Extração e Comparação de
Características Locais para o
Reconhecimento Facial por Meio de
Retratos Falados
Marco Antonio de Albuquerque Silva
UNIVERSIDADE FEDERAL DE OURO PRETOOrientador: Guillermo Cámara Chávez
Dissertação submetida ao Instituto de Ciências Exatas e Biológicas da Universidade Federal de Ouro Preto para obtenção do título de Mestre em Ciência da Computação
Catalogação: sisbin@sisbin.ufop.br
S586e Silva, Marco Antonio de Albuquerque.
Extração e comparação de características locais para o reconhecimento facial por meio de retratos falados [manuscrito] / Marco Antonio de Albuquerque Silva. –
2014.
80 f.: il. color., grafs., tabs.
Orientador: Prof. Dr. Guilhermo Cámara Chávez.
Dissertação (Mestrado) - Universidade Federal de Ouro Preto. Instituto de Ciências Exatas e Biológicas. Departamento de Computação.
Área de concentração: Recuperação e tratamento da informação
1. Fotografia - Teses. 2. Reconhecimento facial (Computação) - Teses. 3. Reconhecimento de padrões óticos - Teses. I. Universidade Federal de Ouro Preto. II. Título.
Extração e Comparação de Características Locais
para o Reconhecimento Facial por Meio de Retratos
Falados
Resumo
Sistemas de reconhecimento facial através de retratos falados são muito importan-tes para agências de segurança. Esses sistemas podem ajudar a localizar ou diminuir o número de potenciais suspeitos. Recentemente, vários métodos foram propostos para resolver esse problema, mas não há uma comparação clara de desempenho entre eles. Neste trabalho é proposta uma nova abordagem para o reconhecimento facial através
de fotografias/retratos falados baseada no Local Feature-based Discriminant Analysis
(LFDA). Esse novo método foi testado e comparado com seus antecessores, utilizando três diferentes conjuntos de imagens (retratos falados) e também com a adição de uma galeria extra de 10.000 fotografias para estender a galeria. Experimentos utilizando as bases de imagens CUFS e CUFSF mostraram que a nossa abordagem supera as aborda-gens do estado-da-arte, além de ser 43% mais rápido que o segundo método, o LFDA.
Nossa abordagem também mostra bons resultados com forensic sketches. A limitação
ao avaliar este conjunto de imagens está no seu tamanho muito pequeno. Ao aumentar o conjunto de dados de treinamento, a precisão da nossa abordagem vai aumentar, uma vez que foi demonstrado por nossos experimentos. Além disso, demonstramos o desem-penho e comparamos vários descritores e os principais métodos, utilizando três bases de dados diferentes e uma galeria extra, tal comparação não existia na literatura.
Abstract
Systems for face sketch recognition are very important for law enforcement agencies. These systems can help to locate or narrow down potential suspects. Recently, various methods was proposed to address this problem, but there is no clear comparison of their performance. We propose a new approach for photo/sketch recognition based on the Local Feature-based Discriminant Analysis (LFDA) method. This new approach was tested and compared with its predecessors using three differents datasets and also adding an extra gallery of 10,000 photos to extend the gallery. Experiments using the CUFS and CUFSF databases show that our approach outperforms the state-of-the-art approaches, and it is 43% faster than the second method, the LFDA. Our approach also shows good
results with forensic sketches. The limitation with this dataset is its very small size.
By increasing the training dataset, the accuracy of our approach will increase, as it was demonstrated by our experiments. Furthermore, we demonstrate the performance and compare various descriptors and the main methods, using three different databases and an extra gallery, such a comparison does not exist in the literature.
Declaração
Esta dissertação é resultado de meu próprio trabalho, exceto onde referência explícita é feita ao trabalho de outros, e não foi submetida para outra qualificação nesta nem em outra universidade.
Marco Antonio de Albuquerque Silva
Agradeço primeiramente a Maria Eduarda, minha mãe, por todo esforço que fez para que eu e minha irmã tivessemos uma boa educação, além de todo amor e paciência.
À minha irmã e eterna amiga, Giulianna, por todo carinho e por todas as resenhas durante toda infância até os dias de hoje, além de todas as brigas que eram resolvidas cinco minutos depois.
Ao professor Guillermo, meu orientador, por ter me acolhido na pós-graduação, pelos puxões de orelhas, pelos conselhos, pela paciência e compreensão.
Ao meu companheiro de viagem e encorajador, com quem aceitei desbravar o sudeste brasileiro e o mestrado, com a cara e a coragem, Danilo Santos.
Aos moradores e ex-moradores da República Navio Pirata, por terem me acolhido durante o período que estive em Ouro Preto e pela amizade, principalmente a: Gordo, Ralin, Slow, Zé-Grandão, Fido e 33, com os quais convivi a maior parte do tempo.
Aos amigos que fiz em Ouro Preto, principalmente à: Luís Gustavo, Ana Paula, Danielle, Filipe e Gaby.
Aos meus amigos conterrâneos: Túlio, Ricardo, Vilker, Jônathas, Alisson e Adson, os quais não me deixaram perder completamente o vínculo com a sociedade no período de escrita deste trabalho.
À Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) pela bolsa de estudos de Mestrado.
E por fim, agradeço à UFOP, especialmente à equipe do PPGCC/UFOP pela recep-ção, estrutura, dedicação e pela contribuição na minha formação acadêmica e humana. Especialmente à Mariana e aos professores: Haroldo, Fabrício e David.
Sumário
Lista de Figuras xiii
Lista de Tabelas xvi
Nomenclatura xvii
1 Introdução 1
1.1 Retratos Falados . . . 2
1.1.1 Viewed Sketches . . . 2
1.1.2 Forensic Sketches . . . 3
1.2 Automatização do Reconhecimento Através de Retratos falados . . . 3
1.2.1 Representação de Características . . . 4
1.3 Motivação . . . 5
1.4 Objetivos . . . 5
1.4.1 Objetivo Geral . . . 5
1.4.2 Objetivos Específicos . . . 6
1.5 Contribuições . . . 6
1.6 Publicações . . . 6
1.7 Organização do Texto . . . 7
2.2 Métodos Baseados em Sintetização . . . 9
2.3 Métodos Baseados em Características Locais . . . 11
2.4 Considerações Finais . . . 13
3 Fundamentação Teórica 14 3.1 Filtros de Imagens . . . 14
3.1.1 Gaussiano . . . 15
3.1.2 Diferença de Gaussianas (DoG) . . . 15
3.1.3 Center-Surround Divisive Normalization (CSDN) . . . 16
3.2 Descritores de Imagens . . . 16
3.2.1 Histogram of Oriented Gradients (HOG) . . . 16
3.2.2 Histogram of Averaged Oriented Gradients (HAOG) . . . 17
3.2.3 Scale-Invariant Feature Transform (SIFT) . . . 19
3.2.4 Local Binary Pattern (LBP) . . . 19
3.2.5 Multiscale Local Binary Pattern (MLBP) . . . 21
3.2.6 Local Radon Binary Pattern (LRBP) . . . 21
3.2.7 Gabor Shape (GS) . . . 23
3.3 Análise Multivariada . . . 24
3.3.1 Análise de Componentes Principais (PCA) . . . 24
3.3.2 Análise Discriminante Linear (LDA) . . . 24
3.4 Métricas de Distância . . . 26
3.4.1 Euclidiana . . . 26
3.4.2 Similaridade do Cosseno . . . 26
3.4.3 Chi-quadrado . . . 27
3.5 Considerações Finais . . . 27
4 Métodos 28 4.1 Local Feature-based Discriminant Analysis . . . 28
4.1.1 Análise Discriminante . . . 29
4.1.2 Classificação . . . 30
4.2 Heterogeneous Prototype Framework . . . 31
4.2.1 Prototype Random Subspace . . . 31
4.2.2 Direct Random Subspace . . . 33
4.3 Método Proposto . . . 34
4.3.1 Extração de Descritores . . . 35
4.3.2 Análise Discriminante . . . 35
4.3.3 Classificação . . . 36
4.4 Considerações Finais . . . 36
5 Resultados Experimentais 37 5.1 Base de Dados . . . 37
5.1.1 CUHK Face Sketch Database (CUFS) . . . 37
5.1.2 CUHK Face Sketch FERET Database (CUFSF) . . . 38
5.1.3 Forensic Sketches . . . 39
5.1.4 Galeria Extra . . . 39
5.2 Pré-Processamento . . . 39
5.3 Resultados . . . 40
5.3.1 Avaliação dos Descritores . . . 40
5.3.2 Avaliação dos Métodos . . . 42
6 Conclusões 58
6.1 Trabalhos Futuros . . . 59
Referências Bibliográficas 60
Lista de Figuras
1.1 Exemplo de par de viewed sketch da CUFS Database (Tang and Wang,
2004) . . . 2
1.2 Exemplo de par de forensic sketch (Gibson, 2010). . . 3
2.1 Resultado da reconstrução utilizando as projeções dos coeficientes entre os autoespaços. . . 9
2.2 Pipeline do método de Wang and Tang (2009). . . 10
2.3 Resultado da reconstrução utilizando o método de Wang and Tang (2009). 11 3.1 Ilustração do descritor SIFT (Lowe, 2004). . . 19
3.2 O operador LBP básico (Ahonen et al., 2004). . . 20
3.3 LBP com vizinhança circular com 8 amostragens e raio 2. . . 20
3.4 Ilustração do processo da Transformada de Radon (Kiani Galoogahi and Sim, 2012b). . . 22
3.5 Ilustração do processo de extração do descritor LRBP (Kiani Galoogahi and Sim, 2012b) . . . 22
3.6 Ilustração do processo de extração do descritor Gabor Shape (Kiani Ga-loogahi and Sim, 2012a) . . . 23
3.7 O processo de amostragem randômica de pedaços de imagem. . . 26
4.1 Processo de treinamento do método LFDA (Klare et al., 2011). . . 30
4.2 Processo de reconhecimento do método LFDA (Klare et al., 2011). . . 31
4.4 Processo de reconhecimento do método Kernel Prototype Random Subs-pace (Klare and Jain, 2013). . . 33
4.5 Processo de treinamento do método proposto. . . 35
4.6 Processo de reconhecimento do método proposto. . . 35
5.1 Fotografia e viewed sketch da CUFS database (Tang and Wang, 2004). . . 38
5.2 Fotografia e viewed sketch da CUFSF database (Wang and Tang, 2009). . 38
5.3 Fotografia e retrato falado feito por um artista através de descrição
ver-bal de uma testemunha. Imagens do livro Forensic Art and Illustration
(Taylor, 2010). . . 39
5.4 Curva ROC comparando os descritores utilizando a base CUFS. . . 41
5.5 Curva ROC comparando os descritores utilizando a base CUFSF. . . 41
5.6 Curva ROC comparando os descritores utilizando a base deForensic
Sket-ches. . . 42
5.7 Comparação do método LFDA, VR@FAR=0.1% variando o tamanho do conjunto de treinamento e utilizando 3 métricas de distâncias diferentes na base de dados CUFSF. . . 43
5.8 Comparação entre os métodos, VR@FAR=0.1% variando o tamanho do conjunto de treinamento, utilizando a base CUFSF. . . 44
5.9 Comparação entre os métodos, com os dois modos de pre-processamento, utilizando a base CUFSF. . . 46
5.10 Comparação entre os métodos, com os dois modos de pre-processamento,
utilizando a base de Forensic Sketches. . . 47
5.11 Comparação entre os métodos utilizando a base CUFS e adicionando a galeria extra de 10.000 fotografias. . . 49
5.12 Comparação entre os métodos utilizando a base CUFSF e adicionando a galeria extra de 10.000 fotografias. . . 50
5.13 Comparação entre os métodos utilizando os Forensic Sketches e adicio-nando a galeria extra de 10.000 fotografias. . . 51
5.14 Comparação entre os métodos utilizando a CUFSF para treinar e os
Fo-rensic Sketchespara testar, adicionando a galeria extra de 10.000 fotografias. 52 5.15 Classificação boa, devido a boa qualidade dos retratos falados. . . 53
5.16 Classificação ruim causada pela qualidade dos retratos falados. . . 54
5.17 Exemplos de enganos pelo métodos, motivado por sujeitos muito parecidos na galeria. . . 55
5.1 LFDA utilizando diferentes filtros e descritores, VR@FAR=0.1%
utili-zando a similaridade de cosseno como métrica na base de dados CUFSF. 44
5.2 P-RS+D-RS utilizando diferentes filtros e descritores, VR@FAR=0.1% utilizando a similaridade de cosseno como métrica na base de dados CUFSF. 45
5.3 D-RS utilizando diferentes filtros e descritores, VR@FAR=0.1%
utili-zando a similaridade de cosseno como métrica na base de dados CUFSF. 45
5.4 P-RS utilizando diferentes filtros e descritores, VR@FAR=0.1% utilizando a similaridade de cosseno como métrica na base de dados CUFSF. . . 45
5.5 Comparação entre os métodos utilizando VR@FAR=0.1% nas bases de
dados CUFS, CUFSF eForensic Sketches. . . 48
5.6 Tempo consumido por cada filtro. . . 56
5.7 Tempo consumido na extração de cada descritor. . . 56
5.8 Tempo consumido no treinamento e teste de cada método, variando o tamanho da base de treinamento. . . 57
5.9 Comparação do consumo de tempo total de cada método utilizando 500 pares para treinar e 500 pares para testar. . . 57
Nomenclatura
CUFS CUHK Face Sketch Database
CUFSF CUHK Face Sketch FERET Database
CUHK Chinese University of Hong Kong
FERET Facial Recognition Technology
GS Gabor Shape
HAOG Histogram of Averaged Oriented Gradients
HOG Histogram of Oriented Gradients
LBP Local Binary Pattern
LDA Linear Discriminant Analysis
LFDA Local Feature-based Discriminant Analysis
LRBP Local Radon Binary Pattern
MLBP Multiscale Local Binary Pattern
PCA Principal Component Analysis
SIFT Scale-Invariant Feature Transform
Introdução
Um novo problema de reconhecimento facial que emergiu recentemente é o de associação entre retratos falados e fotografias. Quando um crime é presenciado por uma testemunha, muitas vezes uma descrição verbal das características do criminoso é utilizada por um desenhista da polícia, para desenhar um retrato falado do suspeito. Muitos criminosos são apreendidos graças a esse recurso, pois as pessoas conseguem associar o desenho ao suspeito (Klare and Jain, 2010b). A automatização desse processo ajuda a polícia a diminuir o número de suspeitos a serem avaliados manualmente, assim tornando a identificação mais rápida e menos cansativa.
Nas duas últimas décadas tem-se presenciado um tremendo avanço no reconhecimento facial, os trabalhos desenvolvidos por Turk and Pentland (1991a,b) serviram de alicerce para os mecanismos modernos de reconhecimento facial (Klare and Jain, 2010b). No entanto, devido à grande diferença entre desenhos e fotos, além da falta de conhecimento sobre os mecanismos psicológicos de geração e avaliação dos mesmos, o reconhecimento de suspeitos através de retratos falados torna-se uma tarefa muito mais difícil do que o reconhecimento facial normal com base em fotografias (Wang and Tang, 2009).
Neste trabalho, apresentamos uma nova abordagem para o reconhecimento facial através de retratos falados, criada a partir de estudos sobre as abordagens existentes. Apresentamos as principais contribuições na área, e uma avaliação sobre o desempenho de vários descritores de imagens aplicados ao reconhecimento entre fotografia e retrato falado. Também são feitos testes comparativos entre os métodos existentes utilizando bases de dados em comum, para uma melhor avaliação dos mesmos, e de pequenas variações feitas sobre os mesmos. Além disso, discutimos as principais de dificuldades,
2 Introdução
como por exemplo a escassez e qualidade dos dados.
1.1
Retratos Falados
Retratos falados são desenhos feitos, através de uma descrição verbal de uma vítima ou testemunha, por desenhistas treinados em uma folha de papel branco, utilizando lápis, pincéis, entre outros materiais. São utilizados para identificar suspeitos há mais de 100 anos. Normalmente são exibidos na televisão, publicados em jornais, espalhados nas ruas, de modo que o maior número de pessoas possa vê-los e fazer o reconhecimento do suspeito retratado, para após denunciá-lo à autoridade de segurança para ser feito o reconhecimento perante a testemunha (Taylor, 2010).
1.1.1
Viewed Sketches
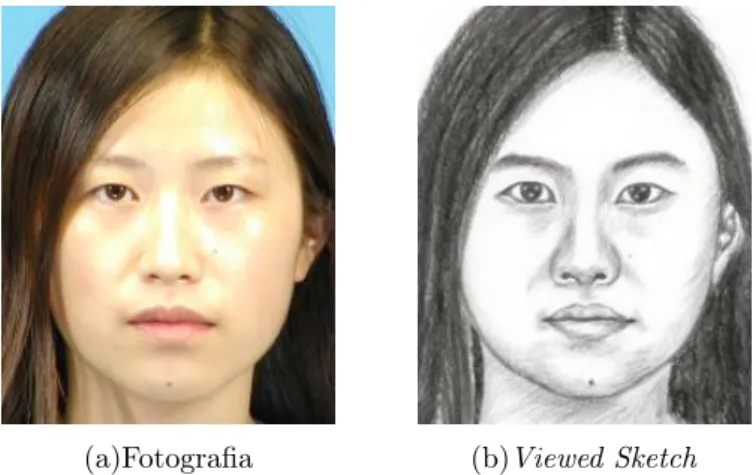
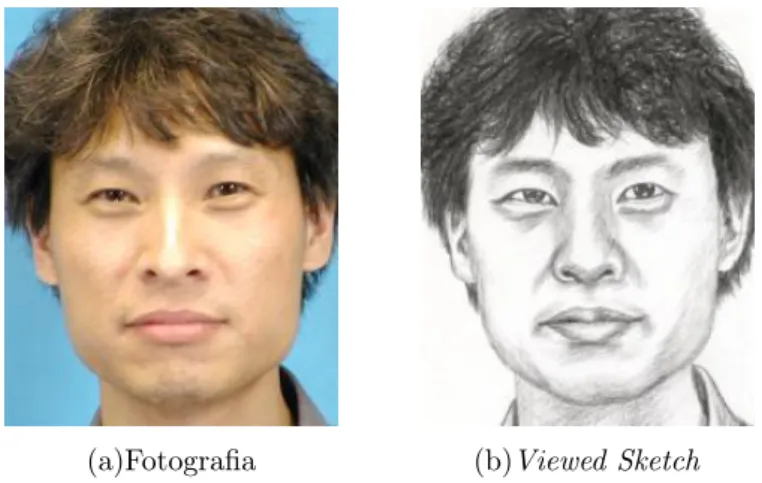
Umviewed sketch não é um retrato falado propriamente dito, e sim um desenho feito por
um artista olhando a fotografia do sujeito, um exemplo de um par fotografia e viewed
sketch é exibido na Figura 1.1. Inicialmente todos os trabalhos no que se diz respeito ao reconhecimento através de retratos falados trabalhavam com esse tipo de desenho, e
até o presente momento servem como benchmarking padrão.
(a)Fotografia (b)Viewed Sketch
1.1.2
Forensic Sketches
São retratos falados feitos por artistas através da descrição de testemunhas, sendo que estas fotos são obtidas após a apreensão e identificação do suspeito, esse tipo de retrato
falado é chamado de forensic sketch. Um exemplo de par de fotografia e forensic sketch
é apresentado na Figura 1.2.
(a)Fotografia (b)Retrato falado
Figura 1.2: Exemplo de par de forensic sketch (Gibson, 2010).
1.2
Automatização do Reconhecimento Através de
Retratos falados
Assim como no reconhecimento facial tradicional, o reconhecimento através de retratos falados também possui várias etapas. A maioria dos métodos seguem os seguintes passos:
• Detectar a face.
• Alinhar a face.
• Normalização da aparência.
• Descrição das características.
• Extração das características.
4 Introdução
O foco principal deste trabalho está na descrição e extração das características co-muns do sujeito, em ambas as modalidades (fotografia e retrato falado).
1.2.1
Representação de Características
Em (Klare and Jain, 2010a) é apresentada uma categorização de características faci-ais, que provê um melhor entendimento e uma padronização nos processos de análise facial. Esta classificação foi criada para ajudar na escolha das características faciais corretas para a tarefa escolhida. As características são divididas em três níveis, que são apresentados abaixo:
Nível 1
É formado por características faciais superficiais, que são facilmente observáveis numa face, por exemplo: cor da pele, gênero, e aparência geral da face. Pode ser extraído de
imagens de baixa resolução, são utilizados métodos comoPrincipal Component Analysis
(PCA) (Eigenface (Turk and Pentland, 1991a,b)) eLinear Discriminant Analysis (LDA)
(Fisherface (Belhumeur et al., 1997)). São utilizados para descriminar grupos a partir do formato do rosto (oval, arredondado, etc.), predominância de traços masculinos ou femininos e etnicidade.
Nível 2
É formado por características que consistem em informações faciais locais, que reque-rem processamento do córtex cerebral, por exemplo: estrutura da face, relação entre os componentes faciais, e detalhes do formato do rosto. São características ideais para serem utilizadas no reconhecimento facial, e requerem observações mais detalhadas das faces. Essas características são extraídas localmente, e descrevem estruturas que são somente relevantes na tarefa de reconhecimento facial. No reconhecimento facial
auto-matizado podem ser usados descritores de imagens, comoScale-Invariant Feature
Trans-form (SIFT) (Klare and Jain, 2010b, Lowe, 2004),Local Binary Pattern (LBP) (Ahonen
et al., 2004, 2006) e Histogram of Oriented Gradients (HOG) (Dalal and Triggs, 2005,
Neste trabalho, características deste nível são utilizadas e analisadas, pois a tarefa consiste no reconhecimento facial, mesmo que as imagens sejam de domínios diferentes (fotografia e retrato falado).
Nível 3
É formado por características que consistem em irregularidades na pele, por exemplo: ci-catrizes, rugas, descoloração, sinais, verrugas, etc. Este tipo de características é utilizado para diferenciar gêmeos e impostores, para tal são necessárias imagens de alta-resolução. Para tal são mapeadas as irregularidades na pele e comparadas.
1.3
Motivação
Nos últimos anos, surgiram vários trabalhos voltados ao reconhecimento entre fotografia e retrato falado. Automatizar essa modalidade de reconhecimento agiliza a identificação de suspeitos, em crimes em que retratos falados são gerados a partir das descrições feitas pelas testemunhas. As técnicas desenvolvidas para essa modalidade de reconhecimento podem ser aplicadas em reconhecimento de imagens obtidas de outras fontes, como imagens térmicas. Além de poder aperfeiçoar o reconhecimento feito através de imagens comuns (espectro visível).
Também é necessário avaliar o desempenho dos descritores e métodos existentes, utilizando bases de dados em comum, tal avaliação se faz necessária pois ainda não existe na literatura. Além de alguns métodos não terem sido avaliados utilizando uma
base de dados realista (forensic sketches).
1.4
Objetivos
1.4.1
Objetivo Geral
• Avaliar o desempenho dos descritores e métodos existentes para reconhecimento
6 Introdução
1.4.2
Objetivos Específicos
• Avaliar o impacto do pré-processamento das imagens no desempenho dos métodos.
• Medir o impacto do tamanho do conjunto de treinamento.
• Efetuar os experimentos utilizando uma grande base de dados.
• Documentar e disponibilizar a implementação dos descritores e métodos.
1.5
Contribuições
• É proposta uma nova abordagem para o reconhecimento facial através de retratos
falados, mais rápida, e que supera os resultados dos métodos atuais, criada a partir de estudos e adaptações sobre os métodos existentes.
• É feita uma avaliação sobre os descritores e os principais métodos em condições
justas e utilizando três bases de dados em comum, tal avaliação até o momento não existia na literatura.
• A implementação dos métodos e descritores foi feita em C++ utilizando a
bibli-oteca OpenCV 2.4.8 (Bradski, 2000) e todo o código está disponível em https:
//github.com/estranho/facialSketchRecognition.
1.6
Publicações
Resultados parciais desta pesquisa foram publicados em conferências, e seguem abaixo:
• Silva, M. A. A., Cámara-Chávez, G. and Menotti, D.: 2013, Photo-sketch
recogni-tion: Eigentransformation method,International Conference on Image Processing,
Computer Vision, and Pattern Recognition (IPCV).
Neste primeiro trabalho implementamos e avaliamos o método Eigentransformation
• Silva, M. A. A. and Cámara-Chávez, G.: 2013, Face sketch-photo recognition,
Workshop of Works in Progress (WIP) in XXVI Conference on Graphics, Patterns and Images (SIBGRAPI 2013), Arequipa, Peru.
Neste trabalho apresentamos a proposta do que se tornaria o trabalho desenvolvido na pesquisa.
• Silva, M. A. A. and Cámara-Chávez, G.: 2014, Face sketch recognition from local
features,XXVII Conference on Graphics, Patterns and Images (SIBGRAPI 2014),
Rio de Janeiro, Brasil.
Neste último trabalho apresentamos os resultados obtidos durante a pesquisa, basi-camente é um resumo desta dissertação.
1.7
Organização do Texto
Neste capítulo foram apresentadas as consideracões iniciais sobre o reconhecimento facial através de retratos falados e da aplicacão do mesmo no mundo real. Foram também apresentadas a justificativa e esclarecidos os objetivos deste trabalho. A estrutura do texto a seguir está organizada da seguinte forma:
No Capítulo 2 está a revisão bibliográfica, onde são apresentadas as principais abor-dagens da literatura, incluindo as que foram selecionadas para implementação e compa-ração neste trabalho.
No Capítulo 3, está a fundamentação teórica, onde são apresentados os detalhes utilizados neste trabalho.
No Capítulo 4 são apresentados os principais métodos para o reconhecimento facial por meio de retratos falados, além do método proposto.
No Capítulo 5, são descritas as bases de dados que foram utilizadas nos testes. Tam-bém são apresentados os resultados dos testes através de tabelas e gráficos para compa-ração. E é realizada uma discussão sobre os resultados dos métodos avaliados.
Capítulo 2
Estado da Arte
Neste capítulo são apresentados os trabalhos mais significantes da área de reconheci-mento facial através de retratos falados. Estes trabalhos podem ser divididos em dois grupos: as abordagens baseadas em síntese e as abordagens baseadas em características (Choi et al., 2012, Kiani Galoogahi and Sim, 2012c).
2.1
Introdução
As abordagens baseadas na síntese propõem sintetizar pseudo-fotos a partir dos retratos falados (ou vice-versa), para assim efetuar o reconhecimento facial na mesma modali-dade, podendo inclusive utilizar qualquer algoritmo de reconhecimento facial. O ponto fraco dessa abordagem, é que a acurácia é muito dependente da qualidade do resultado da sintetização, que é uma tarefa bem mais difícil do que o problema do reconhecimento em si.
Já nas abordagens baseadas em características, o reconhecimento é efetuado dire-tamente, as imagens são representadas por descritores de características e podem ser
utilizados métodos, como aLinear Discriminat Analysis (LDA), que aumentam o poder
discriminativo das características comuns aos indivíduos em ambos domínios (fotogra-fia e retrato falado). Assim temos um mapeamento dos pares em uma representação comum, que não é necessariamente uma das duas modalidades, e sim um espaço inter-mediário. Os métodos que utilizam esse tipo de abordagem são mais simples e superam os resultados dos métodos baseados na síntese.
A grande maioria dos trabalhos utilizam viewed sketches para validar e comparar
seus resultados. Klare et al. (2011) foi o primeiro a utilizar forensic sketches, porém
há dificuldades na obtenção de tal base de dados, devido a disponibilidade, qualidade e quantidade. Assim somente os trabalhos de Klare et al. (2011), Klare and Jain (2013) as utilizam.
2.2
Métodos Baseados em Sintetização
Os primeiros trabalhos desenvolvidos no que se diz respeito à correspondência entre fotos e retratos falados foram desenvolvidos por Tang and Wang (2002, 2003, 2004). As primeiras abordagens usavam uma transformação linear global para converter um retrato falado em uma fotografia, ou vice-versa, assim reduzindo a diferença entre eles para poder reconhecê-los. Essa conversão é baseada no método das autofaces, trabalho desenvolvidor por Turk and Pentland (1991a,b), que é um dos métodos clássicos de reconhecimento facial. A conversão se dá através da projeção dos coeficientes no espaço dos autovetores de um conjunto no outro. Na Figura 2.1 é exibido o resultado da conversão através deste método.
(a)Viewed Sketch (b)Fotografia original (c)Fotografia
reconstruída a partir do
viewed sketch
Figura 2.1: Resultado da reconstrução utilizando as projeções dos coeficientes entre os autoespaços.
Na sequência, Liu et al. (2005) apresentam uma abordagem em que retratos falados são sintetizados preservando a geometria entre fotografia e retratos falados, inspirado
pela idéia do algoritmo, de aprendizagem não-supervisionada,Locally Linear Embedding
10 Estado da Arte
sobrepostos, para sintetizar um retrato falado a partir de uma foto são escolhidos k
pedaços por região, que melhor reconstrói o sujeito no outro domínio, observando a geometria local. Em seguida é utilizado o algoritmo LLE para escolher os pedaços levando em consideração a geometria local e a sobreposição, depois é utilizado uma versão modificada do LDA para fazer o reconhecimento.
No trabalho de Wang and Tang (2009), os autores propõem um novo método para a síntese e reconhecimento de fotos e retratos falados utilizando um modelo de campos ale-atórios de Markov (MRF), semelhante à abordagem de Liu et al. (2005). Primeiramente todas as imagem são divididas em regiões quadradas e sobrepostas. Para o treinamento é necessário um conjunto de fotos que possuam seus respectivos retratos falados, assim
selecionando osk pedaços mais parecidos para formar a imagem sintética, formada pelos
retalhos das imagens usadas no treinamento. O par desenho-foto é computado utilizando
um modelo de Markov Random Field (MRF), e a seleção da melhor combinação para
a reconstrução é feita utilizando o algoritmo Belief Propagation (Yedidia et al., 2001).
Esse processo é ilustrado na Figura 2.2. A transformação de uma foto em desenho (ou o inverso) reduz significamente a diferença entre eles para o reconhecimento. Após a transformação, a princípio, a maioria do algoritmos de reconhecimento facial pode ser aplicada diretamente. Esse método pode produzir reconstruções não tão boas, como é demonstrado na Figura 2.3. Além deste, outros trabalhos, como Gao et al. (2008) e Zhang et al. (2011) utilizam uma abordagem semelhante.
(a)Imagem dividida em
sub-regiões
(b)As k sub-regiões mais similares são escolhidas.
(c)Alimentando uma rede Markoviana.
(a)Viewed Sketch (b)Fotografia original (c)Fotografia
reconstruída a partir do
viewed sketch
Figura 2.3: Resultado da reconstrução utilizando o método de Wang and Tang (2009).
2.3
Métodos Baseados em Características Locais
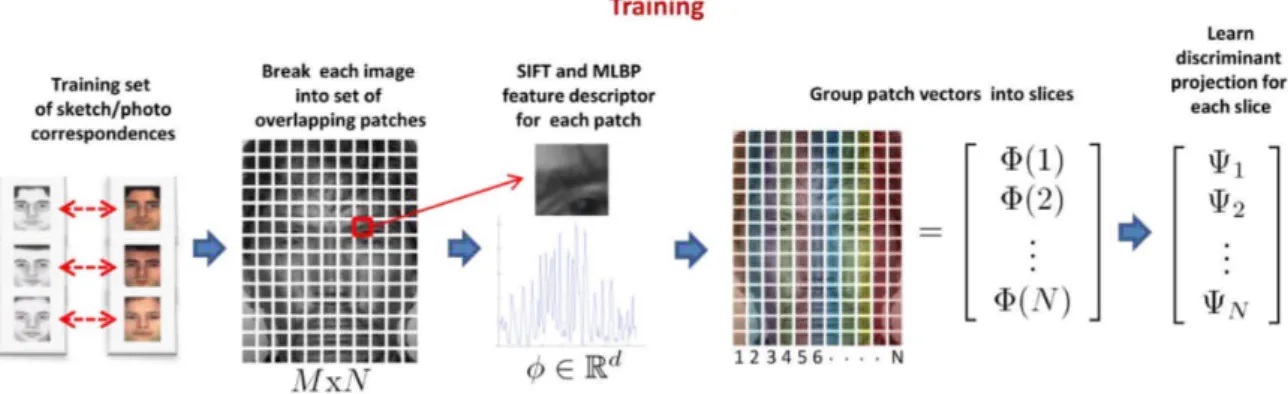
No trabalho de Klare and Jain (2010b) é apresentado um método, baseado em caracte-rísticas locais, para reconhecimento facial através de retrato falado. Esse é o primeiro método conhecido a utilizar características locais para efetuar o reconhecimento entre as duas modalidades. Nessa abordagem, as imagens são divididas em sub-regiões, do mesmo tamanho e sobrepostas. Para cada sub-região um descritor SIFT de 128 dimen-sões é extraído, e a representação da imagem consiste na concatenação dos descritores de todas as sub-regiões. O reconhecimento direto é feito através de distância euclidi-ana. Depois este método foi aperfeiçoado em Klare et al. (2011), adicionando mais um descritor e uma análise discriminante linear para reduzir a diferença entre fotografias e retratado falado.
As pesquisas publicadas até o momento focavam na identificação de desenhos feitos
por artistas vendo a foto (viewed sketches) (Klare and Jain, 2010b, Liu et al., 2005,
Tang and Wang, 2003, 2004, Wang and Tang, 2009). Mas não é esse tipo de cenário que encontramos no mundo real. No trabalho de Klare et al. (2011) é apresentado um
framework chamadoLocal Feature-based Discriminant Analysis (LFDA), onde cada foto
e desenho é representado através de descritores de características SIFT eMultiscale local
12 Estado da Arte
Vários trabalhos vêm apresentando seus próprios descritores, denominados como in-variantes ao domínio (fotografia e retrato falado). Bhatt et al. (2010) apresentam um algoritmo que extrai informações locais em diferentes níveis de resolução, utilizando uma pirâmide laplaciana. O algoritmo extrai características de cada nível da pirâmide
uti-lizando um descritor proposto pelo autor, o Extended Uniform Circular Local Binary
Patterns (EUCLBP), uma variante do LBP (Ahonen et al., 2004). O reconhecimento é
feito utilizando a distânciaχ2, utilizando pesos que são encontrados utilizando um
Algo-ritmo Genético para cada sub-região. No trabalho de Zhang et al. (2011) é apresentado um novo descritor facial baseado na codificação da teoria da informação, o descritor
Coupled Information Theoretic Encoding (CITE). Este descritor é utilizado para cap-turar estruturas faciais locais discriminantes, que são efetivas para o reconhecimento de retratos falados. O reconhecimento é feito utilizando um classificador PCA + LDA (Belhumeur et al., 1997) para diminuir a dimensão e aumentar o poder discriminante e no final é calculada a distância euclidiana para indicar a similaridade.
Kiani Galoogahi and Sim (2012c) apresentam um novo método, em que fotografias e retratos falados são representados por um novo descritor, baseado no descritor HOG, o Histogram of Averaged Oriented Gradients (HAOG). A vantagem do HAOG está em reduzir as diferenças entre as modalidades, fotografia e retrato falado, na fase de extração das características. A medida de dissimilaridade adotado nessa abordagem é a distância
χ2.
Em outra abordagem, (Kiani Galoogahi and Sim, 2012b) propõem mais um novo descritor facial para fazer o reconhecimento direto entre as duas modalidades, esse novo
descritor é chamado de Local Radon Binary Pattern (LRBP). O descritor LRBP é
ins-pirado no fato que o formato do rosto tanto nas fotos quanto nos retratos falados de um mesmo sujeito é similar, mesmo que no retrato falado possa haver algum exagero feito pelo artista. As características da face são extraídas transformando a imagem em um espaço de Radon. Então micro-informações do formato do rosto são extraídas no novo espaço, codificadas através do LBP. Finalmente, LRBP é computado pela concatenação dos histogramas dos LBPs. Com o objetivo de capturar tanto informações locais quanto globais do formato da face, LRBP é extraído em uma pirâmide multi-resolução. Por fim,
a distânciaχ2, usando pesos para cada nível da pirâmide, é utilizada para medir o grau
de similaridade entre os pares.
Kiani Galoogahi and Sim (2012a) apresentam mais um novo descritor invariante a
modalidade (fotografia/retrato falado), chamado de Gabor Shape. Inicialmente filtros
armazenando as magnitudes de cada pixel. No passo seguinte, as matrizes de magnitude são divididas em sub-regiões de mesmo tamanho e não sobrepostas. Cada sub-região é então representada por um histograma obtido atráves da transformada de Radon. Os histogramas de todas as sub-regiões são concatenados formando o Gabor Shape. Por
fim, a distância χ2 é utilizada para efetuar o reconhecimento entre os pares.
Recentemente foi apresentado por Klare and Jain (2013) uma nova abordagem, para o reconhecimento facial heterogêneo, que engloba também o reconhecimento facial através de retratos falados. Este método utiliza uma representação não-linear de similaridade
através de kernels (Balcan et al., 2006) para efetuar a análise e o reconhecimento de
fontes diferentes, e para tal necessita de pares de treinamento de sujeitos das fontes de-sejadas. Diferente dos métodos anteriores, onde os descritores são invariantes nas duas modalidades, este método utiliza os descritores que são mais efetivos em cada moda-lidade. A acurácia do sistema é melhorada ao utilizar um framework de amostragem randômica (Wang and Tang, 2006) em conjunto com a LDA.
2.4
Considerações Finais
Capítulo 3
Fundamentação Teórica
Neste capítulo são apresentados os fundamentos teóricos necessários para compreensão do trabalho. São explicados os métodos de filtragem, representação e extração de ca-racterísticas. Também é apresentado um breve resumo sobre os métodos utilizados na comparação com nossa nossa proposta.
3.1
Filtros de Imagens
Vieira et al. (2007) define filtros de imagens, como: algoritmos capazes de obter novas imagens a partir de transformações lógicas e/ou matemáticas dos dados de entrada. Podem se apresentar como um conjunto de instruções, tanto na linguagem de circuitos eletrônicos como em um programa de computador. O uso de filtros é essencial na cadeia de processamento e análise de imagens, pois eles permitem combater elementos nocivos à compreensão das informações, como por exemplo ruídos e outros artefatos, e realçar aquelas características de interesse como, por exemplo, bordas.
O conceito de filtragem tem suas raízes na utilização da transformada de Fourier para o processamento de sinais, trabalhando assim no domínio da frequência. Porém a filtragem pode ser feita no domínio espacial, diretamente sobre os pixels de uma imagem. É utilizado o termo filtragem espacial, para diferenciar esse método da tradicional filtra-gem no domínio da frequência. O processo consiste em simplesmente mover a máscara do filtro por todos os pontos de uma imagem, e para cada ponto uma resposta para o filtro é calculada. A resposta é dada pela soma dos produtos do coeficientes do filtro pelos pixels correspondentes na imagem, dentro da area coberta pela máscara. A
gem espacial linear é frequentemente referida como “convolução de uma máscara com uma imagem”. Da mesma forma que as máscaras dos filtros são chamadas de máscaras
de convolução, ou até mesmo como kernels (Gonzalez and Woods, 2002). A operação
de convolução é definida na Equação 3.1.
(f ∗g)(x, y) =
∞
X
n1=−∞ ∞
X
n2=−∞
f(x−n1, y−n2)·g(n1, n2). (3.1)
3.1.1
Gaussiano
O filtro Gaussiano tem sido amplamente utilizado em aplicações de processamentos de imagens para remover ruídos, mas não preserva as arestas uma vez que não considera a diferença das intensidades. Ele possui dois parâmetros, a dimensão da janela e um valor para o desvio padrão máximo. É um filtro passa-baixa, isto é, suaviza as imagens.
O quanto a imagem será suavizada está relacionado ao desvio padrão, σ, isto é, quanto
maior o σ, mais a imagem é suavizada.
O filtro Gaussiano bidimensional,G é definido na Equação 3.2.
Gσ(x, y) = I∗
1
2πσ2e
−(x2+y2)/(2σ2)
. (3.2)
3.1.2
Diferença de Gaussianas (DoG)
Tan and Triggs (2007) demonstraram que o filtro de Diferenças de Gaussianas (DoG) melhora os resultados no reconhecimento facial na presença de variância de iluminação. A DoG é obtida através da subtração da imagem original convoluida com uma gaussiana
de variânciaσ2
2 da imagem original convoluída com uma gaussiana de variância σ21, onde
σ2 > σ1. O filtro DoG pode ser utilizado para aumentar a visibilidade, realçando as
bordas e pequenos detalhes nas imagens.
O filtro da Diferença das Gaussianas bidimensional, Γ é definido na Equação 3.3 e
16 Fundamentação Teórica
Γσ1,σ2(x, y) = I∗
1
2πσ2
1
e−(x2+y2)/(2σ2
1)−I∗ 1
2πσ2
2
e−(x2+y2)/(2σ2
2). (3.3)
Γσ1,σ2(x, y) = I∗
1
2πσ2
1
e−(x2+y2)/(2σ2
1)− 1
2πσ2
2
e−(x2+y2)/(2σ2
2)
. (3.4)
3.1.3
Center-Surround Divisive Normalization
(CSDN)
Meyers and Wolf (2008) introduziram o filtro CSDN junto com seu framework de reco-nhecimento facial biologicamente inspirado. O filtro CSDN divide o valor de cada pixel
pela média dos valores dos pixels numa vizinhança s×s ao redor do pixel. Segundo
Klare and Jain (2013), a natureza não-linear do filtro CSDN pode ser vista como um complemento para o filtro da Diferença de Gaussianas (DoG).
3.2
Descritores de Imagens
Em processamento de imagens, descritores são usados para representar características no conteúdo da imagem. Descrevem elementos como forma, cor, textura, orientação, entre outros (Pratt, 2007). Geralmente, os descritores de imagens fornecem uma des-crição compacta sobre a imagem, tornando mais prática a sua análise do que trabalhar diretamente sobre os pixels.
3.2.1
Histogram of Oriented Gradients
(HOG)
O descritor HOG é uma descritor de imagem invariante a rotação, que tem sido am-plamente utilizado em diferentes problemas de visão computacional (Dalal and Triggs, 2005).
O processo de extração do descritor HOG é apresentado a seguir. Dada uma imagem
em tons de cinza,I(x, y)é a intensidade de um pixel com coordenadas(x, y)na imagem
I, os vetores de gradiente podem ser calculados a partir das derivadas parciais dos valores
das intensidades das imagens (Equação 3.5).
gx(x, y)
gy(x, y)
=
∂I(x, y)
∂x
∂I(x, y)
∂y
. (3.5)
A partir dos vetores de gradiente dados por [gx, gy]T, a orientação ϕ ∈ [−π, π) e a
magnitude ρ∈R+ são definidas nas Equações 3.6 e 3.7 respectivamente.
ϕ= tan−1
gy
gx
, (3.6)
ρ= (g2x+g2y)0.5. (3.7)
A partir desses valores é criado um histograma, onde cadabin representa uma faixa de
orientações, e o valor dele corresponde a soma cumulativa das magnitudes dos vetores que possuem uma determinada orientação. Neste trabalho é utilizada esta versão simplificada
do HOG, que será extraído a partir de uma grade fixa, utilizando uma janela de 32×32
pixels. Ao final, esse histograma é normalizado.
3.2.2
Histogram of Averaged Oriented Gradients
(HAOG)
Kiani Galoogahi and Sim (2012c) propoem um novo descritor de imagem, voltado ao
reconhecimento facial, chamado deHistogram of Averaged Oriented Gradients (HAOG).
18 Fundamentação Teórica
fotografias e retratos falados, pois dá ênfase à características de alto-contraste.
É calculado através da média dos gradientes de uma determinada região, porém como pixels vizinhos podem possuir orientação opostas, em regiões de borda, acabariam se anulando. Para resolver esse problema, é proposto dobrar o valor da orientação antes
de calcular a média. Se os ângulos ϕ e (ϕ+π) são dois ângulos opostos, ao dobrar os
seus valores teremos 2ϕ e (2ϕ+ 2π) = 2ϕ, que possuem a mesma direção. Na prática,
2ϕ é a orientação do vetor do gradiente quadrado [gsx, gsy] (Bazen and Gerez, 2002),
que também possui a magnitude elevada ao quadrado. De acordo com as indentidades trigonométricas na (Equação 3.8), temos:
gsx gsy =
ρ2cos 2ϕ
ρ2sin 2ϕ
=
ρ2(cos2ϕ−sin2ϕ)
ρ2(2 sinϕcosϕ)
=
g2
x−g2y
2gygx
. (3.8)
A média do gradiente quadrado para cada pixel numa região de vizinhança localW,
é calculado como na Equação 3.9.
¯ gsx ¯ gsy = P Wgsx P
W gsy
= P
W(g2x−gy2) P
W2gygx
. (3.9)
Finalmente, a orientação e a magnitude para cada pixel são definidas nas Equações 3.10 e 3.11, respectivamente.
¯
ϕ = tan−1
¯ gsy ¯ gsx
,ϕ¯∈[−π, π), (3.10)
¯
ρ=X
W
(gsy2 +gsx2 )0.5 =X
W
ρ2. (3.11)
3.2.3
Scale-Invariant Feature Transform
(SIFT)
O descritor SIFT (Lowe, 1999, 2004) tem sido usado efetivamente no reconhecimento facial. No reconhecimento facial, descritores SIFT são extraídos a partir de uma grade
fixa, não sendo utilizada a detecção dos pontos de interesse (keypoints).
Assim como o descritor HOG, o descritor SIFT também trabalha com a orientação e magnitude dos gradientes. Uma função Gaussiana é utilizada para dar pesos à magnitude
dos gradientes, com σ igual à metade da largura da região. Assim os valores centrais na
janela possuem maior peso na construção do descritor. O descritor consiste em dividir
a imagem em 4×4 regiões e para cada uma extrair um histograma com 8 bins (faixas
de orientações), totalizando em um histograma final de 128 elementos. Na Figura 3.1 é
exibida uma ilustração simplificada do processo (nesse caso a região é dividida em2×2
áreas).
Figura 3.1: Ilustração do descritor SIFT (Lowe, 2004).
3.2.4
Local Binary Pattern
(LBP)
O descritor LBP (Ojala et al., 2002) possui um dos melhores desempenho entre os des-critores de textura e tem sido amplamente utilizado em várias aplicações. Ele provê um alto poder discriminativo e entre suas principais vantagens estão, sua invariância a luminosidade e eficiência computacional. A ideia de utilizar o LBP para o reconheci-mento facial é motivada pelo fato de que faces podem ser vistas como uma composição de micro-padrões que podem ser bem descritos por esse descritor (Ahonen et al., 2006).
20 Fundamentação Teórica
ilustrado na Figura 3.2. Após a extração do descritor LBP de cada pedaço, todos os histogramas são concatenados, formando um único histograma.
s(x) =
1, x≥0
0, x < 0 , (3.12)
LBPP,R=
P−1
X
p=0
s(gp −gc)2P. (3.13)
Figura 3.2: O operador LBP básico (Ahonen et al., 2004).
Na Figura 3.3 é demonstrada a ilustração de uma variação do LBP, que utiliza uma vizinhança circular e onde o raio pode variar.
3.2.5
Multiscale Local Binary Pattern
(MLBP)
No trabalho de Klare et al. (2011), o descritor LBP é extendido para descrever uma face em múltiplas escalas através da combinação de descritores LBP com vizinhaças circulares
computados com os raios r ∈ {1,3,5,7}, concatenados em um único histograma.
3.2.6
Local Radon Binary Pattern
(LRBP)
O descrito LRBP foi desenvolvido por Kiani Galoogahi and Sim (2012b) para ser utili-zado no reconhecimento facial através de retratos falados. É inspirado no fato de que, diferentemente da textura, o formato do face é similar tanto no retrato falado quanto na fotografia correspondente, mesmo quando há distorções ou exageramento de caracterís-ticas feitos pelo artista.
O descritor LRBP é extraído da seguinte maneira, e ilustrado na Figura 3.5: primeiro a imagem é dividida em regiões não sobrepostas. Para cada sub-região é computada uma nova imagem através da transformada de Radon. E para cada imagem transformada, é extraído um descritor LBP. Finalmente o descritor LRBP é construído a partir da concatenação de todos os histogramas.
Transformada de Radon
A transformada de Radon computa projeções da intensidade da imagem sobre linhas
traçadas. Cada linha é definida por sua distância ao centro da imagem s e o ângulo θ
que forma com o eixo das abscissas, como é ilustrada na Figura 3.4. Dada uma imagem
f(x, y) ⇒g e uma linha representada por l(s, θ), a projeção da imagem sobre a linha l
é computada como na Equação 3.14.
Rθ,s[f(x, y)] = Z
l
f(x, y)∂l. (3.14)
Sendo que todos os pontos na linha l satisfazem a Equação 3.15. Temos que a
Equação 3.14 pode ser reescrita como a Equação 3.16, onde δ() é a função Delta de
22 Fundamentação Teórica
Figura 3.4: Ilustração do processo da Transformada de Radon (Kiani Galoogahi and Sim, 2012b).
xsin (θ)−ycos (θ)−s = 0, (3.15)
Rθ,s[f(x, y)] = ZZ
f(x, y)δ(xsin (θ)−ycos (θ)−s)∂x∂y. (3.16)
3.2.7
Gabor Shape
(GS)
O descritor Gabor Shape foi proposto por Kiani Galoogahi and Sim (2012a), como um
descritor invariante a modalidade (fotografia e retrato falado). Uma visão resumida do processo de extração é ilustrada na Figura 3.6, e segue os seguintes passos: Um banco de filtros de Gabor é criado para cada imagem, computando a sua magnitude. Cada magnitude é dividida em regiões não sobrepostas. Cada região é então representada por um conjunto de histogramas obtidos através dos valores da transforma de Radon. Todos
os histogramas são concatenados, formando o descritor Gabor Shape.
Filtros de Gabor
Filtros de Gabor tem sido utilizados para extração de características faciais (Zhang et al., 2005), devido a sua excelente capacidade em salientar aspectos visuais, tais como
localização, orientação e frequência espacial (Liu and Wechsler, 2002). Okernel utilizado
pelo filtro de Gabor é definido pela Equação 3.17.
ψµ,ν(z) =
kkµ,νk2
σ2 e
−kkµ,νk
2kzk2 2σ2
h
eikµ,νz−e−σ2
2
i
. (3.17)
Na construção do banco de filtros de Gabor, são utilizados 40 filtros, variando os parâmetros µ ∈ {0, . . . ,7} e ν ∈ {0, . . . ,4}, que representam a orientação e a escala respectivamente.
24 Fundamentação Teórica
3.3
Análise Multivariada
A análise multivariada engloba várias técnicas, que visam ressaltar características ou até mesmo identificar similaridades em vetores de alta dimensão.
3.3.1
Análise de Componentes Principais (PCA)
Dado um vetorn-dimensional, a Análise de Componentes Principais (PCA) (Fukunaga,
1990) pode ser usada para encontrar um subespaço vetorial cujas bases correspondam
as direções de maior variância no espaço original. Seja W a matriz de transformação
que mapeia o espaço n-dimensional original em um subespaço m-dimensional, onde
normalmente m << n. Os novos vetores yi ∈ Rm são definidos por yi = WTxi, i =
1, . . . , N. As colunas de W são os auto-vetores vi, obtidos através da resolução da
decomposição de λivi = Qvi, onde Q = XXT é a matriz de covariância e λi é o
auto-valor associado ao auto-vetor vi (Martínez and Kak, 2001). O tamanho da dimensão
m é definido ao escolher a quantidade de auto-vetores que irão compor a matriz de
transformação W, sendo escolhidos pela ordem descrescente do tamanho do auto-valor
correspondente.
3.3.2
Análise Discriminante Linear (LDA)
A Análise Discriminante Linear (LDA) (Fukunaga, 1990) procura pelos vetores que me-lhor discriminam as classes. Dado amostras de treinamento de vetores multi-dimensionais, cada um possuindo o rótulo da classe a que pertence, a LDA irá criar a combinação li-near que melhor discrimina cada classe. Isso é feito através de duas medidas diferentes: a primeira é matriz de dispersão intra-classe, que é dada por:
Sw =
c X
j=1 Nj
X
i=1
(xji −µj)(xji −µj)T, (3.18)
onde xji é a i-ésima amostra da classe j, µj é o vetor médio da classe j, c é o número
de classes, e Nj é o número de amostras da classe j. A segunda medida é chamada de
Sb = c X
j=1
(µj −µ)(µj−µ)T, (3.19)
onde µrepresenta a o vetor médio de todas as classes juntas.
O objetivo na LDA é maximizar a dispersão extra-classe e ao mesmo tempo minimizar a dispersão intra-classe. Um forma de se fazer isto é maximizando a razão dada por
det|Sb|
det|Sw|
. (3.20)
SeSw for uma matriz não-singular, esta razão pode ser maximizada quando os vetores
colunas que formam a matriz de projeção S são autovetores da decomposição deS−1
w Sb.
Será possível extrair no máximo c−1 auto-vetores válidos, assim o limite superior da
dimensão da projeção será igual à c−1. Além disso para aplicar a LDA é necessário,
pelo menosn+camostras para garantir queSw não será uma matriz singular, ondené a
dimensão espaço original. Como obtern+camostras pode ser impossível para a maioria
das aplicações, Belhumeur et al. (1997) propuseram o uso de um espaço intermediário para resolver este problema. Assim, é proposto utilizar a PCA para transformar o
espaço n-dimensional em um espaço intermediário m-dimensional e por fim aplicar a
LDA gerando um espaço final f-dimensional.
Amostragem Randômica
Wang and Tang (2006) propuseram uma abordagem para melhorar o desempenho dos métodos de reconhecimento facial que trabalham com geração de subespaços, como a LDA. Esses métodos geralmente sofrem com dois problemas: (1) o tamanho do conjunto de treinamento é pequeno comparado com a dimensão do vetor de características, (2) o desempenho é sensível a dimensão do subespaço. Ao invés de trabalhar possuindo um
único subespaço, eles propõem a utilização de várias bags selecionadas aleatoriamente.
O processo é ilustrado na Figura 3.7.
Para cada bag é executado o processo de treinamento e teste. Dessa forma,
concaten-26 Fundamentação Teórica
ção da projeção de cada bag.
Figura 3.7: O processo de amostragem randômica de pedaços de imagem é ilustrado acima. (a) Todos os pedaços da imagem. (b), (c) e (d) são exemplos de escolhas randômicas (Klare and Jain, 2013).
3.4
Métricas de Distância
Neste trabalho, utilizamos três diferentes métricas de distância para efetuar a compara-ção entre as fotos e retratos falados. Estas métricas são detalhadas abaixo:
3.4.1
Euclidiana
A distância euclidiana é a distância mais popular de todas. É utilizada nas mais diversas áreas da engenharia e ciência. Seguindo a definição básica, a distância euclidiana é definida por
d(x, y) =sX
k
(xk−yk)2. (3.21)
3.4.2
Similaridade do Cosseno
Os resultados da similaridade do cosseno é limitada ao intervalo [−1,1], e é definida nas
Equações 3.22 e 3.23. Dois vetores com as mesma orientação possuem o resultado igual
à 1, já dois vetores opostos possuem similaridade igual à−1, independentemente da sua
a·b =kakkbkcos(θ), (3.22)
sim(x, y) = cos(θ) = A·B
kAkkBk =
X
k
xk∗yk
sX
k
(xk)2 ∗
sX
k
(yk)2
. (3.23)
3.4.3
Chi-quadrado
A distância χ2 (Chi-quadrado) foi originalmente criada para calcular a distância entre
histogramas, que são estritamente positivos. Adaptamos esta distância para que pos-samos aplicá-la para comparar vetores, que possuem valores positivos e negativos, esta distância é definida por
χ2(x, y) = X
k
(xk−yk)2
(|xk|+|yk|)
. (3.24)
3.5
Considerações Finais
Capítulo 4
Métodos
Neste capítulo são apresentados os principais métodos para o reconhecimento facial
por meio de retratos falados. Primeiro apresentamos os métodos Local Feature-based
Discriminant Analysis (Klare et al., 2011) eHeterogeneous Prototype Framework (Klare and Jain, 2013), ambos implementados e comparados no próximo capítulo. E por último, apresentamos o método proposto, que foi determinado ao se estudar os dois primeiros métodos e ao se o utilizar o que eles oferecem de melhor.
4.1
Local Feature-based Discriminant Analysis
No trabalho de Klare et al. (2011), é proposto um framework chamado Local
Feature-based Discriminant Analysis (LFDA). Neste framework fotos e retratos falados são re-presentado através de descritores de características SIFT e MLBP. No processo de trei-namento os pares, formados por um retrato falado e a fotografia correspondente, são submetidos ao LFDA. Primeiramente, todas as imagens são divididas em sub-regiões sobrepostas, e para cada região é extraído um descritor SIFT e um MLBP, e ambos são concatenados. A partir de então são calculadas funções discriminantes baseadas nas fatias verticas dos retratos falados e das fotos, como é ilustrado na Figura 4.1. Essas funções discriminantes tem como objetivo projetar as características de ambas as moda-lidades em um espaço intermediário, onde o retrato falado e a fotografia correspondente são projetados próximos um do outro. E ao mesmo tempo, tenta-se afastar a projeção dos outros indíviduos.
4.1.1
Análise Discriminante
Primeiro, é utilizado um conjunto de treinamento formado por n pares de retratos
fa-lados e sua fotografia correspondente. O vetor de descritores do retrato falado é
repre-sentado por Φi
s = F(Isi) e o da fotografia por Φip = F(Ipi). As matrizes para o
treina-mento são construídas combinando esses vetores de características como vetores colunas,
Xs = [(Φ1
s)T(Φ2s)T . . .(Φns)T] para os retratos falados, Xp = [(Φ1p)T(Φ2p)T . . .(Φnp)T] para
as fotos, e X = [(Φ1
s)T . . .(Φns)T(Φp1)T . . .(Φnp)T] para retratos falados e fotografias
com-binados.
O passo seguinte no LFDA consiste em separar os vetores de características das ima-gens em vários sub-vetores, que representam fatias verticais. Dado que a quantidade
de sub-regiões em que a imagem original foi dividida é de M×N 1, criamos uma fatia
vertical ao dividir a matriz original em N matrizes. Agora, com os vetores de
caracte-rísticas separados em fatias, as matrizes de treinamento agora são Xs
k, X p
k e Xk, com
k = 1. . . N.
Para cada fatiaknós reduzimos a dimensionalidade da matrizXk usando a matriz de
projeção da PCA,Wk, que preserva os 100 primeiros autovetores. A análise discriminante
procede gerando o vetor médio das projeções:
Yk =WkT(Xks+X
p
k)/2 (4.1)
Então, as instâncias de treinamento de retratos falados e fotografias são centralizadas
utilizando esse vetor médio Yk.
e
Xks=WkTXks−Yk
e
Xkp =WkTXkp−Yk
(4.2)
Para reduzir as variações intrapessoais entre retrato falado e fotografia, uma
transfor-mação por branqueamento (em inglês whitening transform) é aplicada. Recombinamos
as instâncias de treinamento em Xek = [XeksXe p
k]. Uma PCA é aplicada em Xek e a matriz
1Como as imagens possuem tamanho igual a 200×250pixels e as sub-regiões são de32×32 pixels
30 Métodos
de projeção da PCAVek ∈R100×100 retém toda a variância de Xek. Seja Λk ∈R100×100 a
matriz diagonal com os auto-valores correspondentes aos auto-vetores de Vek. A matriz
da transformação de branqueamento é definida por Vk = (Λ
−1/2 k VkT)T.
O último passo consiste em computar a matriz de projeção que maximiza a dispersão
intrapessoal através da aplicação da PCA sobre VTY
k, utilizando todos menos um
auto-vetores. A matriz de projeção resultante é representada por Uek ∈R100×99. E a matriz
de projeção final para cada fatia k é definida como:
Ψk=WkVkUk. (4.3)
A projeção final é criada concatenando a projeção de cada fatia, e é definida por
ϕ = [(ΨT1Φ(I)1)T(ΨT2Φ(I)2)T . . .(ΨTNΦ(I)N)T]T. (4.4)
4.1.2
Classificação
O reconhecimento é feito após combinar os vetores projetados de cada fatia em um
único grande vetor, ϕ que representa o indivíduo. A métrica de comparação utilizada
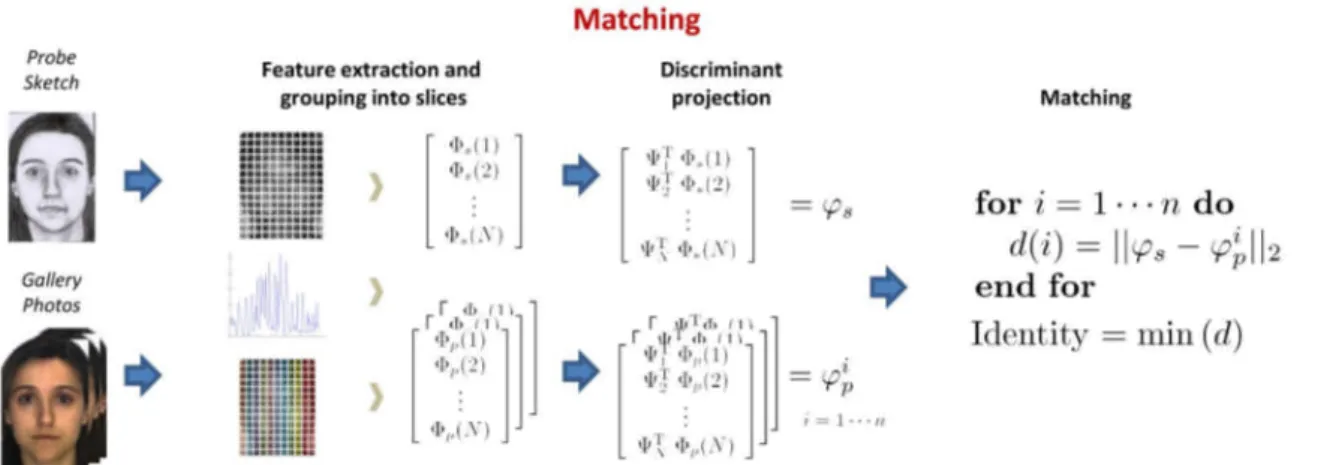
é a distância euclidiana entre os vetores finais de cada retrato falado e fotografia, como pode ser visto na Figura 4.2.
Figura 4.2: Processo de reconhecimento do método LFDA (Klare et al., 2011).
4.2
Heterogeneous Prototype Framework
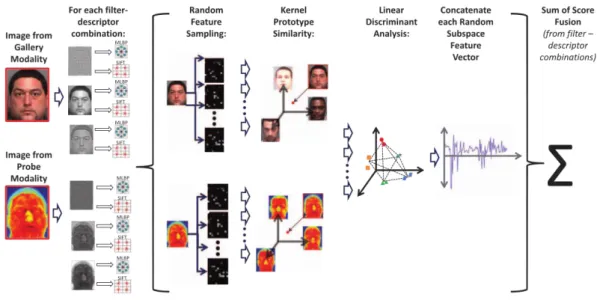
No trabalho de Klare and Jain (2013) é apresentado um framework para o
reconheci-mento facial heterogêneo, isto é, que efetua o reconhecireconheci-mento da face a partir de diversas fontes, como por exemplo: retratos falados, imagens térmicas, infra-vermelho, etc. Esse
framework é dividido em dois métodos distintos: O primeiro, oPrototype Random
Subs-pace (P-RS) e o segundo, chamado de Direct Random Subspace (D-RS).
4.2.1
Prototype Random Subspace
O Prototype Random Subspace (P-RS), começa aplicando 3 filtros diferentes (Gaussi-ano, DoG e CSDN) em cada imagem de entrada, gerando 3 novas images. Cada imagem dessas é dividida em sub-regiões sobrepostas e para cada região é extraído um descritor SIFT e um MLBP em separado. Assim temos 6 representações diferentes para cada
ima-gem de entrada. Para cada representação, o método prossegue ao utilizar B diferentes
bags, formadas por amostras dos N pedaços da imagem. Cada bag consiste em α·N
pedaços, com 0 ≤ α ≤ 1. Nesse ponto, separamos dois conjuntos de pares para o
trei-namento. O primeiro será utilizado como protótipos para a realização da representação baseada em protótipos. O segundo conjunto de treinamento, será mapeado no espaço do protótipos, e utilizado para treinar a LDA.
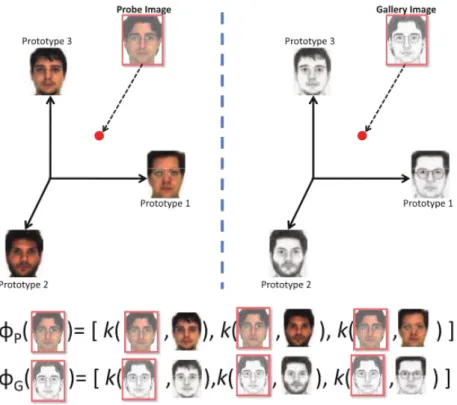
A representação baseada em protótipos (Klare and Jain, 2013) pode ser resumida como um espaço de características onde cada eixo representa uma face, como é ilustrado
32 Métodos
uma nova face a ser mapeada e do conjunto de protótipos, e explorando os conceitos do
kernel trick (Balcan et al., 2006), é possível gerar uma representação de alta dimensão e não linear de uma face, utilizando um vetor de características compacto.
Figura 4.3: Neste método uma face é representada como um vetor de similari-dade com um conjunto de treinamento (Klare and Jain, 2013).
Considerando f(I) como a representação compacta do vetor de característica da
imagem, a similaridade entre duas imagens é medida através da utilização uma função
kernel, definida por k:f(I)×f(I)⇒R
SejaT o conjunto de treinamento (protótipos), que consistem emnsujeitos, definido
como:
T ={P1, P2, . . . Pn}. (4.5)
φ(I) = [k(f(I), f(P1)), . . . , k(f(I), f(Pn))]T. (4.6)
O processo de reconhecimento, ilustrado na Figura 4.4, consiste em para uma imagem de entrada: (1) Gerar as seis representações através das combinações entre os filtros e
descritores. (2) Selecionar bags aleatórias. (3) Para cada bag efetuar o mapeamento no
espaço dos protótipos. (4) Gerar a projeção através da LDA. (5) Concatenar as projeções de cada bag.
Figura 4.4: Processo de reconhecimento do método Kernel Prototype Random Subspace (Klare and Jain, 2013).
Classificação
Os vetores finais de cada representação são comparados utilizando similaridade de
cos-seno. E no final é feita a fusão de scores através da soma normalizada das 6
representa-ções diferentes.
4.2.2
Direct Random Subspace
34 Métodos
Resumindo, o D-RS calcula uma LDA para cada bag.
O D-RS, assim como o P-RS também utiliza o conjunto de 3 filtros (Gaussiano, DoG e CSDN) combinados com os 2 descritores (SIFT e MLBP), totalizando 6 representações
diferentes, e o resultado final é computado utilizando uma fusão de scores através da
soma das matrizes normalizadas.
4.3
Método Proposto
Baseando-se em estudos, análises e modificações sobre os trabalhos de Klare et al. (2011) e Klare and Jain (2013), propomos uma nova abordagem para o reconhecimento facial por meio de retratos falados. Nossa abordagem pode ser resumida nos seguintes passos, e as melhorias sobre o LFDA (Klare et al., 2011) estão destacadas em negrito:
• As imagens são filtradas utilizando o filtro da Gaussiana.
• Cada imagem é dividida em regiões sobrepostas.
• Para cada região são extraídos separadamente os descritores HOG, HAOG,
MLBP e SIFT (enquanto o LFDA utiliza os descritores SIFT e MLBP conca-tenados).
• Para cada descritor, agrupa-se os descritores extraídos das sub-regiões em “fatias”
verticais, formando um único vetor de características.
• Para cada fatia, uma função discriminante é aprendida e aplicada.
• As projeções de cada fatia são agrupadas em um único vetor.
• O reconhecimento é feito utilizando a similaridade de cosseno (enquanto o
LFDA utiliza a distância euclidiana) entre o o vetor de características das fotogra-fias e retratos falados.
• Finalmente, é aplicada a fusão de scores utilizando a soma das matrizes de distâncias normalizadas.
Figura 4.5: Processo de treinamento do método proposto.
Figura 4.6: Processo de reconhecimento do método proposto.
4.3.1
Extração de Descritores
Primeiramente, o filtro Gaussiano é aplicado para remoção de ruídos e suavização da
imagem. Depois cada imagem é dividida em regiões sobrepostas de 32×32 pixels com
16 pixels de intersecção vertical e horizontal. Para cada região são extraídos descritores HOG, HAOG, SIFT e MLBP.
4.3.2
Análise Discriminante
36 Métodos
4.3.3
Classificação
O reconhecimento entre fotografia e retrato falado é feito utilizando a similaridade de cosseno sobre as projeções finais, e para cada descritor (HOG, HAOG, SIFT e MLBP) é
criada uma matriz de distâncias. Ao final, é aplicada uma fusão de scores, feita através
da soma das 4 matrizes de distâncias normalizadas.
4.4
Considerações Finais
Resultados Experimentais
Neste capítulo são apresentados os resultados dos experimentos realizados neste trabalho. Primeiro são descritas as bases de dados utilizadas, depois são explicados os dois métodos de pré-processamento. Na terceira parte temos os resultados dos experimentos utilizando as três bases, comparando os descritores entre si, e nossa abordagem com o estado-da-arte. Ao final temos a medição de tempo que cada método e etapa consomem.
5.1
Base de Dados
Nesta seção são descritas as três bases de imagens utilizadas nos experimentos: CUFS,
CUFSF (ambas formadas por viewed sketches) e uma base formada por Forensic
Sket-ches.
5.1.1
CUHK Face Sketch Database
(CUFS)
A base de imagens CUFS foi criada e utilizada por Tang and Wang (2004). ACUHK Face
Sketch Database consiste em 606 sujeitos, com sua fotografia e seu retrato falado (viewed sketch). Todas as fotografias foram obtidas sob condições normais de iluminação. E para cada foto há um desenho sem distorções, feito por um artista observando a fotografia. Um par de exemplo é exibido na Figura 5.1.
38 Resultados Experimentais
(a)Fotografia (b)Viewed Sketch
Figura 5.1: Fotografia e viewed sketch da CUFS database (Tang and Wang, 2004).
As fotografias que estão nesta base de dados pertecem a três bases de dados diferentes, são elas: AR (Martinez, 1998), XM2VTS (Messer et al., 1999), e CUHK student (Tang and Wang, 2004). Neste trabalho utilizamos 188 pares desta base de dados, pois não foi possível obter todas as fotografias, devido a indisponibilidade da fonte das fotografias das bases AR e XM2VTS.
5.1.2
CUHK Face Sketch FERET Database
(CUFSF)
A base de dados CUFSF (Wang and Tang, 2009, Zhang et al., 2011) consiste em 1194 pares, em que há variações de luminosidade para as fotografias e exagero propositais nas formas do rosto nos desenhos, como pode ser visto na Figura 5.2.
(a)Fotografia (b)Viewed Sketch
5.1.3
Forensic Sketches
Esta base de dados é composta por 158 forensic sketches, cada um com a
correspon-dente fotografia do suspeito, que foi apreendido e identificado posteriormente pela po-lícia. Estes retratos falados foram feitos por desenhistas forenses, e criados a partir de informações repassadas por testemunhas através da descrição verbal. A fotografia correspondente é feita depois que o sujeito foi identificado, um exemplo é exibido na
Figura 5.3. Estes forensic sketches foram retirados de duas fontes diferentes: 110 pares
da artista forense Taylor (2010) e 48 pares da artista forense Gibson (2010).
(a)Fotografia (b)Retrato falado
Figura 5.3: Fotografia e retrato falado feito por um artista através de
descri-ção verbal de uma testemunha. Imagens do livro Forensic Art and Illustration
(Taylor, 2010).
5.1.4
Galeria Extra
Também utilizamos uma base de dados formada por10.000fotografias de suspeitos
apre-endidos, disponível em http://www.califoniamugshots.com, para popular a galeria.
5.2
Pré-Processamento
40 Resultados Experimentais
escalar a imagem, fazendo com que a distância entre os dois olhos seja igual a 75 pixels
e cortar a imagem para uma janela de 200×250 pixels, centralizando o centro entre
os olhos horizontalmente e posicionando-os verticalmente na linhas 115. O segundo método, usado por Zhang et al. (2011), consiste em alinhar a imagem baseando-se no centro entre os olhos e o centro da boca. Neste trabalho, adaptamos este método, e
posicionamos o centro entre os olhos no ponto PCEyes = (100,110) e o centro da boca
no pontoPmouth = (100,188), ao final a imagem é cortada para uma janela de 200×250
pixels. Neste trabalho, chamamos o primeiro método de pré-processamento de BK e o segundo de TW, fazendo referência aos seus autores.
5.3
Resultados
Neste trabalho são feitos 3 (três) experimentos para avaliar os seguintes itens: (1) poder de descrição dos descritores, (2) comparação entre os métodos e (3) avaliação dos tempos. Os resutados são expressos em duas métricas diferentes: Rank, que consiste na posição de classificação do fotografia que realmente corresponde ao retrato falado; E a taxa de
verificação (Verification Rate) ao se fixar a taxa de falsa aceitação (False Accept Rate)
em 0,1% (VR@FAR=0.1%).
5.3.1
Avaliação dos Descritores
No primeiro experimento, avaliamos o desempenhos de vários descritores utilizado na tarefa de reconhecimento através de retratos falados. Estes descritores são: SIFT e MLBP (Klare et al., 2011) e (Klare and Jain, 2013); HOG e HAOG (Kiani Galoogahi and
Sim, 2012c); LRBP (Kiani Galoogahi and Sim, 2012b); Gabor Shape (Kiani Galoogahi
and Sim, 2012a). A métrica de distância utilizada para comparação é a χ2.
Nas Figuras 5.4, 5.5 e 5.6 são exibidos os resultados da avaliação utilizando as três bases de dados. Como nós podemos ver, nas bases CUFS e CUFSF, o descritor HAOG supera os outros descritores, enquanto o LRBP tem os piores resultados. O descritor
Gabor Shape desaponta, pois demonstra um poder de discriminação muito baixo, aliado
à complexidade e ao alto custo computacional que exige. Na base de dados de forensic