E'v
Departa,rnento de
Informática
Constraint
Programming on a
Heterogeneous
Multicore
Architecture
Rui
Mário
da Silva Machado
<[email protected]>Supervisor:
Salvador
Abreu
(Uuiversidade de Évora, DI)Évora
Departarnento
de
Informática
Constraint
Prograrnming on a
Heterogeneous
Multicore
fuchitecture
Rui
Mrírio
da Silva Machado
<[email protected]>Supervisor:
Salvador
Abreu
(Universidade de Évora, DI)try
í)l
Évora
Abstract
Constraint programming libra,ries are useftrl when
building
applications developedmostly
in
mainstrearn programming languages:they
donot
requirethe
developersto acquire skills for a new language, providing instead declarative progra,mming tools
for
usewithin
conventional systerns. Some approachesto
constraint programming favour completeness, such as propagation-based systems. Others axe more interestedin
gettingto
a good solution fast, rega,rdless of whetherall
solutions may be found;this
approach is usedin
local search systerns. Designinghybrid
approaches (propa"gation
*
local search) seerls promising since the advantages may be combined intoa single approach.
Parallel architectures are becoming more corrmonplace,
partly
due to the largescaleavailability
ofindiüdual
systernsbut
also because of the trend towa.rds generalizingthe
use of multicore microprocessors.In
this
thesis an architecture for mixed constraint solvers is proposed, relying both on propagation and local search, which is designedto
function
effectivelyin
ahet-erogeneouÉr multicore architecture.
Resumo
Programação
com
restrições numa
arquitectura
multi-processador heterogénea
As bibüotecas pâra programaçã,o com restrições são úteis ao desenvolverem-se aplicações
em linguagens de progra,macão normalmente mais utilizadas pois não necessita,m que os progra,madores aprendarr
uma
nova linguagem, fornecendo ferra,mentas de programação declarativa para utilizacão com os sistemas convencionais. Algumas soluções para prograrnação comrestriçõe
favorecem completude, tais como sistemas baseadm em propagaçã,o. Outras etã,o mais interesadas em obter uma boa solucã,orapidamente, rejeitando
a
necessidade de encontrar todas as soluçôm; esta sendoa
alternatirmutilizada
nos sistemas de pesquisalocal.
Concebersoluçõs
hÍbridas (propagação*
pesquisa local) parece prometedor pois as vantagens de a,mbasalter-natirms podem ser combinadas numa única solução.
As
arquitecturas paralelas são cada vez mais comuns, em parte devidoà
disponi-bilidade em graude escala de sistemas individuais mas ta,mMm devido à tendência em generelizar o uso de processadota
multi,ure
ou seja, processadores com váriasunidade
de procmsa,mento.Nesta tese é proposta uma arquitectura para
reolvedore
deretriçõe
mistos, de-pendendo de métodos de propagaçãoe
pesquisalocal,
a
qual
foi
concebida para ftrncionar eficazmente num& arquitectura heterogénea multiprocessador.Acknowledgments
This
important
phase of my life could not have been so successful asit
waswithout
the support of people
I
know and met a,ndto
whomI
am profoundly thankful.First
ofall,
I
would liketo
thank
my loving parents and my brotherjust
for
being present.A
loving thanksto
my girlfriend
Swanifor
being herself,for
the
patience, adücea,nd her love.
I
would liketo
dedicate herthis
work.A
very
specialthanks
to
my
tutor
Dr.
Werner Kriechbaum a.ndmy
advisor Dr.Salvador
Abreu
for their time, availabüty
support,
leadership and friendship atevery moment.
Thanks
to
all
ofthe Linux
on Cell Test and Development Tearns as well my whole departmentwith
whom was a pleasureto
workwith.
Contents
I
Introduction
2
Background
2.L
Architectures2.2
Parallel Progre.mming2.3
Dmigning Parallel Programs2.4
Parallelism andProgram-ing
Languages2.5
Constraint Progra.rnrning2.6
Summary3
AJACS
3.1
Concepts.
.3.2
An
E:<a,mple3.3
Parallel execution architecture3.4
Summary4
CelI Broadband Engine
4.L
Overview4.2
Povrer Processor Element-
PPEg 13
t4
16 23 25 27 3E4l
4L 43M
48 50 50 524.3
Synergistic Procmsor Element-
SPE4.4
Prograrnming theCell/B.E.
4.5
Surnmary5
Design of
the
frarnework
5.1
Overview 53 bD 58 60 60 62 62 63 66 75 80 8L 85 88 90 90 91 93 98 105 106 5.2 5.3 5.4 CASPER System Architecture AJACS Level5.5
Cell Level5.6
Application Level
.
.5.7
Extending the search5.8
Adaptive Search5.9
Comparisonwith
other work 5.10 Summary6
Experimental evaluation
6.1
Hardwa,re and Sofüware environment6.2
Test programs6.3
Tests results .6.4
Results interpretation7
Conclusion
7.L
F\rture workList
of
Figures
2.L.1,
Shared memory architecture2.L.2
Distributed
memory architecture2.7.3
Hybrid
memory a,rchitecture3.2.1
Timetabling
exa,mple3.3.1
Ajacs parallelarchitecture
.3.3.2
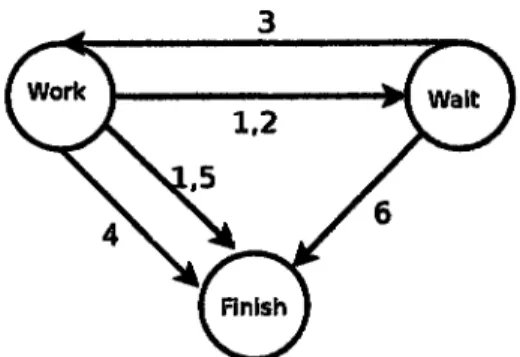
Worker's statetransition
diagra,mL4 15 16 45 46 4E 52 53 54 57 63
M
73 95.74
Cell Broadband Eqgtne Power Processor Element Synergistic
Procesor
Element4.4.1
Cesof file creation4.L.1, 4.2.L 4.3.1 5.3.1 5.4.L 5.5.1 System architecture Storm
split
List
inde»< synchronization5.5.2
Solutionsindor
synchronization.
.6.3.1
Queens4plot
6.3.3 6.3.4 6.3.5 6.3.6 QueensS
plot
Moneyplot
Modified Golomb Ruler
plot
Golomb Ruler
plot
.96 97 99 99
List
of
Tâhtres
3.3.1
W-worker;Gcontroller;
X-some worker;U-list
of workers .6.1.1
Hardware environment6.L.2
Sofbware environment 6.3.1 6.3.2 6.3.3 6.3.4 6.3.5 6.3.6 Queens Overhead Queens resultsSEND+MORE:MONEY
OverheadSEND+MORE:MONEY
Results Golomb Ruler OverheadGolomb Ruler Rmults
4E 91 91 93 94 96 97 97 98
Chapter
1
Introduction
The
umplerity
for
mi,ni,mum component costs has,increased, at a rateof
roughly afactor of
twoper year
...
Certai,nly ouer the shor-t termthi,s rate can be etyected
to
conti,nue,if
not
to ,increase. Oaer the longerterm,
therate
of
incrense i,sa
bi,t more uncertai,n, although thereis
no reasonto
belieaeit uill
not rema'in nearlyunstant
for
at,least 10 Aears.That means by 1975, the number of rcmponents per i,ntegrateil ci,rcui,t
for
mi,ni,mum cost, wi,ll be 65,000.
I
beli,euethat
sucha
large ci,rcui,t can bebui,lt on a si,ngle wafer.
-
Moore, GordonE.
(1965)The microprocessor industry has been shifbing its focus towards multiprocessor chips. Ever since
it
was stated, Moore's law has adequately described the progress of newly developed processors.Before
the
turn
of the
millennium,the
perform&nce improvementsof
a
processor weremostly driven by
frequency scalingof
an
uniprocessor.Still,
multiprocessorchips were already seen as
a valid
approachto
increase performa,nce.The
focuson multiprocessor designs became clear
with
the
diminishing returnsof
frequency scaling and sometimes physicallimitations
emerging.The emergence of chip multiprocessors is a consequence of a number of
limitations in
benefits of technology scaling
for
higher frequency operation, po\reÍ dissipationap
proaching
limit
and memory latency.To addrms thme
limitations
and continue to increase the performance of processors,ma.ny chip manufactures are reearching and developing multi-kernel proc6so$t. An innorrative and interesting oca,mple of such an architecture is the Cell Broadband
Engne.
IBM,
Sony and Toshiba Corporation havejointly
developed an advancedmicropro-cessor, for noct-generation computing applications and
digital
confllmer electronics.The Cell Broadband Engine is optimized
for
computeintensive workloads andrich
media applications,
including
computer entertainment,movie
andother
formsof
digitat coutent.
One
important
feature and amajor
differencefrom
other new architecturesis
thefact
that
the Cell
Broadband Engine isa
heterogeneousr multi-kernel architecture. Essentially,this
meansthe
architecture is composed of several prooessor cores and thesecore
have different instruction sets. One visible and direct consequence isthat
the simple
recompilation
of any software progra,m isnot
euorrghto
take advantageof the procesor's capabilities.
At
a first
and quick
glance, onemight tend
to
believethat the
Cell
Broadband Engine isjust
a normal PowerPC
with
several co'proce§*sorÍt,but
Cell Broadband Engine is mueÀ more thanthat. Thee
"co-proc€ssors" a,re powerfirl and independentproc€Éisons each
requiring
a separate compiler, and have very specific features likeDMA
transfers and interprocessor mmsaging and control.Such new CPU architectures offer a significant performance potential
but
pose thechallenge
that
new progra,mming paradigms andtools
haveto
be developed and evaluatedto
unlock
the
powerof
suchan architecture.
Today softwarearchitec-tures
for the
oçloitation
of
heterogeneous multi-corearchitectrue
a,restill
a field of intensivereearch
andoçerimentatiou.
or
even hundredsof
hardwarethreads.
But
parallelizing prograrnsis
not
arr easytask.
Issues such as race conditions, data dependencies, cornmunication andinter-action
between threads,with
poor
debuggingsupport
are extremely error-prone. Prograrnmers tendto think
sequentially andnot in
parallel and oftenthis
wayof
thinking
is reinforced by major progarnming languages andtheir
paradigrns.More declarative languagm
like
functional and logic prograrnming languages have fewer and more tra,nsparent dependencies andaliasing.
Therefore such languages are much easier to extract pa,rallelismfrom.
The main problemwith
such languagesis their
lackof
generalizedadoption.
They
aremostly
usedin
academiaor
very specialized groups.Constraint Prograrnming is a useful declarative methodolory which has been applied
in
several ways:1. As an
extensionto
existing programming languages, such as Prolog, takingadvantage of the complementa.rity provided by the two approaches (backtrack-ing vs. propagation). This is the case for most Constraint Logic Prograrnming
(CLP)
implementations.2.
As alibrary
in which corstraints become data structures of the host language, which are operated on by thelibrary
procedures. This is the case, for insta,nce, forILOG
Solver [32] andGECODE
[7].3.
As a
special-purpose language, appropriatefor
solving problems formulated as constraints overvariables. This is the
casewith,
a,rnong others,Oz
134],OPL
[31]or
Comet [25].The declarative nature of constraint satisfaction problems (CSP) strongly suggests
that
onetries
to
parallelizethe
computational methods usedto
performthe
tasksrelated
to
solving CSPs, na.rnelypropagation.
Indeed,this
has beenexplicitly
in-corporated
into
most la.nguages mentionedin
point 3, which provide mechanisrnsto
In
this
th6is,
we chmeto
follon'approach uumber2: to
proüde
alibrary
for
con-straint
progra,mmingfor
an existing language. CASPER is inspiredby
the
scheme usedin
AJACS
[12]and
extendsit
to
includeboth
propagation andlocal
search techniques. CASPERrelie
on â puxely functional approachto
representing seareh-spâce statestore,
and is deigned to ensurethat
parallelization is viable by avoidiugsharing as
muú
as possible,to
achiwe the highestdegre
of independenee between sea,rch-space statestore.
Outline
This
thesisis
organized asfollows:
a,fterthis
Introduction
úapter, Chapter
2provides a background on
the
various topics and notations usedin
the
subsequent chapters: different Parallel Computers a,rchitecturesin
general arepreented
as wellas models and
areÀitecture
of parallel progra,mming. Finally, ConstraintProgra,m-rning
is
introducedand
all
associated notationswhiú
concernto this thesis. In
chapter
3, the AJACS model is presented alongwith
its
main ssasepts and parallela,rchitecture. The following chapter,
chapter
4,preents
theCell/B.E.
processorin
general and details
its
internal architecture.In Chapter
5, we present and describein
detailthe
fra,mework which we developedin
the
course ofthe
preeut
work
andin
úapter
6,
some tests andtheir
results arepreented
and discussed.Fiuatly
in chapter
7
some conclusions are drawn andfuture
directionsfor the
work
are suggested.Chapter
2
Background
Parallel computing
is a
mainstayof
modern computation andinformation
analy-sis
and
management, rangingfrom
scientific computingto
information
and dataservices. The
ineütable
andrapidly
growing adoptionof
multi-core parallelarchi-tectures
within a
procmsorchip
by ull of the
computerindustry
pushes explicit parallelismto
the forefront of computing forall
applications and scales, and makesthe
challenge of parallel prograrnming and system understandingall
the morecru-cial.
The
challengeof
programming parallel systerns has been highlighted as oneof the
greatest challengesfor the
computerindustry by
leaders of even the la.rgest desktop compa,nies.Heterogeneous chip multiprocessors present unique opportunities for improving
sys-tem throughput,
reducing processor power. On-chip heterogeneity allowsthe
pro
cessor to better match execution resourcm to each application's needs a,nd to address a much wider spectrum of system loads
-
from lowto
high thread parallelism-
with
2.L
Architectures
Parallel Computer
Memory
Architectures
One way to cla,ssify multiprocessor computers is based on their memory architectures
or how processor(s) interact(s)
with
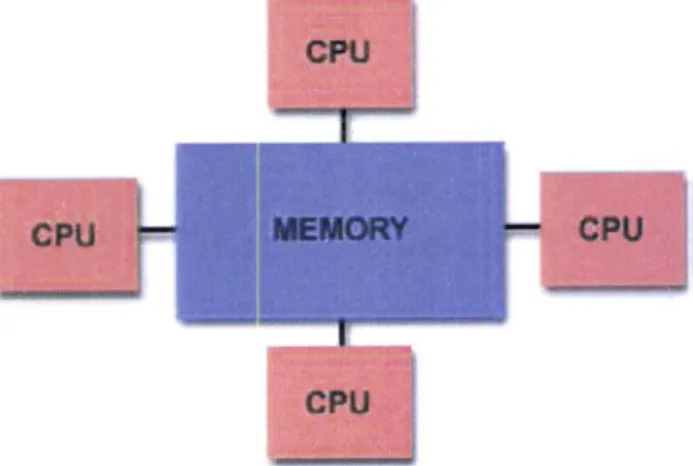
memory.Shared
Memory
In
shared memory computers(figure
2.t.L),
the same memory is accessibleto
mul-tiple
processorsin
a global address spâce.All
processors can work independentlybut
since memory is sharedits
access must be synchronized by the programmer. When one task accesses one memory resource,this
resource cannot be changedby
someother
task.
Every changein
a
memorylocation is therefore visible
to
all
other processors.Shared memory machines can be
diüded into
two main classes based upon memory accesstimes:
Uniform Memory
Access(UMA)and Non-Uniform
Memory Access(NUMA).
In
NUMA the
memory accesstimes
dependson the
memory location relativeto
a processor wherein UMA
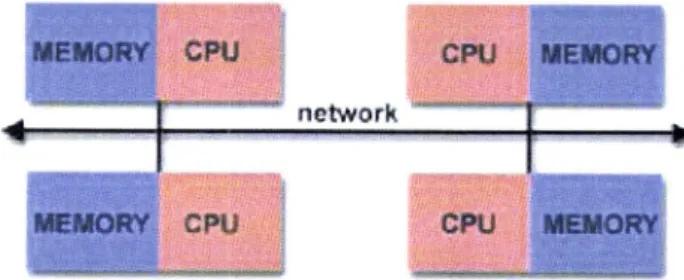
the access times are equal.Distributed
Memory
Distributed
memory systems(figure
2.L.2) requirea
communication networkto
connect
the
processors andtheir
memory.Processors have
their
own localmemory.
Memory addressesin
one processor donot
mapto
another processor, so there is no concept of global address space âcrossall
processors. Because each processor hasits
own local memory,it
operatesin-dependently
in
the sensethat
changes madeto its
local memory have no effect onthe memory of other processors. When a processor needs
to
access datain
another ptocessor's memory,it
is
usuallythe task
of
the
programmerto explicitly
definehow and when
data
is communicated. Synchronization between tasksis
again the programmer's responsibility.nstsork
Figure 2.1.2: Distributed memory architecture
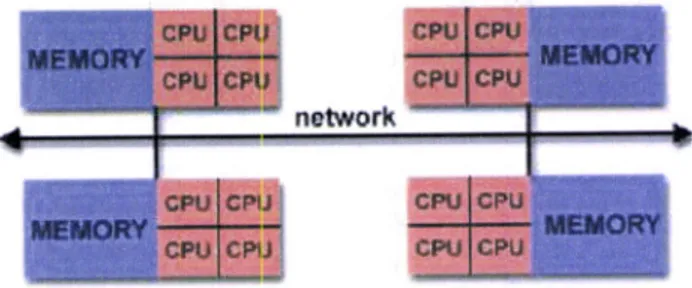
Hybrid
Distributed-Shared Memory
It
is possible to combine the previous architectures in a hybrid model, asfigure
2.1.3illustrates.
In
fact,that's
what modern large computers do.The
processorsin
a
Symmetric MultiProcessing(SMP) can
accessthe
system'smemory
globally
like
in
shared memory computersand
use networkingto
movedata across
the
severaldistributed
SMP machines aswith
thedistributed
memory systems.ÍrgtsoÍk
Figure 2.1..3: Hybrid memory architecture
2.2
Parallel Programming
Ttaditional Von
Neumann computing platforms containa
single processor, which computes a single threadof
controlat
eachinstant.
High-performance computing platforms contain many processors,with
potentially
many threads ofcontrol.
Par-allel programming has become the default
in
many fields where immense amountsof
data
needsto
be processed asquickly
as possible:oil
exploration, automobilemanufacturing, pharmaceutical clevelopment
and
in
animation and special effectsstudios. Such different tasks and
the
algorithms associatedwith
them present dif-ferent stylesof
parallel programming. Some tasks are data-centric and algorithmsfor
working onthem
fit
into the SIMD
(SingleInstruction, Multiple Data)
morlel. Others consist ofdistinct
chunks of distributed programming, and these algorithms rely on good communication models among subtasks.Challenges
The key
to
parallel programming is to locate exploitable concurrencyin
atask.
Thebasic steps for parallelizing any program are:
o
Locate concurrency,o
Structure the algorithm(s)to
exploit concurrency.The major challenges are:
o
Data dependencies.o
Overheadin
synchronizing concurrent memory accessesor
transferring databetween different processor elements and memory
might
exceed anyperfor-mance improvement.
o
Partitioning work is often not obvious and can resultin
unequal units of worko
What
worksin
one environment might not workin
another, dueto
differencesin
bandwidth, topology, hardware synchronization primitives and so on.Parallel Programming
Models
A
parallel programming modelis an
abstractionto
express parallel algorithms in parallel architectures. One goal of a programming model isto
improve theproduc-tivity
of the programmer.It
includes areas of applications, programming languages, compilers, libraries, communications systems, and parallelIlO.
It
isup
to
the
de-velopersto
choose the model which best suitstheir
needs.Parallel models are implemented
in
several ways: as libraries invokedfrom
tradi-tional
sequential languages, as language extensions,or
completely new execution models.Shared
Memory Model
In
the
shared-memory programming model tasks sharea
common address spacewhich
they
read andwrite
asynchronously.An
advantageof
this
modelfrom
the programmer's point of view isthat
the notion of data coownership is lacking, thus there is no needto
specifyexplicitly
the communication of data between tasks.Still,
this model needs mechanisms to synchronize access to the shared memory (e.g. locks, semaphores).Advantages
e
Conceptually easyto
understand and hence design progra'ms fs1o
Easyto
identify
opportunities forparallelim
Disadrrantageo
o
Lack ofportability
as this model is often implementedin
an architecturespe-cific progra,rnming language
o
Maynot
besútable
for loosely coupleddistributd
processors dueto
the highcommunication cost
One implementation of
this
model isDistributed
Shared Memory (DSM).In
DSM,the
commonaddres
space canpoint to
memoryof
other machine. DSM
can be implementedin
hardwareor in
software.In
software, a DSM system can beimple-mented
in
the operating systemor
as a progralnming library.§ffuerrgh DSM
give
uÉ,ers a view suchthat
all prooessors are sharing a unique pieceof memory
in
realityeaú
processor can only acces the memoryit
ourns. Thereforethe DSM mgst be able to bring in the contents of the memory from other processors
wheu
required.
This
gives riseto
multiple
copie
of the
sa,me shared memoryin
different physical
memories. The DSM
hasto
maintsin
the
consistencyof thee
difierent copies, so
that
any processor accessingthe
shared memory shouldreturn
the correct
r6ult.
A
memory consistency model is respousible for the job.Intuitivety, the
readof a
shared variableby
any prooessor shouldreturn the
most recentwrite,
nomatter
if
this write is
performedby
anyprocesor.
The
simplet
solution is to propagate the update of the shared variable
to
all the other procmsorsas soon as
the
update
is made. This is
known
as sequential consistency (SC). However,this
can generate an excessive a.rnount of network tra,frc since the content of the update may uot be needed by every other proce*sor. Thenefore ceúain rela>cedmemory consistency models were developed. Most of them provide synchronization
facilitim
such as locks and barriers, sothat
the shared memory Írccess can be guardedto
eliminate raceconditions.
The
most popular memory consistency models are: sequential consistency (SC), eager release(ERC),
lazy release(LRC),
entry
(EC)and scope (ScC).
Threads
Model
The threads model spins around the concept of a thread.
A
progrr.-
can besplit
upin
several threadsthat
run
simultaneously.In
a uniprocmsor systemthis
"simulta,neously''
meil§
"almost simultaneously'' because the processor can switch betweenthreads so
fast
that
it
givesthe illusion of
executing morethan
onething at
thesame
time. In
modern multiprocessor and multicore a,rchitecture, threads a,re 16rally
executedat
the sa.metime,
in
different units.The threads model is usually associated to a sha,red memory architecture and could
be included
in
the
shared memory prograrnmingmodel.
But
sincethe
conceptof
thread is so widely and independently used
that
it
deserves a place ofits
own.Adnantages
o
The overhead associatedwith
creating a thread is much less than ç1sa,fing an entire processo
Switching between threads requires much less work by the operating systemo
Many progralnmers a,re familiarwith writing
multi-threaded prograrns because threads are abasic construct in marry modern prograrnming languagm like JavaDisadrmntages
r
\trriting
a multi-threadedprogro.*
can be much thougherthan for
otherpre
ga.mming modelse
Synchronization mechanism^s are required to control âccess to shared variablmTwo implementations of
this
model a,re POSD(threads
[5]*d
openMP(tzl
t10l ).Mmsage
Passing
Model
Message passing is probably the most widely used parallel progre.mrning model
te
day. Mmsage-passing progrq.ms create multiple tasks,
with
each task encapsulatinglocal
data.
Each task is identifiedby
a unique nerme, and tasks interact by sending and receiving meslagesto
and from na,med tasks.The
mesage-pa.ssing model doesnot
precludethe
dyna,rnic creationof
tasks, the execution of multiple tasks per procersor, or the execution of different progra,rns by differenttasks.
Hourever,in
practice mostmesagepasing
systems create a fixednumber of identical tasks at progrâ.m startup and do not allow tasks to be created or
destroyed during program executiou.
Thee ffiem,s
are saidto
implement 6 §inglsProgra,m
Multiple
Data (SPMD)
progra,mming model because eachtask executc
the same prograur
but
operatm on different data.Adwntages
r
This model is applicable to bothtightly
coupled computers and geographicallydistributed systems
o
Message passiDg übrariesproüde
a
setof functionality
and lerrclof
eontrolthat
isnot
foundin
any of the other modelsr
All
other parallel programming models can be implemented bD'the mesa,ge pa*sing modelDisadnantages
o
All
of
the
responsibilityfor
an
effective parallelism schemeis
placedon
theprogrammer. The progralnmer must
explicitly
implement a datadistribution
scheme and
all
interprocess communication and synchronization, whileavoid-ing deadlock and race conditions
o
Some parallel progrernmers preferto
havethis
level of control hovreverit
can bedifficult for
noúce programmersto
implement effective parallel prograrnsTwo widely used implementations are
MPI
[16] andPVM
tgl.MPI
is
a
messiage passinglibrary
specification.
MPI
is the only
message passinglibrary
which can be considered astandard.
It
is
supported onvirtually all
HPCplatforrns.
Practically,it
has replacedall
previous message passinglibraries.
Thegoal of
MPI
isto
provide a widely used sta,ndardfor writing
message passing pro-gralns. InMPI,
all parallelism isexplicit:
the prograrnmer is responsible for correctly identifying parallelism and implementing parallel algorithrns usingMPI
constructs. The number of tasks dedicated to run a parallel program isstatic.
New tasks can notbe dynamically spawned during run time although the MPI-2 specification addresses
this
issue.Data Parallel Model
Another commonly used parallel prograrnming model, the data parallel model, calls
for
exploitation of the
concurrencythat
derivesfrom the
applicationof
the
sa,me operationto
multiple
elementsof
a data structure, for
exarnple, *add2
to all
el-ementsof this
axray,or
increasethe
salaryof all
employeeswith
5
years service.A
data-parallel progra,rn consistsof
a sequenceof
such operations. As each operartion
on eachdata
element can bethought of
as an independent task,the
natural granularity of a data-parallel computation is small, and the concept oflocality
doesto
provideinformation about
howdata
areto
be distributed
over processors,in
other
words,how data
areto
be partitioned
into tasks.
The
compiler can then translate the data-parallel progrâ.minto
an SPMD forrnulation, thereby generating cornmunication code automatically..Àdvantages
r
Gives the userthe ability to
process largevolume
of data very fasto
Only one piece of code needs to be produced to implement all of the parallelismDisadwntages
o
Dueto
the large volumes of data involvedin
atypical
data parallelcomputa-tion, this
model maynot
be suitable for geographically distributed processorso
Requirm high bandwidth communicationsto
transfer and share dataHybrid
Model
In
this
model, anytwo or
more parallel programming models are combined.Cur-rently
a
common exa,mpleof a
hybrid
modelis
the
combinatiouof the
message passing model(MPD
with
either the threads model (POSD( threads) or the shared memory model (OpeuMP).Another
conmon
exa,mple of ahybúd
model is combiuing data parallelwith
mm-sage passing.
Data
parallel implementations ondistúbuted
memory architecturesactually use message passing
to
transmit
data between tasks, transpa,rentlyto
theprogrammer.
The
adrantage
and disadvantages come from the combination of the models being used.2.3
Designing
Parallel
Programs
One possible goal
for
parallel prograrnmingis
performanceimprovement.
In
this
perspective, the design of parallel prograrns demands an
extra
effort from thepro
gralnmer. Several factors must be considered in order to decrease the execution wall
clock time.
It
is necessaryto
understand the problemthat
one wantsto
parallelize. One shouldidentify the
progra,rn's hotspots, bottlenecksand
inhibitors.
Hotspots are wheremost
work is
done and can be identifiedby
usingproflling
tools.
Bottlenecks are areas which slow downthe
progra.m's execution asfor
exampleI/O
such as diskaccess. They should be minimized by restructuring
the
codeor
eventuing
anotheralgorithm.
Inhibitors
arepoúions of
codethat
restrain parallelism sincethey
a,renot
independent.A
good exarnple of aninhibitor
is a data dependency.Partitioning
is
oneof
the
first
stepsto
bemade.
It
representsthe
way how wedivide
the
work being donethat
can bedistributed
to
multiple
tasks. There are 2ways
to
dothis.
Functionalpartitioning
focuses onthe
computation(or
controlof
the
program)*rd
each pa,rallel task performsa
part
of the
overalltask.
Domainpartitioning
focuseson the data
associatedto
the
problem andthe
parallel tasks works on a differentportion
of the data.As there are several tasks running
in
parallel, they might need to cornmunicatewith
each other by sha,ring or exchanging
data.
This need for communication depends onthe task being performed since some tasks
run
very independently and some don't.Very
independent tasksdon't
needto
sharedata
-
emba,rrasingly parallel-
whiledependent tasks are
not
that
simple and therefore cornmunication factors must beincluded. When dmiguing a parallel application, one must pay attention
to
factorssuch as cost
of
communication,bandwidth/latency
in
synchronous/asynchronoust cornmunication and the scope of the communication.Another factor is synchronüation. Synchronization is needed when two or more tasks need access to a shared rmource and this is very
important
becauseit
influences thecorrectness of the computed
result.
There are different ways to synchronize accessegsuch as using locks
or
by communicationbetwen
tasks.Dependencies o<ist between progrâ,m statements when the order of statemelrt
er(e-cution afiects
the
reults
of the program.A
data dependency resultsfrom multiple
use
of the
sarne location(s)in
storage. Data dependencie a,re oneof the púmary
inhibitors
to
parallelism.To obtain a
mar<imum performance,all
parallel tasks should be busyall
the
timethus a correct
distribution
of the work is required.A
scheduler is a possibilityif
onedesire
a dyna,mic assigument of jobs.Granularity
is,
in
parallel
computing,the ratio of
computation overcommunica-tions.
With
fine-graiu parallelism, the a,mount of computational work done between communicationsis relatively
small.
In
coarse-grain parallelism,the
ratio
is
high,with
large arnotrntsof
computationalwork
between communications/spchroniza'tion
errents.Both
types of granularity havetheir
advantage and drawbacks. Thechoice
for the
levelof
granularity depends onthe algorithm, the
data set and thehardware environment.
A
proper ermluation oflimits
and costs should be performed.Amdúl's
Lawstate
that
potential
progra,m speedup is definedby the fraction
of code(P) that
can be parallelized:sPeed,uP:
+
(2'3'1)r-P
When introducing the number of procmsors (N):
speed,up:
o-l
Q3.2)
F+s
where
p
-
parallel fraction,N
:
number of procesors and S:
serial fraction.This
lawgive
an idea of how much gain one getswith
the parallelization although other issues should be takeninto
accountto
evaluatethe
costs and complo<ityof
2.4
Parallelism and Programming
Languages
There are 2 two major approaches to parallel prograrnming:
implicit
pa,rallelism andexplicit
parallelism.fu implicit
parallelism,the
compileror
some other prograrn is responsible for the parallelization of the computationaltask. In
explicit parallelism, the prograrnmer is responsible for the taskpartitioning
through language constructsor
extensions (we already referredMPI
as anexplicit
parallelism specification).It
has long been recognizedthat
declarative progra.rnming languages, including logica.nd functional progra.mming languagm, are potentially better
súted
to parallelpro
grarnming.The
keyfactor is a
clear separationof '\rhat"
the
progra,rn computesfrom the details
of
"hou/'
the computation should take place.Imperative programming languages rely on state and
time.
The state changes overtime
as variables are assigned valum and time must be considered when lookingat
an imperative program. On
the
other hand, declarative languages are independentof
time.
While
imperative
progm.ms consistof a
set
of
statements executedin
order, declarative progrâ.ms
don't
care about the orderor
even how marrytime
anexpresion is evaluated.
The
most
colnmonway
of
achieüng
a
speedupin
parallel
hardwa,reis
to
write
progrâ.ms
that
useexplicit
threads of controlin
imperative programming languages in spite of the factthat writing
and reasoning about threaded progrâ.ms is notoriouslydifficult. A lot
of work has beenput in
imperative languages (like Java,C++
andCff)
to
take advantage of concurrency.It
is worthwhileto
note aboutuncurrent
al;ld parallel programmingthat,
althoughboth
warrtto
exploit
concurrencythat
is,
executionof
computationsthat
overlap overtime,
it
can safely be arguedthat
they
arenot
synonymous.In
either case,both
tendto
usethe
sa,rne models (see above) andimply
communication between tasks.computations. Parallelism is an implementation concept
that
oçresse
actiütim
that
happen simultaneously.In
a computer, parallelism is usedonly
to
increaseperformance.
t35lConcur:ency and parallelism a,re orthogonal concepts.
There are three main models of concurrency in progra,mmiug languagm
(from
[S5]): declarative eoncrurency, message passing concrureney and shared state concurrency.Declarative concurrency
isthe
easiestparadip
of concurrent progra,rnming.It
keeps prograrns simple andwithout
race conditions or deadlocks.It
relies on declarative operations.A
declarative operation is indepeudent (does notdepend on any execution state outside of
itself),
statelms (has no internal ercecutionstate
that
is remembered between cells), and deterministic (alwaysgive
the sa,meresults when given the sarne argumeuts). o The
drawback of
this
pamdigm isthat
it
doesn't allow programs
with
nondeterrninism.Only
more academic languagm likeOz
[33]*d
Alice
[24]usethis
Message passing is
a
modelin
which
threads shareno
state and communicatewith
eachother
via
asynchronous messaging.It
extends declarative concrurencyintroducing communication channels to remove the
limitation with
non-determinisn.This
is the model employed bythe
Erlang language.The
Shared state
consists of a set of threads accesing a set of shared passiveob
jects.
The threads coordinate among each other when accesing the shared objects.They
dothis
by
mea,rxrof
coars+greined atomic actions, e.9., locks, monitors, ortransactions.
The concurrency is more ocpressive and gives more control
to
the progra,mmerbut
reasoning
with
this
model is more complex. Shared state concurrency is the model employed by the Java language.2.5
Constraint Programming
Introduction
"Constra'int Programmi,ng represents one of the closest approaches
c,om-puter
sc'ience has yet mad,eto
theHoly
Grai,l of programming: the userstates the problem, the computer solues iá.
"
-
Eugene C. Fleuder,Con-straints
Journal, 1997The idea of constraint-based progra,rnming is to solve problems by stating constraints
(properties, conditions) which must be satisfied
by
the solution(s) ofthe
problem. Considerthe
following problem a.s an exarnple: a bicycle numberlock.
You forgot thefirst digit
but
you remember a few constraints aboutit:
it
is an odd number,it
is
not a
prime number and greaterthan
1. With
this
information, you are ableto
derive
that
thedigit
is the number 9.Constraints can be considered pieces of partial information. They describe properties of unknourn objects a,nd relations arnong
them.
Objects can mean people, numbers, functions from time to reals, prograrns, situations. Relationship can be any assertionthat
can betrue
for some sequences of objects and false for others.Historical
Remarks
Constraint programming has been used
in Artificial
Intelligence Research since the1960's. The
first
system known to use constraints was Sketchpad, a programwritten
by Iva.n Sutherland,
the
"father"of computer graphics,that
allowed the user to draw and manipulate constrained geometric figures on the computer's display.In the 70s, Logic Progra.mming was
born.
Most of the development and achievementsin
the field of constraint progra,rnming was done by Logic Programming researchersof
the
reasons whythe
extension of logic languages such as Prologto
includecon-straints has been so formally clean, convenieut and
natural. In
fact,the
main step towards modern constraint progra,mming was achieved whenit
was notedthat
logicprosrqmming
(with
u-uification over terms) wasjust
aparticular kind
of constraint programming.It
has ledto
thedefinition
of a general fra,mework called constraintlogic progre.mming
(CLP
I21]).It
is easyto
getconfusd
and see Constraint Progra,mming as somethingstriatly
re
lated to Logic Progra,mming when in fact constraint theory is completely orthogonal
to
the progre.mming pa,radi$n.In
the late 80's, onepoweúrl
obserrnation has beenthat
constraints can also be usedto
model communication and synchronization a,mong concurrent agents,in
such a waythat
these tasks a,re now describedin
a
more general and clean way, and canbe achieved
with
greater efficiency andflexibility.
Suú
observatiouis the
basisof
the concurrent constraint progrq.mming fra,mework
(CC
tll
).Already
sincethe
begiruúngof the
90's, constraint-based progra,rnming has been comme.rcially successfirl. One lesson learnedfrom
applicationsis
that
constraintsare
often
heterogeneous andapplication
specific.
In
the
beginningof
constraintprogra,rnming, constraint solving
was
"hard-wfued"in
a built-in
constraint solverwritten
in
a
low-levellanguage.
To
allourmore
flexibility
and
customizationof
constraint solvers, Constraint Handling Rules
(CHR)
was proposed.CHR
[14] isesentially
a concurrent committed-choice language consistiug of multi-headed nrlesthat
transform constraintsinto
simpler oumuntil
they are solved.The a,rchitecture of constraint progra,mming is âlso suited for embedding constraints
in
more couventional languages.This characterize
corwtrai,nt imperutiaeprcgam-naing.
In
constraint imperative progra,rnming,the
user can use constraintswhich
relate progra,m's na,riables and objects.Beides
using the language's conventional featuresthe user can define his own constraints, augmenting the solver's capabilities.
Imperative languages can also be extended
with
language elements from logic pro-grarnming, such as non-deterministic computationswith
logical variables andback-tracking.
Constraints
systems
A
constraint systemis a
formal
specificationof
the
synta>< and semanticsof
theconstraints.
It
definesthe
constraints symbolsand which
formulae are usedfor
reasoning
in
the context of programrning languages.Finite
Domain
constraints havea finite
set asits
domain. This
domain can be integersbut
also enumerable types like colors or resources which should be plannedfor
a process.Many real-life combinatorial problems ca,n be modeled
with
this
constraint system.Finite
domain constraints are very well suitedto
puzzlm, scheduling and planning.For example: an university's timetabling system.
Boolean
constraints area
special case offinite
domain constraints wherethe
do
main contains only
two
valum,true
and false. One areaof
application of Booleanconstraints
is
modelingdigital
circuits.
They
canbe
appliedto
the
generation, specialization, simulation and analysis (verification and testing) of the circuits.There are often casm when, instead
of
imposing a constraint C, we wantto
speak(and possibly constrain)
its truth
value.
For exarnple, logical connectives such asdisjunction, implication, and negation constrain the
validity
of other constraints.A
reified, constraint is
a
constraint C which reflectsits validity in
a boolea"n variable B:ceB:LABe{0,1}
A
R^ationalTIee
is a tree which has a finite set of subtrees. Ttee constraints can be used for modeling data structures, such as lists, records a,nd trees, and for expresingalgorithms
on
thesedata
structures.
Oneof the
applicationsfor this
constraintsystem is progra,rn analysis where one
repreents
and rearnns aboutpropertie
of a program.Constraints can also have
Linear Polynomial Equations
domains. Here, Linear arithmetic constraints a,re linear equations and inequalities. This type of coustraintsis important for
graphical appücations like computer aideddeigu
(CAD)
systems or graphical userinterface, but
also for optimization problems as in linear program-ming.The
Non-linear Equations
constraint system is an erdension of the one for linear polynomials. Problemsfor
solvingthis type of
constraints arisewith
the
inclusionof, for
example,multiplicatiou or
trigonometricfunctions.
Despitethe fact of
not havinga
triüal
solver, non-linea,r constraints appea,rin
the
modeling, simulation and analysisof
chemical, physical procmses and systems.An
application area isfinancial anal3rsis or
robot
motion planning.Constraint
Solving
Algorithrns
An
impoúant
component isthe
constraint
solver.
A constraint
solver
imple,ments an algorithm for solving allowed constraints
in
accordancewith
the constrainttheory.
The
solver collectsthe
constraintsthat
arrive
incre,mentallyfrom
one ormore mnning progre.ms.
It
puts theminto
the constraint store, a data structure forrepresenting constraints and rmriables.
It
teststheir
satisfiability, simplifies andif
possible solves
them.
The final constraintthat
results from a computation is calledthe answer
or
solution.There are
two
main
approachefor
constraint solvingalgorithms:
variableelimi-uation
andlocal
corsistency (local propagation)techniqum.
Variable eliminationachieves
satisfiability
completenesswhile
local-consistency techniqum haveto
be interleavedwith
searchto
achieve completeness.nari-ables. Typically the allowed constraints are equations which are computed to obtain
a normal
form
(orsolution). An
exarnple of a variable elimination algorithm is theGaussian method for solving linear polynomial equations.
Local
consistency(local
propagation) basically adds new constraintsin
order to
cause simplification: new
subproble-s
of theinitial
problem are simplified and newimplied constraints a,re computed (propagated).
Local consistency problerns must be combined
with
searchto
achieve completenms. Usually, search is interleavedwith
constraint solving: a search step is made, adds a new constraintthat
is simplified togetherwith
the existing constraints. This process is repeateduntil
a solution is found.Search can be done by
tryrng
possible valuesfor
a variableX.
These search proce-dures are called labeling. Ofben, a labeling procedurewill
use heuristicsto
choosethe next variable and value
for labeling.
The chosen sequence of va,riables is called variable ordering.Constraint
Satisfaction
Problem
(CSP)
Constraint Satisfaction arose
from
researchin
theArtificial
Intelligence(AI)
field.A
considerable a,rnount of work has been focused onthis
pa"radigmcontributing to
significant results
in
constraint-based reasoning.A
Constraint Satisfaction Problem (CSP) consists of:o
a set of variablesX
:
{ru...,frn},
o
for each variablefri,
à, se,tDi
of possible rmlues(its
domain),o
and a set of constraints restricting the valuesthat
the
va,riables cansimulta-neously take.
A
solutionto
a CSP is an assignment of a value fromits
domainto
every va,riable,.
just
one solution,with
no preference asto
which one.r
all
solutions.e
an optimal, orat
least a good solution, given some objective function definedin
terms of someor all
of thewriablm.
A
CSP is a combinatorial problem which can be solved by search.This
differs fromConstraint
Solving.
Constraint
solving uses \rariableswith
inffnite
domains and reües on algebraic and numeric methods.Seareh
Algorithrns
A
CSP can be solved by tryrng each possible rnlue assignment and see ifit
satisfie
all the constraints. Then there's backtracking, a, more efficient approach. Backtrad<ingincrementally attempts
to
extend apartial
solution toward a complete solution, by repeatedly choming a valuefor
another variable and keepingthe
previous stateof
wriables
sothat
it
can be restored, should failure occur.The
problemwith
such techniqumis the
late
detectionof
inconsisteney. Hence rmriousconsistency techniques
were introducedto
prune
the
search space, bytrying
to detect inconsistency as soon as possible. Consistency teúniques range fromsimple node-consistency a,nd the very popular arc-consistency
to full, but
o<pensivepath
consistency [30].One ean combine systematic search algorithms
with
consistencytechniqum.
The result a,re more efficient constraint satisfaction algorithrns. Backtracking can beim-proved by looking at two phases of the algorithm: moving forward (forward
úecking
and
look-úead
scheme) and backtracking (look-back schemm) [3].Also very
important
isthe
orderin
which variables are considered. The efficiencyof
search algorithmslike
backtrackingthat
attemptsto
extenda
partial
solutionthe algorithm
performance. Various heuristicsfor
ordering of values and variables exist.Another approach
to
guide search is using heuristics and stochastic algorithrns also known as Local Search.The term
heuristicis
usedfor
algorithms whichfind
solutions arnongall
possible ones,but they
donot
guaranteethat
the
bestwill
be found,thereforethey
may be considered as approximately andnot
accurate algorithrns.These algorithrns,usuallyfind a solution close to the best one and they do so fast and easily. Sometimes these
algorithms can be accurate,
that
isthey
actuallyfind
the best solution.To avoid getting stuck
at
"localrnaxima/minimal' they
are equippedwith
variousheuristics
for
randomizingthe search.
Their
stochasticnature
cannot guarantee completeness like the systematic search methods.Some examples of this
kind
of algorithrns are the classicsHi[-Climbing
and Greedyalgorithms
[36] as well as Tabu-Search [17],Min-Conflict
[37]or
GSAT.Constraints
and
Programming
Languages
Constraint Logic Programming
Constraint Logic Programming
(CLP
[22])i"
a combination of logic prograrnmingand
constraint prograrnming.
The
addition
of
constraints makes prograrns more declarative, flexible andin
general, more efficient.In
the
endof
the
70's, efforts have been madeto
make logic programming moredeclarative, faster and more
general.
It
wasat this
point,
that
it
was recognizedthat
constraints could be usedin
logic programmingto
accomplish the objectivesof
declarativeness, speed a,nd generality.
By
embedding a constraint solverto
handleconstraints new possibilities open
up.
For exarnple, constraints can be generated (and checked) incrementally, thus catching inconsistency early in the solving processIn
CLR a
store
of
constraintsis
maintainedand kept
consistentsat
everycom-putation
step.
Each clause ofthe CLP
progra,m matching oneof the
goalsin
the store getsits
constraints and goals accumulatedin
the
store.
However,the
newconstraints can only be added
if
they
are compatiblewith
those already presentin
the store.
This
meansthat
the satisfiability of the whole new set of constraints hasto
be maintained.CLP
languages combine the advantages ofLP
languages (declarative,for arbitrary
predicates, non-deterministic)
with
those of constraint solvers (declarative, efficientfor
special predicates,dsfslministic).
Speciatly useful is the combination of searchwith
solving constraints which can be used to tackle combinatorial problems (usuallywith
e:çonential
compleDdty).Concument
Constraint
Programming
Concurrent
Constraint
Progra.mmingarise
from the
observationthat
constra,ints can be used to model concurrency and commtrnication between coucurrent processen (agents).It
is a generelization ofCLP
with
added concurrency [11].This
newpaxadip
leadsto
many coruequence§. Oneof the
most
important
isthat the
entailment operationis
noq, present(wasn't
in
CLP)
soany
constraintcan be checked for satisfiability or
for
entailrnent.A
constraint is entailed whenits
information is already present
in
the coustraint, entailing the former.The computation state
is a
collectionof
constraints, and eachof the
concurrent agents may either add a new constraintto
the state (likein
CLP)
or check whether a constraint is entailed by the crurent state. Such a test may succeed orfail, but
theass
fhing
isthat
it
can also suspend, andthis
happens when the new constraint i§not entailed by the store
but
is consistentwith
it.
If
a,fter another agent adds enoughinformation
to
the
storeto
makeit
entail
or
be
inconsistentwith the
consideredconstraint,
then the
suspended actionwill
be resumed and either zucceedor
fail.This add/check/suspend is based on a ask-and-tell mechanism. Tell mea,ns imposing
a
constraint asit
happenedin
CLP or
in
other words, adding a constraintto
the store. Ask means "asking" if a constraint already holds (this is done by,r,
entailmenttest).
One important difference between CLP and CC is don't-care non-determinism.Don't-care non-determinism (also referred as cornmitted choice) means
that
if
there are different clausesto
choose from,just
onearbitrary
clausewill
be taken and thealternatives
will
be disca.rded.This
means searchis
being eliminated leadingto
a gainin
efficiencybut
like always, a lossin
expressiveness and completeness.Constraint Handling
Rules
Constraint Handling Rules (CHR) is one of the many proposals made to allow more
flexibility
and customizationof
constraint solvers. Tnsteadof
abuilt-in
constraint solver whichis hard
to
modify, CHR
definessimplification
and propagation over user-definedconstraint*
[6].The CHR language has become a major specification and implementation language
for
constraint-based algorithmsand applications. Algorithms
areoften
specifled using inference rules, rewrite rules, sequents, proof rules, or logical axiomsthat
can be directlywritten in
CHR. Based onfirst
order predicate logic, the clean semanticsof CHR facilitates
non-trivial
program analysis and transformation.About
a dozen implementations of CHR existin
Prolog, Haskell, a,nd Java.CHR are essentially a committed-choice language consisting of guarded rules
with
multiple
headatoms.
CHR
define simplificationof,
and propagation over,multi-sets
of
relationsinterpreted
a"s conjunctionsof
constraint
atoms.
Simplificationrewrites constraints
to
simpler constraints while prmerving logical equivalence (e.g.X )
Y,Y
>
X
+
false).
Propagation adds new constraints which a,re logically redundantbut
maycausefurthersimplification
(e.g.
X
)Y,Y
> Z
+
X
>
Z).
Repeatedly applying
the
rules incrementally solves constraints(".S.
á
)
B,B
)
two featurm which are essential for
non-trivial
constraint handling.Imperative Constraint
Programming
The Constraint Imperative
Programmi.g (CIP)
fa,mily of languagesintegrate
cou-straints and imperative,object-oriented
.
In
addition to combining theusefll
featurm of both paradigms, the abiütyto
define constraints over user-defined domains is also possible.Embed.ling constraints
in
conventional progra,mming languagmis
usually done by extending a language's sSrnta:r, throrrgh alibrary
or by creating new languages. Somelanguage have been developed
to
provide constraints reasoning. For exa,mple,Oz
[34]
i"
a
high-order concurrent constraint progra,mming system.It
combines ideasfrom logic, functional and
conctu:rent progra,mming.Ftom logic
progratnmingit
inherits logicvariable
and logic data structuresto try to
proüde
problem solvingcapabütie
of logic progra,mming. Ozcom6 with
constraints for variables overfinite
sets(finite
domain variablm) .ILOG
CP
[32]is a
C**
library that embodie
Constraint Logic
Progra,mming(CLP)
coucepts such as logicatvariablc,
incremental constraint sati§faction andbacktracking.
It
combinesObject
Oriented Progra,mming(OOP)
with
CLP.
Themotiration
for
usiug OOP isthat
the definition
of new classeis
a powerfirl meâ.nfor
extendingsoftware.
Modularity
is
somethingthat
has beeu recognized as alimitation
in
Prolog.Application
Areas
Some example application areas of constraint
programming
[4],
[40]:o
Computer graphics(to
ocprms geometric coherencein
the case of scene anal-ysis, computer-aided design,...)o
Natural
language processing (construction of efficient parsers,speechrecogni-tion
with
sema,ntics,...)o
Databasesyster§ (to
ensureand/or
restore consistency of the data)o
Operations research problem,s(like
optimization problems:
scheduling,se-quencing, resource allocation, timetabling, job-shop, traveling salesman,...)
o
Molecular biology (search for patterns,DNA
sequencing)o
Business applications (option trading)o
Electrical
engineering(to
computelayouts,
to
locate faults, verification of
circuit
design...)o
Internet(constrained webquerie)
o
Numerical computation (computationwith
guaranteed precision for chemistryengineering, design,... )
Real applications developed