Using whole-genome sequence data to predict quantitative trait phenotypes in Drosophila melanogaster.
Texto
Imagem
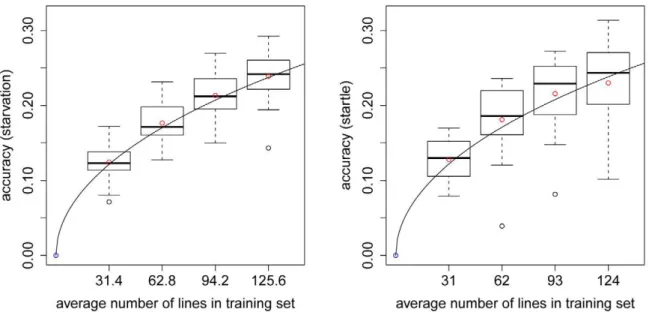

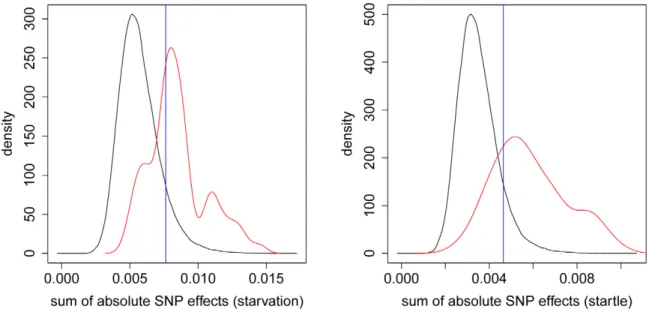

Documentos relacionados
glabrata biofilm formation and control, through the quantification of cultivable cells, total biomass and matrix composition, and through the evaluation of the
Genome - wide selection (GWS) consists of using hundreds to thousands of markers saturating the genome in order to predict genomic breeding values (GEBV) of
The rate of spurious IBD detection in fastIBD was substantially lower than GERMLINE and ISCA, and we did not observe an excess of detected relationships among control populations
In this study we have developed a method to predict, using only sequence composition of the interacting proteins, the functional class of human TF binding partners to be (i) TF,
A busca de uma autonomia no mundo das produções artísticas é um longo caminho construído historicamente: a edificação de um espaço próprio para a arte, galgado
mansoni database provides the community wide access to the latest genome sequence, annotation and other types of data integrated with the genome information.. The genome data
Using the indica variety genome, the IRGSP data, and the expressed sequence tags (ESTs) deposited in public databanks, we performed an analysis of the rice genome searching
We determined the complete nucleotide sequence of the Cyclemys atripons mito- chondrial genome (mtDNA) and found it to be 16,500 base pairs (bp) in length, with the genome
