Improved Offline Connected Script
Recognition Based on Hybrid Strategy
Ghazali Sulong , Amjad Rehman and Tanzila Saba Department of Computer Graphics and Multimedia
University of Technology Malaysia (UTM) Skudai, Malaysia
Abstract
In domain of analytic cursive word recognition, there are two main approaches: explicit segmentation based and implicit segmentation based. However, both approaches have their own shortcomings. To overcome individual weaknesses, this paper presents a hybrid strategy for recognition of strings of characters (words or numerals). In a two stage dynamic programming based, lexicon driven approach, first an explicit segmentation is applied to segment either cursive handwritten words or numeric strings. However, at this stage, segmentation points are not finalized. In the second verification stage, statistical features are extracted from each segmented area to recognize characters using a trained neural network. To enhance segmentation and recognition accuracy, lexicon is consulted using existing dynamic programming matching techniques. Accordingly, segmentation points are altered to decide true character boundaries by using lexicon feedback. A rigorous experimental protocol shows high performance of the proposed method for cursive handwritten words and numeral strings.
Keywords-explicit segmentation, implicit segmentation, hybrid strategy, dynamic programming,
cursive character recognition.
Improved Offline Cursive Script
I. INTRODUCTION
The recognition of handwritten words and numeral strings are researched as two different problems in the past few years. A considerable number of methods are developed to recognize either words or numeral strings. This splitting of the problem has resulted in methods with good performance for one of those problems, but not suitable for both.
wide cannot be covered in the hypothesis. Whereas, larger value ofXmax, generates more slices that again have two main shortcomings. First, it is computationally expensive since it increases number of character hypothesis and therefore, all hypotheses generated
Improved Offline Cursive Script
must be evaluated. This is a very important issue that has been ignored very often in the literature [10]. Second, more severe number of clutters increased significantly that is additional burden on character recognizer in modeling clutters [11].
Another problem that is faced by implicit based recognizer is that segment of one character looks like part of another character or a valid character itself which is called the class-overlapping problem [12]. Additionally, it is evident that segmentation upon recognition has some shortcomings particularly in case of word with illegible, missed or broken characters [13]. In this regard, Britto in [14-15] have observed some loss in recognition performance caused by recognition based segmentation. Additionally, the algorithms developed so far are specific for the applied problem, and a good segmentation algorithm for numeral strings may not have the same performance for words, and vice-versa [11].
Therefore, keeping in view the limitations of each analytical approach, success seems to fuse both approaches termed as hybrid approach in this research. Section II presents the proposed methodology, results are exhibited in section III and finally conclusion is drawn in section IV.
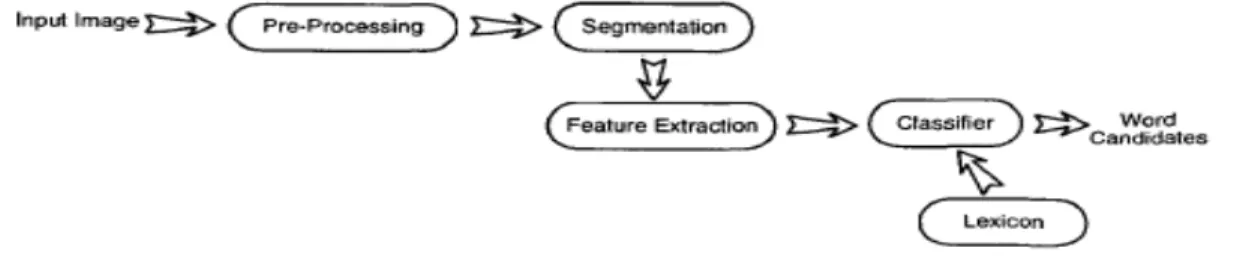
II. PROPOSED METHODOLOGY
Figure 1: Block diagram of proposed Heuristic Rule based hybrid approach.
A. Preprocessing and over-segmentation phase
Following digitization, handwritten images are threshold to filter noise using automatic algorithm [16]. Since, the approach follow vertical cut strategy therefore, to avoid shadow of one character to the neighboring, slant correction is performed [21]. Finally, to workout with the geometrical properties and to accommodate large variability of the handwriting’s stroke width, thinning operation is performed [17]. Figure 2 exhibits preprocessing results.
a. b c
Figure 2: Preprocessing steps: a. Threshold image b. Slant corrected c. Thinned image
Lee and Verma in [7] stressed that over-segmentation process elevates segmentation accuracy. Therefore, the word image is over-segmented heuristically at distance ' 'x to ensure that all valid segmentation columns are marked regardless invalid dissections which is tradeoff.
B. Character validation phase
In order to detect and eliminate incorrect segmentation points that came forth due to over-segmentation, each segmentation column is checked according to some criteria which are characteristics of segmentation points detailed as below.
Loops and semi-loops detection: Loops and semi-loops are always part of characters and therefore are
Figure 3: Loop/semi loop/ ligature detection in thinned image
Character’s boundary detection: As few characters do not contain loop or semi loop such as ‘m’, ‘n’, ‘u’,
‘v’, ‘7’ and ‘h’, therefore can’t get any treatment for their over-segmentation. However, it is mentioned once again that all characters are over-segmented at successive distance in previous phase. Therefore, in order to set actual boundaries of such characters, it is desired to first detect such over-segmented characters. Accordingly, all successive segmentation columns are evaluated once again from their horizontal distance point of view. If successive vertical columns are at distance' 'x , it shows redundant and incorrect result to have a large number of successive segmentation columns at same distance. Therefore, first and last segmentation columns are accepted, extracting the between ones.
Clutter detection and removal: Finally, to reduce matching classes and burden of the classifier, fragments
that don’t belong to any character are identified as clutters. Accordingly, a simple rule is derived for this purpose. If consecutive vertical segment columns still exist at distance less than or equal to' 'x , set their median as segmentation columns.
Figure 4: A series of processing results of heuristic rule-based hybrid approach.
Figure 5: Character segmentation of unconstrained handwritten numerals
C. Segmentation of horizontally overlapped characters
Figure 6: Incorrect segmentation due to touched/ overlapping neighbors
It is mainly due to the reason that ligatures are analyzed vertically from top to bottom. To handle miss-segmentation problem for overlapped characters in the image, rather to perform vertical dissection on the word image from top to bottom, segmentation techniques are applied into the core-region only to determine accurate boundaries of horizontally overlapped characters. However, touching character segmentation problem is out of scope of current research. Accordingly, string core-region is detected based on the improved technique mentioned in [21]. Hence, core-region based segmentation ensures that none of the overlapped characters left un-segmented as shown in Fig 7.
Figure 7: Segmentation of horizontally overlapped character
D. Post-processing phase
over-segmentation, lexicon driven implicit based recognition is introduced. It employed existing dynamic programming technique to find the legal union of primitives so that results are set of accurate matched symbols in the lexicon.
The segments in this research are obtained through proposed explicit segmentation (heuristic rule based segmentation) and existing dynamic programming technique is used to find the best path through space of segments and legal unions of segments [18]. Accordingly, values for nodes are computed to find the best path as exhibited in figure 8. However, in this research, value of each node is provided solely by the character confidence output of the multilayer perceptron (MLP) trained with back-propagation algorithm [22].
Figure 8: An illustration of the word recognition based on dynamic programming
III. CLASSIFICATION RESULTS
A rigorous experimental protocol has been used in order to construct and evaluate our string recognition system. The experiments are performed on touching numeral strings of different lengths extracted from NIST SD19 database [19], and unconstrained cursive handwritten words available in IAM database [20]. A. Experiments on handwritten touched numeral strings
The experiments on handwritten unconstrained numeral strings are carried out using 1,316 numeral strings extracted from the NIST SD19 and distributed into 4 classes: 2 digit (370), 3 digit (285), 4 digit (345) and 5 digit (316) strings. Few character segmentation results on numerals are presented in figure. Finally, detailed analysis is presented in Table 1.
Table 1. UNCONSTRAINED SCRIPT NUMERAL STRING RECOGNITION RATE (%)
Class Top 1 Top 2 Top 3
50 81.01 84.89 89.42
150 76.31 78.96 83.32
300 71.65 74.10 79.57
IV. CONCLUSION AND FUTURE WORK
The experimental results of this research for recognizing numeral strings and words have shown promising performance to have a method to recognize any kind of handwritten string. This hybrid strategy has enabled to segment and verify through recognition. The first stage has shown to be suitable to the task of character segmentation for both words and numeral strings, and the feature set used in the verification stage has shown good performance to recognize both digits and letters. We may improve the performance of the proposed method by further development in a number of areas. One way to do that is by further investigating feature sets, since this method enables the combination of different features at each stage. For instance, a new set of foreground features can be defined to improve the segmentation performance of the first stage, while new features with powerful recognition performance can be evaluated in the second stage. Another point to be investigated is the increasing of the training data, what can adjust better the segmentation and the recognition.
ACKNOWLEDGMENT
This work is supported by Ministry of Science, Technology and Innovation (MOSTI). Authors would like to thank Research Management Center, Universiti Teknologi Malaysia for the research activities and anonymous reviewers for their incisive comments to improve this article.
REFERENCES
[1] A. El-Yacoubi, M. Gilloux, R. Sabourin, C.Y. Suen.“An HMM-based Approach for Online Unconstrained Handwritten Word Modeling and Recognition”. IEEE Transactions on Pattern Analysis and Machine Intelligence, 21(8),1999, pp. 752-760. [2] N. Arica, F.T. Yarman-Vural, “Optical Character Recognition for Cursive Handwriting. IEEE Transactions on Pattern Analysis
and Machine Intelligence”, 24(6),2002, pp. 801-813.
[4] W.Cho, S.W.Lee, J.H.Kim, “Modeling and Recognition of Cursive Words with Hidden Markov Models”. Pattern Recognition, 28(12):1995, pp.1941-1953.
[5] Y. LeCun, L.Bottou, Y. Bengio, and P.Haffner. “Gradient Based Learning Applied to Document Recognition”. Proceedings of IEEE, Vol. 86(11), 1998, pp.2278-2324.
[6] A. Rehman, and M.Dzulkifli, “A Simple Segmentation Approach for Unconstrained Cursive Handwritten Words in Conjunction with the Neural Network, International Journal of Image processing, 2(3), 2008, pp. 29-35.
[7] H.Lee, and B. Verma. “A Novel Multiple Experts and Fusion Based Segmentation Algorithm for Cursive Handwriting Recognition”. Proceedings of the International Joint Conference on Neural Networks (IJCNN'08), 2008, pp.2994-2999. [8] P. Zhang, T.D. Bui, and C.Y. Suen, “A Novel Cascade Ensemble Classifier System with a High Recognition Performance on
Handwritten Digits”, Pattern Recognition, 40(12),2007,pp.3415-3429.
[9] Y.H.Tay, M. Khalid, R. Yusof, and C.V. Gaudin. “Offline Cursive Handwriting Recognition System based on Hybrid Markov Model and Neural Networks”. Proceedings of IEEE International Symposium on Computational Intelligence in Robotics and Automation, Kobe, Japan, 2003, pp. 1190-1195.
[10] L.S. Oliveira, A.S. Britto and R. Sabourin.“A Synthetic Database to Assess Segmentation Algorithms”. Proceedings of Eight International Conference on Document Analysis and Recognition,1, 2005,pp.207-211.
[11] P.R.Cavalin, A.S.Britto, F.Bortolozzi, R.Sabourin and L.S.Oliveira. “An Implicit Segmentation based Method for Recognition of Handwritten Strings of Characters”. Proceedings of ACM symposium on applied computing, 2006, pp.836-840.
[12] Y.H.Tay.”Offline Handwriting Recognition using Artificial Neural Network and Hidden Morkov Model”.PhD thesis,Universiti Teknologi Malaysia, Skudai,2002, Page.30,
[13] K.M. Sayre. “Machine Recognition of Handwritten Words: A Project Report”. Pattern Recognition, 5, 1973,pp.213-228. [14] A.S.Britto, R.Sabourin, F.Bortolozzi,C.Y.Suen.”An Enhanced HMM Topology in an LBA Framework for the Recognition of
Handwritten Numeral Strings”, Proceedings of the International Conference on Advances in Pattern Recognition,Rio de Janeiro-Brazil.(1), 2001, pp. 105-114
[15] A.S.Britto, R. Sabourin, F.Bortolozzi, C.Y. Suen.“A Two-Stage HMM-Based Systems for Recognizing Handwritten Numeral Strings”. Proceedings of the International Conference on Document Analysis and Recognition, Seattle, USA, 2001,pp.396-400. [16] N.Otsu.”A Threshold Selection Method from Gray level Histograms”, IEEE Trans. on Systems, Man and Cybernetics 9(1),
1979, pp.63-66.
[17] T.Y.Zhang, and C.Y.Suen. “A Fast Parallel Algorithm for Thinning Digital Patterns”Communications of the ACM, 27, 1984, pp.236-239.
[18] P.D. Gader,M. Mohamed, J.H.Chiang.”Handwritten Word Recognition with Character and Inter-character Neural Networks”, IEEE Transition on System, Man, Cybernetics. part B: Cybernetics 27, 1997, pp.158–164
[19] P.J.Grother, “NIST Special Database 19-Handprinted Forms and Characters Database”. National Institute of Standards and Technology.1995.
[20] U.Marti, and H.Bunke. “The IAM database: An English Sentence Database for Off-line Handwriting Recognition”. International Journal of Document Analysis and Recognition, 15, 2002, pp.65-90.
[21] A. Rehman, D. Mohammad, G. Sulong. “Simple and Effective Technques for Core-region Detection and Slant Correction in Script Recognition” Proceedings of IEEE , International Conference on Signal and Image Processing (Accepted)