FUNDAÇÃO GETULIO VARGAS
ESCOLA DE ECONOMIA DE SÃO PAULO
ANDRÉ PANARIELLO
TRADING POR ARBITRAGEM ESTATÍSTICA
SÃO PAULO
2016
ANDRÉ PANARIELLO
TRADING POR ARBITRAGEM ESTATÍSTICA
Dissertação apresentada ao Programa de Mestrado Profissional da Escola de Eco-nomia de São Paulo da Fundação Getulio Vargas, como requisito para a obtenção do título de Mestre em Economia.
Área de concentração: Finanças Quantitativas.
Orientador:
Prof. Dr. Juan Carlos Ruilova Terán
SÃO PAULO
2016
Panariello, André.
Trading por Arbitragem Estatística / André Panariello – 2016.
45f.
Orientador:Juan Carlos Ruilova Terán.
Dissertação (MPFE) – Escola de Economia de São Paulo.
1. Ações (Finanças). 2. Mercado de opções. 3. Modelos econométricos. 4. Operções com pares (Finanças). 5. Preços. 6. Análise de séries temporais. I. Ruilova Terán, Juan Carlos. II. Dissertação (MPFE) – Escola de Economia de São Paulo. III. Título.
ANDRÉ PANARIELLO
TRADING POR ARBITRAGEM ESTATÍSTICA
Dissertação apresentada ao Programa de Mestrado Profissional da Escola de Eco-nomia de São Paulo da Fundação Getulio Vargas, como requisito para a obtenção do título de Mestre em Economia.
Área de concentração: Finanças Quantitativas.
Data da Aprovação: 12/08/2016
Banca Examinadora:
Prof. Dr. Juan Carlos Ruilova Terán
(Orientador) FGV - EESP
Prof. Dr. Marcos Antonio Botelho
FGV - EESP
Prof. Dr. Rodrigo Arnaldo Scarpel
Agradecimentos
Ao Prof. Dr. Marcos Botelho pela indicação do tema, conhecimento, genialidade e principalmente pelo apoio nos momentos difíceis encontrados durante essa jornada. Ao Prof. Dr. Juan Carlos Ruilova Terán pela contribuição com a sua experiência no tema e pelo voto de confiança dado ao longo do curso. Ao Prof. Dr. Rodrigo Arnaldo Scarpel pelas sugestões e conhecimento na área. À minha mãe pelo apoio contínuo ao longo dos meus estudos e crença mesmo nos momentos mais difíceis. À Maria Clara pela paciência, companheirismo e compreensão nos momentos em que me fiz ausente. Aos amigos que fiz durante o curso pelos grandes momentos em que passamos juntos estudando. À Risk Office por acreditar e investir em meu desenvolvimento.
“Alguém está sentado na sombra hoje porque alguém plantou uma árvore há muito tempo.” (Warren Buffett)
RESUMO
Este trabalho propõe uma ferramenta para detectar oportunidades de arbitragem esta-tística (AE) em um par específico de ações no mercado brasileiro. A técnica baseia-se na construção de um ativo sintético que apresente característica de reversão à média. Os
forecasts serão realizados em forma de densidade de probabilidade condicional, elaborada
com base em técnicas econométricas como processos autoregressivos (AR) e variância con-dicional dos resíduos (GARCH). Será criado um sistema de trading capaz de se aproveitar das discrepâncias de preços observadas através da dinâmica do ativo sintético. A abor-dagem considerará preços em intervalos de um minuto e posições tomadas com ordens limitadas e a mercado. Ainda serão considerados custos de transação e análise do P&L para os casos abordados.
Palavras-chave: Arbitragem Estatística. Pairs trading. Ativo Sintético. Sistema de
ABSTRACT
This paper proposes a tool to detect statistical arbitrage opportunities in a particular pair of stocks in the Brazilian market. The technique is based on the construction of a synthetic asset that presents mean reversion process. The forecasts will be realized in the form of conditional probability density, which is based on econometric techniques such as autoregressive process (AR) and conditional variance of the residuals (GARCH). A trading system able to take advantage of mispricing observed by the synthetic asset dynamic is created. The approach will consider prices in one minute intervals and positions with limit orders and to market. Still be considered transaction costs and analysis of P&L for the cases addressed.
Keywords: Statistical Arbitrage. Pairs trading. Synthetic asset. Trading system. AR.
Lista de ilustrações
Figura 1 – Evolução dos preços de PETR3 e PETR4 - 04/01/2016 até 23/02/2016 27
Figura 2 – Log-Retornos Acumulados dos preços de PETR3 e PETR4 - 04/01/2016
até 23/02/2016 . . . 27
Figura 3 – Evolução do coeficiente βt - 04/01/2016 até 08/01/2016 . . . 28
Figura 4 – Evolução do Ativo Sintético Zt - 04/01/2016 até 08/01/2016 . . . 29
Figura 5 – Função Autocorrelação Amostral . . . 30
Figura 6 – Função Autocorrelação Amostral da Variância de Zt . . . 31
Figura 7 – Evolução ativo sintético e previsão . . . 33
Figura 8 – Evolução ativo sintético e bandas . . . 33
Figura 9 – Evolução ativo sintético realizado e previsão AR(2)- 04/01/2016 até 23/02/2016 . . . 34
Figura 10 – Variância realizada e GARCH(1,1) - 04/01/2016 até 23/02/2016 . . . . 35
Figura 11 – Realizacão do ativo sintético e bandas de probabilidade condicional b Zt+hL,α eZbt+hH,α - 04/01/2016 até 23/02/2016 . . . 35
Figura 12 – Preços por fechamento de minuto Bid and Ask - 04/01/2016 até 23/02/2016 36 Figura 13 – Log-Retornos Acumulados dos preços Bid and Ask de PETR3 e PETR4 - 04/01/2016 até 23/02/2016 . . . 36
Figura 14 – Sistema de Trading formado pelo ativo sintético e pelas bandas de trading - 04/01/2016 até 11/01/2016 . . . 37
Figura 15 – P&L Acum. do Sistema de Trading - 08/01/2016 até 23/02/2016 . . . 37
Figura 16 – Histograma e Boxplot do P&L por trade - 08/01/2016 até 23/02/2016. 39 Figura 17 – P&L Acum. com custos de transação do Sistema de Trading - 08/01/2016 até 23/02/2016 . . . 40
Figura 18 – Histograma e Boxplot do P&L por trade sem e com custos de transação - 08/01/2016 até 23/02/2016 . . . 40
Figura 19 – P&L Acum. do Sistema de Trading com ordens a mercado - 08/01/2016 até 23/02/2016 . . . 41
Lista de tabelas
Tabela 1 – Teste de Phillips-Perron . . . 29
Tabela 2 – Estimação processo AR . . . 30
Tabela 3 – Critérios de informação . . . 31
Tabela 4 – Estimação GARCH . . . 31
Tabela 5 – Critérios de informação variância . . . 32
Sumário
1 Introdução. . . 12
2 Preliminares teóricas . . . 15
2.1 Estimação dos Parâmetros . . . 15
2.2 Critérios de Informação. . . 15 2.3 Séries Temporais . . . 16 2.3.1 Estacionariedade . . . 16 2.3.2 Ruído Branco . . . 17 2.4 Processo Autorregressivo . . . 17 2.4.1 Previsão em um Processo AR . . . 18 2.4.2 Variância da previsão . . . 18
2.4.3 Intervalo de Confiança da previsão . . . 18
2.5 GARCH . . . 19
3 Identificação de discrepâncias na precificação de ativos . . . 20
3.1 Colocação do problema . . . 20
3.2 Dinâmica de ativos sintéticos bidimensionais . . . 21
3.2.1 Especificação do modelo . . . 22
3.2.2 Estimação dos parâmetros . . . 24
3.3 Sistema de trading . . . 24
4 Resultados. . . 26
4.1 Construção do modelo avaliado . . . 27
4.2 Operações com ordens limitadas . . . 35
4.2.1 Operações sem custos de transação . . . 36
4.2.2 Operações com custos de transação . . . 39
4.3 Operações com ordens a mercado . . . 40
5 Considerações finais . . . 42
12
1 Introdução
Desde a década de 1980, com o que pode ter sido o surgimento da arbitragem estatística, muitos traders tentam até os dias de hoje encontrar um modelo que possa lucrar com as chamadas distorções de preços no mercado financeiro. Em sua definição, a arbitragem estatística (AE) é a existência de uma discrepância estatística no valor esperado de um ou mais ativos. (AE) também pode ser classificada como uma estratégia que busca se aproveitar das anomalias momentâneas nos preços dos ativos financeiros. Uma maneira de se aplicar a arbitragem estatística é buscar distorções de preços entre pares de ações, onde os pares podem ser formados por ações da mesma companhia (ON versus PN), ações do mesmo setor (intra-setorial), ações de setores distintos (inter-setorial) ou até mesmo ações versus índices. A esse tipo de estratégia foi atribuído o nome de pairs
trading. Atualmente, o método de pairs trading é muito utilizado por investidores, bancos
e fundos quantitativos no Brasil e principalmente no exterior.
Conforme (VIDYAMURTHY,2004), a história mais citadada sobre o que poderia ter sido a primeira abordagem estatística de pairs trading nasceu em Wall Street e foi introduzida por um trader chamado Nunzio Tartaglia, que trabalhava no banco Morgan Stanley em meados da década de 1980. Tartaglia formou um grupo de matemáticos, físi-cos e cientistas da computação com o objetivo de desenvolver estratégias de arbitragem estatística usando modelos que conseguissem prever a dinâmica das anomalias de preços. As estratégias desenvolvidas pelo grupo foram automatizadas ao nível que poderiam gerar operações de forma mecanizada e serem executadas perfeitamente através de sistemas de negociação automatizados. Uma das técnicas de negociação empregadas envolvia tradings com pares de ações, conforme mencionado. O processo envolvia identificar pares de ações em que os preços apresentavam movimentos similares. Quando era identificada uma ano-malia nessa relação, montava-se uma posição com a ideia de que a anoano-malia se corrigiria. Tartaglia e seu grupo empregaram a estratégia de pairs trading com grande sucesso ao longo de 1987. Apesar do grupo ter se desmontado em 1989, a estratégia de pairs trading se tornou cada vez mais popular entre traders individuais, investidores institucionais e
hedge-funds.
As metodologias de análise em pairs trading mais usuais são a correlação e cointe-gração, que buscam identificar e testar relações de curto e longo prazo, respectivamente. O início dos estudos sobre a correlação entre séries temporais foi introduzido por (YULE,
1926), que atacou o problema entre duas simples variáveis harmônicas em função do tempo. Mais tarde, em 1987, Robert F. Engle e C. W. J. Granger formalizaram a abordagem de cointegração vetorial em (ENGLE; GRANGER, 1987). O trabalho baseou-se na conexão de um processo média-móvel, autoregressivo e representação de correção de erros para
Capítulo 1. Introdução 13
sistemas cointegrados com o intuito de desenvolver e analisar testes para séries cointegra-das. Essas pesquisas foram primordiais para o desenvolvimento de técnicas baseadas em cointegração para arbitragem estatística em pairs trading, evidenciado por (BOSSAERTS,
1988).
No mercado brasileiro, (CALDEIRA,2011) utilizou a abordagem de cointegração em diversos pares de ações. O estudo objetivou primeiramente identificar quais pares de ações poderiam ser alvos de uma estratégia de pairs trading. Após isso, o alvo foi replicar o modelo de Ornstein-Uhlembeck e calcular o spread para realizar as simulações dos
tradings. O estudo mostrou rentabilidade expressiva ao longo de três anos, volatilidade
e correlação baixa em comparação ao mercado. (PUCCIARELLI, 2014) utilizou uma abordagem de cointegração dinâmica no tempo também em alguns pares de ações baseado no artigo (TRIANTAFYLLOPOULOS; MONTANA, 2011) que, diferentemente, utilizou uma equação de observação com parâmetros α e β constantes no tempo.
(KABASHIMA, 2005) buscou pré-selecionar os pares de ações no mercado brasi-leiro por meio da correlação, após isso, foi utilizado o teste de Dickey-Fuller aumentado (ADF) para verificar a existência de raiz unitária da série de resíduo da combinação
li-near do logaritmo dos preços. Em linha, (LONGO,2008) utilizou o teste Johansen para a formação dos pares a serem testados e construiu um ativo sintético para assegurar a esta-cionariedade dos preços. Por sua vez, (BRITO,2011) seguiu os mesmo passos, entretanto, aplicou a estratégia de cointegração em dados intradiários com frequência de 15 em 15 minutos em pares de ações negociadas no mercado brasileiro e comparou sua performance em relação ao ativo livre de risco (CDI).
Outra modelagem bastante difundida na arbitragem estatística é a análise de com-ponentes principais (PCA), que busca fazer uma transformação ortogonal de variáveis correlacionadas em valores linearmente independentes. (AVELLANEDA; LEE,2010) apli-cam a metodologia em ETFs negociados no mercado americano e analisam o sharpe-ratio da estratégia em diferentes períodos, incluindo a crise de liquidez em 2007. A análise com-parou um portfólio formado por 15 ETFs para representar as flutuações de mercado. Em média, 40% a 60% da variância nos retornos das ações são explicadas pelas componentes geradas. Com o mesmo intuito, (FERREIRA; VIEIRA,2011) aplicou o PCA e modelou a reversão à média como um processo de Ornstein-Uhlenbeck para maximizar uma função utilidade de um dado agente e, com isso, montar uma estratégia de pairs trading que considere uma maior aversão à risco dado um aumento na variância do ativo sintético modelado.
Com a evolução dos estudos na arbitragem estatística, a aplicação de redes neurais nos modelos lineares têm sido batante frequente e, é o que propõe (MEDEIROS; VEIGA; PEDREIRA, 2001) em sua modelagem sobre as taxas de juros. O objetivo foi testar e modelar a não-linearidade nas séries temporais de taxas de juros em alguns meses. A ideia
Capítulo 1. Introdução 14
foi aplicar duas alternativas não-lineares, uma rede neural estimada com regularização Bayesiana e a outra com o chamado coeficiente neural autoregressivo de transição suave. Sua conclusão tenta explicar qual é o tamanho da relevância da não-linearidade nas séries temporais que, resumidamente têm sua importância em alguns períodos específicos, tais como no início e fim da amostra.
Nessa linha, uma outra possível técnica seria obter a discrepância de preços entre os pares de ações e modelá-la como um ativo sintético, que tenha a característica de reversão à média e usar modelos de séries temporais para tentar descrever sua dinâmica. Em 2006, (THOMAIDIS; KONDAKIS; DOUNIAS, 2006) publicaram um artigo que propõe uma ferramenta inteligente combinada a métodos estatísticos para detectar possíveis distorções nos preços de pares de ações. A modelagem preliminar trata da obten-ção de um ativo sintético por meio de algumas formulações, que tenha a característica de reversão à média. Após isso, foi construído um modelo para descrever a sua dinâmica com base em inteligência artificial e um processo que descreva a variância do seu ruído. Com a obtenção dessa dinâmica, são construídos intervalos de confiança para a montagem das posições no ativo sintético.
O objetivo deste trabalho é propor uma ferramenta para detectar oportunidades de arbitragem estatística (AE) em um par específico de ações no mercado brasileiro. A técnica baseia-se em construir um ativo sintético no mesmo molde proposto por (THOMAIDIS; KONDAKIS; DOUNIAS,2006) e modelá-lo com os mesmos mecanismos estatísticos com exceção da rede neural, nele formulada, e aplicá-lo a um par de ações no mercado brasileiro em high frequence. O trabalho ainda contemplará a inserção de custos de transação de forma a tentar deixá-lo mais próximo da realidade.
Este trabalho está organizado conforme descrito a seguir. Primeiramente, no ca-pítulo 2, apresentam-se brevemente os conceitos teóricos utilizados para a elaboração do modelo. No capítulo 3, descreve-se a metodologia adotada para a construção do ativo sintético, estimação, especificação do modelo e desenvolvimento do sistema de trading. Já no capítulo 4, discutem-se os resultados de toda metodologia proposta no capítulo ante-rior, assim como a performance do algoritmo e P&L da estratégia ao longo do intervalo proposto. Por fim, no capítulo 5, apresentam-se as conclusões acerca dos resultados e indicações de possíveis extensões do trabalho.
15
2 Preliminares teóricas
Neste capítulo serão apresentadas brevemente as teorias que constituem a formula-ção do modelo. Informações adicionais podem ser extraídas de suas respectivas referências.
2.1
Estimação dos Parâmetros
Seja um conjunto de n observações {y1, y2, . . . yn} consideradas como resultados
de variáveis aleatórias com distribuição de probabilidade conjunta fθ(y1, y2, . . . yn) cuja
forma geral é conhecida a menos de um conjunto θ formado por um ou mais parâmetros desconhecidos. Chama-se de um modelo para as observações ao conjunto de distribuições
{fθ ; θ∈ Θ}. Embora os valores dos elementos de θ sejam desconhecidos, eles podem ser estimados a partir dos dados observados e o conjunto dos valores estimados destes elemen-tos é denotado por ˆθ. Um estimador é qualquer expressão numérica ou método que seja
usado para obter estimativas para um parâmetro desconhecido. Três métodos bastante conhecidos são o dos Momentos, o dos Mínimos Quadrados e o da Máxima Verossimi-lhança. Para o caso proposto, será utilizada a abordagem da Máxima Verossimilhança, apresentada aqui brevemente (v. (HEIJ et al., 2004)):
Máxima Verossimilhança: Define-se a Função de Verossimilhança, denotada L(θ),
como sendo fθ(y1, . . . , yn) entendida como função de θ, ou seja,
L(θ) = fθ(y1, . . . , yn), θ∈ Θ.
Para distribuições discretas, o valor de L(θ) é igual ao da probabilidade (com respeito à distribuição fθ) do resultado observado, de maneira que a estimativa por máxima
verossi-milhança é o valor de θ para o qual esta probabilidade é o maior dentre todos os valores possíveis de θ ∈ Θ. Analogamente, para distribuições contínuas a estimativa por máxima verossimilhança é obtida maximizando-se L(θ) sobre θ.
2.2
Critérios de Informação
Os critérios de infomação são métodos para decidir sobre a inclusão ou não de uma variável a mais em um modelo. Essa técnica consiste em avaliar qual o poder explicativo da nova variável a ser incluída e, em contrapartida, o critério também impõe um fator de penalização pela complexidade de utilizar um modelo com uma variável a mais. O Akaike
Capítulo 2. Preliminares teóricas 16
AIC = 2k
n − ln(L)
onde k é o número de parâmetros no modelo, L é o ponto máximo da função de verossi-milhança e 2kn é chamado de penalty factor. Conforme a sua formulação, o critério AIC impõe uma maior penalização por conta da adição de um regressor a mais no modelo. Quando comparados 2 ou mais modelos, o com menor valor é preferível.
Similarmente, o Bayesian Information Criterion (BIC) é definido como:
BIC =−2 ln L + k ln(n)
Aqui, L é o ponto máximo da função de verossimilhança, k é o número de parâmetros inclusos no modelo e n é o número de observações, ou de forma equivalente, o tamanho da amostra. Da mesma forma, o BIC penaliza o modelo com maior número de regressores, no caso proposto, maior número de lags. Também é preferível o modelo com o menor resultado.
2.3
Séries Temporais
Conforme (HEIJ et al.,2004), uma variável observada sequencialmente ao decorrer do tempo t = {1, 2, . . . , n} é dita uma série temporal. Essas variáveis são valores reali-zados ao longo do tempo por processos econômicos ou financeiros, que possuem como característica forte correlação com as observações mais recentes.
2.3.1
Estacionariedade
Uma série temporal é estacionária se algumas de suas propriedades estatísticas se mantiverem constantes ao longo do tempo. Ou seja, se a série for cortada em dois intervalos, tanto a média quanto a covariância dos dois intervalos serão praticamente iguais. Mais precisamente, uma série temporal Zt é dita estritamente estacionária (forte)
se a função de distribuição conjunta de {Zt, . . . , Ztm} e {Zt1+k, . . . , Ztm+k} são iguais para
m inteiro positivo, ou seja, iguais para qualquer período no tempo de duração igual.
Uma série é dita estacionária de segunda ordem (fraca), se:
E [Zt] = µ E[(Zt− µ)2] <∞
E[(Zt− µ)(γt−k − µ)] = γk, a depender do tamanho de k.
De acordo com a formulação acima, pode-se trabalhar com a estacionariedade de segunda ordem, já que a estacionariedade estrita é muito complexa de ser verificada
Capítulo 2. Preliminares teóricas 17
empiricamente. Para o caso proposto neste trabalho, será utilizada a hipótese de estacio-nariedade de segunda ordem.
2.3.2
Ruído Branco
Segundo (HEIJ et al.,2004), a notação para o passado de um processo estacionário
Zt pode ser escrita como zt−1 = {Zt−1, Zt−2, . . . , Zt−n}. Neste caso, zt−1 é chamado de
informação disponível até (t − 1). A predição para um passo a frente pode ser descrita como E[Zt|zt−1]. De uma outra forma:
ϵt= Zt− E[Zt|zt−1] (2.1)
ϵt é chamado de Innovation Process, pois corresponde aos choques na série
tempo-ral Zt. Se as observações forem normalmente distribuídas. A média condicional à
informa-ção até (t− 1) é: E[Zt|zt−1] = ϕo+ p ∑ i=1 ϕ′Zt−i (2.2) ϕo e ∑p
i=1ϕ′ são parâmetros a serem estimados. Este processo é considerado
esta-cionário, assim como ϵt também o é. Abaixo, algumas propriedades:
E[ϵt] = 0 para todo t,
E[ϵ2t] = σ2 para todo t,
E[ϵs, ϵt] = 0 para todo s̸= t,
Com variância constante e autocorrelação igual a zero, ϵt é chamado de ruído
branco.
2.4
Processo Autorregressivo
A equação 2.2 pode ser escrita como:
Zt= ϕo+ p
∑
i=1
ϕ′Zt−i+ ϵt (2.3)
conforme (HEIJ et al., 2004), 2.3 pode ser interpretada como um modelo de re-gressão linear. As variáveis explicativas da rere-gressão consistem nos lags imediatamente
Capítulo 2. Preliminares teóricas 18
anteriores da série temporal somada a um termo de perturbação. A equação 2.3 é conhe-cida como modelo autoregressivo de ordem p, AR(p).
2.4.1
Previsão em um Processo AR
Considerando a equação2.3, a condição de estacionariedade implica que Zt é uma
função dos erros passados (ϵt−k, k ⩾ 0). Sendo assim, para Zt+1 significa que ϵt+1 é não
correlacionado com todas as observações de Zt, a previsão um passo a frente é dado por:
b Zt+h = ϕo+ p ∑ i=1 ϕ′Zt+1−p (2.4)
O erro na previsão é dado por Zt+1− Zbt+h= ϵt+1e a variância do erro na previsão
é σ2. Lembramos que h representa uma escolha de quantos passos à frente desejamos
prever.
2.4.2
Variância da previsão
Generalizando o tamanho da previsão para h passos a frente, com a predição do erro (Zt+h− Zbt+h), se tem a variância de uma previsão na forma:
M SE(h) = E[(Zt+h−Zbt+h)2] (2.5)
Chamado de erro quadrático médio, para um passo a frente, se tem o erro da pre-visão igual à inovação ϵn+1. Da mesma forma, o processo de inovação também é chamado
de processo de predição dos erros. A variância da previsão cresce conforme o tamanho de
h aumenta, o que é natural dado que as observações passadas contém mais informações
para um futuro imediato do que para um futuro muito distante. Para um h tendendo a infinito, a variância da previsão converge para a variância do processo do próprio Zt, ou
seja, no longo prazo toda informação sobre o passado, eventualmente, desaparece. Isto porque a correlação de um processo estacionário converge para zero quando k tende a in-finito, então, a informação do passado é não-correlacionada para um futuro infinitamente longe.
2.4.3
Intervalo de Confiança da previsão
Conforme (HEIJ et al.,2004), intervalos de confiança podem ser construídos assumindo-se uma distribuição de probabilidade, neste caso, uma distribuição normal. Para a
instân-Capítulo 2. Preliminares teóricas 19
cia (1− α), ou para uma melhor ilustração, 95% em um intervalo de previsão para Zt+h é dado por: b Zt+h− 1, 64 √ M SE(h)≤ Zt+h ≤Zbt+h+ 1, 64 √ M SE(h) (2.6)
O intervalo da previsão é mais largo para horizontes de h maiores. Dessa forma, a variância M SE(h) aumenta para valores maiores de h.
2.5
GARCH
Até o momento, o processo de inovação ϵt foi considerado como se tivesse uma
variância constante σ2. Essa hipótese não é tão realística, dado que pode existir efeito dos lags na variância condicional σ2 = V ar(Zt|zt
−1) para as séries temporais. Como o
conceito de variância é uma medida de risco ou incerteza nos valores futuros de uma variável, esta torna-se uma ferramenta de suma importância para as decisões econômicas ou financeiras. Ao se trabalhar com uma variância dependente do tempo σ2
t, um dos
modelos que exemplifica a diferença entre variância condicional e não-condicional é o chamado de ARCH (Autoregressive Conditional Heteroskedasticity) que considera, apenas, o efeito dos lags dos termos de erros anteriores. Conforme (STATISTICS, 1992), uma generalização do modelo ARCH pode ser chamada de GARCH (Generalized Autoregressive
Conditional Heteroskedasticity), que em sua forma geral, GARCH(p, q) pode ser escrito,
conforme abaixo: ϵt|It−1 ∼ N(0, σt2) σ2t = αo+ p ∑ i=1 αiσ2t−i+ q ∑ i=1 βiϵ2t−i (2.7)
O termo de erro condicionado ao nível de informação adquirido até o instante imediatamente anterior segue uma distribuição normal de média zero e variância σ2
t. Para p = 0, o processo se reduz a um ARCH(q), e para p = q = 0, ϵté um simples ruído branco.
20
3 Identificação de discrepâncias na
precifica-ção de ativos
Arbitragem Estatística (AE) em pairs trading é uma metodologia de trading alta-mente quantitativa que visa identificar discrepâncias na precificação de um conjunto de ativos financeiros negociados no mercado, cuja combinação dos preços apresentem sinais claros de reversão à média. Algumas destas técnicas faz uso intensivo de modelos compu-tacionais no âmbito da Inteligência Artificial de forma a explorar a dinâmica dos mercados financeiros para efeito da previsão de séries temporais. No que diz respeito a esta previ-são, estudos anteriores (cf. (ZHANG; PATUWO; HU, 1998)) indicam que a predição de séries temporais tem melhor precisão quando é feita sobre a série de uma combinação de diferentes ativos, em vez de se utilizar a série de um único ativo.
3.1
Colocação do problema
Sendo assim, dado um conjunto de preços de ativos{X1, X2, . . . , Xn}, enunciamos:
Nosso Problema Fundamental de Arbitragem Estatística:
Identificar por um sistema automático de decisões de trading (negociação) as discrepâncias de precificações no portfólio variante no tempo {X1t, X2t, . . . , Xnt}, o que, por definição,
significa identificar em tempo real uma (n + 1)-upla
ωt= (ωot, ω1t, . . . , ωnt)∈ Rn+1 tal que a combinação de ativos
Zt= ωot+ n
∑
i=1
ωitXit,
que chamaremos aqui de ativo sintético, apresente reversão à média com distribuição N (0, σ2
t), com variância σt2 finita e dependente do tempo.
A exigência pela reversão à média se impõe para garantir que as discrepâncias even-tualmente tendam para zero e não cresçam indefinidamente pois, caso contrário, ficaria impossível controlar a exposição ao risco do portfólio em negociação. Podemos interpretar
Capítulo 3. Identificação de discrepâncias na precificação de ativos 21
com
ωi negativo indicando a ação de vender |ωi|Xi, ωi positivo indicando a ação de comprar |ωi|Xi.
3.2
Dinâmica de ativos sintéticos bidimensionais
A proposta deste trabalho é desenvolver um algoritmo para obter as bandas de
trading para um portfólio composto por apenas dois ativos X1 e X2. A generalização
para n > 2 ativos será um projeto a ser desenvolvido em pesquisas futuras depois que o algoritmo para o caso de ativos sintéticos bidimensionais atingir um nível adequado de aperfeiçoamento, robustez e amadurecimento.
O modelo padrão de abordagem para identificar uma discrepância de preços é regredir os valores de um ativo contra o outro. Na literatura econométrica, vários testes foram desenvolvidos para este propósito, tais como o de Dickey-Fuller e o de Phillips-Perron. Ambos são testes de raiz unitária, que em particular, prestam-se para distinguir uma tendência determinística de uma tendência estocástica. A tendência determinística se caracteriza pela reversão à média e pelos choques na série serem dissipados ao longo do tempo. Por outro lado, a tendência estocástica não apresenta reversão à média e os choques na série temporal têm efeito de longo prazo. Na prática, as séries temporais também são caracterizadas pelas flutuações de curto prazo e podem impactar em autocorrelação serial1, ou seja, os resíduos podem estar autocorrelacionados e, com isso, os valores críticos apresentados no teste não seriam válidos. Conforme (HEIJ et al., 2004), com base no Dickey–Fuller t-test, pode-se aplicar a correção de Newey–West que lida com o tratamento da correlação serial e considera os erros-padrões para estimar o parâmetro ρ. O t-test baseado na correção de Newey–West para os erros-padrões de ρ é chamado de teste de Perron. Para o caso proposto neste trabalho, será utilizado o teste de Phillips-Perron para a identifcação de reversão à média no ativo sintético.
O próximo passo é criar um modelo que descreva a dinâmica da discrepância de preços, isto é, como os erros em suas diferentes magnitudes e sinais (positivo/ negativo) são corrigidos ao longo do tempo. Como forma de tirar vantagem da previsibilidade, a previsão dos preços necessita ser incorporado à dinâmica da estratégia de trading. Um sistema de
trading baseado em arbitragem identifica os "turning points"da discrepância de preços
de sua série temporal e toma posição nos ativos correspondentes quando a discrepância for excepcionalmente alta (isto é, ω para positiva e −ω para discrepância negativa). A 1 Para uma relação entre a variável dependente y e a independente x, especificada da forma:
yi = x,iβ + εi, i = 1, . . . , n
As distorções são ditas autocorrelacionadas se existem observações i̸= j para εie εjque apresentem
Capítulo 3. Identificação de discrepâncias na precificação de ativos 22
estratégia de arbitragem descrita acima não é livre de risco; embora lucrativa no longo prazo, o lucro imediato depende fortemente do preço de mercado retornar para os seus "padrões normais ou históricos"em um prazo curto de tempo. Geralmente, uma reversão à média fraca tem maior probabilidade de ser observada em momentos adversos do ativo sintético.
O problema com tudo isto é que uma regressão simples de um ativo em função do outro não apresenta reversão à média, como mostra (THOMAIDIS; KONDAKIS; DOU-NIAS, 2006). Numa abordagem alternativa proposta também em (THOMAIDIS; KON-DAKIS; DOUNIAS,2006), vamos procurar controlar a não-estacionariedade do ativo sin-tético adotando um esquema adaptativo no qual os coeficientes da combinação que define
Zt são periodicamente recalculados. Nesta abordagem, vamos considerar a discrepância
de preços (ativo sintético) como sendo dada por:
Zt= X2t− βt−1X1t , (3.1)
onde βt é estimado com base numa janela de comprimento W , i.e., {X1j, X2j , para
j = t− W + 1, . . . , t}.
Para calcular o parâmetro βt , definimos β como sendo a razão média dos preços
entre as duas ações ao longo da janela especificada. Mais precisamente:
βt = mean { X2j X1j , para j = t− W + 1, . . . , t } , (3.2)
A partir daqui, a construção do modelo segue as seguintes etapas:
1. Especificação do modelo. 2. Estimação dos parâmetros.
3. Avaliação do input–of-sample e do output-of-sample.
3.2.1
Especificação do modelo
Com base nas séries de discrepância de preços Zt1, Zt2, . . . , Ztn estima-se um modelo linear
simples, neste caso, um AR(p), conforme equação abaixo:
Zt = ϕo+ p
∑
i=1
ϕ′Zt−i+ εt (3.3)
onde ϕo ∈ R, Zt = (Zt−1, Zt−2, . . . , Zt−n) ∈ Rn×1, εt é o resíduo ou o choque aleatório e ϕ ∈ Rn×1. Conforme (GUJARATI, 2009) um AR(p) é um modelo linear para séries
tem-porais que inclui não só os valores atuais, mas também os passados (lags) como variáveis explicativas.
Capítulo 3. Identificação de discrepâncias na precificação de ativos 23
Entretanto, para a utilização do modelo autoregressivo é necessário inferir quantos
lags são necessários para replicar com maior precisão a dinâmica do ativo sintético. Sendo
assim, para a decisão de incluir um lag a mais na equação linear serão utilizados os critérios de informação AIC e BIC.
AIC = 2k
n − ln(L) BIC =−2 ln L + k ln(n)
No entanto, é comum encontrar a presença de heteroscedasticidade2 nos resíduos
de um processo linear. Concomitantemente, uma outra proposta deste trabalho é modelar a variância do resíduo do processo autorregressivo. Nessas condições, o modelo proposto é a inclusão do componente de volatilidade GARCH(p, q), conforme abaixo:
εt|It−1 ∼ N(0, σ2t) σt2 = αo+ p ∑ i=1 αiσt2−i+ q ∑ i=1 βiε2t−i
O resíduo condicionado ao nível de informação adquirido até o instante imediata-mente anterior segue uma distribuição normal de média zero e variância σt2. Neste caso, o trabalho propõe uma forma de modelagem para a variância condicional do resíduo ε no instante de tempo t que depende não somente do próprio resíduo ao quadrado nos instantes de tempo anteriores ε2
t−1, ε2t−2, . . . , ε2t−q, mas também da própria variância ao
quadrado nos instantes t anteriores σ2
t−1, σ2t−2, . . . , σ2t−q. Ou seja, um GARCH(p, q) é
intro-duzido como uma forma de extensão de um processo ARCH (Autoregressive Conditional
Heteroskedasticity), que considera apenas o efeito dos lags dos resíduos anteriores. Para
a inferência do GARCH(p, q) também será feita a análise com os critérios de informação para a condução do número ótimo de lags da variância e dos resíduos.
2 Lembramos que, num modelo de regressão linear com múltiplas variáveis explicativas e termo residual
εt, Yt= β1+ n ∑ i=2 βiXit+ εt,
dizemos que temos heterocedasticidade, ou dispersão ou variância desigual, quando a variância do resíduo εtpara cada Xi (a variância condicional de εt) varia com o tempo, i.e.,
Capítulo 3. Identificação de discrepâncias na precificação de ativos 24
3.2.2
Estimação dos parâmetros
Com o intuito de encontrar estimadores para o modelo AR(p), optou-se por utilizar a abordagem de Máxima Verossimilhança, simplesmente por ser um estimador não-linear mais eficiente. Sob hipótese de ocorrerem altas perturbações em ϵt, essas observações
po-dem causar um impacto relativamente alto nos estimadores. Há muitas formas de reduzir esse impacto, uma delas é trocar a distribuição utilizada. Entretanto, se ϵt não for
nor-malmente distribuído, a hipótese de normalidade não é satisfeita. Concomitantemente, o estimador de Máxima Verossimilhança lida melhor com essas perturbações, já que uti-liza a distribuição de probabilidade conjunta das observações fθ(Z1, . . . , Zn) da descrição
presente no método de Máxima Verossimilhança apresentado anteriormente.
Da mesma forma, a estimação dos parâmetros desconhecidos do modelo de variân-cia condicional GARCH(p, q) também será feita pela função de Máxima Verossimilhança.
3.3
Sistema de trading
Nessa fase, será formulado o modelo com o intuito de obter a previsão de 1-h passos a frente do valor futuro do ativo sintético. As previsões são dadas na forma de
função densidade de probabilidade condicional, ou seja, obtido uma previsão Zbt+h será
utilizada como base a formulação 2.6que nos conta como podemos formular intervalos de confiança com base na variância da previsão M SE(h). Entretanto, aqui uma modificação importante; como uma proposta do trabalho é modelar a variância condiconal do resíduo
ϵt, será substituída a função M SE(h) pela variância σ2t modelada com GARCH(p, q),
conforme as equações abaixo, utilizadas em (OPSCHOOR; DIJK; WEL, 2014):
b
Zt+hL,α =Zbt+h− (1 − α)σbt+h (3.4)
b
Zt+hH,α =Zbt+h+ (1− α)σbt+h (3.5)
Em que (1−α) é um determinado intervalo de confiança de uma normal N(0, σ2
t) e
b
σ2
n+h é a previsão da variância condiconal modelada pelo GARCH(p, q). Essa formulação
é importante, pois o objetivo do modelo é construir bandas de entrada e saída baseadas nos intervalos de confiança Zbt+hL,α (low) eZbt+hH,α (high).
Após a construção das bandas no espaço de tempo 1-h passos a frente, o modelo receberá os valores atuais, em t, das ações X1t e X2t, de modo a construir os valores do
ativo sintético Zt. Neste espaço de tempo 1-h passos a frente, o modelo é capaz de enviar
Capítulo 3. Identificação de discrepâncias na precificação de ativos 25
• Se Zt<Zbt+hL,α, monta-se uma posição comprada no ativo sintético3;
• Se Zt>Zbt+hH,α, monta-se uma posição vendida no ativo sintético4;
O algoritmo para identificação de um sistema de decisões automáticas desenvol-vido até aqui pode ser incrementado capacitando-o a lidar com as seguintes situações específicas:
(i) Não há nenhuma posição montada e o sistema de decisões indica que é hora de
montar posição;
(ii) Há posição montada e o sistema de decisões indica que é hora de desmontar a posição e
auferir o lucro ou prejuízo. Como não há posição montada, procede-se como descrito em (i).
3 Longing no ativo sintético significa comprar 1 unidade de X
2 e vender βtações de X1. 4 Shorting no ativo sintético significa vender 1 unidade de X
26
4 Resultados
Os cálculos, testes e todas as análises apresentadas neste trabalho foram feitas utilizando-se o software MATLAB. As cotações dos preços das ações foram obtidas pela estação BLOOMBERG e tratadas no Microsoft Excel e portadas ao MATLAB. Pela facilidade em obter gráficos de maior qualidade e performar testes e parametrizações, também optou-se por utilizar o MATLAB.
Para a aplicação proposta neste trabalho, será utilizado o par de ações PETR3 e PETR4 (negociadas no pregão da bolsa de valores de São Paulo, Bovespa) que são repre-sentadas por X1 e X2, respectivamente. Essa escolha tem por finalidade uma aplicação
do modelo no mercado brasileiro e pelo fato de serem ações da mesma companhia, nor-malmente, resultam em um melhor comportamento de reversão à média. Os horários de cotação ao longo dos dias respeitará o intervalo das 11h00min até 15h00min, utilizando preços de fechamento de trade no intraday de minuto a minuto. Esse intervalo de tempo foi escolhido por conta do mercado operar em maior liquidez dentro dessa faixa. Todas as séries de preços são ajustadas a eventos, tal como splits e pagamento de dividendos. A amostra inicial de preços utilizada para a construção do ativo sintético e para a especifi-cação e estimação do modelo será referente ao dia 04/01/2016 até 08/01/2016.
Após esta fase, o modelo performará a previsão e será construído um sistema de trading capaz de identificar as distorções geradas no ativo sintético. Para isso, serão utilizados os preços no intervalo de 08/01/2016 a 23/02/2016 para validação do modelo
out-of-sample.
Conforme a Figura1, pode-se observar a evolução dos preços das ações X1(PETR3)
e X2 (PETR4) ao longo de todo o período t proposto. Pela evolução dos preços, observa-se
que, em nível de tendência, os ativos tendem a seguir a mesma direção.
Na Figura 1, a rigor, o tempo t = 1, 2, 3...n na abscissa representa a sequência de tomadas de preço sucessivas e não propriamente em minutos. Para uma melhor visuali-zação, a arbitragem estatística em pairs trading procura aproveitar-se das oportunidades geradas conforme a Figura 2.
Obviamente, difentemente dos log-retornos acumulados, o sistema aqui proposto tentará identificar apenas os pontos de cruzamento das linhas, sem carregar ambos os ativos em uma estratégia buy and hold.
Capítulo 4. Resultados 27
Figura 1 – Evolução dos preços de PETR3 e PETR4 - 04/01/2016 até 23/02/2016
Figura 2 – Log-Retornos Acumulados dos preços de PETR3 e PETR4 - 04/01/2016 até 23/02/2016
4.1
Construção do modelo avaliado
Na fase input-of-sample será utilizada a amostra incial de preços dentro do intervalo de 04/01/2016 até 08/01/2016 (1000 minutos). Com base nessas séries de preços, pode-se aplicar a formulação 3.2 com o intuito de construir um ativo sintético nos moldes de 3.1. A primeira variável a se obter é βt, entretanto, antes é preciso definir o parâmentro W ,
que representa o comprimento da janela a serem efetuados os cálculos. Dessa forma, por utilizarmos dados de minuto a minuto, parece razoável determinarmos três tamanhos de
Capítulo 4. Resultados 28
W em 10, 30 e 60. Assim, a construção do ativo sintético será feita com base nos preços
do par de ações de 10, 30 e 60 minutos.
Com o tamanho de W definido, inicia-se o cálculo do coenficiente βt, conforme a
Figura 3, que corresponde a uma média do quociente entre X2,j
X1,j, onde j = t−W +1, . . . , t.
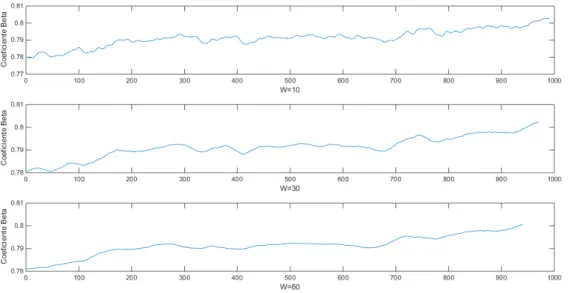
Figura 3 – Evolução do coeficiente βt - 04/01/2016 até 08/01/2016
A Figura 3 mostra a evolução do coeficiente βt ao longo do tempo j para o
parâ-metro W = 10, 30 e 60, respectivamente. Pode-se observar que a razão das duas ações apresentou tendência de alta durante o período observado. A Figura também mostra que utilizar a média do quociente entre as ações X2,j
X1,j para o cálculo de βt tem como objetivo
suavizar as oscilações sem influênciar sua trajetória. Ao utilizar um W maior, aumenta-se a suavização dessa trajetória. A Figura 3 mostra βt calculado com W = 10, a trajetória
do coeficiente apresenta quinas e ruídos obtidos pala variação dos preços. Para W = 30, observa-se uma tendência mais suavizada e com menos quinas. Já para W = 60, é possível ver o coeficiente βt descrito praticamente em uma curva totalmente suavizada.
Com βt calculado, pode-se construir por fim o valor do ativo sintético, conforme a
expressão 3.1:
A construção do ativo sintético, conforme a Figura 4, tem o objetivo de analisar uma discrepância de preços que atenda o principal fator, neste caso, a reversão à média. Pode-se observar que para as diferentes janelas, o W crescente continua com o intuito de suavizar os ruídos presentes na discrepância de preços. Com essa suavização é possível ver que para um W maior, os ruídos mais fortes demoram mais para serem dissipados, isto porque, como a forma de trabalhar com o ativo sintético e seus coeficientes é o calculo de
Capítulo 4. Resultados 29
Figura 4 – Evolução do Ativo Sintético Zt - 04/01/2016 até 08/01/2016
Zt Estatística do Teste Valor Crítico 5% p-valor
W = 10 −19, 23 −1, 9416 0, 001
W = 30 −13, 09 −1, 9416 0, 001
W = 60 −10, 34 −1, 9415 0, 001
Tabela 1 – Teste de Phillips-Perron
suas médias, o efeito de um ruído mais forte no preço do ativo sintético permanece por mais tempo ao longo de sua evolução.
Com o ativo sintético construído, é preciso verificar sua reversão à média antes de sua modelagem. Para isso, utilizaremos o teste de Phillips-Perron.
Conforme a Tabela 1, todas as estatísticas do teste rejeitam para valores altos o valor crítico de 5%, ou seja, rejeitando a hipótese nula de unicidade da raiz. Sendo assim, pode-se trabalhar com a hipótese de que o ativo sintético possui reversão à média. Para fins de simplificação, o ativo sintético que considera a janela W = 10 obteve o valor mais alto de rejeição da hipótese nula, ou seja, apresenta um índice maior de reversão à média. O ativo sintético calculado com a janela W = 10 apresenta um tempo médio de 3 minutos para reverter à sua média. Neste caso, a partir desse ponto, todos os cálculos e análises serão feitos com o ativo sintético construído com a janela de comprimento W = 10.
Com a hipótese formulada anteriormente, podemos dar início a modelagem do ativo sintético, conforme descrito no capítulo 3 que descreve a especificação e estimação do modelo. A principio, foram estimados os modelos autoregressivos com três lags, AR(1), AR(2) e AR(3). Nessa fase, o intuito é definir qual é o número ótimo de lags para a
Capítulo 4. Resultados 30
Parâmetros AR(1) AR(2) AR(3)
Constante (ϕo) 3, 408e− 04 3, 011e − 04 2, 943e − 04 Lag1 (ϕ1) 0, 4202 0, 3482 0, 3438
Lag2 (ϕ2) — 0, 1650 0, 1558
Lag3 (ϕ3) — — 0, 0261
Variância (β2) 8, 465e− 05 8, 228e − 05 8, 230e − 05
LogVerossimilhança ( ln(L)) 3, 049e + 04 3, 065e + 04 3, 067e + 04 Tabela 2 – Estimação processo AR
descrição do ativo sintético, para isso, utilizaremos os critérios de informação. A Tabela
2 mostra os respectivos resultados.
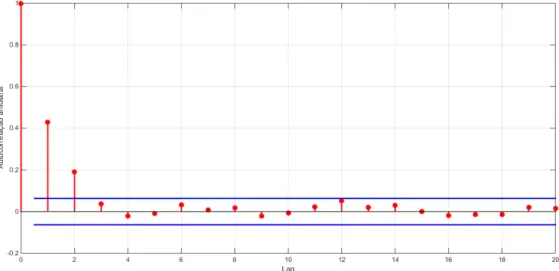
Com os resultados da Tabela 2, pode-se estimar os critérios de informação AIC e BIC. Mas, antes, vale a tentativa de olhar o gráfico de autocorrelação para ver qual o número ideal de lags:
Figura 5 – Função Autocorrelação Amostral
O gráfico de autocorrelação amostral sugere um comprimento de 2 lags para o mo-delo. Para a decisão, também serão levados em conta os critérios de informação, conforme Tabela3:
Conforme os resultados do AIC e BIC, em conjunto com a análise gráfica da função autocorrelação amostral, sugere-se a utilização de um AR(2), já que deve-se utilizar os menores níveis para ambos os critétrios.
Seguindo a mesma linha para a modelagem da variância condicional, será utilizado também os critérios de informação AIC e BIC para definir qual o número ideal de lags a
Capítulo 4. Resultados 31
Modelo AIC BIC
AR(1) −6, 532e + 03 −6, 517e + 03 AR(2) −6, 559e + 03 −6, 538e + 03 AR(3) −6, 557e + 03 −6, 532e + 03
Tabela 3 – Critérios de informação
Parâmetros ARCH(1) GARCH(1,1) GARCH(1,2)
Constante (α0) 7, 406e− 05 4, 853e− 05 5, 564e− 05
Lag1 (α1) — 0, 265 0, 167
Lag1 (β1) 0, 240 0, 237 0, 237
Lag2 (β2) — — 0, 025
LogVerossimilhança ( ln(L)) 3, 191e + 03 3, 195e + 03 3, 195e + 03 Tabela 4 – Estimação GARCH
serem incluídos no modelo GARCH(p, q). Para isso, definimos um conjunto de modelos para serem comparados entre si, dentre estes, ARCH(1), GARCH(1,1) e GARCH(1,2):
Com os modelos especificados, conforme Tabela 4, e antes de performar a análise dos critérios de informação, é interessante olhar o gráfico de autocorrelação da variância do ativo sintético Zt, conforme a Figura 6.
Figura 6 – Função Autocorrelação Amostral da Variância de Zt
O gráfico de autocorrelação amostral da variância de Zt sugere a presença de até
dois lags. Analisado em conjunto com os valores dos critérios de informação performados para os modelos contidos na Tabela 5.
Capítulo 4. Resultados 32
Modelo AIC BIC
ARCH(1) −6, 378e + 03 −6, 368e + 03 GARCH(1,1) −6, 383e + 03 −6, 368e + 03 GARCH(1,2) −6, 381e + 03 −6, 361e + 03
Tabela 5 – Critérios de informação variância
O critério AIC sugere a inclusão de um GARCH(1,1) por conta de obter o me-nor valor entre os três modelos comparados. Já o critério BIC propõe marginalmente a modelagem por um ARCH(1). Entretanto, pela diferença ser quase nula entre o valor do critério BIC para modelagem de um ARCH(1) no lugar do GARCH(1,1), pelo critério AIC apontar um valor maior para o prórpio GARCH(1,1) e pela análise gráfica da auto-correlação apontar até dois lags na variância de Zt, optou-se pela modelagem de variância
condicional pelo modelo GARCH(1,1).
Com o modelo já especificado e estimado, pode-se iniciar a construção das bandas com base em uma previsão h passos a frente, conforme roteiro descrito no capítulo 3.
Para a avaliação, recalibragem e simulação de negócios serão utilizados os preços de trade à partir do dia 08/01/2016 às 11h40min até o dia 23/02/2016 (respeitando a faixa de tempo das 11h00min até às 15h00min, conforme descrito anteriormente). Sendo assim, foram estabelcidas algumas premissas para o sistema de trading:
• O sistema utilizará uma janela móvel de 1000 minutos de preços das ações para a
calibragem do modelo;
• O intervalo para recalibragem será de h (tamanho da previsão), que para o caso
aqui proposto será h = 10;
• As bandas de probabilidade condicional adotadas serão calculadas com um intervalo
de confiança fixo de (1− α)% = 95%;
• A partir da reestimação com a janela móvel, o modelo utilizará a mesma
espe-cificação encontrada anteriormente, ou seja, será mantido constante o AR(2) e GARCH(1,1);
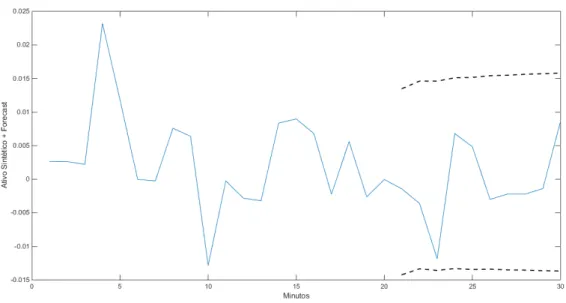
Com base nas premissas descritas, o sistema de trading trabalhará conforme a Figura 7.
Na parte superior, pode-se observar a evolução do ativo sintético ao longo dos 1000 minutos contruídos. Com base nessa amostra, o modelo estima o AR(2) e o GARCH(1,1) para efetuar a previsão na forma de distribuição de probabilidade condicional, conforme a parte inferior da Figura 7.
Capítulo 4. Resultados 33
Figura 7 – Evolução ativo sintético e previsão
Após essa construção, a ideia do sistema de trading é receber os 10 novos valores do ativo sintético Zte comprá-lo ou vende-lo com base nas premissas contruídas, conforme
a Figura 8.
Figura 8 – Evolução ativo sintético e bandas
A partir desse momento, criou-se um sistema de trading, que efetua a previsão na forma de probabilidade condicional para h minutos a frente e os utiliza para montagem de posição, caso as realizações de Zt ultrapassem qualquer banda. Com essa construção, é
possíveal analisar as previsão realizadas para todo intervalo proposto, conforme a Figura
Capítulo 4. Resultados 34
Figura 9 – Evolução ativo sintético realizado e previsão AR(2)- 04/01/2016 até 23/02/2016
Na parte superior da Figura9, observa-se a realização do ativo sintético em função do tempo. Para a parte inferior, apresenta-se a realização dos primeiros 1000 minutos do ativo sintético Zt utilizados para a estimação do modelo e a realização da previsão Zbt.
É possível analisar que apesar da previsão ser linear, descrito por um processo AR(2), as recalibragens em intervalos de h = 10 fazem com que a previsão apresente um ruído próximo ao observado na realização do ativo sintético.
A mesma análise é feita para a variância do ativo sintético ao longo de toda a sua realização, conforme a Figura 10.
Da mesma forma que Ztb , a previsão √
c
σ2
t+h também captura, em certo nível, os
ruídos formados pela realização natural da variância de Zt por conta da recalibragem
feita em intervalos de h = 10. Utilizar um tamanho de 1000 minutos também ajudou na performance do algoritmo. O intervalo total contou com 7950 realizações do ativo sintético, sendo que o sistema foi reestimado 690 vezes ao longo do período completo.
Seguindo o objetivo proposto, a Figura11mostra a evolução do ativo sintético Zt
e logo abaixo, o mesmo Zt com as bandas Zbt+hL,α (low) e Zb H,α
t+h (high) projetadas.
Com a previsão gerada em forma de probabilidade condicional nos moldes de
3.4 e 3.5, percebe-se que o componente GARCH ajusta dinamicamente os intervalos de confiança, conforme as discrepâncias de preços do ativo sintético se tornam mais voláteis. Dessa forma, consegue-se previnir trades em perídos de alta volatilidade e se reduz o risco das operações. Pode-se observar a evolução do ativo sintético nos primeiros 1000 minutos (estimação do modelo) e a partir desse ponto a construção da bandas baseadas em uma previsão de 10 minutos a frente, e a evolução do próprio ativo sintético dentro das bandas.
Capítulo 4. Resultados 35
Figura 10 – Variância realizada e GARCH(1,1) - 04/01/2016 até 23/02/2016
Figura 11 – Realizacão do ativo sintético e bandas de probabilidade condicional Zbt+hL,α e b
Zt+hH,α - 04/01/2016 até 23/02/2016
4.2
Operações com ordens limitadas
O trabalho propõe um sistema em (AE) com abordagem em alta-frequência. Para o modelo ser aplicável ao mercado, tomou-se algumas premissas:
• As quantidades de compra e venda de X1 e X2 serão multiplicadas por 5.000 e
arredondadas para o inteiro mais próximo;
• Portfólio inicial de R$ 100.000,00;
Capítulo 4. Resultados 36
vendas pelo Ask, conforme a Figura 12:
Figura 12 – Preços por fechamento de minuto Bid and Ask - 04/01/2016 até 23/02/2016
Figura 13 – LogRetornos Acumulados dos preços Bid and Ask de PETR3 e PETR4 -04/01/2016 até 23/02/2016
4.2.1
Operações sem custos de transação
Na Figura14é possível visualizar, em maior detalhe, como o sistema se comportou com a evolução do ativo sintético Zt já envelopado pelas bandas de trading. Os pontos
verdes representam as operações de compra de Zt e os vermelhos de venda.
Analisando os resultados da Tabela6, pode-se observar que, em todas as operações o sistema obteve resultado positivo. O método proposto mostrou boa performance ao de-tectar distorções, por menor que fossem no par de ações analisado. Entretanto, o trabalho
Capítulo 4. Resultados 37
Figura 14 – Sistema de Trading formado pelo ativo sintético e pelas bandas de trading -04/01/2016 até 11/01/2016
utilizou a premissa de que todas as ordens seriam executas assim que as fossem enviadas. Um dos princiapis problemas ao trabalhar com dados em alta-frequência é justamente efetivar ambas as ordens instantaneamente. Outro problema é o volume a ser operado, já que se este for muito grande, pode-se afetar o preço dos papéis aumentando a proba-blidade de não ter a ordem efetivada. Pelo lado oposto, trabalhar com um volume muito pequeno faria com que o lucro apresenta-se queda, o que não compensaria a depender dos custos de transação.
Considerando o período inteiro em que o sistema operou de 08/01/2016 às 11h40min até o dia 23/02/2016 às 15h, foram montadas 476 posições sendo de compra ou venda do ativo sintético. Foram contabilizados 238 trades concluídos. Desses 238, apenas, 21 auferiram prejuízo, ou seja, 9% da amostra de trades. Em linha, pode-se analisar a Figura
15 que mostra o P&L do sistema no período completo.
Capítulo 4. Resultados 38
Posição Preço Preço Qtd Qtd
Data Zt βt Zt X1 X2 X1 X2 P&L 8/1/16 12:20 Compra 0, 8022 −0, 0104 8, 00 6, 4 −4011 5000 -8/1/16 12:48 Venda 0, 8022 0, 0260 7, 86 6, 32 4011 −5000 161,54 8/1/16 12:48 Venda 0, 8002 0, 0260 7, 86 6, 32 4001 5000 -8/1/16 12:52 Compra 0, 8002 −0, 0138 7, 83 6, 25 −4001 5000 229,97 8/1/16 12:52 Compra 0, 8010 −0, 0138 7, 83 6, 25 −4005 5000 -8/1/16 14:59 Venda 0, 8010 0, 0013 7, 8 6, 23 4005 −5000 20,15 11/1/16 10:55 Venda 0, 7979 0, 0358 7, 77 6, 25 3990 −5000 -11/1/16 13:01 Compra 0, 7979 −0, 0183 7, 7 6, 19 −3990 5000 20,7 11/1/16 13:01 Compra 0, 8059 −0, 0183 7, 7 6, 19 −4030 5000 -11/1/16 13:09 Venda 0, 8059 0, 0171 7, 68 6, 2 4030 −5000 130,6 11/1/16 13:09 Venda 0, 8053 0, 0171 7, 68 6, 2 4027 −5000 -11/1/16 13:33 Compra 0, 8053 −0, 0139 7, 69 6, 17 −4027 5000 190,97 11/1/16 13:33 Compra 0, 8051 −0, 0139 7, 69 6, 17 −4026 5000 -11/1/16 13:50 Venda 0, 8051 0, 0199 7, 65 6, 17 4026 −5000 161,04 11/1/16 13:50 Venda 0, 8042 0, 0199 7, 65 6, 17 4021 −5000 -11/1/16 13:52 Compra 0, 8042 −0, 0118 7, 66 6, 15 −4021 5000 140,21 11/1/16 13:52 Compra 0, 8043 −0, 0118 7, 66 6, 15 −4021 5000 -11/1/16 14:06 Venda 0, 8043 0, 0173 7, 62 6, 13 4021 −5000 60,84 11/1/16 14:06 Venda 0, 8025 0, 0173 7, 62 6, 13 4012 −5000 -11/1/16 14:32 Compra 0, 8025 −0, 0180 7, 69 6, 15 −4012 5000 180,84 11/1/16 14:32 Compra 0, 8029 −0, 0180 7, 69 6, 15 −4015 5000 -11/1/16 15:00 Venda 0, 8029 −0, 0034 7, 67 6, 16 4015 −5000 130,3
Tabela 6 – Primeiros 2 dias de negócios
O sistema obteve lucro de R$ 35.177,15 considerando o portfólio incial composto por R$ 100.000,00. O lucro dentro do intervalo de 30 dias úteis representou 35,18% do patrimônio da carteira. Dos 10 trades que trouxeram prejuízo ao portfólio, o menor destes foi de R$ 380,65, o que representou -0,38% do patrimônio da carteira.
Conforme a Figura 16, é possível visualizar como estão distribuídos os lucros por
trade.
Pelo boxplot, pode-se analisar que a mediana está localizada no ponto 0,16%, enquanto o primeiro e terceiro quartil estão em 0,1% e 0,22%, respectivamente. Agora, visualizando o histograma (primeira figura), a média de lucro por trade é de 0,16%. O máximo e mínimo da amostra estão posicionados em 0,4% e -0,38%, respectivamente.
Capítulo 4. Resultados 39
Figura 16 – Histograma e Boxplot do P&L por trade - 08/01/2016 até 23/02/2016
4.2.2
Operações com custos de transação
Para as simulações de negócios considerando os custos foram utilizados os mesmos critérios e período do sistema de trading exposto anteriormente. Para a adição dos custos, foram consideradas as seguintes premissas:
• 0% de rebate;
• Custos de 0,1% com corretagem por ordem executada;
• 0,0250% por volume negociado de emolumentos em operações day trade;
• 0% de aluguel. Todas as posições são encerradas no fim de cada dia pelo último
preço disponível.
Pela Figura17, pode-se observar o P&L acumulado por trade efetuado. Neste caso, o sistema identificou as mesmas discrepâncias e efetuou as mesmas operações do modelo anterior. Entretanto, o P&L com a inserção dos custos caiu drasticamente para 6,6%, uma queda de aproximadamente 81% em comparação com o modelo sem a incorporação dos custos. Em algumas ocasiões, principalmente ao efetuar os primeiros trades, o P&L acumulado ficou negativo e só a partir do 35o trade que voltou a gerar lucro.
Na Figura 18, tem-se o boxplot e histograma com a abordagem sem e com cus-tos de transação. A análise mostra que a distribuição que considera os cuscus-tos teve um deslocamento de 0,1% para a esquerda. Como em alguns trades o lucro era quase nulo, a inserção dos custos fez com que 72 resultassem em prejuízo, representando 30,3% da amostra. Operar em alta-frequência exige um dispêndio financeiro alto com os custos, principalmente quando considerado um nível alto de corretagem.
Capítulo 4. Resultados 40
Figura 17 – P&L Acum. com custos de transação do Sistema de Trading - 08/01/2016 até 23/02/2016
Figura 18 – Histograma e Boxplot do P&L por trade sem e com custos de transação -08/01/2016 até 23/02/2016
4.3
Operações com ordens a mercado
Até o momento, foi considerada a hipótese de que todas as ordens enviadas ao book eram em formatos limitados. Entretanto, na prática, as ordens podem não ser executadas durante o período de um minuto. Essa situação poderia desencadear uma falha sistêmica do modelo. Uma alternativa, seria considerar a compra no melhor ask e a venda no melhor
bid. Para isso, foram consideradas as mesmas premissas descritas nas seções anteriores.
Na Figura19, pode-se observar que o P&L acumulado apresenta queda relevante para os trades efetuados. O prejuízo acumulado foi de aproximadamente 15% nos 30 dias úteis analisados. Dos 238 trades, 70% resultaram em prejuízo. O método em (AE) proposto,
Capítulo 4. Resultados 41
Figura 19 – P&L Acum. do Sistema de Trading com ordens a mercado - 08/01/2016 até 23/02/2016
se aproveita das discrepâncias de preços entre o par de ações por menor que sejam, neste caso, efetuar as ordens a mercado torna o modelo inutilizável. Naturalmente, visto que nesses casos, não há oportunidades de arbitragem. Essa é uma decisão importante para o sistema automático de identificações de oportunidades de arbitragem.
42
5 Considerações finais
Este trabalho teve como objetivo construir uma ferramenta para identificação de oportunidades de arbitragem estatística (AE) em pairs trading e aplicá-la ao mercado brasileiro. Essa abordagem baseou-se na construção de um ativo sintético que tivesse a natureza de reversão à média. Após isso, foram conduzidas previsões na forma de den-sidade de probabilidade condicional, formando intervalos de confiança. Ainda houve a inclusão de custos de transação para deixar o modelo mais próximo da realidade.
Os resultados da aplicação com ordens limitadas mostraram-se satisfatórios para a detecção de possíveis oportunidades de arbitragem, e mesmo após a inclusão dos custos, o modelo obteve um bom retorno acumulado. Entretanto, sua aplicabilidade ao mundo real ainda é altamente questionável principalmente pelos níveis de custos e discrepâncias vistas no mercado. Os resultados com custos de transação mostraram queda no P&L de mais de 80% quando comparado ao modelo sem custos. Para o segundo caso, o modelo tem a característica de se aproveitar de pequenas discrepâncias entre os preços das ações. Neste caso, o volume a ser operado é extremamente relevante, já que um volume muito expressivo em relação ao operado por minuto poderia tornar o modelo um market maker, o que iria totalmente contra a abordagem proposta. Apesar dos testes considerarem o
Bid and Ask spread, outro possível impacto realizado pelo volume seria a não efetivação
das posições dentro da frequência estipulada, o que seria equivalente ao desajuste do
β calculado e poderia desencadear em uma pane no sistema de trading. Por sua vez,
considerar o envio das ordens a mercado como candidato à solução para o problema de falha sistêmica implica em tornar o modelo inutilizável.
Quanto ao back-testing realizado, apesar de ter-se utilizado quase 8000 sequências de preços, o intervalo de tempo coberto foram apenas 30 dias úteis. Dessa forma, a apli-cabilidade ainda é questionável já que pode não ter-se capturado momentos em que o par de ativos não reverte à média. O problema de se realizar back-testings em janelas temporais maiores é que o algoritmo requer um tempo considerável para a estimação a cada previsão realizada. O modelo ainda trabalha com um erro de especificação ao longo de todo o seu teste, já que foi especificado com base em uma amostra de 1000 preços iniciais e considerado constante ao longo de todo o back-testing.
Como sugestão de trabalhos futuros, o modelo poderia não desmontar as posições que acarretassem em prejuízo gerados pela inclusão dos custos ou pela abordagem de ordens a mercado. Essa modificação poderia apresentar resultados mais interessantes em termos de performance, já que reduziria a quantidade de trades realizados ao longo do tempo. Outra possível solução para o critério dos custos e pela efetividade das posições
Capítulo 5. Considerações finais 43
seria uma abordagem em baixa-frequência, diferentemente do proposto neste trabalho. Em termos de sofisticação para o modelo, poderia-se utilizar uma rede neural para ajustar o
fitting das previsões realizadas. E por fim, a inclusão de uma banda de stop-loss poderia
minimizar o risco de perdas relevantes em momentos que o ativo sintetico não reverta à média.