AVALIAÇÃO DE MODELOS USADOS PARA ESTIMAR A PROBABILIDADE DE DEFAULT
Dissertação apresentada ao programa de Pós-graduação Stricto Sensu em Economia de Empresas da Universidade Católica de Brasília, como requisito parcial para obtenção do Título de Mestre em Finanças.
Orientador: Prof. Dr. José Angelo Divino
R672a Rocha, Lineke Clementino Sleegers.
Avaliação de modelos usados para estimar a probabilidade de default. / Lineke Clementino Sleegers Rocha – 2012.
51f. : il.; 30 cm
Dissertação (mestrado) – Universidade Católica de Brasília, 2012. Orientação: José Angelo Divino
1. Mercado financeiro. 2. Logística. 3. Avaliação. 4. Variáveis aleatórias. I. Divino, José Angelo. II. Título.
A Deus
Agradeço a Deus pelo dom da vida e pelas bênçãos concedidas durante a realização deste trabalho.
Ao meu marido, aos meus pais, irmã e familiares que sempre confiaram em mim. Ao professor José Angelo pela orientação e apoio dado na realização deste trabalho. A todos os professores do programa do curso de mestrado em Economia de Empresas da Católica por todo o aprendizado proporcionado no curso.
Aos amigos com quem convivi durante o curso com quem compartilhei conhecimento e me ajudaram a superar as dificultadas encontradas ao longo do curso, em especial à amiga Cláudia Rosane Piva.
À Maysa pela presteza, atenção e seriedade com que atendia às nossas demandas. À amiga Cecília de Souza Salviano por todo apoio para participar da seleção do programa de mestrado.
Aos amigos que me apoiaram na realização do trabalho, em especial Hideo Sumihara Filho, Edna Lima e Sérgio Ricardo Batista.
À Caixa Econômica Federal pelo incentivo proporcionado para participar do curso de mestrado em Economia de Empresas da Católica.
Agradeço a todos que contribuíram diretamente ou indiretamente para a realização deste trabalho.
“A arte da previsão consiste em antecipar o que acontecerá e depois explicar
O trabalho identifica determinantes da taxa de default no mercado de empréstimos imobiliários por meio da comparação de modelos alternativos considerando variáveis do perfil do tomador de crédito e características do contrato. O estudo considerou modelos estimados por regressão logística e análise de sobrevivência de Cox. A inclusão de variáveis macroeconômicas foi testada nos modelos identificados para verificar o ganho no poder preditivo. A acurácia dos modelos foi verificada por meio dos indicadores Kolmogorov Sminorv, razão de acurácia, AUROC e entropia. Os resultados indicam melhor acurácia para os modelos estimados por regressão logística, sendo observada uma melhora significativa após a inclusão de variáveis macroeconômicas.
The paper identifies determinants of default on the mortgage market through the comparison of alternative models considering variables of the profile of borrower and contract characteristics. The study considered models estimated by logistic regression and Cox survival analysis The inclusion of macroeconomic variables in each model was tested to verify the gain in predictive power. The accuracy of the models was verified using the Kolmogorov Sminorv indicators, ratio accuracy, entropy and AUROC. The results indicate better accuracy for the models estimated by logistic regression, a significant improvement was observed after the inclusion of macroeconomic variables.
1 INTRODUÇÃO...10
1.1 Objetivo ...12
1.1.1 Objetivo Geral...12
1.1.2 Objetivos Específicos...12
2 REVISÃO LITERÁRIA...13
3 DESCRIÇÃO DA TÉCNICA...16
3.1 Regressão Logística...16
3.2 Modelo de Risco Proporcional de Cox ...18
3.3 Indicadores de Acurácia ...20
3.3.1 Kolmogorov Sminorv (KS)...21
3.3.2 Curva CAP e Razão de acurácia...22
3.3.3 Curva ROC e indicador AUROC...25
3.3.4 Entropia...28
4 DESCRIÇÃO DOS DADOS ...30
5 RESULTADOS OBTIDOS ...33
5.1 Matriz de migração ...33
5.2 Matriz de correlação...38
5.3 Modelos para previsão de default...39
5.4 Coeficientes de acurácia...44
6 CONCLUSÃO ...46
REFERÊNCIAS...47
Tabela 2: Freqüência das variáveis discretas ...32
Tabela 3:Faixas de atraso...34
Tabela 4:Matriz de Migração...35
Tabela 5: Distribuição de default ...36
Tabela 6: Matriz de correlação...38
Tabela 7: Modelos estimados por Regressão Logística...40
Tabela 8: Modelos estimados por meio do modelo de risco proporcional de Cox...43
LISTA DE GRÁFICOS Gráfico 1:Exemplo do gráfico de KS ...22
Gráfico 2:Exemplo de gráfico da Curva CAP ...24
Gráfico 3:Exemplo de Sensitividade e Especificidade...26
Gráfico 4:Exemplo da Curva ROC ...27
Gráfico 5:Entropia x PD...28
Gráfico 6:Probabilidade de migração de atraso ...35
Gráfico 7:Distribuição do tempo de sobrevivência para dados censurados ...37
1 INTRODUÇÃO
O risco está presente em todas as decisões econômicas de agentes racionais envolvendo incerteza. Não há como eliminá-lo, mas é possível gerenciá-lo para que as decisões sejam tomadas levando em consideração os possíveis resultados. O gerenciamento do risco de crédito é fundamental para a solidez de instituições financeiras individuais e do mercado financeiro como um todo.
Cada vez mais se utilizam modelos estatísticos para o cálculo do risco de crédito. Os modelos de risco de crédito compõem um ferramental técnico que supre de informações aos gestores e contribuem para a tomada de decisões que atendam às diretrizes estabelecidas nas políticas de crédito de determinada instituição financeira.
Os modelos de classificação de risco buscam avaliar o risco de um tomador ou operação, atribuindo uma medida que representa a expectativa de risco de default, geralmente expressa na forma de uma classificação de risco (rating) ou pontuação (escore).
Além das variáveis do perfil do tomador de crédito e das características do contrato, diversos outros fatores podem afetar a capacidade de pagamento dos agentes tomadores de crédito, tais como variáveis macroeconômicas. Dentre as variáveis macroeconômicas que explicam a inadimplência podemos citar: os níveis de inflação, a produção industrial e a taxa de juros básica da economia.
Inicialmente, serão consideradas apenas variáveis do perfil do tomador de crédito e as características do contrato. Posteriormente, serão incluídas variáveis macroeconômicas variantes no tempo nos modelos identificados para verificar o ganho no poder preditivo da modelagem nos ambientes alternativos.
A comparação dos modelos será realizada por meio de indicadores tais como:
Kolmogorov Sminorv (KS), Razão de Acurácia e Área Under a ROC Curve (AUROC). Estes indicadores compararam a distribuição da probabilidade de default dos contratos inadimplentes com a distribuição da probabilidade de default dos contratos adimplentes. Espera-se que os contratos inadimplentes tenham probabilidade de default superior aos demais contratos.
1.1 Objetivo
1.1.1 Objetivo Geral
O presente trabalho tem como objetivo identificar os principais determinantes da probabilidade de default no mercado de empréstimos imobiliários garantidos por colateral, por meio da comparação de modelos de avaliação de risco alternativos, considerando elementos do perfil do tomador de crédito, características do contrato e aspectos da conjuntura econômica do país.
1.1.2 Objetivos Específicos
Identificar os principais determinantes da probabilidade de default em empréstimos individuais colaterizados, oriundos do mercado imobiliário.
Avaliar o desempenho de modelos alternativos para estimar a probabilidade de default, representados por regressão logística e modelo de risco proporcional de Cox.
Verificar se a inclusão de variáveis macroeconômicas dependentes do tempo melhora o desempenho dos modelos estimados em termos de critérios de acurácia distintos.
2 REVISÃO LITERÁRIA
Vários estudos vêm sendo desenvolvidos para analisar o comportamento de pagamento de clientes em operações de crédito com ou sem colateral.
Securato (2002) apresenta conceitos de modelos de crédito, como modelos que se prestam a avaliar as possíveis perdas de uma carteira e modelos que são utilizados para o cálculo de probabilidades de inadimplência de pessoas físicas e jurídicas. O autor define risco como sendo “Uma forma de medir quanto podemos perder em uma operação, em relação a um ganho médio estabelecido.” Na visão de Securato (2002), uma fase muito importante inicia-se com a boa escolha de um novo cliente ou a indicação de um negócio adequado ao perfil de cada cliente. É uma etapa extremamente difícil, pois é necessário prever se um determinado cliente será bom ou mal pagador utilizando apenas informações fornecidas pelo próprio cliente.
Nesse sentido, as garantias pessoais ou reais, tornaram-se um instrumento fundamental na obtenção de crédito financeiro. Voordeckers e Steijvers (2006) e Ono e Uesugi (2009) demonstram que o efeito conjunto de garantias físicas e pessoais pode impactar positivamente na relação entre emprestador e tomador.
Além das variáveis do perfil do tomador de crédito e da garantia, o cenário macroeconômico também pode influenciar a capacidade de pagamento dos tomadores de crédito.
e negativa entre essa e a taxa de juro real da economia. A modelagem foi realizada com uso do modelo parcial de Cox de análise de sobrevivência, técnica muito utilizada em estudos relacionados à área de saúde e que vem sendo aplicada em estudos na área da economia e gestão de riscos relacionados à inadimplência, insolvência bancária, falência, bem como no desenvolvimento de modelos de escoragem de clientes tomadores de crédito nos segmentos pessoa física e pessoa jurídica.
Batista, Divino e Orrillo (2011) utilizaram o modelo de Dubey, Geanakoplos e Zame (1995) para derivar a relação teórica entre taxa de juros e probabilidade de default e mostrar a existência de relação positiva entre probabilidade de default (PD) e taxa de juro real do empréstimo e negativa entre PD e taxa de juro real da economia. O estudo demonstrou ainda que, redução da taxa de juros decorrente de política monetária expansionista implica em menor retorno financeiro nas operações de tesouraria realizadas por instituições financeiras, sendo essa compensada por meio da expansão da carteira de crédito. As conclusões do modelo teórico foram ratificadas pela evidência empírica identificada no mercado imobiliário brasileiro, comprovando a relação negativa existente entre taxa de juros real da economia e probabilidade de default.
Carvalho, Divino e Orrillo (2011) utilizaram elementos de Magill e Quinzii (1996) e Dubey, Geanakoplos, e Shubik (2005) para construir um modelo de equilíbrio geral com mercados incompletos, produção e default. O estudo também identificou uma relação inversa entre a taxa de juro real da economia e a probabilidade de default e uma relação direta entre a taxa de juro real do empréstimo e a probabilidade de default. Esses dois últimos resultados foram empiricamente testados e confirmados pelos dados brasileiros. O modelo de risco proporcional de Cox com covariáveis dependentes do tempo encontrou os mesmos sinais derivados na modelagem teórica.
A inclusão de variáveis dependentes do tempo em modelos de previsão de default foi apresentada por Crook e Bellotti (2010). O estudo apresenta que os dados de empréstimo estão geralmente organizados em formato de painel, permitindo a inclusão de covariáveis nos modelos de análise de sobrevivência, painel e fatores de correção.
3 DESCRIÇÃO DA TÉCNICA
Os modelos de risco de crédito buscam avaliar o risco de um tomador ou de uma operação, atribuindo uma medida que representa a expectativa de risco de default, geralmente expressa na forma de uma classificação de risco (rating) ou nota (escore). Estes modelos atribuem pontuações às variáveis de decisão de crédito de um proponente, mediante a aplicação de técnicas estatísticas, visando à segregação de características que permitam distinguir os bons dos maus pagadores. Esta classificação, por sua vez, pode orientar a decisão do analista em relação à concessão ou não do crédito solicitado.
Dentre as metodologias existentes para análise de risco de crédito destacam-se a regressão logística e o modelo de risco proporcional de Cox.
3.1 Regressão Logística
A regressão logística, como apontam Hosmer e Lemeshow (1989) e Collett (1991), é uma técnica estatística utilizada para estudar a relação entre uma variável categorizada de interesse e um conjunto de outras variáveis disponíveis ao estudo. Neste trabalho, será apresentada a teoria associada à regressão logística com variável resposta binária. Hosmer e Lemeshow (1989), por exemplo, descrevem a regressão logística com variável dependente com distribuição multinomial.
A regressão logística é um caso particular de modelos lineares generalizados (Mc-Cullagh e Nelder, 1989), com função de ligação logito e variável resposta para a unidade amostral i, yi, com distribuição de Bernoulli de média µi. O modelo produz
valores ajustados que variam entre 0 e 1 e indica a probabilidade de ocorrência do evento em estudo.
A relação entre as variáveis explicativas e a variável dependente é dada por:
i pi i pi i i X X Y
π
β
β
β
α
β
β
β
α
= + + + + + + + + + = ) ... X X exp( 1 ) ... X X exp( p 2i 2 1 1 p 2i 2 1 1 (1) Sendo queα, β1, .., βp = coeficientes estimados;
A variável resposta Y tem distribuição Bernoulli (1,
π
), com probabilidade desucesso P(Yi =1)=
π
i e de fracasso P(Yi =0)=1−π
i Logo, E(Yi)=π
iA modelagem é dada por Yi =
π
i −ε
i, sendo que εi pode assumir apenas doisvalores.
Se y i=1⇒
ε
i =1−π
i Se y i=0⇒ε
i =−π
iAssim, os erros não são normais e tem distribuição com média zero e variância dada por
π
i(1−π
i) isto é, a distribuição condicional da variável resposta segueuma distribuição binomial com probabilidade dada pela média condicional
π
iOs parâmetros da regressão logística podem ser estimados por máxima verossimilhança, sendo representada por
i i y i y i n i Y L − = −
=
∏
11 ) 1 ( ) /
( β µ µ (2)
No caso da regressão logística
) ... X X exp( 1 ) ... X X exp( p 2i 2 1 1 p 2i 2 1 1 pi i pi i i X X β β β α β β β α µ + + + + + + + + +
= (3)
O sistema de equações obtidas a partir da derivação da função de log verossimilhança em relação a β e igualando a zero não é linear. Por isso, a solução é obtida com a utilização de métodos numéricos. O mais utilizado é o mínimo quadrados reponderados (Pereira, 2004). O modelo pode ser facilmente ajustado já que está implementado em todos os principais softwares de análise estatística.
Uma das vantagens da regressão logística está na interpretação dos parâmetros, concedida pela estatística razão de chances (Agresti, 1990). Na regressão logística eβi é a razão entre a chance de Y
i ser um em relação a ser zero
quando xij=a+1 e quando xij = a. Isto é, mantidas todas as demais variáveis
3.2 Modelo de Risco Proporcional de Cox
O modelo de regressão de Cox permite modelar a probabilidade de default e o tempo de sobrevivência, com uso de covariáveis dependentes do tempo e não exige suposições sobre distribuição probabilística dos dados. Apresentamos aqui uma breve descrição do método tendo Colosimo e Giolo (2006) e Klein, Kleinbaun e David (2005) como referências básicas.
A possibilidade de uso de variáveis dependentes do tempo é uma modificação do modelo original da regressão de Cox, cuja forma geral é dada por:
≤ ≥ = =
→ .t
t) T | . + t < T (t P ) ). ´( ( ). ( ) ( 0 , 0 δ δ β δ t Lim t X g t h t h t (4)
onde g é função não negativa que deve ser especificada de forma tal que g(0) = 1; X’(t) é vetor de covariáveis; β é o vetor de parâmetros estimados e h(t) corresponde à taxa de falha no momento t, conhecida como função risco ou hazard function que depende do tempo, mas não da covariável.
A taxa de falha é composta por um componente paramétrico e um não-paramétrico. Se todo o vetor de covariáveis X for igual a zero, a fórmula do modelo de Cox fica reduzida à função de risco h(t), sendo chamada de função base.
O modelo de risco proporcional de Cox com covariáveis dependentes do tempo pode ser escrito como:
( ))
( )
.(
'( )
,β)
,
(t X h0 t g X t
h t = = exp{X’β} = exp{β1x1 +...+βpxp} (5)
O modelo também é conhecido como modelo proporcional de risco porque a taxa de falha de dois indivíduos quaisquer é constante ao longo do tempo. A probabilidade de sobrevivência até o tempo t é dada por:
(
)
( )
− = ≤=
∫
toh u du T
t P t
S( ) exp (6)
) ( 1 )
(t PD t
S = − (7)
em que PD(t) corresponde à probabilidade de default no momento t.
Os contratos que não entrarem em default no período analisado, ou deixarem de ser observados por qualquer razão, são incluídos na modelagem e classificados como censurados com tempo de vida correspondendo à última vez que foram observados.
C(t) = 0, se observação for censurada 1, caso contrário
O método de máxima verossimilhança, apesar de muito utilizado na estimação dos parâmetros do modelo, torna-se inadequado em razão da existência do componente não paramétrico.
Para contornar esta situação, Cox (1975) propôs o método de máxima verossimilhança parcial que considera na função de máxima verossimilhança o histórico de falhas e censura. O conceito geral do método de máxima verossimilhança parcial é descrito a seguir, também com base em Giolo e Colosimo (2006).
Em uma amostra com ‘n’ indivíduos existem k ≤ n falhas distintas nos tempos t1 < t2 < ... < tk. A probabilidade condicional da i-ésima observação vir a falhar no
tempo ti conhecendo quais observações estão sob risco em ti é:
P[Indivíduo falhar em ti I uma falha em ti e história até ti] =
{ }
{ }
( )
∑
∈i
t R
j j
i x x
β β
' '
exp exp
(8)
Em que R(ti) são observações que não apresentaram falha até o momento ti. A
função de verossimilhança utilizada para fazer inferências acerca dos parâmetros do modelo é formada pelo produto dos termos representados por (1) associado aos
( )
{ }
{ }
( ) i i c t R j j i n i x xL
=
∑
∏
∈ = β ββ ' '
1 exp
exp
(9)
onde ci é o indicador de falha.
Seja si o vetor das p covariáveis do indivíduo que falhou no momento ti, com k
i≤
≤
1 e di o número de falhas neste mesmo tempo, a aproximação proposta para
a função de máxima verossimilhança parcial é dada por:
( )
[
( )
]
( )
[
]
( ) =∑
∏
∈ = i t R j di j i ki x t
t x L β β β ' ' 1 exp exp (10)
Os valores de β que maximizam a função de verossimilhança parcial L(β),
são obtidos resolvendo-se o sistema de equações definido por U(β) = 0, em que
U(β) é o vetor escore de derivadas de primeira ordem da função l(β) = log(L(β)). Isto é,
( )
( ){ }
{ }
( ) . 0 ˆ exp ˆ exp ' ' 1 = − =∑
∑
∑
∈ ∈ = i i t R j j t Rj j j
i n i i x x x x c U β β
β (11)
Em virtude da possibilidade de ocorrência de coincidências nos tempos de falha identificados e entre esses e a censura, a função de máxima verossimilhança é modificada na forma sugerida por Breslow (1972) e Peto (1972).
As principais vantagens do modelo de risco proporcional de Cox é a possibilidade de verificar a relação de variáveis dependentes do tempo com o evento estudado e a inclusão de censura dos dados.
3.3 Indicadores de Acurácia
cujo índice relacionado é o AUROC e Cumulative Accuracy Profile (CAP), cujo índice relacionado é o Accuracy Ratio (AR). O autor apresenta ainda incidência na literatura do indicador Kolmogorov e Sminorv (KS) e o indicador de entropia.
A descrição detalhada de cada indicador é apresentada no Working Paper 14 do BCBS (2005) e Sleegers e Sumihara (2009). A seguir, apresenta-se uma descrição resumida de cada um daqueles indicadores.
3.3.1 Kolmogorov Sminorv (KS)
O teste Kolmogorov-Smirnov (KS) é uma técnica não paramétrica para determinar se duas amostras foram extraídas da mesma população (Siegel, 1975). Este teste se baseia na distribuição acumulada dos escores dos clientes considerados como bons pagadores e maus pagadores.
Se as distribuições cumulativas das duas amostras são muito distantes uma da outra, em qualquer ponto, isto sugere que as amostras provêm de populações distintas, o que indica que o modelo é discriminante, ou seja, atribui alta probabilidade de default para os contratos inadimplente e baixa probabilidade de default para os demais contratos.
Para a realização do teste, devemos ter uma amostra significativa da população, com CPF ou CNPJ distintos, uma variável indicadora do comportamento do cliente (se é bom ou mau) e uma variável indicativa dos escores do modelo.
Para aplicar o teste KS, deve-se construir uma distribuição de freqüências acumuladas para cada qualidade de crédito (bom ou mau cliente), utilizando os mesmos intervalos de escore para ambas as distribuições. Para cada intervalo, subtraímos uma função da outra. A distância máxima encontrada entre estas 2 distribuições representa a medida do KS.
Sejam:
SnB(X) = função acumulada observada para o escore dos bons
clientes, ou seja, SnB(X) =KB/nB, onde KB é a quantidade de clientes bons com
escores não superiores a X e nB é o total de clientes bons.
SnM(X) = função acumulada observada para o escore dos maus
clientes, ou seja, SnB(X) =KM/nM, onde KM é a quantidade de clientes maus
com escores não superiores a X e nM é o total de clientes maus.
KS = Max[SnM(X) - SnB(X)] (12)
O modelo estará mais bem ajustado quanto maior a estatística KS. O gráfico 1 apresenta um exemplo de como o KS é calculado.
KS
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
0 10 20 30 40 50 60 70 80 90 100
Score
%
Bons Maus
K
S
Gráfico 1:Exemplo do gráfico de KS O Autor
Neste trabalho, como as amostras são grandes, a tendência é que todos os modelos rejeitem a hipótese de igualdade nas distribuições. Por isso, será considerado melhor modelo àquele que possuir o maior valor no teste, pois este resultado indica uma separação maior entre bons e maus pagadores.
3.3.2 Curva CAP e Razão de acurácia
A curva Cumulative Accuracy Profile (CAP) é uma metodologia de avaliação bastante utilizada atualmente para medir o desempenho de um sistema de classificação de risco de crédito. Para isso, os percentuais acumulados de contratos por classificação de risco são plotados contra os percentuais acumulados de inadimplentes em uma curva de Lorenz, com o objetivo de visualizar a acurácia da classificação. A curva foi desenvolvida por Max Lorenz e representa graficamente a proporcionalidade de uma distribuição.
Para o cálculo da razão de acurácia, deve-se construir um gráfico com as seguintes curvas:
• Distribuição do modelo perfeito e • Distribuição do modelo analisado.
A curva do modelo aleatório representa a pior situação possível, em que não há qualquer poder discriminatório. Considera-se operações classificadas sem qualquer critério, representando a função identidade, x=y. Ou seja, a proporção das operações inadimplentes e adimplentes tende a ser a mesma para cada categoria de risco. Neste caso, o gráfico é representado por uma reta com inclinação de 45% e a área sob a curva seria igual a 0,50.
No modelo perfeito é possível identificar todas as operações inadimplentes nas menores categorias de risco.
Os modelos analisados tendem a apresentar curvas entre as duas curvas extremas apresentadas anteriormente. A curva do modelo analisado mostra a distribuição das operações inadimplentes ao longo das categorias de risco.
Considere uma amostra de N operações de crédito no início do período (T0)
foram classificadas em n classes de risco (c1 a cn) em ordem crescente de risco. Ao
final do período (T1) foram classificadas como inadimplentes ou adimplentes.
Defina:
NI = Total das operações inadimplentes.
NA = Total das operações adimplentes.
N = NI + NA
I c I c I N N
p = = probabilidade de uma operação inadimplente estar classificada na
categoria c, em que c I
N é o total das operações inadimplentes na categoria c.
∑
= = c j j I c I p P 1= probabilidade acumulada de uma operação inadimplente estar
classificada até a categoria c.
A c A c A N N
p = = probabilidade de uma operação adimplente estar classificada na
categoria c.
∑
= = c j j A c A p P 1= probabilidade acumulada de uma operação adimplente estar
N N P N P P A c A I c I
c = . + . (13)
A curva CAP é formada pelos pontos ( c
P , PIc).
A razão de acurácia é definida como a razão da área entre a curva CAP (cumulative accuracy profile) e a diagonal (modelo aleatório) e a área entre o modelo perfeito e a diagonal.
A fórmula simplificada para o cálculo da razão de acurácia – AR é apresentada abaixo:
( )
− −=
∫
10 1 2 1 1 dx x y d
AR (14)
Onde:
d = taxa de inadimplência
y(x) é a função que forma a curva CAP
Quanto mais a Razão de Acurácia se aproximar de 1, melhor a acurácia do modelo.
O gráfico 2 abaixo apresenta um exemplo do gráfico da curva CAP:
Curva CAP 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 110%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
% Acumulado Total
% A cu m u la d o In ad im p le n te s
Modelo Observado Modelo Aleatório Modelo Perfeito
Engelmann, Hayden e Tasche (2003) demonstra a existência de uma relação linear entre os indicadores AR e AUROC, por meio da fórmula:
AR = 2*AUROC -1 (15)
Sendo assim, conhecendo o valor do AUROC, o valor do AR pode ser calculado diretamente e vice-versa. Porém, o indicador AUROC é mais robusto para avaliar a acurácia dos modelos.
Conforme demonstrado por Sleegers e Sumihara (2009), a própria relação linear com o indicador AR torna o AUROC mais robusto. Calculando a derivada da fórmula AR = (2*AUROC – 1), observamos que a cada variação de um ponto no indicador AUROC, o AR varia 2 pontos.
3.3.3 Curva ROC e indicador AUROC
Segundo Braga (2000), a Curva ROC teve origem na teoria de decisão estatística e foi desenvolvida entre 1950 e 1960 na avaliação de sinais de radar e na psicologia sensorial. A análise da curva ROC foi, desde então, aplicada com sucesso a uma grande variedade de testes de diagnósticos, sobretudo, no diagnóstico de imagem médica. Recentemente também é usada na área financeira para avaliar a acurácia de modelos de risco.
Distribuição de clientes
0,0% 5,0% 10,0% 15,0% 20,0% 25,0%
0 10 20 30 40 50 60 70 80 90 100
Score
%
Distr. Bom Distr. Mau
C
Sensitividade Especificidade
Gráfico 3:Exemplo de Sensitividade e Especificidade O Autor
A Sensitividade pode ser definida como a capacidade de identificar os clientes maus dado que eles realmente são maus. Ou seja, qual é o percentual dos clientes observados na prática como maus pagadores, que foram classificados como maus pelo modelo, dado um determinado ponto de corte.
A Especificidade pode ser definida como a capacidade de identificar os clientes bons dado que eles realmente são bons. Ou seja, qual é o percentual dos clientes observados na prática como bons pagadores, que foram classificados como bons pelo modelo, dado um determinado ponto de corte.
A curva ROC é obtida plotando em um gráfico Sensibilidade x (1 - Especificidade) para os diferentes pontos de corte, conforme ilustrado no gráfico 4.
Curva ROC
0 0,2 0,4 0,6 0,8 1
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
1-Especificidade
S
en
si
ti
vi
d
ad
e
Modelo Observado Modelo Aleatório Modelo Perfeito
Gráfico 4:Exemplo da Curva ROC O Autor
Um modelo perfeito corresponderia a uma linha horizontal no topo do gráfico, porém esta dificilmente será alcançada. Na prática, curvas consideradas boas estarão entre a linha diagonal e a linha perfeita, onde quanto maior a distância da linha diagonal, melhor o modelo. A linha diagonal indica uma classificação aleatória, ou seja, um modelo que aleatoriamente seleciona bons e maus pagadores, como jogar uma moeda para cima e esperar cara ou coroa.
3.3.4 Entropia
A medida de entropia consiste em comparar o grau de incerteza nos dados sem nenhum modelo e nos dados caso o modelo fosse aplicado.
A entropia pode ser definida pela equação abaixo: )) 1 log( * ) 1 ( ) log( * (
0 d d d d
H = − + − − (16)
onde d é a taxa de default.
Observa-se, no gráfico 5, que a entropia atinge o valor máximo de incerteza, quando a probabilidade de default é 50%. Não há cálculo para os valores de PD = 0 ou 100%, pois estes pontos indicam eventos certos, não apresentando nenhuma incerteza.
Probabilidade de Default x Entropia
0% 10% 20% 30% 40% 50% 60% 70% 80%
1% 10% 20% 30% 40% 50% 60% 70% 80% 90% 99%
PD E n tr o p ia
Gráfico 5:Entropia x PD O Autor
Considerando a distribuição de clientes bons e maus de um determinado modelo, podemos calcular a entropia para cada faixa de escore, conforme equação abaixo: ))) / ( 1 log( * )) / ( 1 ( )) / ( log( * ) / ( ( )
(R P A R P A R P A R P A R
em que P(A/R) = probabilidade de um cliente ser mau em um dado escore.
Dividindo os dados em N classes de escore de tamanho δ, temos a entropia condicional:
∑
=
= N
i
i
i P R
R H S
H
1
1( ,δ) ( ) ( ) (18)
Quanto maior a diferença entre a entropia calculada sem considerar o modelo (H0) e a entropia condicional (H1), melhor a discriminação do modelo. Espera-se que
a informação calculada com os dados do modelo seja menor que os dados sem levar em consideração o modelo (H1 <= H0).
O indicador mais usado na análise de entropia é a razão da entropia condicional – CIER (Conditional Information Entropy Ratio). O CIER é o percentual de decréscimo no grau de incerteza, conforme equação abaixo:
[
0 1( , )]
/ 0) ,
(S H H S H
CIER δ = − δ (19)
4 DESCRIÇÃO DOS DADOS
Para estimação do modelo, foram utilizados contratos de crédito imobiliário de uma Instituição Financeira brasileira, adquiridos por pessoas físicas no período de Janeiro de 2006 a Dezembro de 2007. O comportamento de pagamento destes créditos foram observados do momento da contratação até Junho de 2011.
As operações possuem taxas de juros pós-fixadas, contratadas com exigência de garantia real, geralmente o próprio bem financiado, e previsão de punição em caso de default. A punição é caracterizada pela tomada do bem.
A base inicial era composta por 356.199 contratos. Antes do uso das informações foi efetuada a depuração do banco de dados com o intuito de excluir dados inconsistentes ou inexistentes. Nessa depuração, foram excluídos da base os dados de contratos que apresentaram pelo menos uma das situações a seguir: campo inválido ou sem informação, renda mensal inferior a R$ 100,00 ou superior a R$ 65.000,00; e falta de informação sobre o histórico de pagamento. A base após o tratamento dos filtros ficou compostas por 268.036 contratos.
A base de dados possui informações referentes às características do tomador de crédito, características do contrato e variáveis macroeconômicas.
• Tomador: sexo, idade, estado civil, grau de instrução, região geográfica, quantidade de dependentes, profissão, tempo de emprego, renda familiar e tipo de renda (formal ou informal).
• Contrato: razão entre o valor do financiamento e o valor da garantia, prazo e taxa de juros anual do contrato.
• Variáveis macroeconômicas
o taxa de câmbio nominal, R$ / US$, comercial - venda – média do
período. Obtida no Banco Central do Brasil;
o taxa de juros over SELIC em % ao mês anualizada, coletada no
Banco Central do Brasil;
o taxa de desemprego em %, obtida no Instituto Brasileiro de Geografia
e Estatística, Pesquisa Mensal de Emprego (IBGE/PME);
o PIB - R$ (milhões), índice deflacionado e dessazonalizado. Obtido no
o Produção industrial - indústria de transformação - quantum - índice
dessaz. (média 2002 = 100) e deflacionado - Instituto Brasileiro de Geografia e Estatística, Pesquisa Industrial Mensal - Produção Física (IBGE/PIM-PF);
o Arrecadação das receita federais - receita bruta - R$ (milhões), índice
deflacionado e dessazonalizado - Ministério da Fazenda;
o Carga tributária, calculada como a razão entre a arrecadação das
receitas federais e o PIB.
A tabela 1 apresenta as características da amostra utilizada no estudo.
Tabela 1: Estatísticas Descritivas das variáveis contínuas
Variável Média PadrãoDesvio Min P25 P50 P75 Max Valor financiado /
garantia 71,28 17,49 0,30 61,52 76,67 80,00 100,00 Taxa de juros do
contrato (a.a.) 7,66 1,78 4,00 6,00 8,16 9,57 18,00 SELIC 11,11 1,21 7,08 10,82 11,40 11,40 17,15
PIB Industrial 126,50 5,96 104,53 125,30 130,03 130,03 132,18
Taxa de câmbio 1,72 0,21 1,59 1,59 1,59 1,78 2,39
Taxa de desemprego 7,01 1,23 5,30 6,20 6,20 7,60 10,70
PIB 12,37 0,07 12,15 12,29 12,42 12,42 12,43
Arrecadação 10,58 0,10 10,26 10,51 10,65 10,65 10,76
Carga tributária 16,88% 1,00% 13,86% 16,71% 17,18% 17,18% 22,79%
O Autor
A razão do valor financiado sobre a garantia apresenta média de 71,28% e mediana de 76,67%. A taxa anual do contrato varia de 4% a 18% e média de 7,66%. A média da SELIC anual é 11,11% e mediana de 11,40% e a média do PIB industrial foi de 126,50. A taxa de câmbio nominal apresentou média de 1,72 e a média da taxa de desemprego foi de 7,01. O PIB varia de 12,15 a 12,43 e a arrecadação de 10,26 a 10,76. A média da carga tributária foi de 16,88%.
Tabela 2: Freqüência das variáveis discretas
Variável Freqüência % Grau de Instrução
1: Fundamental 57.456 21,44
2: Médio 129.528 48,32
3: Superior 81.052 30,24
Região
1: Norte 4.643 1,73
2: Nordeste 34.606 12,91
3: Centro-Oeste 21.545 8,04
4: Sul 58.843 21,95
5: Sudeste 148.399 55,37
Estado Civil
1: Solteiro/Separado 128.698 48,02
2: Casado/viúvo 139.338 51,98
Tipo de Renda
1: Não possui renda
formal 7.977 2,98
2: Possui renda formal 260.059 97,02
Sexo
Masculino 177.513 66,23
Feminino 90.523 33,77
Possui contrato anterior?
0: Não possui ctr anterior 117.605 43,88
1: Possui ctr anterior 150.431 56,12
Possui contrato posterior?
0: Não possui ctr posterior 83.658 31,21
1: Possui ctr posterior 184.378 68,79
O Autor
5 RESULTADOS OBTIDOS
Para a definição de default foi utilizado o estudo de matriz de migração de atraso e o Edital da Audiência Pública 37 do BACEN. Após a definição de default, foi analisada a distribuição do tempo de sobrevivência para os contratos censurados e não censurados.
O estudo considerou a matriz de correlação entre as variáveis e a estimação de modelos de regressão logística e modelos de risco proporcional de Cox considerando apenas variáveis de perfil do tomador de crédito e características do contrato.
Posteriormente, foram incluídas variáveis macroeconômicas nos modelos identificados para verificar o ganho no poder preditivo com a inclusão destas variáveis. A acurácia dos modelos foi verificada por meio de indicadores tais como: Kolmogorov Sminorv, Razão de Acurácia, AUROC e entropia.
5.1 Matriz de migração
Sendo Xi = tempo (em dias) de atraso no pagamento da prestação no i-ésimo mês de contrato, a matriz de migração será considerada como as probabilidades condicionais de migração de atraso, dadas por:
(
X
j
X
i
)
P
P
ij=
2=
|
1=
(20)Tabela 3:Faixas de atraso Nº Intervalo (dias)
0 0-29
30 30-59
60 60-89
90 90-119
120 120-149
150 150-179
180 180-209
210 210-239
240 240-269
270 270-299
300 300-329
330 330-359
360 360 ou mais
O Autor
Exemplo 5.1: P(Xn+1 = 60 | Xn = 30) é a probabilidade de um contrato estar
com 60 dias de atraso no próximo mês, dado que no mês atual ele esteja com 30 dias de atraso. Isto representa uma probabilidade de duas prestações consecutivas estarem em atraso hoje, dado que no mês anterior havia apenas uma prestação em atraso.
Exemplo 5.2: P(Xn+1 = 0 | Xn = 90) é a probabilidade de um contrato estar
com 0 dias de atraso (“em dia”) no próximo mês, dado que no mês atual ele esteja com 90 dias de atraso. Isto representa uma probabilidade do pagamento de 3 prestações em atraso em uma única vez.
Exemplo 5.3: P(Xn+1 = 30 | Xn = 30) é a probabilidade de um contrato estar
com 30 dias de atraso no próximo mês, dado que no mês atual ele esteja com 30 dias de atraso. Isto significa que ele estava com uma prestação em atraso e quando venceu a segunda prestação, ele pagou apenas uma. Assim ele ainda permaneceu com 30 dias em atraso.
A matriz de migração é obtida através do seguinte procedimento:
a) Contar quantas vezes ocorre cada migração (0-0; 0-30; 30-0; 30-30; 30-60; ...; 360-360) para todos os contratos;
b) Contar quantas vezes ocorre cada atraso (0; 30; 60; ...; 360) para todos os contratos;
Este resultado representa a probabilidade condicional de atraso, ou seja, a probabilidade de atraso “hoje”, dado o atraso de “ontem”.
Os resultados obtidos para o período estudado são apresentados na tabela 4 e Gráfico 6:
Tabela 4:Matriz de Migração
Dias de atraso (n) 0 30 60 90 120 150 180 210 240 270 300 330 360 0 97,15% 2,85%
30 38,36% 37,33% 24,31%
60 34,77% 15,53% 12,73% 36,97%
90 33,88% 7,37% 5,78% 4,24% 48,73%
120 30,76% 4,40% 2,90% 2,03% 1,91% 58,00%
150 26,74% 2,98% 1,75% 1,28% 1,02% 1,10% 65,12%
180 22,34% 1,83% 1,17% 0,94% 0,65% 0,61% 0,63% 71,82%
210 18,85% 1,05% 0,48% 0,41% 0,40% 0,38% 0,66% 0,48% 77,31%
240 16,01% 0,81% 0,45% 0,27% 0,34% 0,31% 0,28% 0,31% 0,48% 80,73%
270 13,74% 0,55% 0,27% 0,08% 0,25% 0,34% 0,23% 0,13% 0,34% 0,32% 83,76%
300 12,56% 0,42% 0,19% 0,16% 0,16% 0,14% 0,14% 0,19% 0,16% 0,28% 0,30% 85,31%
330 11,06% 0,28% 0,25% 0,11% 0,06% 0,06% 0,20% 0,08% 0,06% 0,11% 0,08% 0,22% 87,43%
360 4,44% 0,08% 0,03% 0,02% 0,02% 0,02% 0,04% 0,02% 0,05% 0,02% 0,02% 0,04% 95,20%
Dias de atraso (n+1)
O Autor
2,85% 24,31%
36,97% 48,73%
58,00% 65,12%
71,82% 77,31%
80,73%
83,76% 85,31% 87,43%
95,20%
0 para 30 30 para 60 60 para 90 90 para 120 120 para 150 150 para 180 180 para 210 210 para 240 240 para 270 270 pra 300 300 para 330 330 para 360 360 acima
Gráfico 6:Probabilidade de migração de atraso O Autor
O ponto de corte adotado corresponde ao prazo de 180 dias, onde se verifica que das operações que atingem este nível de atraso 28,2% voltam à situação de adimplência ou menor atraso e 71,8% migram para atrasos maiores.
“Art. 10. O descumprimento é definido como a ocorrência de pelo menos um dos seguintes eventos:
I - para exposição classificada na categoria "varejo":
a) a instituição financeira considera que o tomador ou contraparte não irá honrar integralmente a respectiva obrigação sem que a instituição financeira recorra a ações tais como a execução de garantias prestadas; ou
b) a respectiva obrigação está em atraso há mais de 180 dias, no caso de exposição classificada na subcategoria "residencial", ou há mais de noventa dias, no caso de exposição classificada nas demais subcategorias;”
Na análise das informações, verificou-se que os dados não eram balanceados. Dos 268.036 contratos que compõe o banco de dados, 9.680, que representam aproximadamente 3,6% das operações registradas na base, apresentaram falha (default) e os 96,4% restante foram censurados, ou seja, não apresentaram default no período. A tabela 5 apresenta a distribuição de default.
Tabela 5: Distribuição de default
default Freqüência %
Censura 258.356 96,39
Default 9.680 3,61
O Autor
Em razão da disparidade identificada entre as quantidades dos contratos censurados e não censurados, o estudo foi realizado a partir da construção de amostra balanceada. A amostra foi extraída conforme Whalen (1991), composta por todos os contratos que atingiram default no período e o complemento estratificado de forma aleatória do subconjunto de dados censurados. Sendo assim, a amostra para a modelagem foi composta por 9.680 contratos que entraram em default e 9.680 contratos censurados, totalizando 19.360 registros.
0% 1% 2% 3% 4% 5% 6% 7%
6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 Tempo de sobrevivência
% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% % a cu m u la d o % Censura % ac Censura
Gráfico 7:Distribuição do tempo de sobrevivência para dados censurados O Autor
O gráfico 7 mostra que, dos contratos censurados, 35% foram censurados até o 48º mês e observa-se concentração de censura entre o 42º mês e 52º mês. O período selecionado para contratação e para observação do comportamento de atraso garante que todos os contratos tenham, no mínimo, 36 meses de histórico de pagamento. Por isso, a censura foi observada apenas a partir do 37º mês.
0% 1% 1% 2% 2% 3% 3% 4%
6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 Tempo de sobrevivência
% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% % a cu m u la d o % Default % ac Default
O gráfico 8 ilustra o mês em que aconteceu o default pela primeira vez. Dos contratos que entraram em default, 55,12% entraram até o 36º mês e 71,93% entraram até o 42º mês.
5.2 Matriz de correlação
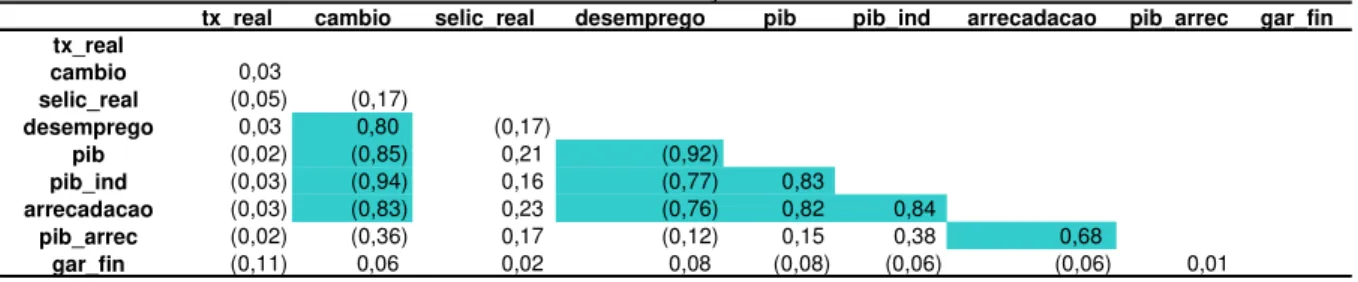
Um elemento importante a ser considerado nos modelos de previsão é a correlação entre as variáveis independentes. A inclusão de variáveis altamente correlacionadas não é desejável, pois estas variáveis, chamadas de colineares, fornecem informações similares para explicar o comportamento da variável dependente, prejudicando a capacidade preditiva do modelo. A tabela 6 apresenta os coeficientes de correlação de Pearson das variáveis do modelo. 1
Tabela 6: Matriz de correlação
tx_real cambio selic_real desemprego pib pib_ind arrecadacao pib_arrec gar_fin tx_real
cambio 0,03
selic_real (0,05) (0,17)
desemprego 0,03 0,80 (0,17)
pib (0,02) (0,85) 0,21 (0,92)
pib_ind (0,03) (0,94) 0,16 (0,77) 0,83
arrecadacao (0,03) (0,83) 0,23 (0,76) 0,82 0,84
pib_arrec (0,02) (0,36) 0,17 (0,12) 0,15 0,38 0,68
gar_fin (0,11) 0,06 0,02 0,08 (0,08) (0,06) (0,06) 0,01
Coeficiente de correlação de Pearson
O Autor
A matriz de correlação mostra alta correlação do câmbio e com as variáveis: índice de desemprego, PIB, PIB industrial e arrecadação. O índice de desemprego possui alta correlação com o PIB, PIB industrial e arrecadação. Por último, os indicadores do PIB, PIB industrial e arrecadação são altamente correlacionados. A inclusão conjunta na regressão dessas variáveis macroeconômicas altamente correlacionadas deve ser evitada, pois pode prejudicar o desempenho do modelo estimado.
1
5.3 Modelos para previsão de default
O software utilizado para a modelagem foi o SAS e os códigos estão apresentadas no Anexo I. Os modelos de regressão logística foram estimados utilizando a rotina “proc LOGISTIC” e os modelo de modelo de risco proporcional de Cox foram estimados por meio da rotina “proc PHREG”.
A seleção das variáveis foi realizada por meio da opção “stepwise”, em que as variáveis são incluídas uma a uma no modelo e, caso sejam significativas permanecem, caso contrário, são retiradas.
O teste de significância sobre os parâmetros para a decisão da permanência da variável baseia-se na estatística Qui-Quadrado sob a hipótese nula : 0
^
0 i =
H
β
, sendoi
β
^o parâmetro estimado para a variável i.
O teste estatístico do parâmetro deve ter um p-valor menor que determinado nível de significância para que a variável permaneça no modelo. Neste caso o nível de significância exigido foi de 5%, valor normalmente assumido nos testes estatísticos.
O resultado será analisado por meio do sinal dos parâmetros estimados e do impacto na probabilidade de default decorrente da variação de uma unidade no valor do parâmetro mantendo as demais variáveis constantes.
Um sinal negativo para determinado parâmetro estimado indica um efeito adverso sobre a probabilidade de default decorrente de um aumento na variável correspondente. Nesse caso, quanto maior o valor da variável menor será a taxa de default. Já um sinal positivo indica um efeito positivo sobre a probabilidade de default decorrente de aumentos naquela variável.
Tabela 7: Modelos estimados por Regressão Logística
Modelo 1 Modelo 2 Modelo 3
Estima-tiva Erro Padrão Pr > ChiSq Efeito Marginal Estima-tiva Erro Padrão Pr > ChiSq Efeito Marginal Estima-tiva Erro Padrão Pr > ChiSq Efeito Marginal Constante 0,394 0,169 0,020 22,544 0,429 <,0001 18,066 0,384 <,0001
gar_fin 0,017 0,001 <,0001 0,4% 0,016 0,001 <,0001 0,4% 0,020 0,001 <,0001 0,5%
Instrução
1: Fundamental - - - - - - - - - - - -
2: Medio -0,154 0,038 <,0001 -3,8% -0,162 0,043 0,000 -4,0% -0,301 0,042 <,0001 -7,5%
3: Superior -0,841 0,048 <,0001 -21,0% -0,811 0,055 <,0001 -20,3% -1,242 0,052 <,0001 -31,0%
regiao
1: Norte - - - - - - - - - - - -
2: Nordeste -0,941 0,110 <,0001 -23,5% -1,004 0,122 <,0001 -25,1% -0,907 0,119 <,0001 -22,7%
3: Centro-Oeste -0,929 0,115 <,0001 -23,2% -0,992 0,128 <,0001 -24,8% -0,963 0,125 <,0001 -24,1%
4: Sul -1,189 0,108 <,0001 -29,7% -1,177 0,119 <,0001 -29,4% -1,090 0,116 <,0001 -27,3%
5: Sudeste -1,190 0,105 <,0001 -29,7% -1,176 0,115 <,0001 -29,4% -1,128 0,113 <,0001 -28,2%
Estado Civil
1: Solteiro/Separado - - - - - - - - - - - -
2: Casado/viúvo -0,364 0,031 <,0001 -9,1% -0,379 0,036 <,0001 -9,5% -0,476 0,035 <,0001 -11,9%
tx_anual 0,067 0,010 <,0001 1,7% 0,040 0,011 0,000 1,0% - - - -
Tipo de Renda
1: Não possui renda formal - - - - - - - - - - - -
2: Possui renda formal -0,577 0,083 <,0001 -14,4% -0,542 0,092 <,0001 -13,6% -0,539 0,091 <,0001 -13,5%
sexo
Masculino - - - - - - - - - - - -
Feminino -0,096 0,033 0,004 -2,4% -0,089 0,038 0,019 -2,2% -0,065 0,037 0,076 -1,6%
ctr_anterior -0,088 0,039 0,022 -2,2% - - - - - - - -
ctr_posterior 0,113 0,042 0,007 2,8% - - - - - - - -
selic_1_anual - - - - -0,486 0,012 <,0001 -12,1% - - - -
pib_ind_1 - - - - -0,134 0,003 <,0001 -3,3% -0,132 0,003 <,0001 -3,3%
spread - - - - - - - - 0,257 0,008 <,0001 6,4%
Parâmetro
O Autor
A razão entre valor do financiamento e o valor da garantia apresentou coeficiente positivo em todos os modelos, ou seja, quanto maior a razão, maior a probabilidade de default. Este resultado indica que um tomador que financia 100% do valor do imóvel tem maior probabilidade de default do que um tomador que financia apenas 30% do valor do imóvel. Como o imóvel é a garantia do financiamento, este resultado é esperado. O efeito marginal desta variável não foi muito diferente nos três modelos estimados, indicando que, caso as outras variáveis se mantenham constantes, um aumento de 1 ponto na razão entre o valor do financiamento e o valor do imóvel aumenta por volta de 0,4% o risco de o indivíduo entrar em default.
Conforme o esperado, as regiões mais pobres apresentaram risco superior às regiões mais ricas. A região Norte apresenta a maior probabilidade de default, sendo seguida pelas regiões Nordeste, Centro-Oeste, Sul e Sudeste. A região Sudeste chegou a apresentar risco de default 29% inferior à região Norte.
A análise do estado civil indica que a concessão de crédito para pessoas casadas/viúvas reduzem a probabilidade de default de 9,1%, no primeiro modelo, e 11,9%, no terceiro modelo, em relação às pessoas solteiras ou separadas. Este resultado é intuitivo, devido à suposição que as pessoas casadas tendem a possuir maior estabilidade financeira e, com isso, maior probabilidade de honrar os compromissos assumidos.
As mulheres apresentam risco que é 2,4% inferior aos homens no primeiro modelo. Este risco reduz à 1,6% no último modelo.
Os modelos sugerem que os proponentes que apresentaram renda formal têm menor probabilidade de default que os indivíduos que possuíam renda informal. O risco para os indivíduos que apresentaram renda formal reduz em mais de 13% em relação aos demais indivíduos, pois quem possui apenas renda informal possui maior incerteza e volatilidade.
Os indivíduos que possuíam algum contrato ativo com a instituição no momento da contratação de crédito imobiliário possuem um risco 2,2% inferior aos demais indivíduos. Este resultado indica risco menor para os indivíduos que já possuem relacionamento com o banco e mostra a importância de fidelizar o cliente. Porém, esta variável foi estatisticamente significativa apenas no primeiro modelo.
Por outro lado, proponentes que contrataram outro produto com o banco após o financiamento habitacional possuem maior probabilidade de default, aumentando o risco em 2,8% em relação aos demais indivíduos que não fizeram tal contratação. Isso indica que o banco tende a oferecer outros tipos de crédito, dificultando o pagamento. Esta variável também foi significativa apenas para o primeiro modelo.
A taxa SELIC apresentou coeficiente negativo, ou seja, quanto maior a SELIC, menor a probabilidade de default. O efeito marginal indica que a queda de um ponto percentual no valor da taxa implica em aumento na probabilidade de default da ordem de 12,1%. Economicamente podemos explicar a situação da seguinte forma, redução da taxa de juros decorrente de política monetária expansionista implica em menor retorno financeiro nas operações de tesouraria realizadas por instituições financeiras, essa perda de receita deve ser compensada por meio da expansão da carteira de crédito. Para aumentar o volume de aplicação na carteira de crédito a instituição financeira deve flexibilizar sua avaliação de risco, ou seja, o banco deve conceder crédito a indivíduos com maior risco tendo como conseqüência elevação na sua probabilidade de default.
O PIB Industrial apresentou coeficiente negativo, ou seja, quanto maior o PIB industrial, menor será a probabilidade de default. O aumento de um ponto no valor do PIB industrial implica redução na probabilidade de default da ordem de 3,3%. Economicamente, o crescimento do PIB indica economia aquecida, pessoas empregadas e elevação da renda, fato que implica menor taxa de default.
O terceiro modelo substituiu a taxa do contrato e a taxa SELIC pelo spread. Esta variável apresentou relação direta com a taxa de default, indicando que o aumento de um ponto percentual no valor do spread aumenta a probabilidade de default em 6,4%.
Tabela 8: Modelos estimados por meio do modelo de risco proporcional de Cox
Modelo 4 Modelo 5 Modelo 6
Estima-tiva PadrãoErro ChiSqPr > MarginalEfeito Estima-tiva PadrãoErro ChiSqPr > MarginalEfeito Estima-tiva PadrãoErro ChiSqPr > MarginalEfeito gar_fin 0,010 0,001 <,0001 1,1% 0,007 0,001 <,0001 0,7% 0,009 0,001 <,0001 0,9%
Instrução
1: Fundamental - - - - - - - - - - - -
2: Medio -0,065 0,025 0,009 -6,3% -0,056 0,025 0,025 -5,4% -0,115 0,025 <,0001 -10,8%
3: Superior -0,537 0,034 <,0001 -41,6% -0,402 0,034 <,0001 -33,1% -0,605 0,032 <,0001 -45,4%
regiao
1: Norte - - - - - - - - - - - -
2: Nordeste -0,523 0,060 <,0001 -40,7% -0,462 0,060 <,0001 -37,0% -0,447 0,060 <,0001 -36,1%
3: Centro-Oeste -0,500 0,063 <,0001 -39,4% -0,432 0,063 <,0001 -35,1% -0,441 0,063 <,0001 -35,7%
4: Sul -0,733 0,058 <,0001 -51,9% -0,582 0,059 <,0001 -44,1% -0,572 0,058 <,0001 -43,5%
5: Sudeste -0,738 0,055 <,0001 -52,2% -0,588 0,056 <,0001 -44,4% -0,596 0,056 <,0001 -44,9%
Estado Civil
1: Solteiro/Separado - - - - - - - - - - - -
2: Casado/viúvo -0,256 0,021 <,0001 -22,6% -0,213 0,021 <,0001 -19,2% -0,268 0,021 <,0001 -23,5%
tx_anual 0,059 0,007 <,0001 6,1% 0,044 0,007 <,0001 4,5%
Tipo de Renda
1: Não possui renda formal - - - - - - - - - - - -
2: Possui renda formal -0,314 0,046 <,0001 -26,9% -0,211 0,047 <,0001 -19,0% -0,226 0,047 <,0001 -20,2%
sexo
Masculino - - - - - - - - - - - -
Feminino -0,057 0,023 0,013 -5,5% -0,040 0,023 0,080 -3,9% -0,035 0,023 0,129 -3,4%
ctr_posterior 0,098 0,023 <,0001 10,3% 0,090 0,023 <,0001 9,4% 0,049 0,022 0,029 5,0%
selic_1_anual - - - - -0,240 0,007 <,0001 -21,4% - - - -
pib_ind_1 - - - - -0,091 0,001 <,0001 -8,7% -0,088 0,001 <,0001 -8,4%
spread - - - - - - - - 0,144 0,005 <,0001 15,4%
Parâmetro
O Autor
Analogamente aos modelos estimados por regressão logística, todos os modelos de risco proporcional de Cox apresentaram coerência nos sinais esperados para os coeficientes. Porém, a análise do efeito marginal sobre a variável dependente apresentou valores superiores aos encontrados nos modelos estimados por regressão logística. As variáveis nível de instrução e região geográfica apresentaram os maiores efeitos marginais para estes modelos.
Os indivíduos que concluíram o ensino superior tem um o risco reduzido de mais de 40% no modelo 4 e no modelo 6 e 32% no quinto modelo em relação aos que concluíram apenas o ensino fundamental.
5.4 Coeficientes de acurácia
Seguem os resultados dos indicadores de acurácia para os modelos estimados.
KS 0% 10% 20% 30% 40% 50% 60% 70% Modelo K S
KS 20% 54% 46% 13% 30% 21%
Logistic sem
macro Logistic macro Logistic spread Cox sem Macro Cox Macro Cox spread
AR 0% 20% 40% 60% 80% 100% Modelo
AR 0,30 0,93 0,81 0,17 0,45 0,35 Logistic sem
macro Logistic macro Logistic spread Cox sem
Macro Cox Macro Cox spread
AUROC 0% 20% 40% 60% 80% 100% Modelo
AUROC 0,65 0,94 0,89 0,61 0,68 0,62 Logistic sem Logistic macro Logistic Cox sem Cox Macro Cox spread
Entropia 0% 10% 20% 30% 40% Modelo
Entropia 4% 25% 20% 2% 9% 5% Logistic sem
macro Logistic macro Logistic spread Cox sem
Macro Cox Macro Cox spread
O Autor
O modelo estimado por regressão logística sem a inclusão de variáveis macroeconômica teve um desempenho inferior aos modelos que consideraram o cenário econômico e quase semelhante ao modelo proporcional de Cox que considerou a variável spread.
Os indicadores de acurácia apontaram o modelo logístico com variáveis macroeconômicas como o modelo de melhor desempenho entre os modelos estimados, sendo que esta acurácia tem uma ligeira redução quando se substitui a taxa SELIC e a taxa do contrato pelo Spread.
6 CONCLUSÃO
O trabalho teve como objetivo identificar determinantes da taxa de default no mercado de empréstimos imobiliários por meio da comparação de modelos alternativos considerando variáveis do perfil do tomador de crédito e características do contrato. O estudo considerou modelos estimados por Regressão logística e Modelo de risco proporcional de Cox.
O estudo considerou, inicialmente, apenas variáveis de perfil do tomador e características do contrato e depois foram incluídas variáveis macroeconômicas nos modelos identificados para verificar o ganho no poder preditivo com a inclusão destas variáveis. Por último, o modelo foi estimado substituindo a taxa do contrato e a taxa SELIC pelo spread.
A acurácia dos modelos foi verificada por meio dos indicadores Kolmogorov Sminorv, Razão de Acurácia, AUROC e entropia. Todos os indicadores apontaram uma melhor acurácia para os modelos estimados por regressão logística. A inclusão de variáveis macroeconômicas aumentou significativamente a acurácia dos modelos estimado por regressão logística e do modelo de risco proporcional de Cox. A substituição da taxa SELIC e da taxa do contrato pelo Spread resultou em queda nos indicadores de acurácia em relação aos demais modelos que consideraram o cenário econômico, mas superior aos modelos antes da inclusão das variáveis macroeconômicas.
REFERÊNCIAS
AGRESTI, A. Categorical data analysis. New York: John Wiley and Sons. 1990. 558p.
ANNIBAL, C. A. O Poder discriminante das operações de crédito das Instituições Financeiras brasileiras. Banco Central do Brasil. Trabalhos para discussão 167. , 67 p. 2008.
BALZAROTTI, V.; FALKENHEIM, M.; POWELL A. On the Use of Portfolio Risk Models and Capital Requirements in Emerging Markets: The Case of Argentina. The World Bank Economic Review.Washington: The International Bank for
Reconstruction and Development, v. 16, p. 197-212, n. 2: 2002.
BATISTA, S. R. F., DIVINO, J.A; Taxa de Juros e Default em Mercados de Empréstimos Colateralizados. Estudos Econômicos. USP. Impresso: 2011.
BASEL COMMITTEE ON BANKING SUPERVISION - BCBS. Working Paper nº 14: Studies on the Validation of Internal Rating Systems. Bank for International
Settlements, maio de 2005. 120 p
BRAGA, A. C. S. Curvas ROC: Aspectos Funcionais e Aplicações. Tese de doutorado em Engenharia de Produção e Sistema. Escola de Engenharia, Universidade do Minho: 2000.
BRESLOW, N. Contribuição à discussão do artigo de D.R. Cox. Journal of the Royal Statistical Society B, 34, 216-217. 1972.
CARVALHO, Divino, Orrillo. Determinantes de Colateral em uma Economia
Empresarial.: Encontro Nacional de Economia. N 39. Anais. Foz do Iguaçu. p. 1-20. 2011.
CHAN-LAU, Jorge A. Fundamentals-Based Estimation of Default Probabilities: A Survey. Working Paper 06/149. [S.I]: International Monetary Fund, 2006. Disponível em: www.imf.org/external/pubs/ft/wp/2006/wp06149.pdf .Acesso em: 24/11/2011. COLLETT, D. Modelling binary data, Chapman and Hall: New York: 1991.
COLOSIMO, E.; GIOLO, S. Análise de sobrevivência aplicada. São Paulo: ABE-Projeto Fisher, 2006.
CROOK, J BELLOTTI, T Time varying and dynamic models for default risk in consumer loans. Journal of the Royal Statistical Society series A (Statistics in Society), Volume 173 Issue 2 , Pages 279 – 468. 2010.