406 DYNAMIC IDENTIFICATION SYSTEM OF A HYDROGEN FUEL CELL THROUGH FUZZY LOGIC
Texto
Imagem
![Figure 1: Alternative energy source based on fuel cell (hydrogen). Source: [2].](https://thumb-eu.123doks.com/thumbv2/123dok_br/16167153.707445/3.1063.226.900.994.1305/figure-alternative-energy-source-based-fuel-hydrogen-source.webp)
![Figure 2: The laboratory where has been obtained the fuel cell hydrogen data. Source: [2].](https://thumb-eu.123doks.com/thumbv2/123dok_br/16167153.707445/4.1063.176.830.339.741/figure-laboratory-obtained-fuel-cell-hydrogen-data-source.webp)
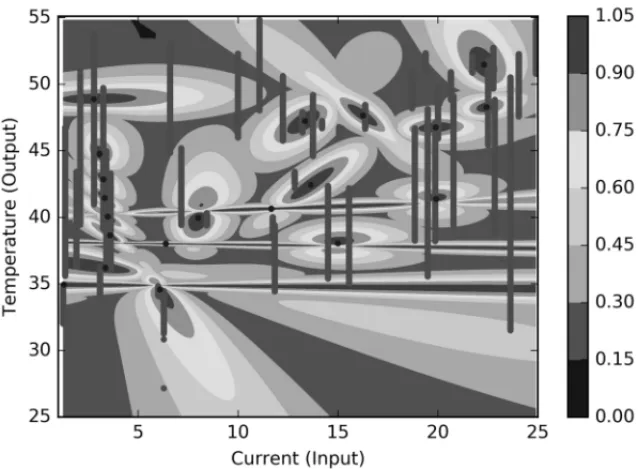
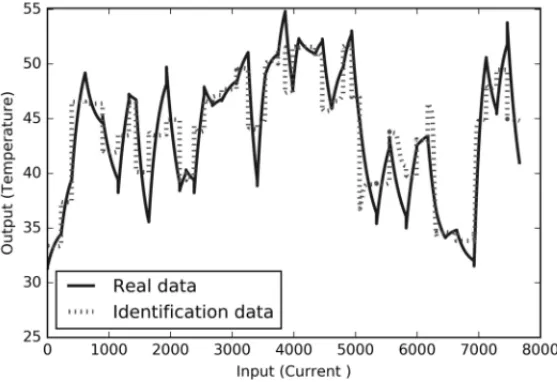
Documentos relacionados
Mulheres gestantes portadoras de DMG são classificadas como grávidas de risco, pois o agravo representa altos índices de morbidade, além de proporcionar maiores
This project focuses on motivating children, attending elementary education, engineering, and programming, using an application and robotics, so they can understand how computer
Using a large data set of independent validation samples, we demonstrate that the approach leads to a near optimum classification results when mapping five (crop) classes within
The overview enabled to conclude that although several tools exist that help players to play by giving statistical information and opponent characteristics there is no
Observamos, como limitação da pesquisa, que não houve nenhuma intervenção no grupo sobre suas atividades de vida, sendo identificada só a percepção dos adolescentes diante
se a lesão eatá situada no tèrgo uparior, os vómitos precoces aao nais repetidos e ^olorosos, isto 4» au tipo eao- façiano da questão; se está colocada mais a baixo, oa voaitoa
Luciani Ester Tenani, Universidade Estadual Paulista “Júlio de Mesquita Filho” (UNESP), São José do Rio Preto, São Paulo, Brasil Profa.. Maria Irma Hadler Coudry,
Dans le roman de Duras, au contraire de ce qui arrive chez Lispector, il est permis au lecteur de connaître l’intégralité du nom de Lol, Lola Valérie Stein, mais cette femme choisit
