Análise de Agrupamento
(
Cluster analysis
)
(
Cluster analysis
)
Introdução
• Procedimento de análise exploratória
• Nenhuma pressuposição dos dados é necessária.
• Diferentemente da análise discriminante, os grupos não são
previamente conhecidos. previamente conhecidos.
• Pode ser utilizada com o objetivo de...
– Identificar a existência padrões homogêneos entre os objetos ou
indivíduos (formação de grupos), com base em 2 ou mais características – Sugerir hipóteses interessantes acerca dos objetos
– Meio informal de identificação de outliers
Exemplos de aplicações
•
Pesquisas de mercado
– Agrupamento de “cidades-teste”
•
Bancos de germoplasma
•
Bancos de germoplasma
– Caracterização
– Estudos de divergência ou diversidade genética
•
Educação
Input
1) Matriz de dados (“matriz
X
”)
Valores de p variáveis tomados em n objetos (indivíduos, unidades amostrais, tratamentos etc.)
2) Matriz de similaridade ou dissimilaridade
Matriz
X
Objeto
Variáveis
X1 X2 ... Xp 1 x11 x12 ... x1p 2 x21 x22 ... x2p
⁞ ⁞ ⁞ ⁞ ⁞
n xn1 xn2 ... xnp
Matriz de distâncias
Objeto 1 2 ... n
1 0 d12 ... d1p
2 0 ... d
2 0 ... d2p
⁞ ⁞
Medidas de (dis)similaridade
• Similaridade: quanto maior o valor observado dessas
medidas, mais parecidos são os objetos. Ex. correlação.
• Dissimilaridade: quanto menor o valor observado dessas
medidas, mais parecidos são os objetos. Ex. Mahalanobis.
Observações
• Qualquer medida de similaridade pode ser transformada numa medida de dissimilaridade e vice-versa.
• A escolha da medida de (dis)similaridade é de fundamental importância – diferentes medidas podem fornecer diferentes agrupamentos!
Medidas de distâncias
As medidas devem ser escolhidas de acordo com os tipos de variáveis:
– Quantitativas: euclidiana, euclidiana média, Mahalanobis, Manhattan,
etc.
– Padrão binário: Distância de Jaccard, índice de empates simples, etc.
– Padrão multicategórico: coeficiente de coincidência simples,
dissimilaridade de Cole-Rodgers
Medidas de distâncias para variáveis quantitativas
Distância euclideana∑
= − = p 1 j 2 j ' i ij ' i ,i (x x )
d
Distância euclideana média Distância euclideana média
∑
= − = p 1 j 2 j ' i ij ' i ,i (x x )
p 1 d
Distância de Mahalanobis
) (
)' (
Padronização das variáveis
Quando as p variáveis não são avaliadas na mesma escala de medida ou suas variabilidades são muito diferentes, é em geral conveniente padronizar as variáveis de forma que todas as variáveis sejam igualmente importantes no processo de agrupamento.
Algumas padronizações comuns são: Algumas padronizações comuns são:
jj ij ij
s x x
z = −
jj ij ij
s x
Medidas de distâncias para variáveis binárias
p ..., , 2 , 1 j ausente está X se , presente está X se , 0 1 x j jij ∀ =
=
Exemplos:
X1) Doença A: presença (1), ausência (0) X1) Doença A: presença (1), ausência (0) X2) Doença B: presença (1), ausência (0) X3) Sexo: macho (1), fêmea (0)
Medidas de distâncias para variáveis binárias
Objeto i Objeto i’
1 0
1 a b
Tabela contingência para número de empates (a e d) e desempates (b e c)
Distância de Jaccard [0, 1]
c b a
c b
di,i' ∈
+ +
+ =
0 c d
Índice de empates simples [0,1]
d c b a d a
si,i' ∈
+ + +
Medidas de distâncias para variáveis binárias
Objeto Variáveis
X1 X2 X3 X4 X5
i 1 0 0 1 1
i’ 1 1 0 1 0
Exemplo
Objeto i Objeto i’
1 0
1 2 1
0 1 1
i’ 1 1 0 1 0
60 . 0 1 1 1 2 1 2 d c b a d a
si,i' =
+ + + + = + + + + =
0 1 1
similaridade! 40 . 0 s 1
Métodos de agrupamento
•
Hierárquicos aglomerativos
– Vizinho mais próximo (ligação simples) – Vizinho mais distante (ligação completa)
– UPGMA (ligação média) – Ward
– Etc. – Etc.
•
Otimização
– Tocher, Tocher modificado
•
Não hierárquico
Métodos hierárquicos
1) Cada indivíduo constitui um cluster de tamanho 1 n clusters.
2) Em cada estágio do algoritmo pares de “entidades” são combinados e constituem um novo conglomerado.
3) Propriedade de hierarquia: cada novo conglomerado é um agrupamento de conglomerados antes formados.
Método da ligação simples
3
5
X
2
1
2
3
Método da ligação completa
3
5
X
2
1
2
3
Método da ligação média
3
5
X
2
1
2
3
Método de Ward
• Precursor de métodos de otimização.
• A função objetivo é minimizar a soma de quadrados dentro dos grupos, em relação a sua média (SQD).
• O método não calcula distâncias entre os grupos!
• Em cada estágio do agrupamento, entidades são unidas de • Em cada estágio do agrupamento, entidades são unidas de
modo a obter o menor aumento da SQD.
• É conveniente utilizar o quadrado da distância euclideana,
pois verifica-se que para dois objetos i e i’,
2 ' i , i '
i ,
i d
2 1
SQD =
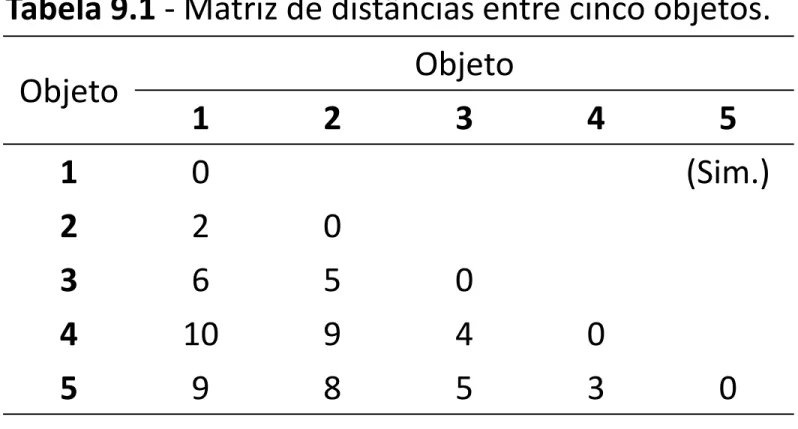
Exemplo
Objeto Objeto
1 2 3 4 5
1 0 (Sim.)
Tabela 9.1 - Matriz de distâncias entre cinco objetos.
1 0 (Sim.)
2 2 0
3 6 5 0
4 10 9 4 0
5 9 8 5 3 0
)
d
,
d
(
mín
d
ij,k=
ik jk)
d
,
d
(
máx
d
ij,k=
ik jkMétodo Função objetivo
Vizinho mais próximo
Vizinho mais distante ij,k ik jk
)
d
,
d
(
média
d
ij,k=
ik jkLigação média
Dendrogramas
1 2 3 4 5 Vizinho mais próximo
D is tâ n c ia 0 1 2 3 4 5
1 2 3 4 5 Vizinho mais distante
D is tâ n c ia 0 2 4 6 8 10
1 2 3 4 5 1 2 3 4 5
Critérios para encontrar o número de grupos
1) Comportamento dos níveis de fusão
2) Nível de similaridade percentual
3) Alguns critérios objetivos: R², RMSSTD, Pseudo F, Pseudo T², Mojena (1977), calculados em cada estágio do agrupamento.
Verificando a qualidade do agrupamento
• Coeficiente de correlação cofenética
• Aplicação de outros métodos de agrupamento
Correlação cofenética
1 2 3 4 2 2 3 6 5 4 10 9 4 5 9 8 5 3
Vizinho mais próximo
c
ia 3 4 5
Distâncias originais
1 2 3 4 2 2 3 5 5 4 5 5 4 5 5 5 4 3
5 9 8 5 3
1 2 3 4 5
D is tâ n c ia 0 1 2 3 Distâncias cofenéticas
Cor = 0.82
Obs.: o teste de Mantel pode ser utilizado
ACP com AG
• Objetivo: redução do tempo computacional para análise de
agrupamento!
• Deve ser evitado!
• Para tomar conclusões, ambas as técnicas podem ser
Exemplo ACP vs AG
x1 x2 x3 x4 [1,] -0.14 0.17 -0.44 1.58 [2,] -0.04 -0.03 0.29 0.16 [3,] 1.01 1.88 0.72 -0.28 [4,] -0.16 0.24 0.46 0.79
Matriz de dados (simulados) padronizados de 10 objetos e 4 variáveis.
Exemplo ACP vs AG
1 2 3 4 5 6 7 8 9 2 1.62 3 3.01 2.26 4 1.21 0.72 2.29
Matriz de distâncias euclidianas entre 10 objetos.
4 1.21 0.72 2.29 5 2.83 2.27 3.42 2.30 6 0.96 1.35 2.62 0.96 3.19 7 2.42 1.01 2.69 1.47 1.71 2.29 8 2.99 1.93 2.07 1.92 3.49 2.21 2.22 9 2.29 2.28 3.13 2.60 3.60 2.51 2.92 3.85
Exemplo ACP vs AG
Vizinho mais distante
ia 2.5 3.0 3.5 0.5 1.0 1.5 1 %
) 1 6
9 3 8 7 2 4 5 1 0 9 1 6 D is tâ n c ia 0.0 0.5 1.0 1.5 2.0 2.5
-2 -1 0 1 2
-1.5 -1.0 -0.5 0.0 0.5 C o m p .2 ( 3 1 %
2 4 3
Seleção de variáveis
• Objetivo: separar variáveis que contenham informações
diferenciadas.
• Input: matriz de similaridade ou dissimilaridade.
• Para variáveis quantitativas pode-se utilizar o coeficiente de
correlação de Pearson como medida de similaridade “relação linear”.
• Utilizando a matriz de correlação, pode-se obter uma medida
Algoritmo k-médias
•
Não hierárquico
•
Processo iterativo
•
Input
: matriz
X
de dados
•
Resumo dos passos:
1) Escolhe-se k centróides para iniciar o processo de partição.
1) Escolhe-se k centróides para iniciar o processo de partição.
2) Cada um dos n objetos é comparado com cada centróide, em geral usando a distância euclidiana. O elemento é alocado ao grupo cuja distância é a menor. 3) Recalcula-se os valores dos centróides para os novos
grupos e repete-se o passo 2.
Algoritmo k-médias
• Requerem o conhecimento a priori do número de grupos.
Consequentemente, os centróides ou a partição inicial tem que ser identificados antes do uso da técnica de agrupamento.
• São mais sensíveis a partição inicial. Iniciando o processo com • São mais sensíveis a partição inicial. Iniciando o processo com
partições diferentes, podemos ter soluções diferentes.
• Têm uma baixa performance quando partições iniciais
aleatórias são usadas.
• A performance é muito superior quando os resultados de um
Problemas de análise de
agrupamentos
• Diferentes algoritmos não produzem necessariamente os
mesmos resultados.
• O problema da sobreposição original dos dados. • O problema da sobreposição original dos dados.
Exercício
Realize o agrupamento pelo método da ligação média dos dados
disponíveis em:
http://support.sas.com/documentation/cdl/en/statug/65328/HTML/default/ viewer.htm#statug_distance_gettingstarted01.htm
Para análises no R
• Pacote: stats
• Funções:
scale(x, center = TRUE, scale = TRUE)
dist(x, method = “euclidean”, ...)
hclust(d, method = “single", ...) hclust(d, method = “single", ...)
cophenetic(x)
![Tabela contingência para número de empates (a e d) e desempates (b e c) Distância de Jaccard [ 0 , 1 ] cbacdi,i'b ∈ ++=+0c d](https://thumb-eu.123doks.com/thumbv2/123dok_br/16217993.712415/12.1263.148.1066.200.768/tabela-contingência-número-empates-desempates-distância-jaccard-cbacdi.webp)