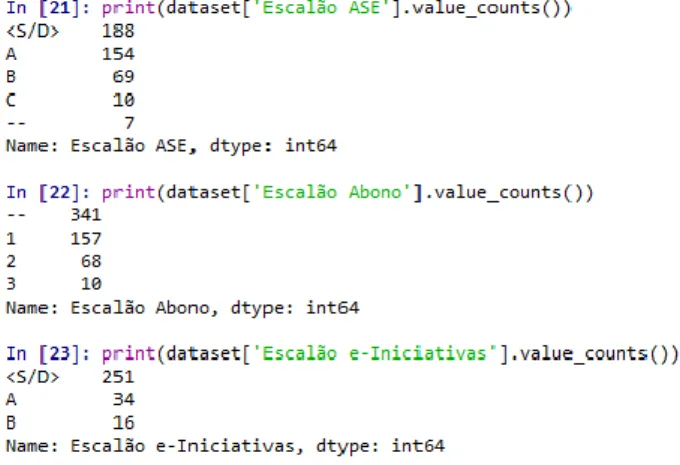
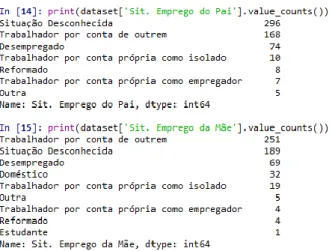



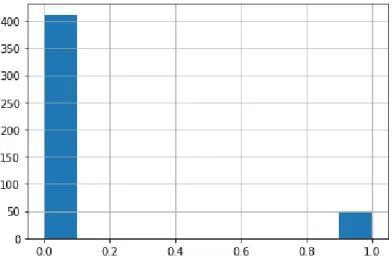
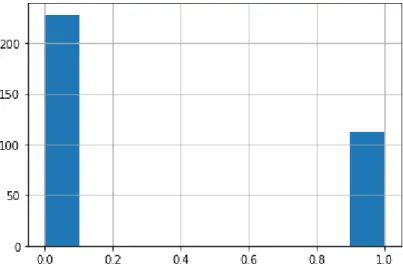
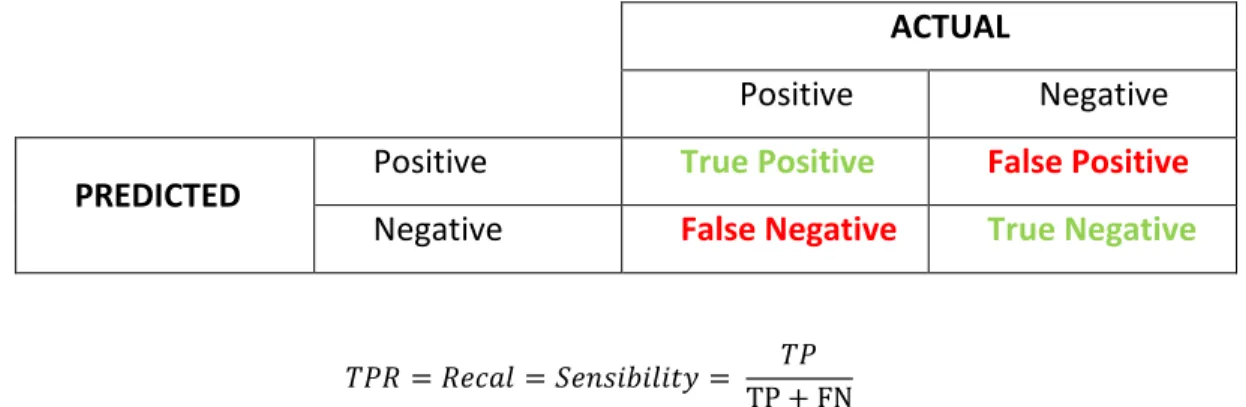
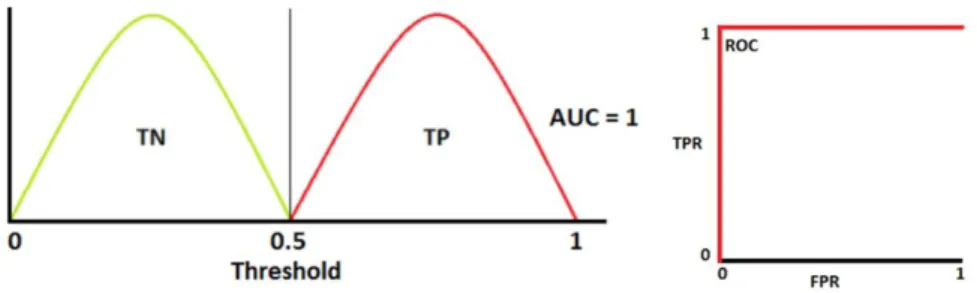
Documentos relacionados
De forma a que o desenho da tábua de montagem do cabo esteja o mais parecido com o cabo, é desejável que um olhal esteja devidamente orientado, e o LAYMAN obriga a que isto seja
Pode pois ter acontecido, aquando da colheita das amostras que estas tivessem isolados dos dois grupos genéticos, para além disso as amostras 17 e 18 foram colhidas
Pode-se, por isso, afirmar que as novas missões assumidas pelos Estados e confiadas às organizações internacionais e aos respectivos aparelhos militares (missões humanitá-
Porque as histórias faladas ou escritas alimentam os nossos desejos humanos, ampliam-nos os horizontes de expectativas, fabricam- nos imagens mentais, desenvolvem o nosso imaginário
A tentativa de estudar o processo de envelhecimento numa região marcada por fortes tradições rurais, para comparação com o mesmo processo em áreas ditas
Os poderes social, político, econômico e militar estão sempre pensando na acumulação de objetos duradouros e controlam a passagem do transitório para o durável, num processo em
Dados estes semelhantes aos encontrados no presente estudo, onde a prevalência de sobrepeso e obesidade foi maior em escola particular, sendo que o gênero
As informações utilizadas foram fornecidos pelo Departamento de Atenção Básica do Ministério da Saúde, no período de 2001 a 2007, contemplando o número de Equipe de
