Universidade Técnica de Lisboa
Instituto Superior de Economia e Gestão
Mestrado em Ciências Actuariais
Aplicação da Teoria de Valores Extremos
à Actividade Seguradora
Jeferino Manuel dos Santos
Orientação
Prof. Doutora Maria de Lourdes Caraças Centeno
Júri
Prof. Doutora Maria de Lourdes Caraças Centeno
Prof. Doutora Maria Isabel Fraga Alves
Prof. Doutor Alfredo Duarte Egídio dos Reis
R
ESUMOO objectivo principal deste trabalho é realçar a importância da Teoria de Valores
Extremos na actividade seguradora. São apresentados de uma forma sucinta alguns dos
principais resultados ligados a esta teoria. São apresentadas algumas estatísticas que
possibilitam a simplificação do processo de reconhecimento de dados de cauda pesada.
A modelação da cauda é um assunto de particular interesse, são apresentados dois
métodos de modelação da cauda, um pelo ajustamento de uma distribuição de Pareto
Generalizada, outro pela aplicação de um método semi-paramétrico adaptativo. No fim,
os resultados obtidos por cada um dos modelos são integrados como módulo num
modelo de solvência.
Palavras chave: Teoria de Valores Extremos, dados de cauda pesada, Distribuição de Pareto Generalizada, estimação semi-paramétrica adaptativa, indemnizações agregadas,
A
BSTRACTThe main purpose of this dissertation is to enhance the importance of Extreme Value
Theory in the insurance sector. A short introduction to the main results inherent in this
theory is presented. Also, a set of statistics to simplify the recognition process of heavy
tailed data is provided. Tail modelling is a subject of particular interest in this
dissertation, two approaches are presented, one by fitting a Generalized Pareto
Distribution, other by modelling by means of a semi-parametric adaptive method. In the
last part, the results of these approaches are integrated as a module in a broader
solvency model.
Índice
Prefácio 9
Agradecimentos 11
Capítulo 1 – Teoria de Valores Extremos 13
1.1. Alguns Resultados Preliminares 13
1.2. Caracterização dos Domínio de Atracção 16
1.3. Distribuição de Pareto Generalizada 27
Capítulo 2 – Análise e Apresentação dos Dados 31
Capítulo 3 – Modelação dos dados 37
3.1 Modelação pela Distribuição de Pareto Generalizada 37
3.2 Abordagem semi paramétrica 44
3.2.1 Estimação Sob Condição de Domínio de Atracção para Máximos 44
3.2.2 Determinação do Nível Óptimo de 48 k
3.3 Discussão de diferentes métodos 58
Capítulo 4 – Teste de Solvência 61
4.1 Teste da Solvência 61
4.2 Modelação das Indemnizações Agregadas 64
4.3 Discussão 72
Capítulo 5 – Conclusão 77
Anexo I 79
Lista de Figuras
Figura 1.1.1 – Funções de densidade das formas possíveis de H
()
. , com α =1 para a Fréchet e para a Weibull. [p. 16]Figura 1.3.1 - Funções de densidade das formas possíveis de G
()
. , para diferentesvalores deξ, com β =1 e ν =0. [p. 28]
Figura 2.1 – Comportamento dos sinistros extremos verificados entre 1993 e 2001. [p. 32]
Figura 2.2 – No gráfico da esquerda estão representadas a distribuição empírica e a distribuição de Pareto. O gráfico da direita tem a escala ampliada na cauda. [p. 33]
Figura 2.3 – Comparação com os quantis da distribuição de Pareto. [p. 33]
Figura 2.4 - Função de excesso médio empírico. [p. 34]
Figura 2.5 - Rn
( )
p para varios valores de p. [p. 35]Figura 3.1.1 – Valores de , da DPG, para diferentes níveis de . [p. 40] ξˆ u
Figura 3.1.2 – Função de distribuição ajustada aos excessos com u=550.000
(à esquerda) e u =600.000 (à direita). [p. 41]
Figura 3.1.3 – Função de distribuição ajustada aos excessos com u=550.000
Figura 3.1.4 – Comparação dos quantis dos excessos com as distribuições ajustadas
com u =550.000 (à esquerda) e u=600.000 (à direita). [p. 42]
Figura 3.1.5 – No gráfico da esquerda estão representadas a distribuição empírica e a
distribuição ajustada com u =550.000 e u=600.000. O gráfico da direita tem a escala
ampliada na cauda. [p. 43]
Figura 3.1.6 – Comparação dos quantis com os da distribuição ajustada com
e u . [p. 44]
000 . 550 =
u =600.000
Figura 3.2.1 – Horror Hill plot. [p. 49]
Figura 3.2.2 – Resultados para diferentes valores de n1 dado ξn,aux =0,765. [p. 53]
Figura 3.2.3 – Resultados para diferentes valores de n1 dado diferentes valores de
aux n,
ξ . [p. 54]
Figura 3.2.4 – Resultados para diferentes valores de , segundo a abordagem de Danielsson. [p. 56]
1
n
Figura 3.2.5 – No gráfico da esquerda pode-se observar a distribuição empírica e a distribuição ajustada, segunda a abordagem de Danielsson. O gráfico da direita tem a
escala ampliada na cauda. [p. 57]
Figura 3.2.6 – Comparação dos quantis com os da distribuição ajustada segundo a abordagem de Danielsson. [p. 58]
Figura 3.3.2 –Comparação dos quantis com os da distribuição ajustada em 3.1 com e a distribuição ajustada segundo a abordagem de Danielsson. [p. 60]
000 . 550 =
u
Figura 4.1.1 – Economic Capital e a Solvência em termos esquemáticos. [p. 62]
Figura 4.1.2 – Função de Densidade (à esquerda) e Função de Distribuição (à direita) da variação do Economic Capital. [p. 63]
Figura 4.2.1 – Rn
( )
p1 das indemnizações da classe A1 do Modelo 1 e Modelo 2. [p. 68]
Figura 4.2.2 – Função de distribuição condicionada empírica das indemnizações da
classe A1 do Modelo 1 e Modelo 2. [p. 68]
Figura 4.2.3 – Funções de densidade (à esquerda) e de distribuição (à direita) de S( )1 ,
, e . [p. 70]
( )2
S Sˆ( )1 Sˆ( )2
Figura 4.2.4 – Comparação dos quantis estimados de S( )1 , S( )2 ,Sˆ( )1 e Sˆ( )2 . [p. 71]
Figura 4.2.5 – Comparação dos quantis das indemnizações agregadas retidas. [p. 72]
Figura 4.3.1 – Comparação dos quantis dos valores simulados de e de )e os quantis dos métodos aproximados. [p. 75]
( )1
P
REFÁCIOPretende-se com o presente trabalho analisar as indemnizações relacionadas com
acontecimentos extremos. São de particular interesse os acontecimentos catastróficos
que conduzem a indemnizações de elevado montante, não se reduzindo a indemnizações
associadas a fenómenos naturais ou desastres causados pelo Homem, mas também a
indemnizações invulgares de acordo com o risco em causa.
Uma modelação adequada das indemnizações extremas é essencial para a actividade de
uma Companhia de Seguros, dado que isso permitiria:
- definir um nível apropriado do prémio;
- modelar adequadamente o resseguro;
- determinar o nível do capital necessário por forma a minimizar a
probabilidade de insolvência.
Uma modelação possível da severidade é o ajustamento de uma função de distribuição
às indemnizações individuais, como em Hogg et al.(1984). Porém, nessa abordagem, as
distribuição escolhida e no valor do parâmetro estimado, podendo conduzir a uma sub
ou sobre estimação da cauda.
Em muitos casos, dependendo do risco em causa, é importante que se modele
isoladamente a cauda da distribuição da severidade por forma a projectar, com maior
precisão, os quantis elevados.
Um dos objectivos principais desta dissertação consiste em aplicar algumas das recentes
abordagens associados à Teoria de Valores Extremos, por forma a obter estimadores
adequados para a cauda.
No Capítulo 1 são apresentados, de forma sumária, alguns dos principais resultados da
Teoria de Valores Extremos.
Os dados, objecto de análise nesta dissertação, são apresentados e o seu comportamento
estudado no Capítulo 2.
No Capítulo 3 são abordados dois estimadores da cauda. Um baseado numa abordagem
paramétrica, o outro, numa abordagem semi-paramétrica adaptativa.
Na primeira parte do Capítulo 4 são discutidas algumas ideias sobre os testes de
solvência. Na segunda parte, é modelado uma parte de um modelo de solvência
aplicando os resultados obtidos no Capítulo 3, nomeadamente, a parte relacionada com
as indemnizações agregadas e as indemnizações agregadas retidas.
A
GRADECIMENTOSÀ Prof. Doutora Maria de Lourdes Centeno, do Instituto Superior de Economia e
Gestão. A sua orientação e sugestões em muito contribuíram para uma melhor
exposição de ideias e conceitos.
À Ms. Ulrike Leyherr, do Allianz Group. Pelo seu contributo no fornecimento de dados
que foram objecto de análise.
À Prof. Doutora Ivette Gomes, da Faculdade de Ciências da Universidade de Lisboa
pelos textos gentilmente facultados.
À Allianz Portugal, pelo estimulo e facilidades concedidos.
À Dra. Teresa Brantuas, responsável pela Direcção de Actuariado da Allianz Portugal, e
a todos os membros que compõem a sua equipa de trabalho. O seu apoio e incentivo
foram importantes.
A todos aqueles que, dedicadamente, comentaram, criticaram e sugeriram ideias e
opiniões.
C
APÍTULO1
Teoria de Valores Extremos
Neste capítulo são apresentados alguns dos principais resultados da Teoria de Valores
Extremos. Os resultados mais importantes, nomeadamente, o Teorema de Fisher –
Tippett e as três distribuições de extremos são expostos na Secção 1.1 deste capítulo. Na
Secção 1.2, são caracterizados os domínios de atracção. Seguidamente, na Secção 1.3.
são discutidas algumas das propriedades da Distribuição de Pareto Generalizada.
1.1. Alguns Resultados Preliminares
Seja uma sucessão de v.a. i.i.d. com função de distribuição . Seja o
máximo de uma amostra aleatória de dimensão n, i.e.,
,... , 2
1 X
X F Mn
(
, ,...,)
, 1max 1 2 ≥
= X X X n
Mn n .
Os resultados que se apresentam nos próximos parágrafos têm a ver essencialmente com
o máximo da amostra, na medida em que, por um lado, o mínimo assume uma menor
importância na actividade seguradora, por outro, a conversão dos resultados na maior
(
X ,X ,...,Xn)
=−max(
−X ,−X ,...,−Xn)
min 1 2 1 2 .
A função de distribuição (f.d.) exacta de Mné Fn
( )
x , visto que[
]
[
]
=[
≤]
=( )
∈ℜ ∈ℵ
≤ =
≤
∏
= =
n x
x F x X x
X x
M n
n i
i n
i i
n Prob Prob , ,
Prob
1 1
I
.Seja
( )
{
∈ℜ <}
≤∞=sup x :F x 1
xf ,
o limite superior do suporte da f.d. F . Então,
∞ → →
x n
Mn q.c. f, , (1.1)
dado que para x< xf
[
Mn ≤ x]
=Fn( )
x →0, n→∞Prob .
Enquanto, para x≥ xf
[
]
( )
1Prob Mn ≤x =Fn x = .
Por conseguinte, M , e, dado que, é não decrescente em relação a , a
convergência é quase certa.
f p
n →x Mn n
Contudo, este resultado não é muito expressivo. É importante conhecer a magnitude que
o máximo de uma amostra de dimensão pode assumir. Esta é a principal preocupação
da Teoria de Valores Extremos.
n
Um dos objectivos desta teoria consiste no estudo do comportamento dos máximos e
dos mínimos das amostras, procurando encontrar aproximações para as suas
semelhante ao da distribuição Normal no Teorema do Limite Central (TLC), como
aproximação da distribuição da média da amostra.
Para que tal aproximação seja possível, a expressão (1.1) sugere a necessidade em
transformar Mn numa variável X, tal que
(
M d)
X cd n n
n − =
−1
.
O Teorema de Fisher –Tippett, também conhecido por Teorema dos Tipos Extremais,
demonstrado em 1943 por Gnedenko, é um dos resultados mais importantes da Teoria
de Valores Extremos.
Teorema 1.1.1 (Teorema de Fisher –Tippett)
Seja uma sucessão de v.a. i.i.d. com função de distribuição e seja, para
, . ,... , 2 1 X X n
M =max
F
1 ≥
n
(
X1,X2,...,Xn)
Se existir uma sucessão de termos positivos, uma sucessão real de e uma f.d.
não degenerada tais que, para cada
n
c dn
()
.H x,
[
Mn ≤cnx+dn]
= Fn(
cnx+dn)
n →→∞ H( )
xProb ,
então as únicas formas possíveis de H
()
. são:Tipo I (Gumbel) H
( )
x ≡Λ( )
x =exp{ }
−e−x , x∈ℜ;Tipo II (Fréchet)
( )
( )
{
}
> > − > ≤ = Φ ≡ − 0 , 0 , exp 0 , 0 , 0 α α α α x x x x x H ;
Tipo III (Weibull)
( )
( )
{
( )
}
> ≥ > < − − = Ψ ≡ 0 , 0 1 0 , 0 , exp α α α α x x x x x H .
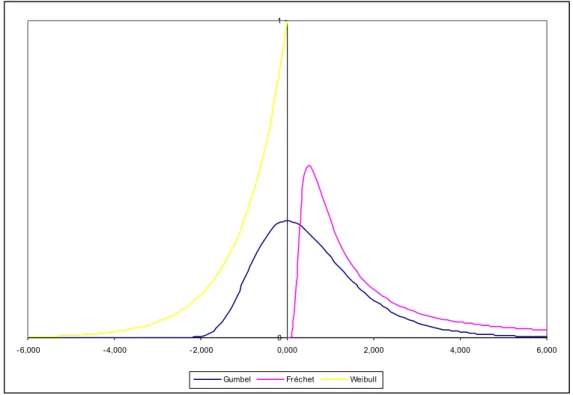
No gráfico seguinte estão representadas as funções de densidade para as diferentes
formas possíveis de H
()
. .0 1
- 6,000 -4,000 -2,000 0,000 2,000 4,000 6,000 Gumbel Fréchet Weibull
Figura 1.1.1 – Funções de densidade das formas possíveis de H
()
. , com α =1 para a Fréchet e para a Weibull.Embora os três modelos se distingam entre si, existe uma relação matemática, pois:
α α
α ⇔ Λ ⇔− Ψ
Φ −
~ ~
ln
~ X X 1
X .
1.2. Caracterização dos Domínio de Atracção
Um dos tópicos mais importantes em Teoria de Valores Extremos é a caracterização dos
domínios de atracção para máximos. Consiste no estabelecimento das condições
necessárias e suficientes de para pertencer a um determinado domínio de atracção e
definir os valores apropriados de c e .
F
Definição 1.2.1 (Domínio de Atracção para Máximos)
F pertence ao domínio de atracção de H para Máximos, e escreve-se , se
existir um par de sucessões
(
H DF∈
)
0
≥
n
c , dn ∈ℜ tal que
(
M d)
Hcn−1 n − n →d .
Teorema 1.2.2 (Domínio de Atracção para Máximos)
F pertence ao domínio de atracção de H para Máximos se e só se existir um par de
sucessões cn ≥0, dn ∈ℜ tal que
(
c x d)
H( )
x Fn n n
n ln
lim + =−
∞
→ .
O conceito da função de variação regular é essencial para a caracterização do domínio
de atracção das leis de Fréchet e de Weibull.
Definição 1.2.3. (Função de Variação Regular)
Uma função U mensurável, ℜ , diz-se que é de variação regular no infinito
com índice
+
+ →ℜ
ρ, e escreve-se U∈RVρ, se para x>0:
( )
( )
t xρ Utx U
t→∞ =
lim .
Uma função U
( )
x diz-se que é de variação regular em zero se U( )
1/x for de variação regular no infinito.Definição 1.2.4. (Função de Variação Lenta)
Uma função L
( )
x mensurável, ℜ+ →ℜ+, diz-se que é de variação lenta se para x>0:( )
( )
1lim =
∞
→ Lt
tx L
Que não é mais do que uma função de variação regular com índice zero.
Se U∈RVρ então U
( )
x /xρ ∈RV0. Definindo L( )
x =U( )
x /xρ torna-se possívelrepresentar . Desta forma, na maioria das situações, basta conhecer as
propriedades das funções de variação lenta para se conhecer as propriedades das
funções de variação regular.
( )
x =xρL( )
x UTeorema 1.2.5 (Propriedades das Funções de Variação Lenta)
Se L
( )
x é uma função de variação lenta:i. Para todo o γ >0, xγL
( )
x →∞ e x−γL( )
x →0, quando x→∞; ii. lnL( ) ( )
x /ln x →0, quando x→∞;iii. A função Lα
( )
x , α∈ℜ, é de variação lenta. Se L1()
. e L2()
. forem funções de variação lenta,iv. L1
()
. +L2()
. e L1() ()
. L2 . são funções de variação lenta;v. Se L2
()
. →∞ quando x→∞, então L1(
L2()
.)
é de variação lenta.Definição 1.2.6 (Função Inversa)
Seja H uma função não decrescente em ℜ. Define-se a função inversa (contínua à esquerda) de H como
( )
y{
s H( )
s y}
H← =inf ∈ℜ: ≥ .
Teorema 1.2.7 (Domínio de atracção de Φα)
Uma f.d. F pertence ao domínio de atracção para máximos de Φα, α >0, se e só se
( )
x x L( )
xF = −α , L∈RV0.
Se F∈D
(
Φα)
, entãoα
Φ →
− d
n n M
c 1 ,
onde cn =F←
(
1−n−1)
.Dem. in Resnick (1987), p. 54-57.
A lei de Fréchet é domínio de atracção de um conjunto de distribuições classificadas de
cauda pesada, no sentido de E
( )
Xδ =∞ para δ >α. A log-gamma, a Pareto ou a Burr,são alguns dos exemplos de distribuições que pertencem a este domínio de atracção.
Tratam-se de distribuições que possuem algum interesse na modelação do valor das
indemnizações em alguns ramos da actividade seguradora.
Teorema 1.2.8 (Domínio de atracção de Ψα)
Uma f.d. F pertence ao domínio de atracção para máximos deΨα, α >0, se e só se
∞ <
f
x e F
(
xf −x−1)
= x−αL( )
x , L∈RV0. Se F∈D(
Ψα)
, então(
−)
→Ψα− d
n n
n M d
c 1 ,
A lei de Weibull é domínio de atracção para máximos de algumas distribuições que têm
limitado o lado direito do suporte, tais como, a Uniforme, a Beta, entre outras. São
distribuições que assumem menor importância na actividade seguradora devido ao
limite superior do suporte ser finito.
Para caracterizar o domínio de atracção para máximos da Gumbel, é necessário
introduzir alguns conceitos adicionais.
Definição 1.2.9 (Função de Variação Rápida)
Uma função mensurável, , diz-se que é de variação rápida, e escreve-se
, se
h ℜ+ →ℜ+
∞ −
∈RV h
( )
( )
< < ∞
> =
∞
→ 0 1.
, 1 0
lim
t se
t se
x h
tx h
x
Teorema 1.2.10 (Propriedades das Funções de Variação Rápida)
i. Seja h∈RV−∞, não crescente, para z>0 e α∈ℜ
( )
<∞∫
∞
dt t h t
z
α
e
( )
( )
=∞∫
∞+
∞ →
x x
dt t h t
x h x
α α 1
lim ;
Para z=1, o inverso também é válido.
ii. Se h∈RV−∞, existem as funções c e δ tal que c
( )
x →c0∈( )
0,∞ ,( )
=−∞ ∞↑ x
x δ
( ) ( )
( )
=
∫
xz du u u x c x
h exp δ , zx≥ .
O inverso também é válido.
Definição 1.2.11 (Função de variação-Γ)
Uma função U , não decrescente, diz-se de variação-Γ, e escreve-se U , se estiver
definida num intervalo
(
, seΓ ∈
)
b
a, limx↑bU
( )
x =∞, e se existir uma função definida em(
tal que, para qualquerf
)
b
a, x,
( )
(
)
( )
xb
t U t e
t xf t U = + → lim .
A função f chama-se função auxiliar e é assintóticamente única.
Definição 1.2.12 (Função de variação-Π)
Uma função V , não negativa e não decrescente definida num intervalo semi-infinito
diz-se de variação- , e escreve-se
(
z,∞)
Π V∈Π, se existirem funções ,tal que para
( )
t >0a
( )
t ∈b ℜ x>0
( ) ( )
( )
xt a t b tx V t log
lim − =
∞
→ .
A função a
( )
t é assintóticamente única.Teorema 1.2.13 (Domínio de atracção de Λ)
Uma f.d. F pertence ao domínio de atracção para máximos de Λ, se e só se
( )
(
)
(
( )
)
( )
(
)
1 1 1 1lim 2 =
Todos os integrais envolvidos são finitos. Nesse caso 1/
(
1−F( )
x)
∈Γ e duas escolhas possíveis para a função auxiliar f( )
( )
(
)
( )
(
F t)
dtdtdy t F
t f
f f f
x x x
x x
y
∫
∫ ∫
− − =
1 1
ou
( )
( )
(
)
( )
(
F x)
dt t F
t f
f
x x
− −
=
∫
1 1
e
(
)
(
F) ( )
ndn = 1/1− ←
( )
n n f dc =
são escolhas aceitáveis.
Dem. in Resnick (1987), p. 48-50.
A lei de Gumbel é domínio de atracção de um vasto conjunto de distribuições, onde
inclui as distribuições de cauda “normal”, ou moderadamente pesada, e as distribuições
com o lado direito do suporte limitado. São disso exemplo a Normal, a Log-normal (que
não é considerado pesada), a Gamma, a Benktander-I e a Benktander-II. Ao contrário
das leis de Frechét e de Weibull, onde as constantes c e podem ser obtidas de
forma quase imediata, pelo Teorema 1.2.13, é possível verificar, que no caso da
Gumbel, existe uma multiplicidade e . Isso deve-se à enorme variedade de
distribuições que pertencem ao seu domínio de atracção.
n dn
n
As funções de distribuição que têm como domínio de atracção a lei de Gumbel,
possuem uma propriedade importante em relação aos momentos.
Corolário 1.2.14 (Existência de Momentos)
Dada uma v.a. X , com f.d. F∈D
( )
Λ e com xf =∞, então F ∈RV−∞. Em particular,( )
[ ]
+ α <∞X
E para todo o α >0, onde X+ =max
(
0,X)
.A segunda parte pode ser verificada pelo Teorema 1.2.10 i.
O cálculo de cn e d n é simplificado com o conceito que se segue.
Definição 1.2.15 (Equivalência de Cauda)
Duas f.d.s e dizem-se que têm caudas equivalentes, se tiverem o mesmo limite
superior do suporte, i.e., se e
F G
g f x
x = F
( ) ( )
x G x cf
x
x↑ / =
lim , 0<c<∞.
Teorema 1.2.16
Dadas duas f.d.s e G, seja e duas distribuições de valor extremo. Seja
e que
F H1 H2
(
H1D
F∈
)
Fn(
cnx+dn)
→H1( )
x , com cn >0 e dn ≥1. Então(
c x d)
→H2( )
xGn n + n se e só se para algum c>0, d∈ℜ
(
cx d HH2 = 1 +
)
, e F G tiverem caudas equivalentes com suporte superior xf e sei. H1 =Φα,então d =0 e limx↑∞
(
1−F( )
x)
/(
1−G( )
x)
=cα; ii. H1 =Ψα, então d =0 e ↑(
−F( )
x)
(
−G( )
x)
=c−αf
x
x 1 /1
lim ;
iii. H1 =Λ, então c=1 e x x
(
F( )
x)
(
G( )
x)
edf − − =
↑ 1 /1
lim .
No caso particularde ser absolutamente contínua, von Mises encontrou as condições
de suficiência que permitem simplificar o processo de averiguação se pertence ou
não, a um determinado domínio de atracção.
F
F
Teorema 1.2.17 (Condições de von Mises)
Seja uma f.d. absolutamente contínua, a sua derivada e o limite superior do
seu suporte, então,
F f xf
i. F∈D
( )
Λ se a. xf ≤+∞,b. ∃x0: f'
( )
x <0, ∀x∈[
x0,xf)
,c.
( )
(
( )
)
( )
11 ' lim
2 =−
−
→ f t
t F t f
f
x
t ;
ii. F∈D
(
Φα)
se a. xf =+∞,b.
( )
( )
0 1lim = >
− ∞
→ F t α
t tf
t ;
iii. F∈D
(
Ψα)
se a. xf <+∞,b.
(
)
( )
( )
01
lim = >
− −
→ F t α
t f t xf
x t f
.
Dem. in Resnick (1987), p. 63-66.
Os dois próximos resultados estão essencialmente relacionados com distribuições
Teorema 1.2.18 (Condição Necessária)
Se existir algum par cn >0, dn ∈ℜ para a d.f.F
( )
x , tal que(
c x d)
H( )
x Fn n n
n + →
∞ →
onde H
( )
x assume uma das formas do Teorema 1.1.1, então,(
)
( )
( )
01 0 lim = − − +
→ F x
x F x F f x x .
Dem. in Galambos (1987), p. 84-85.
Corolário 1.2.19
Seja X uma v.a. discreta, X∈ℵ0+ e Prob
(
X =k)
= pk. Se∑
+∞ = +∞ ↑ k j j k
k p p
lim tender
para zero, então não existem cn >0, dn ∈ℜ, tal que cn−1
(
Mn −dn)
convirja uma distribuição não degenerada.As três distribuições estáveis para extremos podem ser representadas em uma única
forma paramétrica.
Definição 1.2.20 (forma de Jenkinson-von Mises ou função generalizada dos valores extremos)
Define-se Hξ por
( )
{
{
(
{ }
)
}
}
− − + − = − , exp exp , 1exp 1/
x x x H ξ ξ ξ ℜ ∈ > + x x 0 1 ξ 0 0 = ≠ ξ ξ .
Existem outros resultados importantes em Teoria de Valores Extremos que se escreve
Teorema 1.2.21 (Caracterização de D
( )
Hξ )Para ξ∈ℜas seguintes condições são equivalentes
i. F∈D
( )
Hξii. Existe uma função a
()
. positiva e mensurável tal que para 1+ξx>0,( )
(
)
( )
(
)
= ≠ + = + − −→ , 0
0 , 1 lim / 1 ξ ξ ξ ξ x x x e x u F u xa u F f (1.2)
iii. Para yx, >0, y≠1,
( )
( )
( )
( )
= ≠ − − = − − ∞ → 0 , ln ln 0 , 1 1 lim ξ ξ ξ ξ y x y x s U sy U s U sx U sAo ii. pode ser atribuído uma interpretação estatística rescrevendo
( )
(
)
= ≠ + = > > − − −→ , 0
0 , 1 Prob lim / 1 ξ ξ ξ ξ x x u e x u X x u a u X f (1.3)
que é a distribuição assintótica dos excessos em relação a um determinado nível
elevado, u, com escala a
( )
u .Definição 1.2.22 (Função de Distribuição Excesso e Função Excesso Médio)
Seja X uma v.a. com f.d. com o lado direito do suporte . Para um nível u
fixo
F xf <xf
( )
x{
X u xX u}
Fu =Prob − ≤ > , x≥0,
é a f.d. excesso de X sobre o nível . A função u
( )
u E(
X uX u)
e = − >
é a função excesso médio de X .
Na actividade seguradora Fu
( )
x pode ser interpretado por distribuição excess-of-loss.1.3. Distribuição de Pareto Generalizada
A seguinte definição é motivada pela importância do resultado da expressão (1.3).
Definição 1.3.1 (Distribuição de Pareto Generalizada)
Define-se G por ξ
( )
(
)
− + −
= − −
, 1
, 1
1 1/
x
e x x
G
ξ
ξ ξ
0 0
= ≠ ξ ξ
onde
0 ,
/ 1 0
0 ,
0
< −
≤ ≤
≥ ≥
ξ ξ
ξ
se x
se x
.
É possível introduzir os parâmetros de localização e de escala, Gξ;ν,β, substituindo o x
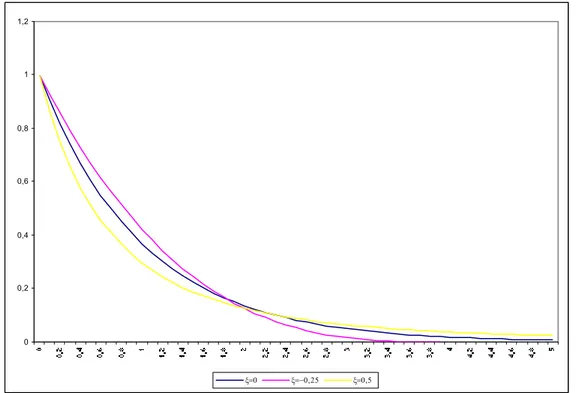
No gráfico que se segue estão representadas as funções de densidade para diferentes
valores de ξ.
0 0,2 0,4 0,6 0,8 1 1,2
ξ=0 ξ=−0,25 ξ=0,5
Figura 1.3.1 - Funções de densidade das formas possíveis de G
()
. , para diferentes valores deξ, com β =1 e ν =0.A Distribuição de Pareto Generalizada (DPG) possui algumas propriedades de enorme
interesse.
Teorema 1.3.2 (Propriedades da DPG)
i. Se a f.d. de X for DPG com parâmetros ξ e β, então, E
( )
X <∞ se e só se1
<
ξ ;
ii. Para qualquer ξ∈ ℜ, F∈D
( )
Hξ se e só se( )
( )( )
0sup lim
0
= −
− < <
→x x x uFu x Gξ, u x
u
f f
β ,
iii. Se x1,x2 ∈D
(
ξ,β)
, i=1,2, então(
)
( )
;( )
2 1 ; 2 1 ; 1 x G x G x x G ξx ξ ξ ξ + = + β β βou seja, a probabilidade de X exceder x1 +x2 uma vez que excede , continua a ser uma DPG. Esta propriedade implica que a DPG é fechada, trata-se de uma
propriedade de enorme interesse nos tratados excess-of-loss e stop-loss.
1
x
iv. Seja ~ Poi
( )
λX X ,
max 1 2
N independente da sucessão i.i.d. , seja ainda
, então
β ξ;
~G
Xn
(
N)
n X
M = ,...,
(
M x)
λ ξ x Hξ:µ,ψ( )
x/ξ N = + − = ≤ −1 1 exp Prob β
onde µ = βξ−1
(
λξ −1)
e ψ =βλξ .Por outras palavras, nas condições referidas Prob
(
MN ≤x)
tem como domínio de atracção GEV.v. Xn ~Gξ;β, ξ <1, então para u< xf ,
( )
(
)
ξ ξu σ u u|X X E u e − + = > − =1 , β +uξ >0,
por conseguinte, a função de excesso médio é linear. Trata-se de uma propriedade
com um enorme sentido prático.
Um dos problemas na modelização de DPG é a escolha do nível de u. Alguns
autores propõem a escolha de um nível de u a partir do qual, a função de excesso
médio empírica se comporta como uma função linear, é um tema a ser aprofundado
C
APÍTULO2
Análise e Apresentação dos Dados
Pretende-se, no presente capítulo apresentar e analisar algumas técnicas para
conhecimento do comportamento de dados de cauda pesada. É dada maior atenção às
indemnizações de elevado montante, sendo introduzidos alguns conceitos relevantes.
Os dados utilizados são retirados da carteira de seguros de danos patrimoniais de
empresas de uma filial da Allianz Group. O período de observação foi de 01-01-1993 a
31-03-2001 e todos os valores foram corrigidos para preços de 2002.
Apresentam-se de seguida algumas estatísticas dos dados em análise.
Média 645.090
Desvio Padrão 2.514.059
Mínimo 130.019
1º Percentil 130.877
1º Quartil 178.033
Mediana 271.391
99º Percentil 5.855.928
Máximo 117.953.980
N 3296
Através do quadro anterior é possível constatar a existência de um pequeno conjunto de
indemnizações de elevado montante.
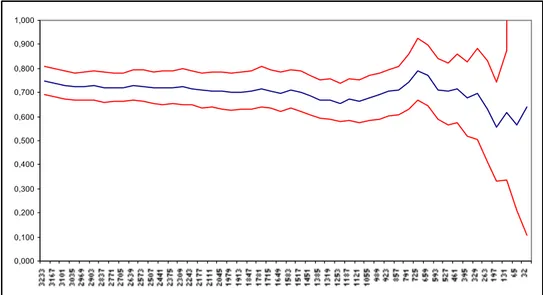
Na Figura 2.1, verifica-se que as indemnizações de maior montante estão distribuídas
regularmente ao longo do período, sem que apresentem alguma tendência na evolução
das indemnizações. Assim, parece razoável assumir a hipótese i.i.d..
I n d e m n i z a ç ã o
0 20. 000. 000 40. 000. 000 60. 000. 000 80. 000. 000 1 00. 000. 000 1 20. 000. 000 1 40. 000. 000
01 -01 -1 993 01 -01 -1 994 01 -01 -1 995 01 -01 -1 996 01 -01 -1 997 01 -01 -1 998 01 -01 -1 999 01 -01 -2000 01 -01 -2001
Figura 2.1 – Comportamento dos sinistros extremos verificados entre 1993 e 2001.
Numa primeira análise, os dados foram ajustados a uma distribuição de Pareto, na forma
de F
( )
x =1−(
β/x)
α,x>β, 130000β = , que é igual ao valor da franquia, e1,03233
=
α , estimado pelo método de máxima verosimilhança.
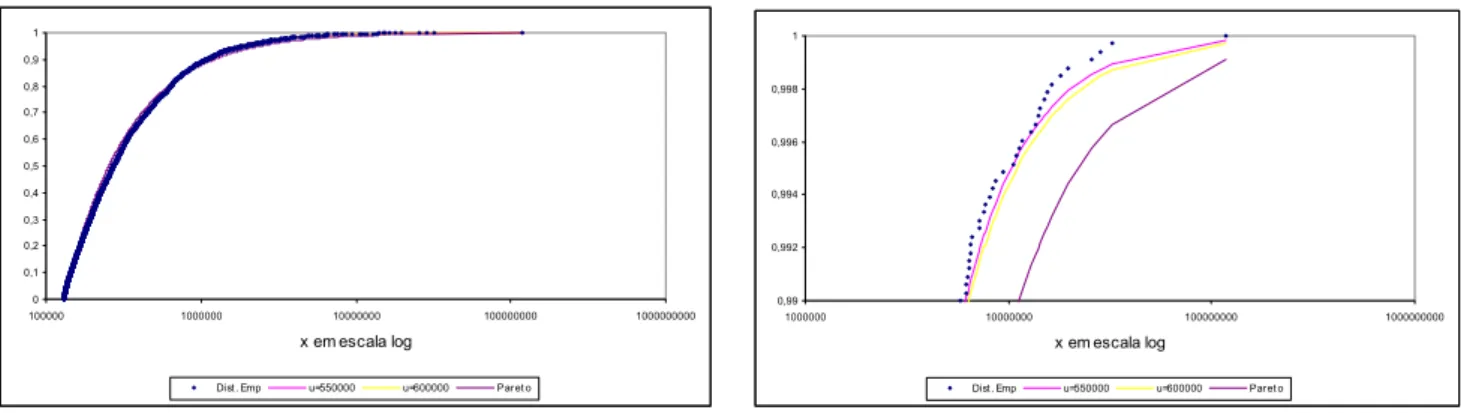
Pela Figura 2.2, constata-se que a distribuição de Pareto tende a sobrestimar a cauda,
efeito torna-se mais evidente na Figura 2.3, que permite visualizar a diferença dos
quantis estimados.
A sobrestimação da cauda pode traduzir-se em custos financeiros, por exemplo, na
determinação do prémio por layer num tratado de excess-of-loss a pagar à resseguradora
ou em custos económicos na determinação do nível adequado do capital da seguradora.
Fn(x) Vs. F(x)
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
100000 1000000 10000000 100000000 1000000000
X em escala log
Fn(x) Vs. F(x)
0,975 0,98 0,985 0,99 0,995 1
1000000 10000000 100000000 1000000000
X em escala log
Figura 2.2 – No gráfico da esquerda estão representadas a distribuição empírica e a distribuição de Pareto. O gráfico da direita tem a escala ampliada na cauda.
Q-Q plot
100000 1000000 10000000 100000000 1000000000
100000 1000000 10000000 100000000 1000000000 Dados Ordenados ( em escala Log)
O cálculo do excesso médio empírico fornece algumas ideias sobre o comportamento da
cauda. Na Figura 2.4 está representado
( )
(
)
{
u,en u ,Xn,n <u< X1,n}
onde
( )
(
)
{ }
∑
∑
= >
=
+ −
= n
i
u X n i
i n
i
I u X u
e
1 1
Excesso Médio Em pírico
0 5000000 1 E+07 1 ,5E+07 2E+07 2,5E+07 3E+07
0 2000000 4000000 6000000 8000000 1 0000000 1 2000000 1 4000000 1 6000000 1 8000000 20000000 u
.
Figura 2.4 - Função de excesso médio empírico.
Para os dados em análise, a função de excesso médio empírico é crescente com u. Esta
constatação confirma que a função de distribuição empírica tem uma cauda pesada. Por
outro lado, verifica-se que a função excesso médio assume uma forma linear
sensivelmente a partir de u =550000 ou de u=600000, indiciando que, a partir desses
níveis, a cauda pode ser modelada com uma Distribuição de Pareto Generalizada, como
sugerido no Capítulo 2.
Outra questão intimamente ligada ao comportamento da cauda, é a existência de
( )
( )
( )
p S
p M p R
n n
n = , n≥1, , p≥0
onde, Sn
( )
p = X1 p +...+ Xn p e Mn( )
p =max(
X1 p,...,Xn p)
.Se
( )
→q.c. 0n p
R ⇔ E
( )
X p <∞( )
→P 0n p
R ⇔
(
{ })
0
R I
X
E p X<x ∈
( )
p Y( )
pR d
n → 2 ⇔ P
(
X > x)
∈R−αp, 0<α <1( )
→P 1n p
R ⇔ P
(
X > x)
∈R0onde, é uma v.a. apropriada e não degenerada. Informação detalhada pode ser
encontrada em Embretchs et al. (1997).
( )
p Y2Na Figura 2.5 estão representados os Rn
( )
p para vários valores de p. Verifica-se que,para , não tende para zero, indiciando a inexistência dos
momentos de ordem superior. 5
, 1
>
p limn↑∞ Rn
( )
pRn(p)
0,00000 0,10000 0,20000 0,30000 0,40000 0,50000 0,60000 0,70000 0,80000 0,90000 1,00000
1 501 1001 1501 2001 2501 3001
n
p=1 p=1,5 p=2 p=2,5 p=3
C
APÍTULO3
Modelação dos dados
Pretende-se, ao longo deste capítulo, modelar os dados apresentados no Capítulo 3 de
acordo com as metodologias relacionadas com a Teoria de Valores Extremos, a fim de
estudar com maior profundidade, o comportamento das indemnizações extremas.
Assim, na Secção 3.1, os dados são modelados por ajustamento de uma Distribuição de
Pareto Generalizada, seguindo a metodologia apresentada em Embrechts et al. (1997) e
McNeil (1997). Na Secção 3.2.1 é apresentada uma abordagem semi-paramétrica, sendo
introduzido um método adaptativo, seguindo as metodologias apresentadas em
Danielsson et al. (2001) e Gomes et al. (2002) na Secção 3.2.2. No final, na Secção 3.3.
procede-se ao desenvolvimento da discussão sobre ambas as abordagens.
3.1 Modelação pela Distribuição de Pareto Generalizada
Pretende-se nesta Secção estudar o comportamento da cauda seguindo uma abordagem
paramétrica. Na abordagem paramétrica procura-se ajustar uma distribuição aos
excessos, , , através da aplicação do resultado ii. do Teorema 1.3.2,
onde se afirma: à medida que u ,
u X
Y = − X >u
f
x
A determinação do nível óptimo de u é essencial para este tipo de modelação. Ao
contrário do que acontece na abordagem semi-paramétrica, que é apresentada na
Secção 3.2, ainda não existe nenhum método adaptativo para a escolha do nível de
óptimo de u, aceite de uma forma generalizada.
Na determinação do nível de u é necessário ter em conta o seguinte dilema:
i. uma escolha do nível de demasiado elevado, pode conduzir a uma maior
variância nas estimativas, na medida em que o número de observações que
excedem é reduzido; u
u
ii. ao passo que, uma escolha do nível de u demasiado baixo, pode originar a um
maior viés, além de não se poder aplicar o ii. do Teorema 2.3.2.
No Capítulo 2 foi sugerido uma forma de determinar o nível de u, que consiste na
escolha de um valor de X , à direita do qual, a função de excesso médio empírica se
assemelha a uma função linear. Existem, no entanto, situações em que o nível óptimo
não é evidente, sendo vários os níveis aceitáveis, como, por exemplo, os indiciados na
Figura 2.4 para os dados em análise.
Na Figura 2.4, atendendo ao número de observações e ao valor do nível em si, existem
alguns indícios de que o nível óptimo possa ser u =550000 ou u =600000.
Os parâmetros ξ e β
( )
u podem ser estimados pelo método de máxima verosimilhança.Seja F uma Distribuição de Pareto Generalizada com parâmetros ξ e β >0, a função
de densidade f é
( )
x ξ x , x D( )
ξ, .f ξ β
β
β ∈
+ =
− −1 1
onde
(
)
[
[
)
]
< − ≥ ∞ = 0 , / , 0 0 , , 0 , ξ ξ β ξ β ξ DA função log-verosimilhança é
( )
(
)
ξ X .ξ n X ; ξ, n i i
∑
= + + − − = 1 1 ln 1 1 ln β β β lPara 2ξ >−1/ , é possível demonstrar que
(
,M)
, n ,N
ξ,
ξ
n n d
n / → →∞ −
− −1
2
1 ˆ ˆ 1 0
β β onde,
(
)
− − + + = − 2 1 1 1 11 ξ ξ
M ,
e ξˆn e βˆn são estimadores de máxima verosimilhança.
Por se pretender modelar a distribuição dos excessos de um determinado nível u, o
vector X é substituído pelo vector Y, o vector dos excessos, e por , o número de
observações que excederam .
N Nu
u
O estimador de ξ pode ser obtido após uma reparametrização.
(
ξ,β) ( )
→ ξ,τ , ondeβ ξ
τ =− / . Resultando,
( )
τ N(
τY)
, ξξ Nu
i i u
∑
= − − = = 1 1 1 ln ˆ ˆ(
)
(
, Y,...,YNu)
τ∈ −∞max 1 :
( )
( )
01 1 ˆ 1 1 1 1 = − + + =
∑
= u N i i iu τY
Y
τ ξ
N
τ
Na Figura 3.1.1. estão representados os valores de para diferentes níveis de u. Estão
representados também os intervalos de confiança bootstrap com 95% de confiança, com
250 réplicas. A partir da Figura 3.1.1, é possível constatar que o valor de é
relativamente estável dentro do intervalo
ξˆ
ξˆ
(
0,6;0,8)
.0,000 0,100 0,200 0,300 0,400 0,500 0,600 0,700 0,800 0,900 1,000
Figura 3.1.1 – Valores de , da DPG, para diferentes níveis de ξˆ u.
O valor das estimativas estão apresentados no quadro seguinte:
u 550.000 600.000
ξˆ 0,74139 0,79825
βˆ 430.802 422.063
u
n 898 732
Nos gráficos seguintes estão representadas as distribuições condicionadas e as
respectivas funções de distribuição empírica condicionada, para e
.
550000 =
u
600000 =
Fnu(x) Vs. GDP (u=600000)
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
100 1000 10000 100000 1000000 10000000 100000000 1000000000 Y em escala log
Empí r ica GDP
Fnu(x) Vs. GDP (u=550000)
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
100 1000 10000 100000 1000000 10000000 100000000 1000000000 y em escala log
Empí r ica GDP
Figura 3.1.2 – Função de distribuição ajustada aos excessos com u=550.000 (à esquerda) e u=600.000 (à direita).
Os gráficos que se seguem têm a escala ampliada no sentido de dar maior enfoque à
cauda.
Fnu(x) Vs. GDP (u=550000)
0,95 0,96 0,97 0,98 0,99 1
1000000 10000000 100000000 1000000000 y em escala log
Empí rica GDP
Fnu(x) Vs. GDP (u=600000)
0,95 0,96 0,97 0,98 0,99 1
1000000 10000000 100000000 1000000000 Y em escala log
Empí rica GDP
Figura 3.1.3 – Função de distribuição ajustada aos excessos com u=550.000 (à esquerda) e u=600.000 (à direita), com a cauda ampliada.
Em ambos os modelos o ajustamento parece ser razoável. A mesma conclusão pode ser
Q-Q Plot (U=550000) 0 20000000 40000000 60000000 80000000 100000000 120000000 140000000
0 5000000 10000000 15000000 20000000 25000000 30000000 35000000 Excessos
Q-Q plot (u=600000)
0 20000000 40000000 60000000 80000000 100000000 120000000 140000000
0 5000000 10000000 15000000 2000000025000000 30000000 35000000 40000000 45000000 50000000 Excessos
Figura 3.1.4 – Comparação dos quantis dos excessos com as distribuições ajustadas com u =550.000 (à esquerda) e u=600.000 (à direita).
Após o ajustamento das funções de distribuição aos excessos, através da distribuição de
Pareto Generalizada, é necessário reparametrizar os modelos por forma a obter a F(x),
ou seja, as distribuições não condicionadas. Assim,
( )
, , ' ˆ ˆ ˆ 1 1 ˆ ˆ / 1 u x v u x xF ≥
− − + − = − ξ β ξ onde − = 1 ˆ ˆ ˆ ˆ ξ ξ β n N v u e ξ β β ˆ ˆ ' ˆ = n Nu .
Para x<u, o número de observações é relativamente elevado: 2398 para e
2564 para e a diferença entre duas estatísticas de ordem consecutivas é
pequena, o que leva a considerar que
550000 = u 600000 = u
X pode ser modelado com a função de
Nos gráficos seguintes são representadas as várias F
( )
x para os dois valores de . É igualmente representada a distribuição de Pareto apresentada no Capítulo 3, como termode comparação.
u
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
100000 1000000 10000000 100000000 1000000000
x em escala log
Dist . Emp u=550000 u=600000 Par et o
0,99 0,992 0,994 0,996 0,998 1
1000000 10000000 100000000 1000000000
x em escala log
Dist . Emp u=550000 u=600000 Paret o
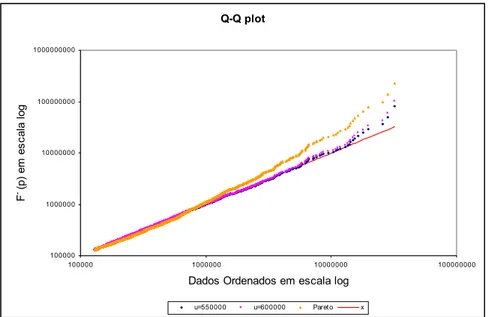
Figura 3.1.5 – No gráfico da esquerda estão representadas a distribuição empírica e a distribuição ajustada com u =550.000 e u=600.000. O gráfico da direita tem a escala ampliada na cauda.
O gráfico da esquerda sugere que o ajustamento de todos os modelos é aceitável. No
gráfico da direita onde a escala é ampliada, verificam-se melhorias no ajustamento
relativamente à distribuição de Pareto. As mesmas conclusões podem ser retiradas da
Figura 3.1.6, onde estão representados os gráficos Q-Q.
Existe, em ambos os modelos, uma sobrestimação dos quantis em relação à distribuição
empírica. Trata-se de um resultado esperado dado que um dos objectivos deste tipo de
Q-Q plot
100000 1000000 10000000 100000000 1000000000
100000 1000000 10000000 100000000
Dados Ordenados em escala log
F
- (p
) e
m
e
s
c
a
la
l
o
g
u=550000 u=600000 Paret o x
Figura 3.1.6 – Comparação dos quantis com os da distribuição ajustada com
e u .
000 . 550 =
u =600.000
3.2 Abordagem semi paramétrica
Nesta Secção, a modelação da cauda da distribuição, segue uma abordagem
semi-paramétrica. Em 3.2.1 é apresentada a ideia subjacente a esta abordagem. Na Secção
3.2.2 é apresentado um algoritmo adaptativo para estimar a fracção óptima da amostra a
utilizar.
3.2.1 Estimação Sob Condição de Domínio de Atracção para Máximos
Seja X1,X2,...,Xn uma sequência de v.a. i.i.d. de uma f.d. F∈D
( )
Φα , tendo em contao Teorema 1.2.7, a cauda da distribuição pode ser escrita da seguinte forma:
( )
x x L( )
xF = −α , x>0,
Por outro lado, atendendo ao Teorema 1.2.2, se F∈D
( )
Hξ então(
c x d)
H( )
x Fn n n
n ln ξ
lim + =−
∞
→ .
Seja u =cnx+dn, a expressão em cima pode ser rescrita do seguinte modo
( )
ξ ξ/ 1 1 − − + ≈ n n c d u u F n .
Desta forma o estimador da cauda é
( )
ξ ξ~ / 1 ˆ ˆ ˆ 1 1 − ∧ − + = n n c d u n u F
com estimadores adequados de , ξˆ cˆn e dˆn.
A estimação de ξ é baseada nas maiores estatísticas de ordem, e é desenvolvida na
Secção 3.2.2 com maior profundidade. A dimensão de deve satisfazer duas
condições:
k
k
( )
n →∞k e n/k
( )
n →∞, que pode ser interpretada da seguinte forma: onúmero de estatísticas de ordem deve ser suficientemente elevado, contudo, há que ter
em conta que apenas a cauda é analisada. Uma escolha adequada do valor de permite
obter algumas propriedades como a consistência e a normalidade assintótica do
estimador.
k
Em relação aos estimadores de c e , estes sofrem uma ligeira alteração
relativamente ao apresentado no Teorema 1.2.7, onde se definiu
n
ˆ dˆn
(
1)
1 −
← −
=F n
cn que
no presente modelo é substituído por cn/k =F←
(
1−(
n/k)
−1)
, onde satisfaz ascondições enunciadas.
Embora existam vários estimadores de α propostos na literatura de Teoria de Valores
Extremos, optou-se no presente trabalho por utilizar apenas o estimador de Hill, por ser,
por um lado, um estimador natural e, por outro, pela sua importância histórica.
Seja X uma v.a. com a f.d. F tal que,
(
>)
=( )
= −α x x F x XProb , x≥1, α >0.
Então, Y =lnX tem como distribuição
(
)
ye y Y > = −α
Prob , , y≥0 α >0,
ou seja, Y ~Exp
( )
α . Assim, o estimador de máxima verosimilhança é:1 1 , 1 1 ln 1 ln 1 ˆ − = − = =
=
∑
∑
nj n j n j j X n X n α .
Generalizando o resultado apresentado
( )
= −α Cx xF , x≥u >0
onde C =uα, para um nível u conhecido, o estimador assumirá a seguinte forma:
1 1 , 1 1 , ln ln 1 ln 1 ˆ − = − = − =
=
∑
∑
X un u X n n j n j n j n j n α
Contudo, na prática, o nível exacto de u não é conhecido. Mas se F∈D
(
Φα)
, então Ftem um comportamento que se assemelha à cauda da distribuição de Pareto.
Seja
{
i X u i n}
Reparametrizando os estimadores, substituindo o suposto nível pela estatística de
ordem
{
, o estimador pode ser rescrito como a seguir se representa:u
}
k K = ( ) ( ) 1 , 1 , ln ln 1 ˆ ˆ , − = − ==
∑
k knj n j H H X X k n k α
α (3.1)
e
( )H n k n k n k X n k
C ˆ ,
, ,
ˆ = α
onde satisfaz as condições referidas. A expressão (3.1) é conhecida como
estimador de Hill.
( )
n kk =
O estimador da cauda é
( )
( )H n k n k X x n k x F , ˆ , α − ∧ = ,
isto é, F tem um comportamento de tipo Pareto acima do nível aleatório Xk,n.
O próximo teorema apresenta as propriedades do estimador de Hill.
Teorema 3.2.1 (Propriedades do Estimador de Hill)
Seja estritamente estacionária com distribuição marginal satisfazendo para
todo o
{
Xn>
}
F0
α e L∈R0,
( )
x x L( )
xF = −α , x>0, Seja αˆ( )H =αˆ( )kH,n o estimador de Hill.
i. (consistência fraca) se
{
Xn}
é i.i.d. e se k( )
n →∞ e k( )
n /n→0 para n→∞, então,( ) α
α H →p
ii. (consistência forte) se
{
Xn}
é i.i.d. e se k( )
n /n→0, k( )
n /lnlnn→∞ para , então,∞ →
n
( ) α
αˆ H →q.c.
iii. (normalidade assintótica) Se
{ }
Xn é i.i.d. e k( )
n →∞ a uma velocidade apropriada, então,( )
(
)
( )
2, 0
ˆ α α
α N
k H − →d .
3.2.2 Determinação do Nível Óptimo de k
A determinação do nível óptimo de é um dos temas de maior interesse em Teoria de
Valores Extremos. A escolha do valor de condiciona o valor das estimativas e as
propriedades do estimador. À semelhança do que acontece na determinação do valor do
nível , na modelação pela Distribuição de Pareto Generalizada, ao determinar o valor
de o analista enfrenta o seguinte dilema: k
k
u
k
i. para garantir que apenas a cauda seja analisada deve-se escolher um valor de
relativamente baixo. Contudo, a variância das estimativas pode aumentar se se
seleccionar um excessivamente baixo.
k
k
ii. porém, ao aumentar demasiado o valor de k, poderá aumentar o viés.
No gráfico da Figura 3.2.1 está representado o horror Hill plot, através do qual é
Horror Hill plot
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
3295 3095 2895 2695 2495 2295 2095 1895 1695 1495 1295 1095 895 695 495 295 95
k
Figura 3.2.1 – Horror Hill plot
Embretchs et al. (1997) propõe o valor de dentro do intervalo onde, para diferentes
valores de k, o valor de se mantém relativamente estável. Trata-se de um critério
relativamente vago. Todavia, existem alguns autores que recorrem a métodos
adaptativos.
k
ξˆ
A abordagem que se apresenta é baseada nos trabalhos de Danielsson et al. (2001) e
Gomes et al. (2002), que é desenvolvida no âmbito da condição de segunda ordem,
( ) ( )
( )
ρρ ξ ξ
1 /
lim − = −
∞ →
x x t
A x t U tx U
t (3.2)
onde, A
( )
t ∈RVρ e U( )
t =F←(
1−1/t)
é uma função mensurável com sinal constante e0
≤
ρ , que é o parâmetro de segunda ordem que determina a convergência de
( ) ( )
tx /F x pF ara t−α. À medida que ρ aumenta, a convergência à aproximação de
primeira ordem também aumenta.
Hall (1982) sugere que é possível obter k
( )
n através de( )
(
( )
)
20 n =argminAssimEξ k −ξ
k n