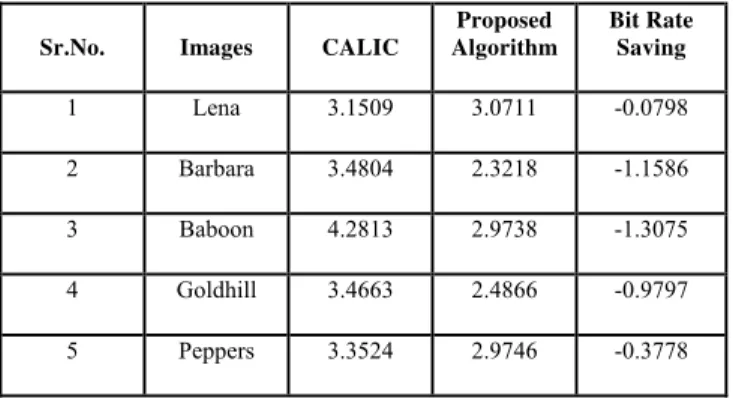
A Similar Structure Block Prediction for Lossless Image Compression
Texto
Imagem
Documentos relacionados
However, individual factors within the scope of human capital and research-, market sophistication- as well as business sophistication conditions are found to play a role
If other dimensions, particularly at the political level (e.g., the problem of “mensalão” and its shock waves), gain ground over the rest, we should be able to make a distinction
“Buscando somar esforços aos importantes avanços até aqui produzidos na discussão ética sobre o reflexo da desigualdade social nas práticas e serviços de saúde, a Bioética
Entendido que o novo no Direito constitui-se em desprivatizar interesses, introduzindo-se uma perspectiva coletiva, é importante que se faça o debate acer- ca da relação entre
A Digital Library is a powerful way to distribute and manage information in many distinct scenarios [1]. As such it was considered to solve the problem of a small size library.
Não por mera coincidência essa relação originária será colocada em obra pela linguagem poética, aquela mesma que se mostra a Heidegger como a morada essencial do ser
Best-Response Correspondence, 17 Best-Response Dynamics, 18 game, 16 Gershgorin theorem, 15 Hotelling model, 20 Hotelling Network, 52 indifferent consumer, 20 Local Market Structure,
