Supervisor – ´
Alvaro Rodrigues Pereira J´
unior
s-WIM - A SCALABLE WEB INFORMATION
MINING TOOL
Felipe Santiago Martins Coimbra de Melo
Orientador – ´
Alvaro Rodrigues Pereira J´
unior
s-WIM - A SCALABLE WEB INFORMATION
MINING TOOL
Disserta¸c˜ao de mestrado apresentada ao Programa de P´os-Gradua¸c˜ao em Ciˆencia da Computa¸c˜ao da Universidade Federal de Ouro Preto, como requisito parcial para a obten¸c˜ao do grau de Mestre em Ciˆencia da Computa¸c˜ao.
Catalogação: [email protected] M528s Melo, Felipe Santiago Martins Coimbra de.
s-WIM [manuscrito] : a scalable web information mining tool / Felipe Santiago Martins Coimbra de Melo – 2012.
iv, 96 f.: il.; grafs.; tabs.
Orientador: Prof. Dr. Álvaro Rodrigues Pereira Júnior.
Dissertação (Mestrado) - Universidade Federal de Ouro Preto. Instituto de Ciências Exatas e Biológicas. Departamento de Computação. Programa de Pós-graduação em Ciência da Computação.
Área de concentração: Ciência da Computação
1. Mineração de dados (Computação) - Teses. 2. Recuperação da informação - Teses. 3. Aprendizado de máquina - Teses. 4. Banco de dados - Big data - Teses. I. Universidade Federal de Ouro Preto. II. Título.
Resumo
Minera¸c˜ao Web pode ser vista como o processo de encontrar padr˜oes na Web por meio de t´ecnicas de minera¸c˜ao de dados. Minera¸c˜ao Web ´e uma tarefa computacionalmente inten-siva, e a maioria dos softwares de minera¸c˜ao s˜ao desenvolvidos isoladamente, o que torna escalabilidade e reusabilidade dif´ıcil para outras tarefas de minera¸c˜ao. Minera¸c˜ao Web ´e um processo iterativo onde prototipagem tem um papel essencial para experimentar com diferentes alternativas, bem como para incorporar o conhecimento adquirido em itera¸c˜oes anteriores do processo.
Web Information Mining (WIM) constitui um modelo para prototipagem r´apida em minera¸c˜ao Web. A principal motiva¸c˜ao para o desenvolvimento do WIM foi o fato de que seu modelo conceitual provˆe seus usu´arios com um n´ıvel de abstra¸c˜ao apropriado para prototipagem e experimenta¸c˜ao durante a tarefa de minera¸c˜ao.
WIM ´e composto de um modelo de dados e de uma ´algebra. O modelo de dados WIM ´e uma vis˜ao relacional dos dados Web. Os trˆes tipos de dados existentes na Web, chamados de conte´udo, de estrutura e dados de uso, s˜ao representados por rela¸c˜oes. Os principais componentes de entrada do modelo de dados WIM s˜ao as p´aginas Web, a estrutura de hiper-links que interliga as p´aginas Web, e os hist´oricos (logs) de consultas obtidos de m´aquinas de busca da Web. A programa¸c˜ao WIM ´e baseada em fluxos de dados (dataflows), onde sequˆencias de opera¸c˜oes s˜ao aplicadas `as rela¸c˜oes. As opera¸c˜oes s˜ao definidas pela ´algebra WIM, que cont´em operadores para manipula¸c˜ao de dados e para minera¸c˜ao de dados. WIM materializa uma linguagem de programa¸c˜ao declarativa provida por sua ´algebra.
O objetivo do presente trabalho ´e o desenho de software e o desenvolvimento do Scalable Web Information Mining (s-WIM), a partir do modelo de dados e da ´algebra apresenta-dos pelo WIM. Para dotar os operadores com a escalabilidade desejada – e consequente-mente os programas gerados por eles – o s-WIM foi desenvolvido sobre as plataformas Apache Hadoop e Apache HBase, que provˆeem escalabilidade linear tanto no armazena-mento quanto no processaarmazena-mento de dados, a partir da adi¸c˜ao de hardware.
A principal motiva¸c˜ao para o desenvolvimento do s-WIM ´e a falta de ferramentas livres que ofere¸cam tanto o n´ıvel de abstra¸c˜ao provido pela ´algebra WIM quanto a escalabilidade necess´aria `a opera¸c˜ao sobre grandes bases de dados. Al´em disso, o n´ıvel de abstra¸c˜ao provido pela ´algebra do WIM permite que usu´arios sem conhecimentos avan¸cados em linguagens de programa¸c˜ao como Java ou C++ tamb´em possam utiliz´a-lo.
O desenho e a arquitetura do s-WIM sobre o Hadoop e o HBase s˜ao apresentados nesse trabalho, bem como detalhes de implementa¸c˜ao dos operadores mais complexos. S˜ao tamb´em apresentados diversos experimentos e seus resultados, que comprovam a escala-bilidade do s-WIM e consequentemente, seu suporte `a minera¸c˜ao de grandes volumes de dados.
Abstract
Web mining can be seen as the process of discovering patterns from the Web by means of data mining techniques. Web mining is a computation-intensive task and most mining software is developed ad-hoc, which makes scalability and reusability difficult for other mining tasks. Web mining is an iterative process and prototyping plays an essential role in experimenting with different alternatives, as well as in incorporating knowledge acquired in previous iterations of the process.
Web Information Mining (WIM) is a model for fast Web mining prototyping. The main motivation behind WIM development was the fact that its conceptual model provides its users with a high level of abstraction, appropriate for prototyping and experimenting during the mining tasks.
WIM is composed by a data model and an algebra. The WIM data model is a rela-tional view of Web data. The three types of existing Web data, namely Web content, Web structure and Web usage, are represented by relations. The main input components for the WIM data model are the Web pages, the hyperlink structure linking Web pages and the query logs obtained from Web users’ navigation. WIM materializes a declarative program-ming language from its algebra. The WIM programprogram-ming language is based on dataflows, where sequences of operations are applied to relations. The operations are defined by the WIM algebra, which contains operators for data manipulation and for data mining.
The objective of this work is the software design and development of the Scalable Web Information Mining (s-WIM), given the data model and the algebra originally presented by WIM. In order to provide s-WIM operators with the intended scalability capabilities – and consequently the programs generated by them – the s-WIM operators were developed on top of Apache’s Hadoop and HBase, which provide linear scalability for both, data storage and processing, by the addition of hardware resources.
The main motivation for s-WIM development is the lack of a free platform offering both, the same high level of abstraction provided by the WIM algebra, and the scalability nec-essary for the operation on huge data volumes. Furthermore, the high level of abstraction provided by the WIM algebra allows users without expertise in programming languages such as Java or C++ to effectively use s-WIM.
The design and the architecture of s-WIM on top of Hadoop and HBase are presented in this work, as well as details on the implementation of the most complex s-WIM operators. This work also presents several experiments performed on s-WIM and their results, that ascertain s-WIM scalability, and consequently, its support for the mining of huge data volumes, including Web data sets.
Contents
1 Introduction 1
1.1 Motivation . . . 1
1.2 Context of the Thesis – Scalable Web Mining . . . 3
1.3 Objectives of the Thesis . . . 4
1.4 Related Word . . . 6
1.5 Main Contributions of the Thesis . . . 9
1.6 Organization of this Thesis . . . 10
2 Background 11 2.1 The WIM Data Model . . . 11
2.1.1 Design Goals . . . 11
2.1.2 Object Set . . . 12
2.1.3 Node Relation . . . 13
2.1.4 Link Relation . . . 13
2.1.5 Relation Set . . . 15
2.1.6 Compatibility . . . 16
2.2 The WIM Algebra . . . 17
2.2.1 Operations, Programs and Databases . . . 17
2.2.2 Relation Set of an Output . . . 19
2.2.3 Inheritance Property . . . 20
2.2.4 Operations of the Algebra . . . 21
2.2.5 Data Manipulation Operators . . . 22
2.3 Data Mining Operators . . . 32
2.4 Apache Hadoop . . . 43
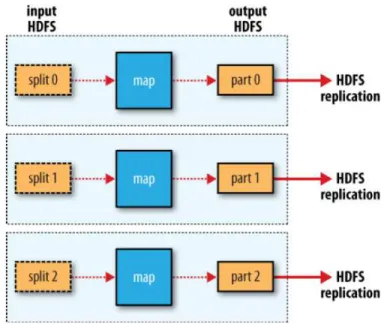
2.4.1 Hadoop Distributed File System (HDFS) . . . 43
2.4.2 MapReduce . . . 43
3.2 Design and Development of the WIM Data Model . . . 50
3.2.1 Implementation of Node and Link Relations . . . 51
3.2.2 Implementation of the Index Structure for the Search Operators . . . 52
3.2.3 Implementation of Relation Sets . . . 53
3.3 Implementation of the WIM Operators . . . 54
3.3.1 The Aggregate Operator . . . 54
3.3.2 The Associate Operator . . . 55
3.3.3 The Cluster Operator . . . 57
3.3.4 The Disconnect Operator . . . 58
3.3.5 The Search Operator . . . 58
3.3.6 The Set Operator . . . 58
4 Experimental Results 69 4.1 Experimental Setup . . . 69
4.2 Experimental Results . . . 71
4.2.1 Aggregate . . . 71
4.2.2 Calculate . . . 72
4.2.3 Convert . . . 72
4.2.4 Select . . . 73
4.2.5 Associate . . . 74
4.2.6 Relink . . . 75
4.2.7 Cluster . . . 76
4.2.8 Search . . . 76
4.2.9 Analyze . . . 79
4.3 Analysis of the Experiments . . . 80
4.3.1 Abundance of Hardware Resources . . . 80
4.3.2 Join Operations on BigData . . . 82
4.4 Final Remarks . . . 85
5 Conclusions and Future Work 87 5.1 Conclusions . . . 87
5.2 Future Work . . . 88
5.2.1 Extensions in WIM Algebra . . . 88
5.2.2 Addition of More Features to s-WIM . . . 89
5.2.3 Use Cases . . . 90
Bibliography 91
NN Name Node
SNN Secondary Name Node
DN Data Node
RegS Region Server
JT Job Tracker
TT Task Tracker
GFS Google File System
HDFS Hadoop Distributed File System
LR1 Link Relation 1
LR2 Link Relation 2
LR3 Link Relation 3
LR4 Link Relation 4
LR5 Link Relation 5
NR1 Node Relation 1
NR2 Node Relation 2
NR3 Node Relation 3
List of Figures
2.1 Example of an object set. . . 12
2.2 Two node relations: url and text. . . 13
2.3 Relational and graphical representation of link relation frequency. . . 14
2.4 An example of a link relation with different compatible node relations for the start and end sets. . . 17
2.5 An illustration of a WIM program with three operations. . . 18
2.6 Two compatible relation sets, with new relations (cluster andsingleCluster) as result of operations. . . 19
2.7 Syntax of operator Select. . . 23
2.8 Example of operator Select with option Value. . . 23
2.9 Example of operator Select with option Top, applied to a link relation. . . 24
2.10 Syntax of operator Calculate. . . 24
2.11 Example of operator Calculate with option Constant, for normalization of values. . . 25
2.12 Syntax of operator CalcGraph. . . 25
2.13 Example of operator CalcGraph for the sum of values in compatible relations. 26 2.14 Syntax of operator Aggregate. . . 26
2.15 Example of operator Aggregate with option Single, for calculating the average. 27 2.16 Example of operator Aggregate with option Grouping, for counting the num-ber of elements with the same value. . . 27
2.17 Example of operator Aggregate with option Grouping, applied to a link relation. . . 28
2.18 Example of operator Aggregate with option Grouping, applied to two at-tributes of a relation. . . 29
2.19 Syntax of operator Set. . . 29
2.20 Example of operator Set with option Intersection, applied to two relations of different types. . . 30
2.21 Syntax of operator Join. . . 31
2.22 Example of operator Join. . . 31
2.23 Syntax of operator Convert. . . 32
2.26 Example of operator Search used for text comparison. . . 34
2.27 Example of operator Search, as typically used for querying. . . 34
2.28 Syntax of operator Compare. . . 35
2.29 Example of operator Compare with option Sparse. . . 35
2.30 Syntax of operator CompGraph. . . 36
2.31 Example of operator CompGraph. . . 37
2.32 Syntax of operator Cluster. . . 37
2.33 Syntax of operator Disconnect. . . 38
2.34 Example of operator Disconnect with option Connected. . . 38
2.35 Syntax of operator Associate. . . 39
2.36 Syntax of operator Analyze. . . 41
2.37 Example of operator Analyze. . . 41
2.38 Syntax of operator Relink. . . 42
2.39 Example of operator Relink. Operator Select is applied afterwards, for elim-inating the links existent in relUsGraph, facilitating visualization. . . 42
2.40 MapReduce workflow for a single reduce task. . . 44
2.41 MapReduce workflow for several reduce tasks. . . 45
2.42 MapReduce workflow without reduce tasks. . . 45
2.43 Example of an HTable. . . 46
3.1 s-WIM core classes. . . 48
3.2 A node relation as stored in HBase. . . 51
3.3 A link relation as stored in HBase. . . 52
3.4 Example of a terms-table storing the postings list for the terms of a collection. 53 3.5 Example of a docs-table storing statistics about a collection. . . 53
3.6 Example of the Aggregate operator performing the calculation of the stan-dard deviation with option Single. . . 56
3.7 Example of theAggregate operator performing the counting of distinct values in a data set with option Grouping. . . 60
3.8 Example of theAggregate operator performing the counting of distinct tuples using data from three relations, with option Grouping. . . 61
3.9 Example of the Associate calculating each data set item’s frequency and joining all items of each transaction. . . 62
3.10 Example of the Associate discovering association rules from transactions. . 63
3.11 Pseudocode of the Cluster operator for options K-Means and K-Medoids. . 64
3.13 Example of the operatorSearch executing optionTF-IDF for a single result
in MapReduce. . . 66
3.14 Example of theSet operator performing optionIntersect on values from two relations. . . 67
3.15 Example of the Set operator performing option Difference on values from two relations. . . 68
4.1 Illustration of Table 4.9 with a lines chart. . . 75
4.2 Illustration of Table 4.12 with a lines chart. . . 78
4.3 Illustration of Table 4.13 with a lines chart. . . 79
4.4 Average runtime of operators Aggregate, Calculate, Convert, and Select running on a cluster with 17 machines. . . 82
4.5 Average runtime of operators Aggregate, Calculate, Convert, and Select running on a cluster with 13 machines. . . 82
4.6 Average runtime of operators Aggregate, Calculate, Convert, and Select running on a cluster with 8 machines. . . 83
4.7 Average runtime of operators Aggregate, Calculate, Convert, and Select running on a cluster with 3 machines. . . 83
Chapter 1
Introduction
1.1
Motivation
The World Wide Web is nowadays consolidated as the most important public source of information in the world, due to two main reasons: i) because in contrast to other medias like radio and television, the Web is free for everybody to publish, and ii) because of its accessibility, each user is free to choose where to navigate among a huge number of pages. Although the Web seems to be properly shaped in order to allow humans to solve some of their information need – for instance –, through search engines, the processing of a sample of the Web to discover patterns and return valid and useful information is not established yet. The reason is that corporations’ information need, although probably published on the Web, is expensive to be processed and then discovered, as a consequence of the lack of special engines for Web data mining.
We define Web data mining, or simply Web mining, as the process of discovering useful information in Web data, by means of data mining techniques. The cost of finding out the right information is not associated to the lack of data mining techniques, but to the complexity of managing the required Web data, and to effectively and efficiently employing well known data mining techniques. With the goals of dropping the cost of Web mining and allowing it to embrace Web-scale data sets, hence making the mining process more accessible and manageable, this master thesis represents one of the first contributions towards the creation of a distributed and scalable tool for mining the Web, by implementing both the data model and algebra originally presented at the WIM PhD thesis [37].
Web mining can be divided into three different types according to analysis targets [31, 11], which are Web content mining, Web structure mining and Web usage mining. Web content mining is the process of discovering useful information from the content of Web pages. Web structure miningis the process of using graph theory to analyze the node and the connection structure of a Web site or among Web sites. Web usage miningcomprises the
use of data mining techniques to analyze and discover interesting patterns on user’s usage data on the Web. Usage data is obtained when the user browses or makes transactions on a Web site.
Web mining is a computation intensive task even after the mining tool itself has been developed. However, most mining software is developed in an ad-hoc manner and is usu-ally not scalable nor reused for other mining tasks. Data mining, and in particular Web data mining, is an iterative process in which prototyping plays an essential role in order to easily experiment with different alternatives, as well as incorporating the knowledge acquired during previous iterations of the process itself. In order to facilitate prototyping, an appropriate level of abstraction must be provided to the user or programmer carrying out the Web data mining task.
Motivated by the lack of an existing framework to allow such abstraction, the central part of this thesis comprises the software design and development of a model for intensive and distributed Web mining prototyping, which is referred to as s-WIM – Scalable Web Information Mining – model. s-WIM is composed at its core by both WIM’s data model and algebra. WIM’s data model is an abstract model that describes how data is represented and accessed. WIM’s algebra is composed by a set of operators for consistent data manipulation and mining. The data model and the algebra are specially designed to manage the three types of Web data in combination: documents, structures between documents, and usage data.
In order to allow scalability for Web mining tasks, s-WIM was developed on top of two frameworks for distributed storage and processing of large volumes of data, Apache’s Hadoop and HBase. The Apache Hadoop1 [7] framework was devised to allow the devel-opment of distributed applications able to run on a cluster of commodity machines. It offers a master/slaves-based infrastructure which is resilient to both, hardware and client code failures. To reach this resiliency, Hadoop has mechanisms to avoid data loss and to reschedule tasks when nodes run out of work. Apache HBase is a distributed column-oriented database built on top of Hadoop distributed file system (HDFS) and implemented after Google’s BigTable. HBase2 [20] allows real-time read/write random-access to large data sets.
Considering the main fields of computer science, this thesis is located in the fields of databases and distributed systems, and arises in a time when both, new types and huge volumes of data must be managed, and new models need to be provided for new applications demands. From the users’ point of view, s-WIM inherits the concepts around relational databases. For instance, s-WIM has a specific file system along with a model and an algebra to manipulate data stored on that model. However, s-WIM provides those features in a distributed and scalable way, which makes it an alternative for a critical
1.2. CONTEXT OF THE THESIS – SCALABLE WEB MINING 3
scenario to which relational databases cannot be employed, such as the Web mining world.
1.2
Context of the Thesis – Scalable Web Mining
According to Chakrabarti [11], Web mining is about finding significant statistical patterns relating hypertext documents, topics, hyperlinks, and queries, and using these patterns to connect users to the information they seek. The Web has become a vast storehouse of knowledge, built on a decentralized yet collaborative manner. On the negative side, the heterogeneity and the lack of structure make it hard to frame queries and satisfy information needs. For many queries posed with the help of keywords and phrases, there are thousands of apparently relevant responses, but on closer inspection these turn out to be disappointing for all but the simplest queries.
The data to be mined is very rich, comprising texts, hypertext markups, hyperlinks, sites, and topic directories. This distinguishes Web mining as a new and exciting field, although it also borrows liberally from traditional data analysis. Useful information on the Web is accompanied by incredible levels of noise, but thankfully, the law of large numbers kicks in often enough that statistical analysis can make sense off the confusion.
Roughly speaking, Web Mining is the extraction of interesting and potentially useful patterns and implicit information from artifacts or activities related to the World-Wide Web. As already mentioned, there are three knowledge discovery domains that pertain to web mining: Web content mining, Web structure mining, and Web usage mining.
Web content mining: it is an automatic process that goes beyond keyword extraction. Since the content of a text document presents no machine-understandable semantics, some approaches have suggested to restructure the document content in a representation that could be exploited by machines. The usual approach to exploit known structure in docu-ments is to use wrappers to map docudocu-ments to some data model. Techniques using lexicons for content interpretation are yet to come.
There are two groups of web content mining strategies: those that directly mine the content of documents and those that improve on the content search of other tools like search engines.
of the web artifacts summarized.
Web Usage Mining: Web servers record and accumulate data about user interactions whenever requests for resources are received. Analyzing the web access logs of different web sites can help understand the user behavior and the web structure, thereby improving the design of this colossal collection of resources. There are two main tendencies in Web Usage Mining driven by its applications: general access pattern tracking and customized usage tracking [49].
The general access pattern tracking analyzes the web logs to understand access patterns and trends. These analyzes can shed light on better structure and grouping of resource providers. Customized usage tracking analyzes individual trends. Its purpose is to cus-tomize web sites to users. The information displayed, the depth of the site structure and the format of the resources can all be dynamically customized for each user over time based on their access patterns.
However, as aforementioned, the richness of Web texts, hypertexts, hyperlinks, sites and topic directories, besides bringing an opportunity never seen before for information discovery, has also become a problem of manageability. It is very hard to collect, store, and process Web-scale data. In 2008, Google, the largest Web search player by far, reported on its blog that a milestone of a trillion unique URLs had been collected by its search engine3
. If it is a very hard issue to store all those data, it is not easier to process them, even if we are interested only in a little portion of that. This is the reason why any Web mining framework has to be provided with capabilities of distributed storage and processing, and has to be easily scalable with the addition of more hardware (e.g. if the data set runs out of space, it is highly desirable that the solution comes by simply adding more hard disks and/or machines to the distributed environment).
Thus, a framework that offers a data model and an algebra comprising the three knowl-edge discovery domains pertaining to Web mining and allows for scalable data storage and processing can be considered a quite complete one.
1.3
Objectives of the Thesis
The main objective of this thesis is comprised by the design and development of s-WIM, a scalable data model with an algebra which allows for fast Web mining prototyping, after the data model and algebra definition presented in the WIM PhD thesis [37]. The goal of s-WIM is to facilitate the task of Web miners when prototyping Web mining applications while allowing them to cope with Web-scale data sets. In order to achieve this main objective, and in the future to have Web miners using the s-WIM software, we highlight four main research challenges: i) the software design and development of s-WIM data model
3
1.3. OBJECTIVES OF THE THESIS 5
on HBase, ii) the software design and development of s-WIM algebra on Hadoop, iii) the software design and development of s-WIM architecture in order to have the data model and algebra at its core while being easily extended to both, allowing the addition of more algebra operators and external features such as a compiler; and iv) related development issues, such as the development of an indexing structure to support the algebra operators aimed at text search.
The original WIM data model refers to how data is represented and accessed. It is important to notice that WIM data model was devised to deal with Web data, and it is necessary to provide an abstraction to the user as a view of the data. The WIM choice was to create an adaptation from the well-known relational tables, in order to represent nodes of a graph, such as the documents on the Web, and the edges of this graph, such as hyperlinks connecting Web documents. However, whereas intended to support Web data manipulation, WIM only provides the formal definition of the model, regardless of scalability issues, which are determinant when processing Web-scale data. Furthermore, WIM does not provide any clues or suggestions on how the model should be designed in order to keep conformity with the formal definition while being scalable, neither on how to use the model while at the same time using operators which require specific data structures, such as the text search operators that need an index structure to work properly.
The WIM algebra refers to the set of operators, including their syntactic and semantic aspects, which exists to manipulate and mine the Web data. The challenge in designing the WIM algebra was not only concentrated on defining the set of operators, but also on how to guarantee the composition between operator’s input and output, which is important to allow users to request any operator output to be input of any other existing operator, having as the only constraint the data types of the input and output. This feature allows WIM operators to be combined in dataflow programming, which means that operators are called in sequence and that parallel processing is allowed whenever independent tasks are requested. However, the WIM original thesis is not coupled on how the operators should be designed and developed to work in a distributed environment, which is mandatory to provide the scalability needed by Web-scale data.
The s-WIM software architecture is highly important at this materialization stage as it is tightly related to s-WIM’s efficiency and maintainability. It is vital to s-WIM to be able to have new operators incorporated, as well as to allow fast changes in the existing ones, when it is necessary. These requisites make the s-WIM’s architectural design a paramount issue.
Because there is a large number of data mining techniques that have been applied to Web data [30, 31], WIM thesis only includes in its algebra a set of the most common techniques, according to what is believed to be the most important for Web mining ap-plications. The WIM algebra currently covers the following techniques: association rules and sequential patterns mining; unsupervised learning tasks such as k-means clustering and clustering based on graph structure and text; search and text comparison; and link analysis, with co-citation analysis and document relevance analysis. All those techniques are present in s-WIM.
In order to accomplish the main objective of this thesis, several experiments are per-formed in order to evaluate the performance and the scalability of the implementation of some of the most complex operators, such as the text search and clustering ones. As the WIM thesis has already analyzed some Web mining problems in order to demonstrate that enough knowledge regarding Web data mining is retained, good execution results enforces the assumption that s-WIM is applicable to a set of real Web mining problems.
1.4
Related Word
The s-WIM framework is intended to be a distributed tool to support the development of Web mining applications. Although s-WIM is totally based on WIM, this chapter only presents initiatives related to s-WIM as a tool, thus, not presenting any related work to WIM itself. It means that this chapter strives to frame initiatives to create distributed tools to support Web and data mining activities, however, it does not go any further into attempts to establish general models to support those activities. If necessary, the reader may refer to the WIM thesis [37] to grab more details on the initiatives specifically related to WIM.
There are several tools currently available in the marketplace aimed at managing un-structured and semi-un-structured data besides un-structured data, even in a distributed and scalable way. Examples of those tools and their providers are Expert System’s COGITO4,
1.4. RELATED WORD 7
Thomson Reuters’ ClearForest5
, DnB6
, InsideView7
, LexisNexis8
, ZoomInfo9
, SPSS10 , SAS Institute11
, Informatica12
, Kxen13
, Denodo14
. However, those tools have a commercial-only purpose, thus, though dealing with the same problem domain than this thesis, they do not constitute related research work.
One of the first research initiatives related to this thesis was TSIMMIS [13, 19, 25], a project to develop tools that facilitate the rapid integration of heterogeneous information sources, including both structured and semistructured data. TSIMMIS has components to translate queries and data (source wrappers), to extract data from Web sites, to combine information from several sources (mediator), and to allow browsing of data sources over the Web. TSIMMIS uses a tree-like model rather than a traditional schema. The type of the data is interpreted by the user from labels in the structure. However, the project’s Web page15
had its last update in 2004.
Another project related to this thesis is ARANEUS. The ARANEUS project [5, 34] pro-poses a Web-base management system, with support to: i) queries, on structured and semi-structured data; ii) views, to reorganize and integrate data from heterogeneous sources; and iii) updates, to allow the maintenance of Web sites. It proposes a new data model for Web documents and hypertexts, and proposes languages for wrapping and creating Web sites, including techniques for publishing data on the Web. ARANEUS includes two different languages: ULIXES [4] and PENELOPE. ULIXES is used to build database views of the Web, which can then be analyzed and integrated using database techniques. PENELOPE allows the definition of derived Web hypertexts from relational views, which can be used to generate hypertextual views over the Web. However, the project’s Web page16
explicitly states that it will no longer be maintained.
The WEBMINER tool [15] provides a query language on top of external mining software for association rules mining and for sequential pattern mining. It is based on the adaptation of an existing miner to a particular problem. More precisely, a pre-processing algorithm groups consecutive page accesses by the same visitor into a transaction, according to some criterion. Then, a miner for association rules or sequential patterns is invoked to discover similar patterns among the transactions. The association rules’ miner has been further
customized to guarantee that no patterns are erroneously skipped. However, there are no further information on this project available on the Web besides its published papers. There is not a software to be downloaded.
In the same line as WEBMINER, WUM (Web Utilization Miner) [44] is a system for discovering interesting navigation patterns. MINT is the WUM mining language, which supports the specification of statistical, structural, and textual criteria. To discover the navigation patterns satisfying the expert’s criteria, WUM exploits an aggregated storage representation for the information in the Web server log. However, the project Web page17 has most of its links pointing at inexistent URLs, besides the fact that most of the project’s documentation is written in German.
More recently, WebFountain appeared as a very ambitious project. It was intended to be a Web-scale mining tool and discovery platform that combines text analytics technology and large and heterogeneous data sources with custom solutions. The WebFountain plat-form was intended to identify patterns, trends and relationships from many documents, in-cluding Web pages, Web logs, bulletin boards, newspapers and other structured data feeds. This platform was also intended to be high-performance, scalable, and distributed, and also to support data gathering, storing, indexing, and querying needs of analysis agents, called miners. In September 2003, Factiva, an information retrieval company owned by Down Jones and Reuters, licensed WebFountain in order to use it in its corporate reputation tracker system18
. However, on claims that WebFountain’s indexing refresh was too slow, Factiva dropped the partnership19
. IBM’s next step was to open source WebFountain20 into UIMA21
. However, in the WebFountain overview document22
, the utilization propo-sitions were to make WebFountain an engine which would allow external access through Web Services, while keeping theminers closed to modification or extension. It means that users are restricted to the availableminers the way they are.
Another very important related initiative is Weka [51]. Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a data set or called from users’ own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. It is also well-suited for developing new machine learning schemes23
. Weka has a standardized data input format, which facilitates the interaction of external systems with its algorithms, besides having a very nice graphical user interface, which allows even dataflow programming. However, although Weka is a very complete and largely adopted tool, it suffers from lack
1.5. MAIN CONTRIBUTIONS OF THE THESIS 9
of scalability. Most of Weka’s data structures are memory-based, so, the amount of main memory available is a serious scalability issue.
The last work related to this thesis found in the literature is Apache Mahout [35]. Mahout’s goal is to build a library of scalable machine learning algorithms. In order to achieve its scalability goals, Mahout was developed on top of Hadoop [50], and has support for integration with MongoDB24
and Apache Cassandra25
. Currently, Mahout supports mainly four use cases: recommendation mining, which takes users’ behavior and from that tries to find items users might like. Clustering, which takes e.g. text documents and groups them into groups of topically related documents. Classification, which learns from existing categorized documents what documents of a specific category look like and is able to assign unlabeled documents to the correct category. And frequent itemset mining, which takes a set of item groups and identifies which individual items usually appear together26
. However, although being scalable and affording reasonably large data sets, Mahout is neither as complete as Weka in terms of algorithms nor as standardized. Furthermore, Mahout provides neither any graphical user interface facilities nor any other easy way to create complete applications based on its algorithms, such as dataflow programming capabilities.
Considering the aforementioned, s-WIM is intended to harness the best design decisions and capabilities while covering the weaknesses of its related initiatives. s-WIM provides an algebra as WEBMINER does, a standardized data storage model as WebFountain does, a plentiful of algorithms encompassing the most used techniques as Weka does, while being scalable as Mahout does. Furthermore, s-WIM is intended to have its own compiler in order to allow for parallel execution of operators, and also to provide a graphical user interface in order to allow for easy and fast prototyping. These features make s-WIM a very interesting research and development opportunity.
1.5
Main Contributions of the Thesis
The main contribution of this thesis is the design and development of s-WIM – Scalable Web Information Mining, a model materialized as a software for supporting Web miners when developing their applications when dealing with the BigData. This model was originally proposed as WIM [37]. We have implemented WIM original data model and algebra on top of Apache’s Hadoop and HBase in order to provide it with distributed and scalable data storage and processing. s-WIM was architecturally designed to be easily extended so that new operators comprising new data mining techniques can be incorporated into it as
users deem it necessary.
The second contribution of this thesis is the performance and scalability evaluation of s-WIM by running experiments on large data sets in order to demonstrate s-WIM to be an scalable Web mining tool. The experiments were performed on data sets of different volumes and on clusters of varying number of nodes, which provides a good perspective on the scalability behavior of both, s-WIM operators and Hadoop/HBase.
The third contribution of this thesis comprises s-WIM itself, as it is intended to be made fully available as an open-source product. Making s-WIM freely available will allow researches on Web or other sources of Big Data to be carried out faster and less painfully, as the level of abstraction offered by the WIM operators enable faster prototyping. In addition, people without experience with programming languages such as Java, but with a basic understanding of SQL will also be able to use s-WIM.
The fourth contribution of this thesis is not so explicit. The research and development made during the production of this thesis have shown to be actually possible to create a real tool for mining Web-scale data sets from a quite high level of abstraction which performs in reasonable time. Thus, the fourth contribution of this thesis is the encouragement of efforts to be done on both improving on s-WIM itself and endeavoring into related initiatives.
1.6
Organization of this Thesis
Chapter 2
Background
Before proceeding to present s-WIM’s design decisions, architecture, development, appli-cations and performance evaluation, it is necessary to provide some background on the ideas and technologies that made s-WIM possible: WIM’s data model and algebra, and Apache’s Hadoop and HBase. The objective of this chapter is to present those items in a sufficient level of detail that allows for a better comprehension of s-WIM’s design and development decisions.
2.1
The WIM Data Model
This section presents the notation and definitions for formalizing the WIM data model as originally presented in WIM thesis [37]. In some cases they are adapted from the standard relational database literature [1, 14]. In the WIM model, two types of relation are defined: node relations, which are presented in Section 2.1.3, andlink relations, which are presented in Section 2.1.4. Node relations exist to represent nodes of graphs, such as documents of a Web dataset, terms of a document, or queries or sessions of a query log; whereas link relations exist to model edges of graphs, such as links of a Web graph, word distance among terms of a document, similarity among queries, or clicks of a query log. To start, the design goals are presented in Section 2.1.1.
2.1.1
Design Goals
Five main design goals were established for WIM data model:
Feasibility. The model might be implementable and the resulting tool/prototype should be useful for different applications. This means that the WIM data model is not just an abstract model.
applied to a set of use cases as a proof of concept of WIM. Furthermore, simplicity will help users implement applications based on the WIM data model and algebra, and extend WIM according to their specific demands.
Extensibility. The WIM algebra must be extensible, once new Web mining applications may demand new operations that are not covered by the current algebra.
Representativeness. WIM must provide a layer of data independence from the raw data that is to be mined. It means that a standard is needed to represent Web data. Generally, Web data has been widely represented as a graph, but as WIM is a model for mining, associations between links and nodes must be provided, so that operations can be applied to different Web data types.
Compositionality. WIM operators are intended to be more than a simple library. It is rather a declarative programming language. It is intended to deal with specific data types, and then an algebra to manipulate and mine data is required. Therefore, the compositionality [1] property is a requisite in order to allow sequences of operations to manipulate the input data. Without such property, the output of a given operation would be useless for other operations and the algebra would not achieve its goal.
In the next sections the key concepts of the WIM data model are presented.
2.1.2
Object Set
AnObject Set Ois any set of Web objects to be represented. In most application scenarios, it is a collection of Web documents in which each object is a different document in this collection. However, several other data sets may have interesting objects to be modeled by WIM. For instance, usage data is not a typical collection of documents, but can still be represented.
Figure 2.1 presents an example of an object set, with six objects which are Web docu-ments. Each document has a URL, a textual content (which is just a couple of words in this simplified example), and an identifier, which is defined by the user who manages the collection.
2.1. THE WIM DATA MODEL 13
2.1.3
Node Relation
Given two domainsD1 and D2,RN is a node relation on these two domains if it is a set of 2-tuples, each of which has its first component fromD1 and its second component fromD2. Exceptionally permitted as the output of specific WIM algebra operations (presented in Section 2.2), a node relation can be unary rather than binary. In this case, a node relation on domain D1 is a set of 1-tuples.
The first attribute is referred to as the Primary Key Attribute K and the second attribute (when it exists) as the Value Attribute V. Then, a node relation RN in the WIM model is defined as RN = (K, V)| (K). The domain (or type
1
) ofK is integer. The possible types ofV are integer, floating point, and string; i.e., tV ∈ {int, f loat, string}
2
. A node relation represents objects from an object set. A single node relation cannot represent more than one object set, although several node relations can represent the same object set, and a node relation can represent a subset of an object set. Figure 2.2 presents two examples of node relations, which represent the same object set, as illustrated in Figure 2.1. Relation url represents the URLs of a set of six Web objects shown in Figure 2.1, whereas relation text represents their text content.
Figure 2.2: Two node relations: url and text.
Observe that the main difference so far between the WIM and relational data models is the number of attributes in each relation. As will be further explained, this is a requirement for WIM because subsets of tuples in relations might be represented as new relations which are part of the same data set.
2.1.4
Link Relation
Given four domainsD1,D2,D3 andD4,RL is a link relation on these four domains if it is a set of 4-tuples with its first element fromD1, its second element from D2, its third element from D3, and its fourth element from D4. A link relation can also be ternary rather than quaternary. In this case, given three domainsD1,D2 andD3,RLis a link relation on these
1 In this text it is also used the term type to express the domain of attributes.
three domains if it is a set of 3-tuples with its first element from D1, its second element fromD2, and its third element from D3.
The first attribute is referred to as the Primary Key Attribute K of the link relation, the second as theStart Attribute S, the third as theEnd Attribute E, and the fourth (when it exists) as the Value Attribute which represents a label for an edge. Then a link relation RL in the WIM model is defined as RL= (K, S, E, L) | (K, S, E). The latter means that there is no label value associated with edges of the graph.
Individually, S and E represent the nodes of a graph and, for this reason, elements in S and in E are typically referred to as nodes in this article. S must represent objects from a single object set, as well as E must represent objects from a single object set. Often, S andE represent objects from the same object set, althoughS andE may represent objects from two different object sets. Together, S and E represent edges of a graph. If S and E represent objects from different object sets, then the link relation represents a bipartite graph, which is useful to model associations between different collections. The type ofK, S and E is integer, and the possible types for L are integer, floating point, and string.
Figure 2.3-(a) presents an example of a link relation called frequency, whereas Fig-ure 2.3-(b) presents the graph represented by this relation. Observe that, for key value 5 (start node 3), the associated values in attributes E and L are null (represented by a hyphen), which means that there is no link from node 3, though it is a node of the graph, as represented in Figure 2.3-(b).
Figure 2.3: Relational and graphical representation of link relation frequency.
2.1. THE WIM DATA MODEL 15
2.1.5
Relation Set
In spite of the restriction with respect to the number of attributes in the relations, the WIM data model has a mechanism to associate value attributes in different relations according to their respective key attributes. The concept of Relation Set allows to associate value attributes from different relations, according to the attribute key K of node relations, or attributes S and E of link relations.
A set of relations R1, R2, . . . , Rn belong to the same Relation Set if and only if:
❼ Every relation in the relation set has the same type, i.e., either tRi =node or tRi = link, for 1≤i≤n. The type of a relation set is represented as tS.
❼ IftS =node, the key attribute in each relation identifies objects from the same object setO.
❼ If tS = link, the start nodes (i.e., attribute S) of each relation identify objects in the same object setO1 and the end nodes (i.e., attribute E) of each relation identify objects from the same object set O2. It is possible that object sets O1 and O2 are the same, i.e., O1 =O2.
A relation set representing node relations is referred to as a Node Relation Set and is represented by SN, whereas a relation set representing link relations is referred to as a Link Relation Set and is represented bySL(remind that a singleSrepresents the attribute start, not a relation set).
According to the above definition, relations url and text in Figure 2.2 belong to the same node relation set because they are both node relations defined on the same object set (shown in Figure 2.1). Relation frequency in Figure 2.3 could be part of a link relation set that represents graphs composed by the documents in Figure 2.1, but it does not belong to the same relation set like that which includes the node relations url and text because frequency is a link relation. Then, by definition,frequency cannot belong to a node relation set.
Observe that the definition of relation set does not impose that every relation in a set must have the same K for node relation sets, and the same values in attributes S and E for link relation sets. This means that relations within the same relation set can have different number of tuples. Actually, this property is the main reason for defining relations with only one value attribute and grouping them as a relation set.
sets, the union of the start nodes of every relation in the set must contain objects from the same object set. The same condition holds for end nodes.
For a node relation set SN, the union of all values of each attributeK of relations inSN is referred to as key set. Note that the key set must correspond to a single object set, as stated before. For a link relation set SL, we refer to start set as the union of the elements in each attribute S of all relations in SL and as end set as union of the elements in each attribute E of all relations in SL.
2.1.6
Compatibility
Relation sets exist to aggregate relations of the same type that represent the same object set. The concept ofcompatibility is important to establish an association between relation sets of different types, but which are defined on the same object set. If two relation sets of the same type represented the same object, they would be defined as a unique relation set, which means that compatibility needs not be defined for relation sets of the same type. The concept of compatibility is specially important for the WIM algebra, as will be presented in the next section.
There are two situations to define compatibility. The first is when both the start and end sets of a link relation set represent the same object set, and the second is when they represent different object sets (for which a bipartite graph is represented).
A node relation set SN and a link relation set SL are compatible to each other if they represent the same object set O. More formally, SN and SL are compatible if both the start and end sets of SL consists of foreign keys in the key set of SN. The symbol ‘⇔’ is used to express compatibility between two relation sets (S
N ⇔SL).
If the start and end sets of SL represent different objects, then SL does not have a single compatibleSN for both start and end sets ofSL. This means that the start and end sets of a link relation set can have different compatible node relations. In this case, if SN
1 represents the object setO
1, which is the object set represented by the start set ofSL, then the start set ofSLis compatible with SN
1. More formally, the start set ofSL is compatible with SN
1 if the start set of SL consists of foreign keys in the key set of SN1. The same definition is valid for the end set: the end set of SL is compatible withSN
2 if it consists of foreign keys in the key set ofSN
2. The symbol ‘⇒’ is used to express compatibility between a start or end set of link relation sets and node relations (S(SL)⇒SN
1 andE(SL)⇒SN2). For illustration, observe that the node relation set formed by the node relation presented in Figure 2.2 is compatible with the set to which the link relation presented in Figure 2.3 -(a) belongs to. Link relation frequency represents edges between nodes, which are objects in Figure 2.1. Observe in Figure 2.3-(b)that this link relation does not represent a bipartite graph.
2.2. THE WIM ALGEBRA 17
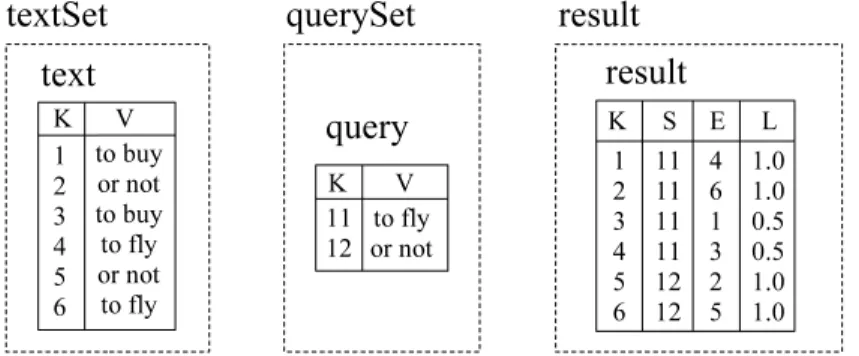
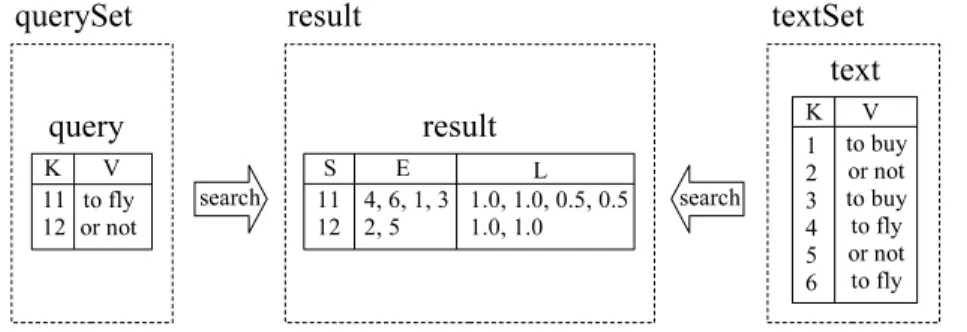
has different compatible relations for start and end sets, consider the example illustrated in Figure 2.4. Supposequery is the only relation in a node relation set querySet,text is the only relation in a node relation set textSet, andresult is the only relation in a link relation set with the same name3
. Relation result represents results of searches for elements of
query in document texts represented by relationtext, using a given comparison technique.
Figure 2.4: An example of a link relation with different compatible node relations for the start and end sets.
Observe that in relation result elements in attribute E are documents returned by queries represented in attributeS. For instance, document number 4 (to fly) was returned by query number 11 (to fly), with a similarity measure represented by the value 1.0 in attribute L.
2.2
The WIM Algebra
This section presents the notation and definitions regarding the WIM algebra as originally presented in the WIM thesis [37].
2.2.1
Operations, Programs and Databases
An operation is the application of an operator to relations of one or two relation sets. An operator is a previously defined function included in the WIM algebra, which shall be presented in this section. The output of any operation must be a new relation, which can be used afterwards in the same program. This means that this output relation will belong to some relation set. We shall see in Section 2.2.2 that output relations can belong to a previously existing relation set, or a new relation set might be created. The decision of
3
to which relation set an output relation belongs to is automatically controlled by WIM, based on the algebra.
A WIM Program is a sequence of operations defined according to the WIM language, which is built upon the WIM algebra. The WIM language is a dataflow programming language and, therefore, is derived from the functional programming paradigm. Thus, a WIM program is modeled like a directed graph, in which nodes represent operations and edges represent the data flow. This approach allows parallelism of tasks whenever the manipulated data is independent in different parts of the program.
It is intrinsic to any operator definition the type of the input relation set(s) and the type and properties of the output relation. The input of an operator typically includes other operator-specific parameters that are not relation sets or relations. Some parameters are previously named options or user-defined values.
Figure 2.5 presents an example of a WIM program with just three operations. The output relation is preceded by the sign “=”, for any operation. The operator comes after the sign and is followed by a list of parameters surrounded by parentheses. The first parameters are the input relation sets, followed by possible textual options, and then possible values. Finally, the list of relations and their attributes appear. This list of relations does not appear in the beginning, just after the associated relation set, because the number of possible relations vary for each operator. Observe as an example the operator Search in Figure 2.5. SetquerySet is the first input relation set,textSet is the second input relation set,OR is an option for operator Search, and finallyquery.V andtext.V are input relations followed by the corresponding attribute to which the operator is applied (V in both cases). Details of the WIM language will not be presented in this thesis, though the signatures of some operators are presented associated with the illustration figure in Section 2.2.
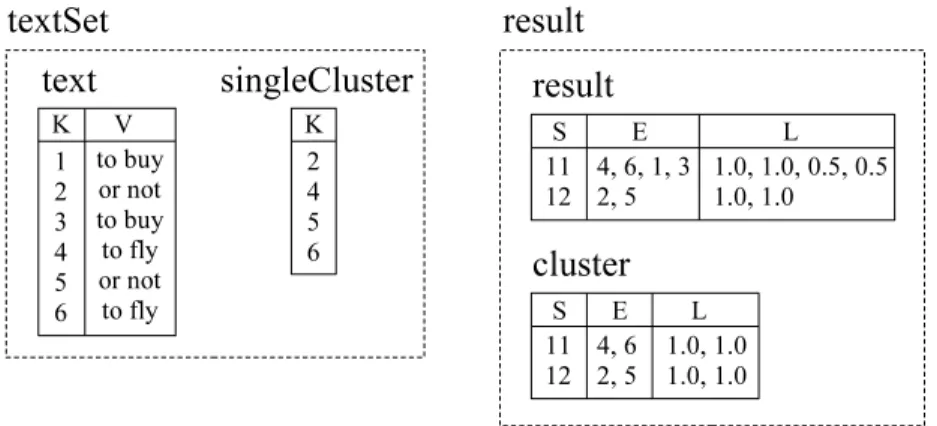
result = Search(querySet, textSet, OR, query.V, text.V); cluster = Select(result, value, ==, 1.0, result.L);
singleCluster = Set(textSet, result, intersection, text.K, cluster.E);
Figure 2.5: An illustration of a WIM program with three operations.
A WIM Database consists of any set of relations, divided accordingly into relation sets, that are registered to be used in programs. Relations in different databases cannot be used in the same WIM program. Relations registered in a WIM database are referred to as Permanent Relations, and relations returned by a WIM program are referred to as Temporary Relations. Temporary relations can only be used within the program they have been created4. Observe that a relation set may contain permanent and temporary relations
2.2. THE WIM ALGEBRA 19
together, during the execution of programs.
2.2.2
Relation Set of an Output
The WIM data model would be useless if operations’ output could not be reused in a program, because, as operations manipulate and mine data, very often several data mining and manipulation operations are needed in sequence in a program, in order to return specific pieces of data to users.
Each WIM operation specification must define the operator’s output characteristics (apart from the input characteristics), like the output relation type, the output relation set, whether the output relation has the value attribute or not and, if true, the type of the value attribute. Further, the relation set which the operator’s output belongs to must be defined, otherwise users do not know what can be done with each operations’ output. There are three possibilities: (i) the output belongs to an input relation set; (ii) the output relation belongs to a new relation set, which is created containing just that relation; (iii) the output belongs to an existing relation set which is not an operation’s input.
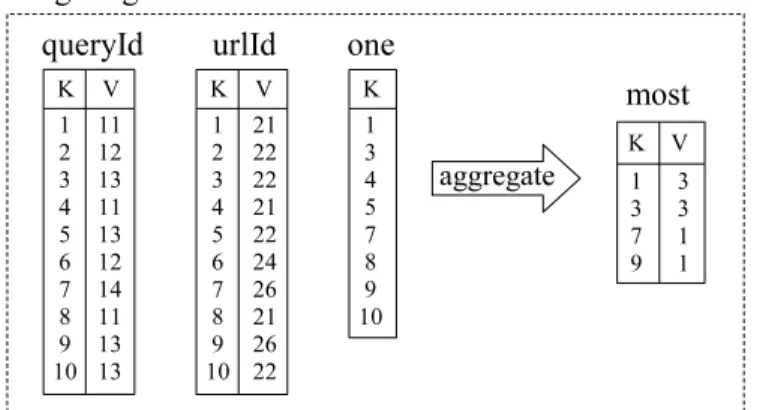
To illustrate the first possibility, consider operators Select and Set in Figure 2.5, which return output relations that belong to the input relation set. Figure 2.6 shows relation cluster as a new relation in the relation set result. Relation cluster only contains edges whose value is equal to 1.0, which is the condition for the selection (edges 11 → 1 and 11→ 3 are excluded for relation cluster). Relation singleCluster does not have attribute V. It is the result of the intersection of attribute K from relation text and attribute E
from relation cluster. Observe that the new relation singleCluster belongs to relation set textSet, which is the first input of the operation.
Figure 2.6: Two compatible relation sets, with new relations (cluster and singleCluster) as result of operations.
Notice that, for the sake of simplicity, the link relationsresult andcluster are illustrated
using a list of end nodes (and their respective labels) associated to each single start node, and that attributeK is omitted in these link relations. This is just a representation used to illustrate link relations in this article (which does not mean that WIM allows multi-valued attributes). For example, for start node 12, there are actually two tuples: (12,2,1.0) and (12,5,1.0) (omitting attributeK).
The second possibility for an operation’s output is to belong to a new relation set. In this case there are two other possibilities: either the output relation set is compatible with an input relation set, or it is not compatible with anything. The latter case might be avoided when designing WIM operations, because the WIM algebra takes advantage of the concepts of relation set and compatibility.
The Search operator in Figure 2.5 is an example of an operator that returns an output relation within a new relation set which is compatible with the input one. Relation result is already represented in Figure 2.4. Observe that relation set result is created because of the Search operator. The start set of relation set result is the foreign key of (and then compatible with) the node relation set querySet, and the end set is foreign key of node relation set textSet.
The third possibility for an operation’s output is to belong to an existing relation set which is not an operation’s input. For illustration, suppose that the fourth operation of the WIM program shown in Figure 2.5 is another operation over relations text and query, returning a link relation with attributes S and E that represent different foreign keys, respectively in relation sets textSet and querySet. This output would be a relation in the existing relation set result. Note that WIM implementation can automatically associate new output relations to existing or new relation sets.
2.2.3
Inheritance Property
The most important property of the WIM algebra is that any value attribute of a relation in a set can be used as value attributes of other relations in the same set, indistinctively. This property means that users can choose a relation from which the key attribute is taken, and other relation in the same set from which the value attribute is taken. This is impor-tant because the need of accessing value attributes from other relations after performing a sequence of operations in a WIM program is quite frequent. This property is called inher-itance, because it means that relations returned by operations actually inherit attributes from other relations in the set.
2.2. THE WIM ALGEBRA 21
appear in relation text, which are in the list (or not, to fly, or not, to fly).
To understand how to use inherited attributes in WIM, consider again Figure 2.5. Note that in every case there is no differentiation from which relation is the value attribute and from which relation is the key attribute, which happens because both attributes come from the same relation. For instance, the first operation uses the value and key attributes from relationquery (see Figure 2.4) for the first input set, and the value and key attributes from relation text for the second input set. If users want to use only the values in relationtextthat exist in relationsingleCluster, they might replace the first operation by:
result = Search(querySet, textSet·singleCluster, OR, query·V, text·V
Note that the relation from which the key attribute is taken is specified with a dot followed by its name, just after specifying the relation set (textSet).
The second most important property of the WIM operations is the inheritance of at-tributes from a compatible node relation set using a relation of a link relation set. Some operators are specially designed taking into consideration this property. For example, con-sider the link relation cluster in Figure 2.6. A given operation can be applied to node pairs that define the edges of the graph represented by this relation, whose start nodes are represented in relation set querySet (see Figure 2.4), and whose end nodes are represented in relation set textSet (see Figure 2.6). For that, values from relation sets querySet and textSet would be inherited and used. For instance, the first edge is 11 → 4, then tuples identified as 11 and 3, respectively in relations query and text, could have their attribute values compared.
2.2.4
Operations of the Algebra
The next sections presents the operations that compose the WIM algebra. When defining the operations in this section, it’s considered that the output relation is identified by an apostrophe (for example, R′). Thus, if the output is a node relation, it is referred to as R′
N, whereas if the output is a link relation, it is referred to as RL′ . Attributes in
{K′, V′, S′, E′, L′} are attributes of the output relation. Input node relations are denoted by RNi,0 ≤ i ≤ 3, whereas input link relations are denoted by RLi,1 ≤ i ≤ 3. When
there is only one relation, then its index is not represented (for example, RN is used
rather than RN1). Attributes in {Ki, Vi} are attributes of input node relations, whose
index i represents the ith
input node relation. Similarly, attributes in {Ki, Si, Ei, Li} are
attributes of input link relations, whose indexirepresents theith
input link relation. Input relations surrounded by square brackets ([]) are optional.
(simplyR is used); (ii) if the output relation goes to the same relation set as the input (for example,{RN, R′
N} ∈SN), or if the output relation set is compatible to the input relation
set (for example, consider R′
N ∈ SN and RL ∈ SL, then SN ⇔ SL); (iii) if the output
represents a subset of tuples from the input (K′ ⊆K) or if the output represents the same
set of tuples from the input (K′ = K); (iv) if the output value attribute (V′ for node
relations andL′ for link relations) exists in the output (for instance, for node relations, the
output R′
N(K′, V′) means that V′ exists, whereas RN′ (K′) means that V′ does not exist);
(v) other constraints, like if S from an input link relation must have a compatible node relation set, i.e., S ⇒SN.
2.2.5
Data Manipulation Operators
Data manipulation refers to retrieval and management of data, which is often required to prepare the data to be used in another operator or returned in an adequate format. These operators are used for selecting tuples, merging relations, and for calculation operations.
Select
This operator selects tuples from the input (node or link) relation, according to a condi-tion, such as equal, different, greater than, etc., which is applied to a numeric attribute. Semantically, Select is defined as:
RN ←Select(SN), where K′ ⊆K, V′ =∅, R
N ∈SN | RL ←Select(SL), where (S′, E′)⊆(S, E), L′ =∅, R
L∈SL
(2.1)
Our representation for the semantic specification of operators consists of the output relation in the left side of the arrow, which is followed by the operator’s name, and its input set(s) surrounded by parenthesis. Observing the semantic definition of operator Select, it is possible to note that it accepts both node and link relations5
as input. The first line defines how it works for node relations, and the second for link relations. Observe that the operator is unary, and the output has the same type as the input.
When semantically defining operators, it is supposed that attributes in {K, V, S, E, L} are attributes of relations in the input set, and attributes in {K’, V’, S’, E’, L’} are attributes in the new output relation. According to the definition of operator Select, its output may be a subset from the input (K′ ⊆K for node relations, and (S′, E′)⊆(S, E)
for link relations). Also, the value attribute is always empty (V′ =∅, andL′ =∅). Further,
the output relation goes to the same set as the input relation set (RN ∈SN and RL ∈SL). The next sections will present the semantic definition of the operators without explain-ing the meanexplain-ing of each part of standard for formalizexplain-ing.
5
2.2. THE WIM ALGEBRA 23
Figure 2.7 presents the syntax of operator Select. It has tree possible options: Value, Attribute, and Top. For option Value, elements of a numeric attribute of the input are compared against a given value passed by the user. For option Attribute, the comparison is performed between two value attributes of different relations in the same relation set. For option Top, only a given number of elements with the highest or lowest values are returned. In this case, the conditions for comparison presented above are not used.
Select := OutputRel ‘=’ ‘Select’ ‘(’ InputSet ‘,’ BodySelect ‘)’ BodySelect := ‘value’ ‘,’ NumRel ‘,’ SelOperation ‘,’ NumValue|
‘attribute’ ‘,’ NumRel ‘,’ NumRel ‘,’ SelOperation|
‘top’ [ ‘,’ Order ] ‘,’ NumRel ‘,’ IntValue SelOperation := ‘==’ |‘! =’|‘<’|‘<=’|‘>’|‘>=’ Order := ‘increasing’ |‘decreasing’
Figure 2.7: Syntax of operator Select.
Figure 2.8 presents an example of operator Select, with option Value. Only tuples whose value in relation countC of relation set usageLog is equal to 1 are returned in relation one.
one = Select(usageLog, value, countC.V, ==, 1);
Figure 2.8: Example of operator Select with option Value.
tfidfPRFinal = Select(tfidf, top, decreasing, tfidfPR2.L, 2);
Figure 2.9: Example of operator Select with option Top, applied to a link relation.
Calculate
This operator is used for mathematical and statistical calculations using numeric attributes. Examples of possible calculations are sum, division, rest of division, and average. Calculate is semantically defined as:
RN ←Calculate(SN), where K′ =K, V′ 6=∅, RN ∈SN | RL ←Calculate(SL), where (S′, E′) = (S, E), L′ 6=∅, RL∈SL
(2.2)
The operator is unary, and both node and link relations are accepted. Its output goes to the same set as the input, and the value attribute is used to represent the result of the calculation performed. As K′ = K (and (S′, E′) = (S, E), for link relations), the output
does not represent a subset from input.
Figure 2.10 presents the syntax for operator Calculate. Two options are possible:
Constant and Pair. For option Constant, the calculation is performed between a constant value passed by the user and each element of an attribute. For option Pair, the calculation is performed between the corresponding elements of two attributes of two relations, for the same tuple.
Calculate := OutputRel ‘=’ ‘Calculate’ ‘(’ InputSet ‘,’ BodyCalc ‘)’ BodyCalc := ‘constant’ ‘,’ ConstOper ‘,’ NumRel ‘,’ NumValue |
‘pair’ ‘,’ PairOper ‘,’ NumRel ‘,’ NumRel
ConstOper := ‘sum’ |‘difference’|‘multiplication’ |‘division’|‘average’ | ‘deviation’|‘mod’ |‘normalize’ |‘absolute’|‘max’|‘min’ PairOper := ‘sum’ |‘difference’|‘multiplication’|‘division’ |‘average’ |
‘mod’ |‘percentage’|‘max’|‘min’
Figure 2.10: Syntax of operator Calculate.