U
niversidade de
S˜
ao
P
aulo
Faculdade deFilosofia, Ciencias eˆ Letras deRibeirao˜ Preto
R
ayner
H
arold
M
ontes
C
ondori
Análise de textura em imagens baseado em medidas de
complexidade
R
ayner
H
arold
M
ontes
C
ondori
Análise de textura em imagens baseado em medidas de
complexidade
Dissertação apresentada à Faculdade de
Filo-sofia, Ciências e Letras de Ribeirão Preto da
Universidade de São Paulo como parte das
exi-gências para a obtenção do título de Mestre em
Ciências.
Área de Concentração:
Física Aplicada a Medicina e Biologia.
Orientador:
Alexandre Souto Martinez.
Versão corrigida
Versão original disponível na FFCLRP-USP
Autorizo a reprodução e divulgação total ou parcial deste trabalho, por qualquer meio convencional ou eletrônico, para fins de estudo e pesquisa, desde que citada a fonte.
FICHA CATALOGRÁFICA
Montes Condori, Rayner Harold
Análise de textura em imagens baseado em medidas de complexidade/Rayner Harold Montes Condori; orientador: Alexandre Souto Martinez. - - Ribeirão Preto, 2015.
63 f. : il.
Dissertação (Mestrado) - - Faculdade de Filosofia, Ciências e Letras de Ribeirão Preto, Universidade de São Paulo, 2015.
Inclui Bibliografia.
Nome: MontesCondori, Rayner Harold
Título: Análise de textura em imagens baseado em medidas de complexidade
Dissertação apresentada à Faculdade de Filosofia, Ciências e Letras de Ribeirão Preto da Universidade de São Paulo como parte das exigências para a obtenção do título de Mestre em Ciências.
Aprovado em: / / .
Banca Examinadora
Prof(a). Dr(a). : Instituição:
Julgamento: Assinatura:
Prof(a). Dr(a). : Instituição:
Julgamento: Assinatura:
Prof(a). Dr(a). : Instituição:
v
A
gradecimentos
Aos meus pais Juvenal e Giovanna, e aos meus irmãos Steve e Johnny, pelo incentivo e apoio providenciado ao longo da minha vida.
Ao meu orientador, Prof. Dr. Alexandre Souto Martinez, pela amizade e orientação constante para o desenvolvimento da minha pesquisa.
Ao meu segundo orientador, Prof. Dr. Odemir Martinez Bruno do Instituto de Física de São Carlos (IFSC), pela guia em relação aos métodos de análise de imagens, necessários para minha pesquisa.
Ao Prof. Dr. Bernard De Baets, e ao Dr. Jan Marcel Baetens da unidade de pesquisa KERMIT, universidade de Ghent, Bélgica, pela orientação no uso das medidas de com-plexidade.
Aos colegas do Laboratório de Modelagem de Sistemas Complexos: Brenno Caetano Troca Cabella, Cristiano Roberto Fabri Granzotti, Enock de Almeida Andrade Neto, Fer-nando Meloni, Gilberto Medeiros Nakamura, Juan Herbert Chuctaya Humari, Olavo Hen-rique Menin e Tiago José Arruda pela troca de conhecimentos e ajuda recebida.
Aos colegas do Laboratório do Grupo de Computação Científica do IFSC, especialmente à Gisele Helena Barboni Miranda, Humberto Antunes de Almeida Filho, Lucas Correia Ribas, Marcos William da Silva Oliveira, Mariane Barros Neiva, Marina Jeaneth Machi-cao Justo e Núbia Rosa da Silva, pelas dicas e apoio fornecido durante o tempo que morei em São Carlos.
Aos amigos pós-graduandos da Universidade de Ghent, especialmente à Andreia, Raúl, Michael, Wouter, Niels e Francisca pelos momentos de alegria e ideias trocadas durante os meses que trabalhei na Bélgica.
À todos os amigos pós-graduandos da USP em São Carlos e Ribeirão Preto que sempre me motivaram a cumprir os meus sonhos, especialmente à Emérita, Giancarlo, Marleny, Yuly, Jhon, Jorge, Alain e Ana Cecilia.
Ao programa de FAMB da FFCLRP, ao IFSC, e aos professores e funcionários que, direta ou indiretamente, colaboraram neste trabalho.
ix
Life is complex in its expression, involving more than percipience, namely desire, emotion, will, and feeling.
R
esumo
MONTES CONDORI, R. H.Análise de textura em imagens baseado em medidas de complexidade. 2015. 63 f. Dissertação (Mestrado - Programa de Pós-Graduação em Física Aplicada a Medicina e Biologia) - Faculdade de Filosofia, Ciências e Letras de Ribeirão Preto, Universidade de São Paulo, Ribeirão Preto, 2015.
pode ser usado para incrementar as taxas de acerto em outras tarefas que envolvam clas-sificação de texturas. Finalmente, com a amostragem CDPA também se obtém resultados significativos, que podem ser melhorados em trabalhos futuros.
A
bstract
MONTES CONDORI, R. H. Image Texture Analysis based on complex measures. 2015. 63 f. Dissertation (M.Sc. - Postgraduate program in Physics Applied to Medicine and Biology) - Faculty of Philosophy, Sciences and Letters, University of São Paulo, Ri-beirão Preto, 2015.
L
ista de
F
iguras
2.1 40 tipos diferentes de textura tiradas do banco de imagens Brodatz. . . 6
2.2 Operações na transformada de Fourier. (a) Imagem original, (b) logaritmo do espectro de Fourier da imagem original, (c) logaritmo do espectro de Fourier deslocado para posicionar o componente de frequência nula no
centro, (d) simetria do espectro de Fourier . . . 19
3.1 Distâncias d = {1,2,3,4} e ângulosθ = {0◦,45◦,90◦,135◦}mais usados
na construção de matrizes de co-ocorrência de níveis de cinza (GLCM) em uma imagem típica. O elemento de cor preto que está no centro é o pixel de referência e os elementos cinzas são os pixeis vizinhos. . . 25
3.2 Conjunto de 40 filtros de Gabor em diferentes escalas e orientações. Eles ao ser convoluídos com uma imagemI, permitem fazer uma análise
multi-resolução no domínio espaço-frequência dessa imagemI. . . 29
3.3 Aplicação do operador de padrões binários locais. (a) Imagens de textura originaisI, (b) imagens transformadasI′. . . 30
4.2 Processo de amostragem radial do espectro de Fourier normalizado Mi′:
(a) Cinco diâmetros, separados um de outro pelo mesmo ângulo θ, ao
longo do qual a amostragem é feita, (b) gráfico dos valores da amostra ra-dialai,4, elas foram plotadas como função das suas posições sequenciais
começando pelo índice 1 até o tamanho do conjunto, (c) cinco diâme-tros divididos em dois segmentos ao longo do qual M′i é amostrada, (d)
gráfico dos valores de magnitude da amostra radialai,4 depois de serem
removidos aqueles valores que pertenciam ao círculo concêntrico pequeno. 37
4.3 Seis círculos concêntricos ao longo do qual os valores de magnitude de
M′i são amostrados. . . 38
4.4 Amostragem por caminhadas determinísticas parcialmente auto-repulsivas. (a) Pontos de interseção dos raios e círculos na metade direita do espectro
M′i, (b) caminhadas determinísticas parcialmente auto-repulsivas a partir
de cada ponto de interseção. . . 39
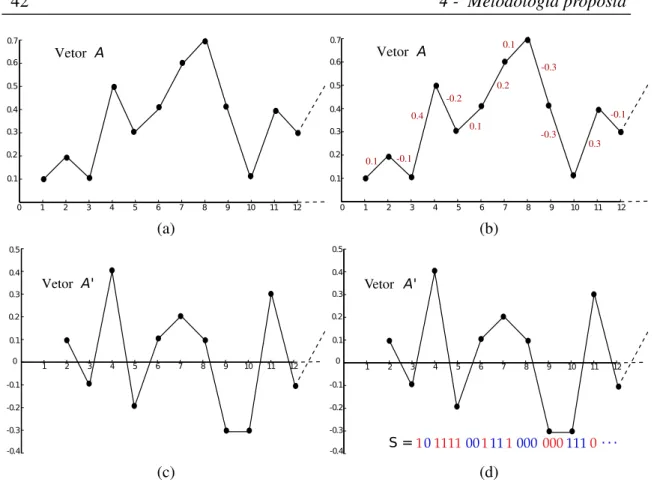
4.5 Processo de binarização de amostras com valores decimais. (a) Frag-mento de uma amostraA, (b) substração dos valores adjacentes deA, (c)
a derivadaA′, (d) construção da sequência bináriaS usando a derivadaA′
e o parâmetro de escalaτ=0.1. . . 42
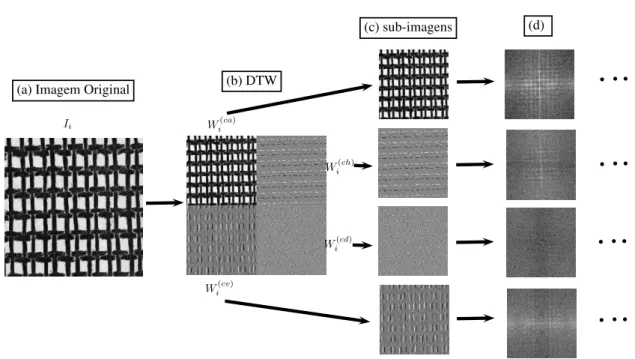
4.6 Transformada discreta de wavelet. (a) Imagem original, (b) a transfor-mada discreta de wavelet em um nível, (c) as quatro imagens da trans-formada trabalhadas separadamente, (d) aplicação do método de amos-tragem descrito nas subseções prévias . . . 44
5.1 Banco de dados Brodatz: Quatro classes de texturas, cada uma com quatro imagens. Este banco é o mais conhecido e estudado na área de Visão Computacional. . . 46
5.2 Banco USPtex: Quatro classes de texturas, cada uma com quatro imagens. Este banco contem uma grande quantidade de diferentes classes de textura. 46
xvii
5.4 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas de acerto alcançadas no banco Brodatz: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características do expoente de Hurst sobre 5, 20, 40, 60, 75 e 135 raios. . . 48 5.5 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas
de acerto alcançadas no banco USPtex: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características do expoente de Hurst sobre 5, 20, 40, 60, 75 e 135 raios. . . 49 5.6 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas
de acerto alcançadas no banco UIUC: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características do expoente de Hurst sobre 5, 20, 40, 60, 75 e 135 raios. . . 50 5.7 Taxas de classificação correta em função do tamanho dos vetores de
carac-terísticas gerados pelo expoente de Hurst nos bancos de imagens Brodatz, USPtex e UIUC. O erro padrão de todas as taxas de acerto é menor ou igual a±0.3%. . . 51
5.8 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas ta-xas de acerto alcançadas no banco Brodatz: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características da complexidade de Lempel-Ziv sobre 5, 20, 40, 60, 75 e 135 amostras radiais. . . 52 5.9 Influência dos parâmetros de raio interno (Rint) e raio externo (Rext) nas
taxas de acerto alcançadas no banco USPtex: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características da complexidade de Lempel-Ziv sobre 5, 20, 40, 60, 75 e 135 raios. . . 53 5.10 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas
de acerto: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características da complexidade de Lempel-Ziv sobre 5, 20, 40, 60, 75 e 135 raios no banco UIUC . . . 54 5.11 Taxas de classificação correta em função do tamanho dos vetores de
5.12 Taxas de classificação correta em função do tamanho dos vetores de ca-racterísticas gerados pelo expoente de Lyapunov nos bancos de imagens Brodatz, USPtex e UIUC. O erro padrão de todas as taxas de acerto é menor ou igual a±0.3%. . . 56
5.13 Taxas de acerto obtidas por número de características. A comparação das três medidas de complexidade estudadas é feita por cada banco de imagens. O erro padrão de todas as taxas de acerto é menor ou igual a ±0.4%. . . 58
5.14 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas de acerto alcançadas no banco de imagens Brodatz: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características da complexi-dade de Lempel-Ziv sobre 5, 15, 20, 40, 60 e 70 amostras circulares. . . . 59
5.15 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas ta-xas de acerto alcançadas no banco USPtex: gráfico de barras 3-D das taxas de acerto obtidas pelos vetores de características da complexidade de Lempel-Ziv sobre 5, 15, 20, 40, 60 e 70 amostras circulares. . . 60
5.16 Influência dos parâmetros raio interno (Rint) e raio externo (Rext) nas taxas de acerto alcançadas no banco UIUC. Os gráficos de barras 3-D represen-tam as taxas de acerto obtidas pelos vetores de características da comple-xidade de Lempel-Ziv sobre 5, 15, 20, 40, 60 e 70 amostras circulares. . . 61
5.17 Taxas de classificação correta em função do tamanho dos vetores de carac-terísticas φ(LZ)i , gerados pela aplicação da complexidade de Lempel-Ziv
sobre vetores amostrados circularmente nos bancos de imagens Brodatz, USPtex e UIUC. O erro padrão de todas as taxas de acerto é menor ou igual a±0.2%. . . 62
5.18 Taxas de acerto em função do tamanho dos vetores de característicasφ(Hu)i
eφ(Ly)i , gerados pela aplicação do expoente de Hurst e Lyapunov
xix
5.19 Taxas de acerto obtidas por número de características. A comparação das três medidas de complexidade estudadas é feita para cada banco de imagens. O erro padrão de todas as taxas de acerto é menor ou igual a ±0.3%. . . 65
5.20 Taxas de acerto atingidas pela concatenação de vetores de características resultantes da amostragem radial e circular em cada banco de imagens. A complexidade de Lempel-Ziv foi aplicada sobre todas as amostras que formam o vetor de características. . . 68 5.21 Taxas de acerto atingidas pela concatenação de vetores de
característi-cas resultantes da amostragem radial e da amostragem circular em cada banco de imagens. A complexidade de Hurst foi aplicada sobre todas as amostras que formam o vetor de características. . . 70 5.22 Taxas de acerto atingidas pelos descritores de Lempel-Ziv ao aplicar a
L
ista de
T
abelas
5.1 Comparação das melhores taxas de acerto atingidas pelo enfoque sem wavelets (SW) e o enfoque com wavelets (CW) usando a amostragem radial. A comparação foi feita por cada medida de complexidade e para cada banco de dados estudado .O erro padrão de todas as taxas de acerto é menor ou igual a±0.4%. . . 59
5.2 Comparação das melhores taxas de acerto atingidas pelo enfoque sem wavelets (SW) e o enfoque com wavelets (CW) usando a amostragem circular. A comparação foi feita por cada medida de complexidade e para cada banco de dados estudado. O erro padrão de todas as taxas de acerto é menor ou igual a±0.3%. . . 66
5.3 Taxas de acerto da concatenação dos vetores de características resultantes da amostragem radial e da amostragem circular no banco de imagens Bro-datz. A complexidade de Lempel-Ziv foi aplicada sobre todas as amos-tras que formam o vetor de características. O erro padrão de cada taxa de acerto atinge um valor máximo de±0.3%. . . 67
5.4 Análise do parâmetro R: Taxas de acerto obtidas usando a amostragem
por caminhadas determinísticas parcialmente auto-repulsivas nos bancos de imagens: Brodatz, USPtex e UIUC. Os vetores de características foram calculados com a complexidade de Lempel-Ziv. O erro padrão de todas as taxas de acerto é menor ou igual a±0.2%. . . 72
5.5 Análise do limiar t0: Taxas de acerto obtidas usando a amostragem por
5.6 Taxas de acerto dos vetores de características resultantes da concatenação de descritores dos métodos tradicionais com os descritores de Lempel-Ziv calculados sobreNrad amostras radiais. O banco utilizado foi o Brodatz. O parâmeroNradequivale ao número de características adicionadas. Esses resultados tem um erro padrão menor ou igual a±0.3%. . . 75
5.7 Taxas de acerto dos vetores de características resultantes da concatenação de descritores dos métodos tradicionais com os descritores de Lempel-Ziv calculados sobreNciramostras circulares. O banco utilizado foi o Brodatz. O parâmeroNcirequivale ao número de características adicionadas. Essas taxas de acerto apresentam um erro menor ou igual a±0.2%. . . 77
5.8 Taxas de acerto obtidas pelos vetores de características resultantes da con-catenação de descritores de Lempel-Ziv calculados sobre Nrad amostras radiais com os descritores dos métodos tradicionais. Os testes foram re-alizados no banco USPtex. O parâmero Nrad equivale ao número de ca-racterísticas adicionadas. O erro padrão para todos as taxas de acerto foi menor ou igual a±0.2%. . . 78
5.9 Taxas de acerto obtidas pelos vetores de características resultantes da con-catenação de descritores de Lempel-Ziv calculados sobre Ncir amostras circulares com os descritores dos métodos tradicionais. Os testes foram realizados no banco USPtex. O parâmeroNcir equivale ao número de ca-racterísticas adicionadas. Todos os resultados tem um erro padrão menor ou igual a±0.2% . . . 79
xxiii
L
ista de
A
breviaturas e
S
iglas
CDPAg Caminhadas Determinísticas Parcialmente Auto-repulsivas em grafos
CLZ Complexidade de Lempel-Ziv
FM Métodos Fractais
GLCM Matrizes de Co-ocorrência em Níveis de Cinza
GW Wavelets de Gabor
LBP Padrões Binários Locais
MC Medidas de Complexidade
RM Ressonância Magnética
ROI Região de Interesse
TC Tomografia Computorizada
S
um
ario
´
Lista de Figuras xv
Lista de Tabelas xxi
Lista de Abreviaturas e Siglas xxv
1 Introdução 1
2 Fundamentos teóricos 5
2.1 Textura . . . 5 2.1.1 Análise . . . 5 2.1.2 Aplicações na área médica e biológica . . . 7 2.2 Medidas . . . 10 2.2.1 Complexidade de Lempel-Ziv . . . 10 2.2.2 Expoente de Lyapunov . . . 12 2.2.3 Expoente de Hurst . . . 14 2.3 Transformadas em imagens . . . 16 2.3.1 Transformada de Fourier . . . 16 2.3.2 Transformada discreta de wavelet . . . 19 2.4 Caminhadas determinísticas parcialmente auto-repulsivas . . . 20
3 Métodos de análise de textura tradicionais 23
3.5 Caminhadas determinísticas parcialmente auto-repulsivas em grafos . . . 31 3.6 Considerações finais . . . 32
4 Metodologia proposta 33
4.1 Pré-processamento: transformada discreta de Fourier . . . 34 4.2 Processo de amostragem . . . 34 4.2.1 Radial . . . 36 4.2.2 Circular . . . 36 4.2.3 Caminhadas determinísticas parcialmente auto-repulsivas . . . 38 4.3 Extração de características . . . 39 4.4 Concatenando descritores . . . 42 4.5 Transformada discreta de wavelet e transformada discreta de Fourier . . . 43 4.6 Considerações finais . . . 43
5 Experimentação e resultados 45
5.1 Descrição dos bancos de dados . . . 45 5.2 Detalhamento dos experimentos . . . 47 5.3 Análise da amostragem radial . . . 47 5.3.1 Expoente de Hurst . . . 48 5.3.2 Complexidade de Lempel-Ziv . . . 52 5.3.3 Expoente de Lyapunov . . . 55 5.3.4 Medidas de complexidade estudadas . . . 56 5.3.5 Transformada discreta de wavelet nos bancos de imagens . . . . 57 5.4 Análise da amostragem circular . . . 57 5.4.1 Complexidade de Lempel-Ziv . . . 60 5.4.2 Expoente de Hurst e Lyapunov . . . 63 5.4.3 Medidas de complexidade estudadas . . . 63 5.4.4 Transformada discreta de wavelet nos bancos de imagens . . . . 64 5.5 Análise da amostragem radial e circular . . . 66 5.6 Análise da amostragem por caminhadas determinísticas parcialmente
xxix
5.6.3 Limiart0 . . . 73
5.7 Amostragem radial e amostragem circular e métodos tradicionais . . . 73 5.8 Considerações finais . . . 81
6 Conclusões 85
6.1 Contribuições . . . 86 6.2 Trabalhos futuros . . . 86 6.3 Trabalhos gerados . . . 87
C
ap
´
itulo
1
I
ntrodu
c
¸
ao
˜
A palavratexturaé muito utilizada para se referir ao sentimento relativo ao toque
em um objeto. Para efeitos de classificação, termos comorugoso,lisooumaciosurgiram
dessa experiência. Existe também aquela textura que esta presente nas imagens conhecida
portextura visual, embora ainda não há consenso sobre a sua definição exata [1]. Ela pode
ser entendida como repetições de padrões simples ou complexos sobre uma superfície. Esses padrões podem ser copias idênticas, aparecendo repetidamente, ou com mudanças menores. Além disso, existe uma relação entre a textura visual e a textura dos objetos físicos que são capturados por essas imagens [2]. Portanto, a análise deste tipo de textura é muito útil para o reconhecimento de objetos.
Neste sentido, a análise de texturas visuais em imagens é uma das mais básicas e populares áreas de pesquisa em visão computacional. Ela é de grande importância em muitas disciplinas tais como ciências médicas [3], botânica [4, 5], geologia [6], senso-riamento remoto [7]. A análise de texturas tem como objetivo representar a imagem envolvida através de um conjunto de descritores (valores numéricos), essa representação é usualmente chamada devetor de características(VC). A obtenção desse vetor precisa
de um ou vários métodos caracterização os quais vão extrair algumas informações rele-vantes da imagem. Com um conjunto deVCs é possível fazer uma grande variedade de
tarefas, como por exemplo Segmentação de Texturas [8, 9, 10], Classificação de Texturas ou Recuperação de imagens por conteúdo [11, 12].
métodos com um enfoque mais estrutural, onde em uma imagem são descobertas e anali-sadas as texturas fundamentais (outexels) contidas na imagem [17, 9]. São também bem
famosas as técnicas que envolvem cálculo de dimensões fractais [18, 19]. Finalmente existem trabalhos que utilizam Padrões Binários Locais [20, 21].
Além dos métodos mencionados no paragrafo anterior, existem outros métodos de caracterização baseados em Medidas de Complexidade (MC) tais como a Comple-xidade de Lempel-Ziv (CLZ), o Exponente de Hurst (EH) e o Exponente de Lyapunov (EL). Normalmente, eles são aplicados em sinais unidimensionais (1-D) tais como Ele-trocardiogramas, Encefalogramas ou séries temporais [22, 23, 24, 25, 26] também tem algumas tentativas de uso em imagens (sinais bidimensionais 2-D) [27, 28], porém sem muito sucesso.
As MC têm boa performance em medições de sinais 1-D, dessa forma elas conse-guem resolver diversos problemas. A principal motivação deste projeto foi a importância de explorar e avaliar as MC em imagens (sinais 2-D), especificamente na análise de textu-ras visuais, tentando trazer as boas qualidades destas medidas em sinais 1-D para realizar está tarefa. Também é importante anotar que embora a análise de texturas tenha sido estu-dada consideravelmente, ainda há muita necessidade de explorar técnicas cada vez mais precisas e eficientes que satisfaçam os requerimentos da grande variedade de aplicações que esta área possui.
O objetivo geral desta dissertação é analisar atextura visualdas imagens em níveis
de cinza, utilizando um conjunto de métodos de caracterização baseados em Medidas de Complexidade (MC) tais como a Complexidade de Lempel-Ziv (CLZ), o Exponente de Hurst (EH) e o Exponente de Lyapunov (EL). Como foi mencionado, as MC normalmente são usados para analisar sinais 1-D. Porém, é possível medir sinais 2-D se conseguirmos amostrá-las eficientemente, ou seja, extrair da imagem de interesse um conjunto de sinais 1-D com a informação representativa necessária para realizar medições. Portanto, o ob-jetivo específico deste trabalho foi determinar o(s) tipo(s) de amostragemque são mais
1 - Introdução 3
A metodologia consiste em encontrar o tipode pré-processamento(Transformada
de Fourier, Transformada de Wavelet) que deve ser feito na imagem para facilitar o pro-cesso de amostragem.
Nesta dissertação, os vetores de características calculados foram utilizados na ta-refa de Classificação de Texturas. Em outras palavras, o problema a ser resolvido foi
atribuir a cada imagem para alguma classe de um conjunto de classes de texturas pre-definidas.
A organização dos capítulos e seções desta dissertação segue abaixo.
O Capítulo 2 contem os fundamentos teóricos. Esse capítulo começa introduzindo algumas definições detexturae a importância dela na área de Visão Computacional.
Tam-bém apresentamos o levantamento bibliográfico e enumeramos as aplicações que ela tem na área médica e biológica. Depois, são explicadas as Medidas de Complexidade (MC), mostramos como é feito seu cálculo computacional, tempos de execução e aplicações. Em seguida, são apresentadas as transformações 2-D que foram utilizadas como parte do pré-processamento das imagens com textura, seus fundamentos matemáticos e algoritmos são explicados bem como as avantagens e desavantagens de cada uma delas. Finalmente defi-nimos as Caminhadas Determinísticas Parcialmente Auto-repulsivas (CDPA), explicando seu cálculo e parâmetros correspondentes.
No Capítulo 3, descrevemos os métodos de análise de textura tradicionais. Entre eles temos: matrizes de co-ocorrência em níveis de cinza (em inglês Gray Level Co-occurrence Matrix ou GLCM), wavelets de Gabor (GW), padrões binários locais (em inglês Local Binary Patterns ou LBP), e caminhadas determinísticas parcialmente auto-repulsivas em grafos (CDPAg). Nesse capítulo explicamos a teoria por trás de cada um dos métodos, bem como as suas implementações, complexidade computacional, vanta-gens e desavantavanta-gens. Finalmente, apresentamos as conclusões do capítulo.
exemplo, a complexidade de Lempel-Ziv somente recebe sequências binárias ou com um alfabeto finito. Portanto, foi necessário adequar os valores numéricos da imagem para poder trabalhar com essa medida. Em seguida, a explicação da conformação dos vetores de características é feita junto com uma análise de complexidade de tempo. Finalmente, temos as considerações finais do capítulo.
No Capítulo 5, apresentamos os experimentos feitos junto com os resultados ob-tidos. Começamos descrevendo as características dos três bancos de imagens onde foram realizados os testes (banco Brodatz, USPtex e UIUC), apresentando os desafios de cada uma. Depois descrevemos detalhadamente os experimentos, e mostramos as taxas de acerto conseguidas por cada método de amostragem e cada medida de complexidade uti-lizada nos três bancos de imagens analisados.
C
ap
´
itulo
2
F
undamentos te
oricos
´
Este capítulo apresenta as definições e informações necessárias para entender esta dissertação. Começamos definindotextura e a sua análise em imagens. Enfatizamos a
importância dessa análise em aplicações na área médica e biológica. Depois introduzi-mos os métodos de medidas de complexidade em sinais unidimensionais, explicando as definições básicas e os algoritmos computacionais envolvidos.
2.1 Textura
A textura é um descritor globalmente difundido e facilmente reconhecível pelo
olho humano, no entanto, é um termo difícil de definir. Na Ref. [2] é explicado que a decisão se uma determinada região de pixeis é referido comotextura depende da escala
em que ela é visualizada. Geralmente, as regiões que contém vários objetos menores são chamadas detextura. Portanto, ela pode ser entendida como a série de repetições de
padrões iguais ou com pequenas distorções sobre uma superfície. A figura 2.1 mostra 40 classes diferentes de textura extraídas do banco de imagens Brodatz [29].
2.1.1 Análise
A análise de textura refese ao processo de caracterização de uma região ou re-giões de uma imagem pelo seu conteúdo de textura. O resultado da caracterização da textura de uma região de interesse (ROI) da imagem é conhecido como Vetor de
Ca-racterísticas (VC). O VC contém todas as medidas numéricas que são utilizadas para
Figura 2.1: 40 tipos diferentes de textura tiradas do banco de imagens Brodatz.
• Classificação: Consiste na identificação do tipo de textura que uma imagem ou ROI desconhecida possuí. Nesta tarefa, um classificador é treinado previamente
com um conjunto exemplo de texturas etiquetadas (conjunto de treinamento), se-guidamente uma imagem desconhecida, representada por um VC, é etiquetada pelo
classificadorcom base no modelo aprendido pelo conjunto de treinamento.
• Segmentação: Consiste em dividir a imagem em regiões de diferentes texturas. Existem dois tipos de métodos de segmentação:
– Métodos Supervisionados: Quando existe informação a priori das texturas
que compõem a imagem. Esses métodos treinam um classificadorcom essa
informação. Em seguida, as ROI da imagem de teste são classificadas através dele.
– Métodos Não Supervisionados: Eles não precisam de nenhuma informação prévia, por conseguinte, a segmentação é feita com base em medidas de simi-laridade. As regiões com textura semelhante são agrupadas.
• Recuperação de imagens por conteúdo: Consiste em dada uma imagem com uma textura desconhecida, encontrar asN texturas mais semelhantes a ela numa base de
2.1 - Textura 7
Na literatura existem muitos métodos de análise de textura, entre os mais renoma-dos e tradicionais temos: As Matrizes de Co-ocorrência em Níveis de Cinza (ou GLCM por as siglas em inglês Gray Level Co-ocurrence Matriz) [13], Wavelets de Gabor (ou
GW) [30], Caminhadas determinísticas parcialmente auto-repulsivas em grafos (ou CD-PAg) [31], e Padrões Binários Locais (ou LBP por as suas siglas em inglêsLocal Binary
Patterns) [20]. A explicação dos fundamentos e funcionamento de cada método é
apre-sentada no capítulo 3.
2.1.2 Aplicações na área médica e biológica
Na medicina e biologia existem muitos problemas que podem ser resolvidos uti-lizando a análise de textura. Por exemplo na Radiologia ou Diagnóstico por imagem, cada vez mais pesquisas que usam esses métodos estão surgindo. A seguir apresentamos trabalhos recentes nessa área.
Para imagens de Tomografia Computadorizada (TC), a Ref. [32] está focada na tarefa de segmentação automática dos pulmões em imagens de TCs de alta resolução. Uma segmentação inicial é obtida com métodos baseado na morfologia. Em seguida, ela é avaliada e refinada iterativamente usando métodos de análise de textura. Além disso, também é avaliada a textura do pulmão para determinar se ele pertence a um paciente doente ou sadio. Outros trabalhos também focados no pulmão são encontrados nas Refs. [33, 34], no primeiro são utilizados métodos de análise de textura (GLCM em imagens transformadas com Wavelets de Daubechies) para detectar se um exame de TC do pulmão contém nódulos pulmonares. No segundo caso, foram analisadas regiões de interesse em TCs do pulmão para determinar se essas regiões tinham tecido com doença pulmonar obstrutiva, vários métodos de textura e forma foram utilizados em conjunto. Na Ref. [35], a análise é aplicado ao diagnóstico de figado gorduroso ou com cirrose, as técnicas utilizadas incluem Wavelets e GLCM.
de fractais e classificados como tecido tumoral ou tecido normal. Na Ref. [37] estuda-se as imagens 2-D de RM, analisando diferentes ROIs e classificando-as em três classes: Tecido saudável, com carcinoma Ductal invasivo ou com carcinoma Lobular invasivo. Vários métodos de análise de textura foram comparados e o melhor deles foi GLCM. A Ref. [38] tem por objetivo diferenciar cistos hepáticos de hemangiomas hepáticos em imagens de Ressonância Magnética do fígado. Novamente, várias ROIs foram caracte-rizadas mediante diferentes métodos de textura e utilizadas para tarefas de classificação e clusterização. Na Ref. [39] foi analisado as versões em 3 dimensões dos métodos de análise de textura tradicionais. A tarefa a ser resolvida foi o diagnóstico da doença de Alzheimer em ROIs de 3 dimensões em imagens de RM.
Para imagens de Ultrassom existem também vários trabalhos publicados [40, 41, 42]. A Ref. [40] está focado no diagnóstico automático do infarto agudo do miocárdio, onde foi comparado o desempenho de alguns métodos de textura tradicionais como Wave-lets e GLCM. A Ref. [41] teve por objetivo classificar as ROIs das imagens de Ultrassom de mama em uma das seguintes classes: tumor benigno ou tumor maligno. Várias técni-cas de análise de textura e as suas combinações foram avaliadas. Finalmente, a Ref. [42] trabalhou com imagens de Ultrassom de placas carotídeas em pacientes com diagnostico de Estenose Assintomática da Carótida (EAC). O objetivo deste estudo foi determinar se essas imagens apresentam um alto risco de produzir algum acidente vascular cerebral usando métodos de análise de textura como GDLM.
Várias pesquisas são centradas também sobre imagens mamográficas, por exem-plo, temos a análise de microcalcificações mamárias com o objetivo determinar se elas apresentam características que podem ser classificadas como malignas [43], um outro trabalho identifica se uma ROI da mamografia contém alguma lesão mamária, distorção arquitetural ou simplesmente tecido saudável [44]. Finalmente na Ref. [45] é implemen-tado um sistema de recuperação de imagens por conteúdo baseado na textura da densidade do tecido mamário.
2.1 - Textura 9
ou seja, não é fornecido nenhuma classe de textura como exemplo. Portanto, a segmenta-ção é feita de tal forma que se procurem regiões diferentes conforme com alguma medida, por exemplo avaliando a energia das regiões encontradas. Depois, essa segmentação é refinada com uma análise de textura supervisada (exemplos de classes de textura são for-necidas). Na Ref. [47] analisa-se imagens de exames de Dermatoscopia para classificar as ROIs em uma das seguintes classes: Nevo melanocítico (benigno) e Melanoma (maligno). A extração de características foi feita com métodos de análise de textura, mas também se incluiu métodos de análise de bordas e geometria. Finalmente, na Ref. [48] são estudadas as colonoscopias com magnificação de imagem, com o objetivo de diferenciá-las como lesões polipoides neoplásicas (adenomas) ou não-neoplásicas. Uma variação do método de LBP em cores foi implementada para analisar a textura e a cor da imagem.
Além dos estudos mencionados acima, existem outros de carácter mais biológico. Na Ref. [49] é proposto um método de segmentação de regiões multi-celulares em ima-gens moleculares obtidas por um microscópio confocal. A ideia de segmentação foi divi-dir a imagem em vários quadrados de tamanho fixo, depois caracterizar a textura de cada quadrado e classificá-lo como parte da célula ou como parte do fundo. A classificação utiliza um modelo previamente treinado com imagens segmentadas por um especialista. Na Ref. [50] foi analisada a textura do parênquima das maçãs. O objetivo era quantificar os efeitos do congelamento nas estruturas celulares da maçã quando ela for congelada até diferentes temperaturas (−20◦C,−80◦C,−196◦C) e depois descongelada para a
tempera-tura normal (21◦C). Vários tipos de imagens foram geradas com diversas técnicas para ser
analisados. Um trabalho interessante foi encontrado na Ref. [51]. Ele teve por objetivo classificar as estruturas terciárias das proteínas. A ideia deles foi transformar a configu-ração de três dimensões dos átomos da proteína em uma matriz de distâncias. A análise de textura foi feita sobre essa matriz, o qual gerou um vetor de características que por úl-timo foi classificado com um modelo previamente treinado. Finalmente Na Ref. [52] foi analisado a textura 3-D dosscaffoldsde regeneração do tecido ósseo. Essesscaffoldssão
ferramentas que imitam uma matriz extracelular nativa: eles atuam como suportes e pro-piciam o crescimento de tecido novo. A representação dosscaffoldsem 3-D foi modelada
2.2 Medidas
Na teoria de sistemas dinâmicos, definircomplexidadeé difícil pelo motivo de ela
ser um termo muito abrangente. Contudo, podemos dizer que ela representa a interação de um grande número de componentes, com diferentes graus de liberdade, cujos com-portamentos individuais não podem ser rastreados nem preditos. Segundo a Ref. [53],
acomplexidade pode ser vista como a quantidade de informação necessária para
descre-ver um fenômeno. Portanto, fenômenos complexos precisam de mais informação. Além disso, estes sistemas apresentam um padrão global, produto das interações do seus com-ponentes, conhecido pelo termo deauto-organização[54].
Muitos trabalhos de pesquisa em análise de sinais e séries temporais têm proposto várias medidas de complexidade [55, 56]. A seguir, vamos explicar o funcionamento
de três medidas que são empregadas neste trabalho: a complexidade de Lempel-Ziv, o expoente de Lyapunov e o expoente de Hurst.
2.2.1 Complexidade de Lempel-Ziv
A Complexidade de Lempel-Ziv (CLZ) foi introduzido no ano de 1976 [57]. Ele foi originalmente proposto para quantificar a aleatoriedade em uma sequência S, de
ta-manhon, a fim de construir sequências aleatórias e identificar famílias de sequências para
tarefas de compressão de dados.
A noção de complexidade de uma sequência dada refere-se ao número de diferen-tes sub-sequências ou padrões que ele contém. A CLZ de uma sequência S é denotada
por Z(S) e constitui o número L de diferentes sub-sequências encontradas quandoS é
escaneado da esquerda para direita. A partição deS em sub-sequências é dada por ˆS.
ˆ
S =S[1. . .i1]
S[i1+1. . .i2]
S[i2+1. . .i3] . . .
S[iL−1+1. . .iL], (2.1)
ondeS[i. . . j] representa uma sub-sequência que começa na posiçãoie acaba na posição j. O símbolo
é utilizado como o separador entre duas sub-sequências. A forma em queS
é particionado depende do algoritmo de compressão usado (LZ77, LZ78, etc. . . ), alguns deles são explicados a seguir.
O algoritmo LZ77 [58] analisa uma sequência de caracteres de entradaS da
es-querda à direita produzindo um particionamento ˆS = Sˆ1
Sˆ2
. . .
2.2 - Medidas 11
i-ésima sub-sequência de ˆS. Suponha que tenhamos escaneado S entre as posições 1 e i−1 produzindo o particionamento ˆS1
Sˆ2
. . .
Sˆp−1. O passo seguinte consiste em
procu-rar uma posiçãokemS, tal que 1 ≤ k ≤ i−1, para o qual o prefixo comum mais longo
(LCP) entreS[i. . .i′−1] e S[k. . .k′ −1] é máximo (Observe que i′ −1 ≤ n, k′ < i′ e k′ −k = i′ −i). Logo depois, nós ajustamos ˆSp = S[i. . .i′] e repetimos o mesmo pro-cedimento iterativamente atéi > |S|. Por exemplo, quando particionamos a sequência
S = abaabababaaaaabbabab, este algoritmo produz ˆS = a
b aa bab abaaa aabb abab.
Portanto, a CLZ da sequênciaS correspondente, é 7.
O segundo algoritmo de compressão é conhecido como LZ78 [59]. Ele constrói ˆ
S usando uma listaΩ, inicialmente vazia. Suponha a sequênciaS[1. . .i−1] foi já
ana-lisada, produzindo ˆS1
Sˆ2
. . .
Sˆp−1. Em seguida, nós encontramos o prefixo mais longo S[i. . .i′− 1] deS que está presente em Ω, após o qual, nós ajustamos ˆSp = S[i. . .i′], adicionamos ˆSp para Ω e repetimos este procedimento até i > |S|. Por exemplo,
para S = abaabababaaaaabbabab, este algoritmo produz o seguinte particionamento
ˆ
S = a
b aa ba bab aaa aab baba
b, tal que o o CLZ correspondente é 9.
O terceiro algoritmo, conhecido como LZW (Lempel-Ziv-Welch) [60], é muito semelhante a LZ78, ele só se diferencia em que a lista Ω é inicializada com todos os possíveis símbolos do alfabeto de entradaΣ, por exemplo quando analisamos a sequência binaria 10100001. A listaΩ é inicializada como os símbolos 0 e 1. Nós indicamos ao leitor a Ref. [61] para obter mais informação sobre os métodos apresentados acima, além de outros, e as suas performances em tarefas de compressão de textos.
Também é importante destacar os trabalhos recentes ([62, 63, 64]) que estão fo-cados no problema conhecido de fatoração de Lempel-Ziv ou fatoração-s. Ele é definido como a decomposição da sequênciaS em fatores f1. . . fk, onde f1 = S[1] e parak ≥ 2,
fk é a sub-sequencia mais longa de S[|f1. . . fk−1|+ 1] que esta presente ao menos duas
vezes na sequencia f1. . . fk. Por exemplo, a fatoração-s deS = abaabababaaaaabbabab
éa,b,a,aba,baba,aaaa,b,babab.
Aplicações da complexidade de Lempel-Ziv
O uso principal dos algoritmos de Lempel-Ziv é a compressão de dados. Portanto, eles são a base do formato de imagem GIF, PKzip, e Zip [66]. Além disso, a CLZ é algumas vezes utilizada em arquivos TIFF e PDF. Finalmente, quando a CLZ é combinado com o algoritmo de Codificação de Huffman [67] resulta no algoritmo Deflate [68], o qual constitui a fundação do formato de arquivo Gzip [69], a biblioteca zlib [70] e o formato de imagem PNG (Portable Network Graphics) [71].
Existem outras aplicações onde a CLZ pode ser utilizada. Em biologia, a CLZ é calculada sobre sequências de aminoácidos para encontrar localizações sub-nucleares de estruturas de proteínas primárias, assim como predizer estruturas de proteínas secundá-rias [72, 73]. As sequências de entrada são, nestes casos, letras maiúsculas, cada uma representando um aminoácido em particular. Na Ref. [74], os automatas celulares são combinados com a CLZ para predizer a classe em que uma proteína pertence. Para conse-guir isto, a sequência de aminoácidos da proteína é primeiro convertida em uma sequência binária, onde cada aminoácido é representado por uma cadeia binária de tamanho 5. Em seguida, um automata celular gera novas sequências binárias a partir da inicial, e a CLZ é computada para todas essas sequências. Um vetor de características é composto com todas as CLZ obtidas e finalmente a fase de classificação é executada. A CLZ é também usado em aplicações biomédicas envolvendo sinais de encefalogramas (EEG) [23, 24, 25, 26] e sinais de eletrocardiogramas (ECG) [22] para efeitos de classificação.
Deve ser mencionado que a CLZ pode ser usada também como um enfoque na seleção de características [75]. Para este propósito, a CLZ é computada para cada coluna da matriz de características, em seguida as colunas com os menores valores de CLZ são removidos. Finalmente, existem aplicações que confiam na CLZ para tarefas de visão computacional, tal como recuperação de imagens por conteúdo e classificação [76, 27], bem como na análise de textura [28].
2.2.2 Expoente de Lyapunov
2.2 - Medidas 13
iniciais. Os sistemas em que as trajetórias em meia afastam-se de forma exponencial são chamados deSistemas Caóticose portanto, possuem umatrator estranho[77].
Definimos o expoente de Lyapunov para um mapa (Sistema dinâmico discreto)
unidimensional arbitrárioxn+1 = f(xn) do seguinte modo.
• Dois pontos iniciais (x0 e x′0) muito próximos entre si são escolhidos, por
conse-guinte, a separação inicial deles éδ0 =|x0−x0′|, de tal forma queδ0 ≪ |x0|.
• Após a primeira iteração do mapa são calculados os pontos: x1 = f(x0), x′1 = f(x′0),
e a distânciaδ1 =|x1−x′1|, na segunda iteração obtemos x2 = f(x1),x′2 = f(x′1) e a
distância δ2. Depois deniterações do mapa a separação entre os pontos xn e x′n é
δn.
• Pode se mostrar que a dependência é exponencial δn ≈ δ0enλ [77], então λé cha-mado de expoente de Lyapunov. Um mapa é caótico quandoλ >0.
• Resolvendo paraλ, e utilizando limites obtemos a seguinte equação
λ= lim n→∞δlim0→0
1
nln (
δn
δ0). (2.2)
A definição de acima pode ser estendida para sistemas dinâmicos demdimensões.
Nesse caso um conjunto deλi,i=0,1, . . . ,m, são calculados. Esse conjunto é conhecido como o espectro de Lyapunov. Um sistema caótico tem pelo menos umλi > 0. Portanto, usualmente basta determinar o maior expoente de Lyapunov. Para maiores informações, ver a Ref. [78].
São poucos os casos em que é possível calcular o expoente de Lyapunov de um sistema dinâmico de forma analítica. Portanto, o uso de métodos numéricos são necessá-rios para fazer este cálculo. Um problema mais difícil é determinar o maior expoente de Lyapunov de um sinal ou série temporal em que as equações do sistema dinâmico não são fornecidas. Wolf [79] propõe um método para calcular o maior expoente de Lyapunov em um sinal. Os passos principais são resumidos a seguir.
1. Dada um sinal S de |S| = N pontos ou elementos {x0,x2, . . . ,xN−1}. Inserir os
parâmetros de entrada do método: dimensão de imersão de, tempo de atraso de Takensτe período médiop, os primeiros dois parâmetros são usados no método de
2. A trajetória reconstruída (trajetória fiducial) é representada pela matriz X de
di-mensões M×de, onde M = N −(de−1)τ, cada linhaXi representa um estado do sistema no instantei.
Xi ={xi,xi+τ,xi+2τ, . . . ,xi+(de−1)τ}
3. DefinimosXucomo o estado inicial de evolução. Começamos comu=0, na matriz
X é procurada a linha Xv com a menor distância euclidiana a Xu, essa distância é denotada porδu0. Outra restrição é que a separação temporal entre Xue Xv precisa ser maior ao período médio p(|v−u|> p).
4. A distância euclidianaδu1 é calculada entre os estados evoluídosXu+1eXv+1.
5. Atualizamosu=u+1. Seguindo um processo semelhante ao passo 3, selecionamos um novo Xv com a menor distância euclidiana δu0, com uma separação temporal
superior a p, e além disso com a menor distância angular em relação ao anterior Xv+1obtido no passo 4.
6. Repetimos os passos 4 e 5 até que u = M− 1. O cálculo do maior expoente de
Lyapunov é dado pela seguinte fórmula:
λ= 1
M−1
M−2
X
u=0
log2 δu1 δu0
. (2.3)
Existem outros trabalhos que fazem o cálculo do expoente de Lyapunov [81, 82] mas o método que obteve melhores resultados nos nossos estudos foi aquele descrito acima.
2.2.3 Expoente de Hurst
O expoente de HurstH(S)é uma medida utilizada para detectarprocessos de
me-mória longaem uma série temporal ou sinal S [83]. Intuitivamente um processo de
me-mória longaé aquele que envolve um componente aleatório em que um evento passado
2.2 - Medidas 15
• Quando 1/2 < H(S) < 1 o processo tem uma correlação persistente, portanto
valores altos (baixos) em S tem maior probabilidade de serem seguidos por outros
valores altos (baixos).
• Quando 0 < H(S) < 1/2, o processo tem correlação anti-persistente, por
con-seguinte, é mais provável que os valores altos (baixos) em S serem seguidos por
valores baixos (altos).
• Se H(S) = 1/2 considera-se um processo sem memória e não existe correlação
nenhuma entre os valores da série.
Dito de outro modo, quanto mais suave for a vizinhança local deS, maior será o H(S).
Ao longo do tempo, vários métodos de cálculo doH(S) tem sido propostos, na Ref. [83]
são apresentados alguns deles, enquanto a Ref. [84] faz uma comparação entre esses métodos.
Nesta dissertação, nós temos utilizado o método de análiseR/S (em inglês
“Res-caled Range Analysis”) para estimarH(S). A escolha deste método foi baseado no seu
melhor desempenho em séries S com poucos elementos [83]. A seguir vamos mostrar
seus passos principais.
1. DividirS emDsub-séries não sobrepostas comKelementos. NormalmenteK×D=
N, ondeN é o número de elementos deS, porém, existe a possibilidade em queD
não é divisor de N, nestes casos a S é truncado. Definimos Cada sub-série como Sd, d = 0. . .D−1 e cada elemento da sub-série como Sd[k], sendoko índice de posiçãok=0. . .K−1.
2. Para cada sub-série Sd, encontrar a média md e o desvio padrão sd. Depois cada elementoSd[k] é transladado, utilizandomd.
S′d[k]= Sd[k]−md. (2.4)
3. Calcular a sub-série acumuladaCd[k] = k
X
j=0
S′d[j], para k = 0. . .K −1 e obter a
gamardde cada sub-série usando a seguinte equação.
rd = max
4. Calcular o valor esperadoEdas proporçõesrd/sd.
E(r/s)K = 1
D
D−1
X
d=0
rd
sd
. (2.6)
5. Repetir os passos 1, 2, 3, 4 para vários valores K e utilizar a seguinte equação
empírica:
E(r/s)K =C∗KH
ln (E(r/s)K)=lnC+HlnK, (2.7)
Cé uma constante eHé o expoente de Hurst.
6. Utilizar um método de regressão lineal simples sobre a equação de acima,H(S) é o
ângulo da tangente da reta de regressão.
2.3 Transformadas em imagens
2.3.1 Transformada de Fourier
A transformada de Fourier (TF) denotada porF é um método de decomposição de um sinal em várias funções periódicas expressas como exponenciais complexas. Essas funções tem diferentes períodos, amplitudes e fases. A equação abaixo mostra a transfor-mada de Fourier para um sinal unidimensional contínuo f(t):
F {f(t)}= F(u)=
Z +∞
−∞
f(t)e−2πutdt, (2.8)
onde = √−1, ué a frequência, e 2πué a frequência angular. A Transformada Inversa
de Fourier é definida pela seguinte equação.
F−1{F(u)}= f(t)= 1 2π
Z +∞
−∞
F(u)ej2πutdu. (2.9)
No caso discreto, para um sinal f[x] de tamanho N a Transformada Discreta de
Fourier é:
F {f[x]}= N−1
X
k=0
2.3 - Transformadas em imagens 17
A TF tem várias propriedades que são úteis tanto no caso contínuo quanto no caso discreto, algumas delas são:
• Superposição: A TF da soma de dois sinais é igual à soma das TF desses dois sinais.
f[t]= f1[t]+ f2[t]→ F {f[t]}= F {f1[t]}+F {f2[t]}. (2.11)
• Deslocamento: A TF de um sinal deslocado no tempo é igual à TF do sinal original multiplicado por uma fase complexa.
g[t]= f[t−t0]→ F {g[t]}=e−j2πut0F {f[t]}. (2.12)
• Teorema da Convolução: A Convoluçãoé um operador lineal que a partir de dois
sinais f[t] eg[t] produz um terceiroh[t] mediante a seguinte equação:
h[t]= f[t]∗g[t]=
t
X
τ=0
f[τ]·g[t−τ]. (2.13)
O Teorema da Convolução consiste em que a TF da convolução de dois sinais é
igual à multiplicação ponto-a- ponto das TF desses sinais.
h[t]= f[t]∗g[t]→ F {h[t]}=F {f[t]} · F {g[t]}. (2.14)
O operador de convolução é muito utilizado na aplicação de filtros digitais sobre si-nais 1-D ou 2-D. O problema dessa operação é que ela pode ser custosa em termos computacionais. Porém, existe um algoritmo bastante eficiente para calcular a TF de um sinal conhecido como aTransformada Rápida de Fourier, com uma
comple-xidade de tempo deO(NlogN), ondeNé o tamanho da sinal. Uma boa explicação
do funcionamento deste algoritmo é feita no Capítulo 12 da Ref. [85], enquanto sua implementação em pseudo-código é encontrada no Capítulo 30 da Ref. [86]. Portanto, como a multiplicação é uma operação mais simples que a convolução, em muitos casos é mais eficiente realizar a convolução através deste teorema, conforme os seguintes três passos:
1. Aplicar atransformada rápida de Fourierno filtro digital e no sinal de entrada.
3. Finalmente, executar atransformada inversa de Fourier sobre o sinal
resul-tante para voltar ao domínio inicial.
Um exemplo de aplicação deste teorema é mencionado no Capítulo 3 ao explicar o funcionamento do método de Wavelets de Gabor.
O Capítulo 3 da Ref. [87] apresenta uma lista com as propriedades mais impor-tantes da TF.
A Transformada de FourierF de uma sinal bidimensional (2-D) continua f(x,y)
é dada pela seguinte fórmula:
F {f(x,y)}=F(u,v)=
Z +∞
−∞
Z +∞
−∞
f(x,y)e−j2π(ux+vy)dx dy. (2.15)
Enquanto, a TF de uma imagem (sinal 2-D discreta) f[x][y] de M linhas e N
colunas é:
F {f[x][y])}=F[u][v]= M−1
X
0
N−1
X
0
f[x][y]e−j2π(ux/M+vy/N). (2.16)
A imagem transformadaF[u][v] expressa em coordenadas retangulares tem uma
parte realℜ[u][v] e uma parte imaginariaℑ[u][v]. Porém, a representação mais utilizada
é com coordenadas polares:
M[u][v]= pℜ[u][v]2+ℑ[u][v]2
Φ[u][v]= arctan
"
ℑ[u][v]
ℜ[u][v] #
ondeM é conhecida como a magnitude ou oespectro de Fourier eΦ é conhecida como o ângulo de fase. Originalmente as baixas frequências estão posicionadas nos cantos de
M enquanto as altas frequências estão posicionadas no centro (Ver Fig. 2.2b). A fim de
ter uma melhor visualização do espectro, a Fig. 2.2c apresenta o resultado de aplicar uma operação de deslocamento sobre a imagem, colocando o componente defrequência zero
no centro.
Uma característica deMé a sua simetria em relação ao centro da imagem. Neste
2.3 - Transformadas em imagens 19
(a) (b)
(c) (d)
Figura 2.2: Operações na transformada de Fourier. (a) Imagem original, (b) logaritmo do espectro de Fourier da imagem original, (c) logaritmo do espectro de Fourier deslocado para posicionar o componente defrequência nulano centro, (d) simetria do espectro de
Fourier
2.3.2 Transformada discreta de wavelet
A transformada discreta de wavelet (TDW) é uma versão mais simples da trans-formada continua de wavelet (TCW). No caso discreto (TDW), filtros de frequências di-ferentes são utilizados para analisar o sinal discreto f[t] em múltiplas escalas. Portanto, f[t] é estudado por meio de um conjunto de filtros passa-altas para analisar as suas altas
frequências e também por meio de um conjunto de filtros passa-baixas para analisar as suas baixas frequências.
cor-responde ao filtro passa-baixo e a função wavelet ψ[t], que corresponde ao filtro
passa-alto. No caso da TDW unidimensional, eles decompõem o sinal f[t] em dois sinais
sub-banda que são chamados decoeficientes de aproximação W(ca1)ecoeficientes de detalhe W(cd1), respectivamente. A resolução dessas dois novas sinais é reduzida pela metade, e
concatenadas, tem o mesmo tamanho da sinal original f[t]. O sinal contendo os
coefici-entes de aproximação pode ser novamente decomposto em duas sinais sub-banda: W(ca2)
eW(cd2), e assim por diante.
No caso da TDW em duas dimensões, para um sinal f[x,y], são gerados quatro
funções como segue:
• φca[x,y]=φ[x]φ[y],
• ψch[x,y]=ψ[x]φ[y],
• ψcv[x,y]= φ[x]ψ[y],
• ψcd[x,y]= ψ[x]ψ[y],
os quais decompõem f[x,y] nos coeficientes de aproximação W(ca1), e os coeficientes
de detalhe horizontalW(ch1), vertical W(cv1) e diagonalW(cd1), respectivamente. De igual
maneira que no caso unidimensional,W(ca1) pode ser novamente decomposto em W(ca2), W(ch2), W(cv2) e W(cd2), e assim por diante. É importante ressaltar que a função escala
precisa ser ortogonal em relação com as suas transformações de escala e traslação para que possa ser usada na TDW. A função wavelet pode ser derivada a partir da função
escala. Na literatura existem vários tipos defunção escala, como por exemplo as funções:
Haar, Daubechies, Meyer, entre outros.
2.4 Caminhadas determinísticas parcialmente auto-repulsivas
As caminhadas determinísticas parcialmente auto-repulsivas (CDPA) foram
origi-nalmente propostas na Ref. [88]. Este apresenta uma dinâmica de movimentação descrita da seguinte maneira: considerando um mapa de N cidades, um viajante se desloca
par-tindo de um ponto inicials0 e movimenta-se de acordo com a regra determinística de, a
2.4 - Caminhadas determinísticas parcialmente auto-repulsivas 21
tenha sido visitado nos últimosµpasos (0 ≤ µ≤ N). O parâmetroµé conhecido como a
memória da caminhada.
O nome decaminhada do turista1foi proposto por Peter Stadler, durante una visita
ao Departamento de Física e Matemática (DFM) da faculdade de Filosofia, Ciências e Letras de Ribeirão Preto (FFCLRP), no ano 2000 [89], como situação real, ele imaginou um mochileiro que ia visitando as cidades pedindo carona.
Considere um plano com N pontos distribuídos uniformemente. As caminhadas
parcialmente auto-repulsivas seguem uma trajetória não periódica de tamanho lt conhe-cida como atransientee depois de alguns passos acabam formando um ciclo ou atrator
de períodolp. As Refs. [88, 90] mostram algumas propriedades importantes dasCDPA nos seguintes casos:
• Quando a memóriaµ = N, a caminhada será totalmente auto-repulsiva, portanto a
trajetória estará composta somente da parte transiente comlt = N.
• Para µ = N−1, a caminhada estará formada por um ciclo de períodolp = N e o tamanho da transiente serált =0.
• Quandoµ=0 não existe trajetória. Portantolp = 1 elt = 0. Este caso é conhecido como oturista preguiçoso.
• Comµ= 1, também conhecido comoturista sem memória, o turista apenas conhece
o ponto onde ele está, e não se lembra dos pontos visitados nos passos anteriores. Depois de um curto transiente o turista sempre fica presso em um ciclo de período
lp = 2. A distribuição conjunta do tamanho do transientelt e período do atratorlp num espaço deddimensões está dada pela seguinte equação para N ≫1:
S(1N,d≫1)(lt,lp)=
Γ(1+Id−1)(lt +Id−1) Γ(lt +lp+Id−1)
δlp,2,
onde Γ(z) é a função gamma e Id = I14 1 2,
(d+1) 2
!
é a função beta normalizada e incompleta.
• Para memórias µ > 1, o menor período do atratorlpmin que pode ser encontrado é igual aµ+1. Por outro lado, nestes casos, a distribuição conjuntaS(lt,lp) torna-se mais complexa.
C
ap
´
itulo
3
M´
etodos de an
alise de textura
´
tradicionais
Na análise de textura em imagens existem vários métodos de caracterização de textura. No presente capítulo, apresentamos as técnicas mais conhecidas e importantes, indicando os parâmetros envolvidos e as suas complexidades de tempo de execução. A análise de complexidade de tempo é feita utilizando anotação assintótica(Ver Capítulo 3
da Ref [86]), a qual é muito útil para medir o custo computacional de um algoritmo. A me-dição do custo é feita através de funções de crescimento (linear, logarítmica, exponencial) dos parâmetros envolvidos no algoritmo. Especificamente, a notaçãoOserá utilizada: ela
considera a função que é o limite superior da função do pior caso do algoritmo.
3.1 Taxonomia dos métodos de textura
Ao longo do tempo, tem surgido bastantes métodos de análise de textura. Por-tanto, alguns autores tentaram classificá-los segundo a forma em que eles obtêm os seus descritores. Porém, essas propostas de classificação de métodos de análise de textura não são perfeitas. Por exemplo, existem alguns métodos que pertencem para mais de uma categoria. A seguir são descritas as principais categorias segundo as Refs. [92, 93, 94]:
• Métodos estruturais: A textura é caracterizada através das suas estruturas ele-mentais chamadas texels outextons. Portanto, as propriedades e regras de
posici-onamento desses texels definem a textura de uma imagem. O método de padrões
binários locais combina aspectos de análise estatística com a estrutural (Ver Ref. [95]).
• Métodos baseados em modelos: Eles constroem um modelo empírico de cada pixel usando uma combinação linear dos pixeis vizinhos. Os parâmetros estimados desse modelo são utilizados para descrever a textura de uma imagem. A análise por modelos fractais é um exemplo deste tipo de métodos.
• Métodos de processamento de sinais: Também conhecidos como métodos basea-dos em transformações. São técnicas que transformam a imagem analisada em uma nova imagem com o fim de obter informações espaço-frequência dos seus pixeis. Neste tipo de métodos geralmente são utilizados filtros e os resultados dependem diretamente do tipo de transformada aplicado. O método de Wavelet de Gabor é um exemplo bem sucedido desta categoria.
• Métodos baseados em agentes: Este tipo de análise calcula os seus descritores através de simulações e interações de agentes autônomos, medindo os seus compor-tamentos e efeitos causados na imagem analisada. As caminhadas determinísticas parcialmente auto-repulsivas em grafos é um método muito estudado desta catego-ria.
Na presente dissertação, incluímos um método tradicional por cada categoria (com exceção da categoria de métodos baseados em modelos)
3.2 Matrizes de co-ocorrência de níveis de cinza
A matriz de co-ocorrência de níveis de cinza (ouGLC Mpela suas siglas em inglês
Gray Level Co-occurrence Matrix) foi originalmente proposta no ano de 1973 [96]. Ele
tornou-se um método bem estabelecido na análise de imagens e útil na caracterização de textura.
Essencialmente, umaGLC Md,θé uma matriz quadrada de tamanhoL×L, ondeL
3.2 - Matrizes de co-ocorrência de níveis de cinza 25
GLC Md,θ corresponde a uma probabilidade Pd,θ[i][j] que indica a frequência de todos os
pares de pixeis presentes em I, com valores de cinzai e j, e que estão separados
espa-cialmente por uma distânciad em um ângulo θ. A matrizGLC Md,θ é simétrica quando Pd,θ[i][j] = Pd,θ[j][i]. Note que umaGLC Md,θ pode ser construída para qualquer
combi-nação (d, θ). A Fig. 3.1 apresenta as distâncias e ângulos mais utilizados [97].
135
◦
90
◦
45
◦
0
◦
Figura 3.1: Distânciasd = {1,2,3,4} e ângulos θ = {0◦,45◦,90◦,135◦}mais usados na
construção de matrizes de co-ocorrência de níveis de cinza (GLCM) em uma imagem típica. O elemento de cor preto que está no centro é o pixel de referência e os elementos cinzas são os pixeis vizinhos.
Depois de estabelecer uma ou mais GLCMs para diferentes combinações dedeθ,
estatísticas de segunda ordem são calculadas, algumas delas são explicadas como segue:
• Contraste (CON): Esta medida pondera as probabilidades Pd,θ[i][j] com pesos
que são o resultado da diferença ao quadrado entre os valores de cinza ie j. Note
que quandoi= jo valor dePd,θ[i][j] é completamente ignorado.
CONd,θ =
L−1
X
i=0 L−1
X
j=0
Pd,θ[i][j](i− j)2. (3.1)
• Homogeneidade (HOM): Esta medida é inversamente proporcional ao contraste
HOMd,θ =
L−1
X
i=0 L−1
X
j=0
Pd,θ[i][j]
• Entropia (ENT): Mede o grau de caos entre as probabilidades de umaGLC Md,θ.
Ela obtém o seu maior valor quando todos os valores Pd,θ[i][j] são iguais.
ENTd,θ =
L−1
X
i=0
L−1
X
j=0
Pd,θ[i][j](−lnPd,θ[i][j]). (3.3)
• Correlação (CORR): Mede a dependência linear entre probabilidades vizinhas
Pd,θ[i][j].
CORRd,θ =
L−1
X
i=0
L−1
X
j=0
Pd,θ[i][j]
(i−µi)(j−µj)
q
(σ2i)(σ2j)
. (3.4)
ondeµi eµjsão as medias.
µi = L−1
X
i=0 L−1
X
j=0
iPd,θ[i][j], µj =
L−1
X
i=0 L−1
X
j=0
jPd,θ[i][j].
eσ2i eσ2j são as varianças:
σ2i = L−1
X
i=0 L−1
X
j=0
Pd,θ[i][j](i−µi)2, σ2i =
L−1
X
i=0 L−1
X
j=0
Pd,θ[i][j](j−µj)2.
O número de descritores do vetor de características (VC) resultante é definido pelo número de matrizesGLC Ms computadas (Ng), multiplicado pelo número de estatísticas de segunda ordem (Ne) usadas. Um parâmetro importante a definir é o número de níveis de cinzaLcontidas na imagem analisada. Usualmente, definirL= 256 não é recomendável porque a matrizGLC M resultante ficaria muito esparsa. Neste sentido, um processo de
quantizaçãoé feito emIpara reduzir o valor deL. Por exemplo, na Ref. [98] um L=32
foi aquele que obteve os melhores resultados nos bancos de imagens analisados.
Complexidade do tempo
• Devido que todos los elementos da imagemIsão processados, o tempo de
constru-ção de uma matrizGLC Md,θ é deO(NfNc), ondeNf eNccorrespondem ao número de linhas e colunas de Irespectivamente.
• Cada vez que calculamos uma medida estatística de segunda ordem, a matriz
GLC Md,θ é escaneada inteiramente. Portanto, o custo de cálculo de uma medida
3.3 - Wavelets de Gabor 27
• Se Ng é o número de GLC Ms computadas e Ne é o número medidas estatísticas calculadas, então a complexidade de tempo do algoritmo em total é deO(Ng(NfNc+
NeL2)).
3.3 Wavelets de Gabor
Como foi apresentado no capítulo 2, a transformada de Fourier é muito utilizada para analisar um sinal f no domínio da frequência. Neste sentido, toda a informação
do domínio temporal (1-D) ou espacial (2-D) do sinal original é perdida. Uma solução inicial é o método da Transformada de Fourier de curto termo (ou S T FT pelas suas
siglas em inglêsShort Term Fourier Tranform). Em sinais unidimensionais, ela consiste
na aplicação daT F em segmentos do sinal analisado f(t). Esses segmentos são obtidos
mediante o uso de uma janela deslizantebde tamanho fixo que percorre f(t) da esquerda
à direita.
S T FTF(b)(τ,u)=
Z +∞
−∞
x(t)b∗(t−τ)e−j2πutdt, (3.5)
ondeb∗ é o complexo conjugado da janelab. O comprimento debé importante. Umab
muito curta consegue uma boa análise de tempo, mas uma pobre análise de frequência; e uma janela b muito grande consegue uma boa análise de frequência mas uma pobre
análise de tempo. Portanto, aS T FT funciona razoavelmente bem quando o comprimento
ótimo da janela deslizanteb é encontrado. Porém, numerosas vezes isso não é possível
ou o procedimento de busca é bastante demorado.
O método de wavelets de Gabor, consegue resolver parcialmente este problema ao fazer uma análise multi-resolução espaço-frequência. O filtro 2-D de Gaborg(x,y) e a
sua transformada de FourierG(u,v) sãos dados pelas seguintes equações:
g(x,y)= 1
2πσxσy exp
"
−12 x
2
σ2x +
y2
σ2y
!
+2πjW x #
. (3.6)
G(u,v)= exp
"1
2
"(
u−W)2
σ2u +
v2
σ2v
##
, (3.7)
onde, σu = 1/2πσx e σv = 1/2πσy. O filtro g(x,y) da Eq. 3.6 é chamado de Wavelet
Ns escalas e No orientações são utilizadas a fim de criar um banco de filtros de Gabor auto-similares. Conforme a Eq. 3.8.
gs,k(x,y)= a−sg(x′,y′), a>1, s= 1. . .Ns, k=1. . .No, (3.8)
ondex′ = a−s(xcosθ+ysinθ),y′ = a−s(−xsinθ+ycosθ),θ = kπ/No. O fator de escala éa−s.
Em seguida, a imagemIé convoluída com cada filtro de Gabor do banco deNs×No filtros. Lamentavelmente, as imagens filtradas contêm informação redundante pois os wavelets de Gabor não são ortogonais. Manjunath na Ref. [30] propõe uma fórmula para reduzir essa redundância introduzindo dois parâmetros: frequências centrais inferiorul e superioruh. Desta maneira, as fórmulas para calcular os parâmetrosa, σx eσy são as seguintes:
a= uh
ul
!S1−1
, σu =
(a−1)uh (a+1)√2 ln 2,
σv = tan
π
2k "
uh−2 ln 2
σ2u
uh
!# "
2 ln 2− (2 ln 2)2σ2u
u2h
#−1/2
FinalmenteW = uh. A Fig. 3.2 mostra a parte real de um conjunto de 40 wavelets de Gabor. Elas foram gerados com os seguintes parâmetros: No = 8,Ns = 4,ul = 0.1,uh = 0.4.
Após a filtragem, algumas medidas estatísticas são extraídas das imagens. Por exemplo, a média e o desvio padrão dos elementos de matriz de cada imagem. Finalmente, um vetor de características é formado pela concatenação dessas medidas.
Complexidade do tempo
• Se Nf e Nc são o número de linhas e colunas da imagemI a ser analisada, então o tempo de construção do banco de filtros de Gabor é deO(NfNcNsNo).
• A convolução é feita no domínio da frequência aproveitando o Teorema da
Con-volução explicada no capítulo 2. Portanto, o custo computacional pertence ao da
transformada rápida de Fourier. A convolução é feita Ns× No vezes. Por
3.4 - Padrões binários locais 29
Figura 3.2: Conjunto de 40 filtros de Gabor em diferentes escalas e orientações. Eles ao ser convoluídos com uma imagemI, permitem fazer uma análise multi-resolução no
domínio espaço-frequência dessa imagemI.
• O tempo de cálculo de uma medida estatística é de O(NfNc). Duas medidas es-tatísticas são tiradas por cada imagem filtrada (média e desvio padrão). O custo computacional neste passo é de O(2NfNcNsNo), como dois é um valor constante, ela pode ser ignorada. Portanto, o custo final é deO(NfNcNsNo).
• A complexidade de tempo total é de O(NsNoNfNc(2 + log(NfNc))) =
O(NsNoNfNclog(NfNc)) . É importante notar que o custo computacional deste mé-todo depende totalmente do custo da transformada rápida de Fourier e o número
de vezes que ela é feita.
3.4 Padrões binários locais
O Método de padrões binários locais (ouLBP pelas suas siglas em inglês Local
Binary Patterns) foi proposto na Ref. [20]. Neste método, a imagem analisadaI é
trans-formada em uma nova imagemI′por meio de um operador. Esse operador substitui cada
pixel da imagemI[i][j] por um padrão binárioSi,j composto de oito bits, os quais resul-tam da comparação dos valores de cinza dos oito primeiros vizinhos ao pixelI[i][j] com o