A Novel K-Means Based Clustering Algorithm for High Dimensional Data Sets
Texto
Imagem
Documentos relacionados
Estas normalmente associam-se constituindo uma rede em que se conectam violências do sistema social com as praticadas no nível interpessoal (Assis, 1994). Face
Ao compararmos a Figura 5.1(b) com a Figura 5.1(a), esta com um pólaron no sistema, vemos que a localização de carga é bem mais acentuada quando temos um bipólaron no sistema, que
In addition, we show multiple kernel k-means to be a special case of MKFC In this paper, a novel clustering algorithm using the 'kernel method' based on
show individual results regarding different distance measures, clustering algorithms, data transformations, and number of clusters.. The symbol ◦ accounts for the mean over
LEACH is a clustering algorithm, which means the nodes of the network are organized within clusters and they communicate between themselves via sensor elements called Cluster
It is calculated by dividing CPM value by CAM value. If the members of the cluster are all on the center the value of the metric is 0, but if the nearest centers of other clusters
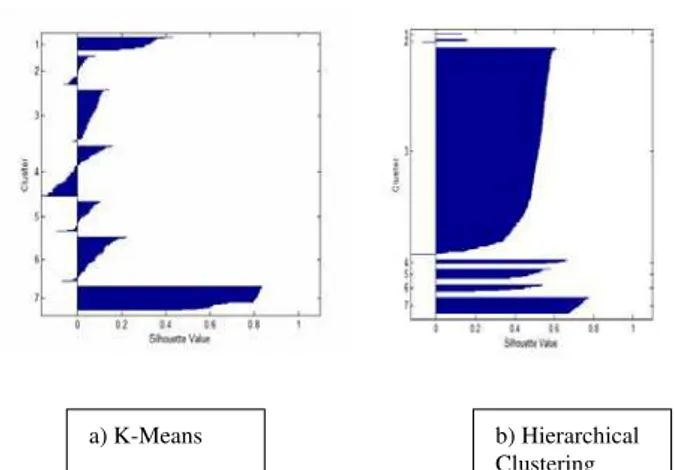
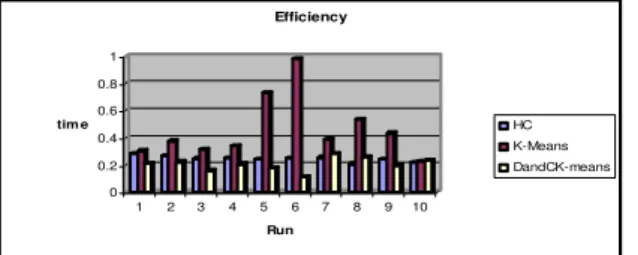
In this paper, a novel density based k-means clustering algorithm has been proposed to overcome the drawbacks of DBSCAN and kmeans clustering algorithms.. The result will be
In this study, developed in a vineyard with a long term natural cover crop, tillage application induced an increase in vine vigour and yield, as well as a better
