U
U
N
N
I
I
V
V
E
E
R
R
S
S
I
I
D
D
A
A
D
D
E
E
C
C
A
A
T
T
Ó
Ó
L
L
I
I
C
C
A
A
D
D
E
E
B
B
R
R
A
A
S
S
Í
Í
L
L
I
I
A
A
Pró-Reitoria de Pós-Graduação e Pesquisa
Programa de Pós-Graduação Stricto Sensu em Informática Mestrado em Gestão do Conhecimento e da Tecnologia da Informação
Descoberta de Conhecimento com o uso
de
Text Mining
: Cruzando o Abismo de
Moore
Edilberto Magalhães Silva
Descoberta de Conhecimento com o uso
de
Text Mining
: Cruzando o Abismo de
Moore
Prof. Dr. Hércules Antônio do Prado e
Prof. Dr. Edilson Ferneda
Orientadores
Brasília-DF
2002
ii
Ficha Catalográfica
S586d Silva, Edilberto Magalhães
Descoberta de conhecimento com o uso de text mining: cruzando o abismo de Moore / Edilberto Magalhães Silva. – Brasília, 2002.
174 p.
Orientadores: Prof. Dr. Hércules Antônio do Prado e Prof. Dr. Edilson Ferneda.
Dissertação (mestrado) – Universidade Católica de Brasília, 2002.
1. Inteligência organizacional. 2. Text mining. 3. CRISP-DM. 4. KDT. 5. Aprendizagem organizacional. I. Título.
iii
Termo de Aprovação
Dissertação defendida e aprovada em 19 de dezembro de 2002, pela banca examinadora
constituída pelos professores:
______________________________________________
Prof. Dr. Hércules Antônio do Prado - Orientador
______________________________________________
Prof. Dr. Edilson Ferneda - Orientador
______________________________________________
Profa. Dra. Kira Maria Antonia Tarapanoff
______________________________________________
iv
Dedicatória
A meus pais, Paulo Roberto e Maria de Fátima pelo apoio incondicional, pelo amor, doação e educação dados ao filho que os ama muito.
A meus familiares, em especial, minhas irmãs, Cristiane e Ana Paula, pela cooperação e privação das horas de convívio tão importantes para mim em decorrência da dedicação a meus estudos.
A Júnior, Arthur, Eduardo, Marcos Vinnícius, Ana Clara e Lívia Maria os quais me sinto honrado em tê-los como afilhados.
v
Agradecimentos
A Deus que por tantos motivos reclamaria outra dissertação.
Aos administradores da RADIOBRÁS, Srs. Carlos Zarur e Luiz Antônio Duarte, pelo apoio, em especial, ao Sr. José Roberto Barrozo pela amizade, conselhos e gerenciamento no estudo de caso.
Aos professores Hércules Prado e Edílson Ferneda pela amizade, orientação e sugestões, indispensáveis para a elaboração desta pesquisa
A ajuda valiosa de Leandro Wives pela disponibilização dos estudos realizados na área de DCT e pelo fornecimento da ferramenta de mineração de texto Eurekha.
Ao Departamento de Ciência da Computação na pessoa do prof. Marcelo Ladeira, que franqueou minha participação no curso Mineração de Dados oferecido, no âmbito do projeto SARA - Saúde Apoiada em Raciocínio Automatizado (cooperação UFRGS/UnB/UCB). A participação no referido curso foi de vital importância para o desenvolvimento da aplicação de mineração de texto contida nesta dissertação.
vi
Epígrafe
vii
Sumário
Lista de Figuras ...x
Lista de Tabelas ...xi
Lista de Abreviaturas ...xii
Resumo ...xiii
Abstract ...xiv
Capítulo I - Introdução ...15
Capítulo II - Apresentação do Problema ...19
2.1 - Importância das Informações Textuais nas Organizações ...20
2.2 - Uso de mineração de textono mundo...21
2.3 - ‘Abismo’ de Moore ...21
2.4 - Colocação do Problema ...23
2.5 - Objetivos...23
2.6 - Caracterização e Articulação da Pesquisa...24
Capítulo III - O Estado da Arte da DCT ...25
3.1 - KDT - Knowledge Discovery in Text...25
3.1.1 – Extração da Informação...26
3.1.2 – Recuperação da Informação ...28
3.2 - Tecnologias para descoberta do conhecimento em Texto ...33
3.2.1 - Descobertas Reativa e Proativa...33
3.2.2 - Inteligência Competitiva ...35
3.2.3 - Tipos de Descoberta ...36
3.3 - Diferenças entre Mineração de texto eFerramentas de Busca ...37
3.4 - Síntese do Capítulo...39
Capítulo IV - Metodologia ...42
4.1 - CRISP-DM ...42
4.1.1 - Definição e Entendimento do problema...46
4.1.2 - Obtenção e Extração dos Dados...46
viii
4.1.4 - Engenharia dos Dados...47
4.1.5 - Engenharia do algoritmo...48
4.1.6 – Mineração ...48
4.1.7 - Interpretação e Validação dos resultados ...49
4.1.8 - Refinamento dos Dados e do Problema ...50
4.2 - Abordagens para DCT ...50
4.2.1 - Abordagem de Palazzo ...51
4.2.2 - Abordagem de Ah-Hwee Tan ...52
4.2.3 - Abordagem de Halliman ...53
4.3 - Abordagem Utilizada das Estratégias de DCT ...55
4.4 - Síntese do Capítulo...56
Capítulo V - Compreensão do Negócio e Pré-Processamento...57
5.1 - Compreensão do Negócio...57
5.1.1 - Objetivo do Negócio ...58
5.1.2 - Avaliação da Situação ...61
5.1.3 - Objetivos da Mineração de Dados...67
5.1.4 - Plano do Projeto ...68
5.2 - Entendimento dos Dados ...71
5.2.1 - Relatório Inicial da Coleção...71
5.2.2 - Descrição dos Dados ...73
5.2.3 - Exploração dos Dados...74
5.2.4 - Qualidade dos Dados...78
5.3 - Preparação dos Dados...79
5.3.1 - Seleção dos Dados ...79
5.3.2 - Limpeza dos Dados ...81
5.3.3 - Engenharia dos Dados...83
5.3.4 - Formatação dos Dados...86
5.4 - Síntese do Capítulo...87
Capítulo VI - Modelagem...88
6.1 - Seleção da Técnica ...88
6.1.1 - Descrição dos Dados e Sumarização...89
6.1.2 - Segmentação ...89
6.2 - Teste do modelo...91
6.3 - Modelo...92
6.4 - Avaliação Técnica ...96
ix
Capítulo VII - Pós-Processamento ...99
7.1 - Avaliação...99
7.1.1 - Avaliação do Modelo ...100
7.1.2 - Revisão dos Processos ...110
7.1.3 - Próximos passos ...112
7.2 - Aplicação...112
7.2.1 - Planejamento da Aplicação ...112
7.2.2 - Produção do relatório final ...113
7.2.3 - Revisão de projeto ...114
7.3 - Síntese do Capítulo...115
Capítulo VIII - Impactos do Conhecimento Adquirido na Gestão do Conhecimento ...116
8.1 - Gestão do Conhecimento e Impactos da Mineração de Textos ...117
8.2 - Modelo Genérico de Gestão do Conhecimento ...118
8.2.1 - Processos da Gestão do Conhecimento ...119
8.2.2 - Fatores Facilitadores da Gestão do Conhecimento ...122
8.3 - Contribuições da Mineração de Texto no Modelo de Gestão do Conhecimento ...123
8.3.1 - Na Gestão da Empresa ...124
8.3.2 - No Modelo Genérico de Gestão do Conhecimento...125
8.4 - Síntese do Capítulo...126
Capítulo IX - Conclusões e Trabalhos Futuros ...127
Capítulo X - Referências Bibliográficas...131
Anexo A - Autorização e Avaliação da RADIOBRÁS...134
Anexo B - Artigo no DM 2002...138
Anexo C - Artigo no KM Brasil 2002 ...149
x
Lista de Figuras
Figura 2.1 - Comparação de uso entre técnicas de mineração. ...21
Figura 2.2 - Ciclo de vida de adoção de tecnologia. ...22
Figura 3.1 - Etapas em uma indexação automática...31
Figura 4.1 - Ciclo de vida de DCBD segundo a CRISP-DM...44
Figura 4.2 - Processo completo da DCBD...45
Figura 4.3 - Abordagem de Palazzo...51
Figura 4.4 - Abordagem de mineração de texto segundo Ah-Hwee Tan. ...52
Figura 4.5 - Abordagem de Halliman. ...54
Figura 5.1 – Plano do projeto. ...68
Figura 5.2 - Interface do Eurekha. ...70
Figura 5.3 - Produção Mensal em 2001. ...73
Figura 5.4 - Formato-padrão do conteúdo textos...74
Figura 5.5 - Padrão de nomenclatura do arquivo-texto...74
Figura 5.6 - Incidência de palavras por mês (a)...76
Figura 5.7 - Incidência de palavras por mês (b)...76
Figura 5.8 - Utilitário de pesquisa textual...82
Figura 5.9 - Ciclo das tarefas da engenharia de dados...83
Figura 5.10 - Nomenclatura dos arquivos de C&T depois da engenharia dos dados...85
Figura 5.11 - Nomenclatura depois da formatação dos textos. ...86
Figura 6.1 - Metodologia de agrupamento para DCT. ...91
Figura 6.2 - Resultado do agrupamento de dezembro/01. ...97
Figura 7.1 - Resultado da categorização de dezembro/01...102
Figura 7.2 - Grandes assuntos abordados pelas notícias. ...102
Figura 7.3 - Evolução na incidência das principais palavras em 2001. ...103
Figura 7.4 - Palavras mais usadas...104
Figura 7.5 - Distribuição de tipos de notícias. ...105
Figura 7.6 - Distribuição geográfica no Brasil...105
Figura 7.7 – Categorias das notícias no período ...107
Figura 7.8 - Categorias das notícias por mês (a)...108
Figura 7.8 - Categorias das notícias por mês (b)...109
Figura 7.9 – Síntese metodológica do estudo de caso...110
Figura 8.1 - Processo geral de aprendizado. ...118
xi
Lista de Tabelas
Tabela 5.1 - Resumo da importação dos dados...72
Tabela 5.2 - Resumo dos dados importados. ...73
Tabela 5.3 - Total e média de palavras por texto. ...75
Tabela 5.4 - Palavras com maior incidência por mês em 2001...75
Tabela 5.5 - Resultado da limpeza de dados...82
Tabela 6.1 - Resultados dos testes de algoritmos x nível de GSM. ...94
xii
Lista de Abreviaturas
ASC II - American Standard Code for Information Interchange
C&T - Ciência e Tecnologia
CRISP-DM - CRoss-Industry Standard Process for Data Mining
DCBD - Descoberta de Conhecimento em Bases de Dados
DCT - Descoberta de Conhecimento em Texto
DM - Data Mining ou Mineração de Dados GSM - Grau de Similaridade Mínimo
IE - Information Extraction ou Extração da Informação IR - Information Retrieval ou Recuperação da Informação KDD - Knowledge Discovery in Databases
xiii
Resumo
Desde o final dos anos 80, um grande esforço de pesquisa vem sendo
desenvolvido com o intuito de se extrair padrões úteis e desconhecidos a partir do grande
volume de dados existente nas organizações. A primeira vertente de pesquisa explorou,
principalmente, dados estruturados. Mais recentemente, passou-se a dar mais atenção a dados
na forma de texto. Entretanto, passados alguns anos de pesquisa em mineração de texto,
observa-se que esse tipo de tecnologia ainda é pouco explorado. Considerando que a maior
parte das informações disponíveis está em forma textual e que nessa forma podem estar
escondidos padrões importantes questiona-se o porquê da pouca utilização de mineração de
texto. Para tentar responder essa questão, foram enumeradas como possíveis causas para a
carência de aplicações de text mining: (a) pouca usabilidade das ferramentas; (b) existência de poucos relatos de experiências de sucesso; e (c) falta de uma metodologia adequada. Neste
trabalho investigou-se o item (c) por meio de um estudo de caso real em uma empresa pública
de jornalismo (RADIOBRÁS). Desenvolveu-se uma aplicação de text mining sobre cerca de 55.000 notícias por ela produzida em 2001. Partindo da análise dos resultados obtidos
procurou-se demonstrar que é possível com o KDT – Knowledge Discovery in Text obter vantagens competitivas, apontando a existência de alternativas metodológicas adequadas para
a superação do chamado ‘abismo’ de Moore. Foram agregadas várias metodologias para KDT
juntamente com a CRISP-DM, originalmente desenvolvida para KDD – Knowledge Discovery in Database, verificando-se que é possível, na prática, reverter conhecimentos adquiridos com o KDT em benefício do melhoramento da eficiência organizacional.
xiv
Abstract
Since the late 80s a great effort has been developed aiming to the acquisition of previously unknown and useful patterns from the huge amount of data existing in the organizations. The initial focus of this research explored chiefly structured data. Most recently, attention has been given to data in the form of texts. After some years researching the text mining it is possible to assert that this kind of technology is still little explored. Considering the major part of the available information is in textual format and that it hides important patterns, the question is: why is text mining not properly explored? Trying to answer this question, some possible reasons were enumerated, such as: (a) weak usability of the tools; (b) non-existence of reports about successful experiences; and (c) lack of adequate methodology. This work investigated the item (c) through a case study on a real situation at RADIOBRAS, a Brazilian public journalism company. The Text Mining application was developed over 55,000 news in 2001. Considering the results, it is possible to show that, through the KDT - Knowledge Discovery in Text, it is possible to get competitive advantages, showing the existence of satisfactory methodological alternatives to overcome the “Chasm of Moore”. Besides the usual KDT techniques, other methodologies were applied. For example, CRISP-DM, originally developed to KDD (Knowledge Discovery in Database), guided the development process. By this approach, we could verify that it is possible to consider critically the acquired knowledge with KDT in order to benefit the improvement of the organizational efficiency.
Capítulo I -
Introdução
Sendo constantemente desafiadas a se adaptarem às mudanças ambientais, as
organizações estão levando em consideração, entre outros, as expectativas dos clientes, as
es-tratégias competitivas, os avanços tecnológicos, as condições instáveis na economia e na
sociedade.
As organizações podem ser vistas como sistemas de processamento de
informa-ções, alinhavadas na maioria de seus procedimentos administrativos. Assim, a Gestão do
Co-nhecimento pode, por sua vez, ser vista como o conjunto de atividades que busca desenvolver
e controlar todo tipo de conhecimento em uma organização a fim de apoiar seu processo
deci-sório em todos os níveis.
Nesse cenário, a geração e a fixação da inteligência organizacional1 têm-se
reve-lado como diferenciais competitivos que podem levar à gestão mais ágil dos negócios em
di-versos sentidos, não só no relacionamento da organização com os seus clientes como também
na adequação da sua estrutura de trabalho, entre outros.
1
“A inteligência organizacional é um ciclo contínuo de atividades que incluem o sensoriamento do ambiente, o desenvolvimento de percepções e a criação de significados por intermédio de interpretação, utilizando a memória sobre as
experiências passadas e escolhendo ações baseadas nas interpretações desenvolvidas”. (Choo apud Moresi, 2001a, p.44)
“A Inteligência organizacional refere-se à capacidade de uma corporação como um todo de reunir informação, inovar, criar
Capítulo I - Introdução 16
A importância da informação para a elaboração do conhecimento e,
conseqüen-temente, para a síntese da inteligência é largamente reconhecida, requerendo tratamento
ade-quado para obtenção de insights que levem à ativação dos processos mentais, atingindo assim
tal síntese.
Desde o final dos anos 80, pesquisadores em “DCBD - Descoberta de
Conheci-mento em Banco de Dados” vêm dedicando intensivos esforços na disponibilização de
ferra-mentas para a extração de padrões desconhecidos a partir de bancos de dados estruturados,
procurando fazer que essa tarefa seja a mais automatizada possível. Nesse sentido, importantes
avanços permitiram que com o uso da tecnologia fosse possível atravessar o usual “abismo”
existente entre a universidade e o mercado, interessado especialmente em ferramentas para
aplicação direta no processo de tomada de decisão e conseqüente aumento de agilidade e
com-petitividade.
Considerando que a tomada de decisão é um processo de investigação, de
refle-xão e de análise, justifica-se a necessidade de se obter informação qualitativa que contenha
alto valor agregado. Dentre as ferramentas disponíveis para isso destacam-se, aqui, as de
Mi-neração de Textos (Text Mining). Nota-se, no entanto, que tais ferramentas não têm apresenta-do um grau de utilização compatível com seu potencial de aplicação.
Neste trabalho, realizou-se um estudo de caso em uma empresa pública de
jorna-lismo - RADIOBRÁS - para a criação de inteligência organizacional com a aplicação de
fer-ramentas de mineração de texto. Para isso, baseada no questionamento do cumprimento do
papel social da empresa, procurou-se delinear o ambiente informacional sob o foco do modelo
genérico de gestão do conhecimento com análise de padrões extraídos do enorme volume de
Considerando que a RADIOBRÁS é uma importante empresa do Estado,
detendo papel relevante na divulgação dos atos da administração pública do País, fica evidente
a necessidade de uma avaliação embasada no conhecimento sobre os resultados de suas
ativi-dades, pois, como qualquer outra empresa, está sujeita à crescente exigência de
competitivida-de imposta às organizações mocompetitivida-dernas.
Na RADIOBRÁS, procurou-se desenvolver inteligência organizacional com a
aplicação de ferramentas de mineração de texto. Para isso, promoveu-se a análise do ambiente
informacional por meio de padrões extraídos do enorme volume de textos produzidos na
orga-nização, na veiculação de notícias sobre o governo federal brasileiro.
Para testar as hipóteses, aplicou-se a CRISP-DM (CRoss-Industry Standard Process for Data Mining), metodologia originalmente concebida para DCBD. Na aplicação dessa metodologia, foram utilizadas as matérias jornalísticas produzidas ao longo de 2001.
Diversas visões, interna e externa, sobre os rumos da organização foram obtidas
por meio de ferramentas para a extração de padrões em grandes quantidades de dados,
subsidiando os gestores na tomada de decisões. Essas visões, construídas para responder a
questões específicas, formaram um acervo de conhecimento num processo de aprendizagem
organizacional que gerou desdobramentos nos modos de gestão da organização.
Os resultados foram encaminhados à administração da empresa, permitindo
in-terpretações úteis para o conhecimento da organização.
Como nas organizações, a maior parte das informações encontra-se na forma
textual, desenvolvimentos recentes permitiram a extração de padrões relevantes desse tipo de
Capítulo I - Introdução 18
acordo com os assuntos abordados em suas notícias; e (v) avaliação da cobertura jornalística da empresa.
A apresentação do problema, abordando as motivações para desenvolvimento do
projeto, foi feita no Capítulo II. No Capítulo III, fez-se uma explanação sobre o estado da arte
da DCT, enfocando as tecnologias mais recentes sobre o assunto. As metodologias utilizadas
na pesquisa foram abordadas no Capítulo IV.
O estudo de caso aplicado na RADIOBRÁS, para melhor distribuição, foi
divi-dido em três capítulos. No Capítulo V, discorreu-se sobre (i) compreensão do negócio,
(ii) entendimento dos dados e (iii) preparação dos dados. No Capítulo VI, abordou-se a mode-lagem do projeto, incluindo a escolha e a definição das técnicas utilizadas no projeto. No
Capí-tulo VII, discorreu-se sobre as etapas de avaliação e aplicação do conhecimento, geradas no
estudo de caso.
No Capítulo VIII, foram abordados os impactos do conhecimento adquirido na
gestão do conhecimento com base nas informações obtidas do estudo de caso.
Finalmente, no Capítulo IX, apresentaram-se as contribuições deste trabalho, os
Capítulo II -
Apresentação do Problema
Vive-se em um mundo onde a mudança é a regra, o que implica uma constante
necessidade de adaptação e conseqüente busca por recursos de modo a superar as dificuldades
inerentes a tal adaptação.
Essa necessidade de adequação e o curto tempo de resposta requerido pelas
situações de mercado passaram a influenciar diretamente o funcionamento da organização que
deixa de agir somente em relação à sua posição junto aos seus concorrentes para atender
tam-bém ao seu planejamento estratégico.
No mundo moderno, a apropriação do conhecimento tem sido fator
imprescindível para a sobrevivência das empresas. Neste sentido, observa-se que grande parte
das informações encontra-se em forma não-estruturada. No entanto, poucas aplicações são
dirigidas a tal tipo de informação. Assim sendo, desta forma, questiona-se o porquê de as
vantagens das tecnologias de manipulação de informações não-estruturadas ( tais como
textos), não serem revertidas em benefício do melhoramento da eficiência organizacional tanto
quanto esperado.
Neste trabalho, enumeram-se algumas das possíveis razões para a existência de
um “abismo” entre a fase de desenvolvimento e a adoção de tecnologias de Mineração de
Capítulo II - Apresentação do Problema e Motivação 20
2.1 - Importância das Informações Textuais nas Organizações
A tarefa de suprir os administradores com os conhecimentos estratégicos em
tempo hábil tem-se tornado mais difícil devido, entre outros fatores, ao volume da informação
disponível. Estudiosos dessa área afirmam que nos anos de 2001 e 2002 a “quantidade de
in-formação produzida será maior que toda a inin-formação já criada pela humanidade até hoje”
(U-niversity of California, 2000).
Segundo Ah-Hwee Tan (1999), 80% das informações de uma organização
en-contram-se em forma textual apontando para a necessidade de extratores de conhecimento em
bases textuais.
Um processo capaz de gerar conhecimento a partir de dados estruturados é o
KDD - Knowledge Discovery in Database ou DCBD - Descoberta de Conhecimento em Bases de Dados. Esse processo combina diversas áreas da descoberta do conhecimento, tais como
Aprendizagem de Máquina, Reconhecimento de Padrões, Estatística e Inteligência Artificial,
com o objetivo de extrair, de forma automática, informação útil em bases de dados.
Diferentemente da DCBD, o KDT - Knowledge Discovery in Text ou DCT - Descoberta de Conhecimento em Texto lida com dados não-estruturados. Muitas pesquisas
têm sido direcionadas a DCT, por trabalhar com textos, considerada a forma mais natural de
armazenamento de informação (Tan, 1999).
A DCT combina técnicas de extração e de recuperação da informação,
proces-samento da linguagem natural e sumarização de documentos com os métodos de DM - Data Mining (Dixon, 1997). Não se encontram, todavia, metodologias que definam um plano de uso dessas técnicas (Wives, 2000), o que, segundo Loh (2000a), deixa uma lacuna sobre
como uma coleção textual deve ser investigada de forma automática ou semi-automática, a fim
2.2 - Uso de mineração de texto
no mundo
Segundo a pesquisa apresentada em Nuggets (2001) (Figura 2.1), text mining re-presenta atualmente apenas 2% das técnicas usadas regularmente para mineração de dados.
Mesmo sem apresentar caráter científico, essa pesquisa revelou que o uso da DCT ainda é
in-cipiente no mercado mundial. Se agregado o webmining, esse percentual sobe para 7%, o que é muito pouco se comparado com o volume de dados existente.
Fonte: Nuggets (Nuggets, 2001)
Figura 2.1 - Comparação de uso entre técnicas de mineração.
2.3 - ‘Abismo’ de Moore
Geofrey Moore op. cit. in Agrawal (2001) propõe um modelo (ciclo de vida) que descreve o comportamento dos consumidores de tecnologias em áreas emergentes (Figura
2.2). Esse modelo define cinco tipos de usuários: os inovadores, os adeptos iniciais, a maioria
Capítulo II - Apresentação do Problema e Motivação 22
Figura 2.2 - Ciclo de vida de adoção de tecnologia.
Os inovadores são os primeiros clientes em tudo o que é novo. Comprometidos
com a tecnologia, sentem prazer em dominar suas complexidades pelo simples fato de
explrá-las. Querem ter acesso à última palavra em inovação, além de serem influenciadores de
o-piniões.
Os adeptos iniciais são revolucionários dispostos a usar a descontinuidade de
qualquer inovação com expectativas de obter vantagem competitiva. Formam um grupo
im-portante para a inovação tecnológica, por ser o primeiro grupo capaz de trazer recursos para a
empresa fornecedora dessa tecnologia.
A maioria inicial não explora a tecnologia em si, como os inovadores e os
adep-tos iniciais, mas procura adotar inovações somente quando comprovada a utilidade dela e
quando referenciada por pessoas em quem confiam. Prefere a evolução ao invés da revolução
em termos de novos produtos.
A maioria tardia só investe em tecnologia quando é obrigada pelas
circunstân-cias. Cético e exigente esse grupo é sensível a preços.
Já os retardatários combatem as inovações tecnológicas e os entusiastas de
Essa classificação, bastante oportuna e realista, no entanto, não é a mais valiosa
contribuição do estudo de Moore. Sua principal constatação é a existência de um “abismo”
entre as fases (2) e a (3), ou seja, uma descontinuidade entre a introdução do produto no
mer-cado e sua consolidação como um produto de larga escala. É nesse “abismo”, segundo o autor,
que a maioria das empresas falha por não dispor do instrumental de marketing adequado para
lidar com a situação.
Uma das motivações deste trabalho foi a crença de que a mineração de texto
en-contra-se exatamente neste ponto. A partir daí, pôde-se levantar algumas razões do porquê de
a mineração de textos não ser ainda muito difundida, o que indica não ter atravessado ainda o
“abismo de Moore”: (i) falta de uma tecnologia adequada no que se refere à exigência de usa-bilidade; (ii) poucos relatos de experiência de sucesso; e (iii) inexistência de uma metodologia adequada para guiar os usuários nas aplicações de Mineração de texto;
2.4 - Colocação do Problema
Como visto, existe um enorme acervo de informações textuais nas organizações
que pode ocultar conhecimentos valiosos. Apesar disso, é incipiente o uso de tecnologias de
DCT. Questiona-se, neste trabalho, as razões para essa contradição.
2.5 - Objetivos
O objetivo deste trabalho foi estudar e propor alternativas para a travessia do
a-bismo de Moore pelas tecnologias de DCT. Para isso, este trabalho foi direcionado a
finalidade de:
Capítulo II - Apresentação do Problema e Motivação 24
(ii) Explorar a possibilidade de uso de uma metodologia de DCBD para desenvolver aplicações em DCT;
(iii) Mostrar a possibilidade de uso efetivo da mineração de texto por meio de um es-tudo de caso real.
2.6 - Caracterização e Articulação da Pesquisa
O problema consiste em verificar se o uso incipiente da tecnologia de DCT, em
face da enorme disponibilidade de texto nas organizações, deve-se à ausência de uma
metodo-logia adequada para o desenvolvimento de aplicações práticas.
Esse tipo de problema comporta, naturalmente, uma abordagem de solução
ba-seada em um estudo aplicado. Assim, a pesquisa foi articulada com base em um estudo de
caso no qual foram aplicadas diversas abordagens encontradas na literatura. O objetivo foi
transpor o ‘abismo’ de Moore com o uso desse ferramental e, dessa forma, descaracterizar o
mito da inexistência de metodologias adequadas para aplicações práticas de DCT como
Capítulo III -
O Estado da Arte da DCT
A descoberta do conhecimento ocorre por meio de complexas interações
reali-zadas entre o homem e uma base de dados, geralmente por meio uma série heterogênea de
fer-ramentas (Fayyad, 1996).
Segundo Stanley Loh op. cit. in Wives (2000), existem três grandes áreas que lidam com informações em grandes bases de dados: (i) Data Mining (Mineração de Dados) para dados estruturados - DCBD; (ii) IE - Information Extraction (Extração de Informações) para dados não-estruturados - DCT; e (iii) IR - Information Retrieval (Recuperação da Infor-mação) para textos ou palavras - DCT.
Neste capítulo, foram abordados os métodos, etapas, técnicas e modelos de
re-cuperação em DCT. Foi mostrada também a diferença entre DCT e ferramentas de busca,
tec-nologias comumente confundidas.
3.1 - KDT - Knowledge Discovery in Text
O KDT - Knowledge Discovery in Text ou DCT - Descoberta de Conhecimento em Texto, ao contrário da DCBD, lida com dados não-estruturados. Mais recentemente,
Capítulo III - Estado da arte do DCT 26
A DCT combina técnicas de extração, recuperação de informação,
processamento da linguagem natural e sumarização de documentos com os métodos de
DM - Data Mining (Dixon, 1997). Por lidar com dados não-estruturados, a DCT é considerada mais complexa que a DCBD.
Seu objetivo é extrair conhecimento de bases em que as ferramentas
usuais não são capazes de agirem, por não estarem equipadas, ou terem sido desenvolvidas
para soluções em dados estruturados (bancos de dados relacionais, por exemplo).
A DCT pode ser considerada um processo de DCBD para dados
não-estruturados como, por exemplo, aqueles encontrados na Internet ou ainda em organizações
que ultimamente, pela facilidade e barateamento de custos, vêm armazenando quantidades
crescentes de texto em meios magnéticos.
A necessidade de se extrair e recuperar informação desses meios é uma
constan-te tanto na vida das pessoas, como no conconstan-texto das organizações. No entanto, a dificuldade de
se fazer uso adequado das informações disponibilizadas, é quase sempre fonte de frustrações.
Suas principais áreas são a IE - Information Extraction (Extração de Informa-ções) e a IR - Information Retrieval (Recuperação da Informação).
3.1.1 – Extração da Informação
A área de IE estuda metodologias, técnicas e ferramentas que possam encontrar
dados específicos dentro de textos, extraindo automaticamente valores de atributos tais como
campos de um banco de dados. Em geral, as aplicações nessas áreas são dependentes do
domí-nio, isto é, só apresentam bom desempenho com certas classes de documentos. Essa área
encontrar textos e documentos relevantes, tendo como fundamento determinadas necessidades,
a IE busca encontrar informações dentro desses textos.
Segundo Gerald Kowalski op. cit. in Wives (1999), o objetivo de um processo de IE é o de transformar dados semi-estruturados ou não-estruturados em dados estruturados,
visando a armazená-los em banco de dados. Essa tarefa é considerada pré-processamento na
descoberta do conhecimento em textos.
Sumarização
Entre as técnicas da IE, a sumarização, tem o objetivo de extrair resumos de
tex-tos (ou de uma coleção de textex-tos), apresentando como resultado seus termos (palavras ou
fra-ses) mais importantes (Palazzo, 2000; Wives, 2000). Esse resumo oferece ao usuário uma
visão geral das informações contidas nos textos, permitindo-lhe identificar, sem ter de ler na
íntegra, os assuntos abordados pela coleção analisada.
Uma forma eficiente de sumarização empregada, geralmente, depois dos
proces-sos de agrupamento, é a análise de centróide2. Essa análise corresponde ao conjunto de
pala-vras mais significativas de determinado grupo (cluster) que são usados para identificá-lo.
Etapas de IE
Segundo Ralph Grishman op. cit. in Dixon (1997) existem três etapas no proces-so de extrair informação:
(i) Extração de fatos – cujo objetivo é encontrar fatos individuais no documento. Nessa fase, o conhecimento específico é crucial, devido à
possibili-dade de uso de técnicas de reconhecimento de padrões, a fim de encontrar os
2
Capítulo III - Estado da arte do DCT 28
tos procurados, tais como: Casamento de Padrões, Análise Léxica e Estruturas Sintática e Semântica;
(ii) Integração de Fatos - vista como o principal meio de analisar um pequeno fato em relação “à grande pintura” na qual se vê a formação e a interação entre os
fa-tos;
(iii) Representação do Conhecimento - é a forma como as informações extraídas dos documentos são colocadas à disposição do usuário. Entre os vários estilos de
re-presentação, a forma gráfica continua sendo a mais comum.
Para cada uma dessas etapas, existem diversas técnicas que podem ser usadas a
fim de atingir os objetivos propostos. Ralph Grishman op. cit. in Dixon (1997) afirma que em todas essas técnicas existe uma convergência para uso do processamento da linguagem natural,
técnicas avançadas de estatística e uso freqüente de redes neurais.
3.1.2 – Recuperação da Informação
A área de IR tem por objetivo localizar os documentos que contêm informações
relevantes para atender às necessidades definidas pelo usuário em uma consulta. Nesse caso, o
usuário precisa examinar os documentos resultantes dessa busca para encontrar a informação,
o que é uma tarefa demorada. Para localizar essas informações, faz-se uso da indexação,
efetu-ando uma busca mais rápida e eficiente. Essa indexação é considerada como um tipo de filtro
(Lancaster op. cit. in Wives, 2000) capaz de selecionar e identificar as características de um documento, extraindo os termos mais significativos e excluindo aqueles que não são
A indexação pode ser, segundo Ricardo Baesa Yates op. cit. in Wives (2000), de três formas:
(i) Tradicional - os termos descritivos dos documentos são selecionados manual-mente, especificando quais farão parte do índice;
(ii) Full-text - os termos que compõem o documento são usados como parte do índice;
(iii) Por parte do texto (tags) - a seleção dos termos é feita de forma automática. A indexação tradicional é comumente usada na área da Ciência da Informação,
em que o controle do índice é feito com intervenção humana. Isso facilita a organização em
topologias, agrupando as palavras mais importantes por determinada área de atuação, por
exemplo, o thesaurus automático3 .
Nesse tipo de indexação, o tempo para execução é mais longo. Levando-se em
consideração que o trabalho é realizado de forma manual, é possível que se cometam erros no
momento de inserir determinado termo ao grupo correspondente. Isso, aliado ao
desconheci-mento de tais grupos pelos usuários, pode gerar um resultado nulo em uma pesquisa, mesmo
que o termo conste na base de dados.
Na indexação total (full-text), a vantagem é ter todos os elementos dispostos em índices. Porém, para que isto ocorra, a indexação torna-se volumosa, requerendo muito espaço
para o armazenamento (William Frakes op. cit. in Wives, 2000). Uma forma de contornar esse problema é o uso de técnicas, como a lista invertida, árvores de TRIE 4 ou árvores de PAT5.
3
Nas pesquisas na área Banco de Dados Documentais (BDD), observa-se que o thesaurus é uma ferramenta bastante útil para a indexação e a recuperação de informações textuais e em sua grande maioria construídos manualmente. Nesse sentido,
Edberto Ferneda (Ferneda, 1997)apresenta um sistema para construção automática do thesaurus.
4
Estrutura em árvore, criada especialmente para indexar palavras usadas como um “dicionário”, em que cada nodo é um
Capítulo III - Estado da arte do DCT 30
A indexação via tags procura indexar apenas partes relevantes do texto (Anil Chakravarthy op. cit. in Wives, 2000). De forma automatizada, a ferramenta percorre o documento e localiza marcas que identificam os trechos mais importantes do texto os quais
são incluídos no índice.
Segundo Bernard Moulin op. cit. in Wives (2000), a procura das marcas (tags) pode ser feita de forma automática: (i) mediante o uso de documentos que utilizam macroes-truturas (cabeçalhos, títulos, capítulos); (ii) microestruturas - conteúdo lógico do texto, identi-ficando seus pontos principais (condições, exceções, referências); e (iii) uma camada de domínio com as demais informações do documento.
Formas de Indexação
Os índices mencionados no tópico anterior podem ser automáticos ou manuais.
No último caso, a elaboração é conduzida diretamente pela área de biblioteconomia. No
pri-meiro caso, os índices encontrados automaticamente são mais usados e mais relevantes por
serem mais ágeis.
Quando se lida com índices, deve-se levar em conta seu fator de
exaustividade. Esse fator mede a quantidade de assuntos distintos que determinado índice é
capaz de reconhecer. Para maior abrangência, o fator de exaustividade também é maior e,
nes-te caso, a precisão é inversamennes-te proporcional. Isto se deve ao fato de que mais palavras
po-dem levar ao mesmo item (Lancaster op. cit. in Wives, 2000).
Para análise de informações em textos, os índices são peças importantes, pois
eles são uma das formas de validar o desempenho e a precisão da recuperação da informação.
5
Estrutura parecida com a árvore de TRIE, em que o documento é visto como uma cadeia de caracteres e cada uma de suas
Na Figura 3.1, são apresentadas as etapas de um processo de indexação automática, segundo
Riloff op. cit. in Wives (2000).
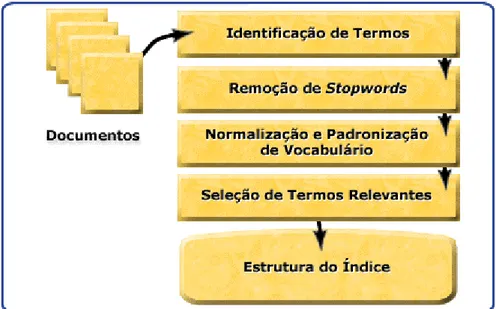
Figura 3.1 - Etapas em uma indexação automática.
Essas etapas, segundo esse autor, não são rígidas, pois, dependendo do contexto,
a ordem de aplicação pode variar ou mesmo não ser utilizada. Resumidamente, essas fases
podem ser assim descritas:
(i) Identificação de termos
Consiste na aplicação de um parser6 que identifica as palavras importantes do texto, ignorando símbolos e caracteres de controle de arquivo ou de formatação. Envolve
tam-bém o uso de seqüências de caracteres a fim de validá-las (dicionário ou thesaurus).
Segundo Wives (2000), essa etapa deve considerar e tratar termos compostos
(por exemplo: processo judicial, processo computacional) por considerar que podem fazer
parte do mesmo índice para não perderem o significado que as palavras expressam quando
es-tão juntas.
6
Analisador léxico que consiste na conversão de uma cadeia de caracteres de entrada em uma cadeia de palavras ou token
Capítulo III - Estado da arte do DCT 32
(ii) Remoção de Stopwords
Para minimizar o esforço da elaboração do índice, faz-se a remoção das
chamadas stopwords. Essas palavras contribuem pouco para o significado de um texto. Usualmente artigos, preposições e advérbios são consideradas stopwords por serem bastante freqüentes e sua eliminação leva a uma redução entre 40% e 50% dos textos a serem
analisa-dos.
(iii) Normalização
Para atender a determinados objetivos, é importante a eliminação de variações
morfológicas de uma palavra. A identificação é efetuada através do radical de uma palavra.
Segundo William Frakes op. cit. in Wives (2000), existem diversas formas para se identificar esses radicais, como a lematização ou stemming.
A vantagem é que, em uma busca, o usuário não precisa se preocupar com a
classe da palavra, podendo ela aparecer no texto como um substantivo, um verbo ou um
adje-tivo. No entanto isto implica diminuição na precisão da pesquisa.
(iv) Seleção de Termos Relevantes
Deve-se considerar que em um texto as palavras têm níveis de destaque
distintos. Aquelas mais freqüentes, excetuando-se as stopwords, são mais importantes que ou-tras que aparecem com menos freqüência. Palavras encontradas nos tópicos em destaque,
co-mo títulos e ainda os substantivos, devem ser destacadas, pois são consideradas mais
relevantes.
Um dos recursos utilizados para descobrir a importância dessas palavras é
no qual ela aparece e que pode ser calculada pela freqüência absoluta7 ou pela freqüência
rela-tiva8.
Usando esses pesos ou sua posição sintática é possível então diminuir o índice
deixando-o mais consistente e com palavras relevantes.
3.2 - Tecnologias para descoberta do conhecimento em Texto
As tecnologias usadas na DCT não são consideradas inovadoras do ponto de
vis-ta de sua origem, uma vez que muivis-tas advêm da DCBD. O que é novo é seu uso para
descoberta do conhecimento em dados armazenados na forma de texto.
Isto não significa que a DCT utiliza somente técnicas da DCBD. A DCT inclui
quaisquer técnicas que possam ser usadas para buscar informação em dados não-estruturados.
Isto dependerá, entre outros fatores, de como se quer adquirir essa informação e da maneira
como se apresenta o problema.
3.2.1 - Descobertas Reativa e Proativa
Segundo Choudhury op. cit. in Loh (2000) a descoberta de conhecimento ocorre de dois modos: o reativo e o proativo.
No modo reativo, o objetivo é direcionado para a solução especificada pelo
usuário que, nesse caso, sabe como solucionar o problema. O usuário segue utilizando pistas
que deseja provar, direcionando o processo de descoberta. Ele sabe o que quer e tem idéia de
onde achar a resposta. Nesse modo, o usuário deve definir, da forma a mais precisa possível,
sua necessidade, o que muitas vezes contradiz o processo da descoberta. Na maioria das vezes,
7
Quantidade de vezes que o termo foi encontrado no texto.
8
Capítulo III - Estado da arte do DCT 34
o que acontece é o usuário não saber especificar as necessidades para resolução dos seus
pro-blemas.
No modo proativo, ao contrário, sem que haja uma intervenção inicial do
usuá-rio, as informações úteis para resolução do problema são encontradas automaticamente. Dessa
maneira, o problema é definido pelo usuário, mas a descoberta ocorre de modo
não-supervisionado. Uma expressão comum para definir o modo proativo é “diga-me o que há
de relevante nesse conjunto de dados”. Mesmo não tendo a intervenção inicial, o usuário
parti-cipa nesse processo exploratório com retroalimentação e interatividade no processo. Esse
mo-do assemelha-se à Mineração de Damo-dos na DCBD e poderia ter como exemplos de objetivos:
(i) criar parâmetros para entender o comportamento do consumidor; (ii) identificar afinidades entre as escolhas de produtos e serviços; (iii) prever hábitos de compras; (iv) analisar compor-tamentos habituais para detectar fraudes.
De maneira geral, poder-se-ia dizer que o processo da descoberta do
conheci-mento é realizado, mais freqüentemente, na forma proativa. Esse processo compõe-se das
se-guintes fases (Michael Goebel op. cit. in Wives, 2000):
(i) Entendimento do domínio de aplicação e definição do objetivo do processo de descoberta;
(ii) Aquisição ou seleção do conjunto de dados;
(iii) Integração e verificação do conjunto;
(iv) Limpeza dos dados (pré-processamento e transformação);
(v) Desenvolvimento de um modelo inicial ou construção de hipóteses;
(vi) Escolha e aplicação de métodos de mineração;
(vii) Visualização e interpretação dos resultados;
(ix) Uso e manutenção do conhecimento descoberto (tomada de decisão no domínio).
3.2.2 - Inteligência Competitiva
Em geral, quando usamos as técnicas do conhecimento proativo ou reativo,
es-tamos em busca de definição de estratégias e ações que devem ser realizadas em prol da
orga-nização. Esses são exatamente os objetivos da Inteligência Competitiva9 que, entre outros,
busca impulsionar o negócio da organização.
No uso da inteligência competitiva, as etapas são flexíveis, pois se devem
ade-quar aos objetivos da empresa. Isto só ocorrerá se ela tiver definidas suas necessidades reais.
Dependerá também das informações necessárias para estimular seu negócio, bem como da
de-finição das fontes dessas informações.
As atividades da Inteligência Competitiva visam a explorar e manter conhecido
o ambiente externo da organização. Nesse cenário, a Internet é considerada fonte importante
de informação, ajudando na busca de novos nichos de mercado e tecnologias inovadoras.
Loh (2000a) sugere como proposta para executar essas atividades em
dados não-estruturados, as seguintes etapas:
(i) Identificação da necessidade de informação - nessa etapa, devem-se identificar quais são as necessidades de informação de cada pessoa na empresa
(principal-mente dos tomadores de decisão), quais dessas informações a própria empresa
pode suprir e quais vão demandar dados externos;
9
“Inteligência Competitiva refere-se ao conjunto de atividades de monitoramento e de análise de dados do ambiente com o
objetivo de fornecimento de informações úteis ao processo decisório e de planejamento estratégico empresarial.” (GESID
apud Canongia 2001)
“A ‘Inteligência Estratégica’ enfatiza a busca de informações para a tomada de decisão e para o planejamento estratégico; ‘Inteligência para Negócios’ é o monitoramento de informação sobre negócios e mercados; ‘Inteligência Competitiva’ foca informações sobre produtos e serviços oferecidos por empresas similares; ‘Inteligência Tecnológica’ enfoca informações de
Capítulo III - Estado da arte do DCT 36
(ii) Identificação e análise de fontes de informação - uma vez conhecidas as neces-sidades de informação, torna-se importante identificar de quais fontes essas
in-formações podem ser recuperadas, podendo ser internas ou externas. No caso de
fontes externas, é importante que sejam identificados o formato, o tempo de
aces-so e o custo delas, assim como a forma de agregá-las às existentes na empresa;
(iii) Coleta - é a busca, em si, da informação ou dos dados nas fontes identificadas;
(iv) Filtragem - por causa da grande quantidade de dados e informações que podem ser coletadas, é possível que muitas não estejam relacionadas às necessidades
i-dentificadas
inicialmente. As informações irrelevantes devem ser descartadas e as relevantes
selecionadas;
(v) Distribuição - os dados ou as informações selecionadas devem ser encaminhadas às pessoas que expressaram sua necessidade;
(vi) Exploração - corresponde à transformação dos dados em informação e conheci-mento. Podendo-se utilizar ferramentas computacionais e métodos estatísticos de
análise;
(vii) Segurança - adquiridos os conhecimentos e informações, estes devem ser postos em prática (utilizados na tomada de decisão) e armazenados em algum local
se-guro com vistas a resguardar essas informações.
3.2.3 - Tipos de Descoberta
A área de aquisição do conhecimento engloba diversos tipos de descoberta, com
várias abordagens específicas para DCT. Segundo (Wives, 2000a) esses tipos de descoberta
(viii)Estruturas de textos; (ix)Clustering; (x) Classes de textos; (xi) Recuperação de informação; (xii)Associação entre textos; (xiv)Associação entre as características;
(xv) Hipertextos; (xvi) Manipulação de formalismo; (xvii) combinação de representações e;
(xviii) Comparação de modelos mentais.
É comum quando se abordam as tecnologias de DCT haver confusão inicial, por
acreditar-se que a descoberta de conhecimento no texto e o uso de ferramentas de busca são a
mesma coisa. Na seção 3.3, são estabelecidas as principais diferenças entre essas tecnologias.
3.3 - Diferenças entre Mineração de texto e
Ferramentas de Busca
A DCT é uma tecnologia recente, do ponto de vista de sua utilização no
mercado de mineração de dados (Tan, 1999) e, talvez seja essa a razão pela qual seus objetivos
serem, muitas vezes, confundidos com as ferramentas de busca na Internet (search engine). Essas ferramentas foram desenvolvidas e aperfeiçoadas para atender à crescente
necessidade de se encontrar dados na gigantesca massa de informação disponibilizada na
Internet. Seu uso e importância são incontestáveis, visto que sem elas ficaria muito difícil
lo-calizar, em pouco tempo, informações tão dispersas. Elas prestam um serviço fundamental de
procura rápida e indexação de informações, entretanto, seu escopo é diferente da mineração de
texto.
Para se verificar a necessidade de melhorar a análise em texto basta que se faça
uma busca, usando ferramentas como o altavista® ou google®. O resultado freqüente dessa busca é outro grande volume de dados. Comumente, escolhem-se os primeiros resultados que
são então analisados, visando a selecionar as informações necessárias. Pode-se afirmar que tal
procedimento é cabível para descobrir as informações, mesmo sendo uma tarefa que necessita
Capítulo III - Estado da arte do DCT 38
Quando se trabalha com uma pequena escala, esse procedimento é viável. Caso
haja necessidade de maior refinamento na busca de informações e essa escala aumenta,
torna-se necessário o uso de outra metodologia. Para quem necessita analisar diariamente
grandes volumes de dados como, por exemplo, pesquisadores, juízes, consultores e editores,
essa tarefa é impraticável (Tan, 1999).
A necessidade de melhoria da análise, nesse ambiente, torna-se ainda mais
rele-vante quando se verifica que há crescente aumento desse tipo de informação.
A principal diferença entre as ferramentas de busca e a mineração de texto é que
a primeira emprega o uso de busca exaustiva. Sua pesquisa é realizada com base em
palavras-chave que basicamente retornam a uma lista de documentos relevantes, ordenados
pela proporção em que esses termos são encontrados em determinado documento (por
exem-plo: página web, texto, arquivos pdf). Esse resultado é então analisado e requer sua leitura para
extração do conhecimento.
A mineração de texto, ao contrário, utiliza métodos de busca baseados em
análi-ses gramaticais e léxicas ou ainda técnicas de clustering (agrupamento). Isso permite descobrir conteúdos demonstrados por meio de palavras ou frases similares entre os documentos.
Além disso, a mineração de texto agrega técnicas de visualização de dados.
Es-sas técnicas permitem mostrar conceitos-chave e relações entre palavras e idéias. Partindo
des-sa visualização, é possível detalhar dados ou “trilhar” caminhos para outros documentos.
Em resumo, pode-se afirmar os seguintes pontos em relação à mineração de
texto:
(ii) Processa documentos eliminando a análise “manual” direta. Categoriza, classifica ou constrói árvores de tópicos e índices de documentos;
(iii) Provê identificação automática e indexação de conceitos entre os textos;
(iv) Apresenta, por meio de técnicas de visualização, o escopo global dos dados. Permite detalhamento quanto ao grau de relevância;
(v) Permite aos usuários fazerem associações, correlacionamentos e âncoras entre os documentos para posterior análise.
As duas tecnologias são essenciais para quem lida com grandes volumes de
da-dos não-estruturada-dos, pois oferecem suporte na busca de informações úteis em textos10 ou em
páginas web.
A mineração de textopermite, todavia, descobrir conceitos-chave e grupos
simi-lares de documentos, sem que haja necessidade prévia de leitura integral dos documentos.
3.4 - Síntese do Capítulo
Conforme enfatizado neste capítulo, a DCT é uma área que provê tecnologias
efetivas para descoberta de conhecimento em bases de dados não-estruturadas. Destarte, é
ob-tido conhecimento na forma de conceitos em que as ferramentas usuais de mineração não
es-tão aptas a fazê-lo.
Observa-se um vasto campo para desenvolvimento de aplicações de descoberta
de conhecimento em texto em função da quantidade e da disponibilidade de informações nas
organizações. As redes corporativas (intranets e extranets), bem como os diversos dados
pro-venientes dos mais variados sistemas oferecem uma rica fonte de conhecimento ainda não
ex-plorada totalmente.
10
Capítulo III - Estado da arte do DCT 40
A necessidade de exploração dessa fonte de informação é justificada por
inúme-ros fatores, entre os quais podem-se citar: (i) Concorrência acirrada; (ii) Quantidade crescente de informação de domínio público; (iii) Aumento na quantidade de informações armazenadas em meio magnético; (iv) Fontes inexploradas de dados não-estruturados; (v) Necessidade de conhecimento para tomada de decisão pelos administradores.
Nesse estudo, identificaram-se diversas técnicas de DCT muitas delas advindas
da DCBD que, por ser um segmento mais utilizado, está servindo como fonte de recursos e
referências.
Confrontando os diversos fatores estudados, verificou-se que as tecnologias de
DCT ainda são pouco aplicadas, se consideradas a enorme disponibilidade de dados textuais
existentes, como mostrado na pesquisa realizada pela School of Information Management and Systems at the University of California (University, 2000), onde foi feita uma projeção que para 2001 e 2002 seriam criadas e disponibilizadas mais informações do que em toda a história
da humanidade. Outro trabalho (Tan, 1999) indica que essas informações estarão, em sua
mai-oria, na forma não-estruturada.
A DCT encontra-se num momento em que precisa superar a lacuna entre o nível
acadêmico e o prático. É importante a aplicação de novos estudos de casos em situações reais.
Como foi visto, no entanto, as propostas de métodos, técnicas e ferramentas da DCT carecem
ainda de aperfeiçoamentos. É real o uso de técnicas de DCBD na DCT. Com essa visão, uma
proposta futura para estudos seria a agregação de metodologias usadas atualmente em dados
A DCT resgata tecnologias para serem usadas em ramos adjacentes ao texto. É o
caso do web mining, muito em foco atualmente. Suas derivações, como o XMLminer, tendem a crescer na mesma proporção que o uso da Internet.
Em síntese, pode-se inferir que a proposta da DCT está solidificada como
alter-nativa para extração do conhecimento no mundo dos negócios. Isto é confirmado se observado
como o ambiente das organizações direciona-se para uma geração cada vez maior de dados
Capítulo IV -
Metodologia
Como visto anteriormente, a área de DCBD - Descoberta do Conhecimento em
Bases de Dados e a DCT -Descoberta do Conhecimento em Texto são possíveis alternativas
para descoberta do conhecimento, contemplando respectivamente, dados estruturados e
textu-ais. A DCBD e a DCT objetivam encontrar, por meio de técnicas e algoritmos, padrões,
corre-lações ou similaridades entre dados. Devido à semelhança entre essas tecnologias de
descoberta de conhecimento, foi utilizada neste estudo de caso a metodologia CRISP-DM -
CRoss-Industry Standard Process for Data Mining, originalmente concebida para aplicações de DCBD.
Este capítulo inicia-se com a descrição da metodologia CRISP-DM e segue com
apresentação das metodologias de Palazzo, Ah-Hwee Tan e Halliman, para DCT. Ao final,
descreve-se a abordagem de uso de cada uma, procurando destacar as contribuições delas no
processo de descoberta do conhecimento no estudo de caso aplicado na RADIOBRÁS.
4.1 - CRISP-DM
Com o intuito de promover a padronização de conceitos e técnicas na busca de
CRISP-DM (CRoss-Industry Standard Process for Data Mining11) (Chapman, 2001). Esse grupo propôs uma metodologia como o mesmo nome, destinada a auxiliar administradores e
responsáveis no processo geral de planejar e executar a mineração de dados, englobando a
es-pecificação do processo até a apresentação dos resultados. Esse grupo era composto por três
empresas pioneiras no setor: a DaimlerChrysler, a SPSS (Data Mining) e a NCR (Data Warehouse).
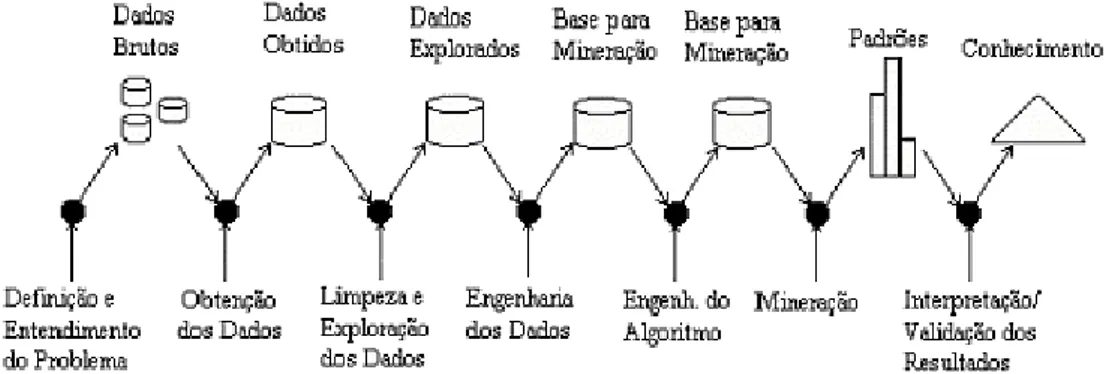
Para a CRISP-DM, o ciclo de vida do processo de DCBD segue uma seqüência
de etapas, conforme mostrada na Figura 4.1. Essas etapas são executadas de forma interativa.
Assim, pelas entradas e respostas providas pelo usuário, a seqüência da execução pode ser
al-terada. O encadeamento das ações, dependendo do objetivo e de como as informações se
en-contram, permite retorno a passos já realizados. Essa metodologia é constituída de seis etapas:
(i) compreensão do negócio; (ii) compreensão dos dados; (iii) preparação dos dados; (iv) mo-delagem; (v) avaliação; e (vi) aplicação.
A Compreensão do Negócio procura identificar as necessidades e os objetivos
do negócio do cliente, convertendo esse conhecimento numa tarefa de mineração de dados.
Busca detectar eventuais problemas e/ou restrições que, se desconsideradas, poderão implicar
perda de tempo e esforço em obter respostas corretas para questões erradas. Essa tarefa
com-preende ainda descrição do cliente, seus objetivos e descrição dos critérios utilizados para
de-terminar o sucesso do seu negócio.
11
Capítulo IV - Metodologia 44
Figura 4.1 - Ciclo de vida de DCBD segundo a CRISP-DM.
A Compreensão dos Dados visa a identificar informações que possam ser
relevantes para o estudo e uma primeira familiarização com seu conteúdo, descrição,
qualidade e utilidade. A coleção inicial dos dados procura adquirir a informação com a qual se
irá trabalhar, relacionando suas fontes, o procedimento de leitura e os problemas detectados.
Nessa tarefa, descreve-se ainda a forma como os dados foram adquiridos, listando seu
forma-to, volume, significado e toda informação relevante. Durante essa etapa, são realizadas as
pri-meiras descobertas.
A Preparação dos Dados consiste numa série de atividades destinadas a obter o
conjunto final de dados, a partir do qual será criado e validado o modelo. Nessa fase, são
utili-zados programas de extração, limpeza e transformação dos dados. Compreende a junção de
tabelas e a agregação de valores, modificando seu formato, sem mudar seu significado a fim
de que reflitam as necessidades dos algoritmos de aprendizagem.
Na Modelagem, são selecionadas e aplicadas as técnicas de mineração de dados
para teste permite construir um mecanismo para comprovar a qualidade e validar os modelos
que serão obtidos. A modelagem representa a fase central da mineração, incluindo escolha,
parametrização e execução de técnica(s) sobre o conjunto de dados visando à criação de um ou
vários modelos.
A Avaliação do Modelo consiste na revisão dos passos seguidos, verificando se
os resultados obtidos vão ao encontro dos objetivos, previamente, determinados na
Compreen-são do Negócio, como também as próximas tarefas a serem executadas. De acordo com os
re-sultados alcançados, na revisão do processo, decide-se pela sua continuidade ou se deverão ser
efetuadas correções, voltando às fases anteriores ou ainda, iniciando novo processo.
A Aplicação é o conjunto de ações que conduzem à organização do
conhecimento obtido e à sua disponibilização de forma que possa ser utilizado eficientemente
pelo cliente. Nessa fase, gera-se um relatório final para explicar os resultados e as
experiências, procurando utilizá-los no negócio.
Uma vez que a CRISP-DM foi concebida para aplicações de DCBD, pode-se
confrontar essa metodologia com o trabalho desenvolvido por Prado (1998) que discorre sobre
o processo completo de Descoberta do Conhecimento em Banco de Dados (Figura 4.2). Essa
abordagem será explorada nas seções seguintes.
Capítulo IV - Metodologia 46
4.1.1 - Definição e Entendimento do problema
Quando se inicia um processo de DCBD, é fundamental saber aonde se quer
chegar e entender o problema de forma real. Esse entendimento caracteriza-se pela
materiali-zação do problema, com a identificação de objetivos que possam, de alguma forma, serem
mensurados. É imprescindível para o êxito do processo delinear a necessidade do cliente. Essa
fase, quando negligenciada, afeta irreversivelmente o processo de DCBD. Sendo assim,
deve-se aliar a extração do conhecimento à definição do problema ao longo de todo processo.
Segundo a CRISP-DM, essa fase do projeto envolve as tarefas de:
(i) levantamento dos objetivos do negócio; (ii) avaliação da situação; (iii) levantamento das metas da mineração; e (iv) execução do planejamento do projeto.
4.1.2 - Obtenção e Extração dos Dados
Essa fase visa, por meio do entendimento do problema, a adquirir uma coleção
de dados necessários para sua resolução. Procura-se entender e descobrir problemas na
quali-dade dos dados e/ou na sua padronização.
Geralmente, aplica-se datawarehousing com vistas a tornar disponíveis dados de fontes heterogêneas de diferentes formas e padrões, o que permite a vantagem de se ter uma
fonte de dados concisa e padronizada.
Segundo Prado (1998), para a execução dessa etapa, duas atividades são
empre-gadas:
(i) Exercício intelectual do analista e do especialista- definição dos atributos a se-rem considerados. Infelizmente, essa atividade é executada com alto grau de
(ii) Extração física dos dados das diversas fontes - atividade complexa por envolver muitos fatores, tais como: apresentação de arquivos em formatos diferentes dos
que constam na documentação, carência de padrão na codificação e versões
desa-tualizadas. Por causa disso, os analistas geralmente procuram incluir toda
infor-mação considerada útil a fim de não ser necessária reexecutar a atividade.
Segundo a CRISP-DM, podem-se definir as seguintes tarefas para essa fase:
(i) levantamento inicial dos dados; (ii) descrição inicial dos dados; e (iii) análise da qualidade dos dados.
4.1.3 - Limpeza e Exploração dos Dados
Essa fase tem como objetivo executar os passos necessários para a construção
do conjunto de dados a ser usado para extração do conhecimento. Procuram-se descobrir
in-formações novas, agrupar conjuntos importantes de dados, proporcionando a familiarização e
realizando um exercício de aproximação com esses dados.
Análises de veracidade também são executadas nessa fase. Segundo John
(1997), dependendo do aspecto que se quer analisar, podem ser observadas relações entre
atri-butos, verificando os resultados de objetivos predeterminados e como eles deveriam
comportar. Isso pode eliminar códigos ou padrões referidos a determinados campos que, fora
do limite esperado, bem como refletir resultados anômalos na mineração dos dados.
Essa fase do processo, conforme a CRISP-DM, é cumprida com a execução das
tarefas de: (i) seleção dos dados; e (ii) limpeza dos dados.
4.1.4 - Engenharia dos Dados
Servindo-se da base de dados, resultante das fases anteriores, verificar-se-á se é
Capítulo IV - Metodologia 48
subconjuntos tanto no que se refere a atributos quanto a termos de tuplas. A obtenção de
amos-tras significativas de dados deve ser feita com a aplicação de técnicas de estatística.
Uma técnica com esse propósito é apresentada por John (1997). Mediante a
construção de diversos modelos, com base em diferentes conjuntos de atributos, verifica-se o
modelo que obtém o melhor desempenho contra dados de teste. Assim, o analista e o
especia-lista podem escolher os atributos que apresentam melhor poder preditivo.
Segundo a CRISP-DM, essa fase corresponde às tarefas de: (i) engenharia dos dados; (ii) fusão dos dados; e (iii) formatação dos dados.
4.1.5 - Engenharia do algoritmo
Nessa fase, são selecionadas as técnicas e os algoritmos para o tipo de
minera-ção de dados mais adequados ao problema. Aqui também são selecionados os parâmetros mais
apropriados ao processo como, por exemplo, a tarefa de escolher o número de camadas em
uma rede neural por meio de várias tentativas.
De acordo com a CRISP-DM, essa fase consiste nas tarefas de: (i) seleção da técnica; e (ii) teste da técnica nos dados.
4.1.6 – Mineração
De acordo com Fayyad (1996) existem dois possíveis objetivos em um processo
de mineração: predição e descrição. O primeiro visa a estabelecer o valor de um ou mais
atri-butos em um banco de dados, tendo como base outros atriatri-butos presentes. Nesse objetivo, a
análise de qualidade é realizada via número de acertos em um total de casos testados.
O segundo tem como finalidade apontar padrões potencialmente interessantes
nos dados sem uma associação com um conceito inicial. Nesse caso, a análise de qualidade