Taherkhani performed the literature review, analyzed the data, performed the categorization and wrote most of the paper, with Korhonen and Malmi providing feedback and suggestions throughout the process. Taherkhani analyzed the data, performed the evaluation and wrote most of the paper, with Korhonen and Malmi providing feedback and suggestions throughout the process.
Motivation
For example, all the following problems share the common task of identifying algorithms/parts of source code and thus can apply AR methods: source code optimization [65] (tuning existing algorithms or replacing them with more efficient ones), clone detection [4, 60] (recognizing and removing clones as an essential part of code refactoring), software maintenance (especially maintaining large legacy code with insufficient or non-existent documentation), and program translation via abstraction and reimplementation [100] (the source-to-source translation approach, which involves abstract understanding of what the target program does).
Research Questions
We investigate the applicability of programming schemes and algorithm-specific characteristics and beacons in AR. As discussed above, we analyze basic algorithms to find a set of distinctive and algorithm-specific characteristics and beacons.
Structure of the Thesis
Similar studies should be done for all algorithms and their variations that we would like to comment on. The results can be used to develop a tool that provides useful feedback on student implementation.
Algorithm Recognition and Related Work 7
Related Work
- Program Comprehension
- Clone Detection
- Program Similarity Evaluation Techniques
- Reverse Engineering Techniques
- Roles of Variables
Cognitive structures include the programmer's knowledge base (his/her prior knowledge and the domain knowledge related to the target program) and the mental representation he/she has built up of the target program. An assimilation process is the process of building a mental representation of the target program using the knowledge base and the given representation of the program.
![Figure 2.1. Key elements of program comprehension models [89]](https://thumb-eu.123doks.com/thumbv2/9pdfco/19364285.0/26.748.259.587.67.392/figure-key-elements-of-program-comprehension-models-89.webp)
Program Comprehension and Roles of Variables, a Theoret-
Roles of Variables
- An Example
For example, a variable used to store a value in a program for a short period of time can be assigned a temporary role. Most Wanted Holds A variable that has the most desirable value found so far.
The Link Between RoV and PC
In the Beta program, the variable name (max) does not reflect its function, which is a minimum search function. The conclusion was that blueprint-like programs help programmers in the PC task and that critical lines are important in the process. They then store the value of the current number in the variable that holds the min/max value, if it is less/greater than the current value of that variable.
Since line 9 in Figure 3.2 is a critical line, the most searched holder role can therefore also be considered a critical line (or a beacon) in a search plan. Swap operations typically include a temporary role, and so this role can be considered part of the lighthouse in the example in Figure 3.1. As discussed in Chapter 2, in a study on the effects of teaching RoV in elementary programming courses, Kuittinen and Sajaniemi [55] found that "the teaching of roles appears to help the adoption of programming strategies related to deep program structures, i.e. variables".
![Figure 3.2. Plan-like and unplan-like programs used in Soloway and Ehrlich PC study [91]](https://thumb-eu.123doks.com/thumbv2/9pdfco/19364285.0/41.748.90.557.70.217/figure-plan-like-unplan-programs-soloway-ehrlich-study.webp)
Decision Tree Classifiers and the C5 Algorithm 27
The C4.5 Decision Tree Classifier
We chose the C4.5 algorithm [77] to build the decision tree because it is a widely used and the most well-known algorithm to do so, and has a good combination of error rate and speed [58]. The C4.5 algorithm retains the advantages of its predecessor, the ID3 algorithm [76], but is further developed in many respects. More details on how the C4.5 algorithm handles the important issues related to building decision trees presented in the previous section can be found in Appendix A.
Overall Process and Common Characteristics 31
Common Characteristics
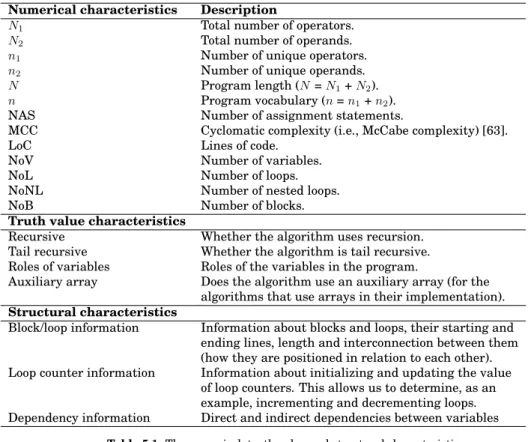
- Computing Characteristics
The features of Table 5.1 were selected based on manual analyzes of many different types of sorting algorithms in the early stages of our work, and as a result of literature searches, especially of program similarity evaluation techniques discussed in Chapter 2. To cover variations of sorting algorithms and other algorithms, we have distinguished several other useful beacons that, in addition to these features, are calculated from the given code and used in the process. The features and related beacons are stored in a database and so each algorithm is represented by an ann-dimensional vector in the database, which contains the number of features and beacons.
Roles are also benchmarks in the sense that, as we will discuss in Chapter 6, the existence of certain roles in implementations of certain types of algorithms are examined as algorithm-specific features to distinguish those algorithms from others. As a software metric, the cyclomatic complexity can be calculated as CC="The number of decision points (ie, ifstatements or conditional loops)" + 1 [63]. In the next section, we will discuss how the roles of variables are detected from a program.
The Tool for Detecting Roles of Variables
U Variable is assigned with a value resulting from the instantiation of a new object or directly with a Boolean value. Therefore, the tool allows users to assign a role to a variable and check whether the tool agrees. Although specifying a role for a variable is optional, special tags must be specified for each variable in a program along with the variable name, otherwise the utility will not consider the variable.
During our project, we improved the tool in this and other aspects to make the role discovery process fully automatic and to make it more suitable for our purpose. For example, in some implementations that used a Do-While loop, the tool did not correctly detect conditions for a one-way flag role. We developed a way to automatically provide the above-mentioned required special tags and improved the tool in many ways in order to extract the detected roles directly from the tool for further processing.
![Table 5.2. The rules based on which roles of variables are detected. See [9]](https://thumb-eu.123doks.com/thumbv2/9pdfco/19364285.0/55.748.97.549.58.426/table-5-2-rules-based-roles-variables-detected.webp)
Schemas and Beacons for an Analyzed Set of Algorithms 41
- Schemas for Sorting Algorithms
- Schemas for Searching, Heap, Basic Tree Traversal
- Detecting Schemas
- Beacons
- Beacons for Sorting Algorithms
- Beacons for Searching, Heap, Basic Tree Traversal
Additionally, the inner loop counter is initialized to the value of the outer loop counter. Additionally, the inner loop counter is initialized to the value of the outer loop counter. Swap_inner_loop: Whether the swap operation is performed in the inner loop of two nested loops.
IITO(Inner loop counter initialized to outer loop counter): whether from the two nested loops, the inner loop counter is initialized to the value of the outer loop counter. Shift_inner_loop: Whether a shift operation is used in the innermost loop of the two nested loops. MPSL (MidPoint Search in a Loop): Whether the algorithm implementation includes searching for the center of an array within a loop.

Empirical studies and Results 51
- The Data Sets
- The Publications and Empirical studies
- Manual Analysis and the Classification Tree Constructed by
- Manual Analysis
- The Classification Tree Constructed by the C4.5 Algo-
- Students’ Sorting Algorithm Implementations, a Categoriza-
- Categorizing the Variations
- Automatic Recognition
- Using the SDM and CLM for Recognizing Sorting Algorithms
- The SDM
- The CSC
- The Decision Tree and Classification Accuracy
- Recognizing the Students’ Implementations
Other" consists of the implementation of other standard algorithms (Shellsort and Heapsort), the implementation of less known inefficient sorting algorithms (such as Bozo sort, Bogosort and Gnome sort) and the implementation of student-made inefficient algorithms (see Publication III for more details on these variations). We tested the performance of the method using 217 implementations of sorting and other algorithms (see Section 7.1). We used the datasets M S2 and SU B1 (see Table 7.1) to evaluate the performance of the method.
We evaluated the classification performance estimation using the leave-one-out cross-validation method. The estimated classification accuracy, measured by the leave-one-out cross-validation method, was 97.3%. Figure 7.2 shows how accurately the implementations of the dataset are recognized by the SDM.

Discussion and Conclusions 69
Applications of the Method
This would allow the teacher to focus only on the solutions that do not meet the specification, rather than reviewing all submissions. Moreover, a teacher can sample the positive cases and assess the accuracy of the system on the false positive cases within a certain time. This will give an indication of the benefit of the system (such as saving teacher time) compared to the accepted incorrect cases.
This application of the method would enable the teacher to give better personal feedback to the students and get interesting examples to discuss with them. Additionally, we need to evaluate our method in an educational setting and investigate how students use the system and how useful they find it. However, since these activities involve large-scale software handling (unlike applications in computer science education), the performance of the method in this context needs to be evaluated with empirical tests.
Our Methods and Other Research Fields
As an example, the task in clone detection is to identify similar pieces of code. An important part of these beacons are the roles of variables, for which we have introduced a new application area in this thesis.
Research Questions Revisited and Future Work
As an example, the most-searched container role distinguishes the implementations of Selection Sorts from the implementations of other sorting algorithms we have analyzed. However, when analyzing search, heap, basic tree traversal and graph algorithms, the tool did not detect the roles of the variables in the implementation of these algorithms accurately enough. Converting implementations of algorithms to feature and beacon vectors and using these vectors as technical definitions of algorithms allows us to use machine learning techniques.
The use of the C4.5 decision tree classifier in our CLM and the estimated classification performance illustrate the applicability of the C4.5 algorithm as a supervised machine learning classification technique. However, as expected, if implementations of algorithms that Aari has no mechanism to deal with are involved, the accuracy decreases. In the thesis, we studied the use of the presented techniques on programs written in Java.
Validity
- Internal Validity
- External Validity
InProceedings of the 14th Annual Workshop on the Psychology of Programming Interest Group (PPIG '02), Brunel University, London, UK., pages. InProceedings of the 10th Koli Calling International Conference on Computing Education Research (Koli Calling 2010), pages 86–93. InProceedings of the 12th Annual SIGCSE Conference on Innovation and Technology in Computer Science Education (ITiCSE '07), pages 73–77.
InProceedings of the 9th Annual SIGCSE Conference on Innovation and Technology in Computer Science Education (Leeds, United Kingdom, 2004), pages. InProceedings of the 17th Annual Workshop on the Psychology of Programming Interest Group (PPIG '05), University of Sussex, UK, 2005. The information gain ratio is the ratio of the information gain to the information split.
Finding the Right Size
The issue of finding the right size in Algorithm C4.5 is handled by pruning the tree after it has been constructed. The tree is built using the divide-and-conquer principle without evaluating any partitions in the build phase. This results in a nested tree, which is then pruned to make it simpler: those parts of the tree that are not important in terms of accuracy are removed.
This approach involves an additional calculation for building the parts of the tree that will be eliminated later in the pruning phase. In the C4.5 algorithm, pruning involves replacing subtrees with leaves or with one of their branches. The process starts from the bottom of the tree and continues by examining each non-leaf subtree.
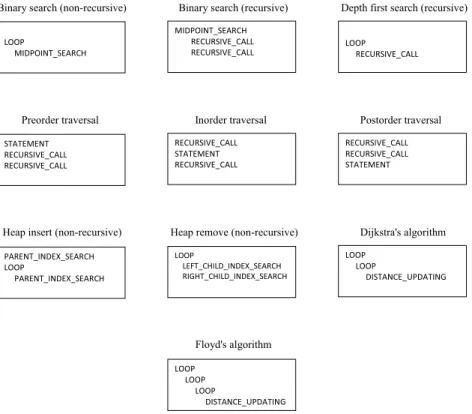
Pseudo-Code for Sorting, Searching, Heap, Basic Tree Traversal
- Binary Search Algorithms
- Depth First Search Algorithm
- Tree Traversal Algorithms
- Heap Algorithms
- Graph Algorithms
In subsection 5.4 on page 1062, 'column in blue' should be 'column in light grey', 'column in green' should be 'column in medium grey' and 'column in red' should be 'column in dark grey'.