Faculdade de Ciˆencias
Departamento de Inform´
atica
ONLINE EVOLUTION OF ROBOT
BEHAVIOUR
Fernando Goulart da Silva
DISSERTAC
¸ ˜
AO
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializa¸c˜
ao em Intera¸c˜
ao e Conhecimento
Faculdade de Ciˆencias
Departamento de Inform´
atica
ONLINE EVOLUTION OF ROBOT
BEHAVIOUR
Fernando Goulart da Silva
DISSERTAC
¸ ˜
AO
Projeto orientado pelo Prof. Doutor Paulo Jorge Cunha Vaz Dias Urbano e co-orientado pelo Prof. Doutor Anders Lyhne Christensen
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializa¸c˜
ao em Intera¸c˜
ao e Conhecimento
First, I would like to thank to both my supervisors: Prof. Paulo Urbano for his useful comments, interesting conversations and always curious, relaxed and fun na-ture; Prof. Anders Christensen for his scientific discipline and rigour, great deal of patience and encouragement along the way.
A special thanks to all the people of the Laboratory of Agent Modelling (LabMAg). Particular acknowledgements to Davide Nunes and Phil Lopes for coffee break con-versations and daily bonjour ; Nuno Henriques, fellow believer, for the advices and interesting discussions; Christian Marques for introducing me to the genius of music and film.
To Kenneth O. Stanley and Andrea Soltoggio for comments and discussions. To Lu´ıs Correia for teaching me about science.
To those friends always caring. This thesis, and everything I have done in my life, would have been impossible without the support of my friends. Therefore, I want to express my gratitude to a restrict group of people that were (or still are) important to me, and that have helped me at different stages of my life. Thank you Ana Macedo, Andr´e Silva, Bruno Ferreira, Diogo Cardoso, Filipe Caba¸co, Francisco Borba, Fl´avio Saraiva, Jo˜ao Rego, Jo˜ao Silva, Jo˜ao Pedro Coelho, Jorge Carvalho Gomes, Madalena Vaz da Silva, and Marcelo Cardoso.
As t´ecnicas de computa¸c˜ao evolucion´aria tˆem sido largamente estudadas e apli-cadas na ´area da rob´otica como forma de automatizar o design de sistemas rob´oticos. Na rob´otica evolucion´aria, os controladores comportamentais dos robˆos s˜ao normal-mente baseados em redes neuronais artificiais. Os pesos das liga¸c˜oes sin´apticas e, ocasionalmente, a topologia das redes neuronais s˜ao otimizados com base em algo-ritmos evolucion´arios, um processo denominado neuroevolu¸c˜ao.
Nesta disserta¸c˜ao, propomos e avaliamos duas novas abordagens para a s´ıntese online, i.e., durante o tempo de opera¸c˜ao no meio ambiente, de controladores neuro-nais para robˆos aut´onomos. A primeira abordagem proposta denomina-se odNEAT, uma vers˜ao online, distribu´ıda e descentralizada de NeuroEvolution of Augmenting Topologies (NEAT), um dos mais proeminentes algoritmos neuroevolucion´arios. O algoritmo odNEAT permite a evolu¸c˜ao online de neurocontroladores em grupos de agentes corporizados, como robˆos, que tˆem como objetivo resolver a mesma tarefa, seja esta individual ou coletiva. Enquanto as abordagens anteriormente propostas para a evolu¸c˜ao online de controladores neuronais se focam exclusivamente na oti-miza¸c˜ao dos pesos da rede neuronal, o algoritmo odNEAT estende o estado da arte e permite a otimiza¸c˜ao evolucion´aria tanto dos pesos da rede neuronal como da sua topologia.
Ao evoluir a topologia neuronal, o odNEAT ultrapassa as limita¸c˜oes inerentes dos algoritmos neuroevolucion´arios que apenas otimizam topologias fixas, sendo que estas tˆem obrigatoriamente de ser escolhidas a priori pelo designer humano. Este processo envolve normalmente experimenta¸c˜ao intensiva pois n˜ao existe nenhuma f´ormula universal para a escolha de uma topologia apropriada para uma dada ta-refa. A escolha de uma topologia inadequada afeta o processo evolucion´ario e, consequentemente, o potencial para adapta¸c˜ao online dado que: (i) redes neuronais demasiado grandes tˆem pesos a mais, sendo que cada um destes adiciona uma di-mens˜ao extra ao espa¸co de pesquisa e, (ii) redes neuronais demasiado pequenas s˜ao incapazes de representar solu¸c˜oes para al´em de um certo n´ıvel de complexidade, o que potencialmente limita a sua performance. No algoritmo odNEAT, por outro lado, uma topologia adequada para resolver a tarefa ´e o resultado de um processo evolucion´ario cont´ınuo no tempo.
Nesta tarefa, agentes dispersos pelo ambiente tˆem de se mover para perto uns dos outros com vista a formarem um ´unico grupo. A agrega¸c˜ao tem um papel importante em muitos sistemas biol´ogicos e rob´oticos dado que ´e a base para a emergˆencia de v´arios comportamentos coletivos.
Os resultados experimentais obtidos ilustram quatro pontos fundamentais. Pri-meiro, devido `a natureza distribu´ıda e ass´ıncrona do algoritmo desenvolvido, os robˆos exibem uma grande heterogeneidade comportamental e diferentes estrat´egias para a agrega¸c˜ao. Segundo, os comportamentos evolu´ıdos, a forma¸c˜ao de grupos dinˆamicos e est´aticos, bem como as estrat´egias individuais para explora¸c˜ao do ambiente, s˜ao observados simultaneamente no mesmo grupo de robˆos. Apesar da diversidade com-portamental, os robˆos s˜ao capazes de colaborar eficientemente com vista `a realiza¸c˜ao do objetivo comum.
Terceiro, a compara¸c˜ao entre o odNEAT e o rtNEAT, um m´etodo semelhante mas centralizado, indica que, apesar de ser intencionalmente distribu´ıdo e descentra-lizado, o algoritmo proposto tem uma performance compar´avel `a do m´etodo centra-lizado. Finalmente, as experiˆencias de escalabilidade indicam que, para grupos de 5 a 15 robˆos, o algoritmo odNEAT ´e escal´avel no que diz respeito ao tempo necess´ario para atingir comportamentos sustent´aveis. Para grupos com um maior n´umero de robˆos, o algoritmo estabiliza e mant´em os mesmos n´ıveis de performance, apesar dos requisitos da tarefa se tornarem cada vez mais dif´ıceis.
Com o objetivo de analisar a contribui¸c˜ao de cada componente algor´ıtmico na performance, realiz´amos uma s´erie de estudos de abla¸c˜ao. Os resultados obtidos indicam que cada componente tˆem um papel importante na performance global do algoritmo, acelerando a evolu¸c˜ao e evitando que o processo evolucion´ario procure desnecessariamente em certas zonas do espa¸co de solu¸c˜oes poss´ıveis.
Na segunda abordagem proposta, estendemos o nosso m´etodo anterior e com-binamos a evolu¸c˜ao online de pesos e topologias (odNEAT) com aprendizagem por neuromodula¸c˜ao. Nos organismos biol´ogicos, a neuromodula¸c˜ao ´e uma forma de modifica¸c˜ao sin´aptica que envolve neur´onios moduladores que difundem qu´ımicos em liga¸c˜oes sin´apticas espec´ıficas. Apesar de ser ainda alvo de estudo, a neuro-modula¸c˜ao tem sido vista como essencial para estabilizar a plasticidade Hebbiana cl´assica e a mem´oria.
A combina¸c˜ao online de evolu¸c˜ao e aprendizagem permite a explora¸c˜ao do po-tencial de adapta¸c˜ao em duas escalas temporais distintas. O processo evolucion´ario permite a adapta¸c˜ao filogen´etica, associada com o desenvolvimento da esp´ecie, en-quanto que a aprendizagem por neuromodula¸c˜ao permite a adapta¸c˜ao ontog´enica, associada com os processos de aprendizagem do indiv´ıduo. Desta forma, enquanto o
ajuste, e modifique ativamente a sua dinˆamica interna.
O m´etodo proposto ´e novamente demonstrado atrav´es de um conjunto de ex-periˆencias efetuadas em simula¸c˜ao, nas quais um grupo de robˆos tem de aprender a resolver uma tarefa de foraging dinˆamica. Nesta tarefa, existem dois tipos de co-mida distribu´ıdos pelo ambiente que periodicamente mudam o seu valor alimentar, tornam-se mais ou menos nutritivos, ou venenosos.
A performance do algoritmo proposto ´e avaliada em configura¸c˜oes experimentais distintas, com um e v´arios robˆos. Os resultados obtidos mostram que, quando a aprendizagem por neuromodula¸c˜ao ´e empregue, a intera¸c˜ao entre evolu¸c˜ao e apren-dizagem permite uma s´ıntese substancialmente mais r´apida de controladores neu-ronais perfeitamente adaptados `as altera¸c˜oes peri´odicas nos requisitos da tarefa. Os nossos resultados indicam ainda que a complexidade adicional necess´aria para incluir neur´onios moduladores nas topologias neuronais, e o consequente aumento no espa¸co de pesquisa, ´e compensada pela capacidade e dinˆamica de aprendizagem das redes neuromoduladas. A aprendizagem por neuromodula¸c˜ao mostra-se ainda capaz de acelerar o processo evolucion´ario quando os requisitos da tarefa mudam rapidamente e quando permanecem est´aveis durante muito tempo.
Uma an´alise topol´ogica das redes evolu´ıdas mostra que cada neur´onio modula-dor apresenta uma baixa densidade de liga¸c˜oes neuronais modulat´orias dado que, tipicamente, regula apenas a atividade de um ou dois outros neur´onios. De facto, o processo evolucion´ario leva `a emergˆencia de neur´onios moduladores especializados que s˜ao exclusivamente dedicados `a regula¸c˜ao dos neur´onios de sa´ıda da rede neu-ronal. Estes aspetos topol´ogicos s˜ao a principal diferen¸ca entre solu¸c˜oes evolu´ıdas com e sem neuromodula¸c˜ao, e o fator respons´avel pela s´ıntese mais r´apida de con-troladores e comportamentos sustent´aveis.
Em termos de escalabilidade, as experiˆencias realizadas indicam que, para grupos de 2 e 5 robˆos, o algoritmo odNEAT com aprendizagem por neuromodula¸c˜ao escala eficientemente. Nestes casos, a performance aumenta significativamente no que diz respeito ao n´umero m´edio de controladores testados por cada robˆo at´e atingir uma solu¸c˜ao est´avel. Para grupos com um maior n´umero de robˆos, por exemplo 8 robˆos, a complexidade da configura¸c˜ao experimental aumenta drasticamente e as solu¸c˜oes est´aveis tornam-se mais dif´ıceis de evoluir.
Palavras-chave: Rob´otica Evolucion´aria, Evolu¸c˜ao Online, Aprendizagem por Neuromodula¸c˜ao, Adapta¸c˜ao Cont´ınua, Redes Neuronais.
In this dissertation, we propose and evaluate two novel approaches to the on-line synthesis of neural controllers for autonomous robots. The first approach is odNEAT, an online, distributed, and decentralised version of NeuroEvolution of Augmenting Topologies (NEAT). odNEAT is an algorithm for online evolution in groups of embodied agents such as robots. In odNEAT, agents have to solve the same task, either individually or collectively. While previous approaches to online evolution of neural controllers have been limited to the optimisation of weights, odNEAT evolves both weights and network topology. We demonstrate odNEAT through a series of simulation-based experiments in which a group of e-puck-like robots must perform an aggregation task. Our results show that robots are capable of evolving effective aggregation strategies and that sustainable behaviours evolve quickly. We show that odNEAT approximates the performance of rtNEAT, a sim-ilar but centralised method. We also analyse the contribution of each algorithmic component on the performance through a series of ablation studies.
In the second approach, we extend our previous method and combine online evo-lution of weights and network topology (odNEAT) with neuromodulated learning. We demonstrate our method through a series of experiments in which a group of simulated robots must perform a dynamic concurrent foraging task. In this task, scattered food items periodically change their nutritive value or become poisonous. Our results show that when neuromodulated learning is employed, neural controllers are synthesised faster than by odNEAT alone. We demonstrate that the online evo-lutionary process is capable of generating controllers that adapt to the periodic task changes. We evaluate the performance both in a single robot setup and in a multi-robot setup. An analysis of the evolved networks shows that they are characterised by specialised modulatory neurons that exclusively regulate online learning in the output neurons.
Keywords: Evolutionary Robotics, Online Evolution, Neuromodulated Learning, Continuous Adaptation, Artificial Neural Networks.
List of Figures xviii
List of Tables xxi
1 Introduction 1
1.1 Motivation . . . 1
1.2 Research Objectives . . . 2
1.3 Context . . . 3
1.4 Thesis Overview and Contribution of Research . . . 3
2 Background 5 2.1 Collective Evolutionary Robotics . . . 5
2.1.1 Introduction to Evolutionary Robotics . . . 6
2.1.2 Fitness Function . . . 7
2.1.3 Background on the Evolution of Collective Behaviour . . . 8
2.2 Online Evolution of Robot Controllers . . . 9
2.2.1 Classifying the Evolutionary Process . . . 9
2.2.2 Single Robot Systems . . . 12
2.2.3 Multirobot Systems . . . 12
2.3 Artificial Neural Networks . . . 16
2.3.1 Neurons and Activation Functions . . . 16
2.3.2 Artificial Neural Network Architectures . . . 17
2.3.3 Measuring the Complexity of Artificial Neural Networks . . . 18
2.3.4 Artificial Neural Networks in Robotics . . . 19
2.4 Learning with Neuroevolution . . . 19
2.4.1 Fixed-Topology Neuroevolution Algorithms . . . 20
2.4.2 Constructive Neuroevolution Algorithms . . . 22
2.4.3 NeuroEvolution of Augmenting Topologies . . . 24
2.5 Summary . . . 31
3 Online Evolution of Neural Topologies 33 3.1 odNEAT: An Online Evolutionary Algorithm . . . 33
3.2.2 Experimental Methodology . . . 41
3.3 Results and Discussion . . . 44
3.3.1 rtNEAT and odNEAT . . . 47
3.3.2 Ablation Studies . . . 50
3.3.3 Scalability Experiments . . . 51
3.4 Contributions to JBotEvolver . . . 53
3.5 Summary . . . 53
4 Online Evolution of Plastic Neural Networks 55 4.1 Motivation . . . 55
4.2 Artificial Evolution of Neuromodulated Plasticity . . . 56
4.2.1 Considerations on the Combination of Evolution and Learning 58 4.3 Experimental Setup . . . 58
4.3.1 The Concurrent Foraging Domain . . . 58
4.3.2 Robot Model and Behavioural Control . . . 60
4.3.3 Experimental Parameters . . . 60
4.4 Results and Discussion . . . 61
4.4.1 Effects of Neuromodulated Learning . . . 61
4.4.2 Structural Role of Neuromodulation . . . 66
4.4.3 Scalability Experiments . . . 68
4.5 Contributions to JBotEvolver . . . 75
4.6 Summary . . . 75
5 Conclusions and Future Work 77 5.1 Summary and Contributions . . . 77
5.2 Future Developments . . . 78
5.2.1 Expanding the Neural Model . . . 78
5.2.2 Genetic Encoding and Genotype-Phenotype Mapping . . . 80
5.2.3 Calibrating odNEAT . . . 83
5.3 Summary . . . 83
A Simulation Platform 85 A.1 Major Requirements . . . 85
A.2 JBotEvolver . . . 86
A.2.1 Simulation Environment . . . 87
A.2.2 Robot Model . . . 89
Abbreviations 91
Index 107
2.1 A classification scheme for evolutionary robotics approaches. . . 11
2.2 Common non-linear neuron activation functions: (a) Hyperbolic tan-gent, and (b) Sigmoid. . . 17
2.3 Example of a neural network with two input neurons, three hidden neurons, and two output neurons. . . 17
2.4 Recurrent and feedforward neural network architectures . . . 18
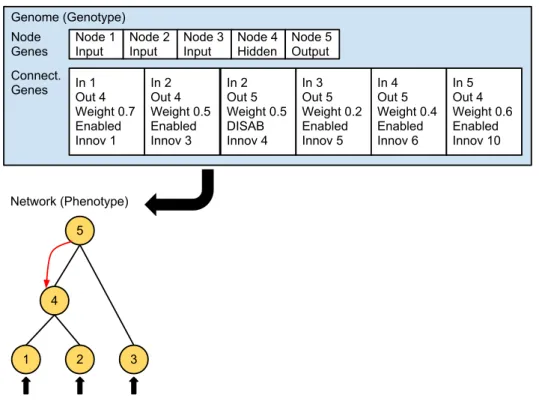
2.5 The variable length genome problem . . . 24
2.6 A NEAT genotype to phenotype mapping example . . . 25
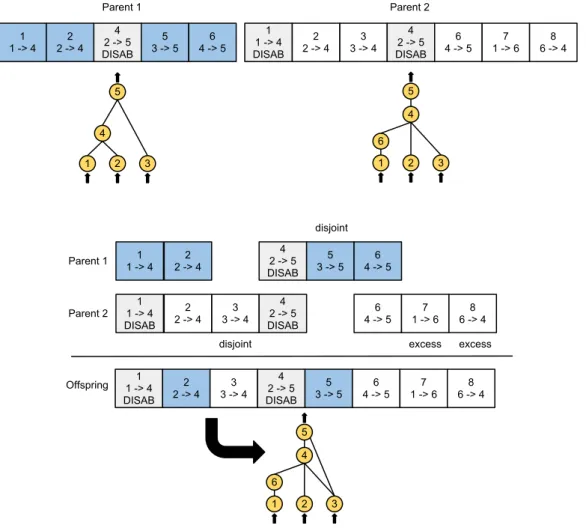
2.7 Matching up genomes for different network topologies in NEAT . . . 26
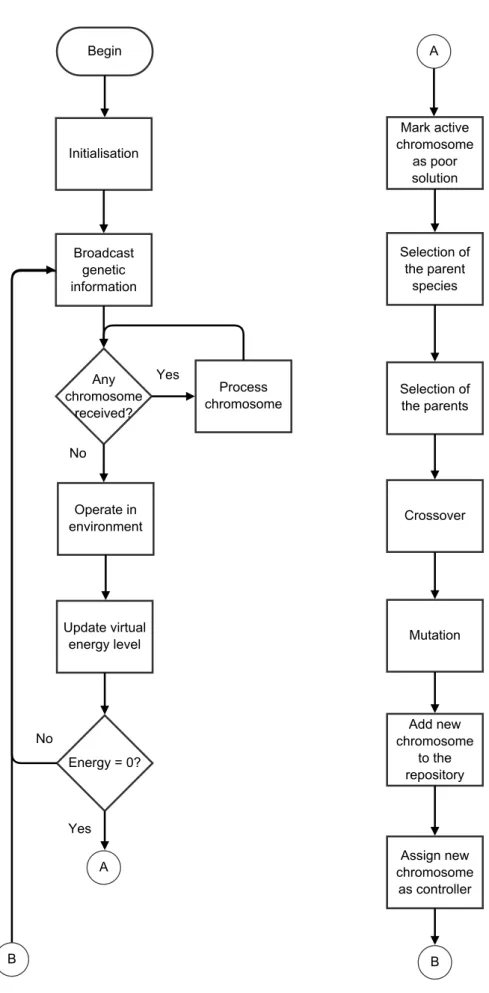
3.1 odNEAT’s flow diagram . . . 36
3.2 The e-puck robot. . . 42
3.3 Group clustering behaviour in the aggregation task . . . 45
3.4 Individual search strategies in the aggregation task . . . 46
3.5 Experimental results with a group of five robots in the aggregation task 47 3.6 Distribution of average evaluations in the aggregation experiments with five robots. . . 47
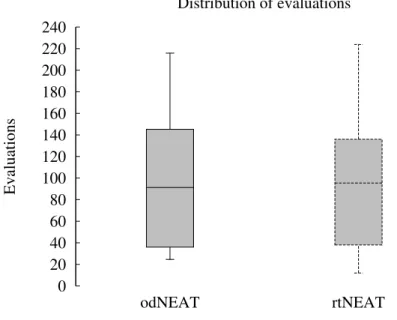
3.7 Distribution of evaluations. odNEAT vs rtNEAT in the aggregation experiments with five robots. . . 48
3.8 Example of a network evolved by odNEAT in the aggregation task . . 49
3.9 Distribution of evaluations in the aggregation scalability experiments 52 4.1 A neuromodulated network . . . 57
4.2 Distribution of evaluations for pd = 9m . . . 62
4.3 Distribution of evaluations for pd = 90m . . . 63
4.4 Distribution of evaluations for pd = 900m . . . 63
4.5 Comparison of performance for odNEAT with and without neuro-modulation in the concurrent foraging task . . . 64
4.6 The best two runs for odNEAT with neuromodulation in the setup pd = 9 mins . . . 65
4.7 Evolved foraging behaviour for pd = 9 mins. . . 68
4.8 Distribution of evaluations in the foraging task scalability experiments 69
4.11 Distribution of chromosomes received for group sizes of 5 and 8 robots. 73 4.12 Tracking the genetic origin of each produced controller in a two robot
evolutionary run (concurrent foraging task). . . 74 4.13 Distribution of matching genes in dissimilar solutions. . . 75
A.1 Components of the JBotEvolver simulation platform . . . 88
3.1 Experimental parameters for the aggregation experiments . . . 44 3.2 Summary of the experimental results with a group of five robots in
the aggregation task . . . 46 3.3 Performance comparison between odNEAT and rtNEAT . . . 48 3.4 Summary of the topological complexity added by odNEAT and
rt-NEAT in the aggregation task . . . 49 3.5 odNEAT ablations summary . . . 50 3.6 Environment size for each experimental configuration in the
aggrega-tion task . . . 51 3.7 Summary of the scalability experiments in the aggregation task . . . 52 3.8 Outliers within a subset of the scalability experiments . . . 52
4.1 Energy value of each food item in the concurrent foraging task . . . . 59 4.2 Summary of the experimental results for odNEAT with and without
neuromodulation in the concurrent foraging task . . . 62 4.3 Performance of the two controllers synthesised faster by odNEAT
with neuromodulation for pd = 9 mins . . . 66
4.4 Summary of the complexity added by odNEAT with and without neuromodulation in the concurrent foraging task . . . 66 4.5 Summary of the most stable controllers in the concurrent foraging task 67 4.6 Summary of the specialised neurons for the best solutions of each
evolutionary run. . . 67 4.7 Summary of the scalability experiments in the concurrent foraging task 69 4.8 Summary of the complexity to the initial topology of each stable
controller for different group sizes . . . 71 4.9 Summary of the genetic information in each robot’s repository . . . . 71 4.10 Summary of the genetic information regarding dissimilar stable
con-trollers . . . 73
Introduction
This thesis is on the subject of online synthesis of behavioural control for autonomous robots. In this first chapter, we start by presenting our motivation and the main objectives. We then describe the scientific context in which ideas and development took place. Finally, we provide an overview of the thesis structure and the scientific publications produced.
1.1
Motivation
Evolutionary computation techniques have been widely studied and applied in the field of robotics as a means to automate the design of robotic systems [32]. In evolutionary robotics (ER), robot controllers are typically based on artificial neural networks (ANNs). The connection weights and sometimes the topology of the ANN are optimised by an evolutionary algorithm (EA), a process termed neuroevolution. Traditional evolutionary approaches have a number of shortcomings when evolv-ing robotic controllers. When a suitable neurocontroller is found, it is deployed on real robots. Since no evolution or adaptation takes place online, the controllers are fixed solutions that remain static throughout the robot’s lifetime. If environmental conditions or task parameters change with respect to those encountered during of-fline evolution, the evolved controllers may be incapable of solving the task as they have no means to adapt.
Online evolution is a process of continuous adaptation that potentially gives robots the capacity to respond to changes in the task or in environmental conditions by modifying their behaviour. An evolutionary algorithm is executed on the robots themselves as they perform their tasks. The main components of the evolutionary algorithm (evaluation, selection, and reproduction) are carried out autonomously by and between the robots without any external supervision. This way, robots may be capable of long-term self-adaptation in a completely autonomous manner.
Online evolution provides the ability to address a new class of problems, i.e.,
problems that require online machine learning or online adaptation. The long-term goal of the field is to provide continuous online adaptation by combining the ability to address the task specified by the human supervisor, i.e., the goal, with a priori unknown or dynamic environmental constraints. Since robots operate in the real-world, the environment and other task-related conditions may be subject to continuous changes. Through interaction and disturbances by other robots, humans, or changes in the environment, control structures or functions may become obsolete or improper for the current task. Especially in dynamic scenarios, the requirements to fulfil a given task, defined in the fitness function, are subject to changes which are often hard to predict or that may occur randomly. In this respect, the potential benefits and perspectives of online evolution as a means to achieve truly open-ended adaptation in multirobot systems are numerous:
• Online evolution, being a continuous adaptation process, has the potential to continuously generate novel behaviours in response to changes in the task-requirements and/or in the environment.
• Through online evolution, robots can learn to become fault-tolerant and to self-repair through self-reconfiguration. For example, consider a two-wheel robot with a gripper. The robot’s task is to find and transport objects. If one of the wheels does not rotate as much as it should due to a mechanical issue, the robot can learn to adjust the wheel controller, i.e., to adjust the set of instructions that are sent to the wheel, and therefore execute the desired navigation behaviour. If the gripper breaks, the robot can learn to push objects as a means to move them around.
• Online evolution has the promise of leading to extremely adaptive and evolv-able robotic systems, allowing robots to learn how to self-reconfigure without human supervision and to continuously develop new, previously unforeseen, functionalities.
1.2
Research Objectives
The objectives of the research presented in this dissertation are the following:
• To establish a principled approach towards the realisation of truly adaptive multirobot systems, that can ultimately be implemented and validated on real robotic hardware.1
1The implementation and validation on real robotic hardware is not considered part of this
dissertation. Our main focus of research is to study the properties and requirements for developing a suitable adaptive algorithm.
• The developed approach should allow a collective of robots to evolve and adapt autonomously, i.e., without any kind of external supervision or interaction during the adaptation process.
• Since there are typically multiple robots in the environment, we intend to explore and exploit the inherent possibilities of adaptation in multirobot sys-tems. We want to devise a methodology in which robots exchange information in order to help each other adapt.
1.3
Context
The work developed in the context of this informatics engineering project (PEI) falls into the field of Evolutionary Robotics, a sub-field of Artificial Life. This dissertation is a joint scientific supervision between members of two research groups:
• Paulo Urbano2 for LabMAg3 – Laboratory of Agent Modelling, Faculty of
Sciences of the University of Lisbon (FC-UL);
• Anders Lyhne Christensen4 for the Institute of Telecommunications5 – Lisbon
University Institute (ISCTE-IUL).
The work took place in the facilities of LabMAg, a multi-disciplinary research unit certified at the Foundation for Science and Technology (Funda¸c˜ao para a Ciˆencia e Tecnologia) of Portugal. The scientific area of LabMAg is Artificial Intelligence with special focus in the concept of agent and multi-agent systems.
1.4
Thesis Overview and Contribution of Research
In this section, we provide an overview of the thesis structure and the scientific publications produced during this dissertation. In Chapter 2, we review the state-of-the-art on the distinct subjects relevant to this dissertation. The chapter is divided into five sections that are dedicated respectively to collective evolutionary robotics, online evolution of robot controllers, artificial neural networks, and learning with neuroevolution.
In Chapter 3, we focus on online evolution of both neural network topologies and weights. More specifically, we propose and evaluate a novel approach called Online Distributed NeuroEvolution of Augmenting Topologies (odNEAT), an online, distributed, and decentralised evolutionary algorithm for online evolution in groups
2 http://www.di.fc.ul.pt/~pub 3 http://labmag.ul.pt 4 http://home.iscte-iul.pt/~alcen/ 5 http://www.it.pt
of embodied agents such as robots. This work was published as a full paper, and selected for oral presentation [108]:
• F. Silva, P. Urbano, S. Oliveira, and A.L. Christensen. odNEAT: An Algo-rithm for Distributed Online, Onboard Evolution of Robot Behaviours. In Thirteenth International Conference on the Simulation & Synthesis of Living Systems (Artificial Life XIII), pages 251–258. MIT Press, Cambridge, MA, 2012.
1st place for the Best Paper Award in the Collective Dynamics track.
In Chapter 4, we extend odNEAT to incorporate neuromodulation, a form of learning that allows agents controlled by artificial neural networks to learn from experience by dynamically changing their internal synaptic strengths during task-execution. Parts of this study were published as a full paper and selected for oral presentation [106]:
• F. Silva, P. Urbano, and A.L. Christensen. Adaptation of Robot Behaviour through Online Evolution and Neuromodulated Learning. In Thirteenth Ibero-American Conference on Artificial Intelligence (IBERAMIA 2012). Springer-Verlag, Heidelberg, in press, 2012.
The studies were extended with experiments involving more complex multirobot setups. The result was a full paper selected for oral presentation [107]:
• F. Silva, P. Urbano, and A.L. Christensen. Continuous Adaptation of Robot Behaviour through Online Evolution and Neuromodulated Learning. In Fifth International Workshop on Evolutionary and Reinforcement Learning for Au-tonomous Robot Systems (ERLARS 2012) in conjunction with the 20th Euro-pean Conference on Artificial Intelligence (ECAI 2012). Montpellier, in press, 2012.
In Chapter 5, we present a summary of our contributions, and discuss directions for future work.
Background
This chapter includes a broad range of subjects relevant to this dissertation. The subjects are presented in a top-down fashion. First, we introduce the reader to evolutionary robotics with a focus on the synthesis of collective behaviour. We then present and discuss the state of the art in online evolution, the core subject of this dissertation, in which robots adapt while operating in the task-environment. Afterwards, we introduce fundamental concepts regarding artificial neural networks theory, and how these models can be applied for behavioural control in robotics. We then present and discuss the most prominent methods in the field of neuroevolution, artificial neural networks optimised through evolutionary algorithms. We review recent developments on fixed-topology and constructive neuroevolution algorithms. In addition, we provide details about one of the more promising approaches, NEAT, that will serve as a focus of investigation for this dissertation.
2.1
Collective Evolutionary Robotics
The utilisation of various robots provides several advantages over single robot sys-tems. For instance, the application of various robots to solve a particular task can include a reduction in total system cost due to the utilisation of multiple simple and cheap robots as opposed to a single complex and expensive robot. Multiple robots can increase the system’s flexibility, robustness, and efficiency by making use of inherent parallelism, division of labour strategies, and redundancy: if one or more robots fail, the system as a whole may continue to work in spite of some of its parts are no longer available. The inherent complexity of some environments may also require the use of multiple robots in order to meet the task-requirements [62].
Constructing tools from a collection of individuals is not a novel endeavour for man. A chain is a collection of links, a rake a collection of tines, and a broom a collection of bristles. Sweeping the sidewalk would certainly be difficult with a single or even a few bristles. Thus
there must exist tasks that are easier to accomplish using a collection of robots, rather than just one.
Kube and Zhang, [71]
Within the context of robotics, certain tasks are easier to accomplish using a group of robots rather than just a single robot. Examples of tasks requiring a group of robots are collective patrolling, searching, and foraging tasks. Foraging extends the searching task by requiring the robots to search, but also to pick up or acquire the objects, and in some cases to deposit them at a goal location. All these tasks could arguably be performed by a single robot, but it would be extremely inefficient. For instance, in the collective patrolling task, several robots are able to cover a larger area in comparison to a single robot with the same features.
In multirobot systems, however, the difficulty increases when the individuals are somewhat autonomous, and there lies the challenge. How can one create an intelligent task-achieving collective behaviour from a group of simple robots?
2.1.1
Introduction to Evolutionary Robotics
The advent of Genetic Algorithms (GAs) [54, 55] in the 1960s – see also [38, 39, 40] for other evolutionary algorithms’ roots – as a computational abstraction of Darwin’s theory of evolution [18] promised to transfer the richness and efficiency of living organisms to artificial agents such as autonomous robots. This envisioned future inspired a whole field of research, now called Evolutionary Robotics (ER) [33, 92].
ER is a methodology for the automatic creation of robotics hardware and/or con-trol software through evolutionary computation techniques such as neuroevolution, the technique we use in this work. Interests in ER have focused on two directions. One direction of studies is concerned with cognitive science and psychology [51]. The second direction focuses on the use of evolutionary techniques as an engineer-ing tool. Our interest lies the latter category. The long term goal is to obtain an automatic process capable of designing, building, and even maintaining, an opti-mal robotic system given only the specification of a task, in order to bypass the difficulty in manually designing controllers for autonomous robots. This difficulty, present even when the task is simple, is explained by the fact that the robot’s be-haviour is an emergent property of the dynamic interaction between the robot and its environment.
Although applying Evolutionary Computation (EC) techniques in order to evolve robotic controllers, there is an important difference between the robotic and the nor-mal engineering approach to EC. In the latter, the evolutionary process is functional: it consists on optimising a number of parameters for a well-defined control problem in a predictable environment with known properties. In ER, the spectrum is wider as
the goal is to evolve the behavioural control for autonomous robots in unpredictable, dynamic, or partially unknown environments. The system should be composed of robust machines that are capable of exploiting the non-linear dynamics offered by their structure and their environment without having to model them explicitly.
2.1.2
Fitness Function
The fitness function is at the heart of ER. It is responsible for determining which controllers within a population are better at solving the particular problem at hand. The successful evolution of intelligent autonomous robot controllers is there-fore intimately dependent on the formulation of suitable fitness functions [89]. In works/studies attempting to evolve autonomous robot controllers capable of per-forming complex tasks, the fitness function (and the bootstrap problem) is often the limiting factor in achievable controller quality so it must be carefully designed.
In [36], the authors define a 3D space for the classification of fitness functions for different evolutionary objectives:
• The functional-behavioural dimension indicates whether the fitness function considers the behavioural outcome or the specific function of the controller. A purely functional fitness is based only on components that directly measure the way in which the system functions. For example, while evolving a neural controller for a walking robot, a functional fitness could measure the frequency and amplitude of the oscillations of the evolutionary controller. On the other hand, a purely behavioural fitness is based only on components that measure the behaviour of the individual’s behaviour. Considering with the same ex-ample of the walking robot, a behavioural function would be proportional to the distance covered by the robot in a given amount of time. Another way of describing the difference between these two fitness extremes is that functional fitness evaluates the causes of behaviour whereas behavioural fitness evaluates the effects of the behaviour.
• The explicit-implicit dimension specifies the number of components, variables and constraints in the fitness function. An explicit fitness function is charac-terised by having many components. On the other hand, an implicit fitness function has few components.
• The external-internal dimension refers to availability with respect to the robot of the variables that compose the function. In order words, the dimension along the external-internal continuum indicates whether the agent relies on global or local state information. An external fitness function includes global information that in reality cannot be accessed by an autonomous robot. An
internal fitness function includes only local state information that is available through the robot’s sensors.
In general, fitness functions for engineering purposes are located in the functional-explicit-external part of the 3D space, and require human expert knowledge. In contrast, and ideally, fitness functions for ER should be located in the behavioural-implicit-internal part, and therefore require little domain knowledge, because such criteria may lead to autonomous self-organisation [36].
In this work, we follow a functional/behavioural-implicit-internal approach. The fitness function is either functional or behavioural depending on which dimension is more suitable for the task we want robots to learn. In respect to the number of components, we keep the constraints as low as possible by simply accumulating the fitness score during each of the robot’s sensory-motor cycle, and therefore follow the implicit dimension. The fitness functions follow the internal dimension as each robot only has access to local information. In other words, the system is self-contained because it does not require any external devices in order to assess its states and performance.
2.1.3
Background on the Evolution of Collective Behaviour
In the last 20 years, the use of ER methods for the development of group be-haviours has increased. Among the first to study collective bebe-haviours were Werner and Dyer [132]. In their work, they studied populations of artificial organisms that evolved simple communication protocols for mate finding. Shortly after, Reynolds [100] evolved a vision-based behavioural model of coordinated group motion of a group of creatures called critters. Critters required to avoid obstacles and a manually pro-grammed predator. Both these pioneering works confirmed that artificial evolution can be successfully used to synthesise controllers for collective behaviours.
A truly remarkable work was reported in [97], the first example of the use of artificial evolution to design coordinated, cooperative behaviour for three robots. The robots were evolved to perform a formation-movement task without losing con-tact with each other, starting from random initial positions and equipped only with minimal infrared sensors. The analysis of the evolved behaviour showed that, after an initial coordination phase, the robots assumed different roles depending on their relative position and their history of interactions between each other. This role al-location was not defined a priori but instead emerged from the interactions among the robots.
Another example of collective behaviours developed by evolving in simulation and successfully testing on real robots was presented in [90]. The authors studied the evolutionary training of ANN controllers for competitive playing behaviours by teams of real mobile robots. In this game, a robotic version of the game Capture
the Flag, each team tried to defend its own goal while trying to ’attack’ another goal defended by the opposite team. Robot controllers were evolved in a simulated environment using evolutionary training algorithms and relied entirely on processed video data for sensing of their environment.
2.2
Online Evolution of Robot Controllers
A number of studies in ER aim at developing mechanisms that explicitly use evo-lution online, and recurring to the robot’s (limited) computational resources, on-board [11]. Performing this type of evolution, however, is difficult and implies two major restrictions: (i) robots must able to evaluate in vivo the quality of any given controller, which can only be done by allowing the controller to take over the robot and perform the specified task, and (ii) all necessary computation must be performed onboard (by the robots themselves), considering its limited processing power and storage capabilities. In collective domains, problems accentuate. Controllers being optimised at a given time may cause a robot to perform disruptive actions that disturb or interfere with the rest of the collective, or may simply not collaborate towards the common goal.
In this section, we review and discuss the state of the art in online evolution of ANN controllers in both single and multirobot systems. Before we proceed with the discussion, we categorise the evolutionary process considering when it happens, where it happens, and how it happens.
2.2.1
Classifying the Evolutionary Process
The classification scheme proposed in [26] is concerned with three features of the evolutionary process, namely the temporal (when), spatial (where), and procedural (how) perspectives as described below:
• offline or design time vs online or runtime (when), • onboard or intrinsic vs offboard or extrinsic (where), • encapsulated vs distributed vs hybrid (how).
Within the mentioned above perspectives, we focus on an online, onboard, and hybrid evolutionary approach. The features of the evolutionary process are described as follows.
Temporal perspective: offline vs online
In offline evolution, the synthesis of robot controllers takes place before the robots start operating in the environment. Controllers are synthesised in simulation and
then transferred to robots post-evolution. Offline evolution is frequently used be-cause it is usually less expensive (there is no robot hardware, and therefore no damage is caused to the robots by experimentation), and allows the researcher to concentrate on developing the control method rather than the engineering issues that often surface with physical robots.
Although the extensive use, offline evolution presents a major drawback when evolving robot controllers. Once controllers are deployed into real robots, they are specialised to a particular task and environmental conditions. Since no adaptation usually takes place online, controllers are fixed solutions and exhibit limited capacity to adapt to environments and to tasks not seen during evolution. The adaptive behaviour acquired from offline synthesis may not be strong enough to handle the unpredictable real-world environment, and cause the robot to take undesired actions in respect to the task-requirements.
Online evolution, on the other hand, is a process of continuous adaptation that potentially gives robots the capacity to respond to changes in the task or in environ-mental conditions by modifying their behaviour. An EA is executed on the robots themselves as they perform their tasks (although offline evolution might precede online evolution as an educated initialisation procedure). This way, robots may be capable of long-term self-adaptation as their behaviour can be gradually improved by continuously learning from the environment.
Procedural perspective: encapsulated vs distributed vs hybrid
From the procedural perspective, we consider how the evolutionary operators are managed. This scheme falls under two categories, distributed and encapsulated evolution. In the distributed approach, each robot carries a single genome and the evolutionary process only takes place when robots meet and exchange genetic information, which in turn leads to an iterative improvement of the population. However, frequent encounters between robots is difficult to guarantee, especially in large and open environments.
A complementary approach is encapsulated evolution. Each robot carries an isolated and self-sufficient evolutionary algorithm that maintains a population of controllers inside itself. The EA runs on a single robot and performs the fitness evaluation autonomously. This evaluation process is usually done in a time-sharing system. Each member of the population takes control of the robot for a certain amount of time, and its quality performing the task is measured. Encapsulated evolution can be extended to multiple robots where each robot is completely inde-pendent from the others. The iterative improvement of controllers is therefore the result of the EAs running in parallel and independently inside each robot.
be combined, leading to a hybrid system similar to an embodied island model [121]. In such a system, each robot acts like an island with genetic information being exchanged through intra-island variation (i.e., within the population of the encap-sulated EA in one robot) and inter-island migration (between two or more robots). The evolutionary is therefore self-sufficient based on encapsulated evolution, and possibly accelerated by the parallelism and exchange of genetic information among the robots resultant from distributed evolution.
Spatial perspective: onboard vs offboard
From the spatial perspective, we distinguish two cases: (i) the onboard case, where all necessary computation and the evolutionary operators such as selection, crossover, and mutation are executed by the robots themselves, considering its limited process-ing power and storage capabilities, and (ii) the offboard case, where both the required computation and the evolutionary operators are performed with the aid of exter-nal equipment outside the robots. An exterexter-nal component could be, for instance, a computer interfaced with the robots collecting fitness information from robots’ real-world operation and managing the evolutionary process, or simply performing necessary computation due to the robots hardware limitations.
Each robot is an island
Evolutionary Robotics Online evolution Offline evolution Offboard evolutionary operators Onboard evolutionary operators Encapsulated evolutionary operators Distributed evolutionary operators Crossover between robots Island-model evolution
Figure 2.1: Classification scheme proposed in [26] for evolutionary robotics ap-proaches.
In Fig. 2.1, we summarise the classification scheme described which established the common terms for further discussion on the subject of online evolution. In
the following section, we review the state of the art in respect to online evolution, discussing both the most recent and the most influential approaches.
2.2.2
Single Robot Systems
The work conducted by Floreano and Mondada was one of the very first attempts to online evolution of controllers: in [34, 35], the authors describe successful synthesis of navigation and obstacle avoidance behaviours on a Khepera robot. The evolutionary process consisted of optimising weights in a fixed-topology recurrent ANN through a generational EA. Evolution was conducted online, with necessary computation being performed on an offboard workstation that provided a significant improvement in computational and memory capacity. The offboard workstation managed the evolutionary operators for selection and variation and, at each time, injected a newly produced controller into the robot in order to assess its quality. The process is similar to a master-slave EA, with the slave calculating fitness and the master orchestrating evolution. The experiments conducted were a breakthrough in the sense that showed that it was indeed possible to perform online behaviour engineering. However, the major drawback was the fact that the evolutionary process was very time consuming and, in this case, lasted for 10 days.
In [85], the same authors described the evolution of a simple grasping behaviour. Experiments conducted previously were extended by adding graspable balls to the environment and a simple gripper to the robot. Synthesis of a gripping behaviour is moderately complex because it involves the use of sensors with different ranges: the gripper sensors are only relevant if the robot is close enough to grasp a ball. In spite of this development on the complexity of behaviours evolved online, the evolutionary process still required several days of continuous evolution, even after the gripper action was reduced to a fixed action pattern in order to minimise complexity of the task. At this point, researchers started to pay attention to the challenges of evolving on physical robots with a special concern on the prohibitively long time required to conduct evolution on physical systems [78].
2.2.3
Multirobot Systems
Advances in distributed evolution – Embodied Evolution
In [129, 130] a new methodology entitled Embodied Evolution (EE) was presented. EE was the first attempt at truly autonomous online evolution in multirobot systems. EE is an online, onboard and distributed EA that allows the speed-up of evaluation time in physical systems by utilising the parallelism inherent to a population of physical robots that evolve together while situated in the task-environment.
weights. Each robot maintains a virtual energy level, constrained by a minimum and maximum values, a fitness score reflecting the individual task performance. At each behavioural cycle, two main actions are executed. First, the fitness is updated depending on the robot’s task execution. After that, robots may exchange genetic material. Each robot probabilistically broadcasts a part of its (mutated) genes at a rate proportional to the fitness (Probabilistic Gene Transfer Algorithm, PGTA, a variation of the Microbial Genetic Algorithm [50]). If a robot broadcasts a gene string, the fitness score is decreased by a constant amount, a penalty in analogy to reproduction costs. Robots that receive gene transmissions incorporate this genetic material in their genome at a rate inversely proportional to their fitness. This way, selection and variation (reproduction) operators are implemented in a distributed manner through the interactions between robots.
In Algorithm 1, we show the pseudo-code of the control program that implements the PGTA, an asynchronous and distributed embodied EA which can be executed directly on real robots without the need of external supervision. indexof and valueof return the locus and value of the received gene, respectively. limit bounds the energy value between the minimum and maximum energy levels. random returns an integer value in the range of its argument. The task specific behaviour includes reading sensor values, updating network outputs, setting motor speed/directions accordingly, and all behaviours related with the task itself such as monitoring performance and setting the values of reward and penalty.
Algorithm 1 Pseudo-code of the control program that implements the PGTA and runs independently on every robot [129].
initialise genes() energy ← min energy loop
if excited? then
send(genes[random(num genes)] + mutation) end if
if received? AND receptive? then
genes[indexof (received)] = valueof (received) end if
do task specific behaviour
energy ← limit(energy + reward − penalty) end loop
A variant of the Embodied Evolution scheme was implemented in [134] in a predator-prey scenario. The interplay of evolution and lifelong individual learning, through isotropic-sequence-order learning using input correlations only [95], was in-vestigated as a mean of providing adaptability to novel environmental conditions. Each robot had a maturation period during which no mating/replacement can take
place. This mechanism allowed robots to adapt using individual learning before being subject to any selective pressure. However, within the authors’ experimental framework, the effects of learning were not significant. Considering both approaches mentioned above, the main disadvantage is the fact that the embodied evolution was dependent on the exchange of genetic information among the robots. In large envi-ronments, where such encounters may be rare, the evolutionary process is therefore prone to stagnation.
Advances in encapsulated evolution – The SYMBRION Project
The SYMBRION project1aims at adaptation and evolution for symbiotic multirobot
organisms [4]. In scientific terms, SYMBRION has been one of the main drivers of online evolution in general, and encapsulated evolution in particular. The initial efforts of the project were dedicated to establishing a principled taxonomy for online evolution, such as that described in Sect. 2.2.1, in order to provide a unified context for long term research in the field [26, 103].
In [45], the authors proposed an algorithm for encapsulated online evolution of robot controllers, the (µ + 1) ONLINE algorithm, which employs a time-sharing mechanism where individuals are evaluated sequentially by being given control of the robot and measuring robot performance during a pre-defined evaluation period. The algorithm was tested for the ability to address distinct challenges inherent in online evolution, such as noisy evaluation conditions and production of acceptable solutions in acceptable time, in an integrated navigation and obstacle avoidance task in a maze-like environment. Shortly after, in [27], it was argued the importance of the mutation operator as the most influential factor to govern evolution in the (µ + 1) ONLINE algorithm. Distinct self-adaptive parameter control mechanisms were tested and evaluated in three tasks: integrated navigation and obstacle avoid-ance, phototaxis, and resource gathering. Results obtained were not fully consistent over the tasks considered but yet supported an increased performance through a de-randomised self-adaptive mutation step size control mechanism.
Recently, in [44], racing was proposed as a technique to cut short the evaluation of poor individuals before the regular evaluation period expires. During a given controller evaluation period, an intermediate fitness is estimated and compared with the worst fitness in the population. If the performance drops below this lower bound, the evaluation is aborted and a new iteration of the algorithm commences. Racing was shown to allow an increase of the number of individuals evaluated per time unit, and, at the same time, also increased the robot’s actual performance by virtue of
1The SYMBRION project is an EU funded FET started in January 2008, for the duration
of five years, under grant agreement 216342. A complete description of SYMBRION project is available at: www.symbrion.eu.
abandoning controllers that perform inadequately. Experiments were conducted in three tasks: integrated navigation and obstacle avoidance, collective patrolling, and balancing.2
Advances in hybrid evolution
Distinct approaches have been proposed for accomplishing hybrid (encapsulated and distributed) online evolution in multirobot systems. An example of such a method is the one presented in [30]. In that study, robots have to gather batteries while maintaining a virtual energy level that reflects their task performance. If a robot’s energy level reaches 0, offspring is created by mating the current controller with one of the genomes collected during lifetime. In [126], six Khepera robots evolved an avoidance behaviour. Each physical robot ran an independent EA for a sub-population of virtual agents, evaluated by time sharing. Migrated genomes, broadcasted by other robots, were re-evaluated by the receiving robot.
An interesting approach was proposed in [96], the Real-time Asynchronous Sit-uated Co-evolution (r-ASiCo) algorithm. r-ASiCo is based on a reproduction mech-anism entitled Embryo Based Reproduction (EBR). The idea behind EBR is that each robot carries, in addition to its own controller parameters (a fixed-topology ANN), another set of parameters corresponding to an embryo and an associated pre-utility value for the embryo that estimates the utility of the controller generated from it. During the lifetime of a controller within a robot, the embryo is modified whenever the robot meets another robot and evaluates it positively (accepted can-didate). When the parent controller dies as a result of being unable to accomplish the task, the embryo substitutes the parent by assuming the control of the robotic unit, and a new embryo is generated.
Recently, researchers in the project SYMBRION have also focused their atten-tions on hybrid online evolution. In [58], a hybrid online onboard algorithm based on EVAG [73], a peer-to-peer evolutionary algorithm, and the (µ + 1) ONLINE algorithm, was proposed. Results showed that the hybrid evolutionary scheme con-sistently presents better performance than both the encapsulated and the distributed case. Hybrid evolution has shown to efficiently harness the parallelism of the adap-tation process over multiple robots while performing well even for small numbers of robots. Afterwards, in [131], in a contribution concerning self-assembly of robots through evolution, the same algorithm was used as a means to promote the emer-gence of large organisms in an environment which favours the survival of modules that are part of an organism. An intriguing aspect is the fact that self-assembly
2The balancing task is conceptually similar to pole balancing or inverted pendulum, with an
increase in difficulty because the robot’s movement is performed in two dimensions rather than just one.
was completely induced by environmental pressure, i.e., without the need for a spe-cific fitness function to promote aggregation, which to some extent goes towards the aspects discussed in Sect. 2.1.2. In the context of the project, the trade-off be-tween achieving survival, and optimising goal-oriented behaviours was also studied in [12], where the emergence of consensus towards specific behavioural strategies was examined.
2.3
Artificial Neural Networks
Artificial Neural Networks (ANNs) are a computational processing paradigm in-spired by the structure and function of biological nervous systems [52]. ANNs are able to approximate any continuous function in theory [17], which makes them a powerful tool for control and prediction. In this section, we introduce the terminol-ogy used in this work and provide examples of different neural network structures.
2.3.1
Neurons and Activation Functions
A neural network consists of one or more interconnected fundamental processing units denominated nodes or neurons. To each neuron n in the network is associated a number of inputs x1, x2, ..., xi and one output y. Each input xi has a weight wi, and
w0 specifies the weight of a bias input x0 = 1. Each neuron n computes its activation
value an, a weighted sum of the input values. an is then subject to an activation
function f that computes the neuron’s output value y, usually by mapping an to a
value between 0 and 1. Therefore for every neuron n, its output value y or activation is given by the following expression:
y = f (X
i
wi· xi) (2.1)
A neuron’s activation function can be chosen by the experimenter in order to suit the needs of a system. However, the utility of an ANN lies in the fact that they can be used to approximate a function from observations. This is the case in learning and optimisation tasks, where neural networks are commonly employed. For a neural network to be able to linear functions, it is necessary to use non-linear activation functions. It is the non-non-linear activation function that allows such networks to compute non-trivial problems using only a small number of neurons. In Figure 2.2 are shown two popular non-linear activation functions, which we use in this dissertation. The hyperbolic tangent is a classic mathematical function. The sigmoid function is given by the following expression:
f (an) =
1
(a) (b)
Figure 2.2: Common non-linear neuron activation functions: (a) Hyperbolic tangent, and (b) Sigmoid.
2.3.2
Artificial Neural Network Architectures
Different network architectures have different capabilities. In this section, we present some of the common types of ANNs that we will use in later chapters.
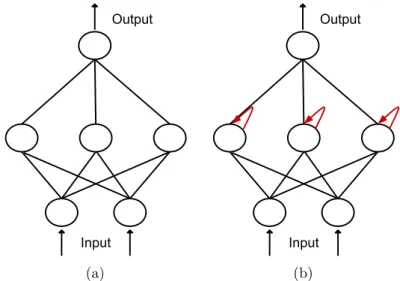
As previously mentioned, a neural network consists of one or more connected neurons. While some neurons are connected to an external environment through inputs and outputs, it is also possible to design ANNs with one or more hidden layers of neurons, which are used when it is necessary for the network to represent more complex functions.3 An example of a network with hidden layers is illustrated
in Figure 2.3. Each neuron in a hidden layer, a hidden neuron, receives the outputs of the neurons in the previous layer and then provides inputs to the neurons in the following layer. Therefore, hidden neurons do not interact directly with the environment as they do not received inputs directly, and their output values are transmitted to other neurons and not to the environment.
Input Output
Figure 2.3: Example of a neural network with two input neurons, three hidden neurons, and two output neurons.
3In fact, networks without hidden neurons cannot compute any logical function that is not
A neural network where the information moves in only one direction, i.e., starts at the input neurons and is propagated straightforward to the outputs is called a feedforward network. While these networks are sufficient to calculate functions with static temporal behaviour, several problems require memory, i.e., to recognise temporally extended patterns in input sequences such as the latching problem or the grammatical inference (tree automata) problem [74]. One of the ways to implement memory in neural networks is to have recurrent connections, feedback connections to a given neuron. In [74, 101] is described how recurrent networks can be useful for learning temporal dependencies. In Figure 2.4, we resume the mentioned neural architectures. Input Output (a) Input Output (b)
Figure 2.4: Neural network architectures. Red lines represent recurrent connections, black lines are feedforward. (a) A fully-connected single hidden layer feedforward network. (b) A recurrent network. Each hidden unit feeds activation back into itself.
Another form of implementing memory in neural networks is by introducing a new type of neuron known as context unit or memory unit, as in Jordan net-works [63], and Elman netnet-works [31].
2.3.3
Measuring the Complexity of Artificial Neural
Net-works
In this work, we use artificial neural networks with different topologies. As measure of neural networks’ complexity, we use the effective number of parameters in each network, Cfp, which is the sum of the number of connections and the number of
neurons (because each neuron has its own ’weight’, the bias value). This measure of complexity is used in a number of heuristics for the back-propagation algorithm to determine, for instance, a suitable size for the training set [52].
2.3.4
Artificial Neural Networks in Robotics
ANNs are an interesting paradigm for researchers in the field of autonomous robotics. Robots operating in the real-world are tightly coupled with the environment through simple, precise feedback loops. The world is sensed through usually noisy sensors, and ANNs provide an advantage since they are robust against noise. A complete controller can consist simply of an ANN, where the input values are the normalised values of the robot sensors (for instance, proximity or light sensors) and the output values control the robot actuators (e.g., the wheels).
In order to use ANNs as robot controllers, it is necessary to determine the type of neural network to use, its topology, and its weights. If a suitable topology is known, ANNs can be trained using gradient descent methods such a backpropagation [102]. Nonetheless, these methods can be trapped at local minima. In addition, gradient descent methods are not well suited to autonomous robotics as the feedback nor the output targets are available for every output iteration. To treat this problem, different studies have focused on neuroevolution. In neuroevolution, the connection weights and sometimes the topology of the ANN are optimised by an evolutionary algorithm (EA) in order to evolve suitable controllers.
2.4
Learning with Neuroevolution
Evolutionary Algorithms (EAs) are generic population-based meta-heuristic optimi-sation algorithms. The objective of EAs is to search through a parameter space for a set parameters that optimise some performance criterion. Nowadays, there are several flavours of EAs. Genetic Algorithms (GAs) [55] are typically used when the genotypes are strings of binary characters. Genetic Programming, proposed in [69] and extending ideas originally introduced in [16], is a branch of GAs in which geno-types are usually computer programs. Evolutionary Strategies are also a variation of the GAs in which mutation is driving force of the evolutionary process [7].
Neuroevolution uses EAs to optimise the weights and sometimes the topology of ANNs. The idea of using EAs as a means to automate the design of neural networks is not new and dates back, at least, to 1989 and the beginning of the 1990s [67, 48, 9, 43, 2]. In this section, we review some of the main developments on fixed-topology and constructive neuroevolution algorithms. We then describe one of the most prominent neuroevolution approaches, NEAT [118], which served as a focus of investigation for this dissertation.
2.4.1
Fixed-Topology Neuroevolution Algorithms
The early work on neuroevolution algorithms focused on optimising weights on fixed-topology networks, probably driven by the theoretical results showing that a neural network with a single hidden layer of neurons could approximate any function, given enough neurons [56]. Below we describe four of the most relevant approaches in the literature.
SANE: Symbiotic, Adaptive Neuro-Evolution
Symbiotic, Adaptive Neuro-Evolution (SANE) [86] takes a different approach to neuroevolution. The system evolves populations of neurons instead of populations of networks. Each population member represents therefore only a partial solution to the problem. During the evaluation stage, random neurons are selected from the population, and combined to form the hidden layer of a feedforward network. Each neuron receives the average fitness of all the networks it was included in. Multiple neurons are thus evaluated at the same time and rewarded for their gener-ality. By evolving individual neurons to cooperate in networks, SANE automatically maintains diversity in the neuron population. Since different types of neurons are usually necessary to solve a problem, networks with too many copies of the same neuron are likely to fail. This way, SANE allows for the emergence of specialised sub-populations and is not as susceptible to premature convergence as classic neu-roevolution algorithms.
ESP: Enforced Sub-Populations
Enforced Sub-Populations4 (ESP) [42] is an improvement of SANE that explicitly
divides an evolving population into separate sub-populations, one for each neuron in the evolving topology. Species do not self-organise since they are enforced from the start in an explicit niching scheme. In ESP, members from each population are combined together to form a complete network, which is then evaluated in the target task. Performance credit is divided between the neurons that contributed to the network. Since recombination only occurs between neurons of the same sub-population, each sub-population is forced to specialise into a sub-function for the network as a whole.
SANE was not capable of evolving recurrent neural networks as the neurons were selected randomly from the population and thus could not rely on being combined with similar neurons in different trials. The sub-populations of ESP resolve this
4In fact, the operation principle of ESP is similar to CCGA [19], a symbiotic evolution strategy
that, much like ESP, evolves specialised neurons on a set of islands, and whose members are not recombined with members from other islands.
problem and additionally allow for a higher amount of specialisation through the mentioned above constrained recombination.
CMA-ES: Covariance Matrix Adaptation Evolution Strategy
A distinct approach is the adaptation of the Covariance Matrix Adaptation Evo-lution Strategy (CMA-ES) algorithm, originally proposed in [46], to fixed-topology neuroevolution [59]. CMA-ES keeps track of correlations between changes in net-work weights and fitness scores. Based on this information, CMA-ES updates the covariance matrix of the weight mutation distribution so that it becomes more biased towards the most promising directions of search. CMA-ES has proven effective on distinct benchmark problems [59]. The main advantage of the method is the use of sophisticated methods to avoid premature convergence, and fast convergence to good solutions even with multi-modal and non-separable functions in high-dimensional spaces.
ENA: Evolving Neural Arrays
Evolving Neural Arrays (ENA) were proposed in [15] as a novel mechanism for learning complex action sequences. ENA employs a divide-and-conquer approach to solve complex tasks. Instead of synthesising one general and possibly complex neural network to solve a given task, a number of feedforward networks are used to solve related sub-tasks. Each array is composed by several neural networks synthesised through a custom evolutionary process involving as many stages as intermediate tasks. Each network Ni in a given array has the same input and the same output
neurons. Output neurons refer to the robot actuators, and the network confidence in handling the situation defined by the current set of inputs. ANNs in a given array are evaluated sequentially until a network outputs a confidence above some threshold, after which the remaining outputs are applied to the robot actuators. The first network in the array defines the default behaviour if no other network displays a confidence high enough to handle the current situation.
In [15], the authors compared the performance of ENA and SANE on various ob-stacle evasion and target reaching tasks of different complexity. ENA outperformed SANE, with the difference in performance being enhanced as the complexity of the problem increased. The main disadvantage of ENA is the incremental evolutionary strategy that requires a complex tasks to be divided into sub-tasks, therefore making the technique problem-dependent.
Comments on Fixed-Topology Algorithms
Fixed-topology neuroevolution algorithms have inherent limitations. The main issue is that the network topology has to be chosen a priori, and there is no universal
procedure for this action. Fixed-topology methods require a human to decide a suit-able topology for a given problem, which usually involves intensive experimentation. Choosing an inappropriate topology affects the evolutionary process: (i) Networks too large have extra weights, and each of these adds an extra dimension to the search space, and (ii) networks too small may be unable to represent solutions beyond a certain level of complexity, which potentially limits their performance.
In contrast to fixed-topology algorithms, constructive algorithms, or Topology and Weight Evolving Neural Networks (TWEANNs), evolve both the weights and the network topology. This way, constructive algorithms can discover an appropriate topology on their own. In addition, topology evolution can be used to increase efficiency and speed by keeping neural networks as small as possible, a strategy taken by the methods we describe in the following section.
2.4.2
Constructive Neuroevolution Algorithms
Neuroevolution algorithms that evolve both the topology and the weights of an ANN are denominated constructive algorithms, or Topology and Weight Evolving Neu-ral Networks (TWEANNs). Constructive algorithms are divided into two groups: (i) those that directly specify the neural architecture [65, 118], i.e., direct encoding, and (ii) those that use a method that indirectly specifies how the network should be constructed [43, 80, 117], i.e., indirect encoding. The simplest approach to construc-tive neuroevolution is to have the algorithm defining each part of an evolving neural network explicitly and directly, i.e., to have a direct encoding mechanism. Indirect encodings (also called generative or developmental encodings) are a relatively new area of research, incorporating concepts and mechanisms from developmental biol-ogy. In contrast with the direct encoding scheme, neural network representations can be much more compact, where the same genotype element can be reused to construct different parts of the phenotype. As we will not deal with indirect encod-ings, we will only describe some of the most relevant constructive direct encoding neuroevolution algorithms.
SAGA: Species Adaptation Genetic Algorithm
The SAGA method [49] is an extension to the classic Genetic Algorithm introduced to facilitate the open-ended evolution of increasingly advantageous behaviours on artificial systems. The approach enables genotypes to increase in length through ap-propriate mutation operators, and has been successfully exploited in the production of ANNs. In SAGA, both the ANN topology and weights are under evolutionary control, being encoded as variable length genotypes.
SAGA starts with simple networks with no hidden neurons. Complexity is then introduced incrementally through duplication, and differentiation of the duplicated
![Figure 2.1: Classification scheme proposed in [26] for evolutionary robotics ap- ap-proaches.](https://thumb-eu.123doks.com/thumbv2/123dok_br/15200190.1017987/35.892.229.663.595.985/figure-classification-scheme-proposed-evolutionary-robotics-ap-proaches.webp)