i
Application of neural networks to the detection of fraud
i
n workers’ compensation insurance
Inês Bruno de Oliveira
Application to a Portuguese insurer
i Title: Application of neural networks to the detection of fraud in wci
Subtitle: Application to a Portuguese insurer
Inês Bruno de Oliveira
MEGI
2
NOVA Information Management School
Instituto Superior de Estatística e Gestão de Informação
Universidade Nova de Lisboa
APPLICATION OF NEURAL NETWORKS TO THE DETECTION OF FRAUD
IN WORKERS
’
COMPENSATION INSURANCE
Application to a Portuguese insurer
by
Inês Oliveira
Project Work report presented as partial requirement for obtaining the Master’s degree in Statistics and Information Management, with a specialization in Risk Analysis and Management
Advisor: Prof. Rui Alexandre Henriques Gonçalves
3
ACKNOWLEDGEMENTS
This work was completed thanks to a special group of people. First, Professor Rui thank you for your guidance, patience, and optimism. Also for all those late e-mails, a very special thank you.
I must thank my parents, my brother and Bruno for all the understanding, motivation, and support which were impressive in the most challenging moments of this work.
4
ABSTRACT
Insurance relies on a complex trust-based relationship in which a policyholder pays in advance to be protected in the future. In Portugal, workers’ compensation insurance is mandatory which may restrict the course of action of both players. Insurers face significant losses, not only due to its core business, but also due to the swindles of claimants and policyholders. Insureds may not have in the market what they really want to acquire which may encourage fraudulent actions. Traditional fraud detection methods are no longer adequately protecting institutions in a world with increasingly sophisticated fraud techniques. This work focuses on creating an artificial neural network which will learn with insurance data and evolve continuously over time, anticipating fraudulent behaviours or actors, and contribute to institutions risk protection strategies.
KEYWORDS
5
INDEX
1.
Introduction ... 9
1.1.
Background and Theoretical Framework ... 9
1.2.
Study Relevance ... 10
1.3.
Problem Identification and Study Objectives ... 12
2.
Literature review ... 13
2.1.
Operational risk ... 13
2.2.
Fraud ... 15
2.3.
Fraud in Insurance business ... 17
2.4.
Fraud in workers’ compensation insurance
... 21
2.4.1.
Legal Context ... 22
2.5.
Analytical models and Data Mining ... 24
2.6.
Neural Networks ... 28
3.
Methodology ... 34
3.1.
Research Methodology ... 34
3.2.
Data Collection Process ... 35
3.2.1.
Meetings ... 36
3.2.2.
Extracting data ... 39
3.2.3.
Data Transformation ... 39
3.3.
Data Overview ... 40
3.4.
Assumptions ... 41
3.5.
Model ... 41
4.
Results and discussion ... 43
4.1.
Measures ... 51
5.
Conclusions ... 54
6.
Limitations and recommendations for future works ... 58
7.
Bibliography ... 60
8.
Annexes ... 65
6
Figure 1 - Biological Neuron ... 9
Figure 2 - Artificial Neuron ... 9
Figure 3 - Structure of risk management ... 13
Figure 4 - Fraud Triangle ... 15
Figure 5 - Overfitting ... 32
Figure 6 - Hinton Diagram ... 33
Figure 7 - Data treatment ... 35
Figure 8 Software Connections ... 36
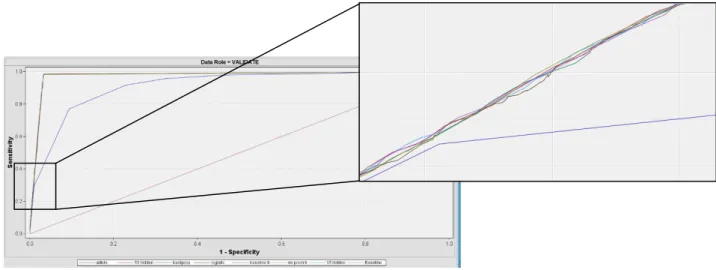
Figure 9 - ROC index for 15 and 50 hidden units ... 44
Figure 10 - ROC plot for the 4
thmodel ... 44
Figure 11 - ROC index for BackProp model ... 44
Figure 12 - ROC Index comparison between pilot and no preliminary training ... 45
Figure 13 - ROC curve for control 2 ... 47
Figure 14 - Article based ROC plot ... 48
Figure 15 - ROC plot for control 3 ... 49
Figure 16 - Known activation functions ... 50
Figure 17 - Example of a distribution of a variable ... 65
Figure 18 - Correlation between two variables... 66
Figure 19 - Fraud classification ... 67
Figure 20 - Misclassification Rate ... 68
Figure 21 - Cumulative Lift ... 68
Figure 22 - Cumulative % Response ... 68
Figure 23 - Cumulative Lift ... 69
Figure 24
–
Cumulative % Response ... 69
Figure 25 - Misclassification Rate ... 69
Figure 26 - Cumulative Lift ... 70
Figure 27 - Cumulative % Response ... 70
Figure 28 - Misclassification Rate ... 70
Figure 29 - Misclassification Rate ... 71
Figure 30 - Cumulative % Response ... 71
Figure 31 - Cumulative Lift ... 71
Figure 32 - Misclassification Rate ... 72
Figure 33 - Cumulative Lift ... 72
Figure 34 - Cumulative % Response ... 72
Figure 35 - Misclassification Rate ... 73
7
Figure 37 - Cumulated Lift ... 73
Figure 38 - Cumulative Lift ... 74
Figure 39 - Cumulative % Response ... 74
Figure 40 - ROC plot ... 74
Figure 41 - Cumulative Lift ... 75
Figure 42 Cumulative % Response ... 75
Figure 43 - Cumulative Lift ... 76
Figure 44 - Misclassification Rate ... 76
Figure 45 - Cumulative % Response ... 76
Figure 46 - Cumulative Lift ... 77
Figure 47 - Cumulative % Response ... 77
Figure 48 - Cumulated lift ... 78
Figure 49 - Misclassification Rate ... 78
Figure 50 - Cumulative % Response ... 78
Figure 51 - Cumulative Lift ... 79
Figure 52
–
Cumulative % Response ... 79
Figure 53 - Misclassification Rate ... 80
Figure 54
–
Cumulative % Response ... 80
Figure 55 - Cumulative Lift ... 80
Figure 56 - ROC plot ... 81
Figure 57 - Cumulative Lift ... 81
Figure 58 - Cumulative % Response ... 81
Figure 59 - Cumulative Lift ... 82
Figure 60 - Cumulative % Response ... 82
Figure 61 - Misclassification rate... 83
Figure 62
–
Cumulative % Response ... 83
Figure 63 - Cumulative Lift ... 83
Figure 64 - Cumulative Lift ... 84
Figure 65 - ROC chart ... 84
Figure 66 - Cumulative % Response ... 84
Figure 67 - Cumulative Lift ... 85
Figure 68
–
Cumulative % Response ... 85
Figure 69 - Misclassification rate... 85
Figure 70 - Cumulative Lift ... 86
Figure 71
–
Cumulative % Response ... 86
8
LIST OF ABBREVIATIONS AND ACRONYMS
RMSE Root mean square error
WCI Workers’ compensation insurance Bus Emp Business Employee
Stat Emp Statistical Employee
9
1.
INTRODUCTION
1.1.
B
ACKGROUND ANDT
HEORETICALF
RAMEWORKAs background to this study, we will introduce the concept of operational risk and its management and present an initial notion of fraud. In addition, we shall exhibit some concepts of artificial intelligence.
Management of operational risks is not a new practice; it has always been important for financial institutions to try to prevent fraud, maintain the integrity of internal controls (of processes and systems), reduce errors in transaction processing and even protect against terrorism. However its importance has steadily increased being comparable to the management of credit and market risk. It is clear that operational risk differs from other financial risks because it is not taken due to the expectation of a reward, nevertheless it exists in the natural course of corporate activity (Basel, 2003; Solvency II, 2009).
Solvency II is the regulatory and supervisory framework for insurers. Its purpose is to establish a common risk management system and risk measurement principles for every insurance and reinsurance company in the European Union. This framework was developed to mitigate some inefficiencies of the former Solvency I (Kaļiņina & Voronova, 2014; Vandenabeele, 2014). The Solvency II framework is based on three pillars: quantitative, qualitative and supervision requirements. In a regulatory level, insurance fraud is included in Pillar I, in the calculation of the Solvency Capital Requirement in the operational risk parcel (Francisco, 2014). As a sustainable company, an insurer aims to eliminate its risk by managing, planning, evaluating and controlling its processes which are practices of the mechanism known as risk management (Kaļiņina & Voronova, 2014).
Internal and external fraud are included in the categorization of operational risk by the Operational Risk Insurance Consortium and defined as intentional misconduct and unauthorized activities by internal or external parties respectively (Patel, 2010). Currently, fraud detection methods can be divided into four categories: business rules, auditing, networks and statistic models and data mining (Shao & Pound, 1999). The use of data mining is due to its financial efficiency finding evidence of fraud through the application of mathematic algorithms in the available data (Phua, Lee, Smith, & Gayler, 2010). One example of these mathematical algorithms is neural networks; this model is inspired in biological neural networks (see resemblance in figures below). Artificial Neural Networks (ANNs) are systems of interconnected neurons which exchange messages between each other.
10 There are many applications of ANNs in today’s business: (i) financial institutions are improving their decision making processes by enhancing the interpretation of behavioural scoring systems and developing superior ANN models of credit card risk and bankruptcy, (ii) securities and trading houses are improving forecasting techniques and trading strategies, (iii) insurers are improving their underwriting techniques, (iv) manufacturers are improving their product quality through predictive process control systems (Li, 1994). In fact, neural networks (as Generative Adversarial Networks) are being used to adjust datasets in order to make them usable for further investigations (using neural algorithms for example). This supports the industrialization of neural networks in the current days (Douzas & Bação, 2017)
1.2.
S
TUDYR
ELEVANCEIn this section, we intent to clarify the reasons as to why we should be concerned about fraud and its detection methods, considering the perspective of insureds and insurers and the consequences for financial institutions. This concerns, in particular, the Portuguese insurance sector which is undergoing a deep change in terms of its administration system. Indeed, a close relationship between insurers and banks has always been beneficial before but the 2008 financial crisis, which has affected both financial markets, is proof that this may be no longer true (APS, 2016a).
According to Pimenta (2009), the estimates of total fraud in insurance in Portugal are about 1,5% to 2,0% of the national GDP which is congruent with what’s happening internationally: in Australia, the numbers round 1,3% of GDP, Canada rounds 2,1% of GDP, France 2,0% of GDP, Ireland 4%, USA 6% and Germany 9%. In fact, the total cost of insurance fraud (non-health insurance) in the US is estimated to be more than 40$ billion per year and in the UK, (overall) fraud is costing £73 thousands of millions a year (Baesens & Broucke, 2016).
11 estimates of the incidence of suspicious claims are at least 10 times as great as the number of claims that are prosecuted for fraud (Dionne & Wang, 2013; SAS, 2012). Maybe because of this, only market leading companies report properly the abuses they suffer. Small companies fear any damages to their reputation, they cannot afford losing mistakenly investigated clients and do not possess the means to properly split fraudulent from non-fraudulent claims. Still, 62% of international companies with more than 5000 employees declare being victims of fraud (Pimenta, 2009).
There was a study conducted by PWC (2016) which included 5428 companies from 40 countries. It showed that 43% of those companies suffered at least one economic crime in the last two years. The sector with a higher percentage of companies that consider themselves as fraud victims is the insurance sector with 57%. A daunting fact is the contamination effect of fraud as it affects multiple segments such as automobile (more than one-third of injury claims in the 90s had elements of fraud), health (in this segment, losses with fraud are about 3%), personal accidents, property risk and so on (Amado, 2015; Tennyson, 2008). According to the European Insurance committee, fraud takes up to 5 to 10% of the claim amounts paid for non-life insurance (Baesens & Broucke, 2016).
Regarding workers’ compensation insurance, the Portuguese sector follows the trend: the sector is deeply out of balance and in need of a restructuring. Several factors have led to this results such as (i) significant modifications to the Portuguese legislation which has led to increasing responsibilities from insurers, (ii) relevant increase of life expectancy resulting in a greater burden to insurers due to the annuity’s payments, resembling what happens in social welfare institutions, (iii) decrease of interest rates forcing re-evaluations of future responsibilities, and resulting in greater provisions by insurance companies, (iv) increase in claim’s costs due to fraudulent behaviours (of policyholders, insured persons and even providers.) Although improving, results continue to be catastrophic. In 2015, the sector had generated -88€ million as technical results (APS, 2016a). The size of workers’ compensation insurance in Portugal is considered significant compared with other sectors. Numbers show that 238 thousand is the number of claims that occurred in 2015 (1.5% higher than 2014) with an average cost per claim of 2 484€. The claim’s ratio ( claims’ cost over premiums) is not a good number to show being 108.3% in 2015 which is still a significant increase from the 115.3% of 2014 (APS, 2016b). In Portugal, CTFRAUDE was formed in 2006 by the Insurers Portuguese Association, which came however too late to tackle such an important risk for insurers as it represents between 5% to 20% of each institution’s total risk (APS, 2016a; Dionne & Wang, 2013).
12 There is no official data about workers’ compensation insurance fraud in Portugal, but there are signs that it is increasing; Alda Correia (member of CTFRAUDE of APS) informed, in an interview, that the numbers amounted to 1% in 2007 and 2% in 2012, with a resulting increase in the premiums paid by insureds (Pimenta, 2009; Ribeiro, 2012). It is evident that there is a gap in the insurance fraud literature which needs investigation. On the other hand, it is known that fraud detection in financial institutions requires an extensive amount of data as well as data processing resources. These have only became commonly available in the last decade.
This work will allow to accurately identify fraud when it happens and efficiently prevent its materialization in the future. This will not only reduce significant losses, it will also encourage innovation in the fraud prevention research area and attract more potential investors. In the next section, we will demonstrate how this work will contribute to this field and what we aim to accomplish with it.
1.3.
P
ROBLEMI
DENTIFICATION ANDS
TUDYO
BJECTIVESThe fraud vulnerability of workers’ compensation insurance is, now, clearly obvious. An aggressive strategy should be put in place, without disrupting relationships with clients by investigating them too frequently or too deeply. Insurance companies have to adopt new methodologies to detect fraud and reduce the necessary time for manual processes due to fraudulent claims (Phua et al., 2010). The undoubtedly severe losses due to fraud schemes should be sufficient reason to set in place more efficient fraud detection and prevention methods, aiming to avoid future suspicious claims even before filing.
This work proposes a new model with continuous learning features, that is, every time is used it improves itself before the next test. The main goal of this project is to improve fraud’s detection and mitigation methods with neural networks using data from a Portuguese insurance company, with the intention generalizing the conclusions and making them useful for other companies in the market. From gathered information, a neural network model will be derived to perceive fraud. The first specific goal to be achieved is the identification of the significant variables for fraud detection in workers’ compensation insurance claims. This requires a statistical analysis of the data and a comparison with others already tested in the fraud detection research area. Next step is, the identification of the most appropriate types of neural networks to use. An extensive literature review to study and summarize the real and potential applications of the several types of neural networks is conducted. This is crucial for the project as there are several types of neural networks and also quite a few ANN algorithms. Lastly, we select the best suited model for the problem under study. This should be based on the last two specific goals.
13
2.
LITERATURE REVIEW
2.1.
O
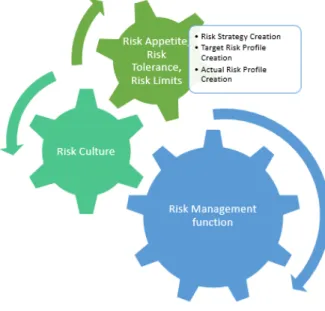
PERATIONAL RISKThe 2008 financial crisis frightened people and made them consider the consequences of their actions, including borrowers, lenders, politicians, and regulators. The unsustainability of the bold investments, greed and human failures of risk management and governance led to worldwide problems (Thirlwell, 2010). Financial institutions should have well defined risk management models and which should include assessment, analysis and elimination of risk (Kaļiņina & Voronova, 2014). As seen in figure 3, risk culture and risk appetite of an institution should be taken into consideration when seeking risk management strategies. Risk appetite is the measure of acceptance of risk (its profits and losses) of an organization. This appetite is one of the components of the risk cultures just as stress testing, risk identification, risk assessment, risk measurement, reporting, risk monitoring and connection with business strategy (Kaļiņina & Voronova, 2014).
Figure 3 - Structure of risk management
14 has been considered a low probability risk (Basel, 2003). This increase suggests financial institutions have significantly reduced their risk management activity for operational risk which is unadvisable as it lies at the heart of all risks: it involves everybody. Recall, managing people is one of the four elements of the Basel definition of operational risk (Dionne & Wang, 2013; Thirlwell, 2010).
15
2.2.
F
RAUDSolvency II states seven risk types in operational risk: external fraud, internal fraud, employment practices and workplace safety, clients, products and business practices, damage to physical assets, business descriptions and system failures and execution, delivery and process management (Dionne & Wang, 2013).
The Oxford Dictionary defines fraud as “wrongful or criminal deception intended to result in financial or personal gain” which seems incomplete: deception does not necessarily mean fraud; some characteristics need to be fulfilled: it should be uncommon, time-evolving and damage-making. Also, the individual should be aware he/she is committing fraud (it is not enough to make a false statement, to be classified as fraud the person has to know he/she is making a false statement the moments such statement is pronounced) (Pimenta, 2009; Vlasselaer et al., 2015). Fraud has a certain seasonality; during economic growth it is mitigated, during recession it is stimulated (as necessity increases, moral standards degenerate while risk aversion may be boosted); sometimes this is enough to caught the attention of managers who consequently intensify operational risk management. (Dionne & Wang, 2013) According to a KPMG study, during the financial crisis (2007-2011) there was a 74% increase in financial institutions internal fraud. Other studies support these results: Allen and Balli (2007) state that operational losses are related to business cycles and Chernobai, Jorion, & Yu, (2011) found a dependence between crisis and operational risk (Dionne & Wang, 2013; “Record Year of Fraud Reports in 2011 - ABC News,” 2012).
The basis of fraud is human behaviour, according to a hypothesis formulated by Donald Cressey, i.e. the fact that people with financial problems know that problem can be resolved by violating the position of financial trust. Furthermore, they are able to adjust their conceptions of themselves as trusted persons or entrusted. The fraud triangle (figure 4) comprehends the underling motives and drivers of fraud (Baesens, Vlasselaer, & Verbeke, 2015; Soares, 2008).
16 Pressure is the main motivation for fraudulent behaviours; it arises of a problem which does not seem possible to be resolved in a licit way. Usually, it results in financial fraud (desire of better lifestyle, game addiction, debts). Next driver of fraud, Opportunity: it is the precondition to the action of committing fraud, the sense that the person will not be discovered therefore relieving the pressure. These opportunities arise from weaknesses within institutions, such as lack of internal control, miscommunications, mismanagement or absence of internal auditing. Lastly, Rationalization: this driver explains why fraudsters do not refrain from committing fraud by justifying the act to themselves as a once-in-a-lifetime act. This way, their conduct appears, to themselves, acceptable. Each one of these three elements adjust themselves resulting in fraud probability evolution through time (Baesens et al., 2015; Soares, 2008).
17
2.3.
F
RAUD INI
NSURANCE BUSINESSThere are records evidencing intentional sinking of ships (ship scuttling) in order to claim the insurance money dated from between 1100 AC and 146 AC. These acts could lead to death penalties and this fact is thought to have originated life insurance. Also, with the growth of railway and automobile industry there was an expansion in insurance contracts and, consequently, insurance fraud (Niemi, 1995; Viaene, Derrig, Baesens, & Dedene, 2002). Insurance fraud is about an intention of an insured person (or policyholder or provider) to deceive the insurance company to profit from it, or vice-versa, based on a contract. The insurer may sell contracts with non-existing coverages or fail to submit premiums and the insured may exaggerate claims, present forged medical expenses or fake damages (Derrig, 2002; Lesch & Brinkmann, 2012). The fact that there is a contract between the fraudster and the victim is an important differentiation from other types of fraud. Here, we can invoke the concept of moral hazard which recognizes that the contract reduces the insureds' incentives to prevent losses, and may even led to exaggerated or fake damages, increasing the probability to retrieve the premium paid by insurers (Francisco, 2014; Tennyson, 2008).
18 Again, insurance fraud depends mostly on human behaviour; Tennyson (2008) has some interesting conclusions on this matter. Fraud campaigns need to be more intense as fraud acceptance is shared between peers. “Fraud breeds Fraud” is a common saying in the finance industry; if fraud tolerance starts increasing, so does fraud costs (Paasch, 2008). The author also states that penalties are not as effective as high detection probabilities in preventing fraud. Still, even these will have a non-significant effect on people that had negative interactions with insurers or have a bad consideration about them. Internal Reward mechanisms are the most important decision-making criteria on whether an individual should deceit, so it is on this point that the campaigns should focus on. Curiously, studies point out that highly educated women and the elderly are less tolerant towards insurance fraud (Lesch & Brinkmann, 2012). Regarding acceptance towards insurance fraud, a person may be:
• Moralist, least tolerant towards insurance fraud, agrees with strong penalties
• Realist, consider fraud dishonest but finds it justifiable in some cases
• Conformist, accepts insurance fraud as commonplace
• Critics, most tolerant towards insurance fraud
Insurance offenders may be classified into three types:
• Freeloaders: law-abiding individuals who take advantages in real situations
• Amateurs: individuals with intention to commit fraud who make false claims and multiple insurance contracts
• Criminals: individuals, usually with criminal records, that belong to broad criminal organisations and commit organized fraud
Although the number of insurance criminals is increasing, in its broad-spectrum insurance fraud is committed on a day-to-day basis by freeloaders and amateurs (Brites, 2006; Clarke, 1990; Tennyson, 2008).
Insurance fraud may be able to be categorized, but firstly it must be clear that fraud in this context should be reserved for meant acts, provable beyond reasonable doubt (Derrig, 2002).
• Criminal or hard fraud: meant, and against the law, aiming for a financial profit for the fraudster due to a deception under the claim
• Suspected criminal fraud
• Soft fraud or systematic abuse: whenever one of the characteristics of criminal fraud is not met
• Suspected soft fraud
19 common than hard fraud, but costs associated with it are smaller. Therefore, usually fraud campaigns emphasize criminal fraud and usually use number of cases brought to convictions as a measurable indicator. However, being the most common, soft fraud is the one that mostly reduces the trust relationship between parties; therefore, in order to anticipate fraud opportunities and reduce this type of fraud, it is advisable to update policyholders on latest fraud discovers and provide moral cues (SAS, 2012; Tennyson, 2008). In short, campaigns will only work if focused on the right motives fraudsters have. The ultimate reason for growth of the insurance business is due to the necessity of people to insure items that generate value like properties (domestic goods, cars) and activities (travel, business). This growth turned insurance companies into ruthless entities, since without claims, the only contact they have is payment of the premiums resulting in seeing fraud against them as a victimless crime. As insurers determine their scope (exceptions must be made for statutory insurance) they do not publicly emphasize that they are victims of fraud. This passes on to the public that insurance companies are robust enough to accept its costs and removes the ethical paradox of fraud. Under some circumstances, one can understand the rationalization of committing fraud; there is a lack of involvement by potential policyholders in the creation of the policies.
21
2.4.
F
RAUD IN WORKERS’
COMPENSATION INSURANCEInsurance fraud is a wide concept as it comprises a lot of different sub-types of (insurance) risk. Some may be worth mentioning like casualty fraud (people not owning the insured property or build-up on claims about it) or personal accident fraud (fake an accident to get payment of medical bills). Others shall have more detail as they have a significant dimension (Lesch & Brinkmann, 2012). Healthcare fraud has some magnitude in the literature due to its frequency: it is widespread fraud. Although it is very compact in a sense as it takes place usually as build-ups of claims other than organized fraud. (Tennyson, 2008) Fraud in healthcare insurance is the criminal activity with the highest growth in the last decade in the USA, considered now more profitable than credit card fraud (Fisher, 2008). Amado (2015) used social networks to build a model capable of predicting the participants more likely to commit fraud. Automobile fraud has significant related studies because its claims often need expert intervention which implies a multitude of resources. Even so, it is known as being hard to prove and most of the cases it is only considered suspicious. One identified cause of this is the consumer privacy which makes it hard to identify claims as fraudulent. Another is, many types of claims in the auto insurance that is hard to find standard characteristics for fraudsters (Francisco, 2014; Tennyson, 2008).
Workers’ compensation insurance (WCI) is a statutory insurance product whose portfolio’s is significantly wide – after years with catastrophic numbers, since 2014 its growing in terms of pricing and accident rates - and its fraud rates are considerable. Recall, the estimates of insurance fraud in Portugal are nearly 1,5% to 2,0% of the national GDP and represent between 5% to 20% of the total risk of an institution. Officially, APS has no numbers about fraud in WCI in Portugal, however CTFRAUDE states, in 2012, 2% of claims were fraudulent.
22 amount of non-filled WCI eligible injuries claims and Gardner, Kleinman, & Butler, (2000) showed the claim filling decision-making is positively dependent on past successful filled claims by co-workers. In Portugal, insurance businesses are supervised by ASF (Insurance and Pension Funds Authority Supervision) in charge of prudential and behavioural regulation. FAT is the workers’ compensation fund which ensures protection for those who, due to the risks associated with their activity, cannot find insurance, policyholders with insolvent companies or even insurers facing governmental pension raise. (ASF, n.d.)
2.4.1.
Legal Context
In Portugal, legislation on work accidents arose in the industrial revolution era, with the growth in the use of machines in the productive processes, which boosted the number of accidents and the severity of them. Initially, the burden of proof rested with the injured person which left many accidents with no repair (guilt was not proved). A new type of responsibility rose then: it is enough that a damage takes place for an obligation to repair it to exist. It rests on the principle that the one who takes the benefit of the labour and the risks it creates, should support the harming consequences of it (responsibility for the risk). This was written in the Law 83, July 24, 1913 which changed with time1. Currently, it is reflected in the Portuguese legislation 98/2009, September 4, which regulates the work accidents and professional illnesses repair regimes including professional rehabilitation and reintegration. The evolution of the lawful regime is characterized by an increase of injured rights and employers responsibilities (consequently, insurers’ responsibilities) (APS, 2016b; Martinez, 2015; Vieira Gomes, 2013).
The notion of work related accident may be mistakenly seen as simple. It is so complex that some countries do not have a legal definition of it like Austria, for example. The notion of work accident was born linked to the professional risk theory, a specific risk different from the general risk of life that every human being takes. There are two theories worth mentioning: professional risk theory and economic risk theory. The first one, assumes a cause-effect relation (causal link) between the work executed and the accident: there is only a work accident if it is due to the core risk of the professional activity. The second considers that the accidents that take place in the workplace during working hours, even if they do not occur directly due to the main activity’s risk, should be repaired. The current Portuguese legal regime follows the last (Vieira Gomes, 2013). Currently work accident is defined (in accordance to the Law 98/2009, September 4) as an accident verified in the work place and time, which has induced directly or indirectly a body damage, functional disturbance or illness from which resulting in a decrease of work capacity or earning, or death. There are, of course, some extensions to this concept. (APS, 2016b).
All insurers must obey to the same law (Portuguese Law) and, in addition, they must present to the client the same general conditions regarding WCI, which are written by the state. The absence of insurance for accidents at works is punishable and can imply a penalty. So, there is some more legislation worth mentioning: Ordinance 256/2011, July 5 approves the uniform part of the workers’ compensation policy’s general conditions for dependent workers and Regulatory Rule 3/200-R, January 8 applies for independent workers, Law 102/2009, September 4 regulates the health and
1 Law 1942, July 27, 1936; Law 2127, August 3, 1965 and Law 100/97, September 13 were the ones
24
2.5.
A
NALYTICAL MODELS ANDD
ATAM
ININGIn this section, we will discuss the basic notions of some detection algorithms that are currently used by institutions. Initially, we shall identify the basic steps of the fraud cycle from fraud detection to fraud prevention. This is the correct order. Most failures in fighting fraud are due to errors in the detection phase; if there are failures here, there is a great probability they will propagate. Fraud detection methods allow to diagnose fraudulent activities whereas prevention aims to avoid fraud (Baesens et al., 2015; Hartley, 2016). Certainly, one should not work without the other. Firstly, the problem must exist, fraudulent activities must be caught, and this happens applying a myriad of detection methods to real data of the institution. Then, some suspicions rise according to the company’s risk culture. An investigation must follow, usually by an expert leading to the confirmation phase: there was a fraud. This is not a straight forward process but more like an (in)finite loop because when fraud is confirmed then some adjustments may be made to the detection model and new fraud risks are applied to the data. However, this does not compromise the (next) prevention phase characterised by the avoidance of fraud being committed in the future (Baesens et al., 2015). Detection failures are repeatedly associated with its input: the company’s data. Tailor-made solutions and difficulties in external facts integration make unreliable and incomplete data which are the number one problem for risk managers in a financial institution. The company’s database, while adapted for each business, should have the capacity to evaluate the potential losses and potential businesses, identify risk sources, point control weaknesses, and present history records regarding losses. Instead, detection fails as soon as there is the need to adapt the selection of insureds, or policies or even network providers (Gonçalves, 2011; Hartley, 2016; Lesch & Brinkmann, 2012). There is a multitude of analytical fraud detection methods which cannot be ranked in isolation; their validation should have in consideration their purpose and the company’s risk culture. However, there are some common indicators one should look for when examining them as statistical accuracy, ease of interpretability, operational efficiency, economical cost and flexibility with regulatory compliance. Current literature points out four main types of detection methods: business rules, auditing, social networks and statistical and data-mining models – these last two are usually connected (Baesens et al., 2015; Shao & Pound, 1999).
Business rules are guidelines and limitations for the company’s processes and status to meet their goals, comply with the regulations and process data. They are usually rules for the integration of external-sources data, data validation, anomalies detection or trigger warnings regarding abnormal situations aiming to decrease insurance risk (Baesens et al., 2015; Francisco, 2014; Herbest, 1996). For a better understanding, Baesens et al. (2015) gave some business rules as example, such as “If the insured requires immediate assistance (e.g., to prevent the development of additional damage), arrangements will be made for a single partial advanced compensation” but this comes with a potential risk of the partial compensation paid being higher than the real loss (Copeland, Edberg, Panorska, & Wendel, 2012; Vlasselaer et al., 2015).
25 Social Networks consist in the implementation of networks connecting suspicious or fraudulent entities by modelling connections between entities in claims (Baesens et al., 2015; Jans, Van Der Werf, Lybaert, & Vanhoof, 2011) In the pros list, the analysis ability can be fully automatic and updating continuously. Also, containing not only information on entities but relations between them may contribute to reveal wider fraud plans or criminal organizations (Baesens et al., 2015; SAS, 2012).
Although the last techniques are considered useful in fraud detection, their use is starting to be complementary: a simple and cost-effective method to detect fraud in existing claim is through statistical approaches which are proven to be more efficient than analysing individual claims. These enhance precision (with limited resources and large volumes of information the detection power increase with data driven techniques), operational and cost efficiency (data-driven approaches are easily manoeuvred to comply with time constraints without needing too many human resources). Some methods are worth mentioning such as outlier detection which can detect fraud different from the historical cases observed (the analysis can be completed with histogram, box plots or z-scores), or clustering (discover of abnormal individuals concerning all or some characterises). To compare groups, one can also use profiling (model with history behaviour). Many types of comparisons (real data versus expected values) can be made also through correlation and regression techniques to evaluate datasets (Bolton & Hand, 2002; Copeland et al., 2012; Vlasselaer et al., 2015). Data Mining, also known as Knowledge Discovery, is referenced as the ability to translate data in information using powerful algorithms (based on ever-increasing processing power and storage capacity). Industries value these characteristics as their datasets are becoming increasingly greater both in dimension and in complexity (Bação & Painho, 2003)
26 Kose et al. (2015) differentiate data mining techniques into proactive and reactive. The first are online techniques showing the risk degree and relevant justification of a claim before even accepting it. The former detects fraud retrospectively, after accepting the claims. A more common distinction in the literature is between supervised and unsupervised learning techniques. Supervised methods (predictive analytics) learn from historical information to differentiate fraudulent activities. A downside is the necessity of observed data with correctly identified labelled samples (fraud or legitimate claims) which also reduces the learning power to detect considerably different or new fraud types (Baesens et al., 2015; Bolton & Hand, 2002; Copeland et al., 2012). These methods are used to construct a model which will produce a classifier (or score) for new claims (Bolton & Hand, 2002). Supervised methods are currently being tested for fraud detection in healthcare and use technologies like neural networks, decision trees and Bayesian networks (Albashrawi, 2016; Copeland et al., 2012). Unsupervised techniques (descriptive techniques), although learning from historical data, do not need it differentiated between fraudulent and non fraudulent to find a behaviour different from normal. A disadvantage is that they are more prone to deception. Outlier detection, clustering and profiling are usually used to detect abnormal behaviour different from a baseline distribution (Baesens et al., 2015; Copeland et al., 2012). According to the Benford’s Law2, unsupervised techniques identify potential fraudulent activities which will need to be validated by experts. The goal is to be more resources’ efficient because less claims will need investigation. By not labelling data, unsupervised techniques can detect new and evolving types of fraud but their effectiveness is relatively untested in the literature (Copeland et al., 2012). In short, unsupervised methods have better performance to detect new types of fraud but are more unreliable because they learn from unlabelled data. They can be used complementing each other. A third type may be worth mentioning, semi-supervised methods use a mix database: some claims are labelled some are not (Baesens et al., 2015; Copeland et al., 2012).
There is a wide range of data mining techniques used in the fraud detection. So far, logistic regression model (which measures the relation between a categorical variable – fraud or not fraud – with the other independent variables) is the most used in detecting financial fraud (Albashrawi, 2016). According to the four eye principle3, business Mining detects fraud by mining event logs as process perspective (process models which explains the paths followed), the organizational perspective (explains the people involved) and the case perspective (explains the action itself) (Jans et al., 2011). Interactive machine learning is characterized by the ability of including experts insights directly into the model building process which is particularly important if the hypothesis explored is subject to change. Kose et al. (2015) explained the importance of a bottom-up analysis of each individual and his relation with the insurance segment and a top-down approach to automate the experts’ method to identify the relevant evidence. The author enhanced the efficiency of the model by, although not viable to decide if a single claim is fraudulent or not, only needing expert analysis in
2 Benford’s Law (or first-digit law), states that the first significant digit of many data sets follows a known frequency pattern, being 1 more probable than 2 which is more probable than 3 and so on. If the analysed data set does not conform to the predictions of the Benford’s Law, there is a possibility fraudulent activity. (Baesens et al., 2015; Copeland et al., 2012; Paasch, 2008)
27 the most suspicious cases. The quality of expert feedback should be enough to compensate the lack of data. In fact, for machine learning techniques to succeed they require quality training data which is, as frequently stated in the literature, difficult to obtain. Thus, interaction between data and experts is significant (Stumpf et al., 2009). Genetic algorithms (GAs) are (global) search techniques aiming to find solutions for optimization problems. GAs follow the Darwin Theory4 and always need: a fitness function to evaluate solutions (GAs search from populations, not single individuals); a representation of the solution (genome) and the set of operations allowed on the genomes. GAs domain are probabilities and not deterministic rules so the initial population is randomly chosen and then measured in terms of the objective function and assigned a probability of being in the next generation of individuals. In minimization problems, for example, the highest probability is assigned to the point with the lowest objective function value (Paasch, 2008; Sexton, Dorsey, & Johnson, 1999). Regarding optimization problems, simulated annealing (SA) should also be mentioned. Generating candidates, the main difference from GAs is that SA only generates one candidate solution to be evaluated by the fitness function (Sexton et al., 1999). GAs and SA can (and usually do) cooperate. It is common in the literature to find their use incorporated in other techniques like neural networks or support vector machines (SVM). These are similar but differ in the measure of error used: neural networks often use root mean square error (minimizing it) while SVMs use generalization error (minimizing the upper bound) (Bhattacharyya, Jha, Tharakunnel, & Westland, 2011). For a better understanding of artificial Neural Networks, the next section should be consulted. In terms of literature, Carminati, Caron, Maggi, Epifani, & Zanero (2014) built a decision support system with both supervised and unsupervised rules aiming to give a probability (of fraud) score. Phua et al. (2010) studied the literature on data mining approaches for fraud problems. Kose et al. (2015) developed a framework for healthcare which includes the relation between individuals and claims. He, Graco, & Yao, (1998) used genetic algorithms and k-nearest neighbour approach for fraud detection in medical claims. Welch, Reeves, & Welch, (1998) used genetic algorithms to develop a decision support system for auditors. Dharwa, Jyotindra N; Patel, (2011) constructed a model for online transaction fraud using data mining techniques to model the risk.
28
2.6.
N
EURALN
ETWORKSNeural Networks can be seen in one of two ways: first, they are a generalization of statistical models. Second, they are a technique that mimics the functionality of the human brain (Baesens et al., 2015; Ngai et al., 2011). Neural Networks learn by example and do not allow programming (Mo, Wang, & Niu, 2016). Three elements are particularly important in any model of artificial neural networks: structure of the nodes; topology of the network and the learning algorithm used to find the weights (Rojas, 1996). The process of application of neural networks includes two phases: learning and testing. The learning phase refers to the changes in the connections between the neurons necessary to adapt correctly the model to our data and summarise its internal principles, and the testing refers to the application of the model built (Guo & Li, 2008; Paasch, 2008).
ANNs are usually used for regression and classification problems such as pattern recognition, forecasting, and data comprehension (Gershenson, 2003). Currently, neural networks are being widely used in credit risk prediction/detection particularly in online banking where data has comprehensive complexities. Therefore, Cost-sensitive Neural Networks are being derived based on scoring methods for online banking. It was found that neural network still outperformed other methods in both accuracy and efficiency, and cost-sensitive learning is proven to be a good solution to the class imbalance problem (Vlasselaer et al., 2015).
These algorithms are known due to their remarkable ability to derive meaning from complicated or imprecise data, which can be used to extract patterns and detect trends that are too complex to be noticed by humans or other computer techniques. They have key characteristics valuable when working with classification problems; they are adaptive (learning techniques and self-organizing rules let them self-adapt to the requirements); they can generate robust models (a large number of processing units enhanced by extensive interconnectivity between neurons); the classification process can be modified if new training weights are set; and lastly, the ability to perform tasks involving non- linear relationships (Ngai et al., 2011; Paasch, 2008).
Although relatively subtle, one can find some critiques to ANN in the literature like Paasch (2008) who describes them as excessively complex compared with statistical techniques. As they work like black-boxes, they lack interpretability because some intermediary determinations are meaningless to humans (Paasch, 2008; Vlasselaer et al., 2015). Cases of overfitting are also mentioned in the literature, which means the model is too specific for the dataset used in the training and does not generalise for others. This can happen if the training data is not representative of the sample or insufficient for a clear representation. Other factors that can make a vulnerable model are poorly chosen network parameters such as momentum or learning rate, the wrong topology or choice of input factors (Mo et al., 2016; Paasch, 2008).
29 The choice of the inputs for an ANN is usually determined by experts because there is no common ground on what rules work better. Guo & Li, (2008) used in their research adjusted inputs for the model: the inputs could be 1 or 0. To do this, the authors adapted the data available by transforming them in confidence values whether it was a discrete or continuous value.
The topology of the neural network can determine the failure or success of the model. However, there are no pre-determined rules to define it: it can be single or multilayer, it could have feedback loops or several hidden layers. For instance, the multilayer perceptron (MLP) is a standard multilayer feed forward network (processing feeds forward from the input nodes to the output nodes) with one input layer, one output layer, and one or multiple hidden layers (Paasch, 2008). Because of the importance of the topology, it would make sense to use a GA to determine it but researches showed it does not give better results (Paasch, 2008).
In the development of an ANN model, there are multiple decisions that can compromise its performance; experts mostly make these as, currently, there is not enough knowledge to automatize them. These choices involve all parameters necessary for the ANN to learn and perform, for instance, population size, number of generations, mutation and crossover probability and selection method. In terms of hidden layers, the decision consists not only on quantity of layers but quantity of neurons. Its role is to derive the characteristics of the inputs, combine them and restore them to the output neurons (Baesens et al., 2015). Guo & Li, (2008) suggested using a specific GUI of their system to select the number of hidden layers and nodes in each layer ending up in a multilayer with smaller average error. In his research, Paasch (2008) used a model with only one hidden layer including 25 hidden neurons. Theoretically, one hidden layer is enough to approximate any function to any desired degree of accuracy on a compact interval. In fact, the vanishing gradient problem states that the chain rule used to update the hidden unit weights has the effect of multiplying n small numbers to compute the gradients of the front layers in an n-layer network. Therefore, the gradient decreases exponentially with n. Consequently, when more than two hidden layers are used, the algorithm becomes slower. Also, a nonlinear transformation in the hidden layer and a liner transformation in the output layer are, academically, recommended. To choose the number of hidden neurons, a try and error process is the most suited using the data that will be used in the training phase. In the literature, usually the number of hidden neuros goes from 6 to 12 (Baesens et al., 2015).
Some parameters like population size or number of generations of the model highly vary according to the characteristics of the data collected. Additionally, a momentum is often added to a neural network by adding a fraction of the previous change to every new change. However, one can see in the literature that a momentum does not allow the neural network to outperform others nor lowers the average error (Paasch, 2008). In terms of the learning rate, one can tell that higher learning rates mean lower network errors but a learning rate too high may compromise the global search. The learning rate may be set to countdown of the number of entries in training data or may even change in each layer of the model. Though, these are relatively untested being the most common a manually fixed learning rate (Guo & Li, 2008; Paasch, 2008).
30 The output layer also deserves some attention regarding the number of neurons it should contain. If a more qualitative output is intended (like fraud score and fraud consequences simultaneously) then several outputs should be used. However, in the literature, one finds more often the use one single output neuron. This output shall focus only on giving a fraud score for each claim: scores higher than a pre-defined threshold shall be considered fraudulent and the others as legitimate (Baesens et al., 2015; Paasch, 2008).
So far, we enhanced some decision-making mechanisms throughout the steps of neural networks: introducing the input sample (activation of the input neurons); propagation of the input creating the output; comparing the network output with the desired one; correcting the network. Now we shall discuss how this propagation works: the definition of the weights is a crucial part of the development of the model. There is no absolute truth on deciding which are the perfect weights but there are some methods that can help (Kose et al., 2015).
The Delphi method relies on a panel of experts and a director. The director constructs questionnaires for the experts and then summarises their feedbacks and thoughts, then a second round of questionnaires is built. This way, the panel will converge toward the right answer (Kose et al., 2015). The Rank Order Centroid Method is based on a ranking provided by experts, as it is easier to rank attributes than to quantify them. Ratio Method is also based on ranking but ranked weighs are assigned from 10 and in multiples of 10; then they are normalised (Kose et al., 2015). In their study, Kose et al. (2015) also used a hybrid solution of these: used binary pairwise comparison method (determine which attributes define more significantly fraudulent activities and then rank them). As in the last method, the experts analyse the forecasts and reweight until the results are satisfactory. One can see in the literature that neural networks that achieve significant results usually have weights estimated by an iterative optimization algorithm after randomly assign initial weights (Baesens et al., 2015). It is common to use a gradient descent method like backpropagation, simulated annealing, or genetic algorithms. Gradient descent methods use the gradient of the error function to descent the error surface. The gradient is the slope of the error surface which indicates how sensitive the error is to changes in the weights (Paasch, 2008).
Backpropagation is a procedure used in the learning phase of neural networks, determining the weights, which is particularly hard in the hidden layers since there is no output to compare. It is a gradient descent method which, after receiving all inputs, derives an output error (Kriesel, 2005) It, usually, follows the following steps:
1. Use the training sample as input of the network. 2. Compare the networks output with the desired one. 3. Calculate the error of each input neuron.
4. Calculate the local error5 of each neuron.
5. Adjust the weights of each neuron to lower the local error.
31 6. Assign responsibility (for this error) to the neurons of the previous level, specially the
stronger ones.
7. Repeat steps 3,4, 5 and 6 for neurons in previous level.
This way, the weights of the network will be updated for the sample of the training set. The update will occur according to the following equation:
where E is the cost function that measures the network’s error, n is the training epoch, ηL is the learning rate for a specific layer, and α is the momentum term (Paasch, 2008).
Backpropagation often finds the solution of the optimization problem in the neighbourhood of its starting point as it is designed for local search; thus the definition of its starting value is extremely important. The downside of local search algorithms is the probability of finding a local minimum and not global. To minimize this, some studies in the literature have used modifications of backpropagation, using more advanced gradient descent techniques as Delta-Bar-Delta Learning, Steepest Decent Method, Quickprop, the Gauss-Newton Method and the Levenberg- Marquardt Method (Guo & Li, 2008; Paasch, 2008; Sexton et al., 1999).
32 authors found no impact on the results. Regarding elitism - copying a small proportion of the fittest candidates, unchanged, into the next generation – the authors thought it would make a difference in terms of time because it would allow not wasting time disregarding weights already determined. Despite the fact it reduced the network error, they concluded it does not make a significant difference. Sexton et al. (1999) used back propagation, simulated annealing and genetic algorithms to determine weights in ANN and concluded, in their research, GA outperform the other two.
Noise is characterised as a random error of variance of featured data. Most real datasets have noise even if it is not known as they usually are archived in several databases. Training an ANN, noise can emerge due to the random allocation of initial weights which may produce different results for different weights (Kalapanidas, Avouris, Cracium, & Niagu, 2003). As a solution, Paasch (2008) suggests use of the average of the results of several training runs. The weights depend on the chosen algorithm (and, consequently, the required inputs) so this may also impact noise. The absolute consequence of noise is that it may propagate in the network and can even be modelled by the training algorithm. If this happens, the model may become too dependent of the training set and do not perform well for the validation set: this is called overfitting. To overcome this, Baesens et al. (2015) suggest to keep small weights in absolute sense (avoids fitting the noise) and add a weight size term to the objective function.
Figure 5 - Overfitting
A frequent question now is when to stop the training phase. It happens when the user is satisfied with the resulted error. Other stop criteria are to stop the training when the change of weight is less than a specified threshold or the number of iterations has reached the predetermined number (Guo & Li, 2008).
It is common to find in the literature, researchers discussing the overly complex processes of neural networks and how difficult it is to understand its behaviour. A way to soothe this is with a Hinton diagram. It allows to visualise the weights between the inputs and the hidden neurons as squares being the size of the square proportional to the magnitude of the weight and the colour of the square represents the sign of the weight. However, when few weights are connected to a variable in the hidden neurons it is not very useful (Baesens et al., 2015).
33 does not allow to understand the relation of inputs and outputs which can be explored by decompositional and pedagogical techniques (Baesens et al., 2015).
Figure 6 - Hinton Diagram
In terms of the output of the network (the results of the model) one should analyse their confusion matrix, that is, the volumes of misguided classifications. Let TP be the percentage of True Positives (legitimate claims classified as legitimate), FP be the percentage of false positive (fraudulent claims classified as legitimate), FN be the percentage of False Negative (legitimate claims classified as fraudulent) and TN the percentage of true negative (fraudulent claims classified as fraudulent). (Guo & Li, 2008) The sensitivity of the network is measured by the volume of True positives and the specificity is quantified by the amount of true negatives (Guo & Li, 2008).
34
3.
METHODOLOGY
3.1.
R
ESEARCHM
ETHODOLOGYIn this work, the paradigm applied is the constructivism, where knowledge is constructed not discovered; more accurately, the interpretivist since theoretic perspective shows the world as too complex to reduce to a few laws. We will derive from our data the knowledge necessary to reach meaningful conclusions and then apply them to other data. The purpose is to have all the information regarding the data collected: the variables and the results (fraud/no fraud) – training set. From here we will construct an algorithm that will replicate these results. This approach is known as qualitative induction. From the data, we will develop a process and test it with all samples of the data, if it does not work for some samples then it will be disregard and a new one will be developed (or the last one will be improved). This induction process is rigorous: it does not choose the samples to fulfil the hypothesis: it chooses deviant cases to disregard the algorithm. However, some acceptance threshold must be in place in order not to disregard too many modifications otherwise we could end up with one algorithm that works perfectly for the collected data, but it is so restrictive that has no application for other works (Gray, 2014). The strategy for the data is based on grounded theory as we will compare the samples of our data with each other through the algorithms and emerging new ones form them.
The data collection process is difficult due to the security, privacy and cost issues so most researchers generate synthetic data (Guo & Li, 2008). This was not an option for this work. The object of this study is a sample of a data base containing both fraudulent and non-fraudulent claims belonging to a Portuguese insurance company.
Once the data is collected, it needs investigation: we start by conducting an exploratory initial analysis.The next stage consists of constructing and improving the procedure to get the results. We make comparisons with other processes already in place to detect fraud and other methods using neural networks. We need to find the weights of the network to obtain the desired output of each sample of data which translates in using supervised learning. There are several algorithms to do this (training process) so we chose from the documented ones with better feedback and test them with our data. Simultaneously to the learning process, we took a decision on whether we should use layered networks and how many neurons per layer; the activation function needs also to be set although we already forecast testing the sigmoid function which is frequently quoted in the literature by its efficiency (it is very close to one for large positive numbers and very close to zero for large negative numbers).
35
3.2.
D
ATAC
OLLECTIONP
ROCESSThe average time needed for the data preparation process is 80% of the project time, more or less. (Guo & Li, 2008). For some, this value can reach 85% which is common for data preparation which is stored in many warehouses. Our data information is split through several channels: claim System, Policy and Entity System and some fraud detection systems complied in the statistics System of the company (Copeland et al., 2012).
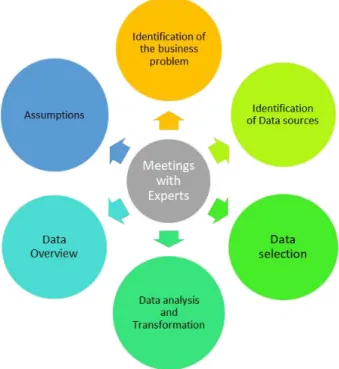
Figure 7 - Data treatment
36 Figure 8 Software Connections
3.2.1.
Meetings
In October 2016, there was an initial meeting with a company expert (from now on mentioned as Bus. Emp. 1) about data availability and accuracy. In November 2016, took place an interview with a data collection expert (from now on mentioned as Stat. Emp. 2) which mentioned how data is usually collected and divided. Accidents data do not have a fraud/non-fraud attribute; they do have a reason to justify closing a process (in the claims system) which may be fraud. The expert mentioned some reasons which could identify some suspicious claims:
• Fraud/False statements
• Policy non-existent
• Work accident non-existent
• Causal Nexus non-existent
• Employee not covered
37 The interview with Bus. Emp. 1 and Bus. Emp. 3 was about the data collection, more specifically the process of it. They explained that it is not viable to ask for all the attributes and then select the useful ones. A primarily scan shall be done to not waste resources in getting irrelevant data. The process arranged was that we should get familiar with Claim Software 1 (output system of claims) and Production software 2 (output system of policies and entities) to understand what (kind of) attributes are more likely to be useful. After that, we shall give them a list to see if there is (resources) availability to extract them.
Bus. Emp. 1 pointed out that before meeting with Cla. Emp. 7 one should become acquainted with Claim Software 1 thus understanding more about closing reasons and comments and in which attributes one can get hints about what triggered the manager to classify the claim as fraud.
Focusing in on an statistical point of view, another meeting was scheduled with Stat. Emp 2 and Stat. Emp 6. Both belong in the Statistical Studies Department at different hierarchical positions: Stat. Emp 2’s key points in this meeting is to give details on some projects in course and some data specifics. P6’ has a broader role in the company so he has more information on projects through several segments and the company’s strategies for the future.
The meeting started with a description of the approaches the company is taking by Stat. Emp 6. There are in place prevention and detection strategies: some more structural (organizational and cultural) and others more analytical (pattern analysis and toxic clients’ history). In this last category, some approaches were mentioned as business rules (informally, some were mentioned for instance, insured amount, unusual patterns, cost of past claims, purpose and alerts by different methods), predictive methods -in this field the company is using advanced analytics (using database with usual, suspect and fraudulent claims). About networks there were also some considerations made, the company has used (and still does in some projects) social networks but has come across some difficulties concerning which (type) should be used: the cost of investigating this may be too high and in the end, there is no proof it will work. Additionally, databases were discussed due to the specificities they should have to fit the networks.
A macro vision of the company was debated: each department has its own rules, processes and procedures which makes industrialization of fraud prevention/detection methods very difficult. Currently, it is in the development phase a project which consists in merging in one only repository the fraud central records. Other project in course is to merge certain databases to create alerts not only in entities (and vehicles registration).
A different database, unknown until now, was introduced – Risk software 4 – which has data about operational risk (where fraud is included). This database is property of another department (risk management department) and when interest was shown to get familiar with it, some barriers rose: it is too extensive and classified to analyse – they suggested to use the other databases (which are the base where Risk software 4 is getting information from). Furthermore, another good news was released: there is an (analytical) data base for archives (namely the fraud investigation reports) with reasonable information (which in Archive software 3 was only available in report -pdf- form).