Carlos Roberto Pereira Almeida Júnior
VERSÃO REVISADA
Ficha catalográ ca elaborada pela Biblioteca Prof. Achille Bassi e Seção Técnica de Informática, ICMC/ USP,
com os dados fornecidos pelo(a) autor(a)
Almeida Júnior, Carlos Roberto Pereira
A447p P2L - Uma ferramenta de profiling ao nível de instrução para o processador softcore LEON3 / Carlos Roberto Pereira Almeida Júnior; orientador Eduardo Marques. – São Carlos – SP, 2016.
102 p.
Dissertação (Mestrado - Programa de Pós-Graduação em Ciências de Computação e Matemática Computacional) – Instituto de Ciências Matemáticas e de Computação,
Universidade de São Paulo, 2016.
Carlos Roberto Pereira Almeida Júnior
FINAL VERSION
AGRADECIM ENTOS
Aos meus pais Carlos e Terezinha pelo amor, apoio e esforço sem tamanho para que eu pudesse me dedicar aos estudos desde o princípio. Sem eles, indubitavelmente, não teria chegado atéestaetapa.
Ao meu orientador, Prof. Eduardo Marques, que me aceitou como aluno e situou-me diversasvezes em meu projeto depesquisa. A suacontribuição técnicaede valores humanossão inestimáveis.
Aos Professores Vanderlei Bonato eMaikon Adilles pelas dicas valiosas e que contribuí-ram deforma significativa paraaconclusão desteprojeto.
À minha esposa, Anne, por ter tornado minha vida mais feliz e manter-me são nos momentos demaior dificuldade.
Ao Rubem Saldanha da Intel por ceder o kit de desenvolvimento utilizado nestetrabalho etambém ao Magnus Hjorth eJan Andersson daCobham Gaisler AB pelo suporteao LEON3.
“ It is paradoxical, yet true, to say, that themoreweknow, themoreignorant
RESUM O
ALMEIDA JÚNIOR, CARLOS R. P.. P2L - Uma ferramenta deprofiling ao nível deinstru-ção para o processador softcoreLEON3. 2016. 102f. Dissertação (Mestrado em Ciências– Ciências deComputação eMatemáticaComputacional) – Instituto deCiênciasMatemáticas e deComputação (ICMC/USP), São Carlos – SP.
A maioria dos sistemas embarcados hoje desenvolvidos utilizam complexos sistemas eletrônicos integrados em um único chip, os Systems-on-a-Chip (SoC). A análise do comportamento de uma aplicação em execução, ou seja, o profiling nessessistemasnão éumatarefatrivial em virtudeda complexidadedos SoCsepelarestrição deferramentas deprofiling adequadas. Nestecontexto, este trabalho apresenta o P2L, umaferramenta de profiling que se baseiaem métricasde nível de instrução efunção para o processador LEON3. O P2L fornece estatísticas detalhadasde uso do processador, memóriase barramento de programas em execução sem uso deinstrumentação. A ferramentaécomposta por um componenteem hardwareedrivers eaplicativos em software. Os resultados mostram queo P2L fornecemedidascom erro inferior a1% eoverhead desprezível quando comparado ao tempo de execução nativa do programaeao do profiler GNU gprof.
ABSTRACT
ALMEIDA JÚNIOR, CARLOS R. P.. P2L - Uma ferramenta de profiling ao nível de in-strução para o processador softcoreLEON3. 2016. 102f. Dissertação (Mestrado em Ciências – Ciências deComputação eMatemática Computacional) – Instituto deCiências Matemáticas e
deComputação (ICMC/USP), São Carlos – SP.
Most embedded systemsdeveloped today usecomplex electronic systemsintegrated into asingle chip, the Systems-on-a-Chip (SoC). The analysis of the behavior of a running application or profiling in thesesystemsis not atrivial task dueto thecomplexity of the SoC and therestriction of appropriate profiling tools. In this context, this work presents P2L - a profiling tool that is based on instruction and function level metrics for theLEON3 processor. P2L providesdetailed usage statistics of the processor, memories, and bus of running programs without the use of instrumentation. Thetool consists of acomponent in hardware, drivers and applicationssoftware. The results show that P2L provides measures with an error less than 1% and negligibleoverhead compared to nativeruntimeprogram and theGNU profiler gprof.
LISTA DE ILUSTRAÇÕES
Figura1 – Alternativasdeimplementação . . . 26
Figura2 – Umaabordagem paraCo-Projeto . . . 27
Figura3 – Contextualização do trabalho . . . 27
Figura4 – Instrumentação - possíveisetapas parainserção deprobes . . . 35
Figura5 – Resultado do profiling ao nível deinstruções deum softwarehipotético . . . 42
Figura6 – Arquitetura genéricadaSnoopP. . . 43
Figura7 – Arquitetura daferramentaACAD . . . 44
Figura8 – Arquitetura daferramentaMPPA . . . 45
Figura9 – Placadedesenvolvimento Terasic DE2i-150 . . . 48
Figura10 – Arquitetura daTerasic DE2i-150 . . . 48
Figura11 – Diagramainterno do processador LEON3 . . . 51
Figura12 – Formato ELF . . . 53
Figura13 – Configuração do LEON3: principal . . . 58
Figura14 – Configuração do LEON3: barramento, memórias eperiféricos. . . 59
Figura15 – Fluxo dedesenvolvimento com ferramentas GRLIB eAltera . . . 60
Figura16 – Arquitetura simplificadado LEON3 com módulo P2L . . . 61
Figura17 – Estágios dePipelinedo LEON3 . . . 62
Figura18 – Análise do Pipeline - Modelsim . . . 63
Figura19 – Arquivos editados parainterfacedesinal daUnidadedeInteiros. . . 63
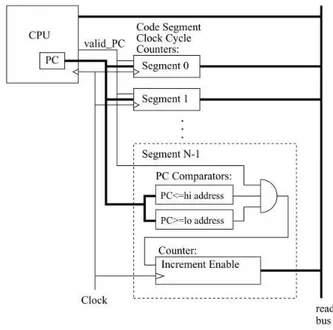
Figura20 – L3STAT - Registro decontroledecontadores. . . 66
Figura21 – Análise de formas deondana capturadeeventos relacionadosàinstruções . 67 Figura22 – Diagramas deblocos do módulo P2L . . . 69
Figura23 – Configuração desegmentos decódigo eeventosno P2L . . . 71
Figura24 – P2L - Fluxo completo deum profiling . . . 72
Figura25 – P2L - Etapa1 deconfiguração deum profiling . . . 73
Figura26 – P2L - Etapa2 deconfiguração deum profiling . . . 74
Figura27 – P2L - Etapa3 deconfiguração deum profiling . . . 75
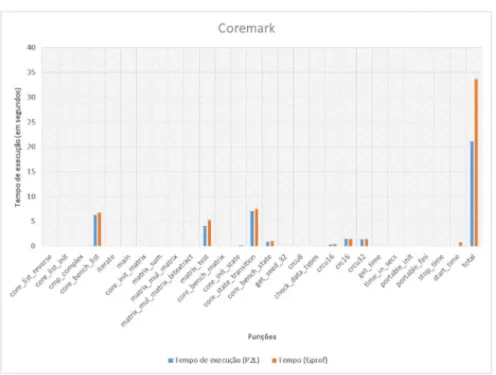
Figura28 – Coremark - Tempo deexecução . . . 81
Figura29 – Dhrystone- Tempo deexecução . . . 85
Figura30 – Mi Bench Susan - Tempo deexecução . . . 87
Figura31 – Mi Bench Djikstra- Tempo deexecução . . . 89
LISTA DE QUADROS
Quadro 1 – Algoritmo paracomputação de um número fatorial . . . 30
Quadro 2 – Contagem deciclos de clock das instruções assembly do fatorial de3 . . . 31
Quadro 3 – Resultado do testedeassertividade. . . 56
Quadro 4 – Unidadedeestatíticas - Eventos disponíveis . . . 65
Quadro 5 – Unidadedeestatíticas - Mapeamento no barramento AHB/APB . . . 66
Quadro 6 – Análisedafunção deexemplo - Definição desegmentosdecódigo . . . 66
Quadro 7 – Espaço de enderaçamento do P2L no barramento AHB/APB . . . 69
Quadro 8 – Análisedafunção deexemplo - Definição desegmentosdecódigo . . . 70
Quadro 9 – Análisedafunção deexemplo - Definição deeventos eprecisão . . . 70
Quadro 10 – Configuração da Plataforma de Testes . . . 78
Quadro 11 – Eventosselecionadosparaos experimentos . . . 79
Quadro 12 – Coremark - Geral . . . 79
Quadro 13 – Dhrystone- Geral . . . 83
Quadro 14 – Mi Bench Susan - Geral . . . 86
Quadro 15 – Mi Bench Djikstra- Geral . . . 86
LISTA DE CÓDIGOS-FONTE
Código-fonte1 – TestedeassertividadeparaModelsim - Código em C . . . 55
Código-fonte2 – TestedeassertividadeparaModelsim - Código em Assembly . . . . 56
Código-fonte3 – Exemplo: instânciadeum componenteem leon3mp.vhd . . . 58
Código-fonte4 – Modificações naUnidadedeInteiros . . . 63
Código-fonte5 – Modificações naUnidadedeestatística . . . 67
Código-fonte6 – Conexão deestatísticas e . . . 68
LISTA DE TABELAS
Tabela1 – Recursosdisponíveis nasPMUs. . . 39
Tabela2 – Exemplo davisualização dedados gerados por profiling . . . 42
Tabela3 – Coremark - Tempo médio deexecução . . . 80
Tabela4 – Coremark - Métricasdenível deinstrução . . . 82
Tabela5 – Dhrystone- Tempo médio deexecução . . . 83
Tabela6 – Dhrystone- Métricas denível deinstrução . . . 84
Tabela7 – Mi Bench Susan - Tempo médio deexecução. . . 87
Tabela8 – Mi Bench Susan - Métricasdenível deinstrução . . . 88
Tabela9 – Mi Bench Djikstra- Tempo médio deexecução . . . 89
Tabela10 – Mi Bench Djikstra- Métricasdenível deinstrução. . . 90
Tabela11 – CPU SPEC2006 Bzip2 - Tempo médio deexecução . . . 92
Tabela12 – CPU SPEC2006 Bzip2 - Métricas denível deinstrução . . . 93
SUM ÁRIO
1 INTRODUÇÃO . . . 25
1.1 Contextualização . . . 25
1.2 M otivação e Objetivos . . . 27
1.3 Objetivos . . . 28
1.3.1 Objetivo Geral . . . 28
1.3.2 Objetivos especí cos . . . 28
1.3.3 Justi cativa. . . 29
1.4 Organização do Trabalho. . . 30
2 FUNDAM ENTAÇÃO TEÓRICA . . . 33
2.1 Pro ling . . . 33
2.1.1 Instrumentação . . . 34
2.1.2 Amostragem . . . 36
2.1.3 Abordagens sem intrusividade e baixo overhead . . . 37
2.1.4 M onitoramento . . . 37
2.1.4.1 Monitoramento exato e estatístico . . . 38
2.1.4.2 Monitoramento com suporte por contadores de hardware . . . 39
2.1.5 Análise . . . 40
2.1.5.1 Análise Post-Mortem . . . 41
2.1.5.2 Análise On-the- y . . . 41
2.1.6 Visualização . . . 41
2.2 Trabalhos relacionados . . . 42
2.2.1 SnoopP . . . 42
2.2.2 ACAD . . . 43
2.2.3 M PPA . . . 44
3 M ATERIAIS E M ÉTODOS . . . 47
3.1 Plataforma de Desenvolvimento . . . 47
3.2 GRLIB . . . 49
3.3 GRM ON. . . 50
3.4 Processador LEON3. . . 50
3.5 L3STAT . . . 51
3.7 Sistema Operacional Linux. . . 52
3.8 Fomato ELF . . . 52
3.9 M étodos de validação. . . 53
4 IM PLEM ENTAÇÃO DA ARQUITETURA PROPOSTA . . . 57
4.1 Fluxo de desenvolvimento do Hardware . . . 57
4.2 Implementação do core P2L . . . 60
4.2.1 Unidade de Inteiros . . . 61
4.2.2 Unidade de estatísticas . . . 64
4.2.3 Integração de dados obtidos na Unidade de Inteiros e de Estatísticas com o P2L . . . 68
4.3 Preparação da aplicação para pro ling . . . 71
4.4 Driver e Escalonador para Linux . . . 72
4.5 Ferramentas de controle e relatório . . . 74
5 RESULTADOS . . . 77
5.1 Benchmarks . . . 77
5.2 Experimentos. . . 78
5.2.1 Coremark . . . 78
5.2.2 Dhrystone. . . 83
5.2.3 M iBench . . . 86
5.2.3.1 Controle Automotivo e Industrial: Susan . . . 86
5.2.3.2 Telecomunicações - Djikstra. . . 86
5.2.4 SPEC CPU2006 . . . 91
5.2.5 Considerações . . . 94
6 CONCLUSÃO . . . 95
6.0.6 Trabalhos Futuros . . . 95
25
CAPÍTULO
1
INTRODUÇÃO
1.1 Contextualização
Os sistemas embarcados podem ser definidos como sistemas de processamento incor-porados a produtos dos quais a maioria são pouco visíveis e perceptíveis para os humanos. Esses sistemascomandam robôs no chão de fábrica, coordenam motores, processos químicose satélites. Auxiliam avidadoméstica, controlando máquinasdelavar, micro-ondas elava louças. Equipam brinquedosinteligentes, smartphonesetablets. Por fim, estão presentesem diversos ambientes e compõem uma área de aplicação importante da tecnologia da informação (LEE; SESHIA, 2015; MARWEDEL, 2006). O nível de complexidade das aplicações embarcadas determinaumaamplaabordagem no desenvolvimento desses sistemas. Os mesmospodem ser concebidos com circuitosintegrados off-the-shelf ; circuitosintegrados personalizados, como os Application-Specific Integrated Circuits (ASIC); ecircuitosintegrados reconfiguráveis, os Field ProgrammableGateArrays (FPGAs). Em virtudedessasopções, umaaplicação simples podeter seusrequisitosatendidospor um modesto microcontrolador disponível comercialmente. Contudo, aplicações embarcadas mais complexas, como a de um sistema autônomo em um automóvel, exigem inúmeras unidades de processamento, memórias, periféricos e softwares que geral-menteestão integradosem componentes dentro de Systems-on-a-Chip (SoC) ou Multiprocessors System-on-Chip (MPSoC) sintetizados em FPGA ou fabricados em ASIC.
26 Capítulo 1. Introdução
While pure hardware synthesis tools like Hardware Description Languages allow the implementation of systems on a chip from high-level specification, the resulting cost of implementation isaconsiderable drawback. On the other hand, off-the-shelf generic processors, and implementation in software, are much cheaper, but seldom suit the hard time constraints imposed on embedded systems. Thus, cost-effective designs should use a mixture of hardware and software to accomplish their goals.
The problem with the design-oriented approach, where allocation of tasks to hardware and softwareprecedesthesynthesis, is that it is not known whether thefinal system will meet itsrequirements. Thissuggests a synthesis-oriented approach, whereconstraintson performanceand cost of thesystems arespeci-fied, and asystematic constraint-driven exploration of the design space is done. Themodel must first be given in termsof a specification for hardware(often in a Hardware Description Language) and for software. Then it ispartitioned, and thespecifications allow run-time estimations, simulations aswell ascost esti-mations, to test whether theresulting system meets theconstraints.(DUFOUR; RADETZKI, 2006)
Assim, o objetivo do particionamento dehardware/softwareéencontrar umacomposição coerente de componentes de hardware e software que não apenas satisfaça as restrições de desempenho, mas que também atenda a outros propósitos desejáveis, como segurança, baixo custo de comunicação, consumo de energia e etc (GEGUANG et al., 2004). Como resultado, esta etapa é dependente de ferramentas precisas de avaliação durante o desenvolvimento do sistema, conformeilustra aFigura 2. Umadelas éa deprofiling, queé responsável por analisar o comportamento de um programa em execução identificando regiõesineficientes ou degargalo, padrões de acesso à memória, Worst Case Execution Time (WCET) e etc. É desejável que o profiling seja preciso e ofereça baixo overhead para tornar o particionamento efetivo, pois em posse das informações obtidas por essa ferramenta, os segmentos críticos de programa podem ser otimizadospor versõesreescritasdo software, guiarem modificações naarquiteturade processadoresouseremconvertidasemaceleradoresdehardwareafimdeseobter ocumprimento deum requisito deprojeto ou melhorar o desempenho detodo sistema(MISHRA et al., 2012).
Figura1 – Alternativas deimplementação
Fonte: Elaboradapelo autor.
1.2. Motivação eObjetivos 27
Figura2 – Umaabordagem paraCo-Projeto
Fonte: Elaborada pelo autor.
relação ao nível deprecisão, overhead adicional no tempo execução daaplicação eintrusividade, que pode causar modificações no comportamento da aplicação analisada. O impacto desses aspectos varia de acordo com a plataforma alvo na qual as aplicações são executadas e da presença de um ambiente multitarefa. No contexto destetrabalho, conformeilustraa figura3, as ferramentasexistentessão insuficientesparalidar acomplexidadedosSoCs/MPSoCs eexigem novasabordagens, sendo ado P2L umapropostanestesentido.
Figura3 – Contextualização do trabalho
Fonte: Elaborada pelo autor.
1.2 M otivação e Objetivos
Um SoC avançado écomposto por inúmeras unidades funcionais. Analisar o comporta-mento de uma aplicação em um sistema tão complexo não é trivial e levaa algumasquestões: Como épossível executar um profiling dentro dessas arquiteturas?É necessário o uso deuma ou váriasferramentas? Como obter o desempenho máximo em uma plataforma senão houver boas técnicas deprofiling?
28 Capítulo 1. Introdução
dela, mastambém o comportamento do processador, acesso amemóriasebarramentos. Essas preocupaçõeslevam anecessidade de ferramentas de profiling dedicadas enão intrusivas. Nesse contexto, a computação reconfigurável oferece flexibilidade e condições de desenvolvimento deferramentasbaseadasem hardware e software. Baseando-senessesprincípios, o processador soft core LEON3 foi escolhido como plataforma alvo. O mesmo é amplamente configurável e adequado para projetos de SoCs. Possui código fonte completo disponibilizado com boa documentação e é baseado naarquitetura consagradado processador SPARC V8, herdando dela um ambiente de desenvolvimento de software maduro. Além disso, é utilizado em inúmeros projetosindustriaiscom destaqueaos daAgênciaEspacial Europeia.
1.3 Objetivos
1.3.1 Objetivo Geral
Este projeto tem como objetivo desenvolver uma ferramenta de profiling ao nível de instrução de alta precisão e baixa intrusividade para o processador soft-core LEON3. A essa ferramenta é dado o nome P2L, um acrônimo paraProfiler to LEON. O P2L tem como papel fornecer estatísticasdetalhadas de uso do processador, memórias e barramento de umaaplicação em execução com capacidadede fornecer informaçõessobrefunçõesou segmentos decódigo cujo desenvolvedor deseja saber o comportamento. Essa ferramenta sebaseiana implementação de um componenteem hardware, que mantém em bancosde registradoresas informações de profiling extraídasdaCPU edeum componentedeestatísticasdesenvolvido pela(GAISLER, 2016).
1.3.2 Objetivos especí cos
Os objetivos específicos deste trabalho são:
∙ Desenvolver um componenteem hardwareparaextrair informaçõesdo registrador Pro-gram Counter no estágio de pipeline adequado dentro da Unidade de Inteiros (UI) do processador LEON3 e, também, eventos geradospela unidade de estatísticasdesenvolvida pela(GAISLER, 2016);
∙ Desenvolver um driver para o sistemaoperacional Linux capaz degerenciar as funcionali-dades do hardwaredesenvolvido;
∙ Desenvolver um aplicativo paraextrair informações do programaalvo deanálise econfi-gurar o hardwaredeprofiling;
1.3. Objetivos 29
1.3.3 Justi cativa
Localizar regiões críticas deumaaplicação éo propósito de uma ferramentade profiling. Todavia, além de identifica-los com métricas associadas ao tempo de execução, determinar quais recursos de hardware estão associados ao gargalo torna-se necessário para se explorar melhor o desempenho deum SoC ou servir deparâmetro aum melhor particionamento durante o desenvolvimento de um sistema. Uma visão geral dessa questão é exemplificada com o auxílio do seguinte exemplo: a computação de números fatoriais é descrita por um simples algoritmo descrito em linguagem C eo correspondenteem assembly do conjunto deinstruções daarquiteturado LEON3 (Sparc V8) édescritano quadro1.
Observando o código assembly, podemosnotar queaestruturaderepetição édesempe-nhadaapóso offset 0x4c easrotinasquecomputam o fatorial, no segmento deoffset 0x1c a0x4c. Dentro deste último segmento, amultiplicação éexercidapelabiblioteca.umul. Elanão élevada em consideração neste exemplo, entretanto, o custo de cada operação varia de 25 a 45 ciclos de clock. A partir da informação que descreve o número de ciclos necessários para execução das instruções (descrito no manual (COBHAM-GAISLER, 2015)) é possível extrair algumas métricas deprofiling de formaoffline, ou seja, sem quesejanecessáriaaexecução do código. A partir da análisedo fluxo de instruçõessupondo aexecução do fatorial do inteiro 3, chega-se a conclusão que aquantidadedeinstruçõesa serem processadas éde63. No caso do cômputo de ciclosdeclock, acontagem éauxiliadapelo quadro2.
Os cabeçalhos Quantidade e Ciclos de processamento indicam, respectivamente, o número de instruções* contabilizados no fluxo de execução total do algoritmo do fatorial do número 3 e quantos ciclos de processamento são necessários para executar uma dessas instruções*.
Analisando o quadro anterior, conclui-seque as63 instruções seriam executadasem 78 ciclos de clock. Todavia, essacontagem não leva em conta os aspectos intrínsecos daarquitetura do processador LEON3. Entretanto, quando seconsiderao overhead no ciclo deexecução, os stallsno pipelineimplicam em um tempo deexecução diferentedo estimado. O código do fatorial quando executado em um LEON3 na suaconfiguração padrão1demandaem média2175 ciclos
de clock. Assim, conhecer as razões que implicam na diferença do tempo de processamento se torna desejável em uma ferramenta de profiling. Esta foi uma preocupação considerada na implementação do P2L. Logo, utilizando-sedessaferramenta, constatou-sequeascausasdo stall estão relacionadas com o cache miss dedadose deinstrução queocorrem, respectivamente, 4 e 2 vezes. Deste modo, estimar o tempo deprocessamento analisando apenas o fluxo deexecução offlinenão é ideal visto quea variação do valor estimado parao extraído naplataformareal éde cercade220%. Tal resultado legitimaaimportânciadas ferramentas deprofiling.
30 Capítulo 1. Introdução
Quadro 1 – Algoritmo paracomputação de um número fatorial
1 / / Códi go C 1 # A ssembl y
2 i n t f at o r i al ( i n t n) { 2 < f at or i al >:
3 i n t i = 0 , f = 1; 3 save %sp , − 104, %sp 4 f or ( i ; i < n ; i ++) { 4 st %i 0 , [ %f p + 0x44 ]
5 f = f * ( n− i ) ; 5 cl r [ %f p + − 8 ]
6 } 6 mov 1 , %g1
7 r et ur n f ; 7 st %g1 , [ %f p + − 4 ]
8 } 8 b f at o r i al +0x4c
9 nop
10 . f at o r i al +0x1c :
11 l d [ %f p + 0x44 ] , %g2 12 l d [ %f p + − 8 ] , %g1 13 sub %g2 , %g1 , %g1 14 l d [ %f p + − 4 ] , %o0 15 mov %g1 , %o1
16 cal l <.umul >
17 nop
18 mov %o0 , %g1
19 st %g1 , [ %f p + − 4 ] 20 l d [ %f p + − 8 ] , %g1 21 i nc %g1
22 st %g1 , [ %f p + − 8 ] 23 . f at o r i al +0x4c :
24 l d [ %f p + − 8 ] , %g2 25 l d [ %f p + 0x44 ] , %g1 26 cmp %g2 , %g1
27 bl f at o r i al +0x1c
28 nop
29 l d [ %f p + − 4 ] , %g1 30 mov %g1 , %i 0
31 r est or e 32 r et l
33 nop
1.4 Organização do Trabalho
1.4. Organização do Trabalho 31
Quadro 2 – Contagem de ciclos declock dasinstruções assembly do fatorial de3
Instrução* Quantidade Ciclosdeprocessamento Subtotal
save 1 1 1
st 8 2 16
clr 1 1 1
mov 8 1 8
b 1 1 1
bl 4 1 4
nop 9 1 9
ld 21 1 21
sub 3 1 3
call 3 1 3
inc 3 1 3
cmp 4 1 4
restore 1 1 1
retl 1 3 3
33
CAPÍTULO
2
FUNDAM ENTAÇÃO TEÓRICA
Estecapítulo discuteastécnicas empregadas pelos Profilersequaissão suas restrições parauso em aplicações em sistemasembarcados.
2.1 Pro ling
O processo que envolve aanálise de um programasobre umaarquiteturadehardware a fim dese obter informações sobreo seu comportamento ou aspectos de sua execução é o que defineum profiling. O resultado podeauxiliar na identificação deseçõescríticas quepermitem guiar o desenvolvedor namodificação dealgoritmosou estruturasdedados, configuração/projeto de arquiteturas de hardware ou na conversão de trechos de programa em aceleradores de hardware (MISHRA et al., 2012). Além disso, um profiler, ou seja, uma ferramenta de profiling, permitequeum desenvolvedor dehardware avalieseumanovaarquiteturaatingeos requisitos deprojeto, um desenvolvedor do software obter os pontosdegargalo ou hotspot deseu programa e, um desenvolvedor de compilador, verificar se o funcionamento de uma nova política de escalonamento de instruções conduz à melhoria do processo de compilação (SRIVASTAVA; EUSTACE, 1994).
34 Capítulo 2. Fundamentação Teórica
Essas ferramentas podem ser classificadas naquelas que simulam um conjunto de ins-truções easquemonitoram o programa naarquiteturadehardwarenaqual são executados. Os profilersbaseadosem Instruction Set Simulators(ISS) dispõem deum maior nível dedetalhes e maior precisão ao custo da velocidade de execução. Esse tipo de ferramenta é geralmente utilizada por desenvolvedores de arquiteturas de hardware paradeterminar o custo-benefício de uma arquiteturaapoiados por conjunto de benchmarks. Essetipo de profiling chegaaser 10 mil vezes mais lento que a execução nativa (LANCASTER et al., 2011). Dessa forma, tornam-se inviáveis parauso com softwaresgrandes ecom SoCs, cujanaturezaheterogênea constituí uma enorme dificuldadeparaaconcepção demodelosdesimulação (TONG; KHALID, 2008). Em razão dessas dificuldades, as ferramentas que sebaseiam naexecução do programano ambiente em quesão executadas são asmaisdifundidas.
Os autores Tong e Khalid (2008) e Patel e Rajawat (2011) realizaram esforços para estruturar as diferentes técnicas deprofiling no contexto de sistemas embarcados, que resultaram nacategorização detrêsabordagens. A primeira, profilersbaseadosem software, são aquelesque podem envolver simulação ou ainserção decódigosdemonitoramento dentro dosprogramas, sem dependênciade um hardwareespecial. Porém, causam considerável overhead. A segunda, as baseadas em hardware, são as queutilizam recursos presentesnessemeio, como registradores contadoresespeciais contidosem Performance Monitor Units(PMU) com o intuito defornecer medidasmais precisas detempo deexecução e outros eventos com menor overhead. Por último, abordagens que levaram ao desenvolvimento dehardwaresespecíficos para profiling em Field-ProgrammableGateArray (FPGA) queinteragem com soft processorsetem o objetivo decausar o mínimo overhead e oferecer alta precisão. Essa classificação não foi identificada em mais artigos dentro dessecontexto e, por essarazão, o enfoquedas subseções seguintes serábaseada nas técnicas enacisão do profiling como sendo o processo de monitorar, analisar e visualizar os dados dedesempenho definida por Lessard (2005).
2.1.1 Instrumentação
Os profilers podem exigir algum nível de modificação do código do programaao qual se deseja analisar o desempenho. A quantidadedecódigo inseridadefine o nível deintrusividade do profiler, sendo que os mais comuns se utilizam da instrumentação. Este é um processo de adicionar pequenos pedaços de código ou probes em um programa a fim de se analisar o seu comportamento econsistedetrêsetapas(MILLER; CALLAGHAN, 1995):
∙ Ponto deinstrumentação: local no código do programaondeo probeéinserido. Geral-mente são localizados na entrada e saída de métodos (edge profiling) e declarações de chamada(instruçõescall);
2.1. Profiling 35
desenvolvidos em hardwareou softwaree timersimplementadosem hardware;
∙ Predicado deinstrumentação: expressõesbooleanas que controlam aexecução deuma primitivadeinstrumentação (essencialmenteumadeclaração if ).
Figura 4 – Instrumentação - possíveis etapasparainserção de probes
Fonte: Elaborada pelo autor.
36 Capítulo 2. Fundamentação Teórica
programasejacompilado de forma estática para permitir ainstrumentação debibliotecas ou que estassejam instrumentadasseparadamenteseo executável fizer uso debibliotecascompartilhadas. Lembrando quenestecaso, o executável precisa ser gerado baseado nasbibliotecasmodificadas. Mesmo com essas restrições, o autor Laurenzano et al. (2010) descreve que esta abordagem pode ser eficiente em aplicações no domínio dos High Performance Computing (HPC), que podem abranger centenas ou milhares de processadores e funcionarem por horas. Neste caso, o código instrumentado tende a ser executado com overhead tolerável na coleta informações de desempenho, mas deve respeitar os prazos de deadlines da aplicação. Os profilers GNU Gprof (GRAHAM; KESSLER; MCKUSICK, 1982), Pebil (LAURENZANO et al., 2010) eCobi (Forschungszentrum Jülich GmbH, 2016) utilizam-se destatécnica.
Naformadinâmicaou just-in-time(JIT), ainstrumentação érealizadaduranteaexecução do programaem um processo que geraoverhead adicional por compreender tarefasde parsing, disassembly, geração decódigo eoutrasdecisõesem tempo deexecução. Estenão éum problema nos profilers de instrumentação estática, pois todas as decisões e ações são tomadas antes do tempo deexecução. Todavia, ofereceavantagem de não modificar o programapermanentemente e nem exigir o código fonte. Os profilers Pin (LUECK; PATIL; PEREIRA, 2012), Dyninst (BUCK, 2000) eValgrind (NETHERCOTE; SEWARD, 2007) são exemplos deferramentas que sebaseiam nessetipo deinstrumentação.
A intrusividade causada pelo probe introduzido de forma estática ou dinâmica causa inerenteoverhead no tempo deexecução do programa. Em sistemas embarcados, principalmente os reativos, cujasaplicações tem rigorosos restrições de cumprimento detempo real, écomum queo mínimo aumento do overhead não sejatolerável(SHANKAR, 2010). Em virtudedesses problemas que ainstrumentação podecausar, algunsprofilers evitam ou seutilizam da "instru-mentação leve"(METZ; LENCEVICIUS; GONZALEZ, 2005) a fim decausar baixo ou nenhum overhead durantea execução do programaanalisado.
2.1.2 Amostragem
2.1. Profiling 37
Os sistemas operacionais oferecem recursos para amostragem de programas. Dessa forma, um profiler pode, por exemplo, realizar a contagem de tempo com auxílio da syscall profil(), que é implementada nos sistemas UNIX-like e tem como função registrar um vetor no espaço de endereçamento do kernel em conjunto com um fator de escala que determina o mapeamento do endereçamento do programano vetor. Cadaelemento do vetor pode armazenar valoresdeescaladeendereçamento de2 a8 bytes. Durantea execução do programaem profiling, o valor do registrador programcounter éexaminado e o valor correspondenteno item do vetor é incrementado a cadatick do sistemade clock. Uma vez queisso ocorre no espaço do kernel, que precisainterromper o processo de qualquer formapara tratar ainterrupção declock, o overhead adicional éconsiderado pequeno.
Uma outra abordagem para sistemas operacionais que não oferecem a chamada de sistema profil() é o kernel gerenciar o envio deum sinal periodicamentepara o processo. Isso pode ser implementado pelo profiler utilizando chamadas de sistemassemelhantesa settimer(), que então realizaa mesmaoperação de examinar o program counter eincrementar um elemento do vetor em memória. Uma vez queestemétodo requer que um sinal seja enviado para o espaço de usuário para cada amostra, o overhead é consideravelmente maior e o atraso envolvido no processo desinalização torna o método bem menos preciso.
OsautoresGang Ren et al. (2010) descrevem o trabalho deprofiling queo Googlerealiza de formacontínua em seus data centerscom a consideração de queasferramentas baseadasem amostragem propiciam níveis aceitáveis deoverhead e imprecisão, sendo as únicasqualificadas parao monitoramento dedesempenho no data center, um contraponto aLaurenzano et al. (2010).
2.1.3 Abordagens sem intrusividade e baixo overhead
O overhead causado pela intrusividade, a preocupação com a precisão das técnicas que se utilizam de amostragem e ausência de meios para avaliar os complexos projetos de arquiteturas levaram ao surgimento dediversas iniciativas desistemasdeprofiling específicos para os sistemas embarcados, com alguns deles relatados nos projetos relacionados. Estes sistemas, quelidam com restriçõesdediversasnaturezasficam àmargem dacompatibilidadedas ferramentas deprofiler existentes, que se baseiam em arquiteturas maisdifundidas no mercado. Por essa razão, o desenvolvimento de hardwares para profiling tornaram-se uma opção a ser considerada, principalmente pelasetapasda concepção do produto em ASIC se basearem em ambientes dedesenvolvimento em plataforma reconfigurável(RIZZATTI, 2016).
2.1.4 M onitoramento
38 Capítulo 2. Fundamentação Teórica
processo, função einstrução. Nonível desistemas, o maisalto deles, observa-seo comportamento externo do sistema e/ou a interação entre sistemas diferentes. No nível de processo éanalisadaa comunicação entreo processoeo sistemacom focoem métricasquerelacionem oescalonamento, a criação efinalização do processo, mudançasde estado, as operações deI/O e a comunicação e asincronização entreos processos. No nível defunção, apreocupação seconcentranaanálise demétricasdefunçõesou procedimentos de um programaou processo. No nível deinstrução, o mais baixo analisável, o monitoramento se baseia dos eventos ocorridos no processador ou hardwarededicado durante o profiling. Nesse nível, tem-se acesso a informações detalhadasem relação àinstruções executadas como as debranch, call, load/storeeoutrasdaarquiteturaalvo (RAVAGNANI, 2007).
2.1.4.1 Monitoramento exato e estatístico
No monitoramento exato, o monitor deprofiling atuadeformapassiva, aguardando as primitivas de instrumentação e gerando métricas a partir de todos os eventos ocorridos. Tem como vantagem oferecer precisão nas medidas, mas tende acriar perturbação no comportamento do programaanalisado, poiscadaevento detectado geraum overhead eum número elevado deles tende agerar uma quantidade muito grande de dadosem um curto período de tempo, entretanto, o controle do predicado podeatenuar essasituação.
O monitoramento exato em softwareéutilizado geralmenteparareunir o rastreamento de eventosdeformaprecisa em aplicações com baixo tempo deexecução ou segmentospequenos deprogramas delongo tempo de execução analisadaspor meio deinstrumentação dinâmica.
Esse tipo de monitoramento, concebido originalmenteem abordagensde profilersem software, tem como foco acomputação de propósito geral. Todavia, a lógica desse monitor pode ser desenvolvidaem hardwareeliminando asdesvantagensdaimplementação em software. Nesse contexto, o hardware se baseia em um conjunto de contadores eregistradores que armazenam o espaço de endereçamento de segmentos deinteressedo programa do qual se deseja analisar o comportamento. Parao seu funcionamento, entretanto, precisaser configurado antesdaexecução do programa. Porém, torna-seideal parauso em sistemasembarcados, poiseliminaanecessidade por instrumentação e pode ter a precisão configurada baseando-se nanecessidade do projeto. Os trabalhos citados em projetosrelacionados fazem uso demonitoramento exato.
2.1. Profiling 39
2.1.4.2 Monitoramento com suporte por contadores de hardware
Integrados aos processadores modernos, as PerformanceMonitor Units(PMU) disponi-bilizam paraprofiling um conjunto decontadoresdehardwarecapazes demedir diversoseventos que ocorrem no processador durante a execução de um programa. A quantidade de eventos relacionadas as métricas deperformancesão extensas, como o número decachemiss, pipeline stalls, instruçõesde acesso àmemória, número deciclos deCPU duranteaexecução. Contudo, essaquantidadeévariável dependendo do fabricanteedo modelo do processador.
Os contadores dentro da PMU podem ser utilizados de dois modos: por contagem e por amostragem. A contagem produz dados durante toda a execução sem oferecer qualquer informação a respeito de funções ou instruções que geraram os eventos. Por outro lado, por amostragem, obtém-seuma correlação doseventos capturados em conjunto com amostras do Program Counter (PC). O sistema operacional pode configurar o processador para gerar uma interrupção quando a contagem de evento exceder um limite. Essa interrupção é tratada pelo kernel eosdadosdaamostragem, incluindo o valor do PC, sãoarmazenadosem umbuffer circular. Este buffer sofre amostragens periódicas por um profiler em espaço de usuário, escrevendo o conteúdo em disco. Após a execução, os endereços armazenados do PC são comparados aos dos obtidosnos arquivos binários, que são traduzidosparaos nomesdefunções eoutros símbolos.
A Tabela 1mostra a quantidade média de contadores existentes nas arquiteturas de processador mais populares. Estes são implementados em número limitado devido ao custo adicional associado ao tamanho no processador em termos de área que ocupam. Por esse motivo, o monitoramento demaiseventosqueo número decontadoresdisponíveisexige o uso de multiplexação. Esse processo efetua o rodízio do conjunto de eventos ativos em períodos, causando overhead jáque depende do sistemaoperacional. O custo de monitorar mais eventos queacapacidade do hardwarecausa, em média, 25% deoverhead, sendo tão custoso quanto o monitoramento em software. No entanto, acontagem, queseutiliza, geralmente, decontadores fixos tem um overhead deaté 2% (NOWAK; BITZES, 2014).
Tabela 1 – Recursos disponíveis nas PMUs
Fabricante Quantidadedecontadores Intel (Corei7) 4 programáveise 3 fixos AMD (Opteron) 4 programáveis e1 fixo ARM (Cortex A-9) 6 programáveis
Fonte: Dados dapesquisa.
Event-40 Capítulo 2. Fundamentação Teórica
Based Sampling (PEBS) disponível nos processadores da Intel (CORPORATION, 2010) ou Instruction-Based Sampling (IBS) nosdaAMD (DRONGOWSKI; CENTER, 2007). Apoiado por um hardwareadicional edisponibilizado apenasparaalgunseventos, o processador armazena em um buffer em memória o valor de PC e informações adicionais, sem utilizar interrupções. Contudo, não garante 100% de precisão, é limitado a alguns eventos e presente apenas nos processadores mais recentes. Esse comportamento causa problemas especialmente em loops, onde a recorrência pode mascarar uma quantidade grande de eventos. Outro problema que afetaaprecisão nacontagem deeventosestárelacionadaàvariação de frequênciadeoperação dos processadores baseados em políticas de economia de energia ou da carga de trabalho. Assim, as métricas relacionadas a ciclo de clock podem ser comprometidas já que dependem da informação da frequência de operação do processador para ser determinado o tempo de processamento(KLEEN, 2011).
Asinformaçõesdegrão fino (em níveisdeinstrução), tornam-sedifíceisdeserem obtidas sem o auxílio das PMUs nas plataformas dehardwaredecomputação depropósito geral. Além disso, análisesao nível defunção permitem menor intrusividade quando seutiliza contadores em hardware. Porém, por serem oferecidos em quantidade limitada, o monitoramento de muitos eventos simultâneos deve ser evitado dadaaperturbação que amultiplexagem causa, podendo comprometer asmedidasdedesempenho.
Nossistemas embarcados, ondeestão presentesinúmerasopçõesdesoft processors, a presençadePMUs élimitada. Alterae Xilinx, as principais fabricantes de hardwarereconfigurá-vel, fornecem, respectivamente, os processadoresNiosII eMicroBlaze. Apenasno NIOS II é presente nativamente um conjunto de contadores de desempenho, entretanto, não é fornecido suporteparauso em sistemasoperacionais e seu uso serestringe àinstrumentação de segmentos decódigo em aplicações standaloneapenas (AlteraCorporation, 2014).
2.1.5 Análise
A etapaseguintedo processo deprofiling éanalisar osdados dedesempenho extraindo deles informaçõesúteis sobreo comportamento do programa. Segundo Lessard (2005), a análise envolve:
∙ A remoção deinformaçõesdispensáveisereduzir osdadosrelevantesparaum subconjunto gerenciável eapropriado;
∙ Realizar a computação dedadosde performancebrutos para asinformações setornarem acessíveis;
∙ Sepossível relacionar ainformação obtidacom o código fontedo programa;
2.1. Profiling 41
A filtragem das informações pode ocorrer nesta etapa e assumem um caráter global baseado em todos os dados de desempenho disponíveis. Por essa razão, essa etapa pode ser opcional no monitoramento edada acomplexidadequepodeassumir, permiteser realizada de duasformas: post-mortem eon-the-fly.
2.1.5.1 Análise Post-Mortem
A análisePost-Mortemnão ofereceriscosdecausar perturbação naexecução doprograma porqueérealizadaao fim da execução. Contudo, o processamento de umagrande quantidadede dadospodeser custosaeo ajustedinâmico do profiling impossível deser feita.
2.1.5.2 Análise On-the- y
Neste tipo de análise, a filtragem é realizada no momento da execução do programa e possibilita evitar que uma grande quantidade de dados seja coletada. Além disso, permite ao profiler ou desenvolvedor, analisar se a configuração do profiling necessita ser ajustada, focando em pontoscom computação maisintensivaou, caso o softwaretenhasido instrumentado, desativar por meio depredicadoso monitoramento depontos irrelevantesdurante aexecução. Contudo, essaanálisepodeter umcusto computacional elevadoegerar umconsiderável overhead, tornando o ajustedo profiling impraticável.
As duas formas deanálisepodem ser executadas concorrentementedeformaapermitir ajustes no profiling em tempo de execução e ao fim, uma análise Post-Mortem dos dados do tempo deexecução.
2.1.6 Visualização
A etapade visualização compreendeo maisimportantepasso no processo deprofiling, pois guiao desenvolvedor (ou equipededesenvolvimento) àtomar decisõessobrecomo deve gerenciar os elementos de desempenho do sistema a fim de atingir um ou mais objetivos. Os dados dedesempenho devem ser claros, concisos ecapazes detransmitir os pontoschavesem esforço paracompreensão (JAIN, 2011). Essesdadosdevem ser produzidosdeformaaserem visualizadosem tabelas, gráficos egrafos. Umaadaptação deHarris (2011) ilustraavisualização deum profiling eas consideraçõesqueas informações podem gerar.
Considere um programa e uma arquitetura de hardware hipotéticas cujo profiling é realizado apartir daamostragem de eventos acada10 segundos. A frequênciado processador é de100 Mhz eo resultado éexibido naTabela2:
42 Capítulo 2. Fundamentação Teórica
Tabela 2 – Exemplo da visualização dedados gerados por profiling
Contador Percentagem Valor StallsdePipeline 10% 100.000
Cachemissdedados 2% 20.000
Cachemissdeinstrução 50% 500.000 Número total deciclos 100% 1.000.000
Fonte: Dados da pesquisa.
Figura5 – Resultado do profiling ao nível deinstruçõesde um softwarehipotético
Fonte: Harris (2011).
quea partir das constatações pode repensar aestruturado tamanho físico das memóriascacheou de suas políticas desubstituição dedados. Porém, a análise podepartir do softwaree chegar-sea conclusão danecessidadedeum profiling anível deinstrução que permitaanalisar seo uso das estruturasdedadosestão bem definidas parao uso apropriado da arquiteturadehardware, por exemplo. AFigura 5indica com mais objetividadeoseventos que causaram maior impacto no desempenho daarquiteturadeforma gráfica.
2.2 Trabalhos relacionados
2.2.1 SnoopP
2.2. Trabalhos relacionados 43
hardwareverifica entreos endereçosespecificadosem low ehigh se o valor está noslimitesde comparação. Se estiver, um contador de64 bits éincrementado.
Figura 6 – Arquitetura genérica da SnoopP
Fonte: Shannon eChow (2004).
Osautorescomparam o desempenho eprecisão do SnoopPcom aferramentaGNU Gprof utilizando o benchmark Dhrystone. Neleédefinido execuções de100 e 1 milhão deiterações e os resultadosobtidospelo SnoopPapontam 0.06% devariação ondeo Gprof não foi capaz de reproduzir qualquer informação naexecução de100 iterações. Isso ocorreporqueo benchmark é executado em menos de10 ms, valor abaixo do tempo de amostragem definido pelarotinade interrupção do Gprof.
Esseprofiler tem algumaslimitações, como adesó executar aanálisedecódigosquenão tenham subfunções. Além dela, não funcionaem ambientecom SistemaOperacional e necessita realizar asíntesedo hardwareparacada aplicação avaliada.
2.2.2 ACAD
44 Capítulo 2. Fundamentação Teórica
Figura7 – Arquiteturadaferramenta ACAD
Fonte: Ravagnani (2007).
2.2.3 M PPA
A MultiProcessor ProfilingArchitecture(MPPA) (CHEN et al., 2009) tem como objetivos monitorar eventosqueocorrem em processadores baseadosno soft coreLEON3. Esseprofiler é composto por duas partes: uma responsável pela detecção do evento e outra para contagem. O módulo de hardware realiza diversas alterações na arquitetura do sistema, introduzindo interfaces para capturas de eventos dentro do processador e interface com barramento AHB. Os eventos disponíveis não são relatados no artigo, entretanto, os resultados se baseiam em métricaassociadas a ciclosdeclock, cache miss dedados e instruções. A ferramenta tem suporte implementado no sistema operacional LINUX, mas não detalha de formaclaracomo a interação com o profiler érealizada. Osautores do trabalho alegam quea precisão daferramenta éde94%.
2.2. Trabalhos relacionados 45
Figura8 – Arquitetura da ferramenta MPPA
47
CAPÍTULO
3
M ATERIAIS E M ÉTODOS
Este capítulo descreveas ferramentasdedesenvolvimento em hardwareesoftware eos métodos para elaboração deste projeto. No contexto do hardware é apresentado a plataforma de desenvolvimento DE2i-150. Em relação ao software, a síntese e depuração do hardware tem auxílio das EDAs(Eletronic Design Automation) daAltera(ALTERA, 2015) edaCobham Gaisler (GAISLER, 2016).
3.1 Plataforma de Desenvolvimento
A plataforma de desenvolvimento Terasic DE2i-150 (TERASIC, 2014) foi utilizadapara aimplementação do projeto proposto. Estekit contemplaumasolução híbridacompostapor uma placacom processador Intel x86 (INTEL, 2014) eum chip detecnologiaField-Programmable Gate Array(FPGA) dafamília CycloneIV daAltera(ALTERA, 2015). A plataformaédefinida por umaplacadedesenvolvimento quecontemplaum processador Intel Atom Dual Corede1.6 Ghz, 2GB dememóriaDDR3 SDRAM, 60GB dememóriaSSD, conectividadeVGA, HDMI, USB, Wireless802.11b/g/n, Ethernet 1Gbps/seoutros dispositivosquea permiteser operaciona-lizadacomo um computador pessoal, o lado PC. Namesmaplacaháo circuito quecontempla a FPGA CycloneIV modelo EP4CGX150DF31C7N, quepossui 149.760 ElementosLógicos, 720 blocosde memóriaM9K, 6480 Kbitsdememóriaembarcadase 8 PLLs. Conectado aesta FPGA hámemóriasde128MB(32MBx32bit) SDRAM, 4MB(1Mx32) SSRAM e64MB(4Mx16) Flash com funcionamento em modo 16-bit. Além disso, conectividade por Ethernet 1Gbps, HSMC, VGA, RS-232 e40 pinos de I/O. O clock gerado pelo oscilador daplacaàFPGA éde 50MHz, mas permite conexão a um gerador de clock externo por meio de conector SMA. A figuraFigura10descreveumavisão geral daarquiteturadaplataformadedesenvolvimento.
48 Capítulo 3. Materiaise Métodos
Figura 9 – Placa dedesenvolvimento Terasic DE2i-150
Fonte: Terasic (2014).
em plataforma x86. Exemplos de como construir aplicações envolvendo as tecnologias são fornecidaspelaTerasic elimitam-se ao uso do softcore NIOSII daAltera((ALTERA, 2015)).
Figura10 – Arquitetura da Terasic DE2i-150
3.2. GRLIB 49
3.2 GRLIB
O projeto LEON nasceu da necessidade da construção de um processador para uso em ambientes críticos sob supervisão da European Spacial Agency. A baixa escalabilidade inicial desse projeto levou ao surgimento da bibliotecaGRLIB, quefornece todaa infraestrutura necessária, organização e suporte a ferramentas para o desenvolvimento de System-On-Chip (SOC). A GRLIB integra um conjunto decoresIPepodeser utilizadapor diferentesferramentas Computer-Aided Design (CAD) edispositivosFPGA dediferentes fabricantes, concentrando um conjunto derecursosqueatuam nageração automáticadesínteseescripts desimulação.
Todos os componentes ou coreIPda bibliotecasão desenvolvidosem VHDL eum único método plug&play é utilizado para configurar e conectar os componentes sem a necessidade de modificar qualquer recurso global. Este método se baseia na instância do componente no arquivo do top-level do projeto. Por padrão, os projetos de sistemas ficam armazenados em diretórios com o nome da plataforma de desenvolvimento antecedido da palavra "leon3-"em design, conforme aárvoredediretórios descrita aseguir.
/
bi n
designs
. . .
t er asi c- de2i - epc4cxgx150 . . .
designs
. . .
leon3-altera-de2i-150 leon3mp.vhd. . 3 . . . doc
l i b sof t war e
Recursos para integração deplataformasde desenvolvimento compatíveis estão disponí-veisno diretório boardse caso umaplataformaestejaindisponível, a Cobham-Gaisler fornece templates paraatentativadeintegração àGRLIB.
50 Capítulo 3. Materiaise Métodos
3.3 GRM ON
O GRMON é um monitor para depuração parao processador LEON3 e projetos SOC baseados nabibliotecaGRLIB. Tem como principaisrecursos:
∙ Acesso deleitura/escritaem todos registradores do sistemaememórias;
∙ Incorporaum disassembler eo gerenciamento detrace buffer;
∙ Download eexecução deaplicações;
∙ Gerenciamento dewatchpoint ebreakpoint;
∙ Suporteaconexão remotaao GNU debugger (GDB) paradepuração em nível decódigo fonte;
∙ Suporteàcomunicação por USB, seral, JTAG, Ethernet, PCI, USB, Spacewire;
∙ Prover um único modelo para síntese esimulação.
O GRMON é imprescindível para uso do LEON3, mas deveser desacoplado quando se realizamedições ou sedesejaextrair o máximo deperformance do sistemaem FPGA. Todavia, em algumas situações podenão ser possivel a desacoplagem desse monitor, como a execução de aplicaçõesstandalonesalva em memóriavolátil.
3.4 Processador LEON3
3.5. L3STAT 51
Figura11 – Diagrama interno do processador LEON3
Fonte: Gaisler (2016).
A amplaflexibilidadedeconfigurações do LEON3 permite em sua configuração mínima contar apenas com um pipeline deinteiros, umacache deinstrução e dados. Em versões mais elaboradas pode conter unidade de gerenciamento da memória (MMU), de multiplicação e divisão de32 bits, de soma-multiplicação de16 bits, einterfacededebug etracebuffers. Tem suporteainterfacesdeextensão quepodem ser utilizadas para unidadede ponto flutuantee um co-processador. Podeser implementação com até 16 processadores, tendo desempenho máximo na versão em FPGA de 125 Mhz eem ASIC, 400 Mhz. Nesteprojeto, afrequência de operação do processador éde50 Mhz.
Em sistemas baseados em processadores sobre FPGA, os mais utilizados são os pro-duzidospelas empresaAlteraeXilinx sendo, respectivamente denomes, NIOSII eMicroBla-ze/PicoBlaze. As duas empresas são maiores fabricantes de chips com tecnologia FPGA do mundo eoferecem ferramentascompatíveispara uso dessesprocessadores, entretanto, ambos são produtoscomerciaisedecódigo fechado. Sendo assim, aflexibilidadedeuso dequalquer um deles ébastantelimitadaeimpediriaaexecução destetrabalho.
3.5 L3STAT
52 Capítulo 3. Materiaise Métodos
geral etem como característicasuporteaaté32 contadoresde32-bits. Taiscontadorespodem ser utilizadoscom até16 cores emonitorar até32 eventos simultaneamente. Os contadorespodem retornar a 0 quando alcançam o seu limite e/ou serem zerados após a leitura, contribuindo para a construção deestatísticaspor longos períodos.
A L3STAT fornece umainterfacebem definidacom o(s) processador(es) ebarramento com um baixo footprint, não impactando significativamenteno número elementos lógicosutili-zadosem FPGA. Essecomponenteem hardwarepodeser configurado baseado nas necessidades de desenvolvimento do projeto, permitindo a configuração da quantidade de contadores e do suporteao monitoramento do barramento, implicando no número deelementoslógicosocupados. Também define parâmetrosdeconfiguração eeventos epermiteo desenvolvimento deeventos personalizados. Em virtude dessas características, decidiu-se a adoção deste componente em detrimento do desenvolvimento deum próprio.
3.6 Ferramentas EDA
O termo Eletronic Design Automation (EDA) compreende uma categoria deferramentas quetrabalham em conjunto em um fluxo de desenvolvimento cujo objetivo éprojetar circuitos eletrônicos, atuando desde esta etapa àconcepção e, posteriormente, produção. Este projeto foi realizado com o suporte de ferramentas de configuração do LEON3 fornecidas pela Cobram Gaisler e a síntesepor responsabilidadedo softwareQuartusPrime15.1 da Altera. A simulação do código VHDL do LEON3 foi feita com a ferramenta ModelSim Stater Edition 10.4b da Mentor Graphics.
3.7 Sistema Operacional Linux
A Cobham-Gaisler forneceem suapáginaumaversão daferramentaBuildroot (BUIL-DROOT, 2016) com o kernel Linux na versão 3.10 com scripts adaptados parauso com LEON3. A Buildroot éuma ferramentaqueauxilianaescolhadebibliotecas, aplicativos eopçõesavan-çadasdeconfiguração parageração do kernel etodo ambiente parauso do Linux. É também a responsável por gerar aimagem contendo o kernel eo bootloader. Além deles, Cobham-Gaisler fornecea toolchain paracompilação cruzada, queé essencial para uso daBuildroot. Por padrão, o Buildroot defineo escalonador Completely Fair Schedule(CFS) parao Linux.
3.8 Fomato ELF
3.9. Métodos de validação 53
de símbolos, links a bibliotecase etc. O ELF foi desenvolvido no UNIX System Laboratories (USL) como partedaApplication Binary Interface (ABI) do System V etornou-seum padrão aceito por diversas arquiteturas dehardware esistemasoperacionais (COMMITTEE, 2001).
Figura12 – Formato ELF
Fonte: Committee(2001).
Os binários gerados neste formato podem sofrer disassemble, permitindo a análise da alocação de memóriavirtual do segmento de instruções paraanálises envolvendo tracing, debug ou profiling.
3.9 M étodos de validação
O método mais comum para o desenvolvimento de modelos sintetizáveis em VHDL é o conhecido por adhoc ou dataflow style. Neste método um número grande de declarações concorrentes em VHDL eprocessospequenos conectadosatravés de sinais são utilizadospara implementar umafuncionalidadedesejada. Não hádistinção entresinaiscombinacionaisese-quenciais. Ler e compreender códigos concebidos desta forma édifícil e são comparados aos diagramasesquemáticos desenvolvidos para projetos decircuitos eletrônicos. Dadaa complexi-dade do projeto deum processador e faltadeescalabilicomplexi-dade do adhoc, a Cobram-Gaisler propôs um novo método para o desenvolvimento do código do LEON, chamado de"dois processos"ou two-process. O objetivo foi suplantar as limitações do método adhoc, sendo aplicados à projetos de sistemascom um único clock de sincronismo, cujarepresentação éa da maioria dosprojetos desenvolvidos (GAISLER, 2000). Osobjetivos datécnicade"dois processos"são:
∙ Prover codificação uniformeao algoritmo; ∙ Aumentar o nível deabstração;
54 Capítulo 3. Materiaise Métodos
∙ Identificar claramentealógicasequencial;
∙ Simplificar adepuração;
∙ Melhorar avelocidadedesimulação;
∙ Prover um único modelo para síntese esimulação.
Alcançar osobjetivosdestatécnicaem VHDL implicaem:
∙ Utilizar tiposrecord em declaração de sinaise portas;
∙ Somenteutilizar dois processospor entidade;
∙ Utilizar declaraçõessequenciaisem alto nível paracodificar o algoritmo.
Em resumo, o modelo arquitetural em VHDL do LEON3 éprojetado para ter boa legibi-lidade. Geralmente, um módulo contem apenas doisprocessos: um combinacional descrevendo todaafuncionalidade eum processo implementando registros, sendo esteum processo orientado à clock. Estruturas do tipo record são utilizadas em demasia para agrupar sinais de acordo com sua funcionalidadee acomunicação entremódulos/processos são realizadaspor meio dos records(CENTRE; TECHNOLOGY, 2000). Contudo, acomplexidadedo código fontesedápor suaextensão. A compreensão defuncionamento dosmódulosnão éimediatae exige ter dema-siado conhecimento de todo o processador. Assim, há uma enorme dificuldade em mapear as consequênciasdemodificação do código do LEON3 ou blocosacopladosaele. Sendo necessária a realização deexaustivos testes afim desedetectar falhas naexecução do processador.
Paraavalidação desteprojeto foram realizadas:
∙ Simulação comportamental do processador por meio daferramentaModelSim;
∙ Depuração do código assembly com funções buscando correspondênciaentreetapas exe-cutadas no processador eeventos computados pelo módulo deestatísticae P2L utilizando GNU Debugger (GDB) eGRMON;
∙ Exaustivos testes de funções de assertividade para garantir que o funcionamento com corretudedo módulo dehardware;
3.9. Métodos de validação 55
tem com objetivo descobrir se a execução desse teste transcorreria bem após asmodificações no LEON3, permitindo assim analisar o comportamento do hardware durante a execução do código fonte por meio da observação dosregistradores PC enPC da CPU, contadores deeventos registrados pelo módulo de estatísticas, como também, dos registradores do P2L que fazem a leitura dos dadosobtidos do processador e do L3STAT. A simulação comportamental, por ser lenta, não permite avaliar aplicações em um sistemaoperacional, masvalidao funcionamento de todo o sistemae do sincronismo dosblocosdehardware.
No ambiente real, os testes envolvendo o hardware sintetizado em FPGA se deram por meio da depuração do código fonte em assembly utilizando o depurador GNU GDB. A cada passo de execução do código, ou seja, a cada incremento do registrador PC, analisou-se o tipo de instrução e o evento que geraria. Assim, através do monitoramento oferecido pelo GRMON, obteve-seo statusdo hardware eregistradores, permitindo detalhar o comportamento pormenorizado do hardwareduranteaexecução dos testes.
Código-fonte1: Testedeassertividade paraModelsim - Código em C
1 #include <stdio.h> 2
3 void __attribute__ ((noinline)) fatorial(int n) { 4 volatile int i = 0;
5 double f = 1; 6
7 for (i; i < n; i++) { 8 f = f*(n-i);
9 }
10 printf("\nFatorial de %d : %lf\n", n, f); 11 }
12
13 void __attribute__ ((noinline)) a() { 14 fatorial(4);
15 }; 16
17 void __attribute__ ((noinline)) b() { 18 fatorial(9);
19 }; 20
21 void profile(); 22
23 int main(){ 24 profile(); 25 a();
26 b(); 27
56 Capítulo 3. Materiaise Métodos
30
31 void profile(){
32 //#Habilita escrita no modulo P2L
33 LEON3_BYPASS_STORE_PA(ADDR_P2L + 0x8, 0x1); 34
35 //# Descreve intervalo da função a() - dentro do executavel (ELF) 36 LEON3_BYPASS_STORE_PA(0x8000050c , 0x1);
37 LEON3_BYPASS_STORE_PA(0x80000518 , 0x400019d0); 38 LEON3_BYPASS_STORE_PA(0x8000051c , 0x400019e8); 39
40 ...
41 //#Enable P2L
42 LEON3_BYPASS_STORE_PA(ADDR_P2L , 0x1); 43 }
Código-fonte2: Teste de assertividadepara Modelsim - Código em Assembly
1 ..
2 400019d0 <a>:
3 400019d0: 9d e3 bf a0 save %sp, -96, %sp 4 400019d4: 90 10 20 04 mov 4, %o0
5 400019d8: 7f ff ff d3 call 40001924 <fatorial> 6 400019dc: 01 00 00 00 nop
7 400019e0: 81 e8 00 00 restore 8 400019e4: 81 c3 e0 08 retl 9 400019e8: 01 00 00 00 nop 10 ...
Quadro 3 – Resultado do teste de assertividade
Função Arg Retorno # Instruções # Chamadas Tempo deexecução
a() 4 24 7 1 1c
b() 9 362880 7 1 1c
57
CAPÍTULO
4
IM PLEM ENTAÇÃO DA ARQUITETURA
PROPOSTA
Este capítulo apresenta todas as etapas da implementação da ferramenta de profiling, cujo core é baseado em hardware reconfigurável e o software, em um driver para o Sistema Operacional Linux eaplicativos paraconfiguração eanálisededados gerados.
4.1 Fluxo de desenvolvimento do Hardware
O desenvolvimento de um novo sistema dentro do ambiente da Altera geralmente se inicia com a criação de um projeto dentro da ferramenta Quartus, que oferece uma interface amigável erecursos para adicionar e criar componentes, configurá-los einterconectá-loscom objetivo da síntese de hardware. Contudo, o fluxo de desenvolvimento de um novo projeto que envolva o LEON3 ocorre de maneira distinta. O primeiro passo é conhecer a estrutura da bibliotecaGRLIB eentender asuaorganização. Todo esseprocesso não envolve umaferramenta visual, mas sim um conjunto descriptseexplorar aestruturadediretórios earquivosdosquais compõeessabiblioteca. Dentro do diretório $local1/grlib/lib encontra-seaestrutura:
/
cont r i b cypr ess esa et h f mf gai sl er gsi
libs.txt
58 Capítulo 4. Implementação da Arquitetura Proposta
mi cr on opencor es spansi on spw synpl i f y t ech t echmap wor k
$> cat $l ocal / gr l i b/ l i b/ l i bs. t xt
synpl i f y t echmap spw et h opencor es gai sl er esa f mf spansi on gsi
Essa estrutura é rígida e padroniza um conjunto de regras em scripts que atuam na compilação e simulação de projetos. Por essa razão, quando um novo componentedehardware for criado, este deve respeitar alguns critérios para ser reconhecido dentro das bibliotecas de coresIP, queestão listados em l i b/ l i bs. t xt . Em cadadiretório descrito nessearquivo háum outro, o di r s. t xt , quecontém oscaminhosdesub-diretóriosondesão armazenadososarquivos em VHDL queimplementam os componentes. Além deles, em cadasub-diretório devem existir os arquivosvhdl syn. t xt evhdl si m. t xt que, respectivamente, contém os nomesdos arquivos quedevem ser compiladosparasíntesee/ou simulação e, o último, aordem no qual os arquivos devem ser compilados.
Para o desenvolvimento de um novo componente, portanto, o desenvolvedor deve configurá-lo na GRLIB seguindo as regras descritas acima. O passo seguinte é configurar o processador LEON3 dentro do diretório top-level do projeto queestáassociado a plataforma de desenvolvimento. Esseprocesso podeser realizado deduasformas: por meio de um ambiente gráfico ou editando os arquivos de configuração manualmente.
Figura13 – Configuração do LEON3: principal
Fonte: Elaboradapelo autor.
4.1. Fluxo de desenvolvimento do Hardware 59
Figura 14 – Configuração do LEON3: barramento, memórias e periféricos
Fonte: Elaborada pelo autor.
Código-fonte3: Exemplo: instânciadeum componenteem leon3mp.vhd
341 -- ...
342 -- MEMORY ONCHIP: DUAL PORT RAM - Size 512 Kb 343 ahbdpdram0: ahbdpram
344 generic map (hindex => 7, haddr => CFG_AHBRADDR ,tech => CFG_MEMTECH , abits => 17)
345 port map ( rstn, clkm, ahbsi, ahbso(7), clkm, p2l_dp_addr , p2l_dp_in , p2l_dp_out , p2l_dp_enable , p2l_dp_write);
346 --347 -- ...
A organização deparâmetrosdeconfiguração do componentecom o uso deconstantes, como a CFG_AHBRADDR e CFG_MEMTECH do exemplo anterior, podem ser feitas no arquivo conf i g. vhd queselocalizano diretório top-level do projeto.
A configuração do processador pela ferramenta gráfica deve ser feita sempre antes de se instanciar um componente em virtude dessa ferramenta reescrever os arquivos principais do projeto, l eon3mp. vhd e conf i g. vhd, desconsiderando modificações anteriores. Depoisdas configuraçõesdo processador ecomponenteestiverem prontas, asíntesedo hardwarepodeser iniciada. Esse processo é dependente das ferramentas fornecidas pelos fabricantes de FPGA, entretanto, aGRLIB simplificao acesso àelasfornecendo suporte para acioná-laspor linhade comando deformasimplificada.
60 Capítulo 4. Implementação da Arquitetura Proposta
Figura 15 – Fluxo de desenvolvimento com ferramentasGRLIB e Altera
Fonte: Elaboradapelo autor.
da GRLIB se baseiam no ambiente definido por esse fabricante. Dessa forma, executar o comando make quar t us no diretório top-level inicia o processo de compilação do projeto até a etapa de geração do arquivo bitstream (ver figura15). O último passo é programar a FPGA, passo que pode também ser realizado por scripts da GRLIB, executando o comando make quar t us- pr og- f pga.
Na seção aseguir será apresentado detalhes da implementação do core P2L descrevendo asmodificações necessárias paraextrair informações daunidade deinteirosdo processador e de estatísticaesuainterligação com o barramento APB.
4.2 Implementação do core P2L
4.2. Implementação do core P2L 61
Figura16 – Arquitetura simplificada do LEON3 com módulo P2L
Fonte: Elaborada pelo autor.
A figura16ilustrao coreP2L integrado ao LEON3 ea suadependênciade componentes do sistema. Esseprocesso éanalisado nassubseções seguintes.
4.2.1 Unidade de Inteiros
O LEON3 possui umaunidadedeinteiros(UI) queimplementaintegralmenteo conjunto de instruções estabelecido pelo SPARC V8, incluindo as de multiplicação e divisão. Nessa unidade, as interfaces de dados e instruções da cache são implementadas de forma disjunta (arquitetura Harvard). Além disso, é constituída por um pipeline de 7 estágios, ilustrado na
Figura17, querealiza asseguintes operações:
1. Fetch (FE): busca a instrução dentro da cache de instruções, mas a prossegue pelo bar-ramento AHB caso não seja encontrada ou esta cache não tenha sido implementada na arquitetura. A instrução éválidano fim desteestágio eéarmazenadadentro daUI;
2. Decode(DE): ainstrução édecodificada eos endereçosdeCall eBranch são gerados;
3. Execute (EX): operações na unidade lógica aritmética (ULA) e de deslocamento são realizadas nesteestágio;
62 Capítulo 4. Implementação da Arquitetura Proposta
Figura 17 – Estágios de Pipeline do LEON3
Fonte: Cobham-Gaisler (2016).
5. Memory (ME): estágio ondea cachededados élidaou escrita;
6. Exception (XC): interrupçõesdo fluxo normal de controle (traps) e outrasinterrupções são tratadas;
7. Write(WR): o resultado gerado pelaULA ededeslocamento ou operaçõessobrecache são escritas devoltano arquivo deregistro.
4.2. Implementação do core P2L 63
Figura18 – Análise do Pipeline- Modelsim
Fonte: Elaborada pelo autor.
ser conectado aum pino de entradado P2L. Esse processo, por mais simples quepossa parecer, envolveinúmeras camadas eestão relacionados aos arquivosilustrados naFigura 19.
Figura19 – Arquivos editados para interfacede sinal daUnidade de Inteiros
Fonte: Elaborada pelo autor.
Em $l ocal / l i b/ gai sl er / l eon3v3 seencontrao arquivo queimplementaaunidade de inteiros do LEON3, o i u3. vhd. OCódigo-fonte4mostra as modificaçõesnecessáriaspara capturado dados gerados pelo PC.
Código-fonte4: Modificações naUnidadedeInteiros
1 entity iu3 is 2 generic (..); 3 port (
64 Capítulo 4. Implementação da Arquitetura Proposta
5 +(100) pc_ex : out std_logic_vector(31 downto 2) 6 );
8 ...
9 architecture rtl of iu3 is
10 +(109) -- P2L: adicionando um sinal de saída
11 +(109) signal p2l_pc_excep : std_logic_vector(31 downto 2) := zero32 (31 downto 2);
12 ...
14 comb : process(ico, dco, rfo, r, wpr, ir, dsur, rstn, holdn, irqi, dbgi, fpo, cpo, tbo, tbo_2p, mulo, divo, dummy, rp, BPRED, BLOCKBPMISS)
15 +(2904) -- P2L: atribuindo PC em exception
16 +(2905) l2p_pc_excep <= r.x.ctrl.pc(31 downto 2); 17 ...
18 reg : process (clk) 19 begin
20 if rising_edge(clk) then
21 +(3525) -- P2L: repassando sinal com atraso em 1 ciclo de clock 22 +(3526) pc_out_x <= l2p_pc_excep;
23 ...
Asmodificaçõesnosoutrosarquivosseresumem arepassagem do sinal do pino pc_out_x atéo arquivo top-level do projeto. Em virtudedaanálisedeeventosser feitaem conjunto com a unidade deestatísticas, manter o sincronismo exigiu queo sinal de PC fosse lido com um atraso deum ciclo declock.
4.2.2 Unidade de estatísticas
A unidade de estatísticas L3STAT é um componente responsável por capturar eventos relacionadosao processador, barramento AHB e pode ser estendida com eventos personalizados pelo desenvolvedor daarquitetura. É composta por 64 registradoresde32 bits, sendo quemetade deles são responsáveispelaconfiguração eo restantepelaarmazenagem dos eventos. O quadro
4demonstrapartedoseventosdisponíveis, sendo queadescrição completapodeser obtida no manual GRRIPCobham-Gaisler (2015).
O quadro5listade queformaesse componente é mapeado no espaço deendereçamento do barramento AHB/APB parauso em um projeto com LEON3. Essemapeamento possibilita a configuração dos eventos nos registradores de controlea partir do endereço base somado a0x80. A configuração segue um padrão definido delimitado por intervalos de bitsconformeaFigura20
e cujainterpretação é dada no quadro6.
4.2. Implementação do core P2L 65
Quadro 4 – Unidade de estatíticas - Eventos disponíveis
ID Descrição do evento Eventosrelacionados ao processador: 0x00 Instruction cache miss 0x01 Instruction MMU TLB miss 0x02 Instruction cache hold 0x03 Instruction MMU hold 0x08 Datacache(read) miss 0x09 DataMMU TLB miss 0x0A Datacachehold 0x0B DataMMU hold 0x10 Datawritebuffer hold 0x11 Total instruction count 0x12 Integer instructions
0x13 Floating-point unit instruction count 0x14 Branch prediction miss
0x15 Execution time, excluding debug mode
0x17 AHB utilization (per AHB master) (implementation dependent)
0x18 AHB utilization (total, master/CPU selection is ignored) (implementation de-pendent)
0x22 Integer branches 0x28 CALL instructions
0x30 Regular type 2 instructions 0x38 LOAD and STORE instructions 0x39 LOAD instructions
0x3A STORE instructions
Eventosrelacionados ao barramento AHB: 0x40 AHB IDLE cycles
0x41 AHB BUSY cycles
0x42 AHB NON-SEQUENTIAL transfers. Filtered on CPU/AHBM if SU(1) = ‘1’ 0x43 AHB SEQUENTIAL transfers. Filtered on CPU/AHBM if SU(1) = ‘1’ 0x44 AHB read accesses. Filtered on CPU/AHBM if SU(1) = ‘1’
0x45 AHB writeaccesses. Filtered on CPU/AHBM if SU(1) = ‘1’ 0x51-0x5F Reserved
e configurações definidas na instância do componente L3STAT no top-level do projeto. Para detecção de eventosdo barramento é necessário que a unidade desuporte adepuração (DSU) sejaacrescentada ao projeto.