Universidade
Católica de
Brasília
PROGRAMA DE PÓS-GRADUAÇÃO
STRICTO SENSU EM GESTÃO DO CONHECIMENTO E
TECNOLOGIA DA INFORMAÇÃO
Mestrado
Um repositório de experiência docente integrando estrutura
a
priori
e estrutura emergente a partir da abordagem de Wiki
Semântico
Autor: José Jesse Gonçalves
Orientadora: Profa. Dra. Germana Menezes da Nóbrega
Co-orientadora: Profa. Dra. Fernanda Lima
JOSÉ JESSE GONÇALVES
Um repositório de experiência docente integrando estrutura a
priori e estrutura emergente a partir da abordagem de Wiki
Semântico
Dissertação submetida ao Programa de Pós-Graduação Stricto Sensu em Gestão do
Conhecimento e Tecnologia da Informação da Universidade Católica de Brasília, como requisito parcial para a obtenção Título de mestre em Gestão do Conhecimento e Tecnologia da Informação.
Orientadora: Profa. Dra. Germana M. da Nóbrega Co-orientadora: Profa Dra. Fernanda Lima
Ficha elaborada pela Coordenação de Processamento do Acervo do SIBI – UCB. G635r Gonçalves, José Jesse.
Um repositório de experiência docente integrando
estrutura a priori e estrutura emergente a partir da abordagem de Wiki Semântico / José Jesse Gonçalves. – 2008.
173 f.: il. ; 30 cm.
Dissertação (mestrado) – Universidade Católica de Brasília, 2008.
Dissertação de autoria de José Jesse Gonçalves, intitulada “Um repositório de experiência docente integrando estrutura a priori e estrutura emergente a partir da abordagem de Wiki Semântico”, requisito parcial para obtenção do título de Mestre em Gestão do Conhecimento e Tecnologia da Informação, defendida e aprovada em de setembro de 2008, diante da banca examinadora constituída por:
_____________________________________________ Profa. Dra. Germana Menezes da Nóbrega
Orientador
_____________________________________________ Profa. Dra. Fernanda Lima
Co-orientadora
_____________________________________________ Prof. Dr. Rodrigo Pires de Campos
Examinador Interno
_____________________________________________ Prof. Dr. Evandro de Barros Costa
Examinador Externo
AGRADECIMENTOS
Agradeço a Deus e a Nossa Senhora que me possibilitaram a realização desse trabalho, concedendo-me saúde, disposição, inteligência, força e vontade.
Agradeço aos meus pais, José e Amália, que tanto me incentivam e que, com carinho e dedicação, muito colaboraram para a consecução do meu objetivo.
Agradeço aos meus irmãos, Cátia, Marcos e Márcio, que estiveram ao meu lado, incentivando-me nas horas de maior dificuldade. Além disso, me deram sobrinhos lindos e divertidos que eu tanto amo.
Agradeço a minha orientadora Profa. Dra. Germana e a minha co-orientadora Profa. Dra. Fernanda, pela dedicação, esforço e apoio durante a realização dessa dissertação.
Agradeço a todos os outros professores que transmitiram conhecimento com altruísmo e dedicação.
Agradeço a todos os amigos que torceram por mim e colegas do curso que colaboraram com conhecimento e com boas risadas. E a todos aqueles que, de uma forma ou de outra, participaram na conclusão de mais esta etapa.
RESUMO
Docentes usam diferentes técnicas e metodologias de ensino que resultam em experiências individuais que, de modo geral, são compartilhadas informalmente e de forma restrita a grupos pequenos de docentes. O compartilhamento e as discussões de forma mais abrangente das experiências docentes podem ser importantes para muitos docentes e para o processo de ensino-aprendizagem. Além disso, pode significar uma contribuição para a gestão do conhecimento de Instituições de Ensino. Em trabalhos anteriores foi desenvolvido um ambiente para o compartilhamento de experiências docentes de uma mesma subárea temática e de aperfeiçoamento de material instrucional por meio de uma rede formalmente organizada. Entretanto, o registro das experiências é feito usando a abordagem de metadados e de maneira sintática. Segundo pesquisas, o preenchimento de metadados sem um vocabulário estruturado, com ambigüidades e problemas semânticos, pode dificultar a recuperação do objeto associado aos metadados. Iniciativas para associar dados estruturados a conteúdos não estruturados têm sido empreendidas em torno de sistemas Wiki e são conhecidos como Wikis Semânticos. O Wiki tem sido reconhecido como uma ferramenta útil para a gestão do conhecimento de
organizações, podendo ser usado como um sistema de colaboração em massa, como repositório de informações contextualizadas e de compartilhamento de experiências. Os Wiki
Semânticos agregam tecnologias que permitem que o ambiente tenha uma estrutura que possa ser entendida por máquinas. O presente trabalho apresenta uma proposta de uso de Wiki
Semânticos para apoiar o compartilhamento de experiências em todas as áreas de uma Instituição de Ensino Superior. Propõe-se a integração do ambiente preexistente de apoio a colaboração de docentes de uma mesma sub-área temática, integrando material instrucional e experiência, com um ambiente baseado em Wiki Semântico e aberto a toda a Instituição,
permitindo o registro e a discussão colaborativa de experiências de maneira não estruturada e de dados estruturados para tornar a recuperação mais consistente dessas experiências.
ABSTRACT
Teachers use different techniques and methods resulting in individual experiences that are often informally shared within small groups. The wide sharing and discussions of such experiences are suitable for many teachers and for the teaching-learning process. In addition, this can contribute to knowledge management in educational institutions. In a previous work, an environment was proposed in order to capture experiences from teachers sharing one thematic area, with the aim of improving instructional material through a formally organized network. However, the storage of experiences relies on the approach of syntactic metadata. Recent relevant research reveals that filling in metadata without a structured vocabulary, with ambiguities and semantic problems may render it difficult to retrieve objects referred to by such metadata. Initiatives to link structured data to non-structured content have been undertaken utilizing Wiki Systems, known as Semantic Wikis. The Wiki has been appraised as a useful tool for knowledge management within organizations. It can be used as a system of massive cooperation, as a repository of contextualized information and sharing of experiences. Semantic Wikis join technologies that enable the environment with a structure that can be understood by machines. This work proposes the use of Semantic Wikis to support the sharing of experiences in all areas of a higher educational institution. We propose the integration of the aforementioned environment for teachers’ collaboration within a thematic area, which allows the integration of instructional material and experience, with an environment based on Semantic Wikis, available for the whole institution. This should allow the registry and the collaborative discussions of both experiences in a non-structured way and of structured data aiming to facilitate the retrieval of such experiences.
LISTA DE FIGURAS
Figura 1: Freqüência de campos usados pelos usuários do ARIADNE KPS em consultas
(NAJJAR e DUVAL, 2006). ...26
Figura 2: Exemplo RDF em representação gráfica ...35
Figura 3: Exemplo em formato RDF/XML serializada (Gil e Ratnakar, 2001)...35
Figura 4: Hierarquia de classes no modelo RDF Schema (BRICKLEY; GUHA, 2004)...36
Figura 5:Taxonomia das classes do modelo RDF(S) (GOMÉZ-PÉREZ et al., 2003)...37
Figura 6: Exemplo de um esquema RDF(S) (Gil e Ratnakar, 2001)...38
Figura 7: Taxonomia das classes da ontologia de representação de conhecimento DAML+OIL definida como extensão de RDF(S) (GOMÉZ-PÉREZ et al., 2003). ...39
Figura 8: Processo de desenvolvimento de ontologia (GOMÉZ-PÉREZ et al., 2003)...47
Figura 9: Tela do Protégé na ficha OWLClasses23...52
Figura 10: Tela inicial do MediaWiki após instalação ...57
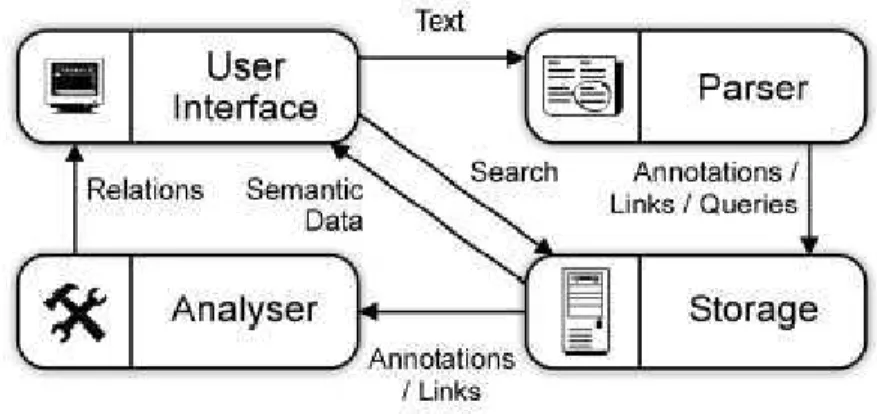
Figura 11: Arquitetura básica de um Wiki Semântico segundo Oren et al. (2006)...67
Figura 12: Fragmento da tela do Platypus Wiki ...69
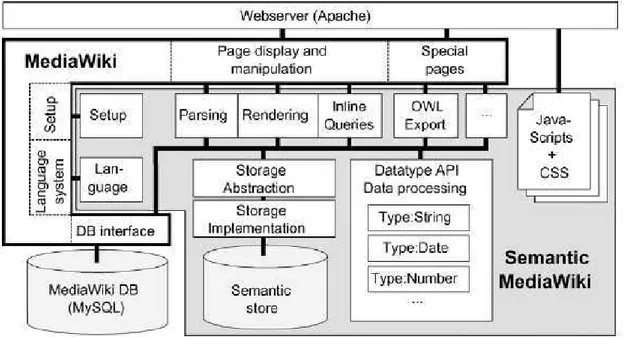
Figura 13: Arquitetura dos principais componentes do SMW em relação ao MediaWiki (KRÖTZSCH, 2007) ...70
Figura 14: Na parte de cima da figura, a representação da ligação das páginas na Wikipedia tradicional. Na parte de baixo a representação das ligações classificadas na extensão da Wikipedia (VÖLKEL et al., 2006)...72
Figura 15: Arquitetura do IkeWiki (SCHAFFERT,2006)...75
Figura 16: Interface do IkeWiki (SCHAFFERT, 2006)...76
Figura 17: Links extraídos das tags (BUFFA et. al, 2006)...77
Figura 18: Arquitetura do SweetWiki ...77
Figura 19: Meta-model do SMWpc (SCHOLZ, 2008)...85
Figura 20: Concepção do doceNet (BRITO, 2006)...92
Figura 21: Interação entre experiWiki e o doceNet...94
Figura 22: Destaque para o Passo 1...97
Figura 23: Arquivo com metadados do doceNet. ...99
Figura 24: Exemplo de uma experiência trazida do doceNet para o experiWiki ...99
Figura 25: Página de experiência no modo de edição ...100
Figura 26: Matriz Conceitual do Thesaurus Brased ...104
Figura 27:Parte da página Category:Experiência onde são listados os links paras as páginas inseridas nessa categoria...108
Figura 28: Categorias de uma página do ambiente experiWiki...108
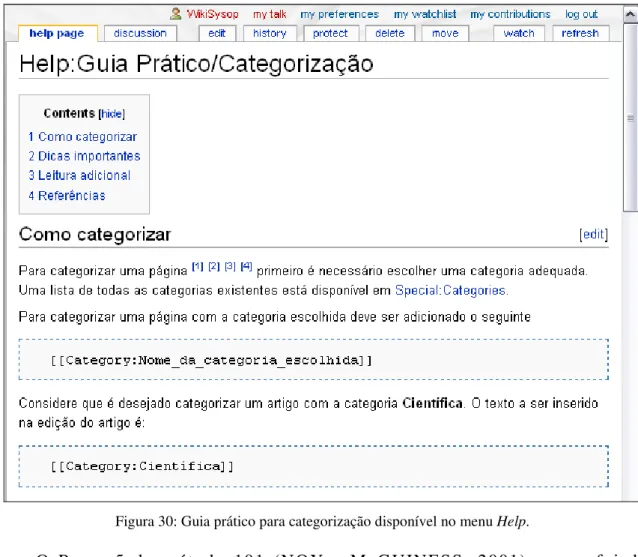
Figura 30: Guia prático para categorização disponível no menu Help...110
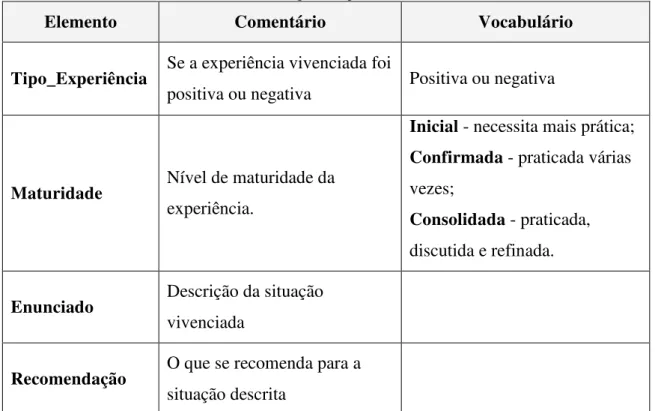
Figura 31: Código da página wiki da propriedade Maturidade ...111
Figura 32: Página wiki da propriedade Maturidade ...112
Figura 33: Exemplo de preenchimento com valor não permitido para a propriedade Tipo...113
Figura 34: Página de experiência com anotações semânticas. ...116
Figura 35: Modo de edição de uma experiência com as anotações semânticas inseridas ...117
Figura 36: Parte da página de experiência onde aparecem as anotações semânticas ...117
Figura 37:Página da categoria Br:Avaliação de Aprendizagem...118
Figura 38: Página de experiência com links anotados...119
Figura 39: Trecho do código onde foi inserida a definição da propriedade ...119
Figura 40: Consulta embutida com resultado em uma tabela...121
Figura 41: Pesquisa feita na página especial Semantic Search ...122
Figura 42: Destaque para o Passo 2...123
Figura 43: Página de ajuda do ambiente...123
Figura 44: Página principal do experiWiki...124
Figura 45: Página especial Recent changes...127
Figura 46: Página especial Block user...127
Figura 47: Guia watch de uma página de experiência...128
Figura 48: Página com banner indicando que o artigo está incompleto ...129
Figura 49: Exemplos de banners usados no experiWiki. ...130
Figura 50: Exemplo da utilização da extensão Cite....131
Figura 51: Parte da lista de categorias mostrada na página especial Categories...132
Figura 52:Parte da página Main Page onde pode ser visualizada uma árvore hierárquica de categorias (não expandida). ...133
Figura 53: Página Principal no modo de edição com a tag <categorytree> selecionada. ...133
Figura 54: Página da categoria Br:Educação...134
Figura 55: Página especial CategoryTree...135
Figura 56: Adicionando experiência com o formulário...136
Figura 57:Lista aberta da propriedade Maturidade. ...137
Figura 58: Formulário acusando erro em seu preenchimento. ...137
Figura 59:Guia da ficha edit with form...138
Figura 60: Página de experiência com caixa adicional inserida pelo formulário...138
Figura 61: Adicionando página de experiência com o formulário Experiência. ...139
Figura 62: Página gerada com o formulário Experiência. ...140
Figura 64: Experiência registrada diretamente no experiWiki...143
Figura 65 – Discussões a respeito de uma experiência (ficha Discussion) ...144
Figura 66: Propriedades e relações da página Fichamento de artigos estruturados ...145
Figura 67: Propriedades e relações da página Fichamento de artigos estruturados. ...145
Figura 68: Tela do protótipo da extensão Análise de Questões ...148
Figura 69: Destaque para o Passo 3...149
Figura 70: Página especial Export pages to RDF...152
Figura 71: Dados semânticos exportados em RDF ...153
Figura 72: Dados semânticos em RDF de uma experiência...154
Figura 73: Definição das propriedades Maturidade e Ocorreu na disciplina ...155
Figura 74: Definição da classe Experiência ...155
Figura 75: Dados exportados abertos no Protégé (visualização das classes OWL). ...156
Figura 76: Nova visualização das classes...157
Figura 77: Visualização das propriedades dos dados exportados abertos no Protégé...157
Figura 78: Visualização das instâncias dos dados exportados abertos no Protégé...158
LISTA DE TABELAS
Tabela 1: Comparação entre ROAs (NEVEN e DUVAL, 2002) ...24
Tabela 2: Porcentagem de uso de metadados do Ariadne (NAJJAR e DUVAL, 2006) ...25
Tabela 3: Modelo de uma declaração RDF ...34
Tabela 4: Características do Passo 1...97
Tabela 5: Metadados da categoria Experiência do doceNet (BRITO, 2006). ...98
Tabela 6: Principais marcos da origem do Thesaurus Brased...105
Tabela 7: Primeiras propriedades definidas e suas características ...114
Tabela 8: Características do Passo 2...125
SUMÁRIO
1. INTRODUÇÃO ...15
1.1. Objetivos...20
1.1.1. Objetivo geral ...20
1.1.2. Objetivos específicos ...20
1.2. Metodologia...20
1.3. Organização da dissertação ...21
2. RECUPERAÇÃO DE EXPERIÊNCIAS DOCENTES E OBJETOS DE APRENDIZAGEM...22
2.1. Recuperação de Objetos de Aprendizagem ...23
2.2. Recuperação de experiência docente ...27
3. REGISTRO NÃO-ESTRUTURADO E RECUPERAÇÃO SEMÂNTICA DE EXPERIÊNCIA DOCENTE ...29
3.1. Ontologia ...29
3.1.1. Linguagens...31
3.1.1.1. XML e XML Schema...32
3.1.1.2. RDF e RDFS...33
3.1.1.3. DAML+OIL ...39
3.1.1.4. OWL ...39
3.1.2. Engenharia de Ontologias...42
3.1.2.1. Componentes de Ontologias ...43
3.1.2.2. Metodologia de construção de ontologias...45
3.1.2.3. Ferramentas para construção de ontologias ...51
3.2. Wiki Wiki Web ...53
3.2.1. Características ...53
3.2.2. Clones...55
3.2.2.1. Mediawiki...56
3.2.2.2. TWiki ...59
3.2.4. Vantagens e Limitações...62
3.3. Wiki Semântico...65
3.3.1. Características ...65
3.3.2. Exemplos ...68
3.3.2.1. Platypus Wiki ...68
3.3.2.2. Semantic MediaWiki...69
3.3.2.3. IkeWiki ...73
3.3.2.4. SweetWiki...76
3.3.3. Utilização ...78
3.3.4. Vantagens e Limitações...79
3.4. Ontologias e Wikis Semânticos...81
3.4.1. Iniciativas...85
3.5. Web Semântica e Gestão do Conhecimento ...87
3.6. Considerações finais do capítulo ...89
4. PROCEDIMENTO DE MANUTENÇÃO DE UM REPOSITÓRIO DE EXPERIÊNCIA BASEADO EM WIKI SEMÂNTICO ...91
4.1. Contextualização da proposta ...91
4.2. Projeto do experiWiki e de sua interface com o doceNet...96
4.2.1. Passo 1: Importação das experiências do doceNet para o experiWiki ...96
4.2.1.1. Criação de páginas iniciais ...98
4.2.1.2. Criação de anotações semânticas...100
4.2.1.2.1. Domínio e escopo da ontologia ...101
4.2.1.2.2. Utilização de termos de thesauri para educação ...103
4.2.1.2.3. Definição dos componentes da ontologia ...106
4.2.1.2.4. Criação de instâncias...115
4.2.1.2.5. Recuperação de páginas de experiências ...120
4.2.2. Passo 2: Utilização e manutenção do experiWiki ...122
4.2.2.1. Extensões do MediaWiki ...130
4.2.2.2. Registro de experiência docente...138
4.2.2.4. Extensão: Questões para recuperar experiência...146
4.2.3. Passo 3: Exportação de dados estruturados para o doceNet ...149
4.2.3.1. Manutenção das anotações semânticas antes da exportação ...150
4.2.3.2. Exportando dados estruturados via wiki...152
4.3. Considerações finais do capítulo ...159
5. CONCLUSÕES E PERSPECTIVAS FUTURAS...162
1. INTRODUÇÃO
O crescente entendimento do conhecimento como uma das fontes de vantagem competitiva sustentável para as organizações rapidamente popularizou a Gestão do Conhecimento (ESERYEL et al., 2006),
impulsionado o interesse nas suas atividades básicas, tais como a identificação, aquisição, desenvolvimento, disseminação, uso e preservação do conhecimento da organização (ABECKER et al., 1998). Nos últimos
tempos, as empresas que produzem e distribuem informações começaram a ganhar posição como importantes produtoras de riquezas, antes característica apenas das empresas que produziam bens tangíveis. A habilidade para manipular e usar o conhecimento em uma organização passou a ser essencial, uma vez que o conhecimento passou a representar o principal ativo e, portanto, é chave para uma vantagem competitiva sustentável (DAVENPORT e PRUSAK, 1998). O constante avanço tecnológico, a globalização e a demanda por bens e serviços ligados à informação e ao conhecimento tornaram o mercado competitivo e turbulento, exigindo que as organizações sejam inovadoras para se manterem competitivas.
A Tecnologia da Informação tem se tornado indispensável na gestão da informação e do conhecimento nas organizações. Muitas vezes seu uso é fundamental para, por exemplo, reunir e organizar informações de várias fontes e torná-las recuperáveis e como suporte para o trabalho coletivo e colaborativo nas organizações. Apesar do importante papel que as tecnologias podem exercer na GC, ainda são apresentados problemas para atingir os seus objetivos (McAFEE, 2006). Grandes investimentos são realizados pelas organizações para capturar e disseminar seus conhecimentos, porém muitas dessas organizações não recebem de volta o valor desse investimento (HAAS e HANSEN, 2007).
A maioria das tecnologias de informação usada na GC atualmente pode ser classificada em canais de comunicação, como e-mails e mensagens instantâneas, e em plataformas, como, por exemplo, as Intranets e portais Web das organizações (McAFEE, 2006). Nos e-mails, mensagens instantâneas e similares a informação pode ser criada e distribuída por qualquer pessoa, porém o seu recebimento é restrito às pessoas de um grupo. Já em plataformas como Intranet, sítios corporativos Web e portais de informação, as informações são amplamente disponibilizadas na organização, porém a geração ou a aprovação dessas informações é centralizada. É importante, entretanto, que o conhecimento de uma organização não seja restrito a pequenos grupos, nem em relação à criação do conhecimento e nem em relação ao seu acesso.
De acordo com Haas e Hansen (2007), a obtenção de conhecimento se dá mais frequentemente pelo contato direto entre as pessoas do que pela pesquisa em documentos codificados. Os documentos, disponíveis eletronicamente ou em papel, muitas vezes evitam que trabalhos sejam refeitos sem necessidade e ajudam a economizar tempo na execução de tarefas, mas não melhoram a qualidade do trabalho (HAAS e HANSEN, 2007).
Tecnologias como e-mails e mensagens são geralmente mais usados pelos trabalhadores do conhecimento (McAFEE, 2006). Contudo, de acordo com pesquisa realizada por Davenport (apud McAFEE, 2006), a maioria dos
Apesar de alguns progressos, um problema fundamental é que as tecnologias usadas atualmente pelos trabalhadores de conhecimento não estão atingindo de forma satisfatória o objetivo de capturar conhecimento (McAFEE, 2006). Os sistemas atuais de Gestão de Conhecimento têm fraquezas significativas no que diz respeito à busca e extração de informação, manutenção e geração automática de documentos (DAVIES et al., 2003). A
Intranet das grandes organizações tem se tornado um repositório de conhecimento organizacional valioso, mas encontrar e manter as inúmeras informações é um problema desafiador, já que o volume de informações não estruturadas tende crescer cada vez mais (DAVIES et al ., 2003).
Além disso, muitas vezes as lições aprendidas e o contexto que as envolvem não são levados em consideração quando as informações são disponibilizadas. De forma geral, o conhecimento corporativo é criado e armazenado na forma de documentos, cujo conteúdo e contexto não são descritos por metadados, ou pelo menos são insuficientemente descritos por eles (ZOUAQ et al., 2006). Isto dificulta a recuperação desses documentos e
também pode impedir que o capital intelectual de dentro da organização seja usado em treinamentos e programas de aprendizagem, que acabam por usar materiais sem conexão com o conhecimento e nem com os processos de trabalho reais da organização (ZOUAQ et al., 2006). Para Davenport e Prusak
(1998), como o conhecimento é de difícil estruturação e pesquisadores procuram por ele usando termos que nem sempre são possíveis de antecipar, um bom thes aur us é essencial para a maioria dos repositórios on-line de
conhecimento.
Em McAfee (2006) é defendido o uso de novas plataformas tecnológicas como wi kis e blogs para os sistemas de Gestão de Conhecimento. Essas
plataformas, que já são populares na Internet e conhecidas como tecnologias da Web 2.0, podem promover a formação de redes sociais para troca e compartilhamento de conhecimento entre colaboradores de uma organização, sejam eles funcionários, clientes, fornecedores e até mesmo concorrentes. Os
wikis e bl ogs possuem recursos que podem ser interessantes para a GC, como
mecanismos de busca, links entre páginas, folks onomi es (prática de criar e
informações e não apenas um grupo restrito de pessoas. Tal característica é importante, pois geralmente as pessoas de uma organização têm algum conhecimento, idéia, experiência, comentário, caso real, link e outras coisas que são importantes para serem disseminadas (McAFEE, 2006). Essa descentralização evita o isolamento das pessoas que participam da execução de trabalhos na organização e cuja contribuição pode ser relevante (CHAU e MAURER, 2005). Os wi kis e blogs também trazem a vantagem de serem
simples de usar, sendo preciso pouco conhecimento técnico.
Uma outra característica importante de plataformas como wi ki s e blogs,
também destacada em McAfee (2006), é a possibilidade de não serem impostas regras rígidas preconcebidas de como um conteúdo deve ser disponibilizado e estruturado. Dessa forma, permite-se que as estruturas e formas vão emergindo com o uso, ao contrário das ferramentas atuais de Gestão do Conhecimento, como Intranets, portais e outros ambientes, que, mesmo com o objetivo de capturar informações não-estruturadas, são ferramentas altamente estruturadas desde o início (McAFEE, 2006). É essencial para as ferramentas de compartilhamento de conhecimento dar suporte não apenas aos conteúdos estruturados, mas também para os conteúdos não-estruturados, como é o caso dos wiki s (CHAU e MAURER,
2005).
Tendo em vista a importância dos recursos tecnológicos na Gestão do Conhecimento nas organizações e estando as Instituições de Ensino Superior inseridas nesse contexto, o presente trabalho busca trazer uma contribuição quanto à captura e disseminação de informação e conhecimento em uma IES, também tendo o docente como foco principal. A troca de experiências entre docentes pode ser uma forma de compartilhar conhecimento e de criação de novos conhecimentos. De acordo com Brito (2006), essa troca acontece, muitas vezes, informalmente, pois as interações entre eles acontecem de maneira espontânea, a fim de compartilhar problemas, idéias, dificuldades e êxitos. Dessa forma, técnicas e metodologias são compartilhadas, juntamente com a discussão das vantagens e desvantagens em utilizá-las, a solução de problemas em comum e outros benefícios (BRITO, 2006).
importante que tais informações sejam capturadas e disseminadas para os demais docentes. Os benefícios podem ser vários, como por exemplo, evitar que erros sejam repetidos, divulgação de metodologias bem sucedidas, ajuda para professores iniciantes ou substitutos e o surgimento de novas idéias por meio das discussões.
A captura, armazenamento e compartilhamento de experiências docentes podem ser importantes em uma Instituição de Ensino Superior. Em trabalhos anteriores foi proposto o ambiente doceNet (BRITO, 2006) para o compartilhamento de experiências entre docentes de uma mesma subárea temática e para o aperfeiçoamento contínuo de material instrucional por meio de uma rede formalmente organizada. Entretanto, o registro das experiências é feito usando a abordagem de metadados e de maneira sintática, o que pode dificultar a recuperação do objeto associado aos metadados, devido ao seu preenchimento sem um vocabulário estruturado, com ambigüidades e problemas semânticos.
Iniciativas para associar dados estruturados a conteúdos não-estruturados têm sido empreendidas em torno de sistemas Wiki e são os Wikis
Semânticos, que agregam tecnologias ao Wi ki tradicional para permitir a
presença de estruturas que possam ser entendidas por máquinas, por meio de anotações semânticas ligadas aos conteúdos. Neste trabalho é proposto um ambiente com estrutura emergente segundo abordagem do Wi ki Semântico
para apoiar o compartilhamento de experiências em todas as áreas de uma Instituição de Ensino Superior. Pretende-se estimular a captura de conhecimento por toda a Instituição, com o registro e armazenamento de informação de forma não-estruturada e sem regras rígidas para isso. Porém, com dados estruturados atrelados a essas informações, permitindo explicitar seu contexto e significado, para promover recuperações bem sucedidas de conhecimento no repositório. Propõe-se, ainda, a integração de tal ambiente com o doceNet, para promover a geração de metadados estruturados para o doceNet, por meio das anotações semânticas desenvolvidas dinamicamente no ambiente Wi ki Semântico, visando, assim, a recuperação de experiências
1.1. Objetivos
1.1.1. Objetivo geral
Esta pesquisa tem como objetivo geral definir um ambiente para compartilhamento de experiência docente que inclua, de um lado, o ambiente (preexistente) com estrutura a priori doceNet e, de outro lado, um ambiente com estrutura emergente segundo a abordagem do Wi ki Semântico, bem como
um procedimento de manutenção da interface entre ambos.
1.1.2. Objetivos específicos
1. Projetar um ambiente baseado em Wi ki Semântico, doravante
denominado experiWiki, incluindo tanto dados não estruturados quanto estruturados, a partir da análise de metadados e fóruns de discussão oriundos de teste em campo com o ambiente de captura de experiência docente doceNet;
2. Definir recomendações para um mecanismo de transformação dos metadados do ambiente doceNet em páginas Wiki anotadas
semanticamente no ambiente experiWiki;
3. Definir um mecanismo de transformação das anotações semânticas do ambiente experiWiki em dados estruturados sobre experiência docente nos metadados correspondentes no doceNet.
1.2. Metodologia
Esta pesquisa pode ser classificada quanto à natureza como aplicada, quanto à abordagem do problema como qualitativa. Quanto aos fins como metodológica e quanto aos meios de investigação como bibliográfica e documental.
A pesquisa é aplicada porque está dirigida a solução de um problema específico que é o armazenamento de informações de maneira sintática pelo doceNet (BRITO, 2006), o que dificulta a recuperação dos materiais instrucionais e das experiências docentes a eles relacionados. Trata-se de uma pesquisa qualitativa, pois não requer o uso de métodos estatísticos para sua interpretação ou conclusão.
pesquisa bibliográfica, pois se fundamenta em conceitos da literatura, como por exemplo, os ambientes Wi ki Semânticos e as ferramentas de construção de
ontologias. Por fim, a pesquisa também pode ser considerada documental, pois faz uso de documentos da Universidade Católica de Brasília, onde o presente trabalho foi desenvolvido.
1.3. Organização da dissertação
Além deste capítulo, esta dissertação é composta por mais quatro capítulos.
O capítulo 2 apresenta pontos de motivação para este trabalho, como a importância do desenvolvimento de sistemas que apóiam as atividades docentes, focando na relevância do compartilhamento formal de experiências docentes. Além disso, são tratados aspectos importantes quanto aos Objetos de Aprendizagem, com ênfase aos seus metadados e a promoção de sua recuperação e reuso.
No capítulo 3 é apresentado o referencial teórico dos principais conceitos que norteiam a proposta deste trabalho.
O capítulo 4 trata da contextualização da pesquisa e apresenta o procedimento proposto e realizado para o desenvolvimento do ambiente experiWiki e sua interface com o doceNet. O procedimento foi dividido em três passos: o Passo 1 trata da importação das experiências do doceNet para o experiWiki; o Passo 2 aborda a utilização pelos docentes e manutenção do experiWiki; o Passo 3, por sua vez, trata da exportação dos dados estruturados do experiWiki para o doceNet.
2. RECUPERAÇÃO DE EXPERIÊNCIAS DOCENTES E OBJETOS DE
APRENDIZAGEM
O uso de Objetos de Aprendizagem (OAs) tem se mostrado vantajoso e importante para os ambientes educacionais e de aprendizagem, principalmente devido à capacidade de reuso e de interoperabilidade dos OAs, podendo ajudar os docentes na elaboração de materiais instrucionais e na preparação de aulas. Para Araujo e Ferreira (2004), as tarefas de preparação dos planos de aulas e de aquisição de material instrucional ainda hoje estão no plano secundário. Segundo os autores, os inúmeros sistemas desenvolvidos para a Educação a Distância trouxeram um grande desenvolvimento para a área, mas a maioria deixa a desejar quando se trata de facilitar o trabalho de elaboração de aulas. Mesmo com as tecnologias e recursos existentes e a quantidade de informação disponível na Web, os professores frequentemente são obrigados a “redescobrir a roda, preparando material didático do zero, a cada aula que necessitam ministrar” (ARAUJO e FERREIRA, 2004).
Em Brito (2006) é destacada a importância do reuso de experiências docentes, bem como o de Objetos de Aprendizagem atrelados a essas experiências. A busca do aperfeiçoamento de metodologias e didáticas aplicadas em sala de aula, muitas vezes resulta em experiências isoladas que são compartilhadas em redes informais de docentes. É importante que as experiências vivenciadas individualmente pelos docentes sejam compartilhadas de forma colaborativa e abragente, podendo, por exemplo, minimizar dificuldades na substituição de um docente, apoiar nas atividades didático-pedagógicas e ajudar na busca pelo aperfeiçoamento contínuo do processo de ensino-aprendizagem (BRITO, 2006). Diante disso, em Brito (2006) foi desenvolvido um ambiente Web, denominado doceNet, para que os docentes compartilhem experiências vivenciadas por meio de uma rede formalmente organizada, em busca de repetir sucessos e de evitar insucessos com base em lições aprendidas.
organizadas e estruturadas pelo ambiente. As discussões são focadas nas experiências, positivas ou negativas, vivenciadas com a utilização dos materiais instrucionais e registradas no ambiente, buscando, assim, o registro das melhores práticas didáticas.
Portanto, encontrar as experiências vivenciadas e registradas no ambiente doceNet é tão importante quanto encontrar os OAs para reuso. Para o registro das experiências no doceNet, assim como os Objetos de Aprendizagem, foi usada a abordagem de metadados. Muito embora esse registro das experiências seja considerado valioso, do ponto de vista prático, compartilha-se com a comunidade científica concernida, o gargalo do preenchimento de metadados para OAs (GONÇALVES et al., 2007a).
2.1. Recuperação de Objetos de Aprendizagem
Segundo Pahl e Melia (2006), o sucesso do crescente desenvolvimento de Objetos de Aprendizagem (OAs) recai no seu reuso e interoperabilidade, sendo necessários mecanismos de descrição e descoberta para permitir que eles sejam publicados por fornecedores e recuperados por usuários em potencial. Um Objeto de Aprendizagem, portanto, possui muitas características, cuja descrição é feita pelos seus metadados. Além dessa descrição, os OAs têm seus objetivos de reutilização e de interoperabilidade atendidos se eles estiverem catalogados de forma consistente e armazenados de forma organizada em repositórios (RICHARDS et al, 2003). Segundo Richards et al. (2003), os Repositórios de Objetos de Aprendizagem (ROAs)
são desenvolvidos com base em tecnologias de banco de dados e, além do armazenamento de OAs, fornecem mecanismos para fomentar a descoberta, recuperação, troca e reuso dos objetos de aprendizagem.
São exemplos de iniciativas de Repositórios de Objetos de Aprendizagem o Multimedia Educati onal Resour ce f or Lear ning and Onli ne Teachi ng (MERLOT)1, ARIADNE K nowl edge Pool Syst em (KPS)2, o SMETE Digit al Library3, entre outros. Cada ROA, no entanto, pode possuir um padrão
de metadados para atender a necessidade dos diferentes contextos em que são desenvolvidos. Alguns esforços são despendidos em busca de padrões para os
1 http://www.merlot.org/merlot/index.htm
metadados. Os padrões L earning Obj ect Metadata (LOM)4 e o Dublin C or e Met adata (DCMI)5, são alguns dos mais conhecidos e utilizados
internacionalmente para descrever as especificações de metadados. Entretanto, muitas organizações, tais como a fundação ARIADNE6 e a
Advanced Distri but ed L ear ning (ADL)7, têm desenvolvido especificações
baseadas nestes padrões. Tais especificações são chamadas de perfis de aplicação (appli cati on prof ile), que adaptam os metadados de um padrão já
existente à necessidade de uma determinada comunidade, criando, assim, uma aplicação de metadados específicos.
Tabela 1: Comparação entre ROAs (NEVEN e DUVAL, 2002)
Perfil de
aplicação Modelo de metadados Domínio de aplicação
Armazenagem de LOs
ARIADNE Perfil de Aplicação – padrão LOM Todos Repositório de documento
SMETE Perfil de Aplicação – padrão LOM engenharia e tecnologia Ciências, matemática, Links
MERLOT Perfil de Aplicação – padrão LOM Todos Links
CAREO8 Perfil de Aplicação CanCore– padrão
LOM Todos
Repositório de documento +
Links
Learn-Alberta9 Perfil de Aplicação CanCore– padrão
LOM Jardim de infância à 12 education
K-Repositório de documento
Edna10 Padrão Dublin Core Educação Links
Sendo assim, as comunidades acabam usando perfis de aplicação diferentes, dificultando a interoperabilidade de OAs. Além disso, muitos desses perfis e padrões possuem metadados com pouca riqueza semântica em seu vocabulário. Segundo Najjar e Duval (2006), a complexidade de preencher manualmente os metadados ainda é o gargalo para a recuperação dos objetos. Além de alguns metadados não serem preenchidos, eles são escolhidos de maneiras diferentes pelos indexadores, bem como os valores determinados para preencher cada um (NAJJAR e DUVAL, 2006). Sendo assim, uma das principais dificuldades na recuperação de OAs está justamente na pobreza
4 http://www.ieeeltsc.org/standards 5 http://dublincore.org/documents/dces/ 6 http://www.ariadne-eu.org/
7 http://www.adlnet.gov/
8 http://www.ucalgary.ca/commons/careo/ 9 http://www.learnalberta.ca/
semântica e pouca clareza de vocabulários no uso dos padrões de metadados de OAs. A característica sintática dos metadados, voltada apenas para a interpretação humana, não permite que sejam processados por sistemas automatizados (SÁNCHEZ-ALONSO et al., 2007). Por tudo isso, encontrar o
objeto de aprendizagem apropriado nos vários repositórios existentes ainda pode representar um desafio para os usuários (NAJJAR et al., 2005).
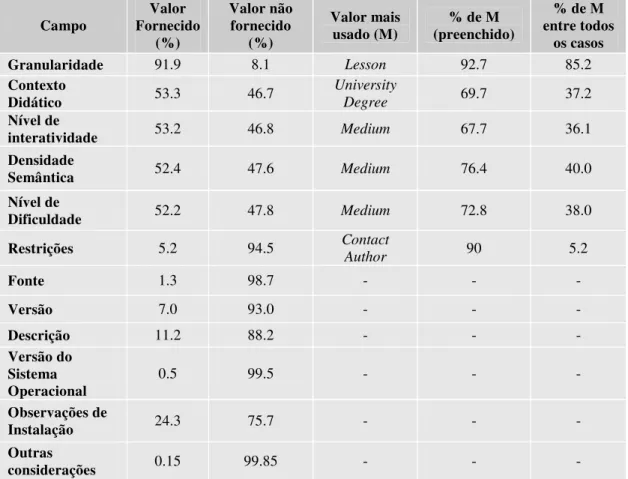
A Tabela 2 mostra a porcentagem que os metadados do perfil de aplicação Ariadne, do repositório ARIADNE KPS, são usados, segundo boletim técnico apresentado em Najjar e Duval (2006). Apenas o metadado “Granularidade” possui a maioria dos preenchimentos. Entretanto, esse metadado era de preenchimento obrigatório em versões anteriores da ferramenta utilizada pelos indexadores para o preenchimento dos metadados (NAJJAR e DUVAL, 2006).
Tabela 2: Porcentagem de uso de metadados do Ariadne (NAJJAR e DUVAL, 2006)
Campo Valor Fornecido (%) Valor não fornecido (%) Valor mais
usado (M) (preenchido) % de M
% de M entre todos
os casos
Granularidade 91.9 8.1 Lesson 92.7 85.2
Contexto
Didático 53.3 46.7 University Degree 69.7 37.2
Nível de
interatividade 53.2 46.8 Medium 67.7 36.1
Densidade
Semântica 52.4 47.6 Medium 76.4 40.0
Nível de
Dificuldade 52.2 47.8 Medium 72.8 38.0
Restrições 5.2 94.5 Contact
Author 90 5.2
Fonte 1.3 98.7 - - -
Versão 7.0 93.0 - - -
Descrição 11.2 88.2 - - -
Versão do Sistema
Operacional 0.5 99.5 - - -
Observações de
Instalação 24.3 75.7 - - -
Outras
considerações 0.15 99.85 - - -
muito tempo, ou porque não se tem consciência de sua importância, ou, ainda, porque se tem dúvidas de que valores atribuir (WARPECHOWSKI e OLIVEIRA, 2005). Outro aspecto importante, exposto em Sicilia (2006), é que, de modo geral, não há preocupação com os detalhes concretos dos requisitos das funções que o registro dos metadados farão uso. Mesmo que algumas funções dos metadados sejam tácitas, como por exemplo, o elemento “Assunto” que é destinado à função de descoberta, ou o elemento “Custo” destinado a uma atividade de compra. Além disso, muitas vezes os metadados escolhidos pelos indexadores para serem preenchidos não são os mesmos escolhidos pelos usuários para fazer buscas, como constatado em Najjar et al.
(2005), o que também pode complicar a recuperação dos OAs. Um exemplo disso é que os campos de metadados usados por mais de 50% dos indexadores, tais como Granularidade, Contexto Didático e Densidade Semântica, não são usados pela maioria dos usuários que fazem buscas de objetos de aprendizagem no ARIADNE KPS (NAJJAR e DUVAL, 2006).
Figura 1: Freqüência de campos usados pelos usuários do ARIADNE KPS em consultas (NAJJAR e DUVAL, 2006).
buscas são da categoria Geral, tais como Título, Língua do Documento e Sobrenome do Autor. Outros dois campos bastante utilizados por eles são o Tipo de Ciência e Disciplina, ambos pertencentes à categoria semântica.
2.2. Recuperação de experiência docente
Devido à abordagem de metadados usada para o registro das experiências docentes, o doceNet compartilha dos problemas citados na seção 2.1 em torno da recuperação de OAs. O preenchimento dos metadados de maneira inconsistente, sem um vocabulário estruturado, com ambigüidades e problemas semânticos, dificulta a recuperação das experiências e OAs relevantes, podendo levar o uso do doceNet a ser pouco eficaz.
Para que um recurso possa ser recuperado de forma estruturada é necessário que os metadados sejam preenchidos de forma consistente e com valores não apenas sintáticos, mas com riqueza semântica em seu vocabulário. Dessa forma, uma das vertentes de iniciativas na literatura em torno de metadados endereçando diretamente ao problema da recuperação de OAs, diz respeito à metadados semânticos. Destaca-se o trabalho de Araujo e Ferreira (2004), no qual os autores propõem o desenvolvimento de aplicações educacionais nas quais os OAs sejam baseados em ontologias, de forma a permitir uma pesquisa mais estruturada. Segundo Araujo e Ferreira (2004), uma determinada ontologia “[...] deve prover um vocabulário que explicite os materiais de aprendizagem e permita anotá-los, bem como um conjunto de relacionamentos entre os termos do vocabulário, para propiciar inferências [...]”.
Também, em Sicilia e Barriocanal (2005), Sicilia (2006) e Sánchez-Alonso et al. (2007) são defendidos os benefícios da utilização de ontologias
para expressar metadados para OAs, dentre os quais, a maior riqueza do formalismo de representação. A utilização de ontologias para descrever conteúdos de aprendizagem, para os autores, permite a extensão de especificações correntes incluindo-se relações adicionais e axiomas entre itens de metadados, sem quebrar sua semântica original.
ambiente, permite o registro de experiências de maneira não-estruturada, mas com a possibilidade de anotá-las semanticamente, procurando explicitar o seu contexto e significado, com o intuito de promover recuperações mais consistentes de experiências docentes. Pretende-se, também, que os dados estruturados desenvolvidos dinamicamente no experiWiki sejam a base para a geração de metadados semânticos para o doceNet. Sendo assim, espera-se contribuir às pesquisas de reuso de Objetos de Aprendizagem, uma vez que os OAs do ambiente estão atrelados às respectivas experiências, sendo recuperados juntamente com elas.
Espera-se também proporcionar uma contribuição no desenvolvimento de sistemas que dão apoio ao docente quanto à elaboração de aulas, uso de materiais instrucionais e suas melhores práticas. Muito embora as informações estruturadas sejam relevantes à recuperação das experiências, ao ponto de se buscar suporte em recursos do desenvolvimento de ontologia, busca-se também neste trabalho meios de facilitar o registro dessas experiências pelos docentes. Em virtude disso, foi escolhido o uso das abordagens de Wi kis Semânticos para facilitar o registro das experiências e
melhorar a forma de acesso e apresentação atuais das informações. Assim, espera-se contribuir também para as pesquisas voltadas ao uso de sistemas
Wi ki Semânticos no contexto educacional e da gestão do conhecimento, onde
3. REGISTRO NÃO-ESTRUTURADO E RECUPERAÇÃO SEMÂNTICA DE
EXPERIÊNCIA DOCENTE
Neste capítulo são apresentados conceitos e tecnologias que sustentam a definição de um ambiente para compartilhamento de experiência docente, introduzida no capítulo 1 e proposta deste trabalho, para o registro não-estruturado de experiência docente e a recuperação semântica dessas experiências. O ambiente proposto inclui dois ambientes e procedimentos de manutenção da interface entre eles. De um lado, um ambiente preexistente de estrutura já definida e, de outro lado, um ambiente com estrutura emergente com base no modelo Wi ki Semântico.
Na seção 3.1 são dados os conceitos de ontologia e na seção 3.2 é apresentada a Wi ki Wi ki Web, seu paradigma, vantagens e limitações.
Sustentada por esses dois pilares, na seção 3.3 é apresentado o Wi ki
Semântico e, entre outras coisas, as vantagens que as anotações semânticas que esses ambientes permitem podem trazer. Na seção 3.4 são apresentadas algumas discussões em torno de alguns tipos de Wi kis Semânticos e como
esses w iki s trabalham e suportam os conceitos de ontologias. Na seção 3.5 são
apresentados alguns dos benefícios que a Web Semântica pode trazer para Gestão do Conhecimento das organizações.
3.1. Ontologia
Uma ontologia é uma especificação formal e explícita de uma conceituação (GRUBER, 1993). Esta definição é frequentemente utilizada na área de Ciência da Computação, onde a ontologia tem surgido como importante área de pesquisa. Devedžić (2006) faz uma breve análise sobre a
Pode-se dizer que a ontologia de certo domínio diz respeito a sua terminologia, a todos os conceitos essenciais desse domínio, sua classificação, sua taxonomia, suas relações, incluindo hierarquias e restrições, e também sobre os axiomas do domínio (DEVEDŽIĆ, 2006).
Ontologias são largamente usadas nas áreas de Engenharia do Conhecimento, Inteligência Artificial e Ciência da Computação, em diversas aplicações como, por exemplo, as relacionadas à gestão do conhecimento, recuperação de informação, comércio eletrônico, educação e em novos campos como a Web Semântica (GÓMEZ-PÉREZ et al., 2003). A Web Semântica é a nova geração
da Web que procura representar a informação de tal forma que possa ser usada por máquinas, não apenas para a apresentação na tela de um computador, mas também para automação, integração e reuso entre aplicações (DEVEDŽIĆ,
2006).
Embora a Web atual seja considerada um grande repositório e um veículo de informações, principalmente em forma de textos e de imagens, a maioria dessas informações atualmente é disponibilizada por meio de linguagens (como HTML, por exemplo) cujo significado somente pessoas podem entender. Linguagens como HTML não fornecem muita capacidade para que essas informações possam ser entendidas e localizadas por programas11. É esse tipo de limitação que se pretende superar com a Web Semântica. Segundo Berners-Lee et al. (apud GÓMEZ-PÉREZ et al., 2003), a
Web Semântica não é uma Web separada, mas uma extensão da atual, na qual a informação é utilizada com um significado bem definido, aumentando a capacidade dos computadores trabalharem em cooperação com as pessoas. Para isso, há a necessidade de ontologias bem estruturadas e com capacidade de especificar, nos diversos domínios de interesse, descrições para conceitos de classes, seus relacionamentos e propriedades (LIMA, 2003).
De modo geral, ontologias “são utilizadas por pessoas, bancos de dados e aplicações que necessitam compartilhar informações pertencentes a um domínio” (LIMA, 2003). De acordo com Araujo e Ferreira (2004), “as próximas gerações de sistemas educacionais baseados na Web deverão ser desenvolvidas com embasamento em ontologias e o desenvolvimento da Web
Semântica também estará fortemente embasado em ontologias”. Para Devedžić
(2006), o primeiro passo para projetar um sistema de representação de conhecimento e seu vocabulário é a análise ontológica do domínio, uma vez que, sem uma ontologia, não pode haver um vocabulário que represente o conhecimento.
As ontologias codificam o conhecimento de um domínio, de forma que definições sobre os conceitos básicos do domínio e os relacionamentos entre eles possam ser usados por computadores, o que permite que o conhecimento seja reusado (LIMA, 2003). Assim, uma vez que o conhecimento essencial de certo domínio é disponibilizado na Web na forma de ontologias interconectadas, é criada uma base sólida para mais e mais aplicações inteligentes serem desenvolvidas no domínio, pois diminui o problema da aquisição do conhecimento (DEVEDŽIĆ, 2006).
Ontologias podem ser expressas como um conjunto de especificações explícitas em linguagem natural dos seres humanos, mas isso impede ou, pelo menos, dificulta o processamento dessas definições por computadores (DEVEDŽIĆ, 2006). Por isso, são requeridas linguagens formais para o
desenvolvimento de ontologias. Algumas dessas linguagens são abordadas na próxima seção.
3.1.1. Linguagens
Para Gómez-Pérez et al. (2003) a escolha da linguagem com a qual a
ontologia será desenvolvida é uma das chaves no processo de desenvolvimento de ontologia. Segundo os autores, geralmente a escolha da linguagem não é baseada na representação do conhecimento e os mecanismos de inferência necessários para a aplicação que usará a ontologia, mas por preferência individual do desenvolvedor.
“linguagens de marcação de ontologia” (GÓMEZ-PÉREZ et al., 2003). Por
meio de suas marcações (t ags), é possível obter informações mais precisas
sobre os documentos e possibilitar uma melhor interpretação pelas máquinas. Usando um exemplo simples, a palavra “manga” dependendo do contexto pode significar uma fruta, a parte de uma camisa ou uma história em quadrinhos japonesa (mangá). A sintaxe XML possibilita especificar qual significado está
sendo usado, eliminando, portanto, a ambigüidade.
Entretanto, a linguagem XML é muito limitada para especificação de ontologias e muitas outras linguagens têm sido desenvolvidas. Nessa seção, primeiramente serão abordados os conceitos das linguagens XML, XML Schema, RDF, RDF Schema. Em seguida, com base nos conceitos dessas linguagens, as linguagens para especificação de ontologias DAML+OIL e OWL serão tratadas.
3.1.1.1. XML e XML Schema
XML (Ext ensi ble Markup Language) é uma linguagem com um formato
simples e flexível derivado do SGML (St andard General iz ed Markup Language) que é um padrão internacional para descrever documentos
eletrônicos. XML é uma recomendação do consórcio W3C12 desde 1998, e foi projetada para descrever dados, tendo como foco o que os dados representam e não como apresentá-los. Sua flexibilidade está no fato de que as marcações de conteúdo dos documentos podem ser definidas livremente, pois não há um conjunto de marcações predefinidas. Por isso, XML pode ser usado para descrever documentos de estrutura arbitrária. Além disso, seus dados podem ser armazenados em texto comum.
Segundo Lima (2003), para que um documento XML seja considerado válido, deve ter associado a ele uma definição chamada DTD (Document Type Def initi on), que possui as restrições que o documento deve atender.
Entretanto, as definições expressas na DTD não contêm nenhuma semântica, sendo sua validação apenas sintática. Além disso, uma DTD oferece pouco suporte para restrições sobre o conteúdo dos elementos, a ordem dos elementos é fixa e a linguagem para a definição de uma DTD não é XML, mas uma notação própria.
XML Schema13, também uma recomendação do consórcio W3C, foi definida para superar algumas das limitações de DTDs. Essa linguagem fornece meios de definir a estrutura, o conteúdo, as restrições, os tipos de dados e as semânticas de documentos XML. Segundo Lima (2003), XML Schema é um progresso em relação às DTDs, pois possui tipos de dados definidos, codificação em XML e também por permitir restrições na faixa de valores aceitos por tipos de dados (tamanho máximo, precisão, etc.).
Contudo, apesar da linguagem XML permitir, por meio de suas marcações, uma estruturação arbitrária dos dados e também uma sintaxe sem ambigüidades, essas marcações não tratam semanticamente os dados. Assim, as marcações de um documento XML podem ter significado para as pessoas, mas não para as máquinas (DEVEDŽIĆ, 2006). XML Schema define
semântica para os documentos, porém, de forma limitada, permitindo, por exemplo, ambigüidades entre os termos. Baseadas em XML, as linguagens RDF e RDFS, que serão apresentadas a seguir, foram desenvolvidas com características que superam algumas limitações da linguagem XML.
3.1.1.2. RDF e RDFS
A linguagem RDF (Res our ce Descripti on Fr amework) foi desenvolvida
e recomendada pelo consórcio W3C para criar metadados (dados sobre dados) para descrever recursos da Web (GÓMEZ-PÉREZ et al., 2003). De acordo
com o consórcio W3C14 esta é uma linguagem de propósito geral para representar informações na Web, como, por exemplo, produtos de lojas on-line, catalogação de livros de uma biblioteca, etc.
RDF supre uma limitação apresentada pelo XML que é a ausência de semântica de um documento. Assim como foi apresentado anteriormente, as marcações de um documento XML são voltadas para a estruturação de documentos, mas não para serem interpretadas por máquinas. RDF permite apresentar através de metadados uma estrutura capaz de descrever recursos de uma forma que permite ser entendida pela máquina. Para isso, são usadas nos documentos marcações não apenas em termos de sintaxe, mas também de semântica.
13 http://www.w3.org/XML/Schema
As expressões em RDF são divididas em três componentes:
• Recurso (sujeito): identifica sobre o quê a expressão está tratando, isto é, qualquer objeto que possa ser descrito por uma expressão RDF e que tenha um URI como endereço na Web;
• Propriedade (predicado): define atributos ou relações usados para descrever um recurso;
• Declaração (objeto): que determina o valor da propriedade.
RDF fornece um mecanismo indiferente ao domínio, sem definir semânticas do domínio da aplicação e nem fazer suposições sobre um domínio particular (DEVEDŽIĆ, 2006). De fato, segundo Goméz-Pérez et al. (2003),
um modelo de dados RDF não faz qualquer suposição sobre a estrutura do documento que contém informação RDF, isto é, as declarações podem aparecer em qualquer ordem em uma ontologia. Uma declaração RDF pode ser representada na forma de uma tripla composta de predicado, sujeito e objeto, ou por grafos, também conhecidos como diagramas de nós e arcos (ARAUJO, 2003).
A tabela abaixo mostra um exemplo simples do modelo de representação RDF.
Tabela 3: Modelo de uma declaração RDF
Sujeito (recurso) http://foo.org/ Predicado (propriedade) Criador Objeto (valor) John Doe
Figura 2: Exemplo RDF em representação gráfica
A sintaxe RDF é baseada em XML, sendo sua linguagem chamada de RDF/XML. A Figura 3 mostra o equivalente ao exemplo da Figura 2, só que desta vez em formato RDF/XML serializada, que é a sintaxe que mostra toda a potencialidade do RDF.
Figura 3: Exemplo em formato RDF/XML serializada (Gil e Ratnakar, 2001).
Apesar de ser considerado um modelo padrão para a descrição de recursos com propriedades, o suporte dado por RDF à ontologia é muito limitado. O modelo de dados do RDF não possui mecanismos para definição de relações entre propriedades e recursos, ficando isso a cargo do RDF Schema (Res our ce Descripti on Fr amew ork Schema) ou simplesmente RDFS,
também desenvolvida pelo consórcio W3C (GOMÉZ-PÉREZ et al., 2003).
Segundo Lima (2003), “um esquema é um tipo de ontologia onde são definidos os termos que serão usados nos documentos RDF e o significado específico de cada termo. São justamente os esquemas que expressam a semântica dos documentos RDF”.
O RDFS fornece um vocabulário também baseado em XML para especificar classes e suas relações, definir propriedades e associá-las com classes e habilitar a criação de taxonomias (DEVEDŽIĆ, 2006). O termo
http://foo.org/ John Doe
RDF(S) é comumente referido a combinação de RDF e RDFS, pois nem o RDF e nem o RDFS isoladamente deveriam ser considerados linguagens de ontologia e sim linguagens para descrever metadados na Web (GOMÉZ-PÉREZ et al., 2003). De acordo com Goméz-Pérez et al. (2003), RDF(S)
fornece a maioria das primitivas básicas para a modelagem de ontologias, alcançando um balanço entre expressividade e “raciocínio” (r easoni ng). A
Figura 4 ilustra os conceitos de classe, subclasse e recurso no modelo RDFS, onde os recursos são agrupados por classes, propriedades e restrições. As classes são representadas por retângulos com bordas arredondadas e os recursos por um grande ponto preto. As setas são desenhadas partindo dos recursos e apontando para as classes que os definem. O retângulo que representa uma subclasse é desenhado dentro do retângulo que representa sua superclasse. Por exemplo, na Figura 4 a classe Property é superclasse da
classe C onstr aint Propert y.
Figura 4: Hierarquia de classes no modelo RDF Schema (BRICKLEY; GUHA, 2004).
É possível observar que tudo é descrito em declarações que são chamadas recursos e são instâncias da classe rdf s:Resour ce. A taxonomia das
Figura 5:Taxonomia das classes do modelo RDF(S) (GOMÉZ-PÉREZ et al., 2003).
Alguns conceitos em RDF(S) são similares aos conceitos de orientação a objetos em algumas linguagens de programação. A classe rdfs :Clas s, por
exemplo, é similar a noção de classe em orientação a objetos, pois representa um conceito genérico de tipo ou categoria (BRICKLEY e GUHA, 2004). Já a classe rdf :Propert y é similar a noção de atributo em orientação a objetos, e
define as propriedades das classes. As propriedades podem definir tanto uma classe quanto uma propriedade. Por exemplo, a propriedade rdfs :s ubCl ass Of
define que uma classe é subclasse de outra. A propriedade r df s:subPr opert yOf
permite a especialização de propriedades. Sendo assim, essas duas propriedades, r dfs :s ubClas sOf e rdfs :s ubPropert yOf, são usadas para definir
taxonomias de classes e taxonomias de propriedades respectivamente.
A Figura 6 mostra um exemplo de um esquema RDF(S) com algumas anotações dos autores Gil e Ratnakar (2001). Primeiramente, é necessário entender os conceitos de namespaces e URIs que são muito utilizados pelas
linguagens RDF e RDF Schema (e também em XML). O namespace de um
item ou elemento é o contexto ao qual ele pertence. Dessa maneira, são evitadas ambigüidades entre elementos de contextos diferentes. Assim, os
names paces são necessários para evitar colisões de nomes quando múltiplos
documentos da Web são combinados. Além disso, os namespaces também
permitem o uso de vocabulários predefinidos. Com o objetivo de assegurar que um names pace seja único, ele é identificado por um URI (Uni vers al Res our ce Identifi er), que em documentos XML, bem como em linguagens
Figura 6: Exemplo de um esquema RDF(S) (Gil e Ratnakar, 2001).
RDF(S) fornece um modelo padrão para descrever recursos Web, mas ainda assim é um modelo bastante simples se comparado com outras linguagens de representação do conhecimento. Frequentemente há a necessidade de primitivas mais ricas e expressivas para especificar semânticas formais na Web (DEVEDŽIĆ, 2006). Não há, por exemplo, maneira de dizer
3.1.1.3. DAML+OIL
DAML+OIL (CONNOLY, 2001) foi desenvolvida como uma extensão do modelo RDF(S) e tem como proposta principal permitir marcações semânticas de recursos Web. DAML+OIL tem uma abordagem orientada a objetos, descrevendo a estrutura de um domínio em termos de classes e propriedades (CONNOLY, 2001). A base de conhecimento do DAML+OIL é escrita em vocabulário DAML+OIL e contém 53 primitivas (14 classes, 38 propriedades e uma instância), sendo que duas classes e dez propriedades são equivalentes às classes e propriedades correspondentes em RDF(S) (GOMÉZ-PÉREZ et al., 2003). A Figura 7 mostra a taxonomia das classes do
DAML+OIL.
Figura 7: Taxonomia das classes da ontologia de representação de conhecimento DAML+OIL definida como extensão de RDF(S) (GOMÉZ-PÉREZ et al., 2003).
3.1.1.4. OWL
Segundo o consórcio W3C, a OWL (Web Ontol ogy Language)15 é
designada para aplicações que precisam que o conteúdo de informações sejam processados e não para as aplicações que apenas apresentam a informação para as pessoas. Assim como seus predecessores, DAML e OIL, o vocabulário da OWL inclui um conjunto de elementos e atributos da linguagem XML, que são usados para definir termos do domínio e suas relações na ontologia (DEVEDŽIĆ, 2006).
OWL cobre a maioria das características do DAML+OIL e dá novo nome a muitas de suas primitivas, pois nem sempre eram fáceis de entender para usuários não especialistas (GOMÉZ-PÉREZ et al., 2003). Segundo
Devedžić (2006), atualmente OWL é a principal linguagem para representar
ontologias e também uma linguagem universal da Web Semântica que pode habilitar máquinas a interpretarem dados e fazer inferências.
Segundo Smith et al. (2004), a linguagem OWL fornece três
sub-linguagens expressivas que são projetadas para serem usadas de acordo com a necessidade dos desenvolvedores e usuários:
• OWL Lite busca atender usuários que necessitam apenas de classificações hierárquicas simples e restrições também simples. Assim, a especificação de algumas restrições na OWL Lite é bastante restrita, como por exemplo, os valores de cardinalidade são apenas 0 ou 1;
• OWL DL tem como propósito a expressividade máxima, mas garantindo que todas as conclusões e decisões – por meio de mecanismos de inferências - sejam computáveis e em tempo finito. Inclui todas as construções da linguagem OWL, porém com restrições, como, por exemplo, a separação de tipos (uma classe não pode ser uma instância ou propriedade e uma propriedade também não pode ser uma instância ou uma classe). A sigla DL possui correspondência com a lógica descritiva (Descripti on L ogi cs);
A OWL Full é uma extensão da OWL DL que, por sua vez, é uma extensão da OWL Lite. Assim, segundo Smith et al. (2004), toda ontologia
válida em OWL Lite também é válida em OWL DL. Do mesmo modo, toda ontologia válida em OWL DL também é válida em OWL Full. É importante ressaltar que o inverso dessa relação não é verdadeiro.
Em suma, OWL DL possui 40 primitivas, sendo 16 classes e 24 propriedades e fornece regras e definições similares ao RDF(S). Além disso, permite a especificação de restrições e relações entre recursos, incluindo cardinalidade, domínio e abrangência (r ange) das restrições, além de regras
de união, disjunção, simetria, inverso e transitividade. Segundo Devedžić
(2006), um dos grandes recursos da OWL é a extrema riqueza para descrever relações entre classes, propriedades e instâncias. Por ser baseado em lógica descritiva, mecanismos de inferências (também chamados de mecanismos de “raciocínio”) oferecem suporte para ontologias construídas com OWL-DL. Segundo Goméz-Pérez et al. (2003), máquinas de inferência ou r eas oner
usadas para OIL e DAML+OIL podem ser adaptadas para OWL, devido às similaridades entre essas linguagens. Como exemplos de máquinas de inferência para OWL, podemos citar: Euler16, Hoolet17, Bossam18, FACT++19, Racer20 e Pellet21.
Com as máquinas de inferência é possível, automaticamente, fazer classificações nos conceitos da ontologia OWL e detectar inconsistências na taxonomia dos conceitos, com base nas descrições explícitas definidas na linguagem (GOMÉZ-PÉREZ et al., 2003). Uma máquina de inferência pode,
por exemplo, testar quando uma classe é ou não subclasse de outra classe, podendo fazer inferências na hierarquia da ontologia. Ou ainda, considerar uma classe inconsistente, pois suas descrições não permitem que ela possua instâncias.
Para finalizar, será exposto como as linguagens abordadas nessa seção se inter-relacionam, segundo Lima (2003):
16http://www.agfa.com/w3c/euler/ 17http://owl.man.ac.uk/hoolet/ 18http://bossam.wordpress.com/ 19http://owl.man.ac.uk/factplusplus/