Universidade Federal do Rio Grande do Norte
Centro de Ciˆencias Exatas e da Terra
Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica
La´ıs Helen Loose
Avalia¸c˜
ao e corre¸c˜
oes de testes de hip´
oteses em
modelos de sobrevivˆ
encia com fra¸c˜
ao de cura
La´ıs Helen Loose
Avalia¸c˜
ao e corre¸c˜
oes de testes de hip´
oteses em
modelos de sobrevivˆ
encia com fra¸c˜
ao de cura
Trabalho apresentado ao Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Orientadora:
Prof
a. Dr
a. Dione Maria Valen¸ca
Coorientador:
Prof. Dr. F´abio Mariano Bayer
La´ıs Helen Loose
Avalia¸c˜
ao e corre¸c˜
oes de testes de hip´
oteses em
modelos de sobrevivˆ
encia com fra¸c˜
ao de cura
Trabalho apresentado ao Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Aprovado em: / /
Banca Examinadora:
Profa. Dra. Dione Maria Valen¸ca Departamento de Estat´ıstica - UFRN
Orientadora
Prof. Dr. F´abio Mariano Bayer Departamento de Estat´ıstica - UFSM
Coorientador
Prof. Dr. Marcelo Bourguignon Pereira Departamento de Estat´ıstica - UFRN
Examinador Interno
Prof. Dr. Francisco Cribari Neto Departamento de Estat´ıstica - UFPE
Loose, Laís Helen.
Avaliação e correções de testes de hipóteses em modelos de sobrevivência com fração de cura / Laís Helen Loose. - Natal, 2016.
vi, 72f: il.
Orientadora: Profa. Dra. Dione Maria Valença. Coorientador: Prof. Dr. Fábio Mariano Bayer.
Dissertação (Mestrado) - Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Programa de Pós-Graduação em Matemática Aplicada e Estatística.
1. Análise de sobrevivência. 2. Fração de cura. 3. Melhoramentos inferenciais. 4. Bootstrap. 5. Correção em testes de hipóteses. I. Valença, Dione Maria. II. Bayer, Fábio Mariano. III. Título.
Catalogação da Publicação na Fonte
Dedicat´
oria
Ao meus pais, Sidio e Haidi, com muito amor.
Agradecimentos
`
A minha orientadora, Dione Maria Valen¸ca, pela disponibilidade, paciˆencia, com-prometimento, dedica¸c˜ao e clareza na orienta¸c˜ao. Obrigada por todos os ensinamentos e por acreditar que seria poss´ıvel realizar esse trabalho.
Ao meu coorientador, F´abio Mariano Bayer, pelas valiosas sugest˜oes, pela disponi-bilidade, comprometimento e por ser o exemplo de professor, pesquisador e pessoa que ´es. Obrigada pelo incentivo, pelos conselhos, por me acompanhar desde a gradua¸c˜ao e ter contribu´ıdo significativamente na minha forma¸c˜ao acadˆemica e pessoal.
A minha fam´ılia e amigos, por entenderem minha ausˆencia e mesmo longe estarem sempre torcendo por mim. Em especial aos meus pais, pelos ensinamentos e exemplos de honestidade, perseveran¸ca e for¸ca. Obrigada por respeitarem minhas decis˜oes, pelo apoio incondicional, por vibrarem a cada conquista e pelo amor sem fim. Aos meus irm˜aos Lu´ıs e L´eo, por suprirem minha ausˆencia e por todo apoio.
Ao meu namorado Moiz´es e sua fam´ılia, por todos os momentos em fam´ılia que me proporcionaram mesmo longe do RS. Em especial ao Moiz´es, al´em de meu namorado, tornou-se meu amigo, meu companheiro de estudo, com quem compartilhei muitas horas de estudos durante a realiza¸c˜ao desse trabalho. Obrigada por toda paciˆencia, amor e carinho.
Aos meus amigos Jhonnata e Felipe, pela acolhida em Natal, por todas as horas de estudos e pelos momentos de descontra¸c˜ao. Obrigada pela amizade e carinho de vocˆes. Aos colegas do PPGMAE, pelos estudos, pelas discuss˜oes acadˆemicas, pelas brin-cadeiras e risadas.
Aos professores do PPGMAE, pelos ensinamentos, apoio e aten¸c˜ao. Aos participantes da banca examinadora pelas sugest˜oes.
`
A CAPES pelo apoio financeiro.
Resumo
Os modelos de sobrevivˆencia tratam do estudo do tempo at´e a ocorrˆencia de um evento de interesse. Em algumas situa¸c˜oes, uma propor¸c˜ao da popula¸c˜ao pode n˜ao estar mais sujeita `a ocorrˆencia do evento. Nesse contexto, surgiram os modelos com fra¸c˜ao de cura. Dentre os modelos que incorporam uma fra¸c˜ao de curados um dos mais conhecidos ´e o modelo de tempo de promo¸c˜ao. No presente trabalho abordamos infe-rˆencias em termos de testes de hip´oteses no modelo de tempo de promo¸c˜ao assumindo a distribui¸c˜ao Weibull para os tempos de falha dos indiv´ıduos suscet´ıveis. Os testes de hip´oteses nesse modelo podem ser realizados com base nas estat´ısticas da raz˜ao de verossimilhan¸cas, gradiente, escore ou Wald. Os valores cr´ıticos dos testes s˜ao obtidos atrav´es de aproxima¸c˜oes v´alidas em grandes amostras, que podem conduzir a distor¸c˜oes no tamanho do teste em amostras de tamanho finito. Nesse sentido, o presente trabalho prop˜oe corre¸c˜oes via bootstrap para os testes mencionados e Bartlett bootstrap para a estat´ıstica da raz˜ao de verossimilhan¸cas no modelo tempo de promo¸c˜ao Weibull. Por meio de simula¸c˜oes de Monte Carlo comparamos o desempenho em amostras finitas das corre¸c˜oes propostas com os testes usuais. Os resultados num´ericos obtidos evidenciam o bom desempenho das corre¸c˜oes propostas. Ao final do trabalho ´e apresentada uma aplica¸c˜ao a dados reais.
Palavras-chave: an´alise de sobrevivˆencia, fra¸c˜ao de cura, melhoramentos inferen-ciais,bootstrap, corre¸c˜ao em testes de hip´oteses.
Abstract
Survival models deals with the modelling of time to event data. In certain situa-tions, a share of the population can no longer be subjected to the event occurrence. In this context, the cure fraction models emerged. Among the models that incorpo-rate a fraction of cured one of the most known is the promotion time model. In the present study we discuss hypothesis testing in the promotion time model with Weibull distribution for the failure times of susceptible individuals. Hypothesis testing in this model may be performed based on likelihood ratio, gradient, score or Wald statistics. The critical values are obtained from asymptotic approximations, which may result in size distortions in finite sample sizes. This study proposes bootstrap corrections to the aforementioned tests and Bartlett bootstrap to the likelihood ratio statistic in Weibull promotion time model. Using Monte Carlo simulations we compared the finite sample performances of the proposed corrections in contrast with the usual tests. The nume-rical evidence favors the proposed corrected tests. At the end of the work an empinume-rical application is presented.
Keywords: Survival analysis, cure fraction, inferential improvement, bootstrap, improvement in hypothesis testing
Sum´
ario
1 Introdu¸c˜ao 1
1.1 Objetivos . . . 3
1.2 Descri¸c˜ao dos cap´ıtulos . . . 3
2 Modelos de sobrevivˆencia com fra¸c˜ao de cura e modelo de tempo de promo¸c˜ao Weibull 4 2.1 Introdu¸c˜ao `a an´alise de sobrevivˆencia . . . 4
2.1.1 Fun¸c˜ao de sobrevivˆencia e fun¸c˜ao risco . . . 5
2.1.2 Censura . . . 6
2.1.3 Modelos param´etricos . . . 6
2.2 Modelos com fra¸c˜ao de cura . . . 7
2.2.1 Formula¸c˜ao do modelo . . . 8
2.2.2 Verossimilhan¸ca para o modelo de tempo de promo¸c˜ao . . . 10
2.3 Modelo de tempo de promo¸c˜ao Weibull . . . 11
3 Testes de hip´oteses e melhoramentos inferenciais em pequenas amos-tras 14 3.1 Estat´ısticas de teste . . . 14
3.2 Melhoramentos inferenciais em testes de hip´oteses . . . 16
3.2.1 Corre¸c˜ao bootstrap usual . . . 17
3.2.2 Corre¸c˜ao de Bartlett bootstrap para a estat´ıstica LR . . . 18
3.2.3 Bootstrap para dados com censura . . . 19
3.3 Testes de hip´oteses em modelos de sobrevivˆencia . . . 21
4 Resultados num´ericos 22
5 Aplica¸c˜ao 32
6 Considera¸c˜oes finais 36
Referˆencias Bibliogr´aficas 37
A Demonstra¸c˜oes 43
A.1 Obten¸c˜ao do logaritmo da fun¸c˜ao de verossimilhan¸ca do modelo de tempo de promo¸c˜ao Weibull . . . 43 A.2 Obten¸c˜ao do vetor escore . . . 44
B Valores fixados para os parˆametros nas simula¸c˜oes 46
C Aspectos computacionais 48
C.1 Simula¸c˜oes . . . 48 C.2 Aplica¸c˜ao . . . 61
Cap´ıtulo 1
Introdu¸c˜
ao
O tempo at´e a ocorrˆencia de um evento de interesse, tamb´em conhecido como tempo de vida, tempo at´e a falha ou tempo de sobrevivˆencia, ´e a vari´avel de estudo em an´alise de sobrevivˆencia (LAWLESS, 2003). Os modelos usuais de sobrevivˆencia s˜ao amplamente conhecidos e discutidos na literatura, sendo baseados na suposi¸c˜ao de que o evento de interesse ir´a ocorrer em todos os indiv´ıduos do estudo, desde que acompanhados tempo suficiente (LAWLESS, 2003; COX; OAKES, 1984; COLLETT, 2015).
No entanto, esses modelos usuais podem ser inadequados quando uma propor¸c˜ao da popula¸c˜ao n˜ao estiver mais sujeita ao evento de interesse, ou seja, parte da popula¸c˜ao estiver “curada”. Modelos que tratam desta abordagem s˜ao chamados de modelos de fra¸c˜ao de cura. Os primeiros modelos para esse tipo de situa¸c˜ao foram propostos por Boag (1949) e Berkson e Gage (1952) no contexto de tempo de sobrevivˆencia de pacientes com cˆancer, considerando mistura de distribui¸c˜oes. Esses modelos ficaram conhecidos como modelos de mistura padr˜ao, pois s˜ao baseados na mistura de duas distribui¸c˜oes, uma para a sobrevivˆencia dos indiv´ıduos n˜ao curados e a outra uma distribui¸c˜ao degenerada, a qual permite tempos infinitos para os curados. Para mais detalhes sobre modelos de mistura ver Maller e Zhou (1996).
O modelo de mistura parece atraente e intuitivo. No entanto, apresenta alguns inconvenientes. Na presen¸ca de covari´aveis ele n˜ao apresenta estrutura de riscos pro-porcionais, caracter´ıstica desejada quando utilizada inferˆencia cl´assica (MATELUNA, 2014; YAKOVLEV; TSODIKOV, 1996). Outra abordagem na classe dos modelos de fra¸c˜ao de cura com a estrutura de riscos proporcionais ´e o modelo de tempo de pro-mo¸c˜ao. Este modelo foi apresentado por Yakovlev et al. (1993), estendido por Chen, Ibrahim e Sinha (1999) e incorporado como caso particular em uma forma unificada juntamente com o modelo de mistura padr˜ao, por Rodrigues et al. (2009). Este modelo,
2
mais complexo que o modelo de mistura padr˜ao, tem caracter´ısticas adequadas para explicar o mecanismo biol´ogico envolvido em estudo de portadores de cˆancer. Tamb´em se adequa a outras aplica¸c˜oes e atende `a caracter´ıstica de riscos proporcionais.
Diferentes abordagens tˆem sido apresentadas no contexto de estima¸c˜ao dos parˆa-metros nesses modelos, sob o ponto de vista cl´assico e bayesiano (MALLER; ZHOU, 1996; CHEN; IBRAHIM; SINHA, 1999; IBRAHIM; CHEN; SINHA, 2005; FONSECA; VALEN ¸CA; BOLFARINE, 2013). A estima¸c˜ao dos parˆametros no presente trabalho ´e baseada nos estimadores de m´axima verossimilhan¸ca (EMV). Sob condi¸c˜oes de regulari-dade esses estimadores possuem proprieregulari-dades de consistˆencia e normaliregulari-dade assint´otica (SEVERINI, 2000). Ap´os a estima¸c˜ao pontual, outro aspecto importante na modela-gem s˜ao os testes de hip´oteses sobre os parˆametros do modelo. Entre as estat´ısticas de teste conhecidas na literatura para realiza¸c˜ao de testes de hip´oteses temos: (i) a estat´ıstica da raz˜ao de verossimilhan¸cas (LR) (NEYMAN; PEARSON, 1928), (ii) es-tat´ıstica Wald (W) (WALD, 1943), (iii) eses-tat´ıstica escore de Rao (S) (RAO, 1948) e (iv) a estat´ıstica gradiente (G) (TERRELL, 2002).
Estes testes s˜ao baseados em estat´ısticas cuja distribui¸c˜ao assint´otica sob a hip´o-tese nula ´e a qui-quadrado e s˜ao denominados testes assint´oticos de primeira ordem (CORDEIRO; CRIBARI-NETO, 2014). Desta forma, os valores cr´ıticos s˜ao prove-nientes de aproxima¸c˜oes v´alidas em grandes amostras. Contudo, essas aproxima¸c˜oes podem ser pobres em pequenas amostras, acarretando consider´aveis distor¸c˜oes da pro-babilidade do erro tipo I (tamanho) dos testes (CRIBARI-NETO; CORDEIRO, 1996; CORDEIRO; CRIBARI-NETO, 2014).
Nas estat´ısticas (i) e (iv), conforme Carneiro (2012), verifica-se consider´aveis distor-¸c˜oes da probabilidade do erro tipo I no modelo de tempo de promo¸c˜ao Weibull. Nesse sentido, torna-se evidente a necessidade de melhoramentos inferenciais em pequenas amostras, por meio de ajustes anal´ıticos ou num´erico computacionais.
1.1 Objetivos 3
CYSNEIROS; CRIBARI-NETO, 2013; CRIBARI-NETO; QUEIROZ, 2014).
Outra alternativa `as corre¸c˜oes bootstrap usuais ´e a corre¸c˜ao de Bartlett bootstrap
para a estat´ıstica da raz˜ao de verossimilhan¸cas, introduzida por Rocke (1989), em que o fator de corre¸c˜ao de Bartlett (LAWLEY, 1956) ´e determinado pelo m´etodobootstrap. Essa corre¸c˜ao se torna uma boa alternativa `a determina¸c˜ao anal´ıtica do fator de cor-re¸c˜ao de Bartlett, que em alguns modelos podem ser custosas ou imposs´ıveis de serem obtidas (CORDEIRO; CRIBARI-NETO, 2014; LOOSE; BAYER; PEREIRA, 2015).
1.1
Objetivos
Neste sentido, o objetivo geral do presente trabalho ´e avaliar e melhorar as infe-rˆencias via testes de hip´oteses em amostras de tamanho finito no modelo de tempo de promo¸c˜ao Weibull. Para alcan¸car este objetivo geral, pontuamos os seguintes objetivos espec´ıficos:
• revisar o estado da arte no que tange corre¸c˜oes de testes de hip´oteses viabootstrap
e Bartlett bootstrap, em especial em modelos de sobrevivˆencia;
• avaliar os testes de hip´oteses da raz˜ao de verossimilhan¸cas, escore, Wald e gradi-ente no modelo de tempo de promo¸c˜ao Weibull. Salienta-se que os desempenhos das estat´ısticas Wald e escore ainda n˜ao foram investigados no modelo de tempo de promo¸c˜ao Weibull;
• melhorar os testes de hip´oteses por meio de corre¸c˜oes bootstrap e Bartlett boots-trap;
• avaliar numericamente via simula¸c˜oes de Monte Carlo as corre¸c˜oes propostas;
• aplicar a dados reais os melhoramentos inferenciais propostos.
1.2
Descri¸c˜
ao dos cap´ıtulos
Cap´ıtulo 2
Modelos de sobrevivˆ
encia com
fra¸c˜
ao de cura e modelo de tempo
de promo¸c˜
ao Weibull
Neste cap´ıtulo ´e apresentada uma introdu¸c˜ao aos conceitos b´asicos de an´alise de sobrevivˆencia e do modelo de fra¸c˜ao de cura, considerando a abordagem unificada proposta em Rodrigues et al. (2009).
2.1
Introdu¸c˜
ao `
a an´
alise de sobrevivˆ
encia
A an´alise de sobrevivˆencia ´e caracterizada por um conjunto de t´ecnicas estat´ısticas que tˆem como principal objetivo o estudo do tempo de vida, ou tempo at´e a ocorrˆencia de um evento de interesse. Por exemplo, tempo at´e a morte de um paciente, tempo at´e a falha de um componente eletrˆonico, tempo at´e a recidiva de uma doen¸ca, tempo at´e a falˆencia de uma empresa, entre outras ocorrˆencias, s˜ao objetivo de estudo em an´alise de sobrevivˆencia. Sendo a vari´avel resposta conhecida na literatura como tempo de vida ou tempo de falha (LAWLESS, 2003; COX; OAKES, 1984; COLLETT, 2015; COLOSIMO; GIOLO, 2006).
Seja T a vari´avel aleat´oria cont´ınua n˜ao-negativa que corresponde ao tempo at´e a ocorrˆencia de um evento de interesse, f(t) a fun¸c˜ao densidade e F(t) a fun¸c˜ao distri-bui¸c˜ao acumulada. Em an´alise de sobrevivˆencia s˜ao frequentemente utilizadas duas outras fun¸c˜oes: a fun¸c˜ao de sobrevivˆencia e a fun¸c˜ao risco, apresentadas a seguir.
2.1 Introdu¸c˜ao `a an´alise de sobrevivˆencia 5
2.1.1
Fun¸c˜
ao de sobrevivˆ
encia e fun¸c˜
ao risco
A fun¸c˜ao de sobrevivˆencia para a vari´avel aleat´oriaT ´e dada por (LAWLESS, 2003):
S(t) = P(T > t) = Z ∞
t
f(u)du= 1−F(t), para t >0. (2.1)
Esta fun¸c˜ao representa a probabilidade de um indiv´ıduo sobreviver pelo menos at´e o tempo t. Note que S(t) ´e mon´otona decrescente com as seguintes propriedades:
i) S(0) = 1
ii) limt→∞S(t) = 0.
A fun¸c˜ao risco ou taxa de falha de T ´e dada por
h(t) = lim ∆t→0+
P(t < T ≤t+ ∆t|T > t)
∆t . (2.2)
Esta fun¸c˜ao especifica a taxa de falha instantˆanea no tempo t (LAWLESS, 2003). As fun¸c˜oes de densidade, sobrevivˆencia e taxa de falha est˜ao relacionadas. Essa rela¸c˜ao ´e dada por
f(t) = −dS(t)
dt , h(t) = f(t)
S(t) =
−dlogS(t)
dt .
Nota-se que conhecendo uma delas as demais podem ser obtidas diretamente. A primeira rela¸c˜ao vem da defini¸c˜ao (2.1), sendo f´acil a verifica¸c˜ao e a segunda vem de (2.2). A demonstra¸c˜ao ´e dada a seguir:
h(t) = lim ∆t→0+
P(t < T ≤t+ ∆t|T ≥t) ∆t
= lim ∆t→0+
1 ∆t
P(t < T ≤t+ ∆t)
P(T > t)
= lim ∆t→0+
1 ∆t
F(t+ ∆t)−F(t)
S(t)
= 1
S(t)∆limt→0+
F(t+ ∆t)−F(t) ∆t
= 1
S(t)F
′(t) = f(t)
2.1 Introdu¸c˜ao `a an´alise de sobrevivˆencia 6
2.1.2
Censura
Em dados de sobrevivˆencia a principal caracter´ıstica observada ´e a presen¸ca de censura, vista como uma ocorrˆencia apenas parcial da resposta (COX; OAKES, 1984). A censura surge quando algum acontecimento impede que a ocorrˆencia do evento de interesse seja observada para um indiv´ıduo. Isso pode ocorrer pela morte do indiv´ıduo, pela mudan¸ca de cidade ou, at´e mesmo, porque o estudo terminou antes que o evento de interesse tenha sido observado (LAWLESS, 2003; COX; OAKES, 1984).
A censura nos dados ´e a principal raz˜ao para o desenvolvimento dos modelos de sobrevivˆencia (LAWLESS, 2003). Nos casos em que n˜ao h´a censura, m´etodos usuais como modelos de regress˜ao ou modelos lineares seriam aplic´aveis.
H´a diferentes tipos de censura, sendo que o mais utilizado e tamb´em considerado nesse trabalho ´e a censura `a direita. Caracteriza-se pela ocorrˆencia da falha ap´os o tempo registrado, ou seja, o tempo do in´ıcio do estudo at´e a ocorrˆencia do evento de interesse ´e maior que o tempo registrado (COLLETT, 2015; LAWLESS, 2003). Entre os mecanismos de censura `a direita conhecidos na literatura o mais comum na pr´atica ´e o de censura aleat´oria. Este caracteriza-se por interrup¸c˜oes aleat´orias no acompanhamento dos indiv´ıduos (LAWLESS, 2003). Neste mecanismo assume-se que os tempos de censura tamb´em s˜ao vari´aveis aleat´orias. Quando a distribui¸c˜ao da censura n˜ao envolve parˆametros de interesse, diz-se que a censura ´e n˜ao informativa (COLLETT, 2015).
2.1.3
Modelos param´
etricos
A seguir s˜ao apresentadas duas distribui¸c˜oes usadas frequentemente na an´alise de dados de sobrevivˆencia, que ser˜ao consideradas neste trabalho.
Distribui¸c˜ao Weibull
A distribui¸c˜ao Weibull ´e uma generaliza¸c˜ao da distribui¸c˜ao exponencial. Dentre os modelos param´etricos, possivelmente ´e o mais utilizado na modelagem de dados de tempo de vida (LAWLESS, 2003).
A fun¸c˜ao densidade de probabilidade de uma vari´avel aleat´oria T com distribui¸c˜ao Weibull ´e dada por
f(t) = a
bat
a−1exp
−
t b
a
, t≥0, (2.3)
2.2 Modelos com fra¸c˜ao de cura 7
A fun¸c˜ao de sobrevivˆencia e fun¸c˜ao risco s˜ao dadas por
S(t) = exp − t b a
e h(t) = a
bat a−1.
Distribui¸c˜ao valor extremo
Na an´alise de dados de sobrevivˆencia muitas vezes ´e conveniente trabalhar com o logaritmo dos dados (COLOSIMO; GIOLO, 2006). A distribui¸c˜ao valor extremo est´a relacionada com a distribui¸c˜ao Weibull, de tal forma que se T tem distribui¸c˜ao Weibull(a,b), Y = log(T) tem distribui¸c˜ao valor extremo com parˆametros µ= log(b) e
σ= 1
a. A fun¸c˜ao densidade de probabilidade da vari´avel aleat´oria Y ´e dada por
f(y) = 1
σ exp
y−µ σ −exp
y−µ σ
,
em quey eµ∈R eσ > 0,µ eσ s˜ao parˆametros de posi¸c˜ao e escala, respectivamente. A fun¸c˜ao de sobrevivˆencia ´e dada por
S(y) = exp
−exp
y−µ σ
.
2.2
Modelos com fra¸c˜
ao de cura
Os modelos cl´assicos de an´alise de sobrevivˆencia tˆem como caracter´ıstica fun¸c˜ao de sobrevivˆencia pr´opria, ou seja, limt→∞S(t) = 0, (ver Se¸c˜ao 2.1.1, propriedade ii).
Fun¸c˜oes de sobrevivˆencia que n˜ao satisfazem essa propriedade s˜ao ditas impr´oprias, caracterizando os modelos com fra¸c˜ao de cura, tamb´em chamados de modelos de longa dura¸c˜ao (CHEN; IBRAHIM; SINHA, 1999; RODRIGUES et al., 2009).
Na pr´atica, a presen¸ca de imunes na popula¸c˜ao pode ser identificada atrav´es do gr´afico de Kaplan-Meier (KAPLAN; MEIER, 1958), que estima de forma n˜ao para-m´etrica a fun¸c˜ao de sobrevivˆencia te´orica. Um indicativo da presen¸ca de imunes nos dados pode ser a ocorrˆencia de um grande n´umero de observa¸c˜oes censuradas no fim do estudo, desde que o acompanhamento seja feito por um tempo suficientemente grande (MALLER; ZHOU, 1996). Desta forma, a curva de Kaplan-Meier vai se estabilizar em um valor maior que zero.
2.2 Modelos com fra¸c˜ao de cura 8
promo¸c˜ao como casos particulares.
2.2.1
Formula¸c˜
ao do modelo
SejaM uma vari´avel aleat´oria que denota o n´umero de causas ou riscos competindo para a ocorrˆencia de um particular evento de interesse, com distribui¸c˜ao de probabi-lidade pm = Pθ(M = m), sendo θ o parˆametro da distribui¸c˜ao e m = 0,1,2, . . .. SejamZk, k= 1, . . . , m, vari´aveis aleat´orias independentes com fun¸c˜ao de distribui¸c˜ao
F(t) = 1−S(t), independente deM, representando o tempo at´e a ocorrˆencia do evento devido `ak-´esima causa.
O n´umero de causas competindo para a ocorrˆencia do evento M e o tempo de ocorrˆencia para cada causa (Zk) s˜ao n˜ao observ´aveis. Apenas pode-se observar o menor tempo entre todas as causas, T = min{Z0, Z1, . . . , ZM}, definido como o tempo at´e a ocorrˆencia do evento. A vari´avelZ0 ´e tal que P(Z0 =∞) = 1, pois quandoM = 0 n˜ao existem causas ou riscos para a ocorrˆencia do evento.
A fun¸c˜ao de sobrevivˆencia da vari´avel aleat´oria T, denotada por Sp(t), ´e dada por
Sp(t) = P(T > t)
=P(T > t,M = 0) +P(T > t,M ≥1)
=P(T > t|M = 0)P(M = 0) +P(T > t|M ≥1)P(M ≥1)
=p0+
∞
X
m=1
pmS(t)m, (2.4)
em queP(T > t|M = 0) = 1,P(M = 0) =p0eS(t) representa a fun¸c˜ao de sobrevivˆen-cia dos indiv´ıduos suscept´ıveis `a ocorrˆensobrevivˆen-cia do evento, caracterizada por ser pr´opria. Logo, ´e f´acil ver que Sp(t) ´e impr´opria, ou seja, limt→∞Sp(t) = p0 >0, sendo p0 > 0 interpretado como a fra¸c˜ao de curados (RODRIGUES et al., 2009).
Seja{am}uma sequˆencia de n´umeros reais. Se
A(s) =a0 +a1s+a2s2+· · ·
converge para s ∈ [0,1], ent˜ao define-se A(s) como a fun¸c˜ao geradora de sequˆencias {am} (FELLER, 1960).
Rodrigues et al. (2009) mostram que:
Sp(t) = A(S(t)) =
∞
X
m=0
2.2 Modelos com fra¸c˜ao de cura 9
em queA(·) ´e a fun¸c˜ao geradora de sequˆencias {pm}.
Ainda, conforme Rodrigues et al. (2009) a equa¸c˜ao (2.4) pode tamb´em ser escrita como
Sp(t) =p0+ (1−p0)Sp∗(t), (2.5)
em queS∗
p(t) = P∞
m=1p∗mS(t)m ep∗m =
pm 1−p0
.
As fun¸c˜oes de subdensidade e de risco do modelo s˜ao dadas, respectivamente, por:
fp(t) =−
∂Sp(t)
∂t =f(t)
∞
X
m=1
mpm[S(t)]m−1 e hp(t) =
fp(t)
Sp(t)
.
A seguir s˜ao apresentados dois casos particulares do modelo unificado que se dife-renciam pela distribui¸c˜ao assumida paraM.
Modelo de mistura
No modelo de mistura assume-se que M tem distribui¸c˜ao Bernoulli com parˆametro 1−θ, em que p0 =θ, p1 = 1−θ epn = 0 paran ≥2 (RODRIGUES et al., 2009). Ba-seada na equa¸c˜ao (2.4) ou em (2.5), a sobrevivˆencia do modelo de mistura apresentado por Berkson e Gage (1952) ´e dada por
Sp(t) = θ+ (1−θ)S(t),
em que θ representa a propor¸c˜ao de curados. As fun¸c˜oes de subdensidade e de risco s˜ao dadas por
fp(t) = (1−θ)f(t) e hp(t) = f(t)
(1−θ)
θ+ (1−θ)S(t).
Modelo de tempo de promo¸c˜ao
Neste modelo assume-se que M tem distribui¸c˜ao Poisson com parˆametro θ. Base-ada na equa¸c˜ao (2.4), a sobrevivˆencia do modelo tempo de promo¸c˜ao apresentado em Yakovlev et al. (1993) e Chen, Ibrahim e Sinha (1999) ´e dada por
2.2 Modelos com fra¸c˜ao de cura 10
em que S(t) ´e a fun¸c˜ao de sobrevivˆencia dos tempos Zk, k = 1, . . . , M, caracterizada por ser pr´opria. Logo, ´e f´acil ver que Sp(t) ´e impr´opria, com limt→∞Sp(t) = exp(−θ), sendo p0 = exp(−θ) a fra¸c˜ao de curados. As fun¸c˜oes de subdensidade e de risco s˜ao dadas, respectivamente, por
fp(t) = θf(t) exp(−θF(t)) e hp(t) = θf(t). (2.7)
2.2.2
Verossimilhan¸ca para o modelo de tempo de promo¸c˜
ao
Para obten¸c˜ao da fun¸c˜ao de verossimilhan¸ca, supomos uma amostra com n indi-v´ıduos e para cada indiv´ıduo i, i = 1, . . . , n, e consideramos as seguintes vari´aveis associadas:
• Mi: vari´avel aleat´oria discreta n˜ao observ´avel com fun¸c˜ao de probabilidade
Pθ(Mi =mi) =
e−θθmi
mi!
, em que θ ´e um vetor de parˆametros desconhecidos;
• Zij, i = 1, . . . , n, j = 1 =, . . . , mi: s˜ao vari´aveis aleat´orias independentes e iden-ticamente distribu´ıdas (i.i.d.) que representam o tempo que a causaj, noi-´esimo indiv´ıduo, leva para provocar o evento de interesse, com fun¸c˜ao de distribui¸c˜ao
F(z|λ) e sobrevivˆencia S(z|λ) = 1 −F(z|λ), sendo λ o vetor de parˆametros associados ao modelo.
• Yi = min{Ti, Ci}: tempo observado para o indiv´ıduo i, sendo Ci o tempo de censura, considerada aleat´oria, n˜ao informativa e independente de Ti, e Ti = min{Zi0,Zi1, . . . , ZiMi};
• δi: indicador da censura, ou seja, se Yi =Ti, δi = 1, e se Yi =Ci,δi = 0;
• xi = (xi1, xi2, . . . , xip)⊤: vetor de covari´aveis associado aoi-´esimo indiv´ıduo; • X: a matrizn×p que cont´em os vetores de covari´aveis.
O conjunto dos dados completos ´e denotado por Dc = (n,y,δ,M,X), em que y= (y1, . . . , yn)⊤ s˜ao os tempos observados, δ = (δ1, . . . , δn)⊤, M = (M1, . . . , Mn)⊤, X = (x1, . . . , xn)⊤. O conjunto dos dados observ´aveis ´e denotado por D= (n,y,δ,X).
As covari´aveis podem ser inclu´ıdas atrav´es do parˆametro associado `a fra¸c˜ao de cura
2.3 Modelo de tempo de promo¸c˜ao Weibull 11
Seja φ = (β⊤,λ⊤)⊤ o vetor de parˆametros desconhecidos. Pode-se mostrar (ver
Carneiro (2012)), que a fun¸c˜ao de verossimilhan¸ca em rela¸c˜ao aos dados completos ´e dada por
L(φ;Dc) = n Y
i=1
[mif(yi|λ)]δi[S(yi|λ)]mi−δipθi(mi).
O logaritmo da fun¸c˜ao de verossimilhan¸ca ´e dado por
ℓ(φ;Dc) = n X
i=1
[δilog(mi) +δilog(f(yi|λλλ)) + (mi−δi) log(S(yi|λλλ)) + log(pθi(mi))].
Como existem vari´aveis latentes, na pr´atica utiliza-se uma verossimilhan¸ca mar-ginal, obtida atrav´es do somat´orio nas vari´aveis Mi. A fun¸c˜ao de verossimilhan¸ca marginal ´e dada por
L(φ;D) = n Y
i=1
[fp(yi|λλλ,θ)]δi[Sp(yi|λλλ, θ)]1−δi.
O logaritmo da fun¸c˜ao de verossimilhan¸ca marginal ´e dado por
ℓ(φ;D) = n X
i=1
δilog[fp(yi|φ)] + (1−δi) log[Sp(yi|φ)]. (2.8)
As demonstra¸c˜oes desses resultados podem ser verificadas, por exemplo, em Car-neiro (2012).
2.3
Modelo de tempo de promo¸c˜
ao Weibull
Neste modelo assume-se que os tempos de falha dos indiv´ıduos suscet´ıveis seguem uma distribui¸c˜ao Weibull(a, b), como apresentada em (2.3). Em an´alise de sobrevi-vˆencia, por raz˜oes computacionais, ´e comum reparametrizar a distribui¸c˜ao Weibull. Um dos trabalhos que utiliza reparametriza¸c˜oes ´e Fonseca, Valen¸ca e Bolfarine (2013). Neste trabalho consideramos a reparametriza¸c˜ao dada a seguir:
ρ= log(a) e γ =−alog(b),
2.3 Modelo de tempo de promo¸c˜ao Weibull 12
Considerando essa reparametriza¸c˜ao, as fun¸c˜oes de densidade de probabilidade e sobrevivˆencia s˜ao dadas, respectivamente, por:
f(t) =eρteρ−1exp(γ−teρeγ) e S(t) = exp(−teρeγ).
Como consequˆencia, temos a fun¸c˜ao de sobrevivˆencia de longa dura¸c˜ao (2.6) dada por
Sp(t) = exp{−θ[1−exp(−te ρ
eγ)]}. (2.9)
De (2.7) temos a subdensidade dada por
fp(t) =θeρte ρ−1
exp(γ−teρ
eγ) exp{−θ[1−exp(−teρ
eγ)]} (2.10)
e a fun¸c˜ao risco do modelo dada por
hp(t) = θeρte ρ−1
exp(γ−teρ
eγ).
Considerando uma amostra com n indiv´ıduos, seja D = (n,y,δ,X) o conjunto dos dados observ´aveis e φ = (β⊤,λ⊤)⊤ o vetor de parˆametros, em que λ = (ρ, γ).
Substituindo (2.9) e (2.10) em (2.8) e incluindo covari´aveis atrav´es da rela¸c˜ao θi = exp(xi⊤β), o logaritmo da fun¸c˜ao de verossimilhan¸ca do modelo de tempo de promo¸c˜ao
´e dado abaixo (ver demonstra¸c˜ao no Apˆendice A):
ℓ(φ;D) = n X
i=1
δi[xi⊤β+γ+ρ+ log(ye
ρ−1 i )−y
eρ i e
γ
]−exp(xi⊤β)[1−exp(−ye
ρ i e
γ )].
(2.11)
O vetor escore ´e obtido derivando (2.11) em rela¸c˜ao ao vetor de parˆametrosφ, dado a seguir:
U(φ) = ∂ℓ(φ;D)
∂φ =
∂ℓ(φ;D)
∂β ∂ℓ(φ;D)
∂ρ ∂ℓ(φ;D)
∂γ =
Uβ(φ)
Uρ(φ)
Uγ(φ)
(p+2)×1 =
n X
i=1
2.3 Modelo de tempo de promo¸c˜ao Weibull 13
em que X∗
i =
xi 0 0
0 1 0
0 0 1
(p+2)×3
´e uma matriz e si(φ) ´e o vetor de dimens˜ao 3×1
dado por (si1(φ), si2(φ), si3(φ))⊤, sendo
si1(φ) =δi−θi[1−exp(−ye ρ i eγ)],
si2(φ) =δi[1 +eρlog(yi)(1−ye ρ
i eγ)]−θiexp(ρ+γ−ye ρ i eγ)ye
ρ
i log(yi) e
si3(φ) =δi(1−ye ρ
i eγ)−θiexp(γ−ye ρ i eγ)ye
ρ i .
A obten¸c˜ao do vetor escore pode ser verificada no Apˆendice A. As estimativas de m´axima verossimilhan¸ca s˜ao obtidas a partir da solu¸c˜ao do seguinte sistema:
Uβ(φ) = 0,
Uρ(φ) = 0,
Uγ(φ) = 0.
A solu¸c˜ao deste sistema n˜ao possui forma fechada, sendo necess´ario o uso de algorit-mos de otimiza¸c˜ao n˜ao-linear para encontrar as estimativas de m´axima verossimilhan¸ca. Neste trabalho utiliza-se o m´etodo quasi-Newton BFGS (PRESS et al., 1992).
A matriz de informa¸c˜ao observada J(φ) ´e dada pelo negativo da segunda derivada da fun¸c˜ao de log-verossimilhan¸ca (2.11), dada a seguir:
J(φ) =−∂
2ℓ(φ;D)
∂φ∂φ⊤ =−
∂2ℓ(φ;D)
∂β∂β⊤
∂2ℓ(φ;D)
∂β∂ρ
∂2ℓ(φ;D)
∂β∂γ ∂2ℓ(φ;D)
∂ρ∂β⊤
∂2ℓ(φ;D)
∂ρ2
∂2ℓ(φ;D)
∂ρ∂γ ∂2ℓ(φ;D)
∂γ∂β⊤
∂2ℓ(φ;D)
∂γ∂ρ
∂2ℓ(φ;D)
∂γ2 .
Cap´ıtulo 3
Testes de hip´
oteses e
melhoramentos inferenciais em
pequenas amostras
Ap´os a estima¸c˜ao dos parˆametros do modelo, em geral, realizam-se testes a fim de determinar se hip´oteses feitas sobre esses parˆametros s˜ao suportadas por evidˆencias ob-tidas a partir de dados amostrais. A seguir descrevemos os testes de hip´oteses baseados nas estat´ısticasLR,W,S eG, uma breve revis˜ao sobre melhoramentos inferenciais em testes de hip´oteses, as propostas de corre¸c˜oes consideradas nesse trabalho e algumas referˆencias que discutem a validade dos testes em modelos de sobrevivˆencia.
3.1
Estat´ısticas de teste
Seja o vetor de parˆametros φ= (ν⊤,τ⊤)⊤, em que ν = (ν
1, . . . , νq)⊤ representa o vetor de parˆametros de interesse eτ = (τ1, . . . , τs)⊤ o vetor de parˆametros de pertur-ba¸c˜ao. Suponha que o interesse esteja em testar
H0 :ν =ν0 versus H1 :ν 6=ν0,
em queν0 ´e um vetor de constantes especificado de dimens˜ao q.
O estimador de m´axima verossimilhan¸ca sob H0 (restrito) ´e denotado por φe = (ν0⊤,τe⊤)⊤ e o estimador de m´axima verossimilhan¸ca irrestrito φb = (νb⊤,bτ⊤)⊤. Seja
ℓ(φ) = ℓ(ν,τ) o logaritmo da fun¸c˜ao de verossimilhan¸ca de ν e τ. Conforme Cor-deiro (1992), podemos particionar o vetor escore U(φ), a matriz informa¸c˜ao de Fisher
K(φ) e sua inversa K(φ)−1 da mesma maneira que particionamos φ, sendo U(φ)⊤ =
3.1 Estat´ısticas de teste 15
(Uν(φ)⊤, Uτ(φ)⊤),
K(φ) = Kν ν(φ) Kν τ(φ)
Kτ ν(φ) Kτ τ(φ)
!
e K(φ)−1 = K
ν ν
(φ) Kν τ
(φ)
Kτ ν
(φ) Kτ τ
(φ) !
.
Considerando essas parti¸c˜oes as estat´ısticas da raz˜ao de verossimilhan¸cas, Wald, escore e gradiente s˜ao escritas conforme segue:
LR= 2[ℓ(bν,τb)−ℓ(ν0,τe)],
W = (νb−ν0)⊤[K
ν ν(b
φ)]−1(νb−ν0),
S=Uν(φe)⊤K ν ν
(φe)Uν(φe),
G=Uν(φe)⊤(νb−ν0),
sendoKν ν
= Kν ν −Kν τKτ τ−1Kν τ⊤
−1
. Note que quando ν e τ s˜ao ortogonais, Kν ν
=
K−1
ν ν.
Sob condi¸c˜oes de regularidade usuais e sob a hip´otese nula, as quatro estat´ısti-cas apresentadas s˜ao assintoticamente equivalentes, possuindo aproximadamente dis-tribui¸c˜ao χ2
q em grandes amostras, em que q ´e o n´umero de parˆametros testados na hip´otese nula (SEVERINI, 2000; CASELLA; BERGER, 2002; VARGAS; FERRARI; LEMONTE, 2014).
Um importante trabalho no contexto de testes de hip´oteses ´e Buse (1982), o qual apresenta interpreta¸c˜oes geom´etricas dos testes baseados nas estat´ısticas RV, W e S. No mesmo sentido, recentemente Montoril (2010) apresenta a interpreta¸c˜ao geom´etrica tamb´em para o teste baseado na estat´ıstica G.
3.2 Melhoramentos inferenciais em testes de hip´oteses 16
Os testes de hip´oteses s˜ao realizados com base em valores cr´ıticos obtidos a partir de aproxima¸c˜oes v´alidas em grandes amostras. Nesse sentido, o uso destes testes em pequenas amostras pode acarretar consider´aveis distor¸c˜oes na probabilidade do erro tipo I. Essas distor¸c˜oes podem ser reduzidas atrav´es de melhoramentos inferenciais (CRIBARI-NETO; QUEIROZ, 2014; VARGAS; FERRARI; LEMONTE, 2014). A seguir s˜ao apresentados os procedimentos utilizados no presente trabalho baseados em m´etodos num´erico computacionais para corre¸c˜oes em testes de hip´oteses.
3.2
Melhoramentos inferenciais em testes de hip´
o-teses
Melhoramentos inferenciais em testes de hip´oteses tˆem recebido grande destaque na comunidade acadˆemica nos ´ultimos anos, sendo desenvolvidos em diferentes mode-los, via ajustes anal´ıticos ou num´erico computacionais. Duas importantes referˆencias sobre melhoramentos inferenciais em pequenas amostras s˜ao Cribari-Neto e Cordeiro (1996) e Cordeiro e Cribari-Neto (2014). Esses trabalhos abordadam corre¸c˜oes como a de Bartlett, por exemplo, a qual foi proposta por Bartlett (1937) e posteriormente generalizada por Lawley (1956), obtida de forma anal´ıtica. A ideia dessa corre¸c˜ao ´e considerar uma transforma¸c˜ao na estat´ıstica de teste, baseada em um fator de corre¸c˜ao, a qual leva a uma melhor aproxima¸c˜ao da distribui¸c˜ao da estat´ıstica corrigida pela dis-tribui¸c˜ao qui-quadrado. Tamb´em s˜ao abordadas outras corre¸c˜oes como a tipo Bartlett, Bartlett bootstrap e bootstrap.
Dentre os trabalhos desenvolvidos considerando corre¸c˜oes em testes de hip´oteses temos Cysneiros e Cordeiro (2002), no qual ´e obtida a corre¸c˜ao tipo Bartlett para a estat´ıstica escore, em nota¸c˜ao matricial, na classe dos modelos n˜ao-lineares da fam´ılia loca¸c˜ao e escala, al´em da aproxima¸c˜aobootstrap para a distribui¸c˜ao nula das estat´ısticas escore e raz˜ao de verossimilhan¸cas. Em Cysneiros e Ferrari (2006) ´e obtida a corre¸c˜ao de Bartlett para a estat´ıstica da raz˜ao de verossimilhan¸cas modificada para testar dispers˜ao vari´avel no modelo n˜ao-linear da fam´ılia exponencial. Cysneiros et al. (2010) prop˜oem corre¸c˜oes anal´ıticas para a estat´ıstica escore, bem como a vers˜ao bootstrap
3.2 Melhoramentos inferenciais em testes de hip´oteses 17
melhoramentos inferenciais no contexto de dados com censura. Cribari-Neto e Queiroz (2014) consideram no modelo de regress˜ao beta vers˜oes ajustadas da estat´ıstica raz˜ao de verossimilhan¸cas j´a propostas na literatura por Ferrari e Pinheiro (2011), e corre¸c˜oes via bootstrap para as estat´ısticas raz˜ao de verossimilhan¸cas, escore e Wald. Vargas, Ferrari e Lemonte (2014) nos modelos lineares generalizados apresentam a corre¸c˜ao de Bartlett para as estat´ısticas raz˜ao de verossimilhan¸cas e escore, e derivam o fator de corre¸c˜ao tipo Bartlett para a estat´ıstica gradiente, al´em de vers˜oes bootstrap para as quatro estat´ısticas j´a mencionadas no presente trabalho. Recentemente Loose, Bayer e Pereira (2015) prop˜oem a corre¸c˜ao Bartlett bootstrap no modelo de regress˜ao beta inflacionado, comparando com a estat´ıstica usual e ajustes anal´ıticos via Skovgaard (SKOVGAARD, 1996) j´a propostos na literatura para o modelo por Pereira e Cribari-Neto (2014). Cabe destacar que n˜ao h´a trabalhos que abordam corre¸c˜oes em testes de hip´oteses no modelo com fra¸c˜ao de cura, em especial no modelo tempo de promo¸c˜ao Weibull.
Todos os trabalhos mencionados avaliam o desempenho dos testes usuais e de suas vers˜oes corrigidas. Em todos os casos os testes corrigidos s˜ao menos distorcidos que os testes usuais. Cabe ainda destacar que os desempenhos das corre¸c˜oes anal´ıticas ou via m´etodos num´erico computacionais s˜ao muito semelhantes. Em geral as corre¸c˜oes num´erico computacionais apresentam desempenhos iguais ou at´e superiores `as corre¸c˜oes anal´ıticas.
Nesse sentido, corre¸c˜oes via m´etodos num´erico computacionais s˜ao alternativas vi´a-veis para melhoramentos inferenciais em pequenas amostras, quando h´a dificuldades anal´ıticas impeditivas ou muito custosas, como no modelo aqui considerado. A seguir s˜ao apresentados os dois m´etodos de corre¸c˜ao em testes de hip´oteses considerados no presente trabalho.
3.2.1
Corre¸c˜
ao
bootstrap
usual
Uma das op¸c˜oes de melhoramento inferencial em testes de hip´oteses ´e a corre¸c˜ao
aleat´o-3.2 Melhoramentos inferenciais em testes de hip´oteses 18
ria observada a distribui¸c˜ao emp´ırica da estat´ıstica de teste de interesse (CORDEIRO; CRIBARI-NETO, 2014; CRIBARI-NETO; QUEIROZ, 2014). Para maiores detalhes ver Davison e Hinkley (1997).
Conforme Cribari-Neto e Queiroz (2014) o esquema bootstrap pode ser descrito baseado nos seguintes passos:
1. Seja y a amostra observada. Calcular a estat´ıstica de teste de interesse (dentre as apresentadas na Se¸c˜ao 3.1), denotada por ξ(y).
2. Gerar a amostra bootstrap y∗
b do modelo, substituindo os parˆametros do modelo pelas estimativas sob H0, obtidos com base na amostra original y.
3. Estimar o modelo usando y∗
b e calcular a estat´ısticaξb∗ =ξ(y∗b). 4. Repetir os passos 2 e 3 um n´umeroB grande de vezes.
5. Calcular o quantil de interesse ξ∗
1−α, com base na distribui¸c˜ao emp´ırica das B realiza¸c˜oes da estat´ıstica ξ∗
b, obtidas usando os passos do item 2 at´e 4.
6. Realizar o teste utilizando a estat´ıstica ξ(y) calculada no item 1 junto com o valor cr´ıtico de bootstrap, ξ∗
1−α, obtido no item 5. A regi˜ao de rejei¸c˜ao ´e definida com base no quantilξ∗
1−α, sendo a hip´otese nula, H0, rejeitada quando a estat´ıstica ´e maior que o quantil estimado, ou seja, ξ(y) > ξ∗
1−α. Ou ainda, em termos de p-valor aproximado por bootstrap:
p∗ = PB
b=1I{ξ∗ b>ξ(y)}
B ,
em que
I{ξ∗
b>ξ(y)} = (
1, se ξ∗
b > ξ(y), 0, c.c.
H0 ´e rejeitada se p∗ ´e menor que um valor α selecionado.
3.2.2
Corre¸c˜
ao de Bartlett
bootstrap
para a estat´ıstica
LR
3.2 Melhoramentos inferenciais em testes de hip´oteses 19
(BARTLETT, 1937), onde o fator de corre¸c˜ao ´e obtido via m´etodobootstrap (EFRON, 1979).
Rocke (1989) descreve a obten¸c˜ao da corre¸c˜ao de Bartlett bootstrap utilizando o valor esperado de LR estimado diretamente da amostra observada y = (y1, . . . , yn)⊤ utilizando reamostrasbootstrap.
Conforme Loose, Bayer e Pereira (2015) esse procedimento pode ser descrito pelos seguintes passos:
1. Gerar sob H0 B reamostras bootstrap (y∗
1, . . . ,y∗B) do modelo, substituindo os parˆametros do modelo pelas estimativas sob H0 usando a amostra original.
2. Obter a estat´ıstica LR bootstrap (LR∗b) para cada pseudo amostra y∗
b, com b = 1, . . . , B. Calculada da seguinte forma:
LR∗b = 2{ℓ(φb∗b;y∗b)−ℓ(φe
∗b ;y∗b)},
em que φb∗b ´e o EMV de φ irrestrito e φe∗b ´e o EMV sob H0.
3. Calcular a estat´ıstica LR corrigida, dada por:
LRB =
LR×q LR∗ ,
em que LR∗ = 1
B
B P b=1
LR∗b.
Rocke (1989) afirma que a corre¸c˜ao de Bartlett bootstrap tem vantagens computa-cionais comparadas ao esquema bootstrap usual, de tal forma que com B = 100 em geral tem-se resultados equivalentes ao m´etodo bootstrap usual com B = 700. Ainda, Bayer e Cribari-Neto (2013) afirmam que valores de B maiores que 200 conduzem a melhoramentos neglig´ıveis para a corre¸c˜ao de Bartlett bootstrap.
3.2.3
Bootstrap
para dados com censura
3.2 Melhoramentos inferenciais em testes de hip´oteses 20
s˜ao obtidas do vetor (Yi, δi), i = 1, . . . , n, reamostrado com reposi¸c˜ao. Akritas (1986) apresenta uma discuss˜ao das duas abordagens.
Um dos poucos trabalhos que abordam reamostragem em dados com censura `a di-reita com o objetivo de melhoramentos inferenciais em testes de hip´oteses ´e Barreto, Cysneiros e Cribari-Neto (2013). Alternativamente, utilizam bootstrap param´etrico para a obten¸c˜ao das reamostras. As amostras bootstrap s˜ao constru´ıdas baseada na distribui¸c˜ao associada `a amostra original, utilizando os estimadores dos parˆametros dessa distribui¸c˜ao. Sendo que a quantidade de censura das amostrasbootstrap ´e preser-vada, ou seja, as reamostras tem a mesma quantidade de censura da amostra original. O presente trabalho considera a mesma abordagem de Barreto, Cysneiros e Cribari-Neto (2013). As reamostras s˜ao geradas pelo m´etodobootstrap param´etrico, buscando preservar a quantidade de censura da amostra original nas amostrasbootstrap. A seguir ´e descrito o procedimento de reamostragem proposto, para o modelo considerado neste estudo, baseado no m´etodo bootstrap param´etrico.
Reamostragem bootstrap no modelo tempo de promo¸c˜ao Weibull
Seja φe = (eβ⊤,λe⊤)⊤ o EMV de φ sob H
0 e λ = (ρ, γ)⊤. A matriz das vari´aveis regressoras permanece constante, sendo a mesma da amostra original. As amostras
bootstrap s˜ao geradas considerando o algoritmo dado a seguir:
1. Gerar ocorrˆencias de m∗
i da distribui¸c˜ao Poisson com m´edia θei = exp(x⊤i βe). 2. Dado m∗
i >0, gerar zi∗1, . . . , z∗im∗
i iid da distribui¸c˜ao Weibull(ea,eb), sendo a=e ρ e
b = exp(−γ/eρ).
3. Obter os tempos de falha por t∗
i = min{zi∗1, . . . , zim∗ ∗ i}.
4. Gerar c∗
i aleatoriamente de uma distribui¸c˜ao uniforme, U(0,u), sendo utal que a propor¸c˜ao de censura da amostra original ´e conservada.
5. Obter os tempos observados por:
yi∗ = (
max{c∗
1, . . . , c∗n}, se m∗i = 0, min{t∗
i, c∗i}, se m∗i >0.
6. Associar a cada tempo observado o indicador de falha δ∗
i, dado por:
δ∗i = (
1, se y∗
i =t∗i, 0, se y∗
3.3 Testes de hip´oteses em modelos de sobrevivˆencia 21
Considerando os passos 1 a 6, obt´em-se o conjunto dos dados da b-´esima amostra
bootstrap, denotado por D∗
b = (n,y∗b,δ
∗
b,X), em que y∗b = (y∗1, . . . , yn∗). Cabe destacar, que a proposta para gera¸c˜ao das amostras bootstrap aqui apresentada para o modelo em estudo ´e pioneira em modelos de fra¸c˜ao de cura, podendo ser generalizada para outros modelos dessa classe.
As corre¸c˜oes bootstrap e Bartlett bootstrap s˜ao realizadas conforme os passos dos algoritmos apresentados nas Sub-se¸c˜oes 3.2.1 e 3.2.2. A amostrabootstrap gerada, D∗
b, ´e aplicada nos passos correspondentes nos algoritmos, sendo o modelo dado em (2.11).
3.3
Testes de hip´
oteses em modelos de sobrevivˆ
en-cia
As inferˆencias baseadas nas estat´ısticas de teste apresentadas na Se¸c˜ao 3.1 depen-dem de resultados assint´oticos, os quais est˜ao relacionados `a teoria assint´otica dos es-timadores de m´axima verossimilhan¸ca. A seguir s˜ao apresentadas algumas referˆencias que evidenciam a validade dos resultados para os modelos de sobrevivˆencia.
Um dos primeiros trabalhos a analisar com detalhes as propriedades assint´oticas do estimador de m´axima verossimilhan¸ca do modelo com fra¸c˜ao de cura, com distribui¸c˜ao exponencial associada aos tempos de falha, foi Ghitany e Maller (1992). Posterior-mente, Maller e Zhou (1996) apresentam demonstra¸c˜oes da normalidade assint´otica do estimador de m´axima verossimilhan¸ca e resultados para testes em grandes amostras, considerando o modelo param´etrico exponencial com covari´aveis, censura (n˜ao infor-mativa) e fra¸c˜ao de cura. Conforme Maller e Zhou (1996), o desenvolvimento te´orico para outras distribui¸c˜oes se d´a de forma an´aloga ao modelo exponencial.
No contexto dos modelos Weibull com fra¸c˜ao de cura, segundo Paes (2007) as propriedades do estimador de m´axima verossimilhan¸ca podem ser vistas como uma extens˜ao da teoria desenvolvida para modelos lineares generalizados (MCCULLAGH; NELDER, 1989). Ainda Paes (2007) descreve com detalhes os resultados assint´oticos para modelos Weibull com fra¸c˜ao de cura apresentados por Ghitany, Maller e Zhou (1994).
Cap´ıtulo 4
Resultados num´
ericos
Para avaliar os desempenhos em pequenas amostras dos testes raz˜ao de verossimi-lhan¸cas (LR), gradiente (G), escore (S) e Wald (W), as vers˜oes corrigidas porbootstrap, respectivamente,LRb,Gb,Sb eWb e do teste baseado na raz˜ao de verossimilhan¸cas cor-rigida via Bartlett bootstrap (LRB), foi realizado um estudo de simula¸c˜ao. O n´umero de r´eplicas de Monte Carlo foi 5000 e para as corre¸c˜oes bootstrap foram considera-das B = 1000 reamostras bootstrap. Os tamanhos amostrais utilizados foram iguais a
n= 30, 50, 100. Toda a implementa¸c˜ao computacional foi desenvolvida na linguagem R (R Development Core Team, 2014), sendo que para a estima¸c˜ao dos parˆametros do modelo foi utilizada a fun¸c˜aooptim, considerando o m´etodo BFGS com primeiras deri-vadas anal´ıticas. Para os testes Wald e escore foi considerada a informa¸c˜ao observada, j´a que a informa¸c˜ao de Fisher nesse modelo ´e imposs´ıvel de ser obtida, conforme j´a descrito no Cap´ıtulo 2. A matriz de informa¸c˜ao observada foi obtida atrav´es da aproxi-ma¸c˜oes num´ericas no R, fornecida pelo optim. Ainda, a parametriza¸c˜ao utilizada noR se d´a em termos do logar´ıtmo deT, dessa forma utiliza-se a distribui¸c˜ao valor extremo apresentada em 2.1.3 (CARVALHO et al., 2011).
Da mesma forma que em Carneiro (2012), a matriz das vari´aveis regressoras ´e gerada a partir de distribui¸c˜oes de Bernoulli(pb), compb em torno de 0,5, e considerada constante durante todas as r´eplicas de Monte Carlo. Nas simula¸c˜oes, a fim de avaliar o impacto do aumento do n´umero de parˆametros de perturba¸c˜ao, foram consideradas quatro (p = 4) e seis (p = 6) covari´aveis. Para p = 4, foram geradas para cada i = 1,2, . . . , n, xi1, xi2, xi3 e xi4 de forma independente, de distribui¸c˜oes de Bernoulli, com probabilidades de sucesso (pb) 0,49, 0,5, 0,51 e 0,52, respectivamente. Analogamente, para p= 6, foram geradas xi1, xi2, xi3, xi4, xi5 e xi6 de distribui¸c˜oes de Bernoulli, com probabilidades de sucesso (pb) 0,48, 0,49, 0,5, 0,51, 0,52 e 0,53, respectivamente.
Os valores de Mi s˜ao gerados da distribui¸c˜ao Poisson com m´edia θi = exp(x⊤i β).
23
Os valores de β s˜ao fixados de tal forma que, combinados com a matriz das vari´aveis regressoras, a m´edia da fra¸c˜ao de cura seja em torno de 10% e 30%. Para os indiv´ıduos n˜ao imunes (Mi > 0) foi gerada uma amostra de tamanho mi (zik;k = 1, . . . mi) da distribui¸c˜ao Weibull(a,b), em que a = 2 e b = 4. Os tempos de falha s˜ao obtidos por ti = min{zik;k = 1, . . . mi}. As censuras s˜ao geradas aleatoriamente de uma distribui¸c˜ao uniforme, U(0,u), sendo que o valor de u afeta inversamente a propor¸c˜ao de censuras da amostra. Ap´os gerada a censuraci, os tempos observados s˜ao dados por
yi = min{ti, ci}. A cada tempo observado ´e associado o indicador de falha, δi = 1 se
ti ≤ci eδi = 0 seti > ci . QuandoMi = 0, o tempo observado recebe max{ci, . . . , cn}, (valor suficientemente grande), e o indicador de falhas recebe zero. Os valores fixados nas simula¸c˜oes paraβ e u s˜ao descritos no Apˆendice B.
Assim como Fonseca, Valen¸ca e Bolfarine (2013) e Carneiro (2012), para definir o percentual de censuras entre os curados e a propor¸c˜ao de censuras com rela¸c˜ao ao total de indiv´ıduos suscet´ıveis ao evento, consideramos os seguintes eventos: A = curados,
Ac = n˜ao curados, C = censurados ou imunes. A partir desses eventos definimos a propor¸c˜ao de censuras dentre os n˜ao curados, denotada porpc1, dada a seguir:
pc1 =
(C∩Ac) #Ac ,
em que # denota a quantidade de indiv´ıduos no conjunto. A propor¸c˜ao de censurados ou imunes ´e dada por
pc2 =
#C
#(A∪Ac).
Em aplica¸c˜oes a dados reais a quantidadepc2 ´e vista como o percentual de censuras da popula¸c˜ao. Ainda em Fonseca, Valen¸ca e Bolfarine (2013) ´e apresentada uma rela¸c˜ao entre pc1 e pc2, que ´e dada por
pc2 =pc1(1−p0) +p0,
em quep0 representa a propor¸c˜ao de imunes.
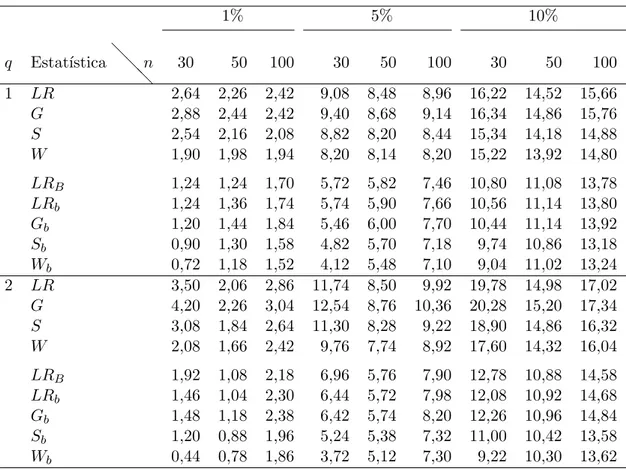
Os resultados para a avalia¸c˜ao da taxa de rejei¸c˜ao nula dos testes est˜ao apresentados nas Tabelas 4.1 a 4.6. Foi considerado o modelo de tempo de promo¸c˜ao Weibull, n´ıveis nominais iguais a 1%, 5% e 10%. As trˆes combina¸c˜oes dep0 epc1 usadas para as simu-la¸c˜oes implicam propor¸c˜oes de censuras na popula¸c˜ao (pc2) iguais a 19%, 37%, 51%. Para as Tabelas 4.1 e 4.4, a propor¸c˜ao de imunes ou fra¸c˜ao de curados fixada foi de
24
Tabela 4.1: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 4, 10% de fra¸c˜ao de cura e 10% censura, (pc2 = 19%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 1,84 1,58 1,30 7,20 7,02 6,16 13,70 12,88 11,20
G 1,90 1,84 1,30 7,28 7,28 6,18 13,50 13,26 11,26
S 2,04 1,18 1,34 7,56 6,36 6,12 13,76 12,28 11,30
W 1,56 1,12 1,28 6,92 6,16 6,06 13,30 12,18 11,14
LRB 0,86 0,90 1,00 4,42 5,08 5,40 9,10 10,04 9,86
LRb 0,94 1,02 1,22 4,46 5,18 5,44 9,02 10,24 9,92
Gb 0,98 1,00 1,16 4,52 5,14 5,46 9,02 10,14 9,92
Sb 0,82 0,98 1,14 4,40 4,84 5,46 8,74 10,26 9,96
Wb 0,90 0,94 1,14 4,46 4,82 5,46 8,92 10,30 9,92
2 LR 2,38 1,82 1,44 8,74 7,42 6,68 15,40 13,54 11,76
G 2,56 2,16 1,56 8,94 7,58 6,86 15,36 13,96 11,92
S 2,54 1,70 1,46 8,98 7,32 6,58 15,76 13,30 11,68
W 1,90 1,52 1,30 8,22 6,94 6,38 14,86 12,74 11,54
LRB 0,94 1,18 0,92 5,34 5,38 5,34 10,16 10,40 10,12
LRb 1,06 1,22 1,04 5,38 5,46 5,40 10,08 10,42 10,14
Gb 1,04 1,28 1,10 5,30 5,40 5,44 10,08 10,60 10,12
Sb 0,96 1,06 1,16 5,12 5,42 5,34 9,78 10,62 10,28
Wb 0,96 1,16 1,18 5,28 5,46 5,42 9,90 10,58 10,28
pc2 = 19% (percentual de censuras da popula¸c˜ao). Nas Tabelas 4.2 e 4.5 foram fixados
p0 = 10% e pc1 = 30%, (pc2 = 37%). Ainda, para as Tabelas 4.3 e 4.6, foram fixados
p0 = 30% e pc1 = 30%, (pc2 = 51%).
25
taxas de rejei¸c˜ao nula para 13,54%, 13,96%, 13,30% e 12,74%, respectivamente, LR,
G, S e W. J´a os testes baseados nas corre¸c˜oes propostas mant´em as taxas de rejei¸c˜ao pr´oximas aos n´ıveis nominais, apresentando no mesmo cen´ario, taxas de rejei¸c˜ao iguais a 10,40%, 10,42%, 10,60%, 10,62% e 10,58%, respectivamente, para LRB, LRb, Gb, Sb eWb.
A Figura 4.1 apresenta os gr´aficos QQ-plot (quantil exato versus quantil assint´o-tico), considerando os diferentes tamanhos amostrais, q = 1 e a mesma configura¸c˜ao de censura da Tabela 4.1. Observando a Figura 4.1, nota-se que a estat´ıstica corrigida por Bartlettbootstrap apresenta distribui¸c˜ao mais pr´oxima da distribui¸c˜ao nula de re-ferˆencia, χ2
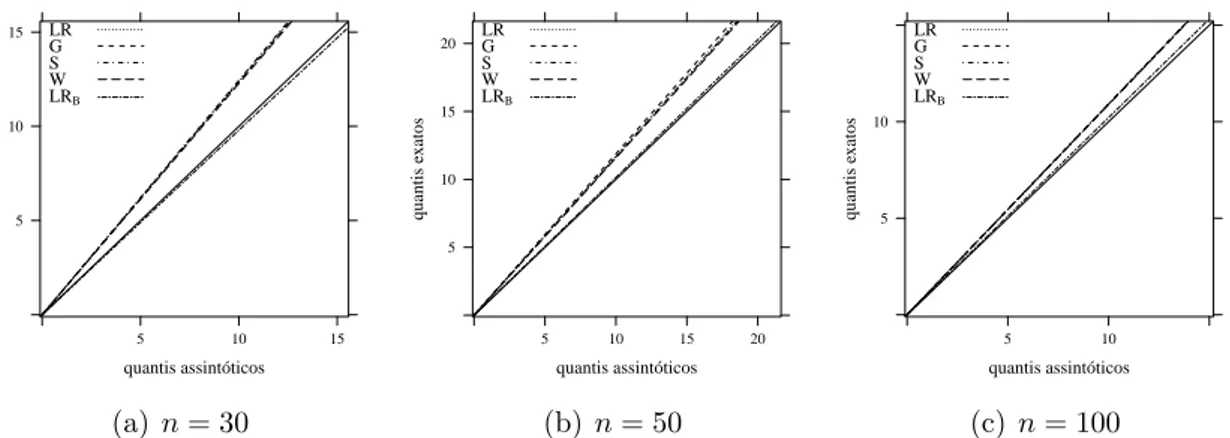
q. J´a as estat´ısticas usuais, para o tamanho amostral n = 30, apresentam distribui¸c˜oes muito pr´oximas entre si, mas longe da distribui¸c˜ao nula de referˆencia, quando comparadas com LRB. A medida que o tamanho amostral aumenta as distri-bui¸c˜oes das estat´ısticas usuais tornam-se mais pr´oximas `a de referˆencia.
quantis assintóticos quantis e xatos 5 10 15
5 10 15
LR G S W LRB
(a) n= 30
quantis assintóticos quantis e xatos 5 10 15 20
5 10 15 20
LR G S W LRB
(b)n= 50
quantis assintóticos quantis e xatos 5 10 5 10 LR G S W LRB
(c) n= 100
Figura 4.1: Gr´afico quantil-quantil considerando 10% de fra¸c˜ao de cura e 10% censura,
q= 1 e diferentes tamanhos amostrais.
Na Tabela 4.2 s˜ao apresentadas as taxas de rejei¸c˜ao nula para o cen´ario com per-centual de censura na popula¸c˜ao de 37%, com 4 covari´aveis, considerando q = 1, 2. Verifica-se, assim como na Tabela 4.1, que os testes baseados nas corre¸c˜oes propostas apresentam menores distor¸c˜oes de tamanho quando comparadas `as usuais. Por exem-plo, paran= 30, n´ıvel de 10%, tem-se taxas de rejei¸c˜ao nula muito pr´oximas aos n´ıveis nominais (10,16%, 10,14%, 10,04%, 9,92% e 9,98%, respectivamente para LRB, LRb,
Gb, Sb e Wb). J´a as estat´ısticas usuais se mostram mais liberais, apresentando taxas de rejei¸c˜ao de 15,36%, 15,10%, 15,32% e 14,66%, respectivamente, para LR, G, S e
26
Tabela 4.2: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 4, 10% de fra¸c˜ao de cura e 30% censura, (pc2 = 37%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 2,72 2,82 1,42 8,88 10,10 6,28 15,36 17,32 12,24
G 2,74 3,06 1,46 8,86 10,32 6,30 15,10 17,30 12,32
S 2,88 2,40 1,38 8,92 8,82 6,08 15,32 16,12 11,90
W 2,22 1,96 1,30 8,16 8,72 6,04 14,66 16,26 11,94
LRB 1,06 1,14 0,92 5,22 5,66 4,96 10,16 10,90 10,28
LRb 1,22 1,22 1,02 5,14 5,84 4,94 10,14 11,08 10,20
Gb 1,12 1,00 0,96 5,22 5,62 4,92 10,04 10,70 10,08
Sb 1,22 1,30 1,00 5,08 5,90 4,72 9,92 10,78 10,02
Wb 1,22 1,22 1,04 5,16 5,78 4,86 9,98 10,90 10,10
2 LR 2,30 2,66 3,02 8,98 10,36 10,78 16,70 17,52 18,00
G 2,44 3,00 3,18 9,32 10,76 11,26 16,62 17,64 17,74
S 2,58 3,24 3,54 9,44 10,34 10,52 16,66 17,00 17,92
W 1,78 1,86 2,64 7,76 8,84 9,90 15,72 16,06 17,36
LRB 0,68 0,98 1,26 4,04 5,18 5,66 8,96 11,34 11,00
LRb 0,66 1,26 1,64 4,08 5,50 5,92 9,18 11,46 11,38
Gb 0,64 1,16 1,48 4,04 5,42 5,76 9,22 11,20 11,18
Sb 0,80 1,44 1,74 4,28 6,12 6,24 9,32 11,76 11,74
Wb 0,76 1,20 1,50 4,20 5,52 5,96 9,08 11,60 11,50
acarreta em aumento das distor¸c˜oes dos testes usuais. Ainda, `a medida que o tamanho amostral aumenta, os resultados dos testes usuais s˜ao ainda mais distorcidos (q = 2). Esse resultado n˜ao ´e esperado, no entanto, est´a de acordo com os resultados obtidos por Carneiro (2012), no qual ´e considerado o mesmo modelo e configura¸c˜oes aqui apresen-tadas. Esse comportamento at´ıpico pode ser justificado, possivelmente, por problemas num´ericos, que em amostras maiores ocorrem com maior frequˆencia. Os testes basea-dos nas corre¸c˜oes propostas mesmo quando q = 2 apresentam bom desempenho, com as menores distor¸c˜oes.
27
Tabela 4.3: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 4, 30% de fra¸c˜ao de cura e 30% censura, (pc2 = 51%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 2,20 2,24 1,54 8,36 8,56 6,20 14,16 14,98 11,24
G 2,40 2,82 1,62 8,34 9,42 6,40 14,30 15,86 11,48
S 2,18 1,62 1,28 8,24 7,14 5,90 14,12 13,46 11,14
W 1,32 1,46 1,16 7,28 6,76 5,70 13,20 13,48 10,90
LRB 0,90 0,98 1,06 4,82 5,14 5,00 9,46 10,12 9,96
LRb 0,80 1,22 1,22 4,90 5,42 5,14 9,48 10,24 10,06
Gb 0,76 1,10 1,16 4,86 5,28 5,06 9,26 10,10 9,98
Sb 0,84 1,14 1,14 4,88 5,16 5,14 9,66 9,98 9,90
Wb 1,04 1,18 1,14 5,18 5,22 5,18 10,00 10,14 9,88
LR 2,48 2,26 2,32 9,12 9,04 9,88 15,12 16,82 17,06
G 2,92 3,04 2,98 9,68 10,54 10,82 15,50 18,18 18,04
S 2,12 1,40 1,64 8,06 6,92 8,34 14,40 13,68 15,14
W 1,30 0,90 1,42 6,90 6,48 8,06 13,54 12,94 14,88
LRB 0,78 0,82 1,08 4,66 5,10 5,70 9,98 10,20 11,70
LRb 0,82 1,04 1,28 4,78 5,24 5,92 9,94 10,42 12,04
Gb 0,72 1,08 1,20 4,44 4,96 5,78 9,52 9,98 11,86
Sb 0,92 1,02 1,28 4,64 5,32 5,70 9,72 10,20 11,70
Wb 1,04 1,00 1,28 5,14 5,48 5,76 10,16 10,50 11,78
8,56%, 9,42%, 7,14% e 6,76%. As respectivas corre¸c˜oes propostas apresentam taxas de rejei¸c˜ao nula de 5,14%, 5,42%, 5,28%, 5,16% e 5,22%. Ou seja, as corre¸c˜oes propostas apresentam menores distor¸c˜oes quando comparadas aos testes usuais, com taxas de rejei¸c˜ao pr´oximas aos n´ıveis nominais. Ao aumentar o n´umero de restri¸c˜oes (q= 2), os desempenhos dos testes em geral apresentam resultados ainda mais distorcidos quando comparados a q = 1. Ainda cabe destacar que o aumento do tamanho amostral n˜ao melhora o desempenho dos testes quando considerado q = 2. As corre¸c˜oes propostas mesmo com o aumento do n´umero de restri¸c˜oes apresentam as taxas de rejei¸c˜ao nula pr´oximas aos n´ıveis nominais.
28
Tabela 4.4: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 6, 10% de fra¸c˜ao de cura e 10% censura, (pc2 = 19%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 2,78 2,20 1,50 9,00 7,80 6,68 15,54 13,78 12,62
G 2,88 2,22 1,50 9,24 7,90 6,76 15,68 13,82 12,68
S 2,50 2,22 1,46 8,84 7,90 6,52 15,48 13,66 12,70
W 2,32 2,12 1,42 8,62 7,78 6,40 15,28 13,52 12,58
LRB 1,58 1,32 1,10 5,48 5,72 5,40 10,86 10,40 10,90
LRb 1,46 1,36 1,24 5,28 5,76 5,52 10,36 10,56 11,02
Bb 1,22 1,38 1,20 5,08 5,74 5,62 10,46 10,60 11,02
Sb 1,20 1,14 0,96 4,90 5,50 5,44 9,84 10,44 11,00
Wb 0,80 1,08 0,94 4,16 5,46 5,40 9,30 10,56 11,00
2 LR 3,04 1,90 2,04 9,94 7,94 7,30 17,10 13,86 12,98
G 3,40 2,00 2,10 10,36 7,94 7,54 17,50 13,96 13,08
S 2,78 2,04 1,92 9,50 8,02 7,32 16,64 13,80 12,82
W 2,20 1,78 1,80 8,86 7,76 7,10 16,02 13,64 12,62
LRB 1,80 1,36 1,36 6,80 5,84 6,30 12,32 10,70 11,48
LRb 1,44 1,22 1,44 5,92 5,58 6,10 11,14 10,28 11,40
Bb 1,30 1,18 1,48 5,82 5,48 6,18 10,70 10,12 11,44
Sb 0,86 1,02 1,34 4,84 5,24 5,68 9,14 9,46 10,74
Wb 0,38 0,80 1,26 3,58 4,78 5,64 7,82 9,48 10,88
de 37%. Em rela¸c˜ao `as corre¸c˜oes propostas, os resultados indicam bom desempenho na maioria das configura¸c˜oes, com distor¸c˜oes menores que os testes usuais. Durante o estudo de simula¸c˜ao verificou-se o percentual m´edio de censura nas amostrasbootstrap, sendo poss´ıvel constatar que as corre¸c˜oes apresentam maiores distor¸c˜oes quando o per-centual m´edio de censura nas amostrasbootstrap n˜ao foi o mesmo da amostra original. Dessa forma, salienta-se a importˆancia de, em aplica¸c˜oes, preservar a quantidade de censura da amostra original.
pa-29
Tabela 4.5: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 6, 10% de fra¸c˜ao de cura e 30% censura, (pc2 = 37%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 2,64 2,26 2,42 9,08 8,48 8,96 16,22 14,52 15,66
G 2,88 2,44 2,42 9,40 8,68 9,14 16,34 14,86 15,76
S 2,54 2,16 2,08 8,82 8,20 8,44 15,34 14,18 14,88
W 1,90 1,98 1,94 8,20 8,14 8,20 15,22 13,92 14,80
LRB 1,24 1,24 1,70 5,72 5,82 7,46 10,80 11,08 13,78
LRb 1,24 1,36 1,74 5,74 5,90 7,66 10,56 11,14 13,80
Gb 1,20 1,44 1,84 5,46 6,00 7,70 10,44 11,14 13,92
Sb 0,90 1,30 1,58 4,82 5,70 7,18 9,74 10,86 13,18
Wb 0,72 1,18 1,52 4,12 5,48 7,10 9,04 11,02 13,24
2 LR 3,50 2,06 2,86 11,74 8,50 9,92 19,78 14,98 17,02
G 4,20 2,26 3,04 12,54 8,76 10,36 20,28 15,20 17,34
S 3,08 1,84 2,64 11,30 8,28 9,22 18,90 14,86 16,32
W 2,08 1,66 2,42 9,76 7,74 8,92 17,60 14,32 16,04
LRB 1,92 1,08 2,18 6,96 5,76 7,90 12,78 10,88 14,58
LRb 1,46 1,04 2,30 6,44 5,72 7,98 12,08 10,92 14,68
Gb 1,48 1,18 2,38 6,42 5,74 8,20 12,26 10,96 14,84
Sb 1,20 0,88 1,96 5,24 5,38 7,32 11,00 10,42 13,58
Wb 0,44 0,78 1,86 3,72 5,12 7,30 9,22 10,30 13,62
rˆametros verificou-se que as distor¸c˜oes dos testes usuais s˜ao ainda maiores. Em rela¸c˜ao `as corre¸c˜oes propostas, foi poss´ıvel verificar que todas possuem bons resultados, em todos os cen´arios considerados, com pequena diferen¸ca do n´ıvel nominal quando essa ocorre. Dessa forma, qualquer vers˜ao corrigida ´e recomend´avel. Por vantagens compu-tacionais poderia ser considerada a estat´ıstica da raz˜ao de verossimilhan¸cas corrigida por Bartlettbootstrap (LRB).
30
Tabela 4.6: Taxas de rejei¸c˜ao nula (%) para H0 :β1 =. . . =βq = 0, comp = 6, 30% de fra¸c˜ao de cura e 30% censura, (pc2 = 51%), considerando os diferentes tamanhos amostrais e n´ıveis nominais.
1% 5% 10%
q Estat´ıstica❅❅
❅n 30 50 100 30 50 100 30 50 100
1 LR 2,72 2,00 2,24 9,52 8,22 8,08 16,14 14,34 14,44
G 3,16 2,08 2,54 9,80 8,44 8,56 16,32 14,38 14,80
S 2,60 1,70 1,88 8,68 7,74 7,52 15,34 14,04 13,90
W 2,06 1,50 1,70 8,18 7,62 7,38 15,10 14,00 13,68
LRB 1,10 0,98 1,62 5,28 5,40 6,84 10,26 11,30 12,70
LRb 1,08 1,16 1,72 5,34 5,58 6,96 10,28 11,20 12,86
Gb 1,12 1,12 1,92 5,18 5,56 7,20 10,40 11,16 12,94
Sb 0,90 1,04 1,50 5,02 5,18 6,52 9,64 10,94 12,46
Wb 0,82 0,98 1,44 5,10 5,24 6,50 9,72 11,08 12,34
2 LR 3,26 2,50 1,84 11,38 8,42 8,06 18,72 14,74 14,40
G 4,00 2,68 2,20 12,50 8,66 8,60 19,72 14,80 14,98
S 2,44 2,24 1,58 9,98 8,10 7,12 16,76 14,18 13,46
W 1,74 1,84 1,38 8,56 7,60 6,86 15,94 13,86 13,20
LRB 1,20 1,18 1,46 5,36 5,88 6,50 11,14 10,30 12,20
LRb 1,04 1,28 1,52 5,12 5,78 6,60 10,94 10,40 12,34
Gb 1,20 1,34 1,62 5,36 5,76 6,84 11,06 10,50 12,54
Sb 0,92 1,18 1,18 4,46 5,56 5,96 9,94 10,18 11,70
Wb 0,94 1,18 1,20 4,38 5,52 5,80 9,66 10,22 11,62
Tabela 4.7: Taxas de rejei¸c˜ao n˜ao nula (%) para H0 :β1 = 0 eH1 :β1 =δ, com p= 4, considerando o tamanho amostral n= 50 e n´ıvel nominal 5%.
Estat´ıstica❅❅
❅δ −1,5 −1,0 −0,5 0,5 1,0 1,5
LR 95,86 78,90 33,72 12,88 62,80 96,50
G 95,56 77,44 33,18 11,00 58,76 95,38
S 94,22 75,74 31,56 16,90 69,36 97,56
W 95,56 78,20 32,96 16,74 69,12 97,48
LRB 96,30 80,42 35,96 14,46 65,80 97,14
LRb 96,28 80,74 36,40 14,66 66,10 97,18
Gb 96,10 80,26 36,30 12,96 63,16 96,64
Sb 94,68 78,02 33,92 18,28 71,64 97,98
31
Cap´ıtulo 5
Aplica¸c˜
ao
Este cap´ıtulo apresenta uma aplica¸c˜ao a dados reais dos testes apresentados e das corre¸c˜oes propostas. Os dados utilizados correspondem a um estudo realizado pela cooperativa de oncologia Ocidental, publicado por Edmonson et al. (1979), em que um ensaio aleatorizado foi feito para comparar dois tratamentos para cˆancer de ov´ario em 26 pacientes. Estes dados, cl´assicos na literatura em an´alise de sobrevivˆencia, est˜ao dispon´ıveis com o nome ovarian no pacote survival (THERNEAU; GRAMBSCH, 2000) no R (R Development Core Team, 2014).
A base de dados apresenta o tempo (em dias) das pacientes at´e a morte ou censura, o indicador da censura, a idade, a presen¸ca ou n˜ao de doen¸ca residual, o tipo de tratamento, e uma medida de performance, em que 1 ´e a melhor.
tempo (em dias)
sobre
viv
ência
0 200 400 600 800 1200
0,0
0,2
0,4
0,6
0,8
1,0
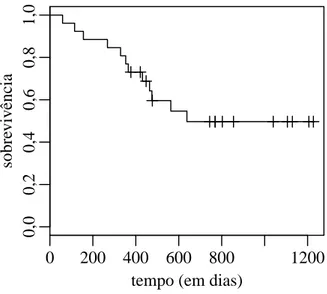
Figura 5.1: Kaplan-Meier dos dados referente ao tempo at´e a morte de pacientes com cˆancer de ov´ario.
33
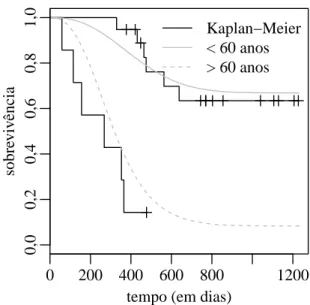
A Figura 5.1 apresenta o gr´afico de Kaplan-Meier, que estima a curva de sobre-vivˆencia com base nestes dados. Pode-se notar que h´a um indicativo da presen¸ca de imunes nos dados, atrav´es da alta presen¸ca de censura `a direita no fim do estudo e pelo Kaplan-Meier, que se estabilizou em um valor em torno de 0,53. Nessa situa¸c˜ao os modelos com fra¸c˜ao de cura s˜ao adequados.
Em rela¸c˜ao `as caracter´ısticas dos indiv´ıduos, foram consideradas 4 covari´aveis (fa-tores): idade (x1 = −1 se a paciente tem menos de 60 anos, e 1 em caso contr´ario); doen¸ca residual (x2 = 1 se a paciente tem presen¸ca de doen¸ca residual, 0 em caso contr´ario); tipo de tratamento (x3 = 1 para o tratamento do grupo 1, 0 para o grupo 2) e medida de performance (x4 = 1 para a melhor performance, e 0 para a pior).
Dessa forma, o modelo tempo de promo¸c˜ao Weibull foi ajustado, com o objetivo de avaliar o efeito das covari´aveis consideradas no estudo sobre a fra¸c˜ao de cura. As covari´aveis foram inclu´ıdas no modelo atrav´es do parˆametro θ, por meio da rela¸c˜ao
θi = exp(x⊤i β).
Inicialmente foram consideradas todas as covari´aveis no modelo, associadas `a fra¸c˜ao de cura, dada por
p0i = exp[−exp(β1x1i+β2x2i+β3x3i+β4x4i)].
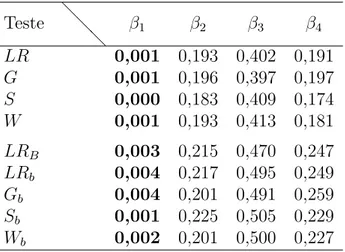
Ap´os a estima¸c˜ao dos parˆametros foram realizados testes de hip´oteses para verificar a significˆancia dos parˆametros associados a cada covari´avel. As hip´oteses consideradas foram
H0 :βj = 0 versus H1 :βj 6= 0, (5.1)
para j = 1, . . . ,4. Da mesma forma que nas simula¸c˜oes, foram considerados p = 4 e
q= 1, sendo 5 o n´umero de parˆametros de perturba¸c˜ao em todos os testes realizados. Os testes foram realizados considerando o n´ıvel de significˆancia de 5%, sendo a hi-p´otese nula rejeitada se p-valor < 0,05. Na Tabela 5.1 s˜ao apresentados os p-valores associados aos testes de hip´oteses realizados considerando as estat´ısticas usuais, corri-gida (LRB) e os testes corrigidos. S˜ao destacados em negrito os p-valores que rejeitam a hip´otese nula.