Fabiano Cavalcanti Fernandes
SISTEMA NEURO-
FUZZY
PARA CLASSIFICAÇÃO DE
CALCIFICAÇÕES EM MAMOGRAMAS
SISTEMA NEURO
-FUZZY
DE APOIO AO DIAGNÓSTICO DE CÂNCER
DE MAMA
Dissertação apresentada ao Programa de Pós-Graduação Strictu Sensu em Gestão do Conhecimento e da Tecnologia da Informação, da Universidade Católica de Brasília, como requisito parcial para obtenção do Título de Mestre em Gestão do Conhecimento e da Tecnologia da Informação.
Orientadora: Profª. Dra. Lourdes Mattos Brasil Co-orientadora: Dra. Janice Magalhães Lamas
Ficha elaborada pela Coordenação de Processamento do Acervo do SIBI – UCB. 13/08/2007
F363s Fernandes, Fabiano Cavalcanti.
Sistema neuro-fuzzy para classificação de calcificações em mamogramas / Fabiano Cavalcanti Fernandes. – 2007.
94f. : il. ; 30 cm
Dissertação (mestrado) – Universidade Católica de Brasília, 2007. Orientação: Lourdes Mattos Brasil
Co-orientadora: Janice Magalhães
1. Mama – Radiografia. 2. Diagnóstico. 3. Calcificação. 4. Redes neurais (Computação) I. Brasil, Lourdes Mattos, orient. II. Magalhães, Janice, co-orient. III. Título
Dissertação defendida e aprovada como requisito parcial para obtenção do Título de Mestre em Gestão do Conhecimento e Tecnologia da Informação, defendida e aprovada, em 21 de
junho de 2007, pela banca examinadora constituída por:
Profª. Lourdes Mattos Brasil, Dra. Orientadora
Janice Magalhães Lamas, Dra. Co-orientadora
Prof. Leonardo Vidal Batista, Dr. Examinador externo
Prof. Renato da Veiga Guadagnin, Dr. Examinador interno
À Carolina pelo apoio
Agradeço ao meu pai, pelo incondicional
apoio e orientação.
À Carolina, pelo amor, paciência e
incentivo.
Agradeço às minhas orientadoras,
Profª. Dra. Lourdes Brasil e Dra. Janice
Lamas pela extraordinária dedicação e
direção em todos os momentos.
Agradeço ao Prof. Dr. Leonardo Vidal
Batista, ao Prof. Dr. Edilson Ferneda e ao
Prof. Dr. Renato da Veiga Guadagnin pelas
importantes sugestões ao trabalho. Agradeço ao Prof. Dr. Rildo Ribeiro dos
Santos pelo incentivo ao ingresso neste
RESUMO
No Brasil, o câncer de mama é a maior causa de óbitos por câncer entre as mulheres. Como suas causas são desconhecidas, o mesmo não pode ser prevenido. A presença de calcificações é um sinal importante para a detecção do carcinoma mamário. A detecção precoce é um aspecto chave para o controle do câncer de mama e a mamografia é um dos exames mais confiáveis para a detecção do câncer de mama. A análise de imagens em mamogramas para a detecção precoce do câncer de mama pode ser feita com maior eficiência se o radiologista estiver munido de ferramentas computacionais adequadas, devido à própria limitação do olho humano na análise detalhada em imagens de alta resolução e na identificação de padrões de calcificações da mama. As redes neurais artificiais são comprovadamente adequadas ao reconhecimento de padrões e, portanto, úteis como ferramentas de apoio ao diagnóstico médico. A presente dissertação propõe um sistema neuro-fuzzy para a classificação da região de interesse do mamograma, tratando-se especificamente de calcificações, como maligna ou benigna. Este trabalho será incorporado aos projetos VIRTUATLAS (Atlas Virtual de Anatomia e Fisiopatologia da Mama) e o IACVIRTUAL (Inteligência Artificial Aplicada na Modelagem e Implementação de um Consultório Virtual), em curso na Universidade Católica de Brasília.
ABSTRACT
In Brazil breast cancer is the leading cause of death by cancer for women. Since the causes are unknown, it cannot be prevented. The presence of calcification clusters is an important sign for breast carcinoma detection. Mammography is one of the most reliable exams for breast cancer detection. Early detection is the key issue for breast cancer control and computer-aided diagnosis system can help radiologists in detection and diagnosing breast abnormalities. Artificial neural networks are suitable for pattern recognition tasks and therefore useful for medical diagnosis support. This study presents a fuzzy-neural system that classifies the mammogram calcification region of interest as benign or malign. The present system will be incorporated at VIRTUATLAS (Breast Physiopathology and Anatomy Virtual Atlas) and IACVIRTUAL (Artificial Intelligence applied to the Modeling and Implementation of a Virtual Medical Office) projects.
Keywords: Artificial Neural Networks. ANFIS. Mammography. Medical Diagnosis.
Figura 1 - Sistema de diagnóstico auxiliado por computador para mamografias, (CHENG et
al., 2003) ... 22
Figura 2 – Estágio de pré-processamento dos dados (BISHOP, 1995) ... 29
Figura 3 – Modelo não-linear de um neurônio (HAYKIN, 1999, p. 11)... 33
Figura 4 – Estrutura de uma ANFIS (JANG, 1993) ... 38
Figura 5 – Diagrama esquemático do cubo de cores RGB (GONZALEZ, 2002)... 39
Figura 6 - Função de Pertinência Gaussiana ... 43
Figura 7 - Função de Pertinência S... 44
Figura 8 - Função de Pertinência Trapezoidal... 45
Figura 9 - Função de Pertinência Polinomial ... 45
Figura 10 - Projeto IACVIRTUAL ... 48
Figura 11- Projeto VIRTUATLAS... 51
Figura 12 - Sistema proposto... 59
Figura 13 – Fluxograma de Pré-Processamento com validação cruzada ... 60
Figura 14 - Fluxograma de Detecção ... 61
Figura 15 - Fluxograma de Extração de Características Texturais... 61
Figura 16 - Fluxograma de Classificação utilizando o modelo ANFIS ... 63
Figura 17 – Rede ANFIS utilizada no estudo... 66
Figura 18 - Mamograma original (a) e correspondente ROI (b) ... 67
Figura 19 - ROI original (a) e ROI sem background (b)... 68
Figura 20 - ROI sem background (a) e background em forma de superfície de iluminação irregular (b)... 68
Figura 21 - ROI sem background (a) e ROI com aumento de contraste (b)... 69
Figura 22 - ROI com aumento de contraste (a) e ROI sem ruído(b) ... 69
Figura 23 – RMS de aprendizagem para arquitetura ANFIS com a Função de Pertinência TRAPMF ... 72
Figura 27 - RMS de validação para arquitetura ANFIS com a Função de Pertinência
GBELLMF ... 77 Figura 28 – RMS de testes para arquitetura ANFIS com a Função de Pertinência GBELLMF
... 78 Figura 29 - – RMS de aprendizagem para arquitetura ANFIS com a Função de Pertinência PIMF... 80 Figura 30 – RMS de validação para arquitetura ANFIS com a Função de Pertinência PIMF. 81 Figura 31 - RMS de testes para arquitetura ANFIS com a Função de Pertinência PIMF ... 82 Figura 32 - RMS de aprendizagem para arquitetura ANFIS com a Função de Pertinência PSIGMF... 84 Figura 33 - RMS de validação para arquitetura ANFIS com a Função de Pertinência PSIGMF
Tabela 1 - Resultados das pesquisas em língua portuguesa com os textos de “Redes Neurais
Artificiais”, “Lógica fuzzy”, “Reconhecimento de Padrões” e “Mamografia”... 18
Tabela 2 - Resultados das pesquisas em língua inglesa com os textos de “Neural Network”, “Pattern Recognition”, “Fuzzy” e “Mammography”... 19
Tabela 3 – Resultado da divisão das imagens em conjuntos... 66
Tabela 4 – Descritores texturais ... 70
Tabela 5 – Desempenho da rede ANFIS com a Função de Pertinência TRAPMF ... 71
Tabela 6 - Desempenho da rede ANFIS com a Função de Pertinência GBELLMF ... 75
Tabela 7 - Desempenho da rede ANFIS com a Função de Pertinência PIMF ... 79
Tabela 8 - Desempenho da rede ANFIS com a Função de Pertinência PSIGMF ... 83
ACM - Association for Computing Machinery
ANFIS - Adaptative-Network-based Fuzzy Inference System
BI-RADS – Breast Imaging Reporting and Data System
CAD – Computer Aided Diagnosis
COPPE – Coordenação dos Programas de Pós-graduação em Engenharia da UFRJ GC - Gestão do Conhecimento
IA - Inteligência Artificial
IACVIRTUAL - Projeto Inteligência Artificial Aplicada na Modelagem e Implementação de um Consultório Virtual
IEEE - The Institute of Electrical and Electronics Engineers
INCA - Instituto Nacional do Câncer
MGCTI - Mestrado em Gestão do Conhecimento e da Tecnologia da Informação da Universidade Católica de Brasília
MIAS – The Mammographic Image Analysis Society Digital Mammogram Database
MS – Ministério da Saúde
NEFCLASS – Neuro-Fuzzy Classification
RNN – Redes Neurais Naturais
ROC - Receiver Operating Characteristic
ROI – Region of Interest
RP – Reconhecimento de Padrões RV – Realidade Virtual
SEH - Sistema Especialista Híbrido STI - Sistema Tutor Inteligente TI – Tecnologia da Informação
Lista de figuras ...9
Lista de tabelas ...11
Lista de abreviaturas e símbolos ...12
1. Introdução ...16
1.1 Motivação ... 17
1.2 Revisão de literatura ... 17
1.3 Relevância do estudo ... 20
1.4 Formulação do problema ... 22
1.5 Objetivos... 22
1.6 Organização do trabalho... 23
2. Referencial teórico...24
2.1 Gestão do conhecimento médico... 25
2.1.1. Gestão do conhecimento... 25
2.1.2. Conhecimento médico ... 26
2.2 Reconhecimento de padrões ... 27
2.2.1 Pré-processamento, segmentação e extração de características ... 28
2.2.2 Curva polinomial ... 30
2.2.3 Reconhecimento supervisionado e não-supervisionado ... 30
2.2.4 Classificadores... 30
2.3 Redes neurais artificiais... 31
2.3.1 Conceitos ... 31
2.3.2 Redes MLP (Multilayer Perceptron)... 33
2.3.3 Validação cruzada... 35
2.3.4 Aprendizagem... 35
2.3.5 O modelo ANFIS... 36
2.4 Imagens digitais... 38
2.4.1 O modelo de cores RGB (Red Green Blue)... 38
2.4.2 Análise de textura ... 39
2.4.3 Matriz de co-ocorrência de níveis de cinza ... 41
2.4.4 Filtro de mediana ... 42
2.5 Sistemas fuzzy... 42
2.6 Projeto IACVIRTUAL ... 47
2.7 Projeto VIRTUATLAS ... 50
2.7.1 Objetivos do Atlas Virtual... 50
2.7.2 Descrição do Atlas Virtual ... 50
2.8 Mamografia ... 51
2.8.1 O câncer de mama ... 51
2.8.2 Calcificações... 52
3. Metodologia...55
3.1 Classificação da pesquisa ... 56
3.2 Hipótese ... 56
3.3 Coleta e análise de dados... 57
3.4 Delimitação do estudo ... 58
3.5 O modelo proposto ... 59
4. Resultados ...64
5. Conclusões e trabalhos futuros...87
5.1 Conclusões... 88
5.2 Trabalhos futuros... 89
1.1 Motivação
A escolha do tema foi o resultado da identificação da necessidade de uma ferramenta de auxílio ao diagnóstico do câncer de mama nos projetos VIRTUATLAS (Atlas Virtual de Anatomia e Fisiopatologia da Mama) e IACVIRTUAL (Projeto Inteligência Artificial Aplicada na Modelagem e Implementação de um Consultório Virtual). O principal instrumento de estudo da mama é o mamograma, imagem radiográfica da mama, e sua análise é obtida através de uma inspeção visual da imagem pelo especialista. Como as RNA (Redes Neurais Artificiais) são comprovadamente adequadas para a identificação de padrões em imagens digitais, segundo Cheng et al. (2003), pretende-se estudar sua aplicação na análise de mamogramas, mais especificamente na manifestação de calcificaçõesna mama. Será proposto um modelo de ferramenta CAD (Computer Aided Diagnosis – Diagnóstico Auxiliado por Computador) que será validado em uma base de imagens de mamogramas com diagnósticos de calcificações.
1.2 Revisão de literatura
Foram feitas pesquisas em bibliografias especializadas no que diz respeito a livros e às diversas bases de teses, dissertações, monografias e artigos como USP, COPPE, Scirus e
Tabela 1 - Resultados das pesquisas em língua portuguesa com os textos de “Redes Neurais Artificiais”, “Lógica fuzzy”, “Reconhecimento de Padrões” e “Mamografia”
Web site Resultados Resultados válidos Observações
http://www.google.com.br 13 2
http://scholar.google.com.br 5 1
http://www.scirus.org 9 1
http://teses.usp.br 3 1 Palavra chave:
mamografia
http://www.pee.ufrj.br/teses/ 1 1 Palavra chave:
mamografia
Santos (2002) implementa um esquema de processamento para detectar nódulos em mamas densas em imagens mamográficas digitalizadas, com base na transformada de
Watershed detectando aproximadamente 93% dos nódulos existentes no grupo das imagens
analisadas. Esta pesquisa mostra a importância da segmentação de imagens, e a necessidade de técnicas de pré-processamento para o aumento de contraste e pós-processamento para redução de ruídos a fim de obter índices satisfatórios de falsos-negativos.
Leite (2005) utiliza uma RNA com treinamento supervisionado em backpropagation
para classificar mamogramas normais ou com achados anormais com auxílio de um radiologista especializado, obtendo uma taxa de reconhecimento de 86% das regiões de interesse selecionadas. Nesse estudo foi feito uma análise de componentes independentes para a extração de parâmetros da imagem antes da submissão à classificação da RNA.
Campos (2006) propõe um método de discriminação e classificação de mamogramas com anatomopatológico maligno, benigno e com ausência de achados anormais, usando análise de componentes independentes e RNA. O método foi testado com mamogramas da base de dados Mini MIAS (The Mammographic Image Analysis Society Digital Mammogram
método obteve uma taxa de sucesso média de 97.83%, com 97.5% de especificidade, e 98% de sensibilidade (DELAMARO et al., 2006).
Em seguida, foram feitas pesquisas na língua inglesa em bibliografias especializadas no que diz respeito a livros e às diversas bases de teses, monografias e artigos como ACM, IEEE, Scirus e Google Scholar. Os resultados das pesquisas em língua inglesa com os textos de “Neural Network”, “Pattern Recognition”, “Fuzzy” e “Mammography” são mostrados na Tabela 2.
Tabela 2 - Resultados das pesquisas em língua inglesa com os textos de “Neural Network”, “Pattern Recognition”, “Fuzzy” e “Mammography”
Web site Resultados Resultados válidos
http://portal.acm.org/dl.cfm 31 1
http://www.ieee.org 12 2
http://www.scirus.org 17 3
http://scholar.google.com 4 1
Dentre os trabalhos internacionais nesta área, e mais próximos do problema abordado nesta pesquisa, temos o de Cheng et al. (2004b) onde inicialmente os mamogramas são “fuzzificados” utilizando a teoria dos conjuntos fuzzy e a entropia fuzzy. Em seguida são aplicadas técnicas de filtragem para detecção de tamanhos e localização de calcificações, atingindo bom desempenho em mamas densas, produzindo baixas taxas de falsos-negativos e falsos-positivos.
Zhang et al. (2005) propõem um algoritmo neural-genético para seleção de características em conjunto com classificadores neurais e estatísticos para classificar padrões de calcificações em mamogramas digitais, com resultados onde o classificador neural obtém 85% de taxa de acertos mostrando-se melhor do que o classificador estatístico.
processadas localmente ou globalmente. O sistema foi avaliado com a base de dados MIAS e obteve resultados satisfatórios, atingindo até 93,7% de taxa de acertos.
Cheng et al. (2004a) apresentam uma RNA fuzzy para detectar lesões malignas de massa em mamogramas, a rede possui quatro camadas onde a primeira é a camada de entrada consistindo de quatro neurônios fuzzy, a segunda camada possui quatro neurônios não-fuzzy e a terceira camada consiste em um número de neurônios determinados pelo processo de treinamento e varia com os parâmetros de rede e a distribuição de dados. A quarta camada possui no máximo dois neurônios fuzzy e um neurônio competitivo. A proposta apresentada obteve uma fração de verdadeiro-positivo de 0,92 quando o número de falso-positivo é de 1,33 por mamograma e 1,0 quando o número de falso-positivo é 2,15 por mamograma.
Lee e Tsai (2004) apresentam uma discriminação entre calcificações malignas e benignas, para a classificação são calculados o número total, a área média, a circularidade média e a distância mínima entre as calcificações. Lógica fuzzy e algoritmos genéticos para otimização de funções de pertinência são empregados para classificar as ROI (Regiões de Interesse). O sistema foi avaliado com a base de dados MIAS e obteve resultados de 100% de sensibilidade, 77% de especificidade, com o valor Az da curva ROC (Receiver Operating Characteristic) de 0.95.
1.3 Relevância do estudo
casos a cada 100 mil mulheres segundo o INCA (2006). A prevenção primária continua sendo impossível, pois a causa da doença permanece desconhecida. A descoberta precoce é fator chave para melhorar o prognóstico do câncer de mama, segundo Cheng et al. (2003). Além disso a realização periódica de mamografia em mulheres resulta em redução de mortalidade de aproximadamente 40-50% (TABAR, L. et al., 2003).
A acuidade visual máxima do olho humano é de 26 segundos de arco. Ou seja, dois raios luminosos entrando no olho devem ter uma separação mínima de 26 segundos de arco entre eles para que as fontes que os produziram possam ser identificadas como fontes separadas. Isto faz com que a uma distância de 10 m só podemos distinguir pontos que estejam separados de, no mínimo, um milímetro uns dos outros, segundo E-Física (2007).
Devido às limitações do olho humano, posicionamento inadequado, técnica inadequada, ruído, etc. cerca de 10 a 30% das lesões de mama não são identificadas durante o exame de rotina feita pelo especialista. Com os avanços do processamento digital de imagens, a inteligência artificial e o reconhecimento de padrões, os radiologistas podem melhorar a eficiência do diagnóstico em cerca de 10% utilizando ferramentas de diagnóstico auxiliado por computador, segundo Cheng et al. (2003, p. 2967).
1.4 Formulação do problema
O problema definido no presente trabalho é como detectar e reconhecer padrões em mamogramas utilizando RNA, de modo a permitir o apoio ao diagnóstico de câncer de mama para o caso específico de calcificações. A Figura 1 ilustra um sistema de CAD para mamografias, extraído de Cheng et al. (2003).
Figura 1 - Sistema de diagnóstico auxiliado por computador para mamografias, (CHENG et al., 2003)
1.5 Objetivos
O objetivo geral deste trabalho é a modelagem e a implementação de um protótipo de um sistema CAD para auxiliar o especialista médico no diagnóstico do câncer de mama.
Os objetivos específicos são:
1. Disponibilizar uma ferramenta CAD para integração ao IACVIRTUAL; 2. Construir um modelo e um protótipo de um sistema neuro-fuzzy;
3. Testar o sistema neuro-fuzzy em laboratório, com os dados do Mini MIAS, permitindo uma futura integração aos projetos VIRTUATLAS e IACVIRTUAL; 4. Disponibilizar o protótipo como uma ferramenta de Gestão do Conhecimento para
apoio ao diagnóstico, voltado a estudantes e profissionais da área médica.
Mamograma Pré-processamento Enhancement e
Segmentação
Extração de Características Detecção de
Agrupamentos Seleção de
Características
1.6 Organização do trabalho
Este trabalho está organizado em cinco capítulos, incluindo este capítulo.
2.1 Gestão do conhecimento médico
2.1.1. Gestão do conhecimento
A gestão do conhecimento pode ser vista como um conjunto de atividades que busca desenvolver e controlar todo tipo de conhecimento em uma organização, visando à utilização na consecução de seus objetivos. Esse conjunto de atividades deve ter como principal meta apoiar o processo decisório, em todos os níveis. Para tanto, é preciso estabelecer políticas, procedimentos e tecnologias que sejam capazes de coletar, distribuir e utilizar efetivamente o conhecimento, representando fator de mudança no comportamento organizacional, segundo Moresi (2001).
O conhecimento organizacional pode ser classificado em dois tipos, de acordo com Nonaka e Takeuchi (1997). Um é o conhecimento explícito, que pode ser articulado na linguagem formal, sobretudo em afirmações gramaticais, expressões matemáticas, especificações, manuais e assim por diante. Esse tipo de conhecimento pode ser então transmitido, formal e facilmente, entre os indivíduos.
O segundo tipo, o conhecimento tácito, é difícil de ser articulado na linguagem formal. É o conhecimento pessoal incorporado à experiência individual e envolve fatores intangíveis como, por exemplo, crenças pessoais, perspectivas e sistemas de valores.
Stollenwerk (2001) constatou a importância do processo de criação do conhecimento, comum a todos os modelos por ela estudados, e, dentro desse processo, a dimensão aprendizagem organizacional foi percebida como essencial para operacionalização do modelo.
que o conhecimento esteja disponível nos locais de tomada de decisão e mantendo-os sempre atualizados.
2.1.2. Conhecimento médico
A profissão médica tem sofrido significativas mudanças devido ao desenvolvimento e aos avanços científicos das áreas concernentes. Assim como na grande maioria das profissões atuais, profissionais da área médica devem constantemente se atualizar. A geração e comunicação de conhecimento por parte de médicos é, hoje, um importante elemento do sucesso e um desafio profissional, segundo Portal Médico (apud Silva, 2005a).
Durante o processo de diagnóstico, o profissional de saúde realiza uma série de inferências sobre a natureza das disfunções do corpo. Estas inferências são derivadas das observações existentes, ou seja, dados consistentes sobre a história do paciente, sinais, sintomas, testes de rotinas, respostas a várias manipulações, o tempo de curso de alguns eventos, os conhecimentos clínicos, fisiológicos, bioquímicos, anatômicos e patológicos, sobre casos semelhantes e a sua biologia subjacente, a experiência prévia do médico em realizar diagnósticos do mesmo tipo, bem como o senso comum e a intuição de acordo com Kassirer e Gorry (1978).
Os profissionais de saúde utilizam amplamente suas experiências passadas no processo de reunir e interpretar informações. Estas experiências são essenciais, pois reduzem a necessidade de se ter um número considerável de questões desnecessárias, de ordenar testes de diagnósticos supérfluos e de tornar a tarefa de informação manejável e eficiente conforme Kassirer e Gorry (1978).
lesões mamárias são perdidas durante um exame de rotina. Com os avanços do processamento digital de imagens, reconhecimento de padrões e inteligência artificial é possível aprimorar o diagnóstico com a ajuda de sistema CAD, aumentando em até 10% a taxa de acertos do médico radiologista (CHENG et al., 2003).
O sistema CAD pode armazenar o conhecimento tácito e explícito do médico radiologista e a sua experiência passada na área, possibilitando um melhor desempenho do mesmo nos exames de rotina e uma segunda leitura para especialistas nos diagnósticos de câncer de mama. Um sistema CAD, portanto, é de fundamental importância nos projetos VIRTUATLAS e IACVIRTUAL como vetor de disseminação e utilização de conhecimento médico.
2.2 Reconhecimento de padrões
de RP. A segunda leitura é recomendação feita pelo BI-RADS (Breast Imaging Reporting and Data System), se possível por outro radiologista.
Conforme Bishop (1995), a forma mais adequada de tratar problemas de reconhecimento de padrões é a abordagem estatística, que reconhece a natureza probabilística das informações a serem processadas e a forma pela qual se devem expressar os resultados. Devido à variação considerável nos padrões, as variáveis medidas devem ser tratadas como quantidades estocásticas e a sua perfeita classificação nem sempre é possível. O objetivo do método de reconhecimento de padrões é, portanto, minimizar a probabilidade de erro durante a classificação dos mesmos. Uma classificação pode ser vista como um mapeamento de um conjunto de variáveis de entrada xi, ... , xd, para uma variável de saída y representando o nome
ou rótulo da classe mapeada. Em problemas mais complexos podem existir várias variáveis de saída,
Y
k onde k = 1 . . .n. De modo geral, não é possível determinar uma forma apropriadapara um mapeamento exceto com a ajuda de um conjunto de dados de exemplo. O mapeamento é, portanto modelado em termos de alguma função matemática que contenha um número de parâmetros ajustáveis cujos valores são determinados com ajuda dos dados. Essas funções podem ser escritas conforme Equação 1.
Yk =
y
k (x;w) (1)Onde w denota o vetor de parâmetros. Um modelo de RNA pode ser considerado como uma escolha particular de um conjunto de funções
y
k (x;w). Neste caso, os parâmetrosrelativos à w são chamados de pesos.
2.2.1 Pré-processamento, segmentação e extração de características
objeto em questão e onde começa o próximo objeto. A fronteira conceitual entre a extração de características e a classificação é arbitrária, e o extrator de características deve caracterizar um objeto para que o mesmo seja reconhecido por medidas de objetos similares na mesma categoria.
Segundo Bishop (1995), ao invés de representar uma transformação total de um conjunto de entrada xi, . . .xd para um conjunto de variáveis de saída y1, . . .ycatravés de uma
única função de uma RNA, existe um grande benefício, de quebrar esse mapeamento em um estágio inicial de pré-processamento seguido por uma parametrização do modelo de RNA. Para se mapear um espaço d-dimensional x1 . . .xdpara uma variável de saída y deve-se dividir
o espaço de entrada em um determinado número de células M e especificar o valor de y para cada célula, resultando em um crescimento exponencial do número total de células Md, reduzindo a performance do sistema, fenômeno conhecido como impacto da dimensionalidade. Fica claro que a técnica de dividir o espaço de entrada em células é uma forma ineficiente de se representar uma função não linear multivariada. As RNA feedforward
são muito menos susceptíveis ao impacto da dimensionalidade. Uma das principais tarefas do estágio de pré-processamento é de reduzir o impacto da dimensionalidade dos dados antes de utilizá-los para treinar uma RNA ou outro sistema de reconhecimento de padrões. A Figura 2 mostra o estágio de pré-processamento dos dados.
Figura 2 – Estágio de pré-processamento dos dados (BISHOP, 1995)
Pré-processamento
Rede Neural Artificial
x1 . . .xd
xm1 . . .xmd
2.2.2 Curva polinomial
Muitos dos aspectos importantes com relação à aplicação de RNA podem ser resumidos pelo contexto de ajuste da curva polinomial, onde se deve adequar um polinômio a um conjunto de pontos de dados N pela técnica de minimização de função de erro. Considerando o polinômio de ordem M na Equação 2.
y(x) =
w
0 +w
1x + . . . + wM xM = ∑M
w
jx j j=0(2) O polinômio pode ser considerado como um mapeamento não linear que toma x como entrada e produz y como saída. A forma precisa da função y(x) é determinada pelos valores dos parâmetros
w
0 , . . .,w
M, análogos aos pesos de uma RNA. É conveniente denotar oconjunto de parâmetros (
w
0, . . .w
M) pelo vetor w. O polinômio pode ser escrito como ummapeamento funcional na forma y =y(x;w).
2.2.3 Reconhecimento supervisionado e não-supervisionado
No reconhecimento supervisionado, um professor produz as categorias ou o custo para cada padrão em um conjunto de treinamento e busca reduzir a soma dos custos para esses padrões. Já no reconhecimento não-supervisionado não existe um professor de forma explícita e o sistema forma clusters ou agrupamentos naturais dos padrões de entrada. O conceito de “agrupamento natural” é definido explicitamente ou implicitamente pelo próprio cluster, e dado um conjunto particular de padrões, algoritmos diferentes de agrupamento produzirão resultados diferentes, conforme Duda (2001).
2.2.4 Classificadores
muitas vezes é determinar a probabilidade para cada classe possível. A variação de valores de características para objetos na mesma classe pode ser devida à complexidade ou ao ruído, ou a uma seleção inadequada de atributos. O ruído é definido como qualquer propriedade do padrão reconhecido que não se relacione ao modelo estudado mas a componentes estocásticos do ambiente ou dos sensores.
2.3 Redes neurais artificiais
2.3.1 Conceitos
Conforme Azevedo, Brasil e Oliveira (2000), a construção de RNA tem inspiração nos neurônios biológicos e nos sistemas nervosos. Entretanto, é importante compreender que, atualmente, as RNA estão muito distantes das RNN (Redes Neurais Naturais) e, as semelhanças são mínimas.
Segundo Russel e Norvig (1995) uma RNA é composta de um determinado número de nós, ou unidades, conectados por links. Cada link tem um peso numérico associado a ele. Os pesos são formas primárias de armazenamento de longo prazo em RNA, e o aprendizado acontece através da atualização desses pesos. Algumas unidades são conectadas ao ambiente externo e podem ser designadas como unidades de entrada ou de saída. Os pesos são modificados de acordo com as tentativas de tornar o comportamento de entrada ou de saída da rede mais de acordo com as entradas fornecidas pelo ambiente.
De acordo com Russel e Norvig (1995) cada unidade é composta por um conjunto de
qualquer controle global sobre o conjunto de unidades como um todo. Na prática, a maioria das implementações de RNA é feita através de software e é utilizado um controle síncrono para atualizar todas as unidades seguindo uma seqüência pré-fixada.
Para construir uma RNA que realize uma determinada tarefa, deve-se decidir primeiramente quantas unidades devem ser usadas, que tipos de unidades são apropriadas e como estarão conectadas de modo a formar uma rede. Em seguida, deve-se inicializar os pesos da RNA e treinar os pesos utilizando um algoritmo de aprendizado aplicado ao conjunto de exemplos de treinamento para a tarefa. O uso de exemplos também implica na decisão de como codificar os exemplos em termos de dados de entrada e saída da rede.
A Figura 3 mostra uma unidade típica, que recebe sinais de entrada e computa um novo nível de ativação, que é enviado para o link de saída Yk. A computação do nível de ativação é
baseada nos valores de cada sinal de entrada recebido de um nó vizinho e dos pesos de cada link de entrada. A computação é dividida em dois componentes, isto é, o primeiro é um componente linear chamado de junção aditiva, INi, que computa a soma ponderada dos
valores de entrada das unidades. O segundo é um componente não linear chamado de função de ativação, φ, que transforma a soma ponderada no valor final, que serve como o valor de ativação da unidade, ai. A Equação 3 mostra que a entrada ponderada total é a soma das
ativações de entrada vezes os seus respectivos pesos, conforme Russel e Norvig (1995).
INi = Σ Wj,i . aj = Wi . ai (3)
Figura 3 – Modelo não-linear de um neurônio (HAYKIN, 1999, p. 11)
Para caracterizar uma RNA, segundo Azevedo, Brasil e Oliveira (2000), é importante especificar os seguintes pontos:
• Os componentes da rede: os neurônios; • A resposta de cada neurônio;
• O estado global de ativação da rede;
• A conectividade da rede dada pelos valores de conexões sinápticas; • Como se propaga a atividade da rede;
• Como se estabelece a conectividade da rede; • O ambiente externo a rede;
• Como o conhecimento é representado na rede.
2.3.2 Redes MLP (Multilayer Perceptron)
De acordo com Azevedo, Brasil e Oliveira (2000, p. 23), uma rede MLP com uma camada intermediária de neurônios é suficiente para aproximar qualquer função contínua e
BiasBk
v
k Wk1Wk2
Wkm
Σ
Linksde entradaFunção de ativação X1 X2 Xm X1
φ
(.)
uma rede MLP com duas camadas intermediárias é suficiente para aproximar quaisquer funções matemáticas, contínuas ou não.
Em uma rede MLP, o número de camadas intermediárias é determinado pela natureza do problema a ser aproximado. Em geral este número é definido de maneira empírica, dependendo da distribuição dos dados a serem utilizados e de validação subseqüente. Entretanto, Eberhart e Dobbins (1990 apud AZEVEDO, BRASIL e OLIVEIRA, 2000) apresentam uma heurística onde QNi (número de neurônios da camada intermediária) é igual à
raiz quadrada de QNe (quantidade de neurônios da camada de entrada), somada com QNs
(número de neurônios da camada de saída), conforme Equação 4.
QNi = (QNe)½ + QNs (4)
Uma grande dificuldade no treinamento de redes MLP é a ocorrência de convergência para um mínimo local em função da distribuição dos dados. Para minimizar este problema, Rumelhart, Hinton e Williams (1986 apud AZEVEDO, BRASIL e OLIVEIRA, 2000) apresentam um método de treinamento chamado algoritmo backpropagation ou retropropagação. O algoritmo ajusta repetidamente os pesos das conexões entre os neurônios de maneira a minimizar as diferenças entre as saídas reais e as observadas. O método é baseado em um gradiente descendente, onde a função de ativação precisa ser contínua, diferenciável e de preferência não decrescente, para que o gradiente possa ser calculado e o ajuste dos pesos seja direcionado. O algoritmo de retropropagação é composto de duas fases: a forward, que define a saída em função de um padrão de entrada e a backward, que a partir da saída desejada e dos valores obtidos pela rede, busca atualizar os pesos das conexões sinápticas.
uma taxa de aprendizado lr e de um momento m, otimizam o processo de aprendizado nas
épocas de treinamento e facilitam a convergência para um mínimo global. 2.3.3 Validação cruzada
Conforme Haykin (1999), a essência do aprendizado em backpropagation é codificar um mapeamento de entrada para a saída, representado por um conjunto de exemplos, em pesos sinápticos e limiares de ativação de uma rede MLP. O objetivo é que a rede esteja bem treinada e que seu processo de aprendizagem possa ser suficiente para uma futura generalização. Após um ciclo de treinamento, uma rede MLP pode piorar sua taxa de acertos para entradas diferentes daquelas utilizadas para a aprendizagem, esse fenômeno é chamado
de overfitting ou ajuste demasiado aos dados. Para reduzir a sua ocorrência, uma das
alternativas é a utilização do método de validação cruzada, onde o conjunto de dados é dividido aleatoriamente em um conjunto de treinamento e em um conjunto de testes. O conjunto de treinamento é então dividido em dois outros subconjuntos disjuntos: (i)
estimação, para seleção do modelo e (ii) validação, para testar ou validar o modelo. Segundo Kearns (1996 apud HAYKIN, 1999) 80% do conjunto de treinamento deve ser atribuído ao conjunto de estimação e 20% deve ser atribuído ao conjunto de validação.
A motivação da divisão em três conjuntos é validar o modelo com um conjunto de dados diferentes dos utilizados para a estimação dos parâmetros da rede. Como existe a possibilidade de que o modelo com os parâmetros que resultem em melhor desempenho possa tornar a MLP direcionada para o conjunto de validação, o desempenho de generalização é realizada no conjunto de testes, que é diferente do conjunto de validação.
2.3.4 Aprendizagem
qual a rede está operando. O tipo de aprendizagem é definido pela maneira como ocorrem os ajustes realizados nos parâmetros, ou seja, como são alteradas as intensidades das conexões entre os neurônios.
Segundo Azevedo, Brasil e Oliveira (2000), a aprendizagem supervisionada busca extrair de um professor ou supervisor, o conhecimento de que o mesmo dispõe sobre o ambiente, permitindo um mapeamento entrada-saída. Durante a sessão de treinamento de uma RNA, pares de entradas e saídas são apresentadas a ela. A rede toma cada entrada e produz uma resposta na saída. Esta resposta é comparada com o sinal de saída desejado. Se a resposta real difere da resposta desejada, a RNA gera um sinal de erro, o qual é, então, usado para calcular o ajuste que deve ser feito para os pesos sinápticos da rede. Assim a saída real se aproxima da saída desejada e o erro é reduzido. O processo de minimização de erro requer um circuito especial conhecido como professor ou supervisor.
O aprendizado não-supervisionado não requer um supervisor, isto é, não há saída desejada. Durante a sessão de treinamento, a RNA recebe em sua entrada excitações muito diferentes e organiza, arbitrariamente, em categorias. Quando uma entrada é aplicada na rede, a RNA fornece uma resposta de saída indicando a classe a qual a entrada pertence. Se uma classe não pode ser encontrada para o padrão de entrada, uma nova classe é gerada.
2.3.5 O modelo ANFIS
Um dos primeiros sistemas híbridos neuro-fuzzy para aproximação de funções foi o modelo ANFIS (Adaptative-Network-based Fuzzy Inference System). Ele representa um sistema fuzzy do tipo Sugeno de ordem zero em uma arquitetura de RNA feedforward especial de cinco camadas (JANG, 1993). O modelo ANFIS implementa regras conforme Equação 5.
A base de regras deve ser conhecida anteriormente. O modelo ANFIS ajusta apenas as funções de pertinência dos parâmetros antecedentes e conseqüentes. O seu treinamento pode ser feito em backpropagation ou híbrido, que é uma mistura do método backpropagation com o método de míninos quadráticos.
A estrutura da rede ANFIS, mostrada na Figura 4, contém η unidades de entrada na camada U0 (não computada, segundo Jang (1993)). As outras camadas (denotadas como U1,
..., U5) têm as seguintes funcionalidades (NAUCK et al., 1997):
• Camada 1: Cada unidade em U1 armazena três parâmetros para definir uma função de
pertinência em forma de sino que representa um termo lingüístico. Cada unidade é conectada a exatamente uma unidade de entrada e calcula o grau de pertinência do valor de entrada obtido.
• Camada 2: Cada regra é representada por uma unidade em U2. Cada unidade é
conectada àquelas unidades na camada anterior que pertencem aos antecedentes da regra.
• Camada 3: Nesta camada U3, para cada regra Rr existe uma unidade que calcula seu
grau relativo de preenchimento.
• Camada 4: As unidades de U4 são conectadas a todas as unidades de entrada (não
mostrado na Figura 4) e a exatamente uma unidade em U3.
Figura 4 – Estrutura de uma ANFIS (JANG, 1993)
2.4 Imagens digitais
Segundo Gonzalez (2002), uma imagem pode ser definida como uma função bidimensional f(x,y) onde x e y são coordenadas espaciais. A amplitude de f em qualquer par de coordenadas (x,y) é chamada de intensidade ou nível de cinza da imagem naquele ponto. Uma imagem digital é aquela na qual os valores de x, y, e f são valores finitos e discretos. 2.4.1 O modelo de cores RGB (Red Green Blue)
De acordo com Gonzalez (2002), a retina possui três cones fotos-receptores que quando excitados nos proporcionam a visão colorida. O espaço de cor RGB do processo de visão do ser humano, na retina, onde a codificação da percepção não é eficiente, baseia-se nesta teoria, relacionando a cor a um primeiro estágio.
No modelo RGB cada cor aparece no formato de seu componente espectral primário de vermelho, verde e azul. O modelo é baseado no sistema de coordenadas cartesianas, no espaço
y
Ω
Ω
Ω
Ω
x2 x1Π
Π
Π
Π
Π
N
N
N
N
N
Σ
R3. Neste modelo os pontos de escala de cinza são representados por valores iguais de RGB. O subespaço de cores é mostrado no cubo da Figura 5.
Figura 5 – Diagrama esquemático do cubo de cores RGB (GONZALEZ, 2002)
As cores diferentes neste modelo são pontos no cubo, definindo vetores a partir da origem até os pontos. Por uma questão de conveniência, os valores de cores estão normalizados, ou seja, os valores RGB variam no intervalo de [0,1].
Uma imagem representada pelo modelo de cores consiste de três componentes de imagens, uma para cada cor primária. Quando reproduzida em um monitor RGB, o olho combina os pontos de fósforo R, G e B na tela, produzindo uma imagem composta. O número de bits utilizado para representar cada pixel no espaço RGB é chamado de profundidade de
pixel, conforme Gonzalez (2002). 2.4.2 Análise de textura
Não existe um consenso ou uma definição formal para textura, porém sua maior característica é a repetição de um padrão ou de vários padrões em uma região segundo Parker (1996). Uma definição mais relevante é um atributo representando um arranjo espacial de
G (0,1,0)
R (1,0,0)
B (0,0,1)
Vermelho Azul
níveis de cinza dos pixels em uma região conforme Castleman (1996 apud IEEE Standard 610.4). O padrão pode se repetir com exatidão ou com pequenas variações de tema, possivelmente em função da posição. Existe também um aspecto aleatório da textura que não pode ser ignorado, o tamanho, a forma, a cor e a orientação de elementos do padrão, também chamados de textons, podem variar na região. Algumas vezes, a diferença entre duas texturas está apenas no grau de variação ou na distribuição estatística entre os textons.
Textura é a propriedade possuída por uma região que seja suficientemente grande para demonstrar sua natureza recorrente. A mesma textura exibida em diferentes escalas será percebida como diferentes texturas. É improvável que qualquer operação de medida simples possa permitir a segmentação de regiões de textura em uma imagem digital. As linhas de divisão são freqüentemente arbitrárias e são definidas mais em função da percepção humana. Por outro lado, é possível que alguma combinação de operações possa resultar em segmentações razoavelmente boas para vários tipos de texturas de acordo com Parker (1996).
Quando se deseja medir a textura de uma imagem, deve-se quantificar a natureza da variação de nível de cinza em um objeto. O ruído eletrônico induzido por uma câmera e ruído de grão de filme são exemplos de ruídos aleatórios. Nestes casos a variação em nível de cinza no objeto não exibe um padrão reconhecível. As texturas aleatórias são mais comumente caracterizadas por propriedades estatísticas como o desvio padrão do nível de cinza para a medida da amplitude da textura e a largura da autocorrelação, para a medida do tamanho da textura.
Para uma dada imagem, a transformada de Fourier em duas dimensões contém informações completas sobre a sua textura. Isso pode ser útil para derivar características texturais do espectro como do objeto em si, conforme Castleman (1996).
2.4.3 Matriz de co-ocorrência de níveis de cinza
Uma matriz de co-ocorrência de níveis de cinza (GLCM – gray level co-occurrence matrix) contém informações sobre as posições de pixels que têm valores similares de níveis de cinza. A idéia é percorrer a imagem e calcular a freqüência de pixels que diferem em valor e são separados por uma distância fixa δ em posição. Normalmente, a direção entre dois pixels é também considerada havendo, portanto, múltiplas matrizes, uma para cada direção de interesse. Usualmente, existem quatro direções: horizontal, vertical e as duas diagonais. Para cada valor de δ, existem quatro imagens, cada uma com um tamanho de 256 x 256, para uma imagem original de 256 níveis de cinza. Devido a grande quantidade de dados, o mais usual é analisar essas matrizes e calcular alguns valores numéricos que encapsulam a informação, chamados de descritores, segundo Parker (1996). Um descritor de textura é um valor, calculado a partir da imagem de um objeto, que quantifica alguma característica da variação do nível de cinza de um objeto, conforme Castleman (1996).
A entropia pode ser usada como descritor numérico de textura para a imagem e é mostrada na Equação 6, que é a medida de informação contida na matriz M (PARKER, 1996).
∑
∑
− =j
i P M i j P M i j
H . [ , ]log( . [ , ]) (6)
2.4.4 Filtro de mediana
O filtro de mediana utiliza uma técnica de filtragem não linear, reduz o ruído aleatório sem prejudicar excessivamente os flancos da imagem, sendo comparáveis a filtros lineares passa-baixas, de acordo com Castleman (1996).
2.5 Sistemas
fuzzy
A dificuldade de se obter todas as informações e de equacionar a realidade imprecisa do mundo levou alguns cientistas a propor lógicas alternativas que seriam mais propícias à representação daquele mundo particular, de acordo com Azevedo, Brasil e Oliveira (2000). A lógica fuzzy envolve a captura, representação e trabalho com noções lingüísticas, que se relacionam a objetos que possuem fronteiras indefinidas ou imprecisas.
A função de pertinência gaussiana é definida conforme Equação 7 e um exemplo de seu gráfico para m = 8, mostrado na Figura 6.
A(x) = e-k(x-m)², onde k > 0,
(7)
Função de Pertinência Gaussiana
0 0,2 0,4 0,6 0,8 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Universo
P
er
tin
ên
ci
a
Figura 6 - Função de Pertinência Gaussiana
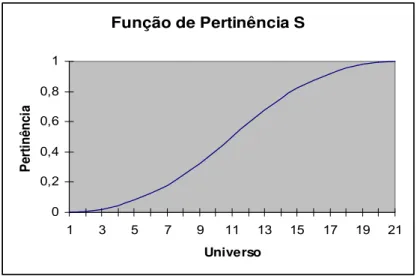
A função de pertinência S é definida conforme Equação 8 e seu gráfico ilustrado na Figura 7.
Função de Pertinência S
0 0,2 0,4 0,6 0,8 1
1 3 5 7 9 11 13 15 17 19 21
Universo
Pe
rt
in
ên
ci
a
Figura 7 - Função de Pertinência S
Como característica de um conjunto fuzzy, a intensificação de contraste diminui os valores de pertinência menores do que ½, enquanto que os graus de pertinência maiores do que este limiar são elevados, reduzindo a difusão do conjunto. A operação de intensificação de contraste é definida pela Equação 9.
(9)
Função de Pertinência Trapezoidal -0,1 0,1 0,3 0,5 0,7 0,9 1,1
1 2 3 4 5 6 7 8 9 10 11
Universo P er ti n ên ci a
Figura 8 - Função de Pertinência Trapezoidal
Função de Pertinência Polinomial
0 0,2 0,4 0,6 0,8 1
1 2 3 4 5 6 7 8 9 10 11
Universo P er ti n ên ci a
Figura 9 - Função de Pertinência Polinomial
2.5.1 Caracterização de informação de conjuntos fuzzy
2.5.2 Entropia como medida de nebulosidade
Seja uma variável X com um número finito de estados de saída x1, x2, ..., xn com as
respectivas probabilidades de ocorrência p1, p2, ..., pn, como mostrado na Equação 10.
(10)
Onde pi = p(xi), e p(x) é a distribuição de probabilidade de um conjunto finito X. A
entropia, de acordo com Shannon (1948), é definida conforme Equação 11.
(11)
A entropia quantifica a incerteza que vem da falta de previsibilidade dos resultados, devido a sua natureza probabilística. A entropia alcança o seu valor máximo quando a probabilidade de ocorrência pn atinge o valor 1/n e se alguma das probabilidades de
ocorrência pn atinge o valor 1, a entropia torna-se igual a 0.
Segundo Cheng (2004b), a entropia fuzzy pode ser definida conforme a Equação 12.
(12)
Onde Sn é a função Shannon, i = 1, 2, . . . , M, j = 1, 2, . . . , N, gij é o nível de cinza do pixel Pij e µx a sua pertinência. Quanto maior a entropia da ocorrência de um evento fuzzy,
mais informação tem o evento fuzzy.
2.5.3 Energia como medida de nebulosidade
(13)
Onde e: [0,1] → [0,1], é uma função incremental sobre o domínio, com as condições de fronteira e(0) = 0 e e(1) = 1. A medida de nebulosidade de energia expressa a massa total do conjunto fuzzy.
2.6 Projeto IACVIRTUAL
Módulo de Dados Dados Clínicos
Descoberta de Conhecimento Base de
Dados Base de Casos
Prontuário Eletrônico do Paciente Processament o de sinais Processament o de imagens Telemedicina
Módulo de Apoio à Decisão
Módulo de I nterface
Hipermídia & Realidade
Virtual
Módulo do usuário
Paciente Estudante Especialista Módulo SWAM SWAM SERN SEBR SEH RBC Módulo Educacional STI RV
Figura 10 - Projeto IACVIRTUAL
O IACVIRTUAL é composto pelos seguintes módulos:
• O Módulo SWAM, sistema Web para análise de mamografia digital com o objetivo de apoiar no diagnóstico médico na identificação da existência de um tumor maligno e seu tratamento.
funcionalidades que permitirão importar modelos volumétricos, codificados nos principais padrões existentes, e visualizar esses modelos através de uma interface gráfica interativa, onde o usuário disporá de ferramentas básicas de navegação tridimensional.
• O Módulo de Apoio à Decisão dá suporte ao diagnóstico médico e, indiretamente, subsidia o Módulo Educacional quanto à resolução de problemas. Ele é composto pelos seguintes sub-módulos:
- O SEH (Sistema Especialista Híbrido), cujo conhecimento é representado por meio de um formalismo que integra regras de produção através do SEBR (Sistema Especialista Baseado em Regras), SERN (Sistema Especialista Baseado em Redes Neurais Artificiais), algoritmo genético e lógica fuzzy, segundo Rojas (2003).
- O RBC (Raciocínio Baseado em Casos), no qual o conhecimento é representado por uma base de casos conforme Silva et al. (2004).
- O Módulo de Dados oferece uma base estruturada de dados e de casos, incluindo os dados clínicos, os elementos para o processamento de imagens e de sinais e para telemedicina. - O Módulo de Interface, além dos elementos clássicos de hipermídia, oferece recursos de realidade virtual.
2.7 Projeto VIRTUATLAS
2.7.1 Objetivos do Atlas Virtual
O projeto VIRTUATLAS (Atlas Virtual de Anatomia e Fisiopatologia da Mama) tem por objetivo implementar um Atlas Virtual da Mama para auxílio a estudos da anatomia e estruturas da mama, bem como estudo sobre o desenvolvimento dos carcinomas mamários, suas diversas fases e as estruturas envolvidas, utilizando técnicas de RV. Os objetivos do projeto Virtuatlas são:
1. Construir modelos de simulação da anatomia da mama; 2. Construir modelos de simulação da fisiopatologia da mama;
3. Construir uma base de dados visuais e textuais relativos à anatomia e à fisiopatologia da mama em suas mais diversas manifestações, que possa ser acessado por descritores previamente estabelecidos;
4. Construir mecanismos de interface baseados em Realidade Virtual como provedores de informações para finalidades didáticas e terapêuticas;
5. Criar procedimentos de utilização do Atlas Virtual da mama através de STI. 2.7.2 Descrição do Atlas Virtual
O Atlas Virtual da Mama pode ser dividido em duas partes. A primeira é responsável pela anatomia da mama, mostrando as estruturas anatômicas internas. A segunda é relacionada ao desenvolvimento do câncer de mama em suas diversas estruturas e diferentes tipos em qualquer dos vários estágios de desenvolvimento da patologia.
opção de visualizar todas as estruturas internas, dispostas em camadas. Em uma das opções disponíveis, o usuário poderá ainda visualizar qualquer uma das camadas das estruturas internas da mama e com opção de aproximação. A Figura 11 mostra a arquitetura do projeto VIRTUATLAS.
Figura 11- Projeto VIRTUATLAS
2.8 Mamografia
2.8.1 O câncer de mama
De acordo com a OMS (2006), em todo o mundo cerca de um milhão de mulheres descobre que está com câncer de mama a cada ano. Segundo o INCA (2006), o número de novos casos de câncer de mama esperados para o Brasil em 2006 é de 48.930, com um risco estimado de 52 casos a cada 100 mil mulheres.
No corpo humano as células estão constantemente se reproduzindo através do processo chamado de mitose, onde uma célula adulta divide-se em duas. A mitose é realizada de forma controlada dentro do organismo, porém em determinadas ocasiões e por motivos ainda
Módulo de Anatomia Fisiopatologia do Câncer Recursos de Estereoscopia
Atlas Virtual da Mama
Navegação pelas estruturas Informações sobre Anatomia Exibição do desenvolvimento do Câncer
Dados sobre o tumor Informaçãoes para processamento estereoscópico Dados para desenv. Câncer Informações para processamento estereoscópico Imagens estereoscópicas
Banco de Dados - VirtuAtlasDB Módulo de Anatomia Módulo de Anatomia Fisiopatologia do Câncer Recursos de Estereoscopia Recursos de Estereoscopia
Atlas Virtual da Mama
Navegação pelas estruturas Informações sobre Anatomia Exibição do desenvolvimento do Câncer
Dados sobre o tumor Informaçãoes para processamento estereoscópico Dados para desenv. Câncer Informações para processamento estereoscópico Imagens estereoscópicas
desconhecidos, determinadas células reproduzem-se com uma velocidade maior, resultando em massas celulares chamadas neoplasias segundo Leite (apud GOUMOT, 1993).
As neoplasias malignas apresentam um crescimento rápido desordenado e infiltrativo, onde as células não guardam semelhanças com as que lhes deram origem e se desenvolvem em outras partes do corpo, fenômeno denominado metástase, característica mais marcante dos tumores malignos segundo Leite (apud GOUMOT, 1993).
O câncer de mama mínimo é definido como um câncer de menos de 1,0 cm de diâmetro não invasivo. A maioria dos cânceres que são clinicamente palpáveis medem 1 cm ou mais de tamanho. Mesmo os cânceres mamários mínimos de 0,5 cm de diâmetro, tidos como clinicamente iniciais, representam um tumor biologicamente tardio. O tamanho médio dos cânceres detectados por auto-exame é maior do que 2 cm de acordo com Santos (2002). O câncer de mama comporta-se de forma menos previsível do que outros cânceres e pacientes com câncer de mama podem sucumbir muito rapidamente. A sobrevida das pacientes depende do tamanho do tumor no diagnóstico inicial e da presença ou ausência de linfonodos auxiliares positivos. O diagnóstico precoce, portanto, não apenas influencia o prognóstico, mas propicia uma cirurgia cosmeticamente mais aceitável que pode fornecer índices livres de recidiva e de sobrevida comparáveis as intervenções cirúrgicas mais dramáticas e agressivas, conforme Santos (2002). O diagnóstico precoce do câncer de mama seria melhorado se as técnicas pudessem detectar com precisão e de forma não invasiva as alterações pré-cancerosas hiperplásicas.
2.8.2 Calcificações
muitas calcificações benignas, também são geralmente muito pequenas e, freqüentemente, exigem o uso de uma lente de aumento para serem vistas, segundo BI-RADS® (2005).
De acordo com BI-RADS® (2005), as calcificações dividem-se em: 1. Tipicamente benignas
a. Calcificações na pele: Possuem centro radiotransparente e, freqüentemente, são patognomônicas em sua aparência;
b. Calcificações vasculares: Possuem trilhas paralelas ou calcificações lineares que são claramente associadas com estruturas tubulares;
c. Calcificações grosseiras ou semelhantes a “pipoca”: São calcificações grandes, maiores do que 2 mm de diâmetro, produzidas por um fibroadenoma em involução;
d. Calcificações grandes semelhantes a bastonetes: São calcificações associadas à ectasia ductal, podem formar bastonetes lineares, sólidos ou descontínuos, geralmente maiores do que 1 mm de diâmetro.
e. Calcificações redondas: quando múltiplas podem variar em tamanho. Podem ser consideradas benignas quando se encontram dispersas.
f. Calcificações com centro radiotransparente: São calcificações que variam de 1mm a 1 cm de tamanho, redondos ou ovóides, com superfície lisa e centro radiotransparente. g. Calcificações em “casca de ovo” ou em “anel”: São calcificações finas que aparecem
como cálcio depositado sobre a superfície de uma esfera.
h. Calcificações em “leite de cálcio”: São calcificações sedimentadas em macro ou microcistos, aparecem na mamografia craniocaudal como depósitos amorfos, indistintos, redondos, enquanto na incidência lateral em 90º elas são mais claramente definidas, em forma de meia-lua, crescente, curvilínea ou linear.
j. Calcificações distróficas: geralmente se formam na mama irradiada ou na mama pós-trauma, são grosseiras e maiores do que 0,5 mm.
2. Preocupação intermediária, calcificações suspeitas
a. Calcificações amorfas ou indistintas: São suficientemente pequenas ou de aparência imprecisa. Justificam uma biópsia quando agrupadas, de forma regional, linear ou segmentar.
b. Calcificações heterogêneas grosseiras: São irregulares, evidentes, maiores do que 0,5 mm e tendem a coalescer, mas não tem o tamanho das calcificações distróficas irregulares.
3. Alta probabilidade de malignidade
a. Calcificações pleomórficas finas: São geralmente mais visíveis que as de forma amorfa e não se enquadram na classificação 2a nem 3b. Variam de tamanho e forma e tem usualmente, menos do que 0,5 mm de diâmetro.
3.1 Classificação da pesquisa
Essa pesquisa pode ser identificada quanto à natureza como aplicada, quanto à abordagem do problema como quantitativa. Quanto aos fins como descritiva, quanto aos meios de investigação como bibliográfica e de campo, segundo Moresi (2003).
É pesquisa aplicada porque está dirigida à solução de um problema específico: desenvolver um sistema neuro-fuzzy para reconhecimento de padrões de calcificações em mamogramas. Trata-se também de uma pesquisa quantitativa, pois serão coletados dados referentes à eficiência do sistema para atingir o objetivo desejado.
Constitui-se em pesquisa descritiva porque se pretende analisar características de uma determinada população de mamogramas e estabelecer correlações para um diagnóstico médico. É pesquisa bibliográfica, pois compreende o estudo sistematizado a partir de conhecimentos disponibilizados em artigos, livros, periódicos, jornais, acervos de dados eletrônicos, entre outros.
Por fim, é de campo, na medida em que se aplicarão técnicas de RNA, testes, treinamento e observação dos resultados a partir de casos reais de bases de dados digitais de mamogramas.
3.2 Hipótese
Esta pesquisa pretende testar a seguinte hipótese:
3.3 Coleta e análise de dados
Como base para os experimentos, será utilizada o banco de dados de imagens mamográficas Mini MIAS (Mini Mammographic Database) Suckling et al. (1994).
Este banco de imagens possui 322 casos de mamogramas, sendo que 27 deles são casos de calcificações malignas ou benignas. O Mini MIAS ainda não se enquadra no padrão de classificação do BI-RADS® (2005) e as informações do mesmo são apresentadas no Quadro 1.
Quadro 1 – Informações fornecidas pela base de dados Mini MIAS (Suckling et al., 1994)
MAMMOGRAPHIC IMAGE ANALYSIS SOCIETY
MiniMammographic Database
Thank you for downloading the MIAS MiniMammographic Database. By
popular request the original MIAS Database (digitised at 50 micron pixel edge) has been reduced to 200 micron pixel edge and clipped/padded so that every image is 1024 pixels x 1024 pixels.
Feel free to use the database in any of your scientific research, but please read the licence agreement first (Licence.txt).
If you have have any questions/comments about the data or would like information on how to get the original MIAS Database please contact me at the address below. You will be put on a mailing list for further information about any upgrades of this database. See also our WWW-page at http://skye.icr.ac.uk/miasdb/miasdb.html for updated information.
John Suckling
Department of Physics Royal Marsden Hospital Fulham Road, London. SW3 6JJ, UK.
Email: j.suckling@rmh_lon.icr.ac.uk 19 January 1995
================================================================= CREDITS:
Organiser: J Suckling
Truth-Data: C R M Boggis and I Hutt
Co-Workers: S Astley, D Betal, N Cerneaz, D R Dance, S-L Kok, J Parker, I Ricketts, J Savage, E Stamatakis and P Taylor.
Special Thanks: N Karrsemeijer.
Pilot European Image Processing Archive (PEIPA) Orgainser: A Clark. ================================================================= REFERENCE:
J Suckling et al (1994) "The Mammographic Image Analysis Society Digital Mammogram Database" Exerpta Medica. International Congress Series
1069 pp375-378.
================================================================= INFORMATION:
appropriate details as follows:
1st column: MIAS database reference number. 2nd column: Character of background tissue: F - Fatty
G - Fatty-glandular D - Dense-glandular
3rd column: Class of abnormality present: CALC - Calcification
CIRC - Well-defined/circumscribed masses SPIC - Spiculated masses
MISC - Other, ill-defined masses ARCH - Architectural distortion ASYM - Asymmetry
NORM - Normal
4th column: Severity of abnormality; B - Benign
M - Malignant
5th,6th columns: x,y image-coordinates of centre of abnormality. 7th column: Approximate radius (in pixels) of a circle enclosing
the abnormality. NOTES
=====
1) The list is arranged in pairs of films, where each pair
represents the left (even filename numbers) and right mammograms (odd filename numbers) of a single patient.
2) The size of ALL the images is 1024 pixels x 1024 pixels. The images have been centered in the matrix.
3) When calcifications are present, centre locations and radii apply to clusters rather than individual calcifications. Coordinate system origin is the bottom-left corner.
4) In some cases calcifications are widely distributed throughout the image rather than concentrated at a single site. In these cases centre locations and radii are inappropriate and have been omitted.
================================================================= mdb001 G CIRC B 535 425 197
mdb002 G CIRC B 522 280 69 mdb003 D NORM
mdb004 D NORM
mdb005 F CIRC B 477 133 30
3.4 Delimitação do estudo
3.5 O modelo proposto
O sistema proposto consiste de quatro estágios: pré-processamento, detecção, extração de características e classificação, os quais são mostrados na Figura 12 e explicados nos parágrafos subseqüentes.
Figura 12 - Sistema proposto
Na fase de pré-processamento, as imagens utilizadas foram provenientes da base de dados Mini MIAS, as quais neste estudo foram selecionadas de um total de 322 imagens, pelo critério de apenas conter calcificações, resultando em um total de 19 casos adequados, contendo 12 casos malignos e 7 casos benignos. Utilizando o método de validação cruzada, com um procedimento pseudo-aleatório, as imagens foram divididas igualmente em dois grupos, um de treinamento e outro de teste. O conjunto de treinamento é, então, dividido em dois outros subconjuntos, isto é, 70% para estimação e 30% paravalidação, ajuste este devido ao tamanho da amostra de dados ser muito pequena, conforme está ilustrada na Figura 13.
Pré-Processamento
Extração de Características Texturais
Figura 13 – Fluxograma de Pré-Processamento com validação cruzada
A próxima fase foi a de detecção, onde de cada imagem de mamograma foi extraída a ROI, localização indicada pela base de dados Mini MIAS, utilizando-se a função imcrop da linguagem Matlab (2003). Com cada ROI foi realizada uma operação de retirada de imagem de fundo, utilizando as funções imopen(K,strel('disk', 15)) e imsubtract(K,background), Em seguida foi realizada uma operação de aumento de contraste utilizando a função imadjust(I2). Para redução de ruído, utilizou-se um filtro de mediana medfilt2(I4,[3 3]) que reduz o ruído preservando os flancos da imagem, conforme Figura 14.
Início
Selecionar Mamogramas com
Calcificação
Divisão Pseudo-Aleatória (50% / 50%)
Conjunto de testes
Conjunto de treinamento
Divisão Pseudo-Aleatória (70% / 30%)
Conjunto de estimação
Figura 14 - Fluxograma de Detecção
Na fase de extração de características, foram extraídos de todas as 19 ROI manipuladas os descritores texturais de entropia, energia e homogeneidade, de acordo com a Figura 15.
Figura 15 - Fluxograma de Extração de Características Texturais
Início
Extração da entropia
Extração da energia
Extração da homogeneidade
Resultados Início
Extração da ROI
Retirada da imagem de fundo
Aumento de contraste da imagem
Redução de ruído
A fase de classificação ANFIS foi realizada com os descritores de textura resultantes da fase de extração de características texturais dos conjuntos de estimação, validação e testes, referenciando como saída da rede ANFIS a benignidade com o valor numérico 0 e a malignidade com o valor numérico 1.
Inicialmente, o arquivo do conjunto de estimação foi submetido ao ANFISEDIT, que é uma implementação do modelo ANFIS no Matlab (2003), e em seguida, a rede ANFIS foi treinada. Na seqüência, a rede é validada com o arquivo de validação, caso não atinja uma boa performance, a rede é treinada novamente com o conjunto de estimação com uma variação de parâmetros como épocas, funções de pertinência e tipo de aprendizado híbrido ou
Figura 16 - Fluxograma de Classificação utilizando o modelo ANFIS
Com a rede ANFIS treinada, o especialista médico poderá submeter novas imagens, sem diagnóstico estabelecido, e conseguir uma segunda opinião com relação à imagem estudada.
Sim
Não Início
Treinamento ANFIS
Validação ANFIS
Conjunto de estimação
Conjunto de validação
Performance adequada?
Testes ANFIS
Conjunto de testes