A Minimal Spiking Neural Network to Rapidly Train and Classify Handwritten Digits in Binary and 10-Digit Tasks
Texto
Imagem

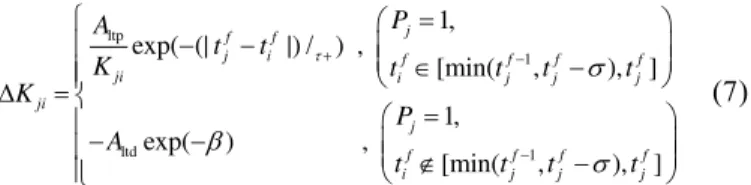
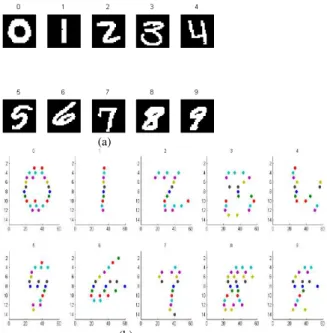

Documentos relacionados
Abstract – The purpose of this work was to evaluate a methodology of adaptability and phenotypic stability of alfalfa genotypes based on the training of an artificial neural
Neste trabalho, apresentam-se pesquisas realizadas por integrantes do (TRANS)FORMAÇÃO, organizando-as em três categorias, a partir de um recorte que tornasse
Unsupervised learning is a machine learning technique that sets parameters of an artificial neural network based on given data and a cost function which is to be
O estudo efetuado através da revisão bibliográfica mostrou que os autores concordam que certos cuidados são capazes de evitar os acidentes e indicam que a agulha utilizada
A PSO-based artificial neural network has been proposed as an intelligent prediction approach to estimate product compositions of a binary distillation column; boil-up and reflux
In this paper, an RBF neural network was used as a classifier in the face and fingerprint recognition system in which the inputs to the neural network are
In this paper, genetic algorithm based artificial neural network hybrid prediction model is proposed to foretell surface roughness and tool wear.. A multiple
In line with this, artificial neural network technology of backpropagation neural network (BPNN), radial basis function neural network (RBFNN) and generalized regression
