Fuzzy Classification in the Determination of Input Application Zones
Texto
Imagem

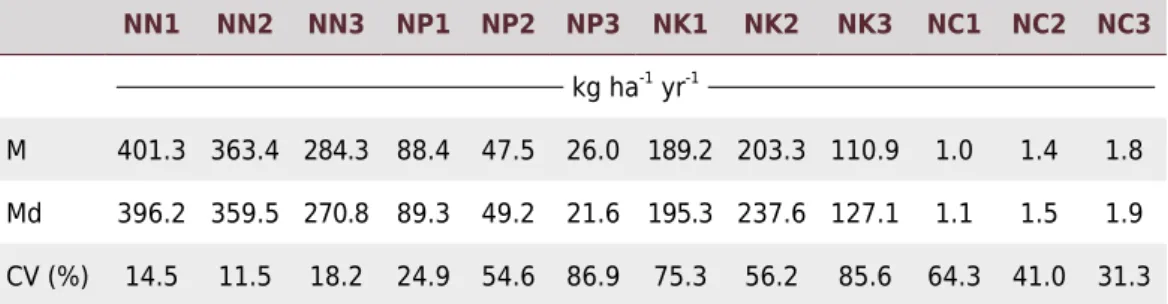
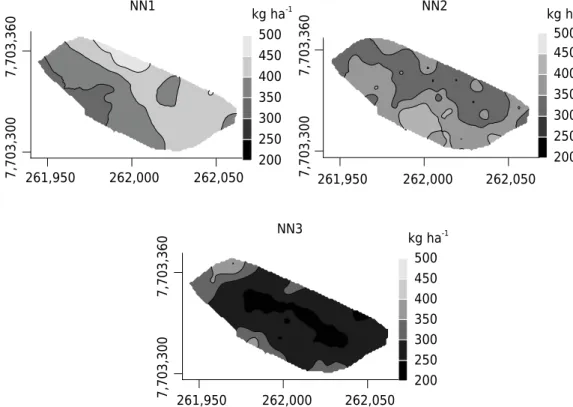
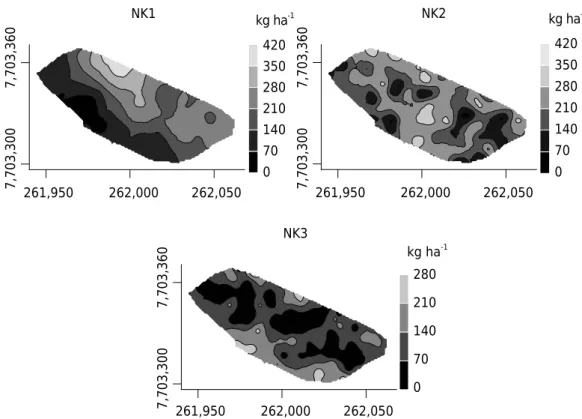
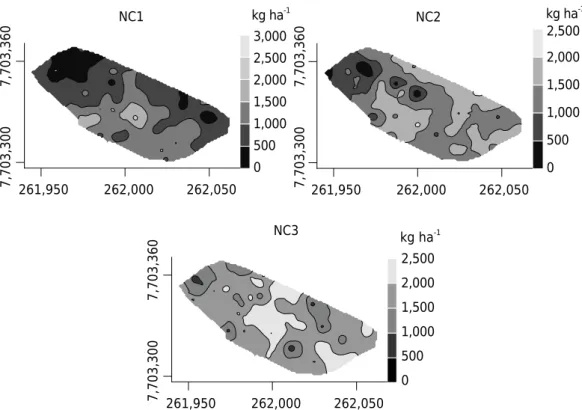

Documentos relacionados
didático e resolva as listas de exercícios (disponíveis no Classroom) referentes às obras de Carlos Drummond de Andrade, João Guimarães Rosa, Machado de Assis,
i) A condutividade da matriz vítrea diminui com o aumento do tempo de tratamento térmico (Fig.. 241 pequena quantidade de cristais existentes na amostra já provoca um efeito
This study aims to demonstrate that a modification of a chevron osteotomy, as popularized by Austin and Leventhen (1) , and largely employed for mild deformities, allows the
Neste trabalho o objetivo central foi a ampliação e adequação do procedimento e programa computacional baseado no programa comercial MSC.PATRAN, para a geração automática de modelos
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
The Function Block Types defined in Fuzzy Control Language FCL shall specify the input and output parameters and the Fuzzy Control specific rules and declarations.. The
The probability of attending school four our group of interest in this region increased by 6.5 percentage points after the expansion of the Bolsa Família program in 2007 and
No campo, os efeitos da seca e da privatiza- ção dos recursos recaíram principalmente sobre agricultores familiares, que mobilizaram as comunidades rurais organizadas e as agências
