R eseaRcha Rticle P REDICTINGB URNEDA REAS OF F ORESTF
Texto
Imagem


Documentos relacionados
14 The same situation was observed in the present study, because the group treated with less than two years of diagnosis obtained better results than those patients treated with
Despite the study limitations, the influence ex - erted by the physical principles of water, and the fact that the results obtained in this study were lower than those of studies
A presente investigação teve como objetivo avaliar o impacto de outro tipo de experiências de disfuncionalidade menos estudadas e às quais a criança pode ter sido exposta
The analytical features of the proposed procedure were better than those obtained by other procedures for gossypol extraction and determination using cottonseed meal (Table 4).
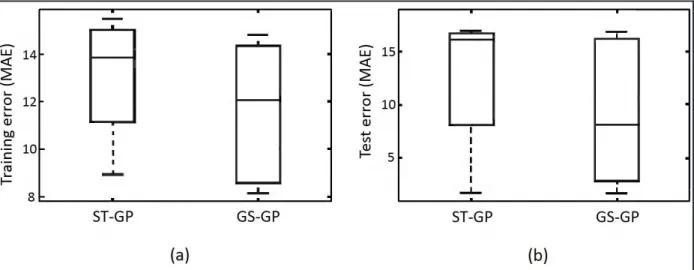
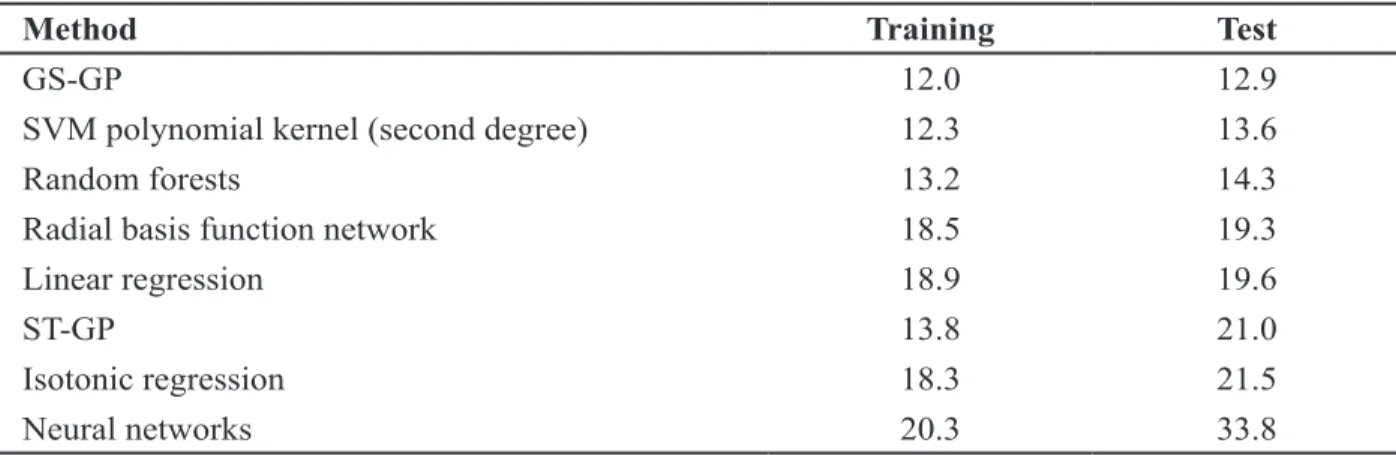
In particular, the results obtained with geometric semantic genetic pro- gramming are significantly better than the ones produced by standard genetic programming and other state of
This method was applied to three groups of individuals with different clinical and epidemiological characteristics, and the results compared with those obtained by other
Canela were very different in comparison with those of native Brazilian cupped oysters (C. rhizophorae), and were significantly so in comparison with those of other species
Results: In the univariate analysis patients with LD showed higher state anxiety scores ( p = 0.009) and worse work adjustment ( p = 0.019) than those without LD. A total of 45.3% of
