Optimal space-time coverage and exploration costs in groundwater monitoring networks
22
0
0
Texto
Imagem




+5
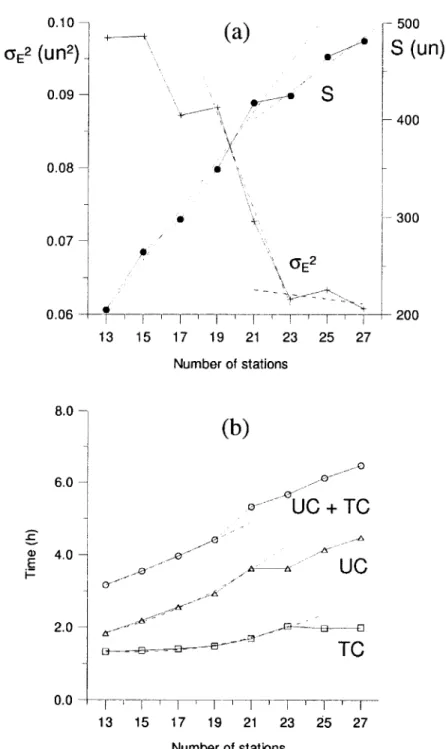
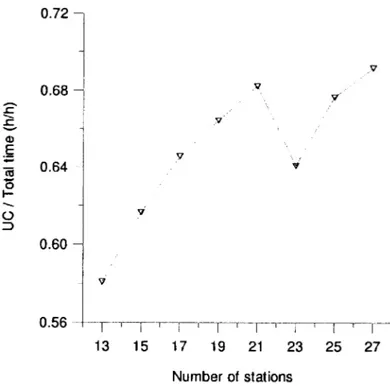
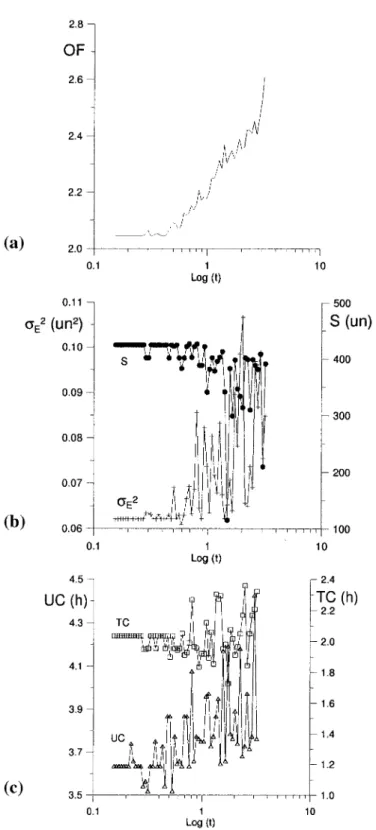
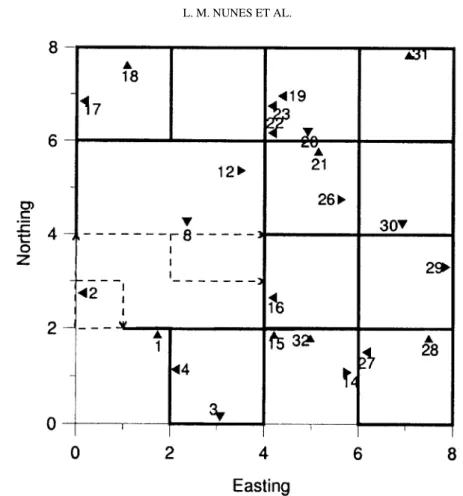
Documentos relacionados