REDUNDANT VARIABLES AND THE QUALITY OF MANAGEMENT ZONES
Texto
Imagem
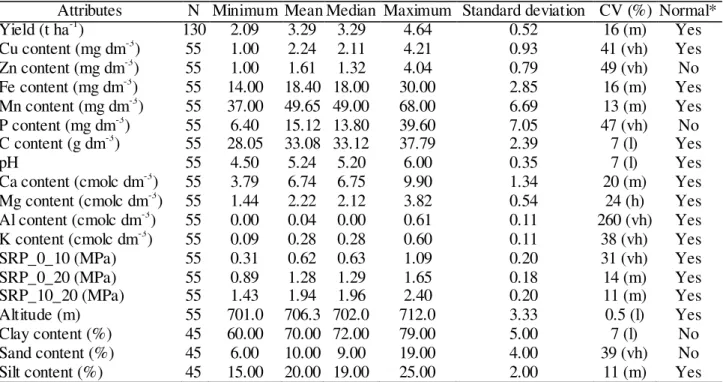
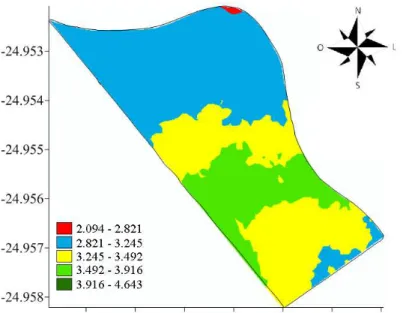

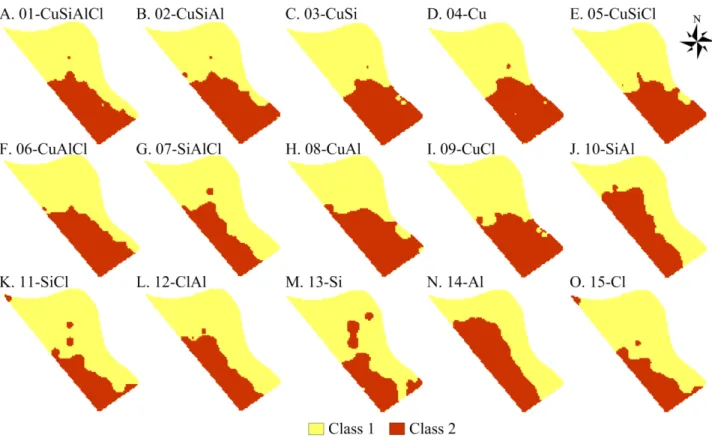
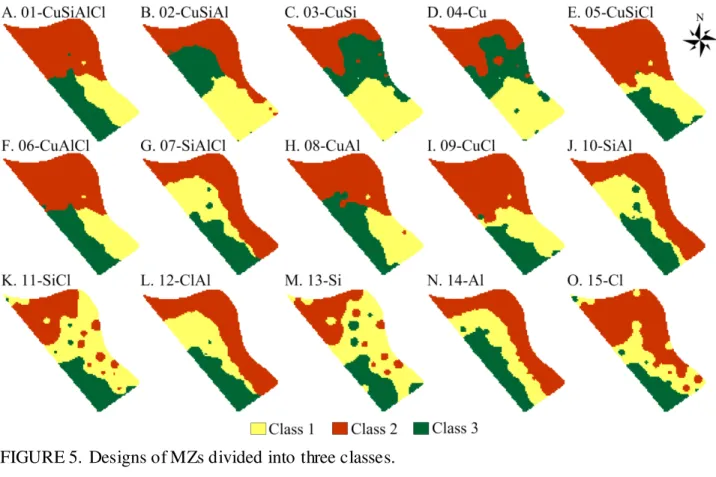


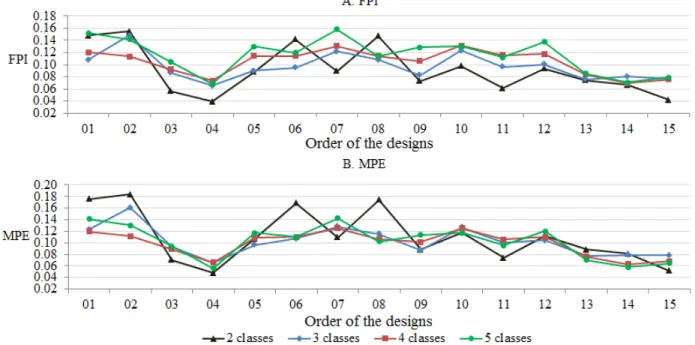
Documentos relacionados
The Genetic Fuzzy Rule Based System set the parameters of input and output variables of the Fuzzy Inference System model in order to increase the prediction accuracy of
O Projecto Rios segue uma metodologia científi ca que permite aos grupos comparar os resultados obtidos entre as várias saídas de campo e com outros grupos. As acções de melhoria
Atualmente, o Brasil constitui um mercado relativamente grande, possui um parque tecnológico expressivo e possui um sistema complexo e relativamente avançado de
Já o peso médio das presas aumentou com a temperatura, o que poderá ser o resultado do aumento de consumo de lagomorfos (com maior biomassa) e de insetívoros nas regiões com uma
Emad et al., (2010) demonstraram que o tratamento de quelóides com cirurgia e radioterapia é mais eficaz e seguro do que a corticoterapia associada a crioterapia, no entanto não
'Auditoria pode ser definida como sendo a certificação, a constatação e a avaliação de mn sistema, no qual o auditor emitirá um parecer sobre a fidedignidade
In current approaches to automatic segmentation of multiple sclerosis (MS) lesions, the segmentation model is not optimized with respect to all relevant evaluation metrics at
Dotado de uma gestão profissionalizada, com visão estratégica global desenvolvida e ligada ao exterior, e dispondo de importantes recursos financeiros libertados pela actividade na
