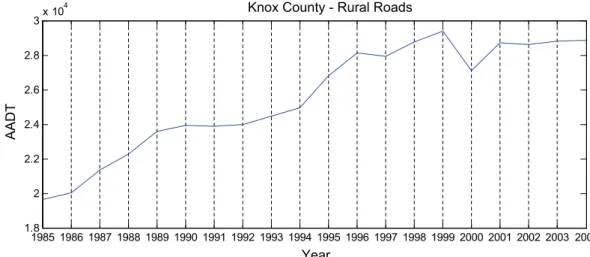
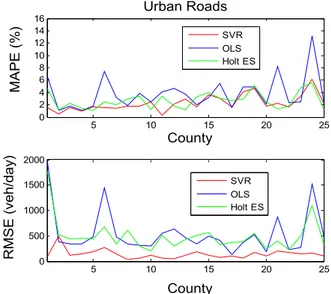
AADT prediction using support vector regression with data-dependent parameters
Texto
Imagem
Documentos relacionados
conc jorna de co entre conv pela narra const jorna (LAG nacio socia base probl revol socio socia jorna sejam verac como de m 2004 jorna (2007 realid jorna coisa que notíc e
To determine the adulteration of petrodiesel/biodiesel blends with palm oil, the prediction model was built using PLS regression, and the infrared spectral data from the analysis
Sabendo-se dos benefícios potenciais do cicloer- gômetro para melhora do condicionamento cardio- vascular, desempenho físico e dos possíveis riscos associados ao cicloergômetro
Using data from a subset of the participants, called the development cohort, a logistic regression model with the outcome (in our example, 1-year mortality) as the dependent
computational journalism to support and make the work of a data journalist easier, like. applications that help visualize the results of data stories such as
O presente Relatório de Mestrado dá resposta ao exposto no Regulamento do Curso de Mestrado em Enfermagem Médico-Cirúrgica da Escola Superior de Enfermagem São José
In other words, instead of the transportation costs that the producers use for the transportation of mulberry leaves to be used in the production activities, the
A observação realizada teve como objetivo observar os grupos em geral, de modo a perceber os funcionamentos e hábitos, mas também as crianças/alunos
