NAME AMBIGUITY PROBLEM IN
CONTRIBUTIONS FOR SOLVING THE AUTHOR
NAME AMBIGUITY PROBLEM IN
BIBLIOGRAPHIC CITATIONS
Tese apresentada ao Programa de
Pós--Graduação em Computer Siene do
In-stitutode CiêniasExatas daUniversidade
Federal de Minas Gerais Departamento
de Ciênia da Computação omo requisito
parial para a obtenção dograu de Doutor
emComputer Siene.
Orientador: Maros André Gonçalves
Co-orientador: Alberto Henrique Frade Laender
CONTRIBUTIONS FOR SOLVING THE AUTHOR
NAME AMBIGUITY PROBLEM IN
BIBLIOGRAPHIC CITATIONS
Thesis presented to the Graduate Program
in Computer Siene of the Universidade
Federal de Minas Gerais Departamento
de CiêniadaComputaçãoinpartial
fulll-ment of the requirements for the degree of
Dotor inComputer Siene.
Advisor: Maros André Gonçalves
Co-advisor: Alberto Henrique Frade Laender
2012, Anderson Almeida Ferreira.
Todos os direitosreservados.
Ferreira, AndersonAlmeida
F383 Contributions for Solving the Author Name
Ambiguity Problemin BibliographiCitations/
Anderson AlmeidaFerreira. Belo Horizonte, 2012
xx, 114 f. : il.; 29m
Tese (doutorado) Universidade Federal de Minas
Gerais Departamento de Ciênia daComputação
Orientador: Maros André Gonçalves
Co-orientador: Alberto Henrique Frade Laender
1. Computação Teses. 2. Sistemasde reuperação
dainformação Teses. Biblioteasdigitais Teses.
3. Registrosde autoridadede nomes (Reuperaçãoda
informação). I.Orientador.II.Coorientador.III.Titulo.
I thank my advisor, professor Maros André Gonçalves, and my oadvisor, professor
Alberto H. F. Laender, for supporting todeveloped this thesis.
I thank my oauthors that ontributed signiantly to the development of the
artiles used as base to this thesis, speially, Maros, Alberto, Adriano, Jussara, Ana
Paula and Rodrigo.
Ithank my friendsatLBD,the UFMGdatabase group,forthe nieenvironment
to work inthis laboratory.
I alsothank the administrativestas of PPGCC that always solve all questions
with respet my PhD, suh as travels, doumentation and soon.
Finally,Iamgratefultomyparents,GuimarãesandGeralda,whoalways
enour-aged me, to my wife, Lília, for your understanding and saries during my studies,
and tomy sons, Luas and André.
ThisresearhispartiallyfundedbytheInWeb-TheNationalInstituteofSiene
and Tehnology for the Web (MCT/CNPq/FAPEMIG grant number 573871/2008-6),
InfoWeb (MCT/CNPq grant 55.0874/2007-0) and by CNPq and FAPEMIG
Author name ambiguity is a problemthat ours when a set of bibliographi itation
reords ontains ambiguous author names, i.e., the same author may appear under
distint names,ordistintauthorsmay have similarnames. This is oneof the hardest
problems faed by urrent sholarly digital libraries (DLs), suh as DBLP, CiteSeer,
MEDLINE and BDBComp. In this thesis, we present a set of ontributions to help
solving the author name ambiguity problem. First of all, we present a taxonomy
to lassify the author name disambiguation methods that helps to better understand
how the methods work and onsequently understand their limitations. Seond, we
presentSANDanewhybriddisambiguationmethodthatexploitsthestrengthsofboth
supervised author assignment and unsupervised author grouping methods. SAND is
a three-step disambiguationmethod. In its rst step (i.e., the author groupingstep),
a set of itation reords is lustered so that reords that are likely to be assoiated
with the same author are grouped together in lusters. In its seond step (i.e., the
luster seletion step), some of these lusters are seleted to be used as trainingdata.
Finally, in its third step (i.e., the author assignment step), these seleted lusters are
used as training data and are given as input to a assoiative name disambiguator
with the ability to detet the appearane of new authors that were not inluded in
the training data. As our nal ontribution, we present SyGAR, a new generator of
synthetiitationreordsthat helpstoevaluateauthorname disambiguationmethods
under several senarios. SyGAR generates syntheti itation reords following the
publiation proles of existing authors, extrated froman input olletion. Moreover,
SyGAR allows the simulation of several real-world senarios suh as the introdution
of new authors (not present in the input olletion), dynami hanges in an author's
publiation prole as well as the introdutionof typographial errors in the syntheti
1.1 Synonyms: a unique authorwith several name variations.. . . 2
1.2 Homonyms: several authorswith a same namevariation. . . 3
2.1 Anillustrativeexample. Eahgeometri gure represents areferene toan
author. The same gures refer tothe same author. . . 14
2.2 Authorshipdistributionwithineahambiguousgroup. Authors(x-axis)are
sorted indereasing order of proliness (i.e., more proli authors appear
inthe rst positions).. . . 17
3.1 A taxonomy for author name disambiguationmethods. . . 20
4.1 Illustrativeexample. The authorgrouping and lusterseletion steps. . . . 45
4.2 Comparison between the osine similarity funtion, (a) and (), and
eu-lidean distane, (b) and (d), for seleting the training data in DBLP and
BDBComp. . . 58
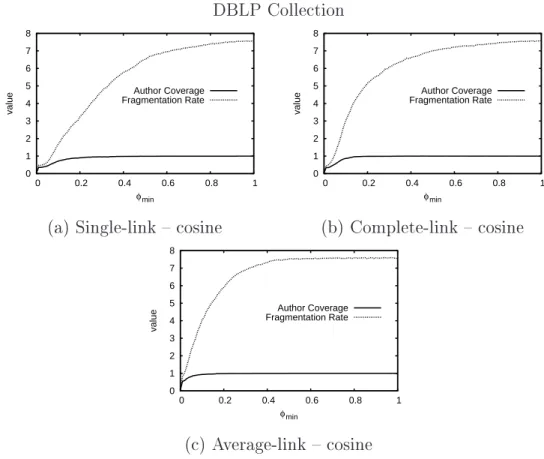
4.3 Comparison between the author overage and the fragmentation rate in
DBLP using some strategies for seleting the training data. The seletion
of the training data uses (a) single-link, (b) omplete-link and ()
average-link lustersimilaritieswith osine similarity funtion onthe vetors. . . . 59
4.4 Comparison between the author overage and the fragmentation rate in
BDBComp using some strategies for seleting the training data. The
se-letion of the training data uses (a) single-link, (b) omplete-link and ()
average-linklustersimilaritieswithosine similarity funtiononthe vetors. 60
4.5 Strategy 3performed inthe (a)DBLP and (b) BDBComp olletions. . . 61
4.6 Sensitivity analysis for
φ
min
. . . 634.7 Sensitivityanalysisfor
φ
min
. TheomparisonofSAND'sperformaneusing thenameoftheauthorsasprovidedintheolletionswiththeauthornamesin short format (i.e., the author names are represented by only the initial
proles. . . 72
4.9 Senario 2: EvolvingDL and additionof new authors (
%
InheritedT opics
=80%). 724.10 Senario 3: Dynamiauthor proles (
δ
=
5 and%
P rof ileChanges
=10%,50% and 100%). . . 735.1 SyGARmain omponents SyGARreeives asinput adisambiguated
ol-letion of itation reords and builds publiation proles for all authors in
the input olletion. Then, the publiation proles are used to generate
syntheti reords. As a nal step, SyGAR may introdue typographial
errors inthe outputolletionand hange the itation attributes. . . 79
5.2 A plate representation of the LDA [Blei et al., 2003℄ The LDA model
assumesthat eahitation reord
r
follows the generativeproess.r
draws the number oftermsN
d
inthe worktitleaording toagiven distribution, draws a topi distributionθ
aording to a Dirihlet distribution model with parameterα
T opic
and, for eah term, hooses a topiz
following the multinomial distributionθ
and a termw
from a multinomial probability onditioned on the seleted topiz
, given by distributionφ
, whih in turn is drawn aording toa Dirihlet distribution with parameterα
T erm
.. . . . 825.3 Changing author
a
's prole by alteringher topi distribution. (a) the orig-inaltopi distribution of authora
. (b) The topis assoiated witha
sorted aordingtotheirprobabilities(P
a
T opic
)soastohaveahistogramaslosetoabellshapeas possible. () The topi distribution shifted along the x-axis
by a fator
δ
= 5
;2
shifts are shown in the gure. . . 885.4 Sensitivity of SyGAR to
α
T opic
,α
T erm
,β
T opic
andN
T opics
Relative error between performane of eah method onsyntheti and real olletions. (a)and () show the results of SVM and HHC, respetively, when applied to
synthetiallygenerated olletionsusingvariousvalues of
α
T opic
,α
T erm
andN
T opics
, keepingβ
T opic
= 0
.
07
. (b) and (d) show the results of SVM andHHC,respetively,whenappliedtosynthetiallygeneratedolletionsusing
various of
β
T opic
andN
T opic
,keepingα
T opic
=α
T erm
=10−
5
. . . 92
5.5 SyGAR validation. We use
α
T opic
=α
T erm
=10−
5
and
β
T opic
=0.7. . . 945.6 Senario 1 Evolving DL with stati author population and publiation
proles. . . 98
5.7 Senario 2EvolvingDLand additionofnewauthors(
%
InheritedT opics
=80%). 992.1 Illustrativeexample (ambiguousgroup of A. Gupta). . . 9
2.2 Performane of the evaluationmetris. . . 14
2.3 The DBLPand BDBComp olletions . . . 16
3.1 Summaryof harateristis- Author groupingmethods . . . 39
3.2 Summaryof harateristis- Author assignment methods. . . 40
4.1 Results (with their standard deviations) obtained by the author grouping step foreah ambiguousgroup inthe (a) DBLP and (b) BDBComp olle-tions, withoutusing the popularlastnames. . . 56
4.2 Results (with their standard deviations) obtained by the author grouping step foreah ambiguousgroup inthe (a) DBLP and (b) BDBComp olle-tions, using the popular lastnames. . . 57
4.3 Results obtained by SAND-1. . . 64
4.4 Results obtained by SAND-2. . . 65
4.5 ResultsobtainedbySAND,HHC,KWAYandLASVM-DBSCAN methods. Best results are highlighted inbold. . . 66
4.6 Results (with their standard deviations) of SAND, SLAND, SVM and NB inthe DBLP and BDBComp olletions. Best results, inludingstatistial ties, are highlightedin bold. . . 67
4.7 Resultsobtainedbythe authorgroupingandlusterseletionstepsoupled withSVMs(S-SVM)and NaïveBayes(S-NB)tehniquesintheseondstep (i.e., the author assignment step). Best resultsare highlighted inbold. . . 69
5.1 SyGAR inputparameters. . . 79
and 5 synthetially generated olletions(
N
T opics
= 600
). . . 915.4 Distributionofaveragenumberofpubliationsperyear perauthor(DBLP:
Aknowledgments xi
Abstrat xiii
List of Figures xv
List of Tables xvii
1 Introdution 1
1.1 Motivation . . . 3
1.2 Contributions . . . 6
1.3 Thesis Outline. . . 7
2 The Author Name Disambiguation Task - Foundations 9 2.1 Denitions . . . 10
2.2 Task Charaterization . . . 10
2.3 Evaluation Metris . . . 11
2.4 Colletions . . . 14
3 Automati Author Name Disambiguation Methods 19 3.1 A Taxonomy for Author Name DisambiguationMethods . . . 19
3.1.1 Type of Approah. . . 21
3.1.2 Explored Evidene . . . 26
3.2 Overview of Representative Methods . . . 27
3.2.1 Author Grouping Methods . . . 28
3.2.2 Author Assignment Methods. . . 33
3.2.3 Using AdditionalEvidene . . . 35
3.3 Summary of Charateristis . . . 38
4.1.1 The Author GroupingStep . . . 44
4.1.2 The ClusterSeletion Step . . . 47
4.1.3 The Author AssignmentStep . . . 51
4.2 ExperimentalEvaluation . . . 55
4.2.1 ExperimentalSetup . . . 55
4.2.2 Evaluatingthe Author GroupingStep. . . 56
4.2.3 Evaluatingthe Clustering Seletion Step . . . 57
4.2.4 EvaluatingSAND . . . 62
4.2.5 Comparisonwith the Author GroupingBaselines . . . 64
4.2.6 Comparisonwith the Supervised Author Assignment Methods . 66 4.2.7 ComparisonwithOther Supervised Methods forthe Author As-signmentStep . . . 68
4.2.8 Disussion . . . 69
5 SyGAR: Syntheti Generator of Authorship Reords 75 5.1 SyGAR Design . . . 78
5.1.1 Inferring PubliationProles from the Input Colletion . . . 80
5.1.2 GeneratingReords for Existing Authors . . . 85
5.1.3 Adding New Authors . . . 86
5.1.4 Changingan Author's Prole . . . 87
5.1.5 ModifyingCitation Attributes . . . 87
5.2 Validation . . . 88
5.3 Evaluation of DisambiguationMethodswith SyGAR . . . 95
5.3.1 AnalysisSenarios . . . 95
5.3.2 ExperimentalSetup . . . 96
5.3.3 Evaluationof Results . . . 98
6 Conlusion 103 6.1 Summary . . . 103
6.2 Future Researh . . . 104
Introdution
Several sholarly digital libraries (DLs), suh as DBLP 1
, CiteSeer 2
, MEDLINE 3
and
BDBComp 4
, provide features and servies that failitate literature researh and
dis-overy as well as other types of funtionality. Suh systems may listmillions of
bibli-ographi itationreords (here understood asa set ofbibliographi attributes suh as
author and oauthor names,work and publiationvenue titles of apartiular
publia-tion) and have beome an important soure of information for aademi ommunities
sine theyallowthesearhanddisoveryofrelevantpubliationsinaentralized
man-ner. Also,studies basedonDL ontent anlead tointeresting resultssuh asoverage
of topis, researh tendenies, quality and impat of publiations of a spei
sub-ommunity or individuals, patterns of ollaboration in soial networks, et. These
types of analysis and information, whih are used, for instane, by funding agenies
on deisions for grants and for individual's promotions, presuppose high quality
on-tent [Laender etal., 2008; Lee etal., 2007℄.
Aording toLee et al.[2007℄, the hallenges tohavehigh quality ontent omes
from data-entry errors, itation formats, lak of (enforement of) standards,
imper-fetitation-gatheringsoftware,ambiguousauthornames,abbreviationsofpubliation
venue titles and large-sale itationdata.
Among these hallenges, the problemof ambiguous authornames has required a
lot of attention fromthe DL researh ommunity due toits inherentdiulty.
Speif-ially, ambiguity of author names is a problem that ours when a set of itation
reords ontains ambiguous author names, i.e., the same author may appear under
distint names (synonyms), or distint authors may have similar names (homonyms).
1
http://dblp.uni-trier.de
2
http://iteseer.ist.psu.edu
3
http://medline.os.om
4
This problem may be aused by a number of reasons [MKay etal., 2010℄, inluding
namehangesduetopersonalirumstanes, variationintransliterationof non-roman
names,typographialerrors,lakofstandardsandommonpraties,anddeentralized
generation of ontent (i.e., by means of automati harvesting [Lagoze and de Sompel,
2001℄).
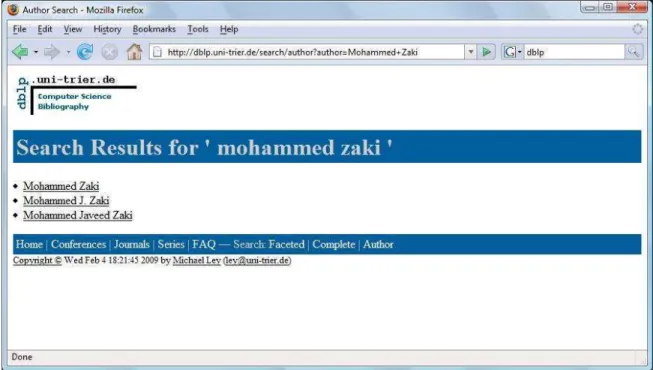
An interesting example that illustrates the author name ambiguity probleman
betaken fromDBLP. Until reently,if one searhed forthe author nameMohammed
Zaki,theresultwouldinludethreenamevariations-MohammedZaki,Mohammed
J.ZakiandMohammedJaveedZaki (seeFigure1.1). Althoughallthesethreenames
seemed to refer to the same person, they in fat illustrate a ase that involves both
synonyms and homonyms. While the rst name referred to Mohammed Zaki from
Al-Azhar University, NasrCity, Cairo, Egypt, the seond and third names referred to
Mohammed Zaki from the Rensselaer Polytehni Institute Department of Computer
Siene,USA, thusharaterizinga synonym situation.
Figure 1.1. Synonyms: aunique author withseveralname variations.
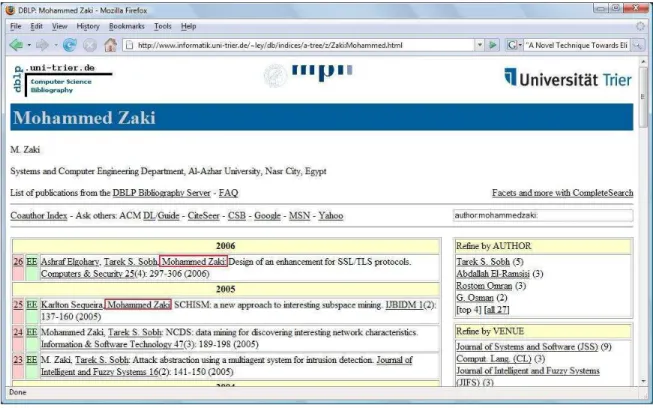
On the other hand, by likingon the Mohammed Zaki link the resultingpage
(seeFigure1.2)wouldshowanexampleofhomonym,sinetheseonditationatually
orresponds to a paper oauthored by Mohammed Javeed Zaki from the Department
ases in whih two dierentauthors simplyhave the same name,a ommonsituation,
for example, for authorswith Asian names.
Figure 1.2. Homonyms: several authors withasame namevariation.
1.1 Motivation
There are several open hallenges that need tobe addressed in orderto produemore
reliable solutions that an be employed in a prodution mode in real digital libraries.
Belowwe disuss some of them.
Eetiveness. Methods for disambiguating author names must be eetive,
i.e., they must orretly disambiguate the author names in bibliographi itations.
Although many methods have been reported in the literature (see Chapter 3 for a
omprehensive overage of those), there isstill alot of roomfor improvements.
Very Little Data in the Citations. In most ases we have only basi
infor-mation about the itations available: author (oauthor) names, work and publiation
venue titles, and publiation year. Furthermore, in some ases author names ontain
only the initial and the last surname and the publiation venue title is abbreviated.
Very Ambiguous Cases. Several methods exploit oauthor-based heuristis,
by expliitlyassuming the hypotheses that: (i) very rarely ambiguous referenes will
have oauthors in ommonwho have alsoambiguous names;or (ii)it is rare that two
authors with very similar names work in the same researh area. These hypotheses
work in most ases but, when they fail, the errors they generate are very hard to x.
Forexample, in the ase of authors with Asian names, the rst hypothesis fails muh
morefrequently than for authors withEnglish or Latin names.
Citations with Errors. Errors our in itation data whih are sometimes
impossibletodetet. The methods need tobetolerant to suh errors.
Eieny. With the high amount of artiles being published nowadays in the
dierent knowledgeareas, the solutionsneed to deal withthe problemeiently. Few
proposed methodshave this expliit onern.
Pratiality and Cost. As we shall see, most of the best urrent methods
for solving the author name disambiguationproblemare supervised, i.e., they require
large amounts of manually labeled data expliitly indiating whether two ambiguous
names orrespond to the same author or no, to serve as training for some mahine
learning proedure [Ferreiraet al., 2012b℄. Creating suh training data is very ostly
and laborious. This alsomay hurt the pratial appliation of these methods, mainly
asthe digital library evolves and more trainingis requiredto learn new patterns.
Adaptability to Dierent Knowledge Areas. As we shall see, most of the
olletions used to evaluate the methods are related to Computer Siene. However,
otherknowledgeareas (e.g., Humanities,Biology,Mediine) may havedierent
publi-ationpatterns (e.g., many publiationswith asole authororwith alot of oauthors)
whih may ause some additional diulties for the urrent generation of methods,
requiringadaptations.
Inremental Disambiguation. Ideally, disambiguation should be performed
inrementally asnew itationsare inorporatedinto the DL, sineit isnot reasonable
to assume that the whole DL should be disambiguated at eah new load. However,
most,if not all,methods ignorethis fat.
Evaluation. The methods for disambiguating author names in bibliographi
itationsare usually evaluated instati senarios withoutonsidering a time evolving
digitallibrary,ontainingdynamipatternssuhastheintrodutionofitationsofnew
authorsand the hangeof researhers' interests/expertises overtime.
Author Prole Changes. It is very ommon that the researh interests of
an author hange over time. This an happen for many reasons, for example, new
prole ausing diulties for the methods. A possible solution probably involves
re-training, but determiningwhen toretrain is ahallenge. However, this issue has been
largely ignored by all methods.
New Authors. Themethodsshouldbe apableofidentifyingreferenes tonew
ambiguous authorswho do not haveitations inthe DL yet.
These hallenges have led to a myriad of author disambiguation
meth-ods [Bhattaharya and Getoor, 2006, 2007; Culottaet al., 2007; Fanet al., 2011;
Han etal., 2004, 2005a,b; Huang et al., 2006; Kananiet al., 2007; Kanget al., 2009;
Levin and Heuser,2010;Levin etal.,2012;Malin,2005;On et al.,2006;Pereira etal.,
2009; Shuet al., 2009; Soler, 2007; Song et al., 2007; Tang et al., 2012; Torvik et al.,
2005; Treeratpituk and Giles, 2009; Yang et al., 2008℄. However, despite the fat that
most of these methods were demonstrated to be relatively eetive (interms of error
rate or similar metris), none of them provides a perfet and nal solution for the
problem, i.e., they produe errors meaningthat there is spaefor improvements.
In this thesis, we are partiularly interested in the Eetiveness, Pratiabilty
and Cost, andEvaluation hallenges. Tohelp withthe rsttwohallenges,wepropose
SAND (standingforSelf-trainingAuthorName Disambiguator). Asmentionedbefore,
the most eetive methods usually follow a supervised approah. These methods
ex-ploit a set of trainingexamples, from whih a disambiguationfuntion is derived and
then used to assign the itation reords to their orresponding authors. However, the
aquisition of training examples requires skilled human annotators to manually label
itationreords. DLsare verydynamisystems, thusmanuallabelingoflargevolumes
of examplesisunfeasible. On theotherhand,unsupervisedmethodsrequirenomanual
labeling eort, sine they simply group itation reords into lusters by maximizing
intra-luster similarity while minimizing inter-luster similarity. SAND exploits the
strengths of both supervised andunsupervised methods. Speially,itworksinthree
steps. In the rst step, (author grouping), in an unsupervised way, reurring patterns
inthe oauthorshipgraphare exploitedinordertoprodueverypurelustersof
refer-enes. In the seond step, (luster seletion), a subset of the lusters produed in the
previous step is seleted as training data for the next step. Then, in the third step,
(author assignment), a learned funtion is derived to disambiguate the referenes in
the lustersthat were not seleted in the previous step.
To help addressing the Evaluation hallenge, we propose SyGAR (standing for
SynthetiGenerator ofAuthorshipReords). Itisapableofgeneratingsyntheti
ita-tion reordsgiven asinput a list of disambiguated reordsof itationsextrated from
venue title) ofexisting authorsextrated fromthe inputolletion. Moreover, SyGAR
anbeparameterizedtogeneratereordsfornewauthors(not presentintheinput
ol-letion),for authorswithdynami proles,as wellasreordsontainingtypographial
errors.
1.2 Contributions
The two main hypotheses of this thesis are that wemay: (1) automatiallyselet and
labeltheexamples usedbya supervised tehnique, aimingtoeiently produe a
dis-ambiguationfuntionthatwillbeusedtodisambiguatetheauthornamesintheitation
reords, and (2) produe realisti olletions to evaluate the disambiguation methods
in various senarios. In order to onrm these hypotheses, the main ontributions of
this thesis are:
1. Ataxonomyforlassifyingauthornamedisambiguationmethods[Ferreira etal.,
2012b℄thatallowedustobetterunderstandthe urrentmethodsproposed inthe
literature and present asurvey of the most representative ones;
2. SAND (standing for Self-training Author Name Disambiguator) [Ferreira etal.,
2010℄,a new hybriddisambiguationmethod, that exploits the strengths of both
unsupervised and supervised tehniques for authorname disambiguation; and
3. SyGAR (standing for Syntheti Generator of Authorship
Reords) [Ferreiraet al., 2009, 2012a℄, a new tested and validated
syn-theti generator of itation reords, that helps evaluating, in several realisti
senarios and under ontrolled onditions, solutions to the name ambiguity
problem aswell asto other problems relatedto name ambiguity.
In addition to the above ontributions, the work presented in this
the-sis also inuened the development and evaluation of other methods, namely
HHC (Heuristi-based Hierarhial Clustering) [Cota etal., 2010℄, WAD (Web
Au-thor Disambiguation) [Pereira etal., 2009℄, INDi (Inremental Name
Disambigua-tion) [Carvalho et al., 2011℄, SSAND (Seletive Sampling for Author Name
1.3 Thesis Outline
The rest of this thesis is strutured inas follows.
Chapter 2 [The Author Name Disambiguation Task - Foundations℄ formally
denes the name disambiguation task and some metris and olletions used to
evaluate disambiguationmethods are presented.
Chapter 3 [Automati Author Name Disambiguation Methods℄ denes a
taxonomy for lassifying name disambiguation methods and provide a desription of
several representative methods.
Chapter 4 [SAND: Self-training Author Name Disambiguator℄ desribes our
proposed author namedisambiguationmethod along with itsevaluation.
Chapter 5 [SyGAR: Syntheti Generator of Authorship Reords℄ presents
our generator of syntheti itationreords toevaluated disambiguationmethods.
Chapter 6 [Conlusion℄ onludes the thesis, by summarizing our results and
The Author Name Disambiguation
Task - Foundations
In this hapter, we formally haraterize the name disambiguation task and desribe
some metris and olletions used to evaluatedisambiguationmethods.
To illustrate the denitions, we will use the examples showed in Table 2.1. In
this tabletherearefouritations(
{
c1, c2, c3, c4
}
),whereeahone hasitsauthornames identied inthistable byr
j
,
1
≤
j
≤
20
. The authornamesr3
andr15
are examplesof homonyms wherer3
refers to Ajay Gupta from IBM Researh, India andr15
refers to Aarti Gupta from NEC Laboratories Ameria, USA. The namesr3
andr7
are examples of synonyms. Bothnames referto Ajay Gupta fromIBM Researh -India.Table 2.1. Illustrativeexample (ambiguousgroup ofA.Gupta).
CitationId Citation
c1
(r1
) S. Godbole, (r2
) I. Bhattaharya, (r3
) A. Gupta, (r4
) A. Verma.Building re-usable ditionary repositories for real-world text mining.
CIKM, 2010.
c2
(r5
) Indrajit Bhattaharya, (r6
) Shantanu Godbole, (r7
) Ajay Gupta,(
r8
) Ashish Verma, (r9
) Je Ahtermann, (r10
) Kevin English. En-abling analysts inmanaged servies for CRM analytis. KDD, 2009.c3
(r11
)T.Nghiem,(r12
)S.Sankaranarayanan,(r13
)G.E.Fainekos,(r14
)F.Ivani,(
r15
)A.Gupta,(r16
)G.J.Pappas. Monte-arlotehniques for falsiation of temporal properties of non-linear hybrid systems.HSCC, 2010.
c4
(r17
) WilliamR. Harris, (r18
) Sriram Sankaranarayanan, (r19
) Franjo2.1 Denitions
We start with some basi denitions.
Denition 2.1.1 (Citation Reord) A itation reord
c
is a set of bibliographi data, suh as author names, work title, publiation venue title, publiation year, et.,thatispertinent to apartiular artile. Moreformally, eah itation reord
c
has a list of attributesthat inludesat least author names, work titleand publiation venue title.A spei value is assoiated to eah attribute in a itation, whih may be omposed
of several elements. In ase of the attribute author names, an element orresponds
to the name of a single unique author. In ase of the other attributes, an element
orresponds to a word/term.
Denition 2.1.2 (Referene) Eah author name element is a referene
r
to an au-thor. Weassoiatealistofattributestoeahreferener
. Intheontextofbibliographi itations,r.author
orresponds to the author name attribute,r.coauthors
orresponds to the other author names in a itation reord (oauthors),r.title
orresponds to the work title attribute,r.venue
orresponds to the publiation venue title attribute, and other attributes suh as publiation year, aliation, e-mail and so on.For instane, the referene
r3
in the itationc1
in the Table 2.1 has the follow-ing attributes values:r3.author
=A. Gupta,r3.coauthors
={S. Godbole, I. Bhat-taharya, A. Verma},r3.title
=Building re-usable ditionary repositories for real-world textmining,r3.venue
=CIKM andr3.year
=2010.Denition 2.1.3 (Ambiguous Group) An Ambiguous group is a group of
refer-eneswhosevalueoftheauthorname attributeareambiguous,i.e.,groupsof referenes
having author name attributes with similar names.
2.2 Task Charaterization
Thenamedisambiguationtaskmaybeformulatedasfollows: Let
C
=
{
c1, c2
, ..., c
k
}
be aset ofitationreords. Eahelementoftheattribute authornames isareferener
j
toanauthor. Theobjetiveofadisambiguationmethodistoprodueadisambiguationfuntion that is used to partitionthe set of referenes to authors
{
r1, r2, . . . , r
m
}
inton
sets{
a1, a2, . . . , a
n
}
, so that eah partitiona
i
ontains (all and ideally only all)thereferenes toa same author.
for instane, by using a bloking method [On et al., 2005℄. Bloking methods address
salabilityissues avoiding the need for omparisons amongall referenes.
2.3 Evaluation Metris
In this setion,we desribeK, pairwiseF1,luster F1, RCS and B-ubed metristhat
are usually used for evaluating disambiguation methods. The key idea is to ompare
the lustersextrated by disambiguationmethodsagainstideal,perfetlusters, whih
were manually extrated. Hereafter, a luster extrated by a disambiguationmethod
will be referred to as empirial luster, while a perfet luster will be referred to as
theoretial luster.
K Metri
The
K
metri [Lapidot, 2002℄ determines the trade-o between the average luster purity (ACP) and the average author purity (AAP) or ohesion. Given anambiguousgroup,ACPevaluatesthepurityoftheempiriallusterswithrespettothetheoretial
lusters for this ambiguous group. Thus, if the empirial lusters are pure (i.e., they
ontain only referenes to the same author), the orresponding ACP value will be 1.
ACP isdened inEquation 2.1:
ACP
=
1
N
e
X
i
=1
t
X
j
=1
n
2
ij
n
i
(2.1)where
N
is the total numberof referenes in the ambiguousgroup,t
is the numberof theoretial lusters in the ambiguous group,e
is the number of empirial lusters for this ambiguous group,n
i
is the total number of referenes in the empirial lusteri
, andn
ij
is the total number of referenes in the empirial lusteri
whih are also in the theoretiallusterj
.Foragiven ambiguousgroup,the ohesion metriAAP evaluatesthe
fragmenta-tion of the empiriallusters with respet to the theoretial lusters. If the empirial
lustersarenotfragmented,theorrespondingAAPvaluewillbe1. Inotherwords,the
ohesion metri AAP an be thought as the inverse of the fragmentation. The higher
the AAP value, the less fragmented are the lusters. AAP is dened in Equation 2.2:
where
n
j
is the total number of referenes in the theoretial lusterj
.The
K
metri onsists of the geometri mean between ACP and AAP values. It evaluates the purity and fragmentation of the empirial lusters extrated by eahmethod. The
K
metri is given inEquation 2.3:K
=
√
ACP×
AAP (2.3)Pairwise F1
PairwiseF1(
p
F1)istheF1metri[Rijsbergen,1979℄alulatedusingpairwisepreision and pairwise reall. Pairwise preision (pP
) is alulated aspP
=a
a
+
c
, wherea
is thenumber of pairs of referenes in an empirial luster that are (orretly) assoiated
withthesame author,and
c
isthenumberofpairs ofreferenes inanempirialluster not orresponding to the same author. Pairwise reall (pR
) is alulated aspR
=a
a
+
b
,where
b
is the number of pairs of referenes assoiated with the same author that are not inthe same empirial luster. The F1-metri isdened inEquation 2.4:p
F1= 2
×
pP
×
pR
pP
+
pR
(2.4)Cluster F1
ClusterF1 (
cF
1
)is the F1 metri alulated using luster preisionand lusterreall thatmeasurestheperformaneatthe lusterlevel. Clusterpreision(cP
)isalulated ascP
=
a/
(
a
+
c
)
, wherea
is the number of ompletely orret lusters (a orret lustershouldhaveallthe referenes of anauthorand onlythem,i.e., noneof anotherauthor; otherwise it is inorret) and
c
is the number of inorret lusters. Cluster reall (cR
) is alulated ascR
=
a/
(
a
+
b
)
, whereb
is the number of lusters that should be reated but were not. This is a metri to summarize information abouttheompletelyorret lustersgenerated by the method. Likewise,F1 isanalogously
dened by the aboveformula.
Ratio of Cluster Size
B-Cubed
B-Cubed metri was proposed by Baggaand Baldwin [1998℄ and has been used to
evaluate Web person name searh task [Artiles etal., 2010℄. B-Cubed alulates the
nal preisionand reall based onthe preision(
P
r
) and reall (R
r
) of eah referener
that are dened as:P
r
=
n
r
i
n
i
(2.5)
R
r
=
n
r
i
n
j
(2.6)
where
n
r
i
is the total number of referenes that refer to same author ofr
and belongto the same empirialluster
i
that ontainsr
,n
i
isthe total number of referenes in the empirial lusteri
that ontainsr
andn
j
is the total number of referenes in the theoretial lusterj
that ontainsr
.The nalpreision(
bP
)and reall(bR
)are alulated by thefollowingformulas:b
P=
N
X
r
=1
w
r
×
P
r
(2.7)b
R=
N
X
r
=1
w
r
×
R
r
(2.8)where
N
is the number of referenes in the olletion andw
r
is the weight of the referener
in the olletion. The value of eahw
r
is ommonlydened as1
/N
.The harmoni mean (bF
α
)of B-Cubed preisionand reall is alulated by:b
Fα
=
1
α
1
bP
+ (1
−
α
)
1
bR
(2.9)
Appliation of the metris - an illustrative example
Consider the following example (see Figure 2.1): We have three theoretial lusters
and four empirial lusters. Only one empirialluster is not pure and there are two
referenes fragmented intotwolusters.
Table 2.2 shows the results of eah metri applied to the illustrative example
(a)Theoretial lusters (b) Empiriallusters
Figure2.1. Anillustrativeexample. Eahgeometrigurerepresentsareferene
to an author. The same guresrefer tothe sameauthor.
Table 2.2. Performane oftheevaluation metris.
Metri Result
K
ACP
=
1
9
×
(
3
2
3
+
3
2
3
+
1
2
2
+
1
2
2
+
1
2
1
) = 0
.
89
K =0.81
AAP
=
1
9
×
(
3
2
4
+
3
2
3
+
1
2
3
+
1
2
2
+
1
2
1
) = 0
.
73
pF1
pP
=
3+3+0+0+0
3+3+1+0
= 0
.
84
pF1= 0.70
pR
=
3+3+0+0+0
6+3+1
= 0
.
60
F1
P
=
1
4
= 0
.
25
F1= 0.28
R
=
1
3
= 0
.
33
RCS RCS
=
4
3
= 1
.
33
B-Cubed bP
=
1
9
(
3
3
+
3
3
+
3
3
+
3
3
+
3
3
+
3
3
+
1
2
+
1
2
+
1
1
) = 0
.
89
bFα
=0
.
5
=0.68bR
=
1
9
(
3
4
+
3
4
+
3
4
+
3
3
+
3
3
+
3
3
+
1
4
+
1
2
+
1
2
) = 0
.
72
whih annot be paired with other ones of the same author in the same empirial
luster.
2.4 Colletions
Amongthe olletions more ommonlyused toevaluate the author name
disambigua-tionmethodswe an mention CiteSeer, DBLP, Penn, BDBComp and Rexa 1
that
on-tain publiations of omputer siene researhers, arXiv 2
that ontains itations from
highphysispubliations,BioBase 3
thatontainsitationsfrombiologialpubliations,
IMDb 4
thatontainsdatafrommovies,MEDLINEandBioMedthatontaindatafrom
biomedial publiations and Cora 5
that ontains data on dupliate itations. In this
setion, we desribe in more details DBLP, perhaps the most used of all previously
mentionedolletions[Han etal.,2004,2005b,a;Pereira etal.,2009;Yang etal.,2008℄,
and BDBComp, a olletionbuilt by us, that has the distintive property that many
authorspossessonlyonepubliation,makingthedisambiguationtaskevenharder. We
exploit both olletions inthis thesis for evaluation purposes.
The olletion of referenes extrated from DBLP sums up 4,287 referenes
as-soiated with 220 distint authors, whih means an average of approximately 20
ref-erenes per author. This olletion inludes 2,270 referenes whose author names are
in short format. Small variations of this olletion have been used in several other
works [Hanet al., 2004, 2005b,a; Pereira et al., 2009; Yang etal., 2008℄. Its original
version was reated by Han et al. [2004℄, and they manually labeled the referenes.
For this, they used the author's publiation home page, aliation name, e-mail, and
oauthor names in a omplete name format, and also sent emails to some authors to
onrmtheirauthorship. Thereferenes forwhihtheyhad insuientinformationto
bejudgedwere eliminated. Hanet al.[2004℄alsoreplaedthe abbreviated publiation
venue titles by their omplete version obtained from DBLP. We used 11 ambiguous
groups extrated by Hanet al.[2004℄ with some orretions.
The olletion of referenes extrated from BDBComp sums up 361 referenes
assoiatedwith184distintauthors,approximatelytworeferenesperauthor,inwhih
onlyeigth authornamesare inshortformat. Notie that,althoughmuhsmallerthan
the DBLP olletion, this olletion is very diult to disambiguate, beause it has
many authors with only one itation. This olletionwas reated by us and ontains
the 10largest ambiguousgroups found inBDBComp at the time of its reation.
Table2.3showsmoredetailedinformationabouttheolletionsanditsambiguous
groups. Disambiguation is partiularly diult in ambiguous groups suh as the C.
Chen group, in whih the orret author must be seleted from 60 possible authors,
and the F. Silva group, in whih the majority of authors has appeared in only one
itation.
As mentioned before, eah referene has the author name, a list of oauthor
names, the title of the work and the title of the publiation venue (onferene or
journal) attributes.
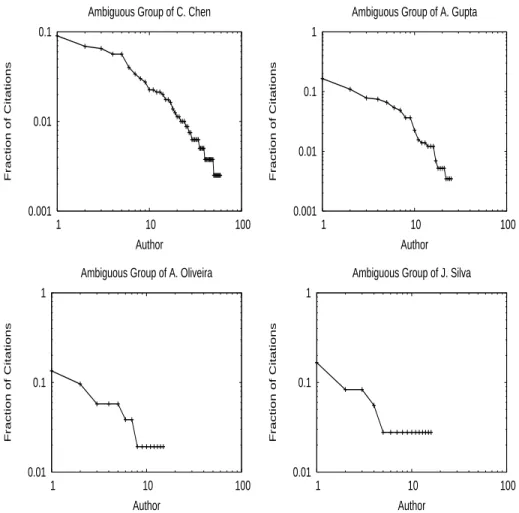
Figure 2.2 shows the authorship distribution within eah of two representative
groups of eah olletion. Notie that, for agiven group, few authors are very proli
4
http://www.imdb.om
Table 2.3. TheDBLP and BDBCompolletions
DBLP BDBComp
Ambiguous #Referenes/ Ambiguous #Referenes/
Group #Authors Group #Authors
A. Gupta 576/26 A. Oliveira 52/16
A. Kumar 243/14 A. Silva 64/32
C. Chen 798/60 F. Silva 26/20
D. Johnson 368/15 J. Oliveira 48/18
J. Martin 112/16 J. Silva 36/17
J. Robinson 171/12 J. Souza 35/11
J. Smith 921/29 L. Silva 33/18
K.Tanaka 280/10 M. Silva 21/16
M. Brown 153/13 R. Santos 20/16
M. Jones 260/13 R. Silva 28/20
M. Miller 405/12
−
−
andappear inseveral itations,whilemost ofthe authors appear in onlyfewitations
(thesametrendisobservedinallgroupsofDBLPandBDBComp). Thisisanintrinsi
0.001
0.01
0.1
1
10
100
Fraction of Citations
Author
Ambiguous Group of C. Chen
0.001
0.01
0.1
1
1
10
100
Fraction of Citations
Author
Ambiguous Group of A. Gupta
0.01
0.1
1
1
10
100
Fraction of Citations
Author
Ambiguous Group of A. Oliveira
0.01
0.1
1
1
10
100
Fraction of Citations
Author
Ambiguous Group of J. Silva
Figure 2.2. Authorship distribution within eah ambiguous group. Authors
(x-axis) are sorted indereasing order of proliness (i.e., more proli authors
Automati Author Name
Disambiguation Methods
Inthishapter,weproposeataxonomy[Ferreiraet al.,2012b℄forharaterizingthe
au-thornamedisambiguationmethodsinsholarlydigitallibrariesandpresentanoverview
of representative author name disambiguationmethods.
3.1 A Taxonomy for Author Name Disambiguation
Methods
This setion presents a hierarhial taxonomy for grouping the most
repre-sentative automati author name disambiguation methods found in the
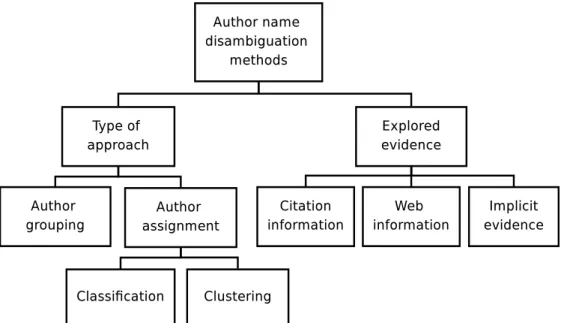
litera-ture. The proposed taxonomy is shown in Figure 3.1. The methods may
be lassied aording to the main type of exploited approah: author
group-ing [Bhattaharya and Getoor,2007;Cotaet al.,2010;Culotta etal.,2007;Fanet al.,
2011; Ferreira etal., 2010; Hanet al., 2005b; Huang et al., 2006; Kananietal., 2007;
Kang et al., 2009; On and Lee, 2007; Pereira et al., 2009; Soler, 2007; Song etal.,
2007; Torvik et al.,2005;Torvik and Smalheiser, 2009; Treeratpituk and Giles, 2009;
On etal., 2006; Yang etal., 2008℄, whih tries to group the referenes to the same
author using some type of similarity among referene attributes, or author
assign-ment [Bhattaharya and Getoor, 2006; Ferreiraet al., 2010; Han etal., 2004, 2005a;
Tang etal., 2012℄, whih aims at diretly assigning the referenes to their respetive
authors. Alternatively, the methods may be grouped aording to the evidene
ex-plored inthe disambiguationtask: the itationattributes (only), Web information,or
Figure 3.1. A taxonomyfor author namedisambiguation methods.
Notie that in this hapter we over only automati methods. Other types of
method,suhasmanualassignmentby librarians[Sovilleet al.,2003℄orollaborative
eorts 1
,relyheavily onhumaneorts, whihprevent themfrombeingused inmassive
name disambiguation tasks. For this reason, they are not addressed in this hapter.
There are also eorts to establish a unique identiation to eah author, suh as the
useofanOpenResearher ContributorIdentiation 2
(ORCID),butthesearealsonot
overed here.
Sine the name disambiguation problem is not restrited to a single
on-text, it is also worth notiing that several other name disambiguation
meth-ods, whih exploit distint piees of evidene or are targeted at other
ap-pliations (i.e., name disambiguation in Web searh results), have been
de-sribed in the literature [Bekkerman and MCallum, 2005; Diehlet al., 2006;
Galvez and de MoyaAnegón, 2007; Vuet al., 2007; Yoshidaet al., 2010℄. However,
adisussion of these methodsis outsidethe sope of this hapter.
Finally,we shouldstress that the ategories inour taxonomy are not ompletely
disjoint. For instane, there are methods that use two or more types of evidene or
mixapproahes. In the next subsetions, we detailour proposed taxonomy.
1
http://meta.wikimedia.org/wiki/WikiAuthors
3.1.1 Type of Approah
As said before, one way to organize the several existing author name disambiguation
methodsisaordingtothetypeofapproahtheyexploit. Weelaboratethisdistintion
further in the disussion below.
3.1.1.1 Author Grouping Methods
Authorgroupingmethodsapplyasimilarityfuntiontotheattributesofthereferenes
(or group of referenes) in order to deide whether to group the orresponding
refer-enesusingalusteringtehnique. Thesimilarityfuntionmaybepredened(basedon
existing ones and depending on the type of the attribute) [Bhattaharya and Getoor,
2007; Cotaet al., 2010; Han etal., 2005b; On and Lee,2007; Soler, 2007℄,learned
us-ing a supervised mahine learningtehnique [Culottaetal., 2007; Huang et al., 2006;
Torvik et al.,2005;Torvik and Smalheiser,2009;Treeratpituk and Giles,2009℄,or
ex-trated from the relationships amongauthors and oauthors, usually represented as a
graph [Fanet al., 2011; Levinand Heuser, 2010; On etal., 2006℄. The dened
simi-larity funtion is then used along with some lustering tehnique to group referenes
of a same author, trying to maximize intra and minimize inter-luster similarities,
respetively.
Dening a Similarity Funtion
Here, a similarity funtion is responsible for determining how similar two referenes
(or groups of referenes) to authors are. The goal is toobtain a funtion that returns
high similarity values for referenes to the same author and returns low similarity
values for referenes to dierent authors. Moreover, it is desirable that the similarity
funtion be transitive. More speially, let
c1
,c2
andc3
be three itation reords, ifc1
andc2
are very similar (aording to the funtion) andc2
andc3
are also very similar, thenc1
andc3
should have high similarity aording to our funtion. Next, we disuss the ways todetermine this similarity funtion.Using Predened Funtions
This lassofmethodshasaspeipredened similarityfuntion
S
embeddedintheiralgorithms to hek whether two referenes or groups of referenes refer to the same
author. Examples of suh funtion
S
inlude [Cohenet al., 2003℄: the Levenshteindistane, Jaard oeient, osine similarity, soft-TFIDF and others [Cohen etal.,
These methods do not need any type of supervision in terms of training data
but their similarity funtions are usually tuned to disambiguate a spei olletion
ofitation reords. Fordierent olletions,a new tuning proeduremay be required.
Finally, not allthe funtions used in these methodsare transitive by nature.
Learning a Similarity Funtion
Learning a spei similarity funtion usually produes better results, sine these
learnedfuntions are diretly optimized for the disambiguationproblem at hand. To
learn the similarity funtion, the disambiguation methods reeive a set
{
s
ij
}
of pairs of referenes (the training data) along a speial variable that informs whether thesetwo orresponding referenes refer to the same author. The pair of referenes,
r
i
andr
j
∈
R
(the set of referenes) are usually represented by a similarity vetors
~
ij
. Eahsimilarity vetor
s
~
ij
is omposed of a setF
ofq
features {f1
, f2, . . . , f
q
}. Eahfeaturef
p
of these vetors represents a omparison between attributesr
i
.A
l
andr
j
.A
l
of tworeferenes,
r
i
andr
j
.The value of eah feature is usually dened using other funtions, suh as
Lev-enshtein distane, Jaardoeient, Jaro-Winkler,osinesimilarity,soft-TFIDF,
eu-lideandistane, et., orsome spei heuristi, suh as the numberof terms or
oau-thornamesinommon,orspeialvaluessuhasthe initialoftherst namealongwith
the lastnames, et.
The training data is then used to produe a similarity funtion
S
fromR
xR
to {0
,
1
}, where1
means that the two referenes do refer to the same author and0
meansthat they donot. As mentionedbefore, methods relying inlearningtehniquestodene the similarity funtion are quiteeetive indierent olletions of itations,
but they usually need many examples and suient features to work well, whih an
bevery ostly to obtain.
Exploiting Graph-based Similarity Funtions
The methods that exploit graph-based similarity funtions for author name
disam-biguationusually reate a oauthorship graph
G
= (
V, E
)
for eah ambiguous group. Eah element of the author name and oauthor name attributes is represented by avertex
v
∈
V
. The same oauthor names are usually represented by only a unique vertex. Foreahoauthorship(i.e., apairof authorswhopublishes anartile)anedgeh
v
i
, v
j
i ∈
E
is reated. The weight of eah edgeh
v
i
, v
j
i
is related to the amount ofartilesoauthored by the orresponding authornames represented by verties
v
i
andombined withother similarityfuntions onthe attributesof the referenes toauthors
or used as anew feature in the similarityvetors.
Clustering Tehniques
Author grouping methods usually exploit a lustering tehnique in their
disambigua-tion task. The most used tehniques are partitioning, hierarhial agglomerative
lustering, density-based and spetral lustering [Hanand Kamber, 2005℄. In general,
these lusteringtehniquesrelyonagoodsimilarityfuntion togroupthereferenes.
Next, we provide a brief desription of these tehniques applied to the author name
ambiguity problem.
Partitioning Clustering Tehnique
A partitioning lustering tehnique, applied to the author name ambiguity problem,
reates
k
partitionsof the set of referenes toauthors. These methods usually reeive the numberk
of authorgroupstobereatedasinputaswellasthe set ofreferenes to bedisambiguated. They reateaninitialpartitioningofk
lusters(usually randomly) and,toimprovethedisambiguationproess,movereferenestoauthorsfromonelustertoanotherbasedonsomesimilarityriteria. Theaimisthat,inthe endoftheproess,
thereferenes toasameauthorwillbeputtogetherinthesamelusterwhilereferenes
to dierent authors willremainin dierent lusters.
One advantage of these partitioning tehniques is that a referene may be
assigned to dierent authors during the disambiguation proess, whih an
poten-tially help reduing erroneous assignments. This does not our in hierarhial
agglomerative lustering tehniques (see below). However, these methods usually
need to know the orret number of authors to perform well, whih in most of
ases is an unrealisti assumption. Moreover, similarities are usually alulated
with respet to a representative referene within the lusters (e.g., a entroid).
Thus, referenes that are not similar enoughto this representative one but are similar
tootherreferenesinthelustermaynotbeinsertedintothis(perhapsorret)luster.
Hierarhial Agglomerative Clustering
A hierarhialagglomerativelustering tehnique [Han and Kamber, 2005℄ groupsthe
referenes toauthors ina hierarhial manner. Initially,eah referene orresponds to
a single luster. Next, in eah iteration of the proess, the two most similar lusters
are groupedtogether andthe similarityamongalllustersisrealulated. Theproess
One disadvantage of this tehnique is that if two referenes to dierent authors
are put together in a same luster during the proess, they an no longer be moved
to dierent lusters for the remainder of the proess, i.e., this type of error annot
be orreted. In the ase of the name disambiguationtask, this partiular homonym
problemisone ofthe hardesttoorret. Anotherdisadvantage istheost: weusually
needto ompare all lusterswith eah other tond the most suitable tobe fused.
Density-based Clustering
Withdensity-based lustering, a lusterorresponds to adense region ofreferenes to
authors surrounded by a region of low density (aording to some density riteria).
Referenes in regionswith lowdensity are onsidered asnoise.
An example of a density-based lustering algorithm that has been used in the
author name disambiguation task is DBSCAN [Hanand Kamber, 2005℄. DBSCAN
estimatesthe density ofreferenes by ounting thenumberofreferenes withina
spe-iedradius. DBSCAN lassieseahrefereneasorereferenes(i.e., referenes whose
numberofneighborhoodreferenes withina speiradius exeedsagiven threshold),
border referenes (i.e., a referene that isnot a ore referene but is withinthe
neigh-borhood of a ore referene) and noise referenes (i.e., areferene that is neitherore
nor border).
DBSCAN initially labels all referenes as ore, border or noise based on the
proedure desribed above. Next, it disonsiders all noise referenes and introdues
edges between the ore referenes whithin a given radius of eah other. Eah group
of onneted referenes is a luster and eah border referene is assoiated with one
lusterof its ore referenes.
One advantage of density-based lustering tehniques is that the lusters are
onstrutedusing several representative referenes to authors. A disadvantage is that
they are very sensibleto their thresholds.
Spetral Clustering
Spetrallustering tehniques [Zha et al., 2001℄ are graph-based tehniques that
om-putethe eigenvalues and eigenvetors,the spetralinformation,ofa LaplaianMatrix
that, in the the author name disambiguation task, represents a similarity matrix of
min-the spetral information (i.e., eigenvalues and eigenvetors) instead of the similarity
matrix in the lustering proess.
Spetrallustering usually produesbetter performane thantraditional
luster-ingtehniques. However, the spetrallusteringmethodused in[Han etal.,2005b℄ for
authornamedisambiguationneedstoknowtheorretnumberoftheauthors(lusters)
whih, asdisussed before, an beunrealisti inreal senarios.
3.1.1.2 Author Assignment Methods
Author assignment methods diretly assign eah referene to a given author by
on-struting a model that represents the author (for instane, the probabilities of an
author publishing an artile with other (o-)authors, in a given publiation venue
and using a list of spei terms in the work title) using either a supervised
lassi-ation tehnique [Ferreira etal., 2010; Han etal., 2004℄ or a model-based lustering
tehnique [Bhattaharya and Getoor, 2006; Hanet al., 2005a℄.
Classiation
Methodsinthis lassassignthe referenes totheirauthorsusingasupervised mahine
learningtehnique. Morespeially,theyreeiveasinputasetofreferenestoauthors
with their attributes alledthe trainingdata (denotedas
D
) thatonsists of examplesor, inthis ase, referenes for whih the orretauthorship isknown. Eah example is
omposed of aset
F
ofm
features{f1, f2
, . . . , f
m
}along with aspeial variablealled theauthor. Thisauthorvariabledrawsitsvaluefromadisretesetoflabels{a1, a2, . . . ,
a
n
}, in whih eah label uniquely identies an author. The training examples areused to produe a disambiguation funtion (i.e., the disambiguator) that relates the
features in the training examples to the orret author. The test set (denoted as
T
)for the disambiguation task onsists of a set of referenes for whih the features are
known while the orret author is unknown. The disambiguator, whih is a funtion
from {
f1, f2, . . . , f
m
} to {a1, a2, . . . , a
n
}, is used to predit the orret author for the referenes in the test set. In this ontext, the disambiguator essentially divides thereords in
T
inton
sets {a1, a2, . . . , a
n
}, wherea
i
ontains (ideally all and no other) referenes inwhih thei
thauthor isinluded.These methods are usually very eetive when faed with a large number of
examples of itationsfor eah author. Another advantage is that, if the olletionhas
been disambiguated (manually or automatially), the methods may be applied only
havebeenreported,theaquisitionoftrainingexamplesusuallyrequiresskilledhuman
annotators tomanually labelreferenes. DLs are very dynami systems, thusmanual
labeling of large volumes of examples is unfeasible. Further, the disambiguation task
presentsnuanesthatimposetheneedformethodswithspeiabilities. Forinstane,
sineitisnot reasonable toassumethatexamples forallpossibleauthorsare inluded
inthetrainingdataandtheauthorshangetheirinterestareaovertime,newexamples
need be insert into training data ontinuously and the methods need to be retrained
periodiallyinorder tomaintain their eetiveness.
Clustering
Clustering tehniques [Hanand Kamber, 2005℄ that attempt to diretly assign
refer-enes to authors work by optimizing the t between a set of referenes to an author
and some mathematial model used to represent that author. They use probabilisti
tehniques to determine the author in a iterative way to t the model (or estimate
the parameters in probabilist tehniques) of the authors. For instane, in the rst
run of suh a method eah referene may be randomly distributed to an author
a
i
and a funtion, from a set of features {f1, f2, . . . , f
m
} to {a1, a2, . . . , a
n
}, is derived using this distribution. In the seond iteration, this funtion is used to predit theauthor of eah referene and a new funtion is derived to be used in the next
iter-ation. This proess ontinues until a stop ondition is reahed, for instane, after
a number of iterations. Two algorithms ommonly used to t the models in
disam-biguationtasksareExpetation-Maximization(EM)[Dempsteret al.,1977℄andGibbs
Sampling[Griths and Steyvers, 2004℄.
Thesemethodsdonotneedtrainingexamples,buttheyusuallyrequireprivileged
informationabout the orretnumberof authorsorthe numberof authorgroups(i.e.,
group of authors that publish together) and may take some time to estimate their
parameters (e.g., due to the several iterations). Additionally, these methods may be
able to diretly assign authors to their referenes in a new itations using the nal
derived funtion.
3.1.2 Explored Evidene
Citation Information
Citation information are the attributes diretly extrated from the itations, suh as
author and oauthor names, work title, publiation venue title, publiation year, and
so on. Theseattributes are the onesommonlyfound inallitations,but usually they
are not suient to perfetly disambiguate all referenes to authors. Some methods
alsoassume the availability ofadditionalinformation,suh as e-mailaddresses, postal
addresses, pageheaderset.,whihare notalwaysavailableoreasytoobtain,although
if existent, they usually help the proess.
Web Information
Web information represents data retrieved from the Web that is used as additional
information about an authorpubliation prole. This informationis usually obtained
by submitting queries tosearh engines basedon the values of itationattributes and
thereturnedWebpagesareusedasnewevidene(attributes)toalulatethesimilarity
among referenes to authors. The new evidene usually improves the disambiguation
task. Oneproblemis theadditionalost ofextratingallthe needed informationfrom
the Web douments.
Impliit Evidene
Impliitevideneisinferredfromvisibleelementsofattributes. Severaltehniqueshave
beenimplementedtond impliitevidene, suhasthelatenttopisofaitation. One
example is the Latent Direhlet Loation (LDA) [Blei et al., 2003℄ that estimates the
topi distribution ofa itation(i.e., LDA estimates the probability ofeah topigiven
aitation). Thisestimateddistributionisusedasnewevidene(attribute)toalulate
the similarity amongreferenes toauthors.
3.2 Overview of Representative Methods
In this setion,we present abriefoverview of representativeauthor name
disambigua-tion methods whih fall under one ormore ategories of the proposed taxonomy. Our
mainfoushereisonthosemethodsthathavebeenspeiallydesignedtoaddressthe
name ambiguityprobleminthe ontextof bibliographiitations,sine they are more
methods explore itation information in the disambiguation task. Thus, we leave to
Subsetion3.3 the disussion of those methods that use additionalevidene.
Although not part of our taxonomy, one importantpointto understand the
dis-ussion that follows is the evaluationmetris that are used by eah proposed method
intheir experimental evaluations. In additionto the metris disussed inSetion 2.3,
some disambiguation methods also use auray, whih is basially the proportion of
orret results among all preditions, the traditional metris of preision, reall, and
F1 [Rijsbergen,1979℄,ommonlyusedforinformationretrievalandlassiation
prob-lems 3
and MUC [Bagga and Baldwin, 1998℄. In this lastmetri, reallisalulated by
summing up the number of elements in the theoretial lusters minus the number of
empiriallusters (obtained with the method)that ontain these elements and
divid-ingthis by the total ofelementsminusthe numberoftheoretial lusters. Preision is
alulatedsimilarly.
3.2.1 Author Grouping Methods
Using Predened Funtions
Hanet al.[2005b℄representeahrefereneasafeaturevetorwhereeahfeature
orre-spondstoan elementof agiven instane of one ofitsattributes. The authorsonsider
two options for dening the feature weights: TFIDF [Baeza-Yates and Ribeiro-Neto,
1999℄ and NTF (Normalized Term Frequeny), being NTF given by
ntf
(
i, d
) =
f req
(
i, d
)
/maxf req
(
i, d
)
wheref req
(
i, d
)
refers to the feature frequenyi
within thereord
d
, andmaxf req
(
i, d
)
refers to the maximum term frequeny of featurei
inthe reordd
. Theauthorsproposethe use ofK-wayspetrallustering withQR deompo-sition [Zha etal., 2001℄ toonstrut lusters of referenes tothe same author. To usethis lustering tehnique, the orret number of lusters to be generated needs to be
informed. The K-way spetrallustering methodrepresents eah refereneas avertex
of an undireted graph and the weight of the edge between two verties represents
the similarity between the attributes assoiatedwith the respetive referenes. K-way
spetrallustering splits the graphso that reordsthat are moresimilar toeah other
willbelong tothe same luster. This methodwas evaluated using data obtained from
the Web and DBLP. Experimental results ahieved 63% of aurayin DBLP and up
to84.3% inthe Web olletion.
Analgorithmforolletiveentityresolution(i.e.,analgorithmthatuses only
dis-ambiguated oauthor names when disambiguatingan author name of a itation)that
3
exploits attributeelements(i.e.,value ofattributespresentintheitationreords)and
relationalinformation (i.e., authorshipinformationbetween entities referred in the
i-tations reords) isproposed by Bhattaharya and Getoor[2007℄. The authorspropose
aombinedsimilarityfuntiondenedonattributesandrelationalinformation. Asthe
initialstep, the authorsreatelustersofdisambiguatedreferenes verifyingiftwo
ref-erenes haveatleast
k
oauthornamesinommon(theyusedonlytheauthornamesin their experiments, but mention that other attributes may be used). The experimentswere performed using soft-TFIDF, Jaro-Winkler, Jaro and Saled Levenshtein
mea-sures for name attributes, and for relational attribute they used Common Neighbors,
Jaard oeient,Adami/Adar similarityand Higher-orderneighborhoodmeasures.
The authorsexploitagreedyagglomerativestrategythatmergesthe mostsimilar
lus-ters in eah step. The olletions used in the experiments were a subset of CiteSeer
ontainingmahinelearningdouments,aolletionofhighenergyphysispubliations
from arXiv that was originally used in the KDD Cup 2003 4
and BioBase 5
, ontaining
biologial publiations of Elsevier and was used in an IBM KDD-Challenge
ompeti-tion. The method obtained around 0.99 of F1 in the CiteSeer and arXiv olletions
and around0.81 in the BioBase olletion.
Soler [2007℄ proposes a new distane metri between two itations,
c
i
andc
j
, (or lusters of itations) based on the probability of these publiations having termsand author names in ommon. In that work, the author proposes a semi-automati
algorithm that reates lusters of artiles using the proposed metri and summarizes
the lustersby meansof a representative itationof the luster inludingthe distane
from it to the others. Soler groups the itations for whih the inter-itation distane
is minimum using as evidenes the author names, email, address, title, keywords,
re-searh eld, journal and publiation year attributes. The nal deision on whether
two andidate lusters belong to the same author or not is given by a speialist. He
presents some illustrative ases of lusters obtained using his metri with reords
ex-tratedfromISI-ThomsonWeb ofSiene database 6
butamoreformalevaluationwas
not performed.
Cota etal. [2010℄ propose a heuristi-based hierarhial lustering method for
author name disambiguation that involves two steps. In the rst step, the method
reates lusters of referenes with similar author names that share at least a similar
oauthor name. Author name similarity is given by a speialized name omparison
4
http://www.s.ornell.edu/projets/kddup
5
http://www.elsevier.om/wps/nd/bibliographidatabasedesription.ws_home/600715/
desription#desription
funtion alled Fragments. This step produes very pure but fragmented lusters.
Then, in the seond step, the method suessively fuses lusters of referenes with
similarauthor namesaording to the similaritybetween the itationattributes (i..e.,
work titleand publiation venue) alulated using the osine measure. In eah round
of fusion, the information of fused lusters is aggregated (i.e., all words in the titles
are grouped together) providingmore informationfor the next round. This proess is
suessivelyrepeateduntilnomorefusionsarepossibleaordingtoasimilarity
thresh-old. Theauthors usedpairwiseF1 and Kmetris onolletionsextrated fromDBLP
and BDBComp to evaluate the method and obtained around 0.77 and 0.93 for K in
DBLPandBDBComp,respetively. Anextensionofthismethodthatallowsthe name
disambiguation task to be inrementally performed is presented in [Carvalho etal.,
2011℄.
Learning a Similarity Funtion
Torvik et al.[2005℄proposetolearnaprobabilistimetrifordeterminingthe
similar-ity among MEDLINE reords. The learning model is reated using similarity vetors
between two referenes. In that work, the similarity vetor ontains features resulting
of the omparison between the normal itation attributes along with medial subjet
headings, language, and aliation of two referenes. The authors also propose some
heuristisforgeneratingtrainingsets (positiveandnegative)automatially. Whenthe
probabilisti metri reeives the attributes assoiated with two referenes, their
sim-ilarity vetor is reated and the relative frequeny of this prole in the positive and
negative trainingsets isheked for determiningwhether these two referenes refer to
the same author or not. In a subsequent work, Torvik and Smalheiser [2009℄ extend
this method by inluding additional features, new ways of automatially generating
training sets, an improved algorithm for dealing with the transitivity problem and a
new agglomerative lustering algorithm for grouping reords. The authors estimate
reall around 98.8%. They also estimate that only 0.5% of the lusters have mixed
referenes ofdierentauthors(purity),and that onlyin2% ofthe ases the referenes
of the same authorare split intotwoor more lusters(fragmentation).
Huang et al.[2006℄ presentaframeworkfor solvingthe nameambiguityproblem
inwhihablokingmethodisrstappliedtoreatebloksofreferenestoauthorswith
similarnames. Next DBSCAN, a density-based lustering method[Ester et al., 1996℄,
isusedforlusteringreferenes byauthor. Foreahblok,thedistane metribetween