Contents lists available at ScienceDirect
Expert
Systems
With
Applications
journal homepage: www.elsevier.com/locate/eswa
An
expert
system
for
extracting
knowledge
from
customers’
reviews:
The
case
of
Amazon.com,
Inc.
Mauro Castelli
a, Luca Manzoni
b, Leonardo Vanneschi
a, Aleš Popovi
ˇc
a ,c ,∗aNOVAIMS,UniversidadeNovadeLisboa,1070-312,Lisboa,Portugal
bDISCo,DipartimentodiInformaticaSistemisticaeComuniczione,UniversityofMilanoBicocca,20126,Milano,Italy cFacultyofEconomics,UniversityofLjubljana,KardeljevaPlošˇcad17,1000Ljubljana,Slovenia
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Received 12 September 2016 Revised 4 April 2017 Accepted 5 May 2017 Available online 6 May 2017
Keywords:
Genetic programming Semantics
E-commerce Customers’ feedback
a
b
s
t
r
a
c
t
E-commercehasproliferatedinthedailyactivitiesofend-consumersandfirmsalike.Forfirms,consumer satisfactionisanimportantindicatorofe-commercesuccess.Today,consumers’reviewsandfeedbackare increasinglyshapingconsumerintentionsregardingnewpurchasesandrepeatedpurchases,whilehelping toattractnewcustomers.Inourwork,weuseanexpertsystemtopredictthesentiment ofaproduct consideringasubsetofavailablecustomers’reviews.
© 2017ElsevierLtd.Allrightsreserved.
1. Introduction
Inthemarketingandmanagementliterature,customer satisfac-tionisincreasinglyemphasizedasavitalfactorforincreasingsales and thus corporate performance (Anderson, Fornell, & Lehmann, 1994; Balasubramanian, Konana, & Menon, 2003; Szymanski & Henard, 2001 ). As firms engage ever more in e-commerce ini-tiatives, customer satisfaction is an important indicator of e-commercesuccess.Despitethegrowthinsalesandvolumesseen around the world, e-commercesites often tendto underestimate customer reviews’ importance fornewpurchasesandrepeat pur-chases, aswell asforattracting newcustomers.More oftenthan not,customer reviewsareneglected onthelistofwhatfirms be-lieve are the critical success factors of an e-commerce initiative (Liu & Arnett, 20 0 0 ). In fact, firmstend to focus chieflyon opti-mizing the design of the website, customer service andsupport, andtheadministrativeactivities relatedtothemanagement of e-commerce(Bendoly & Kaefer, 2004; Bergendahl, 2005; Teo & Liu, 2007 ).
Althoughalloftheseactivitiesrequirevaluableeffort, overlook-ing customer reviews andfeedback can curtailthe success of e-commerce(Cui, Lui, & Guo, 2012; Kim, Galliers, Shin, Ryoo, & Kim, 2012; Lee, Han, & Suh, 2014; Qiu, Lin, & Li, 2015 ). More
specif-∗ Corre sponding author.
E-mail addresses: [email protected], [email protected] (M. Castelli), [email protected] (L. Manzoni), [email protected] (L. Vanneschi), [email protected] (A. Popovi ˇc).
ically, accordingto the“Social Commerce2007” report of Bazaar-voice(Bazaarvoice, 2007 ) asa result ofthe opportunity given to customers to provide feedback and reviews on purchased prod-ucts, 42% ofe-commerce managers reported a significant rise in thevolumeandaverageordervalue.Ontheotherhand,only6%of e-commerce managers revealed a decline in orders after the re-views were made public. Similarly, large e-commerce sites such asAmazonandeBayhavefoundthatmanyconsumersappreciate the opportunity to evaluate products before their (possible) pur-chase.About40%ofcustomersparticipatinginasurveybyNielsen (Nielsen, 2010 )statedtheywouldnothavepurchasedanelectronic itemwithouthavinghadaccesstotheopinionsofothercustomers, whereas85.57%oftheparticipantssaidtheyreadreviewsoftenor veryoftenbeforebuyingonline.Inthisperspective,an additional factorwitha significant impact on onlinepurchasing behavior is thecustomer social network. As reportedin Verbraken, Goethals, Verbeke, and Baesens (2014) ,knowledge ofa person’ssocial net-workcanhelpinpredictingthatperson’se-commerceacceptance ofdifferentproducts.The quality ofreviewsisalsoconsidered to beveryimportant.Astudyreportedin Lackermair, Kailer, and Kan- maz (2013) found that 75% of customers reportedthat the qual-ity of such reviews greatly influences their decision to purchase a product from an online store. Last but not least, the possibil-itytousecommentsmadeby customersinorderto improvethe SEO(SearchEngineOptimization)processalsoneedstobe consid-eredasarelevantfactorforfirms.Infact,thecontentofcustomers’ opinionscould beindexedandusedtoproducesearch engine re-sults.Inthiscase,theadvantageisthatthereviewsarewrittenin
naturallanguage,whichisabletomatchmanykeywordsandthus giveafurtherboosttotheSEOtask.
Obviously, customer feedback cannot be considered the only variablethatcan(positivelyornegatively)affecttheaveragevalue of orders. Thus, firms need to consider the broader interplay of factors to fully comprehend which enable and which inhibit e-commercesuccess(Gefen, 20 0 0 ).Ananalysisoftheroleofall pos-siblecomponentsis verycomplex,yet, thestrongcorrelation be-tweenreviewsandfirmsales,aswellasstudiesdemonstratingthe importanceofreviewsinestablishingane-commercewebsite’s re-liability,makee-commercesites’inclusionofcustomerreviewsan establishedpractice.
The ability to predict the score of future reviewsis useful in manyapplications: for instance, it is possible to suggest, among objectswithsimilarratings,theonethathasthehighestexpected futurereviewscore.Itmayalsobeusefulforpredictingissueswith the items: from the detection of sellers withcounterfeit objects toissues concerning the manipulation ofthe reviews(Hu, Liu, & Sambamurthy, 2011 ). In both cases,a score that variestoomuch withrespecttothepredictedonecanbeinterpretedasasignalof apossibleanomaly.Other studiesdealingwiththeimportance of predictingthereviewscoreofan itemarepresentedin Qu, Ifrim, and Weikum (2010) , Gupta, Di Fabbrizio, and Haffner (2010) and Ganu, Elhadad, and Marian (2009) .
All aspects mentioned so far show that customer feedback is an important asset for e-commerce managers. Hence, extracting non-trivialknowledgeandmanageableinformationfromsuchrich datapoolsis achallengingissue ofparamountimportance for e-commercemanagers.
To answer this call, in this paper we propose the use of a machine learning (ML) technique. The application of a ML tech-nique tries to overcome the limitations of traditional statistic-based linear regression methods. Although these techniques and modelsarereliable,theyarethebestchoiceinmanaging unstruc-tureddataordatawherenopreviousknowledgeoftheunderlying modelisavailable.Hence,moresophisticatedmeansmustbe em-ployedto extractmeaningfulinformation fromdata.MLmethods haveshownanability toperform betterwhen dealingwith non-linearity and unstructured and complex data. While existing ML techniqueshavebeensuccessfullyusedtoaddressproblemsin dif-ferentdomains,researcherscontinuouslyseektoadvanceexisting methodsandprovide novel onesforanalyzingdata sets tomake senseofthedata,extractusefulinformation,andbuildknowledge toinformdecision-making.Inthislight,andconsideringthelarge amountofdataavailabletoday,inthispaperwepropose an arti-ficialintelligencesystemforextractingusefulinformation consid-eringthe feedbackofe-commercecustomers.The proposed algo-rithmisavariantofthestandardgeneticprogramming(GP) algo-rithmbut,unlikethestandardone,itisabletoscalebeyonddata setsofafew millionelementsanditisbasedonasolid theoreti-calbackgroundthatguaranteestheexistenceofcertain properties thatwillhelpthesearchprocessproducemorereliablesolutions
Thepaperisorganizedasfollows: Section 2 describesthe stan-dardGP algorithm andthe operators used in thesearch process. Section 3 presentsthe geometric semanticoperators usedin this paper.Morespecifically,wehighlightthebenefitsoftheoperators onthesearchprocess. Section 4 describestheexperimentalphase anddiscussestheresultsobtained. Section 5 concludesthepaper, providingsomedirectionsforpossiblefutureresearch.
2. Geneticprogramming
Genetic Programming (GP) is a technique that comes from a larger computational intelligence research area called evolution-ary computation (EC). GP consists of the automated learning of computer programs by means ofa process inspired by biological
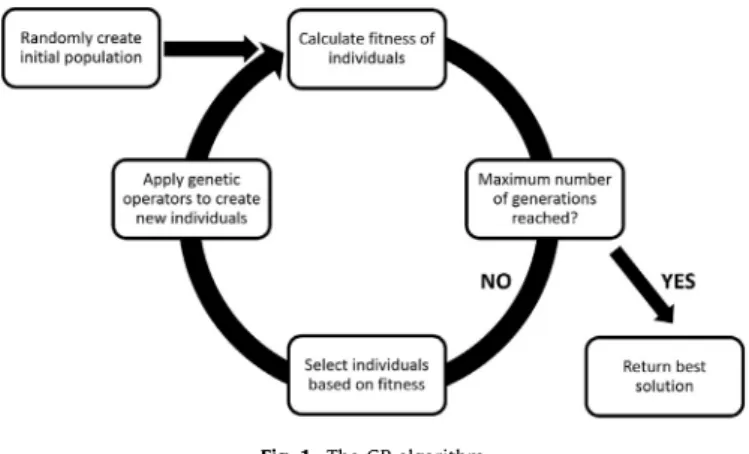
Fig.1. The GP algorithm.
evolution(Koza, 1992 ).Generationbygeneration,GPstochastically transformspopulationsofprogramsintonew,hopefullyimproved, populationsofprograms.Thequalityofasolutionisexpressedby usinganobjectivefunction.Thevalueofthisobjectivefunctionis thefitnessofan individual.Thesearch processofGPisshownin Fig. 1 .
In order to transform a population into a new population of candidatesolutions,GPusesparticularoperatorscalledgenetic op-erators.ConsideringthecommontreerepresentationofGP individ-uals, thestandard geneticoperators (crossover and mutation) act onthestructureofthetreesthatrepresentthecandidatesolutions. Inotherterms,standardgeneticoperatorsactonthesyntaxofthe programs.Inthispaper,weusedgeneticoperatorsthat,unlikethe standardones,areabletoactatthesemanticlevel.Thedefinition of semantics used in thiswork is that which was also proposed in Moraglio, Krawiec, and Johnson (2012) andwillbecomeclearin thefollowingsection.
To understand the differences between the genetic operators used in thiswork andthose used in the standard GP algorithm, thelatterare briefly described.The “standard” crossoveroperator is traditionallyused to combinethe geneticmaterial of two par-ents by swapping part of one parent with part of the other. In moredetail,afterchoosingtwoindividualsbasedontheir fitness, thecrossoveroperatorperformstwooperations:1)itselectsa ran-dom subtree in each parent; and2) swaps theselected subtrees between the two parents (the resulting individuals are the chil-dren). The mutation operator introduces random changes in the structures of individuals in the population. The best known mu-tation operator, calledsub-tree mutation,works as follows: 1) it randomlyselectsapointinatree;2) itremoveswhateveris cur-rentlyattheselectedpointandwhateverisbelowthatpoint;and 3) itinsertsa randomlygenerated subtreeatthat point.This op-eration is controlled by a parameterthat specifies the maximum size(usuallymeasured intermsoftreedepth)forthenewly cre-atedsubtreethatistobeinserted.
3. Geometricsemanticoperators
termsemanticsisusedtorefertothebehaviorofaprogramonce it is appliedto a set ofdata.This definitionrelates the term se-manticswiththevectorofoutputsobtainedafterapplyingagiven program(orcandidatesolution)toasetoftrainingdata(Moraglio et al., 2012 ). Including the semantics concept in the search pro-cessallows GPtoovercomeone ofitscurrentlimitations.Infact, whilesemanticsdetermineswhataprogramactuallydoes,the tra-ditional genetic operators manipulate programs only in terms of theirsyntax.Hence,traditionalGPoperatorscompletelyignorethe information aboutthe behavior of programs provided by seman-tics.Thedrawbackofthischoiceisthatitisdifficult(oreven im-possible) topredictthe effectmodifications whichaffectthe syn-tax oftheprograms willhaveonthe semanticsofthe same pro-grams.
To overcome this problem, new genetic operators that act on the semantics of the programs have recently been defined (Moraglio et al., 2012 ).Inparticular,amongtheseveraladvantages oftheseoperatorswithrespecttothetraditionalones,ithasbeen shownthat theseoperatorsare abletoinduce aunimodalfitness landscape(Stadler, 1995 )onanyproblementailingfindingamatch betweena setofinputdata anda setofexpectedtarget ones.In thispaper, we willconsider the definitionofgeometric semantic operatorsforrealfunctions’domainssincethesearetheoperators wewilluseintheexperimentalphase.
Geometric Semantic Crossover. Given two parent functions T1,T2:Rn→R,thegeometric semanticcrossoverreturnsthe real functionTXO=
(
T1·TR)
+((
1−TR)
·T2)
,whereTR isarandomreal functionwhoseoutputvaluesrangeintheinterval[0,1].The interested readeris referred to Moraglio et al. (2012) for formal proof ofthe fact that thisoperator corresponds to a geo-metriccrossoveronthesemanticspaceinthesenseitproducesan offspring that standsbetweenits parentsinthisspace. Neverthe-less, evenwithoutformalproof,we canhaveanintuitionofitby consideringthatthe(unique)offspringgeneratedbythiscrossover hasasemanticvectorthatisalinearcombinationofthesemantics oftheparentswithrandomcoefficientsincludedin[0,1].
To constrain TR in producing values in [0, 1] we use the sig-moidfunction:TR=1 1
+e−Trand whereTrandisarandomtreewithno constraintsontheoutputvalues.
Geometric Semantic Mutation. Given a parent function T: Rn→R,the geometricsemanticmutationwithmutationstepms returns the realfunction TM=T+ms·
(
TR1−TR2)
,where TR1 andTR2arerandomrealfunctionswithcodomainintherange[0,1].
These operators are able to transform each regression prob-lem in a problemcharacterized by a unimodal fitness landscape (Moraglio et al., 2012 ). This property guarantees the algorithms convergence to-wards optimalsolutions and allowssemantic GP to outperform the standard syntax-based GP on regression prob-lems. An introduction to geometric semantic operators can be foundin Vanneschi (2017) .
While theseoperators haveseveraladvantages(asreportedin Moraglio et al., 2012 ), thereis an importantlimitationthat must be considered. As can easily be noticed considering their defini-tion, every application of these operators produces an offspring that containsthe complete structure of the parents, plus one or morerandomtreesasitssubtreesandsomearithmetic operators: thesizeofeachoffspringisthusclearlymuchlargerthanthesize ofitsparents.Inordertocounteractthisexponentialgrowthofthe individuals(Moraglio et al., 2012 )thatmakesdifficulttousethese operators to address real-life problems,in thispaper we usethe solutionproposedin Vanneschi, Castelli, Manzoni, and Silva (2013) . Ingreaterdetail,theworkdescribedin Vanneschi et al. (2013) pro-posedaverysimpleandeffectiveimplementationoftheGP algo-rithm that allows GP to usethe geometric semanticoperators in afeasible way.Thisistheimplementationusedinthispaperand
documentedin Castelli, Silva, and Vanneschi (2014) .Aswidely dis-cussedin Vanneschi et al. (2013) ,thisimplementationandthe fea-turesofthegeometric operatorsallowtheproposed systemtobe usedtoanalyzelargedatasetswithinareasonableamountoftime. Inparticular,thesystemscaleslinearlywithrespecttothenumber ofinstancesinthedataset.
4. Experiments
This section describes the business problem that was consid-ered, the available data, the experimental settings, and the ob-tainedresults.
4.1. Problemanddata
We used the datasets provided by McAuley and Leskovec (2013) ,whichinclude allreviewsappearing on amazon.com from June1995 toMarch2013. Eachentryinthedatasetis composed, amongother fields,by an objectidentifier, the review score, the timeofthereview,andtheusefulnessofthereviewasafraction
a
b, wherea is thenumber ofpeople who havefound thereview usefulandbthenumberofpeoplewhohaveevaluatedthereview. Foreachreview,weconsideredthefollowingfeature:
• Score.Thereviewscore.
• Usefulness.Thenumberofpeoplewhohaveevaluatedthe
re-view and the number of people who have found the review useful,representedasapairofnumbersandreferredtoasthe usefulnessofthereview.
• Time.Thetime (indays)betweenthisreviewandthefirst
re-viewoftheobjecttowhichthereviewrefers.
Wefocusedonpredictingtheaveragereviewscoreofanobject givenalimitednumberofreviews.Forexample,wherean object hasbeen reviewed50 times,we usethe first 10 reviewsto pre-dicttheaverage ofthelast 40reviews. Eachentryin thedataset consistsofreviewsofaspecificobject.Inourstudy,weonly con-sideredobjectsthathavebeenreviewedatleast30times(forsize 10and20) or50times(for size30and40). Onlyobjectsin two categoriesoftheamazonstorewereconsidered:
• Thekindlestore(KS).Thisdataset,forsize10and20,consists
of923objects(dividedintoatrainingsetof627objectsanda testsetof296objects,a70%–30%split).Forsize30and40,the datasetconsistsof554objects(388inthetrainingsetand166 inthetestset).
• Industrial andScientific(IS).The resultingdatasetconsistsof
311 objects(218inthetrainingsetand93 inthetest set)for size 10and20.Thedatasetforsize30 and40consistsof212 objects(148intrainingsetand64inthetestset).
4.2.Experimentalsettings
Fig.2. The results on the IS dataset (S) for size 10.
Fig.3. The results on the IS dataset (S +U) for size 10.
in Vanneschi, Silva, Castelli, and Manzoni (2014b) .The individuals areinitializedusingtherampedhalf-and-halfmethod(Koza, 1992 ), withthe maximal initial depth equalto 6. The functional opera-tors were +, ×, −, andthe protected division asin Koza (1992) . Theterminalnodesare theinputvariables andrandomconstants intherange[−100,100].Thevaluesoftheseparameterswere cho-senafterapreliminarytuning phase.Inparticular,several combi-nationsofcommonlyusedparameters’valuesweretakeninto ac-countand,finally,weselectedthesetofparametersthatreturned thebestperformance.Forbothdatasetsconsidered,weperformed 100 independent runsand we recorded,for each generation and foreach run, the fitness ofthe best individual in thepopulation inthe trainingset, andthe fitness ofthe same individual in the test sets. Each of the 100 runs wasperformed using a different split betweenthe training andthe test set. The results obtained were comparedwith those produced by other well-known state-of-the-art machine learning methods. This comparison allows us todrawsome considerationsaboutthecompetitivenessofthe re-sults.ToperformthecomparisonbetweensemanticGPwithGSOs (hereinafterGSGP) andother machinelearningmethods,weused the implementations provided by the Weka public domain soft-ware(Weka Machine Learning Project, 2013 ). AsdoneforGSGP,a preliminarystudywasperformedinordertotunetheconsidered techniques’parameters.
4.3.Results
Plotsshownin Figs. 2–17 reporttheresultsachievedontheIS dataset.DenotingtheinterquartilerangewithIQR,theendsofthe whiskersrepresentthelowestdatum andthehighestdatum.The centralbardenotesthemedianRMSEonthe100runsperformed andthecrossrepresents theaverage.Severalconfigurations were
Fig.4. The results on the IS dataset (S +U +T) for size 10.
Fig.5. The results on the IS dataset (S +T) for size 10.
Fig.6. The results on the IS dataset (S) for size 20.
Fig.8. The results on the IS dataset (S +U +T) for size 20.
Fig.9. The results on the IS dataset (S +T) for size 20.
Fig.10. The results on the IS dataset (S) for size 30.
Fig.11. The results on the IS dataset (S +U) for size 30.
Fig.12. The results on the IS dataset (S +U +T) for size 30.
Fig.13. The results on the IS dataset (S +T) for size 30.
Fig.14. The results on the IS dataset (S) for size 40.
Fig.16. The results on the IS dataset (S +U +T) for size 40.
Fig.17. The results on the IS dataset (S +T) for size 40.
considered.Thetarget we wanttopredict istheaverage scoreof theremainingreviews.Weusethefollowingnotation:
• (S): in thiscase we considered, forprediction purposes, only
thereviewscores;
• (S+U):inthiscase,we consideredthereviewscores andtheir
usefulness;
• (S+T): in thiscase, we considered the review scores and the
timeofthereviews;and
• (S+T+U): in this case, we considered the review scores, the timeofthereviewsandtheusefulnessofthereviews.
Further,inthefigures,LRstandsforlinearregression(Weisberg, 2005 ),RBFstandsforradialbasisfunctionnetwork(Haykin, 1999 ), SVMreferstosupportvectormachines(Schölkopf & Smola, 2002 ) and NN refers to feed-forward artificial neural networks trained withtheBackpropagation learningrule(Gurney, 1997 ).In all fig-ures, thefirst five boxes, fromleft to right, representthe results obtained with the compared five methods on the training set, whiletheremainingfiveboxesrefertotheresultsonthetestset.
If we consider the results obtained in the caseof 10 reviews (Figs. 2–5 ), GP outperforms all the other methods on both the trainingandthetest set, withthe onlyexception of the(S) case whereGP is outperformed by LR on the test set.If we consider the caseof 20 reviews (Figs. 6–9 ), GP outperforms all the other methods for the (S+U) case on both the training and test sets.
Forthe (S+U+T)case, GP andNNare themethods that gavethe bestperformance onboththetrainingandtestsets.Ontheother hand,GP is outperformed by the other methods for the (S) and the (S+T) cases. For 30 reviews (Figs. 10–13 ), GP and NN are the best methods forboth the training and test sets, except for the(S)caseonthetestset.Finally,for40reviews(Figs. 14–17 ),GP andNNare thebest methods onboth thetraining andtest sets,
Fig.18. The results on the KS dataset (S) for size 10.
Fig.19. The results on the KS dataset (S +U) for size 10.
Fig.20. The results on the KS dataset (S +U +T) for size 10.
exceptforthe (S)caseonthe test setandthe(S+T) caseonthe
trainingandtestsets.Inthelattercase,GPisoutperformedbyNN. Asapartialconclusion,wecanstate thatGP,ingeneral, performs betterthanthecompetitorswhenthenumberofreviewsissmall (10 or20). Fora largernumberofreviews(30 or40),the perfor-manceofNN increasesandNNhavea performance that is com-parable,andinsomecasesevenbetterthanGP.However, alsofor thecasesof30and40reviews,GPisreliably thebest,orsecond best,performeramongthecomparedmethods.
Plots shownin Fig. 18–33 report the results obtainedfor the KSdataset.
Fig.21. The results on the KS dataset (S +T) for size 10.
Fig.22. The results on the KS dataset (S) for size 20.
Fig.23. The results on the KS dataset (S +U) for size 20.
Fig.24. The results on the KS dataset (S +U +T) for size 20.
Fig.25. The results on the KS dataset (S +T) for size 20.
Fig.26. The results on the KS dataset (S) for size 30.
Fig.27. The results on the KS dataset (S +U) for size 30.
Fig.29. The results on the KS dataset (S +T) for size 30.
Fig.30. The results on the KS dataset (S) for size 40.
Fig.31. The results on the KS dataset (S +U) for size 40.
Fig.32. The results on the KS dataset (S +U +T) for size 40.
Fig.33. The results on the KS dataset (S +T) for size 40.
for30reviews(Figs. 26–29 ),withtheonlyexceptionofthe(S)case whereLRoutperformsGPonthetestset,andNNistheworst per-formeronthetestset.Finally,for40reviews(Figs. 30–33 ),GP out-performsalltheothermethodsonboththetrainingandtestsets, exceptforthe(S)caseinwhichitisoutperformed byNNonthe trainingset andLR andSVM on thetest set, andthe (S+T) case
inwhichGPisoutperformedbyNNonboththetrainingandtest sets.All inall,we mayconcludethatthe resultsobtainedonthe KSdatasetconfirm thesametrendasthosealreadydiscussedfor theISdataset:GPis,ingeneral,thebestmethodfor10or20 re-views,andithasaperformancethatisbetterthan,orcomparable to,NN(thattogetherwithGPisthebestperformer)for30and40 reviews. These experiments clearlydemonstrate the appropriate-nessofGPforsolving thestudied problemwhenalsoconsidering that, unlike the other techniques considered, the performance of GPisquitesimilar onboththetrainingandtest setsforall stud-iedcases.Further,whenlookingattheboxesofGPintheprevious figures andcomparingthemtothe boxesintheotherfigures, we canseetheresultsofGParecharacterizedwithlowvariance.Allof theseaspectsmakeGPanappropriatetechniqueforunderstanding e-commerceclients’preferenceswhenusingasetofreviews.
To analyze the statistical significance of the results discussed so far, a set of tests was performed on the median errors. The Wilcoxon rank-sum test for pairwise data comparison, a rank-basedstatistic,wasusedunderthealternativehypothesisthatthe samples from the first set are smaller or equal to the values of thesecond samplewitha probabilityexceeding0.5. Aconfidence value of
α
=0.1wasusedand, consideringthe presenceofmore than two samples,a Bonferronicorrection forthis value was ap-plied.Thep-valuesobtainedarereportedfrom Tables 1–8 .ConsideringtheISdataset(Tables 1–4 ),itispossibletoobserve that forthe trainingset GP produces resultsthat are statistically betterthanthoseproducedbytheother techniquesonalargeset ofconfigurations.Onlyfor20reviewsdoGPandNNperform com-parably forconfigurations(S), (S+T),and(S+T+U). Regardingthe
performance onthetestset,itispossibletodrawsimilar consid-erations: GP is the best performer in the large majority of con-figurations, withthe only exceptions of the following cases: For the(S)configuration,GP,LR,RBF,andSVMproduceresultsthatare notstatisticallydifferent,whileforthe(S+T)and(S+T+U)
config-urationswith20reviewsGPandNNproduceresultsthatare com-parable(i.e.thedifferenceintermsofmedianRMSEisnot statis-ticallysignificant).
Table1
p-value returned by the Mann–Whitney test on the IS dataset for size 10.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test)
S 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.6059 1.0 0 0 0 S +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 0.0 0 01 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 02 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0
Table2
p-value returned by the Mann–Whitney test on the IS dataset for size 20.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test) S 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.5515 1.0 0 0 0 S +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.9353 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.9433 0.0 0 0 0 0.0 0 0 0
Table3
p-value returned by the Mann–Whitney test on the IS dataset for size 30.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test) S 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.8605 0.0 0 01 0.9809 0.9690 S +U 0.0 0 01 0.0088 0.0 0 0 0 0.0 0 0 0 0.0 0 01 0.0104 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T +U 0.1915 0.0183 0.0 0 0 0 0.0 0 0 0 0.1073 0.0073 0.0 0 0 0 0.0 0 0 0
Table4
p-value returned by the Mann–Whitney test on the IS dataset for size 40.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test)
S 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.9733 0.0631 0.7538 0.5861 S +U 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0789 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.3048 S +T 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.9999 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0
Table5
p-value returned by the Mann–Whitney test on the KS dataset for size 10.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test) S 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 S +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0
Table6
p-value returned by the Mann-Whitney test on the KS dataset for size 20.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test) S 0.0 0 0 0 0.1942 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 S +U 0.0 0 0 0 0.0570 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0401 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 0.9857 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.9885 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.1989 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.2093 0.0 0 0 0 0.0 0 0 0
Table7
p-value returned by the Mann–Whitney test on the KS dataset for size 30.
LR (train) NN (train) RBF (train) SMO (train) LR (test) NN (test) RBF (test) SMO (test)
S 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.4557 1.0 0 0 0 S +U 0.0 0 0 0 0.0368 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0279 0.0 0 0 0 0.0 0 0 0 S +T 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 1.0 0 0 0 0.0 0 0 0 0.0 0 0 0 S +T +U 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0 0.0 0 0 0
Table8
p-value returned by the Mann–Whitney test on the KS dataset for size 40.
behavioris very similarto that observed fortheIS dataset. Ana-lyzing the performance on the test set, it is possibleto see that GPhasacomparableperformancetoLRandSVMforthe(S) con-figuration. Also, GP and NN produce results that are not statis-tically different for the case of 20 reviews in the (S+T), (S+U),
and(S+T+U)configurations.
In conclusion, the results of the statistical tests confirm the suitabilityoftheproposed GP-basedtechniqueforaddressingthe problemathand.Asafinal consideration,itisimportanttopoint outthatitisnotonlythereviews’scorethatisimportantfor pre-dicting a product’s success, but also the usefulness of a review isparticularlyrelevantandmaycontributeto abetter prediction. Hence,e-commercemanagerswhoprovideclientswiththe oppor-tunity to ratea product andto also rateexisting reviewsshould havea competitive advantage withrespectto e-commerce stores thatdonotprovidethesefeatures.
5. Conclusions
We proposeda geneticprogrammingsystemforpredicting re-view scores basedon a subset of existing reviews. The proposed systemusesgeneticoperators that are ableto integrate semantic awarenessintothesearch process. Theuseoftheseoperators in-ducesaunimodalfitness landscapeinevery problemthat entails findingamatchbetweenpredictedvaluesandtargets(like regres-sionandclassificationproblems).Consideringtheparticular prob-lem under scrutiny, it is possible to draw some interesting con-clusions:in both datasets considered a small subset of all exist-ingreviews(reviewscoresandotherattributes)wassufficientfor predictingtheaverage review scores better than using,asa pre-dictor,theaverageoftheknownreviewscores.Thisisavery im-portantpointforbusiness:inelectroniccommercealargeamount ofdatais available andthe knowledge extractionprocess can be averytime-consumingtask.Havingasystemavailablethatisable toguaranteegoodpredictiveaccuracycanspeeduptheentire pro-cess. More specifically, thebest prediction wasachievedon both thetrainingandtest sets,consideringthereviewscoresandtheir usefulness.Hence,whilereviewscoreisanimportantattribute,the usefulnessofthereview(whichmaybeseenasameasureofthe review’squality)alsoplays a primaryrole inachievinggood pre-dictiveaccuracy.Inamoregeneralperspective,thisstudyoffers e-commercemanagersatoolformorecomprehensively understand-ingcustomerbehaviorwithregardtonewandrepeatedpurchases. Wehopethisstudypavesthewayforfutureresearchinthearea.
References
Anderson,E.W.,Fornell,C.,&Lehmann,D.R.(1994).Customersatisfaction, mar-ketshare,andprofitability:Findingsfromsweden.JournalofMarketing,58(3), pp.53–66.
Balasubramanian,S.,Konana,P.,&Menon,N.M.(2003).Customersatisfactionin virtualenvironments:Astudy ofonlineinvesting.ManagementScience,49(7), 871–889.
Bazaarvoice (2007). Social commerce report 2007. http://www.bazaarvoice.com/. Beadle,L.,&Johnson,C.G.(2009).InA.Tyrrell(Ed.),Semanticallydrivenmutationin
geneticprogramming(pp.1336–1342).Trondheim,Norway:2009ieeecongress onevolutionarycomputation.
Bendoly,E.,&Kaefer,F.(2004).Businesstechnologycomplementarities:Impactsof thepresenceandstrategictimingofERPonB2Be-commercetechnology effi-ciencies.Omega,32(5),395–405.
Bergendahl,G.(2005).Modelsforinvestmentinelectroniccommerce:financial per-spectiveswithempiricalevidence.Omega,33(4),363–376.
Castelli, M., Silva, S., & Vanneschi, L. (2014a). A c ++ framework for geometric se- mantic genetic programming. GeneticProgrammingandEvolvableMachines, 1–9. doi: 10.1007/s10710-014-9218-0.
Castelli,M.,Vanneschi,L.,&Silva,S.(2014b).Semanticsearch-basedgenetic pro-grammingand theeffectofintrondeletion. Cybernetics,IEEETransactionson, 44(1),103–113.
Cui,G.,Lui,H.-K.,&Guo,X.(2012).Theeffectofonlineconsumerreviewsonnew productsales.InternationalJournalofElectronicsandCommerce,17(1),39–58. Ganu,G.,Elhadad,N.,&Marian,A.(2009).Beyondthestars:Improvingrating
pre-dictionsusingreviewtextcontent.InWebdb:9(pp.1–6).
Gefen, D. (2000). E-commerce:The roleof familiarity and trust. Omega, 28(6), 725–737.
Gupta,N.,DiFabbrizio,G.,&Haffner,P.(2010).Capturingthestars:predicting rat-ingsforserviceandproductreviews.InProceedingsofthenaaclhlt2010 work-shoponsemanticsearch(pp.36–43).AssociationforComputationalLinguistics. Gurney,K.(1997).Anintroductiontoneuralnetworks.AnIntroductiontoNeural
Net-works.Taylor&Francis.
Haykin,S.(1999).Neuralnetworks:Acomprehensivefoundation.PrenticeHall. Hu,N.,Liu,L.,&Sambamurthy,V.(2011).Frauddetectioninonlineconsumer
re-views.DecisionSupportSystems,50(3),614–626.Onquantitativemethodsfor detectionoffinancialfraud.
Kim,C.,Galliers,R.D.,Shin,N.,Ryoo,J.-H.,&Kim,J.(2012).Factorsinfluencing internetshoppingvalueandcustomerrepurchaseintention.ElectronicCommerce ResearchandApplications,11(4),374–387.
Koza,J.R.(1992).Geneticprogramming:Ontheprogrammingofcomputersbymeans ofnaturalselection.Cambridge,MA,USA:MITPress.
Koza,J.R. (2010).Human-competitiveresultsproducedbygeneticprogramming. GeneticProgrammingandEvolvableMachines,11(3-4),251–284.
Lackermair,G.,Kailer,D.,&Kanmaz,K.(2013).Importanceofonlineproductreviews fromaconsumer’sperspective.AdvancesinEconomicsandBusiness,1(1),1–5. Lee,H.,Han,J.,&Suh,Y.(2014). Giftorthreat?Anexaminationofvoiceofthe
customer:Thecaseofmystarbucksidea.com.ElectronicCommerceResearchand Applications,13(3),205–219.
Liu,C.,&Arnett,K.P.(2000).Exploringthefactorsassociatedwithwebsitesuccess inthecontextofelectroniccommerce.Information&Management,38(1),23–33. McAuley,J.,&Leskovec,J.(2013).Hiddenfactorsandhiddentopics:Understanding ratingdimensionswithreviewtext.InInproceedingsofthe7thACMconference onrecommendersystems,RecSys’13(pp.165–172).NewYork,NY,USA:A.C.M. Moraglio,A.,Krawiec,K.,&Johnson, C.G.(2012). Geometric semanticgenetic
pro-gramming.InC.A.CoelloCoello,V.Cutello,K. Deb,S. Forrest,G.Nicosia,& M.Pavone(Eds.),Parallelproblemsolvingfromnature,ppsnxii(part1).In Lec-tureNotesinComputerScience:7491(pp.21–31).Springer.
Nielsen (2010). Global online shopping report. http://acnielsen.co.th/us/en/ newswire/2010/global-online-shopping-report.html.
Qiu,J.,Lin,Z.,&Li,Y.(2015).Predictingcustomerpurchasebehaviorinthe e-com-mercecontext.ElectronicCommerceResearch,1–26.
Qu,L.,Ifrim,G.,&Weikum,G.(2010).Thebag-of-opinionsmethodforreviewrating predictionfromsparsetextpatterns.InProceedingsofthe23rdinternational con-ferenceoncomputationallinguistics(pp.913–921).AssociationforComputational Linguistics.
Schölkopf,B.,&Smola,A.(2002).Learningwithkernels:Supportvectormachines, regularization, optimization, and beyond.Adaptive computation and machine learning.MITPress.
Stadler,P.(1995).Towardsatheoryoflandscapes.InR.López-Pena,H.Waelbroeck, R.Capovilla,R.García-Pelayo,&F.Zertuche(Eds.),Complexsystemsandbinary networks.InLectureNotesinPhysics:461-461(pp.78–163).SpringerBerlin/ Hei-delberg.
Szymanski,D.,&Henard,D.(2001).Customersatisfaction:Ameta-analysisofthe empiricalevidence.JournaloftheAcademyofMarketingScience,29(1),16–35. Teo,T.S.,&Liu,J.(2007).Consumertrustine-commerceintheunitedstates,
sin-gaporeandchina.Omega,35(1),22–38.
Vanneschi,L.(2017).InO.Schütze,L.Trujillo,P.Legrand,&Y.Maldonado(Eds.), Anintroductiontogeometricsemanticgeneticprogramming(pp.3–42)).Cham: SpringerInternationalPublishing.
Vanneschi,L.,Castelli,M.,Manzoni,L.,&Silva,S.(2013).Anewimplementationof geometricsemanticGPanditsapplicationtoproblemsinpharmacokinetics.In K.Krawiec,A.Moraglio,T.Hu,A.Etaner-Uyar,&B.Hu(Eds.),Genetic program-ming.InLectureNotesinComputerScience:7831(pp.205–216).SpringerBerlin Heidelberg.
Vanneschi, L., Castelli, M., & Silva, S. (2014a). A survey of semantic methods ingenetic programming.Genetic Programming andEvolvableMachines, 15(2), 195–214.
Vanneschi,L.,Silva,S.,Castelli,M.,&Manzoni,L.(2014b).Geometricsemantic ge-neticprogrammingforreallifeapplications.InGeneticprogrammingtheoryand practicexi(pp.191–209).SpringerNewYork.
Verbraken, T., Goethals,F., Verbeke, W., & Baesens, B. (2014). Predictingonline channelacceptancewithsocialnetworkdata.DecisionSupportSystems,63(0), 104–114.
Weisberg,S.(2005).Appliedlinearregression.WileySeriesinProbabilityand Statis-tics.Wiley.
Weka machine learning project (2013). Weka. http://www.cs.waikato.ac.nz/∼