Comput. Appl. Math. vol.24 número3
Texto
Imagem

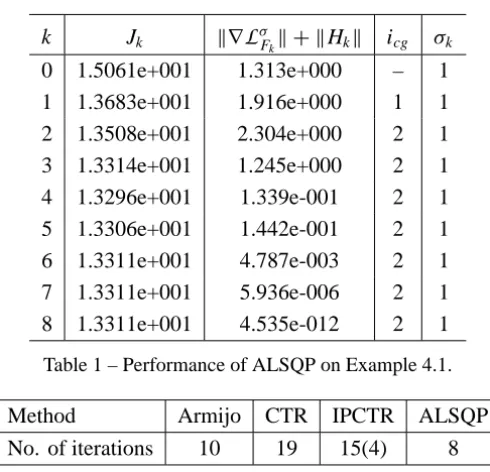
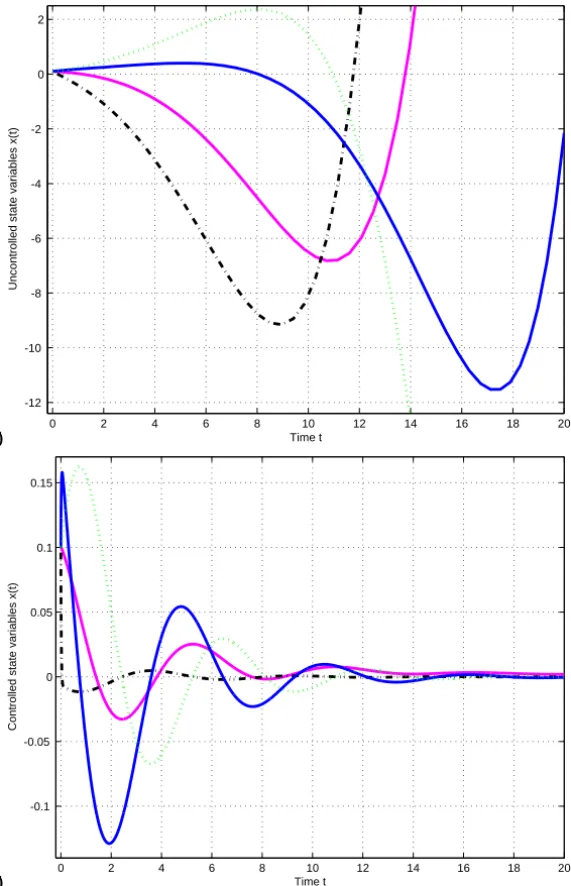


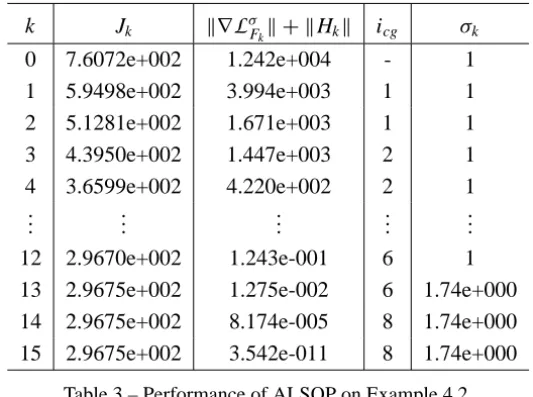
![Table 5 – Performance of ALSQP vs. Armijo, CTR and IPCTR on test problems from [8].](https://thumb-eu.123doks.com/thumbv2/123dok_br/18977803.455920/25.918.127.792.126.889/table-performance-alsqp-armijo-ctr-ipctr-test-problems.webp)
Documentos relacionados
As inscrições para o “Programa de Férias de Verão 2016” decorrem de 4 a 13 de maio de 2016 e poderão ser efetuadas na CAF e na sede administrativa, dentro dos horários
NÓS E OS OUTROS EM/COM QUEM HABITAMOS Na atual sociedade do conhecimento, pautada por encontros inesperados com as mudanças da era digital e cimentada por múltiplas incertezas,
Na cultura da cana-de-açúcar o manejo químico é o mais utilizado, no entanto é importante conhecer todas as formas de controle, e visar integra-las de modo a
Patentes que demonstraram a produção ou purificação do ácido succínico e/ou succinato como produto principal por.
Sistemas de Processa- mento de Transações Sistemas de Controle de Processos Sistemas Colaborativos Sistemas de Apoio às Operações Sistemas de Informação Gerencial Sistemas de Apoio
Extinction with social support is blocked by the protein synthesis inhibitors anisomycin and rapamycin and by the inhibitor of gene expression 5,6-dichloro-1- β-
Treinamento de Especialistas no Exterior 700 Jovens Pesquisadores ( para expatriados e estrangeiros) 860 Cientistas Visitantes (para expatriados e estrangeiros) 390.
