Segmentação de Íris utilizando Bag of Keypoints
São Paulo
Segmentação de Íris utilizando Bag of Keypoints
Este trabalho tem como objetivo principal a utilização de uma técnica de visão compu-tacional chamadaBag of Keypointsna locali-zação e segmentação de íris e a comparação dos resultados obtidos com os resultados de uma disputa de segmentação de íris.
Orientador:
Prof. Dr. Maurício Marengoni
UNIVERSIDADE PRESBITERIANA MACKENZIE
RUA DA CONSOLAÇÃO, 930 CEP 01302-907 - CONSOLAÇÃO
SÃO PAULO - SP - BRASIL
Paulo, estado de São Paulo, pela banca examinadora constituída pelos doutores:
Prof. Dr. Maurício Marengoni Orientador
Prof. Dr. Leandro Augusto da Silva Universidade Presbiteriana Mackenzie
Lista de Figuras
Lista de Tabelas
1 Introdução p. 11
2 Revisão Bibliográfica p. 14
2.1 Segmentação . . . p. 14 2.1.1 Clusterização . . . p. 15 2.1.2 Técnicas baseadas em histograma . . . p. 15 2.1.3 Detecção de arestas . . . p. 16 2.1.4 Crescimento de regiões . . . p. 17 2.1.5 Watershed . . . p. 18 2.2 Clusterização e Modelo de Curvatura . . . p. 18 2.3 Localização de reflexos, limites da íris e limites da pálpebra . . . p. 20 2.4 Detecção de íris através da combinação de pupila e íris . . . p. 21 2.5 Localização do limite límbico . . . p. 22 2.6 Localização da íris através da busca de círculos e reflexos especulares . p. 23 2.7 Segmentação de íris através da detecção da esclera . . . p. 25
5 Metodologia Científica p. 38 5.1 Base de Dados . . . p. 38 5.2 Detecção e Representação de Pontos Característicos . . . p. 39 5.3 Dicionário de Pontos Característicos . . . p. 39 5.4 Treinamento e Classificação . . . p. 40 5.5 Segmentação . . . p. 42
6 Resultados p. 44
6.1 Pontos característicosSIFT ouSURF? . . . p. 44 6.2 Número de pontos descritores em cada imagem . . . p. 44 6.3 Número de palavras no vocabulário . . . p. 45 6.4 Region Growing . . . p. 46 6.5 Um processo mais simples . . . p. 49
7 Conclusões e Trabalhos Futuros p. 51
1
Introdução
A biometria é uma área de estudo que utiliza características físicas e/ou comporta-mentais das pessoas para fazer a identificação de um indivíduo. Os sistemas de identi-ficação biométrica estão se tornando cada vez mais populares devido a características do tipo confiança, velocidade de execução, conforto de utilização e dificuldade de fal-sificação[2]. Os sensores que capturam estas características biométricas, normalmente, são sensores ópticos e técnicas de processamento de imagens são utilizadas para fazer a identificação de indivíduos.
Existem diversas características que podem ser utilizadas no reconhecimento de uma pessoa, entre elas estão: impressão digital, voz, modo de andar, face e íris. O reconhecimento utilizando a íris se destaca pela dificuldade de se alterar acidentalmente ou intencionalmente as suas características, já que a íris é um órgão protegido dentro do olho humano. O reconhecimento é feito através do padrão da íris, isto é, o anel colorido que circunda a pupila do olho, sendo que este padrão é único e se mantém inalterado durante toda a vida de uma pessoa[3].
Qualquer sistema de reconhecimento de íris segue basicamente os mesmos passos:
• Aquisição da imagem,
• Segmentação da íris na imagem,
• Extração das características (isto é, obter os padrões da íris) e
• Comparação das características extraídas com uma base de dados.
O passo mais crítico entre os descritos acima é a segmentação, pois a segmentação incorreta da íris pode ocasionar o reconhecimento incorreto de uma pessoa. Os pro-blemas que surgem durante esta etapa são: a variabilidade do posicionamento e do tamanho da íris na imagem, presença de oclusões (causadas por cabelos, cílios, pálpe-bras e óculos); borrões na imagem; problemas no foco; reflexos especulares e ângulos de visão oblíquos.[4]
(a) (b)
Figura 1: Exemplo de segmentação incorreta, com diversos tipos de ruído.
Os algoritmos de reconhecimento de indivíduos à partir da identificação de íris ge-ralmente são projetados para aquisição da imagem da íris de forma cooperativa, isto é, o usuário que será reconhecido facilita o processo de captura da imagem de sua íris (por exemplo, o usuário se mantém parado na frente da câmera). Os maiores proble-mas aparecem quando a aquisição da imagem da íris é feita de forma não cooperativa, onde o usuário tem pouca ou quase nenhuma participação no processo de captura da imagem. Com isso, as imagens capturadas apresentam diversos tipos de ruído (proble-mas de foco ou de posicionamento da íris), dificultando o processo de captura da íris e, conseqüentemente, o reconhecimento da pessoa[5].
Todo o processo de captura, segmentação e identificação da íris deve ser rápido e robusto. A robustez está relacionada com a capacidade do algoritmo em lidar com diversos tipos de ruídos e ainda assim reconhecer o indivíduo corretamente. Em termos de rapidez devemos salientar que uma pessoa, mesmo atuando de forma colaborativa irá permanecer parada para a captura de uma imagem apenas por alguns segundos. O desempenho global do sistema de reconhecimento de íris está diretamente ligado com o desempenho do algoritmo de segmentação (pois é nesta etapa que o algoritmo extrai de maneira eficaz a região da imagem associada exclusivamente com a íris)[6].
Atualmente, os algoritmos para detecção e segmentação de íris tem sido baseados em diversas ténicas de processamnto de imagens e de visão computacional. Entre elas podemos citar técnicas de segmentação de íris através da localização de círculos em imagens, clusterização e a detecção da esclera com o intuito de localizar a íris.
A pesquisa realizada durante o desenvolvimento deste trabalho procurou responder às seguintes questões técnicas:
• É possível limitar a região de uma imagem de forma inteligente e computar pontos característicos apenas dentro destas regiões?
• É possível utilizar estes pontos característicos do tipoSURF para localizar objetos de interesse do tipo íris?
agru-pamento ou crescimento de regiões e segmentar uma região de interessenuma imagem?
Este trabalho se difere de outros que também fazem a segmentação de íris pois ex-plora a possibilidade de se utilizar uma técnica de visão computacional chamadaBag of Keypoints(baseada em uma técnica de processamento de textos chamadaBag of Words), para identificar regiões da imagem que possuem trechos da íris. Com algumas regiões da íris identificadas, são selecionados pontos dentro destas regiões e, consequentemente dentro da íris, para serem utilizados como sementes da técnica deRegion Growingque é utilizada então para segmentar a íris.
2
Revisão Bibliográfica
2.1
Segmentação
Segmentação é o processo de divisão de uma imagem em grupos de pixels homo-gêneos em alguma propriedade e que simplifiquem a representação da imagem, facili-tando assim uma posterior análise e reconhecimento ou classificação. A segmentação geralmente é utilizada como um pré-processamento na localização de objetos e con-tornos (linhas, curvas ou outras formas geométricas) em imagens. Na Figura 2, são exibidas diversas segmentações de íris, com baixa taxa de erro na área segmentada, ob-tidas no NICE.I. A região verde das imagens indica segmentação em excesso e a região vermelha indica a falta de segmentação.
Figura 2: Exemplo de segmentações com baixas taxas de erro no NICE.I[1]
Uma vez segmentadas, as imagens podem ser utilizadas em diversas aplicações, entre elas podemos citar:
• Aplicações médicas
– Medição de volume de tecidos [8]
– Diagnósticos[9]
– Estudo da estrutura anatômica[10]
• Localização de objetos em imagens de satélites (estradas, florestas, etc.) [11]
• Reconhecimento de face[12], impressão digital[13], íris[14]
Diversas técnicas de processamento de imagens têm sido utilizadas no processo de segmentação, porém, não existe uma técnica que seja de uso geral e que possa ser aplicada em qualquer situação. Uma forma comum de se segmentar imagens é a aplicação de várias técnicas de filtragem e binarização combinadas que resolvem, de maneira eficaz, um problema de segmentação específico.
Entre as técnicas mais utilizadas na segmentação de imagens podemos citar: cluste-rização[15], técnicas baseadas em histograma [16], detecção de arestas[17], crescimento de regiões[18], particionamento de grafos[19]ewatershed[17].
2.1.1
Clusterização
De forma geral as técnicas de clusterização dividem os dados em grupos baseado em alguma medida de proximidade. Existem dois tipos de abordagens para este tipo de técnica: hard clustering, onde cada pixelda imagem pertence a apenas um grupo; e clusterização do tipofuzzy, onde umpixelpode pertencer a mais de um grupo com um determinado fator de pertencimento[15].
Os algoritmos de clusterização não necessitam de uma rede de treinamento e exis-tem três algoritmos que são freqüenexis-temente utilizados:k-means,expectation-maximization
efuzzy c-means.
O algoritmo k-means agrupa os dados calculando iterativamente a intensidade de nível de cinza média para cada agrupamento e segmenta a imagem classificando cada
pixelno grupo onde a diferença entre a propriedade verificada no pixel e a média do grupo for mínima. O algoritmoexpectation-maximization possui basicamente o mesmo princípio que o algoritmo k-means, porém este método assume que os dados seguem um modelo Gaussiano (também conhecido como distribuição normal), neste caso, um pixel pertence ao grupo se a probabilidade de pertencer a distribuição de um grupo for maior que pertencer a qualquer outro grupo.
No algoritmo fuzzy c-means, cada pixeltem uma probabilidade (fator de pertenci-mento)de pertencer a um certo grupo, isto é, quanto maior o valor que associa umpixel
a um grupo, maiores são as chances destepixelpertencer ao grupo.
2.1.2
Técnicas baseadas em histograma
As técnicas de segmentação baseadas em histogramas são computacionalmente mais eficientes quando comparadas a técnicas de outros tipos, pois, neste tipo de técnica um
utilizando-se todos ospixels da imagem e, após esta etapa, os picos e vales gerados no histograma são utilizados para localizar grupos na imagem[20].
Uma outra forma de segmentação é a aplicação recursiva desta técnica nos grupos encontrados, com o intuito de obter grupos menores e uma segmentação mais deta-lhada. Isto é repetido até que nenhum novo grupo seja encontrado. Uma das desvan-tagens deste processo é que pode ser difícil encontrar picos e vales significativos em uma imagem. Uma opção para resolver este problema é gerar histogramas baseados em outros sistemas de cores[21].
Figura 3: No topo à esquerda é mostrada a imagem original, no topo à direita temos o histograma desta imagem. No histograma, a região em laranja é a que será utilizada na segmentação. A imagem inferior à esquerda mostra uma máscara com base na região selecionada no histograma, onde ospixels brancos representam os pixelssegmentados. A imagem inferior à direita mostra a imagem segmentada. Podemos observar que uma região de pele foi segmentada.
2.1.3
Detecção de arestas
O resultado obtido com esta técnica de segmentação é um conjunto de curvas conec-tadas ou não que indicam o limite de um objeto nesta imagem. A aplicação desta técnica pode reduzir significativamente a quantidade de dados a serem processados em etapas posteriores (já que o processamento pode ser feito apenas nas regiões encontradas) e podem filtrar regiões sem significância para o problema.
Na maioria dos casos, deve ser feita uma correção na imagem após a detecção de arestas pois, as linhas de borda obtidas geralmente estão fragmentadas, isto é, as arestas não estão totalmente conectadas. Além disso, podem ser obtidas falsas arestas que não correspondem a linhas reais na imagem original.
Os algoritmos mais conhecidos desta técnica são: Canny edge detector, Differential edge detectore Sobel. A Figura 4 apresenta um exemplo de segmentação por detecção de arestas utilizandoCanny edge detector.
Figura 4: Exemplo de detecção de arestas usandoCanny edge detector
2.1.4
Crescimento de regiões
O princípio básico da técnica de segmentação de imagens por crescimento de re-giões é de se marcar alguns pontos na imagem numa região de interesse e utilizar estes pontos como sementes fazendo com que a região ao redor da semente cresça se os pixels ao redor possuirem as mesmas propriedades da semente, gerando assim uma região ho-mogênea em uma certa propriedade. Estas sementes são escolhidas com algum critério como, por exemplo, pelo nível de cinza ou até mesmo a posição em uma imagem[18].
As vantagens desta técnica são: segmentação da imagem em regiões com proprie-dades similares e simplicidade, pois ela se baseia na comparação de pixelsapenas com seus vizinhos próximos.
Figura 5: Crescimento de regiões utilizando 10 sementes colocadas nospixelscom níveis de cinza mais próximos ao branco
2.1.5
Watershed
A transformada de watershed considera a magnitude do gradiente de uma imagem como uma superfície topográfica. Pixels tendo as maiores magnitudes de gradiente correspondem às linhas da bacia hidrográfica, que representam os limites desta bacia.
A Figura 6 apresenta um exemplo da segmentação de uma imagem de coração uti-lizando a técnica de watershed.
Figura 6: Exemplo de aplicação da técnica de watershed em uma imagem de ressonân-cia magnética de um coração
2.2
Clusterização e Modelo de Curvatura
O primeiro passo desse algoritmo consiste em remover os reflexos especulares da imagem, como pode ser visto na Figura 7 (b). Após este passo, a imagem é clusterizada em diversos grupos selecionando 30% dos pontos mais claros e 20% dos pontos mais escuros, este resultado pode ser visto na Figura 7 (c).
(a) (b)
(c) (d) (e)
Figura 7: A figura mostra um exemplo de segmentação de íris utilizando a técnica de clusterização da imagem. (a) Imagem original. (b) Imagem após a remoção de reflexos especulares. (c) Clusterização inicial. (d) Resultado da clusterização. (e) Classificação semântica. Imagens adaptadas do artigo de Tanet al.[5].
O passo seguinte consiste em classificar os pontos não clusterizados a alguma das regiões encontradas no agrupamento. Essa atribuição é feita através de um limiar da diferença entre a média das cores da região e a cor do ponto sendo verificado, divido pelo desvio padrão das cores da região. Se esse valor for menor que 2,5, então o ponto pertence à região se existe um caminho entre este ponto e esta região. O resultado da clusterização pode ser visto na Figura 7 (d).
Assim que todos os pixels da imagem estiverem associados com alguma região, es-tas regiões serão rotuladas através de suas formas e cores. De uma maneira simples, a região da pele pode ser identificada através da sua intensidade, entretanto, outras regiões (sombrancelhas, cílios, cabelo e óculos) são difíceis de serem identificadas. Este problema pode ser resolvido através da aplicação de algumas regras:
1. A região da íris geralmente possui uma forma onde a região central é mais grossa do que as pontas, como pode ser visto na Figura 7 (e).
2. A sombrancelha é uma região horizontal escura em cima da região da íris.
A clusterização e a rotulação das regiões permite identificar a região da íris mas ainda é necessário localizar o limite límbico (borda externa da íris que a separa da região da esclera) e a pupila. A localização é feita através da modelagem do limite límbico e da íris como dois círculos não concêntricos.
A localização da pálpebra é difícil de ser feita devido à oclusões causadas pelos cílios e a sua forma irregular. Baseado na observação de que os cílios estão na vertical, um filtro de ordem de uma dimensão (com tamanho 7 e ordem 2) foi utilizado para reduzir ou até mesmo eliminar os cílios das imagens. Para localizar a pálpebra um modelo de curvatura é utilizado, sendo que, este modelo foi obtido através da análise manual das imagens de treino.
O último passo consiste em remover as oclusões causadas por sombras, que são detectadas através de um modelo de predição baseado nas estatísticas de intensidade das diversas regiões da íris.
2.3
Localização de reflexos, limites da íris e limites da
pálpebra
O algoritmo descrito no artigo de Sankowskiet al.[2]consiste em cinco passos:
• Localização de reflexos.
• Preenchimento de reflexos.
• Localização dos limites da íris.
• Localização do limite da pálpebra inferior.
• Localização do limite da pálpebra superior.
Para localizar os reflexos, a imagem é convertida para uma imagem em nível de cinza no modelo de cor YIQ (luminance in-phase quadrant). Após esta conversão, um limiar é aplicado na imagem e, por último, o mapa dos reflexos, obtido com o uso do limiar, é melhorado através de transformações morfológicas como, por exemplo, dilatação e erosão.
O passo de preenchimento de reflexos consiste em interpolar o valor das cores dos
pixels vizinhos de fora da região do reflexo. Para cada pixel na região de reflexo, os quatro pixels (esquerda, direita, cima e baixo) mais próximos à ele, que estão fora da região de reflexo são obtidos. O novo valor dopixel que está sendo analisado é então calculado a partir da interpolação dos valores desses quatropixelsobtidos.
A Figura 8 mostra o processo de preenchimento de reflexos e localização dos limites da íris.
(a) (b)
Figura 8: (a) Imagem original. (b) Imagem com preenchimento de reflexos e limites da íris detectados. Imagens obtidas no artigo de Sankowskiet al.[2].
Para a localização da pálpebra inferior foi utilizado o algoritmo de detecção de arestas proposto por Wildes [23]. Primeiramente, a imagem com o preenchimento de reflexos é suavizada com o uso combinado de um fitro de média para remover os ruídos do tipo "sal e pimenta" e um filtro gaussiano.
Um filtro para detectar arestas horizontais é utilizado na imagem suavizada. À partir deste ponto, o limite da pálpebra inferior começa a ser procurado através do uso de diversos arcos com vários raios e posições.
A localização da pálpebra superior foi feita através do conceito proposto por Zuo, Ratha e Connell[24] que modela os cílios superiores como um segmento de linha.
2.4
Detecção de íris através da combinação de pupila e
íris
O artigo escrito por Almeida [25] envolve uma sucessão de fases que lidam com o pré-processamento da imagem, localização da pupila, localização da íris, combinação da pupila com a íris, detecção dos cílios e remoção de reflexos.
Na etapa de pré-processamento os reflexos são reduzidos através de um limiar da luminosidade do pixel. Após este passo, são construídas duas imagens: uma com as componentes azul e verde e outra com a componente vermelha da imagem. A ima-gem com a componente vermelha é utilizada como base para a segmentação da íris e a diferença entre a imagem com a componente vermelha e a imagem com as compo-nentes azul e verde será utilizada para detectar regiões com maior preponderância da componente vermelha (ex.: pele).
região escura que deve corresponder à pupila. O segundo método procura diversos qua-drados escuros de diversas dimensões em toda a imagem e o terceiro método utiliza um
gridde 15 pontos igualmente espaçados. Estes métodos são utilizados para posicionar sementes que tentarão encontrar um círculo escuro de um tamanho apropriado.
A localização da íris é feita de maneira similar à localização da pupila. Após localizar as possíveis íris na imagem, o algoritmo possui um conjunto de possíveis pupilas e íris. Para todas as combinações possíveis de pupila e íris uma função heurística é usada para avaliar cada uma das possíveis combinações. A melhor combinação de pupila e íris informada pela função heurística é utilizada para a segmentação.
2.5
Localização do limite límbico
No método descrito por Liet al. [26], o limite límbico é procurado através de dois algoritmos. O primeiro algoritmo retorna um valor de confiança da localização da íris e, caso esse valor de confiança seja menor que um limite pré-definido, o segundo algoritmo é utilizado para localizar o limite límbico.
O primeiro algoritmo utiliza a técnica de AdaBoost [27] para localizar um olho na imagem, sendo que, o AdaBoost é um algoritmo que constrói um classificador forte à partir da combinação de classificadores fracos. Embora, em geral, o processo de aprendizado no AdaBoost seja lento, seu uso apresenta duas vantagens: detecção rápida e classificação eficiente.
Se após esta etapa o olho não tiver sido localizado, toda a imagem será utilizada no próximo passo, caso contrário somente a região com a localização do olho será utilizada. O segundo passo consiste em clusterizar a imagem através dok-meanspara segmentar a região do olho. Após a segmentação, um detector de arestas é aplicado na imagem para obter um mapa de arestas que é utilizado na transformada de Hough para encontrar a circulos na região do olho. Todo o processo pode ser visto na Figura 9.
O segundo algoritmo proposto utiliza a informação sobre a pele para segmentar a imagem. Após a segmentação, os mesmo passos aplicados no primeiro algoritmo são seguidos.
Após a utilização desses dois algoritmos, a melhor segmentação obtida entre eles é selecionado e então as pálpebras superior e inferior são localizadas através de um modelo de parábola, conforme pode ser visto na Figura 10.
Figura 10: Localização das pápebras com modelo de parábola. Adaptado de Liet al. [26]
.
2.6
Localização da íris através da busca de círculos e
reflexos especulares
No método descrito por Jeonget al. [28] a íris é localizada através da detecção das arestas de dois círculos e, para validar se esses dois círculos contém a região da íris, deve haver pele menos um reflexo especular dentro dessa região. Geralmente, os reflexos especulares aparecem na região da íris e da pupila e o nível de cinza deles são mais claros que os pixels da região da esclera, pupila e pele, já que a superfície da córnea reflete mais luz do que outras regiões.
(a) (b) (c)
Figura 11: Localização da íris utilizando AdaBoost: (a) detecção das arestas de dois círculos, (b) localização através do AdaBoost, e (c) detecção das arestas de dois círculos na região encontrada em (b). Adaptado de Jeonget al.[28].
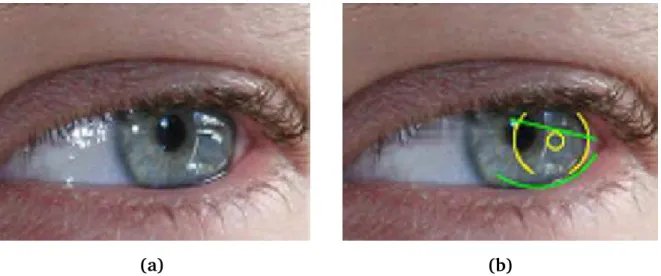
Se, após estes passos, não for encontrada uma região de reflexo especular, então o algoritmo assume que o olho da pessoa está fechado. Caso contrário, as pálpebras são localizadas através de uma transformada de Hough parabólica, como pode ser visto na Figura 12.
(a) (b)
Figura 12: Localização das pálpebras com transformada de Hough: (a) imagem original e (b) resultado da localização. Adaptado de Jeonget al.[28].
Figura 13: Exemplo de reflexo causado por janelas (demarcado em vermelho) e região utilizada para obter o padrão da íris (em branco). Adaptado de Jeonget al.[28].
O próximo passo é calcular a média das cores de cada canal RGB e, para cadapixel, calcular a distância entre a cor dopixel e a cor média obtida. Se essa distância estiver dentro de um limite, que foi calculado empiricamente através das imagens de treino, então opixelpertence a região final à ser segmentada.
2.7
Segmentação de íris através da detecção da esclera
Chen et al.[3]propuseram um novo método baseado na busca da esclera. A detecção da esclera é feita através do cálculo da saturação de cadapixelatravés do seu valor RGB, conforme a equação 2.1:
S = 1− 3
(R+G+B)[min(R, G, B)] (2.1)
Através de algumas análises foi determinado que os valores de saturação que estão entre 0 e 0,21 representam a esclera. Com base neste limite da saturação, a esclera pode ser extraída da imagem, conforme a Figura 14.
Figura 14: Exemplo de detecção de esclera com ruídos na imagem. Adaptado de Chenet al.[3].
loca-lizada, porém, é necessário remover regiões de pele clara e de reflexos na imagem da esclera. Essa remoção é feita para todos ospixelscom saturação maior que 0, utilizando a média das cores dos pixels de uma máscara de 17 x 17, centtralizada no pixelsendo analisado. A imagem resultante é então binarizada através de um limiar e dois tipos de esclera podem aparecer nessa imagem: esclera dupla, como é mostrada na Figura 15 (a), e esclera única, mostrada na Figura 15 (c). A localizaçao da íris para escleras duplas é obtida à partir dos pontos extremos (cima, baixo, direita e esquerda) das duas regiões de esclera, e pode ser visto na Figura 15 (b).
Em imagens com uma única região de esclera, não é possível saber para qual lado da esclera a íris está localizada. Um retângulo é criado com base nos limites extremos superior e inferior, enquanto o retângulo é extendido para o lado conforme a relação da distância entre a esclera e o limite lateral da imagem, isto é, quanto maior a distân-cia entre a esclera e um dos lados da imagem, mais o retângulo será estendido nessa direção, conforme podemos ver na Figura 15 (d).
(a) (b) (c) (d)
Figura 15: Localização do olho à partir da esclera. (a) Esclera dupla, (b) localização da região do olho à partir da esclera dupla, (c) esclera única e (d) localização da região do olho à partir da esclera única. Adaptado de Chenet al.[3].
A borda externa da íris é detectada usando o método de transformação circular de Hough modificado para encontrar círculos na área onde a íris deve estar localizada, obtida nos passos anteriores, e o centro deste círculo não deve estar em uma região de esclera. Além disso, ao invés de usar um detector de arestas nas quatro direções foi utilizado um detector de arestas horizontais.
Em seguida, é necessário detectar as pálpebras. Para lidar com os diversos ruídos que podem ocorrer, uma nova metodologia foi utilizada para identificar os pontos da borda localizado no limite entre a pálpebra e a íris. Primeiramente, a itensidade média dos níveis de cinza de uma região abaixo da pupila é calculada. Após este cálculo, raios são traçados à partir do centro do círculo em direção à borda e, para cadapixel
desse raio, a sua intensidade em nível de cinza é comparada com a média obtida. Se a intensidade sendo comparada estiver fora do intervalo de ±10%, então este pixel é definido como sendo a borda da íris.
3
Dicionário de Pontos
Característicos
No artigo de Csurka et al.[29]foi proposta uma nova metodologia de categorização visual chamada Dicionário de Pontos Característicos, ouBag of Keypoints. Esta nova me-todologia é baseada em uma técnica de categorização de texto chamada Bag of Words [30]
. A ideia de se adaptar técnicas de categorização de texto para a área de visão com-putacional não é nova, Zhuet al.[31] investigaram a quantização vetorial de pequenas imagens quadradas, que foram chamadas de blocos-chave. Foi mostrado que a quanti-zação vetorial produz mais resultados semânticos que os métodos baseados em análise de cores e texturas[29].
O método descrito no artigo de Csurka et al.[29]possui quatro passos fundamentais:
• Detecção e descrição de trechos da imagem
• Atribuição de descritores de trechos aos grupos pré-determinados (vocabulário) através de um algoritmo de quantização vetorial
• Construção de um conjunto deKeypoints, que sumariza o número de trechos as-sociados aos grupos, ou seja, construir um dicionário de palavras
• Classificação de múltiplas classes, considerando o dicionário como um vetor de características, determinando em quais categorias a imagem deve ser classificada
Os descritores obtidos no primeiro passo devem ser invariantes às condições que são irrelevantes para a tarefa de categorização (transformações nas imagens, como, por exemplo, a rotação e a translação) e ainda variações de iluminação e oclusões parciais, porém rico o suficiente em informações que discriminem a categoria na qual o trecho analisado pertence. O segundo passo deve conter um vocabulário do tamanho ideal para distinguir mudanças relevantes em partes das imagens e não distinguir mudanças irrelevantes que podem ocorrer como, por exemplo, ruídos.
O objetivo principal deste algoritmo é utilizar um vocabulário (ou conjunto de ca-racterísticas) que tenha um bom desempenho de categorização em um determinado conjunto de dados de treinamento. Os passos envolvidos no treinamento são:
• Construir um conjunto de vocabulários: cada um sendo o centro de um grupo, em relação aos descritores
• Extração dosbags of wordsdesses vocabulários
• Treinamento dos classificadores (por ex: SVM) usando os bags of words como vetores de entrada
Os resultados do trabalho de Csurka et al.[29] mostraram que essa nova técnica se mostrou eficaz em imagens que possuam um fundo complexo, neste caso a técnica se mostrou também robusta obtendo um alto grau de desempenho no processo de catego-rização sem explorar as informações geométricas contidas nas imagens.
No trabalho realizado por Filliat [32] a técnica Bag of Keypoints foi utilizada no de-senvolvimento de um sistema de localização e aprendizagem de mapas feitos por robôs. De acordo com o artigo, esta técnica se mostrou confiável e rápida para um robô reco-nhecer o ambiente em que ele se encontrava e ainda a técnica se mostrou estável após um longo tempo de uso.
De acordo com Zhang et al., independentemende da classe da imagem, esta técnica proporciona uma alta taxa de acerto de categorização, como podemos ver na Tabela 1:
Categorização Taxa de acerto
Bicicletas 97,6% Livros 81,7% Construções 82,0% Carros 88,6% Faces 99,4% Telefones 94,0% Árvores 97,3%
Tabela 1: Taxa de acerto de categorização com Bag of Keypoints
A seguir apresentamos uma explicacão mais detalhada sobre cada uma das etapas da técnica deBag of Keypoints.
3.1
Detecção e Representação de Pontos Característicos
Existem diversos descritores capazes de detectar e representar características de ob-jetos em imagens, entre eles podemos citar oSIFTe oSURF[34]. Basicamente o descritor
3.1.1
SIFT
O descritor denominado Scale Invariant Features Transform (SIFT) [35] é um dos descritores locais mais citados na literatura de visão computacional. Seu grande uso ocorre devido a sua propriedade de ser fortemente invariante às mudanças de escala, rotação, iluminação e ponto de vista [36]. O descritor SIFT [35] tem sido utilizado para o reconhecimento de objetos em ambientes onde podem existir oclusões parciais [37], localização de robôs e mapeamento de lugares[38], fotos panorâmicas, modelagem 3D, rastreamento, reconhecimento de gestos humanos, entre outros.
O descritorSIFT foi criado para resolver o problema de correspondência entre ima-gens, e pode ser utilizado ainda para: reconhecer objetos em imaima-gens, reconhecer ce-nas, montagem automática de mosaicos, correspondência estéreo, tracking, entre ou-tras.
OSIFT possui 4 etapas:
• Detecção de espaço de escala
• Localização de pontos característicos
• Atribuição de orientação aos pontos característicos
• Cálculo dos descritores dos pontos característicos
O processo de determinação destes pontos característicos feitos pelo método SIFT
baseia-se em sucessivos borramentos gaussianos, reduções de escala, e diferença de gaussianos.
Os descritores dos pontos característicos obtidos através do método SIFT são um conjunto de 128 valores numéricos que representam o ponto característico, sendo que estes descritores não contém informações referente a escala, rotação, iluminação e ponto de vista.
Figura 16: Exemplo dos pontos detectados peloSIFT
3.1.2
SURF
A idéia do descritor SURF (Speed-Up Robust Features)[39] é semelhante à do des-critor SIFT, porém o SURF é um descritor que consome menos tempo computacional para detectar e descrever pontos de interesse nas imagens. De acordo com seus autores o descritorSURFé mais rápido e mais robusto em relação a transformações geométricas do que o SIFT [39]. Além disso, o SURF também procura encontrar características que sejam invariantes à rotação e à escala.
A motivação que levou a criação do SURF foi encontrar uma forma de diminuir o tempo computacional para detectar e descrever pontos de interesse nas imagens, sem sacrificar significativamente a eficácia em relação aoSIFT.
Assim como oSIFT, oSURFrepresenta o descritor de um ponto característicos atravé de um conjunto de valores numéricos, sendo que, por padrão, oSURFutiliza apenas 64 valores numéricos, porém, é possível utilizar um descritor SURF estendido com 128 valores numéricos, assim como no caso doSIFT.
O SURF possui uma forma de detectar os pontos de interesse parecida com o des-critor SIFT, exceto que, ao criar a pirâmide de imagens, oSURF utiliza o detector Fast Hessiansem fazer a redução de escala. O cálculo dos descritores baseiam-se no somató-rio das respostas senoidais de Haar de duas dimensões, calculados numa subregião de 4 x 4 em torno do ponto de interesse.
descritorSURF e os pontos característicos encontrados (em verde).
Figura 17: Exemplo dos pontos detectados pelo SURF
3.2
Dicionário de Pontos Característicos
O dicionário de palavras é utilizado para aprender um modelo gerador [40] capaz de selecionar as regiões mais representativas do problema, de forma que o número de regiões selecionadas deve ser grande o suficiente para distinguir mudanças relevantes nas imagens, mas não tão grande a ponto de distinguir variações irrelevantes como ruído[41][29][36].
A criação desse dicionário de palavras geralmente se dá através do uso imagens de treinamento[42]. Além disso, dependendo da complexidade do problema, o número de palavras do dicionário varia, sendo que, a escolha das palavras é realizada através do uso de algoritmos de agrupamento como, por exemplo, o k-means. No caso do uso do método de k-means, cada centróide dos grupos encontrados são utilizados como palavras do dicionário.
3.3
K-means
particio-nando então um conjunto de amostras em um determinado número de grupos.
Para realizar o particionamento dos grupos, o algoritmo realiza os seguintes passos:
1. Seleciona K centros de massa aleatoriamente.
2. Atribuição: atribui cada amostra ao grupo com o centro mais próximo
3. Atualização: atualiza os centróides de cada grupo
4. Verifica uma condição de parada, se a condição for alcançada o processo para, senão retorna ao passo 2.
Note porém que, centróides iniciais diferentes podem fazer com que a divisão final seja diferente.
A atribuição de cada amostra à um grupo é feita através do cálculo da distância entre a amostra e o centróide do grupo. Esse cálculo pode ser feito através, por exemplo, da distância Euclidiana entre a amostra e o centróide.
O cálculo dos novos centróides dos grupos pode ser feito de diversas maneiras, sendo que a forma mais comum é calcular um ponto fictício que seja a média das amos-tras do grupo. Outra forma de se calcular um novo centróide é encontrar uma amostra no grupo que possua a menor média das distâncias para as demais amostras do grupo (a mais próxima do centróide).
Após diversas iterações algoritmo descrito acima o algoritmo converge, isto é, as amostras não mudam mais de grupos. Esta convergência pode levar muito tempo, en-tão alguns critérios de teste de convergência são estabelecidos para que o algoritmo termine mais rápido. Os critérios de convergência podem ser o número de iterações do algoritmo, ou que a quantidade de amostras que mudam de grupos sejam menor do que uma porcentagem definida.
3.4
Classificador SVM
OSVM(Support Vector Machine)[43]é uma técnica de aprendizagem para problemas de classificação entre duas classes. É um método sistemático, reproduzível, e baseado na teoria de aprendizado estatística. O algoritmo funciona mapeando um vetor de entrada definido em um espaço de muitas dimensões para duas saídas possiveis. O processo de aprendizagem consiste em aprender um hiperplano capaz de separar os vetores de entrada em dois grupos. De maneira simples podemos dizer que o SVM
separa linearmente as amostras de um problema através de um hiperplano[44].
4
NICE.I
A segmentação de íris é uma etapa importante no processo de reconhecimento de íris. O problema da segmentação é que as imagens podem apresentar diversos tipos de ruídos, tais como oclusões, ruídos de captura, ângulos de visão, etc. Devido à impor-tância deste problema, a Universidade da Beira Interior, em Portugal, criou no período de Julho de 2007 à Dezembro de 2008 uma disputa mundial de segmentação de íris chamada NICE.I (Noisy Iris Challenge Evaluation)[1]. A idéia desta disputa era avaliar o desempenho de diversos algoritmos de segmentação de íris enviados pelos partici-pantes. Boa parte das imagens das íris foram obtidas comclose-up e em um ambiente cooperativo e sem restrição de movimentação e a iluminação utilizada no ambiente era adequada para o tipo de tarefa sendo executada. Além disso, as íris das imagens pode-riam estar obstruídas por qualquer tipo de ruído (ex: obstrução causada pelos cabelos, cílios, óculos, etc).
A UBIRIS.v1, base de dados criada para o evento, foi contruída com 1877 imagens coletadas de 241 pessoas diferentes em duas sessões de fotos. Na primeira sessão, os ruídos foram minimizados, principalmente os ruídos causados por reflexão especular, luminosidade e contraste, utilizando uma sala escura para obter as imagens.
Na segunda sessão, a sala foi substituída por outra onde havia iluminação natural. Esta troca de sala causou um aumento no ruído das imagens, fazendo com que os ruí-dos como reflexão especular, contraste, luminosidade e problemas de foco fossem mais comuns nas imagens obtidas nesta sessão. As imagens da segunda sessão simularam as imagens capturadas por sistemas reais de reconhecimento com ou sem participação dos indivíduos no processo de aquisição da imagem.
Figura 18: Exemplos de oclusões e ruídos, onde podem ser vistas oclusões causadas por cílios, pálpebras, óculos e cabelos, reflexos especulares e imagem capturada com ângulo de visão oblíquo.
No NICE.I todos os algoritmos foram avaliados com relação à taxa de erro na classi-ficação. Este erro é determinado conforme mostrado nas equações abaixo:
SejaI ={I1, I2, ..., In}as imagens das íris.
SejaO ={O1, O2, ..., On}as imagens geradas pela saída do algoritmo.
SejaC ={C1, C2, ..., Cn}as imagens binárias das íris (isto é, uma imagem em preto
e branco, no qual ospixelspretos marcam ospixelsque representam a íris na imagem), classificadas manualmente pela equipe do NICE.I. Devemos assumir que as imagens do conjunto C são as imagens que contém a segmentação perfeita de cada imagem do conjuntoI.
Figura 19: Exemplo da segmentação desejada
A taxa de erro da classificação do algoritmo para a imagemIié dada pela proporção
dos pixels classificados incorretamente sobre a quantidade depixels da imagem, como pode ser visto na equação 4.1.
Ei =
F P +F N
largura×altura (4.1)
Onde F P eF N são respectivamente ospixels considerados como falsos positivos e falsos negativos da saída do algoritmo.
A taxa de erro da classificação E1 do algoritmo é a média dos errosEi das imagens
de entrada como pode ser visto na equação 4.2.
E1 = 1
n
X
i
Ei (4.2)
O valor E1 está limitado no intervalo entre 0 e 1 e representa a porcentagem mé-dia de erro de classificação, onde 0 e 1 representam respectivamente o melhor e o pior resultado possível. Esta medida de erro foi utilizado no NICE.I para classificar o desem-penho dos algoritmos enviados à disputa.
Uma segunda medida de erro foi utilizada para compensar a desproporção entre os
pixelsque representam a íris e os pixels que não representam íris nas imagens. A taxa de erroEi′ de uma imagem é dada através da média das taxas entre os falsos positivos
(FPR) e os falsos negativos (FNR) e é calculada pela equação 4.3.
Ei′ =
F P R+F N R
2 (4.3)
E2 = 1
n
X
i
Ei′ (4.4)
As oito melhores taxas de erroE1 obtidas no NICE.I podem ser vistas na Tabela 2:
Ranking Artigo Taxa de erro E1
1 Efficient and robust segmentation of noisy iris images
for non-cooperative iris recognition[5] 0,0131 2 Reliable algorithm for iris segmentation in eye image[2] 0,0162
3 A knowledge-based approach to the iris segmentation
problem[25] 0,0180
4 Robust and accurate iris segmentation in very noisy iris
images[26] 0,0224
5 A new iris segmentation method for non-ideal iris
ima-ges[28] 0,0282
6 A highly accurate and computationally efficient
appro-ach for unconstrained iris segmentation[3] 0,0297
7 Noisy iris segmentation with boundary regularization
and reflections removal[4] 0,0301
8 Robust iris segmentation on uncalibrated noisy images
using mathematical morphology[6] 0,0305
5
Metodologia Científica
Neste capítulo iremos descrever os dados e o processo de desenvolvimento utilizado neste trabalho.
5.1
Base de Dados
Este trabalho utilizou como base de dados as imagens disponibilizadas aos partici-pantes do NICE.I. Estas imagens são um conjunto de imagens de treinamento obtido à partir da base de dados UBIRIS.v2.
Foram disponibilizadas 500 no formato TIFF, com dimensão de 400 x 300 pixels. Além disso, para cada uma destas 500 imagens existe uma imagem no formato BMP, também de 400 x 300, que contém a localização e a segmentação manual da íris, para ser considerada com padrão de segmentação. Nestas imagens padrãopixels pretos re-presentam as regiões da íris epixelsbrancos representam pontos que não são íris. Exem-plos destas imagens da base e da segmentação manual são apresentados na Figura 20.
Figura 20: Exemplo de imagem da base de dados. À esquerda a imagem de um olho com a íris e à direita a segmentação manual correspondente.
5.2
Detecção e Representação de Pontos Característicos
Numa primeira etapa foram selecionadas 100 imagens da base descrita acima para a extração de pontos característicos. Esses pontos característicos serão utilizados nas seguintes etapas:
• Criação do dicionário de palavras
• Categorização das regiões das imagens
• Segmentação da imagem comRegion Growing
Os pontos característicos foram obtidos através do uso dos algoritmosSIFT eSURF. A implementação doSIFT utilizada foi a de Stephan Saalfeld1, enquanto a
implemen-tação doSURF utilizada foi a que vem disponível na biblioteca OpenCV[47].
Esses pontos característicos foram calculados para cada imagem e salvos em arqui-vos de texto para diminuir o tempo computacional nas etapas de treinamento e de teste. A única informação salva foi o descritor de cada ponto, tanto para oSIFT, quanto para oSURF. Além disso, oSURF foi configurado para retornar o descritor estendido, isto é, o descritor contendo 128 valores numéricos, já que o normal são 64 valores.
Foram feitas diversas configurações nos parâmetros dos algoritmos para que eles retornassem um número adequado de pontos característicos para cada imagem, como será visto mais à frente. Segue abaixo a configuração usada no descritorSURF:
• extended: 1
• hessian threshold: 1
• quantidade de oitavas: 3
• quantidade de camadas: 4
Abaixo, a configuração usada no descritor SIFT:
• quantidade de oitavas: 8
• intervalo: 1
5.3
Dicionário de Pontos Característicos
Após o processo de extração de pontos característicos das imagens, o próximo passo é criar um dicionário de palavras visuais baseado nestes pontos característicos.
Como não se pode utilizar todos os pontos característicos das imagens de treino como palavras do dicionário é necessário selecionar alguns pontos característicos para representar todos esses pontos. A seleção dos pontos característicos para criar palavras do dicionário foi feita utilizandoo algoritmok-means disponível na biblioteca OpenCV
[47]
.
Neste trabalho, os dicionários gerados sempre tinham um número de palavras que representavam pontos de íris iguais ao número de palavras que representavam pontos de não íris. Esta divisão em grupos de mesma cardinalidade foi feita para garantir que não houvesse um bias em termos de número de palavras no dicionário. Para garantir esse número igual, os pontos característicos foram divididos em dois grupos: pontos ca-racterísticos de íris e de não íris e, para cada grupo, utilizamos o algoritmok-meanspara selecionar as palavras de cada grupo.
Como critério de convergência do algoritmo k-means utilizamos 10.000 iterações. Os centróides retornados após a parada são pontos inexistentes no conjunto de pontos característicos das imagens de treino, já que estes pontos são obtidos através da média dos pontos característicos do grupo, e que não é necessariamente um ponto caracterís-tico mas representa um centro de massa de pontos caracteríscaracterís-ticos.
Para evitar este problema, em cada grupo encontrado pelo algoritmo de k-means, foi selecionado o ponto característico mais próximo do centróide e os centróides foram então descartados. A seleção do melhor ponto representante de um grupo é feita através da média da distância deste ponto para todos os outros pontos do grupo. A distância entre dois pontosSIFTeSURFpode ser calculada através da distância euclidiana de seus descritores. O ponto com a menor média de distância do grupo é o ponto escolhido como representante do grupo, garantindo assim que o ponto representante seja um pontoSIFT ouSURF existente em uma das imagens de treinamento.
5.4
Treinamento e Classificação
O método proposto consiste em classificar regiões da imagem como sendo regiões de íris ou regiões sem íris. Para fazer essa classificação é necessário treinar um classifi-cador com os dados das regiões. Este trabalho utilizou o classificlassifi-cador SVM da biblioteca OpenCV[47].
Para classificar regiões da imagem é preciso primeiro dividir a imagem em regiões. Esta divisão foi feita de maneira simples, através da divisão da imagem emgrids de 20 x 15. Se a região não possuir qualquer ponto característico, então a região é automa-ticamente classificada como uma região sem íris. Caso a região possua algum ponto característico ela é utilizada no treino do classificador.
Para treinar o classificador é necessário converter cada região em um histograma. A conversão da região em um histograma é feita utilizando o algoritmo descrito abaixo.
• Criar o histograma como um vetor numérico, sendo que o tamanho deste vetor é o número de palavras do dicionário
• Para cada ponto característicop1da região
– Inicializardcom um valor muito alto
– Para cada pontop2do dicionário
∗ Atribuir ad2a distância entre os pontosp1ep2
∗ Sed2for menor qued, atribuir àdo valor ded2e atribuir àio índice do pontop2 no dicionário
– Incrementar em1a posiçãoido histograma
A distância euclidiana foi utilizada para calcular a distância entre os pontosp1ep2. Esses histogramas são utilizados como vetores de entrada do classificador SVM sendo que, se a região possuir um pixel de íris ela é considerada como uma região de íris, senão é considerada como uma região sem íris.
Diversos testes na configuração do classificador foram realizados, sendo que os va-lores utilizados no sistema final foram:
• tipo do SVM: C-SVM
• tipo dokernel: RBF
• γ: 1 / 128
• custo: 1
O processo de treinamento pode ser visto na Figura 21, onde o primeiro passo é a utilização do SURF para obter os pontos característicos das imagens de treino e a clusterizaçao desses pontos para obter o vocabulário. O passo seguinte consiste em gerar o histograma de cada região com base no vocabulário para gerar oBag of Keypoints
Figura 21: Processo de treino.
Na etapa de testes, as imagem são divididas emgrids do mesmo tamanho daqueles utilizados na etapa de treinamento e, para cadagridcalculamos o histograma e classifi-camos o grid através do SVM. Se a região for classificada como sendo uma região que contém íris, então um ponto característico dessa região deve ser selecionado para servir como entrada na técnica de Region Growing. A seleção desse ponto é feita através do seguinte algoritmo:
• Inicializardcom um valor muito alto
• Para cada ponto característicop1da região
– Para cada pontop2do dicionário que sejam pontos característicos de íris
∗ Atribuir àd2a distância entre os pontosp1ep2
∗ Sed2 for menor que d, atribuir àd o valor ded2 e atribuir à Po ponto característico p1
• Retornar o ponto característicoP
5.5
Segmentação
Ao chegar nessa etapa teremos um conjunto de pontos característicos que perten-cem à íris de uma pessoa. Para realizar a segmentação estes pontos foram utilizados como sementes para a técnicaRegion Growing. Para este experimento foi utlizado o al-goritmo deRegion Growing implementado na biblioteca OpenCV[47] através da função
• lo_diff: diferença máxima de cor (para baixo) entre o pixel sendo observado e um dos vizinhos segmentados: 3
• up_diff: diferença máxima de cor (para cima) entre o pixel sendo observado e um dos vizinhos segmentados: 1
Antes porém de se fazer a segmentação a imagem é suavizada através da função
cvSmooth, utilizando as configurações padrões, ou seja, tipo de suavização gaussiana de tamanho 5. Após este pré-processamento, cada ponto característico é utilizado como semente independente para a funçãocvFloodFillobtendo-se um número de regiões igual ao número de pontos característicos determinados. Cada uma das regiões segmentadas são unidas para formar uma segmentação única.
Após este passo é calculado o desvio padrão das cores da região segmentada e, os pixels com valores de cores fora de dois desvios padrões dos valores segmentados (representando as cores mais próximas ao preto e ao banco) foram descartados. Este descarte foi feito porque esses pontos têm grandes chances de representar a pupila, cílios e / ou reflexos.
O processo de localização da íris e segmentação pode ser visto na Figura 22:
6
Resultados
6.1
Pontos característicos
SIFT
ou
SURF
?
O primeiro experimento executado teve como objetivo verificar qual o tipo de des-critor seria mais eficiente para o processo de se criar um dicionário de palavras visuais. Os resultados em termos de classificação obtidos com os descritoresSIFT eSURF, utili-zando 1000 palavras no vocabulário podem ser vistos na Tabela 3. A porcentagem de regiões de imagens classificadas de forma incorreta considera apenas os falsos positivos, pois, como os pontos característicos dessas regiões serão utilizados como sementes no processo deRegion Growing, o uso destes pontos causaria uma variação significativa no resultado final da segmentação.
Taxa de erro
Técnica Regiões classificadas de forma incorreta (%)
Imagens com íris classificadas
como sem íris (%)
SIFT 33,40% 0,60%
SURF 24,91% 0,00%
Tabela 3: Tabela com as taxas de erro obtidas pelos dois algoritmos de pontos caracte-rísticos para 1000 palavras visuais
Devido ao melhor resultado apresentado pelo descritor SURF (conforme indicado na Tabela 3), este foi selecionado para os demais experimentos.
6.2
Número de pontos descritores em cada imagem
Quantidade de
pontos
característicos
Regiões de imagens Imagens com
íris
classificadas
como sem íris
FP FN VP VN
Aprox. 1000 975 15301 3032 139653 1 Aprox. 5000 1407 14139 4244 139171 0
Tabela 4: Tabela com as taxas de erro para as variações na configuração do SURF FP: Falsos Positivos, FN: Falsos Negativos, VP: Verdadeiros Positivos, VN: Verdadeiros Negativos
Note que embora exista uma melhora no número de regiões classificadas correta-mente como íris (VP), as diferenças obtidas tanto no falso negativo como no verdadeiro negativo são praticamente iguais, mas, o número de falsos positivos aumentou mais que 50%, influenciando diretamente o valor da taxa de erroE1. Este resultado era, de certa forma, esperado, visto que um conjunto maior de pontos deve incluir pontos ca-racterísticos de "pior" qualidade no conjunto e, como os 1000 pontos utilizados já eram suficientes para classificar, praticamente, todas as imagens, a inclusão de um número maior de pontos não poderia melhorar o desempenho em termos de verdadeiros posi-tivos, mas, devido a qualidade destes pontos, era de se esperar um aumento dos falsos positivos, como constatado. Foram então utilizados 1000 pontos na geração de pontos característicos feitos peloSURF.
6.3
Número de palavras no vocabulário
Quantidade de
palavras do
vocabulário
Quadrantes Imagens com
íris
classificadas
como sem íris
FP FN VP VN
20 1169 15710 2589 139352 3
100 1199 13922 4377 139322 2
200 297 16338 1961 140224 21
2000 0 18299 0 140521 389
Tabela 5: Tabela com as taxas de erro e acertos obtidas devido a variações no tamanho do vocabulário - FP: Falsos Positivos, FN: Falsos Negativos, VP: Verdadeiros Positivos, VN: Verdadeiros Negativos.
A Tabela 6 mostra as taxas de acertos em porcentagem do nosso método para qua-drantes de 20pixelspor 15pixels:
Categorização Taxa de acerto
Nosso método - Brandão e Marengoni[48] 63,1%
Nosso método - 20 palavras 89,4%
Nosso método - 100 palavras 90,5%
Nosso método - 200 palavras 89,5%
Nosso método - 2000 palavras 88,5%
Tabela 6: Tabela dos resultados obtidos com a categorização de quadrantes
A diferença do método atual para o método apresentado no WVC 2011 foi o número de imagens utilizadas nos treinos e testes. O método atual está utilizando 100 imagens no processo de treinamento e 400 imagens no processo de testes, enquanto o método apresentado no WVC 2011 estava utilizando 400 imagens no processo de treinamento e 100 imagens no processo de testes.
6.4
Region Growing
Quantidade de
palavras do
vocabulário
Pixels
FP FN VP VN
20 1836869 1742076 1777875 40963881 100 2169244 1760999 1762045 40748413 200 1415562 1729052 1683500 39332587
Tabela 7: Tabela com as taxas de erro e acertos obtidas na segmentação usando Re-gion Growing- FP: Falsos Positivos, FN: Falsos Negativos, VP: Verdadeiros Positivos, VN: Verdadeiros Negativos
A taxa de erroE1obtida com esta técnica, comparada com as taxas de erros obtidas noNICE.I podem ser vistas na Tabela 8:
Ranking NICE.I Algoritmo Taxa de erro E1
1 Efficient and robust segmentation of noisy iris
images for non-cooperative iris recognition[5] 0,0131
8 Robust iris segmentation on uncalibrated noisy
images using mathematical morphology[6] 0,0305
- Bag Of Keypoints - 200 palavras no
vocabulá-rio 0,0712
- Bag Of Keypoints - 20 palavras no vocabulário 0,0785
- Bag Of Keypoints - 100 palavras no
vocabulá-rio 0,0846
Tabela 8: Tabela com as taxas de erro obtidas neste trabalho e noNICE.I
Figura 23: Melhores segmentações obtidas pelo algoritmo
Verde: segmentação correta; Vermelho: excesso de segmentação; Azul: falta de seg-mentação
Figura 24: Piores segmentações obtidas pelo algoritmo
6.5
Um processo mais simples
Para atestar a eficácia do método proposto foi feita uma simplificação do sistema para verificar se o uso do vocabulário de palavras visuais era necessário. Neste experi-mento foram utilizados apenas os pontos característicos computados pelo métodoSURF
e aplicados diretamente ao classificador SVM. Neste experimento foramutilizadas 20 imagens para treinamento e 400 imagens para testes. O processo de treino foi similar ao feito com o uso da técnica deBag of Keypoints, os pontos característicos das imagens de treino foram obtidos sendo que, alguns pontos que não pertenciam à íris foram des-cartados para que o número de pontos de íris e pontos de fora da íris fossem os mesmos. Esses descritores então foram utilizados como treino do classificadorSVM.
A classificação foi feita através dos descritores dos pontos SURF das imagens de testes, sendo que, oSURF retornou aproximadamente 1000 pontos característicos por imagem. O classificador SVM recebia como entrada o destritor do ponto SURF e dava como saída se este pontoSURF pertencia ou não à região da íris.
O classificador SVM foi treinado com validação cruzada utilizando 5 folds, através da funçãotrain_autodaOpenCV 1.
O resultado deste teste pode ser visto na Tabela 9.
Quantidade de
pontos no
treino
Classificação de Pontos SURF
FP FN VP VN Acerto
2725 302234 24523 21733 229003 43,42% 5300 167028 20665 25591 364209 67,50% 11000 172342 12868 33388 358895 67,93%
Tabela 9: Tabela com as taxas de erro e acertos obtidas na utilização do descritorSURF
como entrada do classificador SVM FP: Falsos Positivos, FN: Falsos Negativos, VP: Ver-dadeiros Positivos, VN: VerVer-dadeiros Negativos
A Figura 25 apresenta os seis melhores resultados de segmentações obtidas pelo algoritmo proposto, enquanto a Figura 26 apresenta as seis piores segmentações obtidas pelo algoritmo.
Figura 25: Melhores segmentações obtidas pelo algoritmo mais simples
Verde: segmentação correta; Vermelho: excesso de segmentação; Azul: falta de seg-mentação
Figura 26: Piores segmentações obtidas pelo algoritmo mais simples
7
Conclusões e Trabalhos Futuros
A técnica de Bag of Keypoints se mostra eficiente para classificar diferentes tipos de imagens. Neste trabalho a utilização desta técnica para encontrar a íris em regiões das imagens se mostra promissora. No melhor caso, esta técnica apresentou apenas 0,7549% de falsos positivos, que influenciam diretamente no resultado da segmenta-ção, já que os falsos positivos não representam um ponto na íris. Os falsos negativos (8,7659%) não influenciam no resultado da segmentação, já que os pontos desses qua-drantes não são utilizados como sementes na segmentação da íris.
A simples implementação doRegion Growingcom a alteração para limitar os valores ao intervalo de até dois desvios padrões se mostrou muito eficaz na segmentação final das imagens. Como podemos ver, o nosso resultado, que foi de 0,0712, está próximo aos resultados dos algoritmos enviados aoNICE.I, onde o melhor valor obtido foi 0,0131 e o oitavo foi 0,0305.
Ao longo dos experimentos, foi observado que não adianta aumentar muito o nú-mero dos pontos característicos que oSURFretorna para cada imagem e, o aumento do número de palavras do vocabulário não traz um aumento significativo nos resultados finais, causando até mesmo uma piora desses resultados. Esse aumento de pontos e palavras não trouxe nenhuma melhora nos resultados, apenas um aumento expressivo no tempo de treinamento do algoritmo.
Além disso, vimos que o algoritmo mais simples, no qual foi utilizado os descritores dos pontosSURF para treinar o classificadorSVM ao invés de utilizar o histograma, se mostrou menos eficaz do que o algoritmo proposto neste trabalho. Podemos ver que nas melhores segmentações obtidas com o algoritmo mais simples, uma grande quantidade de pele foi segmentada, mostrando que a classificação através dos descritoresSURF não é eficaz para o problema de classificação de íris.
Um dos trabalhos futuros possíveis é um estudo sobre a escolha das palavras do vocabulário para melhorar a escolha dessas palavras, diminuir o tempo computacional e, melhorar os resultados finais.
Além disso, outra trabalhos futuros é a mudança na técnica de segmentação da íris. Será que alguma técnica utilizada noNICE.Ipode ser alterada para substituir a técnica deRegion Growing, trazendo melhoras significativas no resultado final do algoritmo?
Referências
1 NICE.I - Noisy Iris Challenge Evaluation, Part I. Disponível em:
<http://nice1.di.ubi.pt/>. Acesso em: 04 jun. 2010.
2 SANKOWSKI, W.; GRABOWSKI, K.; NAPIERALSKA, M.; ZUBERT, M.; NAPIERALSKI, A. Reliable algorithm for iris segmentation in eye image.Image and Vision Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 231–237, 2010. ISSN 0262-8856.
3 CHEN, Y.; ADJOUADI, M.; HAN, C.; WANG, J.; BARRETO, A.; RISHE, N.; ANDRIAN, J. A highly accurate and computationally efficient approach for unconstrained iris segmentation.Image and Vision Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 261–269, 2010. ISSN 0262-8856.
4 LABATI, R. D.; SCOTTI, F. Noisy iris segmentation with boundary regularization and reflections removal.Image and Vision Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 270–277, 2010. ISSN 0262-8856.
5 TAN, T.; HE, Z.; SUN, Z. Efficient and robust segmentation of noisy iris images for non-cooperative iris recognition.Image and Vision Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 223–230, 2010. ISSN 0262-8856.
6 LUENGO-OROZ, M. A.; FAURE, E.; ANGULO, J. Robust iris segmentation on uncalibrated noisy images using mathematical morphology. Image and Vision
Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 278–284, 2010. ISSN 0262-8856.
7 CLARK, M. C.; HALL, L. O.; GOLDGOF, D. B.; VELTHUIZEN, R.; REED, F.; SILBIGER, M. S. Automatic tumor segmentation using knowledge-based techniques. IEEE
Transactions on Medical Imaging, v. 17, p. 187–201, 1998.
8 LIM, S.; JEONG, Y.; HO, Y. Automatic liver segmentation for volume me-asurement in CT Images. Journal of Visual Communication and Image Repre-sentation, v. 17, n. 4, p. 860–875, ago. 2006. ISSN 10473203. Disponível em:
<http://dx.doi.org/10.1016/j.jvcir.2005.07.001>.
9 MASULLI, F.; SCHENONE, A. A fuzzy clustering based segmentation system as support to diagnosis in medical imaging.Artificial Intelligence in Medicine, v. 16, n. 2, p. 129–147, 1999.
11 SENTHILNATH, J.; RAJESHWARI, M.; OMKAR, S. Automatic road extraction using high resolution satellite image based on texture progressive analysis and normalized cut method. Journal of the Indian Society of Remote Sensing, Springer India, v. 37, p. 351–361, 2009. ISSN 0255-660X. 10.1007/s12524-009-0043-5.
12 AMOR, B. B.; ARDABILIAN, M.; CHEN, L. Enhancing 3d face recognition by mimics segmentation.Intelligent Systems Design and Applications, International Conference on, IEEE Computer Society, Los Alamitos, CA, USA, v. 3, p. 150–155, 2006.
13 BERNARD, S.; BOUJEMAA, N.; VITALE, D.; BRICOT, C.Fingerprint Segmentation using the Phase of Multiscale Gabor Wavelets. 2002.
14 ANNAPOORANI, G.; KRISHNAMOORTHI, R.; JEYA, P. G. Accurate and Fast Iris Segmentation. 2010.
15 BENSAID, A. M.; HALL, L. O.; BEZDEK, J. C.; CLARKE, L. P. Partially supervised clustering for image segmentation.PR, v. 29, n. 5, p. 859–871, May 1996.
16 TOBIAS, O. J.; SEARA, R. Image segmentation by histogram thresholding using fuzzy sets.IEEE Transactions on Image Processing, v. 11, n. 12, p. 1457–1465, 2002. 17 SALMAN, N. Image segmentation based on watershed and edge detection techniques.Int. Arab J. Inf. Technol., v. 3, n. 2, p. 104–110, 2006.
18 MANCAS, M.; GOSSELIN, B.; MACQ, B. Segmentation using a region-growing thresholding. In: Proceedings of the SPIE 5672 (2005) 388–398. [S.l.: s.n.]. p. 12–13. 19 YU, S. X.; GROSS, R.; SHI, J. Concurrent object recognition and segmentation by graph partitioning. In: in NIPS. [S.l.]: MIT Press, 2002. p. 1383–1390.
20 STEGER, C.; ULRICH, M.; WIEDEMANN, C. Machine vision algorithms and applications. [S.l.]: Wiley-vch, 2008.
21 OHLANDER, R.; PRICE, K.; REDDY, D. Picture segmentation using a recursive region splitting method. v. 8, p. 313–333, 1978.
22 DAUGMAN, J. New methods in iris recognition.IEEE Transactions on Systems, Man, and Cybernetics, Part B, v. 37, n. 5, p. 1167–1175, 2007.
23 WILDES, R. Iris recognition: an emerging biometric technology. In:IEEE 85. [S.l.]: IEEE Computer Society, 1997. p. 1948–1963.
24 ZUO, J.; RATHA, N. K.; CONNELL, J. H. A new approach for iris segmentation. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. [S.l.]: IEEE Computer Society, 2008. p. 1–6.
25 ALMEIDA, P. d. A knowledge-based approach to the iris segmentation problem.
Image and Vision Computing, Butterworth-Heinemann, Newton, MA, USA, v. 28, n. 2, p. 238–245, 2010. ISSN 0262-8856.
![Figura 2: Exemplo de segmentações com baixas taxas de erro no NICE.I [1]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18110178.323214/15.892.143.795.620.958/figura-exemplo-segmentações-com-baixas-taxas-erro-nice.webp)








