Methodology for Training Small Domain-specific Language
Models and Its Application in Service Robot Speech Interface
ONDAS Stanislav
1, JUHAR Jozef
1, HOLCER Roland
21 Technical University of Košice, Slovakia
Department of Electronics and Multimedia Communications Park Komenského 13, 041 20 Košice, Slovak Republic
E-Mail: {Stanislav.Ondas, Jozef.Juhar}@tuke.sk
2 Z S VVÚ KOŠICE a.s., Research, Development, Design & Supply Company,
Južná trieda 95, 041 24 Košice, Slovakia, E-mail address: [email protected]
Abstract – The proposed paper introduces the novel methodology for training small domain-specific language models only from domain vocabulary. Proposed methodology is intended for situations, when no training data are available and preparing of appropriate deterministic grammar is not trivial task. Methodology consists of two phases. In the first phase the “random” deterministic grammar, which enables to generate all possible combination of unigrams and bigrams is constructed from vocabulary. Then, prepared random grammar serves for generating the training corpus. The “random” n-gram model is trained from generated corpus, which can be adapted in second phase. Evaluation of proposed approach has shown usability of the methodology for small domains. Results of methodology assessment favor designed method instead of constructing the appropriate deterministic grammar.
Keywords: random language model; adaptive speech interface; service robot
I. INTRODUCTION
The field of service robotics is growing rapidly due to the increasing need of automation, safety and time saving. Robotic systems are mainly deployed in industry and nowadays we see applications of robots for healthcare or home-usage too [1], [2].
Using speech for controlling the robotic systems becomes more and more popular, because of its undisputable advantages. Besides the fact that it is one of the most natural communication ways for people it can also improve safety, usage comfort and can decrease cognitive load of the user or operator.
For controlling robotic system by voice, rather than large vocabulary continues speech recognition system (LVCSR), the simpler recognition systems able to recognize isolated words and phrases are often successfully used. These systems are more accurate and also more robust, because of their limited complexity.
The choice of commands-based speech interface brings a need to define all possible speech commands and phrases, which can be used for controlling the robotic device. An appropriate deterministic grammar has to be constructed, which allows desired commands. In the case of robotic systems under construction and of the systems with middle and high complexity could be difficult to define such deterministic grammar. There are two main reasons. First reason is that the robotic system is not fully developed. Therefore we do not know exactly how it will be used. The second reason of difficulty is the complexity of the robotic system, which do not enable us to write sufficient complex grammar. Creation of the stochastic language model (n-gram) can be seen as the logical solution, unfortunately, often there are no training data to train such a model.
During designing the speech interface for the complex modular robotic system (CMRS) (described more detailed in section III and [3]) we were in situation described in previous paragraph. In that time, the idea to develop the methodology for creating the small domain-specific language models for middle-complex systems, which does not require any training corpus, appeared.
The next reason to design a new methodology was that we were not able to find any other methodology, which can be used in our situation. The closest approach to our idea has been presented by Harris in [9], who generated the bigram language model from Phoenix grammars. Such approach tries to learn language grammar from set of accurate-designed deterministic grammars. Unfortunately, there are no such grammars for our domain.
There are also a lot of approaches, which are based on adaptation of language model (general or for other domain) on new domain with a small training corpus, e.g. one presented by Rudnicky in [10]). Such approach requires availability of small training set for language model adaptation. The next disadvantage of this approach lies in the relative large model, which should not be suitable for low-resources devices.
Therefore the new methodology was designed, which enables to train language models only from _____________________________________________________________________________________________________________
domain vocabulary and to adapt them to operator’s usage style. The methodology was applied to train a small domain-specific language model for speech interface to complex modular robotic system. The performance of prepared language model and its adapted versions were tested and evaluated.
The paper is organized as follows. The section II provides the description of designed methodology. Section III briefly introduces the complex modular robotic system and the speech interface, where the newly-designed methodology has been applied. Section IV. describes the evaluation of adaptation process of constructed domain-specific language model.
II. METHODOLOGY FOR BUILDING DOMAIN-DEPENDENT LANGUAGE MODELS
In case of very limited resources and the domain with middle complexity that does not enable to create usable deterministic language model (grammar) usually the Wizard-of-Oz simulation can be applied. However, there are situations, e.g. if is expensive or time consuming to build the model of desired system, which do not enable to perform Wizard-of-Oz. For such situations we designed the methodology for training the small domain-specific stochastic language models only from the domain vocabulary.
The methodology has two phases - constructing of so called “random” bigram model and adaptation of this model.
The phase 1consists of following steps: 1. Collecting the service vocabulary
Service vocabulary can be constructed by summarization of devices, functions and parameters of the robotic system. Such vocabulary should be extended by all possible variants of word’s basic form (e.g. by their inflected forms).
2. Constructing the deterministic grammar, which can generates random words (unigrams) and word pairs (bigrams).
Grammar that generates single words and pairs of words (bigrams) should looks like one drawn in Fig. 1.
Fig. 1 Deterministic grammar for generating unigrams and random bigrams
3. Generating all possible word pairs (bigrams).
4. Training stochastic language model from the set of generated word pairs. We named the result of this process “random bigram model”.
The phase 2 is focused on the adaptation of prepared random bigram model. It is performed during the initial using of the desired system. The adaptation can be done
directly by speech commands spoken by the operator without any post processing, but better results can be obtained using manually corrected commands.
Developed methodology enables to build and adapt domain-specific small language model, which will be adapted to the operator-style.
III. COMPLEX MODULAR ROBOTIC SYSTEM
The complex modular robotic system has been designed and is developed in range of three projects. The mobile robotic platform (3D model on Figure 1), developed ZTS VVÚ a.s. Košice company, able to move autonomously in rugged terrain with the speed about 3-5km/h and gradeability of 45°, with usable capacity of 400kg is intended to be the output of the work in range of the mentioned projects. The robotic vehicle will bear several superstructures (extensions):
the robotic arm with 6 degrees of freedom and nominal load 200kg
the extricate system with expansion force 20 kN the decontamination system for removing of toxic substances
Fig. 2. Model of the complex modular robotic system However the introduced robotic system will be able to perform several tasks fully autonomously, a lot of other tasks need some cooperation with human operator. The usage scenario of such systems is, that the mobile robotic platform (vehicle) has wireless connection with the control panel computer, which can be encapsulated in to the robust briefcase (e.g. in [4]). Such control panel provide an interface between operator and robotic vehicle, which enables to control it by joystick, keyboard or buttons and the information from vehicle are depicted on display.
To add the possibility to control selected functions by speech can significantly increase usability of the robotic system, due to the fact, that a large range of system’s functions is difficult to control only by hands. Therefore, modules, which enable cooperation with robotic system through speech interaction, need to be designed and integrated.
A. The robot speech interface
The robot speech interface for controlling the complex modular robotic system has been designed and is under development.
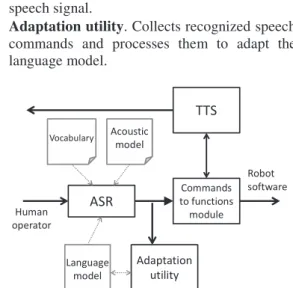
The pilot version of the interface (Fig. 3) consists of four fundamental components:
_____________________________________________________________________________________________________________
•
ASR
(Automatic Speech Recognition) module that transforms speech signal into the text commands.• Commands to functions module. It performs
mapping of speech commands into the robot’s functions.
• TTS (Text-to-speech) system performs speech
synthesis, which transforms text output to speech signal.
• Adaptation utility. Collects recognized speech
commands and processes them to adapt the language model.
Fig. 3 The robot speech interface architecture
ASR module was created by integration an open-source speech recognition toolkit, described in [5]. The appropriate parameterization and acoustic were prepared for speech recognition process. The most used parameterization, based on MFCC (Mel-frequency cepstral coefficients) coefficients was selected. The vector of parameters consist of twelve static MFCC coefficients, zero coefficient (0), delta (D), acceleration or acceleration coefficients (A) and with subtraction of cepstral mean (Z) – (MFCC_D_A_Z_0) and its length is 39 values.
Acoustic models were adopted from our LVCSR system. They were trained on parliament speech database mostly. Training process as well as results were described in [6].
Commands to functions module performs mapping of speech commands into the functions of the robotic system. By analysis of devices, functions and parameters eight semantic categories were selected (Function, Agens, Patiens, Direction_atr, Volume, Unit, AP_Atributes and Oth) to categorize meaning of the input words. The keyword-spotting algorithm was implemented to map incomming words into proposed categories. 14 functions of the robot and its devices were identified and defined (with their parameters and results). Each speech command is then mapped into one of them.
Text-to-Speech system has been integrated also, because a need of producing some feedback to the operator. The ussual scenario of teleoperation mode is that the operator speaks commands, which are repeated by the system and then confirmed by operator. The
HMM-based approach has been integrated, wich is described in [7].
The adaptation utility collects recognized speech commands and processes them to adapt the language model. Voice commands with average confidence greater than threshold are selected for adaptation. SRILM toolkit is used to adapt language model using new voice commands.
IV. EVALUATION
The proposed method for creating domain-specific small language models was applied for training language model for the speech interface of the complex modular robotic system.
Devices and functions of the robotic system were analyzed and the vocabulary with approx. two hundred words was prepared. Then the random deterministic grammar was constructed in Julian format, which generates all possible unigrams and bigrams. The utility for generation all possible sequences from such a grammar was prepared. Another utility for generation random sentences from deterministic grammar, which is a subpart of Julius recognition toolkit [5], can be used also, but often it was not able to generate all possible bigrams (only subset). Both utilities were tested and the first one was selected for generating all possible bigrams. The training set consisting of 40 thousand unigrams and bigrams was generated from deterministic grammar. Then, SRILM toolkit [8] was used for training the random bigram model. The same toolkit was used also for adaptation of the model.
For testing purposes 206 speech commands were spoken and recorded by the operator. In the next step, the manual transcription was done to be able to compute Word Error Rate (WER).
The first experiment was focused on the obtaining of the reference WER, which can be reached by the deterministic grammar constructed from vocabulary, which enables random sequences of words. Next experiment was focused on evaluation of the random n-gram model, which was constructed from deterministic grammar. Table 1 contains comparison obtained results.
TABLE 1. Comparison of deterministic grammar and random bigram model.
MODEL TYPE WER (%)
deterministic random grammar 21,23
random bigram model 10,61
As is shown in Table 1, random bigram model provides significantly better results than deterministic random grammar. For such small domain, prepared random bigram model can be successfully used also without adaptation.
In the next step, the adaptation was performed. The operator started to use the speech interface and to perform tasks according prepared usage scenarios. The adaptation utility collected the recognized commands. We experimentally set the threshold for taking the command into adaptation process on accuracy of 80%. _____________________________________________________________________________________________________________
From first 180 recognized speech commands, 90 commands were collected for adaptation. Firstly we tried to adapt the basic random model without any post-processing of recognized commands. Then, recognized commands were manually post-corrected, and the basic model was adapted again. WER parameter was evaluated for both adaptations – one without post-correction and one with post-post-correction. Table 2. contains obtained results.
TABLE 2. Results of random bigram model adaptation.
MODEL TYPE WER (%)
adaptation without post-correcting 8,94 adaptation with post-correcting 5,59
Results in Table 2 show, that adaptation of the random model can bring further improvement of accuracy. Adaptation without post-correcting of training data brought relative improvement of 12% in comparison to basic model. In case of post-corrected training set, 45% relative improvement has been reached. Moreover, such improvement was reached with very small training set of 90 speech commands.
We can conclude that we obtained WER which is comparable to WERs that can be obtained from hardly-defined rule-based deterministic grammar.
IV. CONCLUSIONS
The proposed paper introduces the new methodology for training small domain-specific language models only from vocabulary. The methodology is divided into two phases. In the first phase, the “random” language model is trained from bigram sequences generated from deterministic grammar, which enables whatever word pairs. Such a grammar can be easily constructed from the vocabulary of particular domain. The second phase of the methodology is performed in early using of the robotic system and is focused on the adaptation of the “random” language model with previously recognized speech commands.
Such a methodology can be helpful in case of the difficulty to prepare deterministic grammar for particular domain (because of its complexity) together with unavailability of training data. It also enables to adapt the system to the operator’s style of system’s using.
There can be seen two main advantages of proposed methodology. The first advantage lies in reducing the costs (or difficulty) of preparing an appropriate language model for small domain speech interfaces. In spite of preparing heavily-constructed grammar, our methodology requires only collecting of vocabulary for desired domain. Next steps can be automated easily and they do not require any special knowledge or resources. The second advantage arises from using of stochastic language models. In spite of deterministic grammar they can be easily adapted.
Designed methodology was applied for preparing the language model for the speech interface of complex modular robotic system and was evaluated on the speech
commands for such a system. The evaluation shows that using of “random” n-gram model itself increases accuracy of the system in comparison to “random” deterministic grammar and adaptation of the model has potential to increase accuracy even more.
In our future work we plan to focus on testing the methodology on larger domains and also on tuning the training and adaptation process.
ACKNOWLEDGEMENT
The research presented in this paper was supported partially (50%) by Research & Development Operational Program funded by the ERDF through project Research of modules for intelligent robotic systems (ITMS project code 26220220141) and partially (50%) by Competence Center for Innovation Knowledge Technology of production systems in industry and services (ITMS project code 26220220155).
REFERENCES
[1] E. Broadbent, R. Stafford, B. MacDonald, “Acceptance of healthcare robots for the older population: Review and future directions”, International Journal of Social Robotics, 1 (4), pp. 319-330, 2009
[2] P. Boissy, H. Corriveau, F. Michaud, D. Labonté, M.-P. Royer, “A qualitative study of in-home robotic telepresence for home care of community-living elderly subjects” Journal of Telemedicine and Telecare, 13 (2), pp. 79-84, 2007
[3] S. Ondáš, J. Juhár, M. Pleva, M. Lojka, E. Kiktová, M. Sulír, A. ižmár, R. Holcer. Speech technologies for advanced applications in service robotics. In: Acta Polytechnica Hungarica. Vol. 10, no. 5 (2013), p. 45-61. - ISSN 1785-8860
[4] S. Ondas S., “Service robot SCORPIO with robust speech interface”, In: International Journal of Advanced Robotic Systems. Vol. 10, no. 3, p. 1-11. ISSN 1729-8806, 2013. [5] A. Lee, T. Kawahara and K. Shikano, Julius - an open
source real-time large vocabulary recognition engine, in: Proceedings of Eu-ropean Conference on Speech Communication and Technology (Eurospeech), Aalborg, Denmark, 2001, pp. 1691-1694.
[6] S. Darjaa, M. Cer ak, M. Trnka, M. Rusko, R. Sabo, “Effective Triphone Mapping for Acoustic Modeling in Speech Recognition”, Proc. of INTERSPEECH 2011, Florence, Italy, pp. 1717-1720, 2011.
[7] M. Sulír, Phonetically Balanced Slovak Speech Corpus for Text-To-Speech Synthesis. In: SCYR 2013: Proceedings from conference: 13th Scientific Conference of Young Researchers: May 14th, 2013, Her any, Slovakia. - Košice : TU, 2013 S. 392-394. - ISBN 978-80-553-1422-8
[8] A. Stolcke, J. Zheng, W. Wang, V. Abrash, SRILM at sixteen: update and outlook, in Proceedings of IEEE Automatic Speech Recognition and Understanding Workshop, (Waikoloa, ASRU, 2011), 5 pp.
[9] T. K. Harris, Bi-grams Generated from Phoenix Grammars and Sparse Data for the Universal Speech Interface. In: Language and Statistics Class Project, CMU, May 2002
[10]A. I. Rudnicky, Language modeling with limited domain data, Proceeding of the 1995 ARPA Workshop on Spoken Language Technology, Morgan Kaufmann, 1995, pp.66-69.
_____________________________________________________________________________________________________________