UNIVERSIDADE DA BEIRA INTERIOR
Engenharia
Towards Preemptive Text Edition using Topic
Matching on Corpora
Acácio Filipe Pereira Pinto Correia
Dissertação para obtenção do Grau de Mestre em
Engenharia Informática
(2º ciclo de estudos)
Orientador: Prof. Doutor João Paulo Cordeiro
Co-orientador: Prof. Doutor Pedro R. M. Inácio
Acknowledgments
I have received tremendous support throughout my academic life, and this year was no excep-tion. With the help of many people I was able to focus on the work at hand with ease. As such, I would like to thank those who supported me and ensured I was able to finish this dissertation.
A special thanks to my family for always backing me up in my decisions and providing the nec-essary conditions for me to work. Their love and support has been the most important factor in my personal and professional development.
I am very grateful for the help and guidance that was given to me by both my supervisors, without whom I would be unable to deliver this work. I would like to thank Professor João Paulo Cordeiro and Professor Pedro Ricardo Morais Inácio for their wisdom and advisement.
I acknowledge that meeting with my friends has always been a good stress reliever, providing me with lots of joy and fun. Thank you for all the moments that enriched my day. I am grateful to João Neves for the interesting discussions that allowed me to develop a better critical thinking.
Finally, I would like to thank Musa Samaila, Manuel Meruje and specially Bernardo Sequeiros, mostly for the great environment they have created in the laboratory and their help in the development of this work.
Resumo
Hoje em dia, a realização de uma investigação científica só é valorizada quando resulta na publi-cação de artigos científicos em jornais ou revistas internacionais de renome na respetiva área do conhecimento. Esta perspetiva reflete a importância de que os estudos realizados sejam validados por pares. A validação implica uma análise detalhada do estudo realizado, incluindo a qualidade da escrita e a existência de novidades, entre outros detalhes. Por estas razões, com a publicação do documento, outros investigadores têm uma garantia de qualidade do es-tudo realizado e podem, por isso, utilizar o conhecimento gerado para o seu próprio trabalho. A publicação destes documentos cria um ciclo de troca de informação que é responsável por acelerar o processo de desenvolvimento de novas técnicas, teorias e tecnologias, resultando na produção de valor acrescido para a sociedade em geral.
Apesar de todas estas vantagens, a existência de uma verificação detalhada do conteúdo do documento enviado para publicação requer esforço e trabalho acrescentado para os autores. Estes devem assegurar-se da qualidade do manuscrito, visto que o envio de um documento defeituoso transmite uma imagem pouco profissional dos autores, podendo mesmo resultar na rejeição da sua publicação nessa revista ou ata de conferência. O objetivo deste trabalho é desenvolver um algoritmo para ajudar os autores na escrita deste tipo de documentos, propondo sugestões para melhoramentos tendo em conta o seu contexto específico.
A ideia genérica para solucionar o problema passa pela extração do tema do documento a ser escrito, criando sugestões através da comparação do seu conteúdo com o de documentos cien-tíficos antes publicados na mesma área. Tendo em conta esta ideia e o contexto previamente apresentado, foi realizado um estudo de técnicas associadas à área de Processamento de Lingua-gem Natural (PLN). O PLN fornece ferramentas para a criação de modelos capazes de representar o documento e os temas que lhe estão associados. Os principais conceitos incluem n-grams e modelação de tópicos (topic modeling). Para concluir o estudo, foram analisados trabalhos realizados na área dos artigos científicos, estudando a sua estrutura e principais conteúdos, sendo ainda abordadas algumas características comuns a artigos de qualidade e ferramentas desenvolvidas para ajudar na sua escrita.
O algoritmo desenvolvido é formado pela junção de um conjunto de ferramentas e por uma coleção de documentos, bem como pela lógica que liga todos os componentes, implementada durante este trabalho de mestrado. Esta coleção de documentos é constituída por artigos com-pletos de algumas áreas, incluindo Informática, Física e Matemática, entre outras. Antes da análise de documentos, foi feita a extração de tópicos da coleção utilizada. Deste forma, ao extrair os tópicos do documento sob análise, é possível selecionar os documentos da coleção mais
semelhantes, sendo estes utilizados para a criação de sugestões. Através de um conjunto de ferramentas para análise sintática, pesquisa de sinónimos e realização morfológica, o algoritmo é capaz de criar sugestões de substituições de palavras que são mais comummente utilizadas na área.
Os testes realizados permitiram demonstrar que, em alguns casos, o algoritmo é capaz de for-necer sugestões úteis de forma a aproximar os termos utilizados no documento com os termos mais utilizados no estado de arte de uma determinada área científica. Isto constitui uma evi-dência de que a utilização do algoritmo desenvolvido pode melhorar a qualidade da escrita de documentos científicos, visto que estes tendem a aproximar-se daqueles já publicados. Apesar dos resultados apresentados não refletirem uma grande melhoria no documento, estes deverão ser considerados uma baixa estimativa ao valor real do algoritmo. Isto é justificado pela pre-sença de inúmeros erros resultantes da conversão dos documentos pdf para texto, estando estes presentes tanto na coleção de documentos, como nos testes.
As principais contribuições deste trabalho incluem a partilha do estudo realizado, o desenho e implementação do algoritmo e o editor de texto desenvolvido como prova de conceito. A análise de especificidade de um contexto, que advém dos testes realizados às várias áreas do conheci-mento, e a extensa coleção de documentos, totalmente compilada durante este mestrado, são também contribuições do trabalho.
Palavras-chave
Artigos, Documentos Científicos, Language Tool, Latent Dirichlet Allocation, LDA, N-gram, Pro-cessamento de Linguagem Natural, PLN, Qualidade, Sugestões, Wordnet.
Resumo alargado
Introdução
Este capítulo serve de resumo ao trabalho descrito nesta dissertação, expandindo um pouco mais o que foi exposto no resumo. A primeira subsecção apresenta o enquadramento da dissertação, o problema que se pretende analisar e os objetivos propostos para este trabalho. Depois seguem-se as principais contribuições, o estado da arte e o deseguem-senho e implementação do algoritmo desenvolvido no contexto do projeto. Finalmente, as últimas subsecções apresentam os testes mais importantes e as principais conclusões extraídas do trabalho realizado.
Enquadramento, Descrição do Problema e Objetivos
As sociedades evoluem através da criação, recolha e utilização do conhecimento. A sua utiliza-ção permite o desenvolvimento de ideias que podem resultar em melhorias na qualidade de vida. Uma das principais fontes de conhecimento é o trabalho realizado pela comunidade científica. Este consiste fundamentalmente na experimentação, com o objetivo de testar uma ideia, pro-var um resultado teórico ou procurar novas soluções para um problema existente, entre outros. Quando estas experiências apresentam resultados promissores, é escrito um artigo científico que descreve a experiência realizada, as ideias que motivaram este desenvolvimento e procedi-mentos seguidos para a sua realização. Estes artigos são depois submetidos a revistas e jornais científicos da área, que são responsáveis por assegurar a qualidade do documento, garantindo a existência de novidade na experiência e verificando a qualidade da escrita. Quando aceites, os artigos publicados resultam na partilha de conhecimento dentro da comunidade científica, possibilitando o posterior desenvolvimento desse estudo por outros investigadores, ou servindo de inspiração para a realização de outros estudos. Este processo de publicação resulta num ciclo de partilha de informação que é responsável por acelerar o progresso do conhecimento e assegurar a correção do trabalho desenvolvido.
O facto de ser realizada uma verificação do trabalho apresentado implica um esforço acres-cido para o investigador, visto que este deve assegurar a qualidade do documento. A falta de qualidade de um documento pode transmitir uma imagem pouco profissional dos seus autores, dificultando a sua publicação numa comunidade onde esta é a única forma de valorizar a inves-tigação desenvolvida [CK11]. A escrita deste tipo de documentos é uma prática difícil [RKEO15], requerendo um elevado grau de conhecimento da linguagem utilizada. Assegurar que o texto escrito transmite corretamente a mensagem desejada pelo autor é uma das dificuldades senti-das pelos investigadores, visto que o significado de um termo depende do contexto no qual este está inserido. A utilização de uma terminologia específica para cada área do conhecimento é outra dificuldade encontrada.
Dado o problema apresentado, os principais objetivos deste trabalho são:
• O desenvolvimento de um algoritmo capaz de assistir um investigador na escrita de docu-mentos científicos, onde o contexto do documento é tido em conta. Este desenvolvimento pode ser repartido em dois sub-algoritmos: o primeiro é responsável por extrair o contexto do documento e encontrar fontes de informação de acordo com esse contexto; e o segundo é responsável pelo cálculo de sugestões de melhorias e de correções de acordo com a in-formação recolhida das fontes selecionadas pelo primeiro;
• A avaliação do desempenho do algoritmo desenvolvido. Esta deve ser acompanhada da configuração do algoritmo de forma a maximizar o seu desempenho, de acordo com os resultados obtidos;
• A implementação de um editor de texto com a integração do algoritmo. Este último ob-jetivo serve como prova de conceito da utilização do algoritmo num contexto realista.
Principais Contribuições
As principais contribuições resultantes do trabalho realizado no âmbito deste projeto podem ser sumariamente descritas da seguinte forma:
• A primeira contribuição é a apresentação de um estudo ao estado da arte de conceitos relacionados com o trabalho desenvolvido. Este estudo descreve alguns conceitos intro-dutórios relativamente à área de Processamento de Linguagem Natural (PLN), incluindo modelação de linguagem através de n-grams e algumas técnicas de smoothing, utilizadas na resolução do problema da escassez de dados (data sparsity). A segunda parte do estudo apresenta algoritmos de modelação de tópicos (topic modeling) para extração de temas de uma coleção de documentos. O estudo contém ainda a apresentação de trabalhos realizados na área da escrita e avaliação de documentos científicos;
• O algoritmo capaz de propor sugestões relativamente a melhorias ou correções, tendo em conta o contexto específico do documento que se encontra sobre análise é outra contri-buição importante. O código fonte do editor de texto que instancia este algoritmo irá ser aberto, permitindo o estudo e desenvolvimento de melhorias pela comunidade;
• A aplicação desenvolvida como prova de conceito do algoritmo é ela própria uma contri-buição visto que permitirá aos investigadores receber sugestões para os seus documentos; • A análise dos resultados de um sistema que combina este conjunto específico de ferra-mentas e técnicas de PLN não foi encontrada no estado da arte, sendo também esta uma contribuição;
• Depois de desenvolvido o algoritmo foram realizados testes para determinar o desempenho do mesmo. Os testes realizados utilizaram um conjunto de tabelas com n-grams de vários x
géneros de Inglês. Este conjunto inclui: tabelas com n-grams de Inglês genérico; e várias tabelas com n-grams específicos de cada uma das áreas contidas na coleção de documentos utilizada. A variedade de contextos descrita pelas tabelas utilizadas permitiu a realização de um pequeno estudo relativo à especificidade da escrita em documentos científicos.
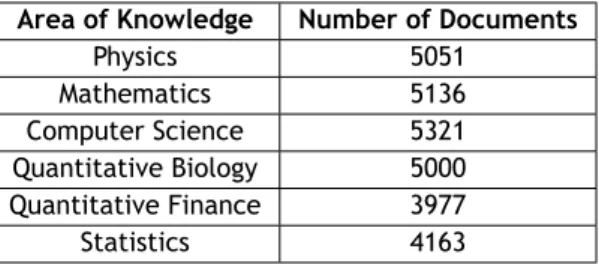
A coleção de documentos recolhida é outra contribuição que resultou como colateral do tra-balho realizado. Após uma extensa procura, sem sucesso, por coleções de documentos, que apresentassem as características necessárias à realização deste trabalho, a solução encontrada foi recolher documentos para a construção de uma nova coleção. Esta coleção segue uma apro-ximação à distribuição uniforme relativamente ao número de documentos de cada área (e sub-área), contendo mais de trinta mil documentos das áreas de Informática, Matemática, Física, Estatística, Biologia Quantitativa e Finanças Quantitativas.
Estado da Arte
Os n-grams são o modelo mais utilizado para a representação do texto de um subconjunto de uma linguagem [CG96]. Como tal, este é o principal foco da secção inicial do Capítulo 2, onde é descrito o processo utilizado para o cálculo da probabilidade de expressões ou frases. Segue-se uma descrição do problema, que se depara com o facto da maioria dos n-grams nunca ocorrer no conjunto de treino (data sparsity), bem como da sua resolução através de técnicas de smoothing, que permitem atribuir uma probabilidade a estes n-grams. São apresentadas algumas técnicas de smoothing, culminando na versão modificada do Kneser-Ney que é aquela que apresenta melhor desempenho [CG96]. Para concluir esta secção são apresentados os métodos utilizados na avaliação deste tipo de técnicas.
A secção do Capítulo 2 que se segue é referente à modelação de tópicos (topic modeling) uti-lizada na extração de temas de um conjunto de documentos. O resultado da modelação de tópicos é a representação reduzida de cada um dos documentos na coleção analisada de acordo com os tópicos extraídos. Os algoritmos apresentados nesta secção são classificados como al-goritmos de generative probabilistic topic modeling, visto que assentam na ideia de que cada documento na coleção foi gerado através de um processo chamado generativo (generative). O objetivo destes algoritmos é o de reconstruir a estrutura associada ao processo generativo, onde estão definidas as representações de cada um dos documentos, entre outras variáveis. São en-tão apresentados alguns dos métodos utilizados para estimação desta estrutura. Esta secção finaliza com a descrição de procedimentos que podem ser utilizados para comparar documentos através da representação obtida por este processo.
Para terminar o Capítulo 2, o estudo do estado da arte apresenta um conjunto de trabalhos de investigação realizados na área dos documentos científicos. Esta secção começa por apresentar estudos que descrevem uma das estruturas mais utilizadas neste tipo de documentos, a estrutura Introduction Methods Results and Discussion (IMRAD). Para esta estrutura, são apresentadas
algumas teorias sobre o intuito dos segmentos apresentados em cada uma das secções. A secção que se segue apresenta algumas características relacionadas com o estudo da qualidade de um documento científico e uma ferramenta para análise automática de ensaios. Finalmente, é descrito um conjunto de ferramentas desenvolvido com um intuito similar ao deste trabalho, que é o de ajudar na escrita de documentos científicos.
Algoritmo
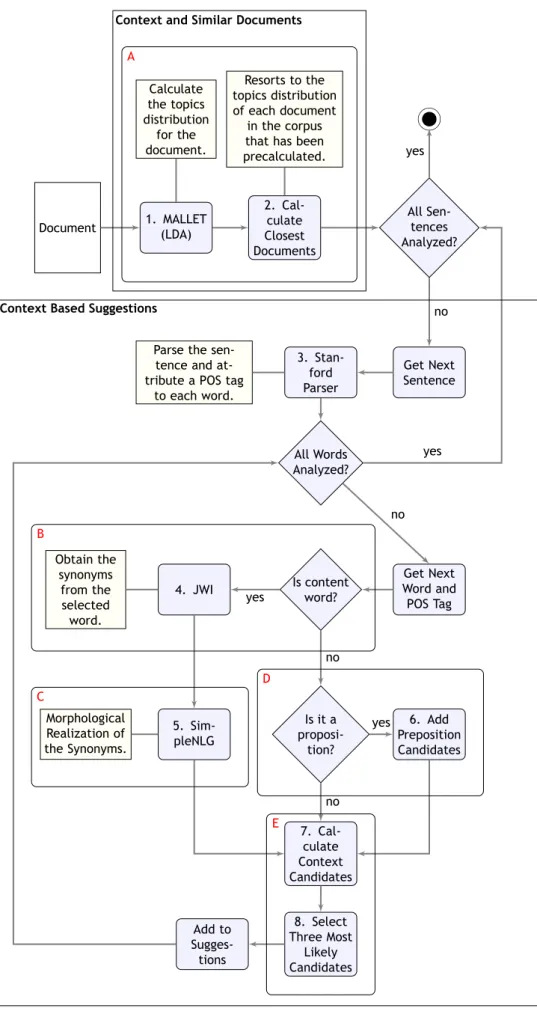
O algoritmo desenvolvido pode ser dividido em dois sub-algoritmos: o primeiro é responsável por extrair os temas tratados no documento, de forma a conseguir selecionar um conjunto de documentos cujos temas sejam semelhantes; e o segundo é responsável por calcular sugestões para melhoramentos e correções de palavras num documento, de acordo com os documentos selecionados pelo primeiro sub-algoritmo. Este primeiro sub-algoritmo baseia-se principalmente na utilização de modelação de tópicos (topic modeling) para encontrar documentos semelhantes num corpus. O segundo recorre a um conjunto de técnicas para criar uma lista de candidatos a possíveis substituições de palavras existentes no documento. Depois, através da utilização de um modelo de n-grams pré calculado nos documentos selecionados, o algoritmo propõe ao utilizador os três candidatos mais prováveis de aparecer.
Testes
Os testes realizados tinham como principal objetivo avaliar o desempenho do algoritmo desen-volvido. Foram realizados testes de dois tipos: objetivos, onde foram avaliadas as sugestões propostas pelo algoritmo em documentos com alterações realizadas automaticamente; e subje-tivos, através da avaliação subjetiva de várias versões de um conjunto de parágrafos, em que alguns aplicavam as sugestões propostas pelo algoritmo.
Os testes objetivos verificavam se o algoritmo era capaz de propor como sugestões as palavras que estavam no documento antes da sua alteração. A avaliação foi realizada de acordo com o Mean Reciprocal Rank (MRR), permitindo uma análise da correção das palavras tendo em conta a posição em que a palavra correta ocorre, valorizando pouco palavras que aparecem nas posições mais baixas da lista. O melhor valor de MRR obtido diz respeito à utilização dos n-grams de todos os documentos do conjunto de treino de Informática, como fonte para a análise dos documentos do conjunto de teste de Informática.
Os testes subjetivos analisaram a opinião de um pequeno conjunto de sujeitos em relação a várias versões de um mesmo conjunto de parágrafos. O primeiro conjunto tinha sido escrito pelo autor deste documento sem recorrer a quaisquer análises externas. O segundo resultou da aplicação da melhor sugestão proposta pelo algoritmo para todas as palavras cuja própria palavra não estivesse na lista de sugestões, para o conjunto original. O terceiro resulta de um processo semelhante ao segundo com um maior grau de liberdade, onde a aplicação de sugestões
só era feita nos melhores casos, permitindo ainda a conjugação das sugestões propostas. Os resultados destes testes demonstraram que a maioria dos sujeitos concordou que os parágrafos provenientes deste último processo eram aqueles cujo vocabulário era o melhor.
Conclusões e Trabalho Futuro
Os objetivos foram atingidos, sendo o principal o desenvolvimento de um algoritmo com o ob-jetivo de ajudar na escrita de artigos científicos e os restantes a sua avaliação e posterior integração num editor de texto.
Os resultados obtidos através dos testes objetivos apresentam uma clara aproximação do docu-mento analisado aos docudocu-mentos utilizados para o cálculo das sugestões. No melhor caso, os testes demonstraram que o algoritmo era capaz de recuperar mais de um terço das palavras originais que foram alteradas automaticamente. Isto é uma indicação de que algumas caracte-rísticas linguísticas estão a ser capturadas pelo algoritmo.
Os testes subjetivos apresentaram resultados menos claros, onde, ainda que por pouco, a mai-oria dos sujeitos selecionou mais vezes os parágrafos sem nenhuma das alterações fornecidas pelo algoritmo. Uma possível justificação depara-se com o facto da lista de sugestões utilizada conter todos os candidatos, sem uma seleção prévia dos três mais prováveis. Isto pode ter indu-zido em alterações onde a palavra substituta era menos provável do que aquela já apresentada nos parágrafos originais.
A combinação dos resultados obtidos em ambos os tipos de teste parecem indicar que a utilização do algoritmo pode ajudar a ultrapassar algumas das dificuldades sentidas pelos investigadores aquando da escrita de documentos científicos. No entanto, esta melhoria está dependente da realização de uma análise detalhada das sugestões propostas, tornado este processo moroso e demorado. Como tal, o melhor será talvez recorrer às sugestões apenas em palavras onde o autor tenha dúvidas, diminuindo o esforço necessário mas continuando a beneficiar do seu uso.
Abstract
Nowadays, the results of scientific research are only recognized when published in papers for in-ternational journals or magazines of the respective area of knowledge. This perspective reflects the importance of having the work reviewed by peers. The revision encompasses a thorough analysis on the work performed, including quality of writing and whether the study advances the state-of-the-art, among other details. For these reasons, with the publishing of the docu-ment, other researchers have an assurance of the high quality of the study presented and can, therefore, make direct usage of the findings in their own work. The publishing of documents creates a cycle of information exchange responsible for speeding up the progress behind the development of new techniques, theories and technologies, resulting in added value for the entire society.
Nonetheless, the existence of a detailed revision of the content sent for publication requires additional effort and dedication from its authors. They must make sure that the manuscript is of high quality, since sending a document with mistakes conveys an unprofessional image of the authors, which may result in the rejection at the journal or magazine. The objective of this work is to develop an algorithm capable of assisting in the writing of this type of documents, by proposing suggestions of possible improvements or corrections according to its specific context.
The general idea for the solution proposed is for the algorithm to calculate suggestions of im-provements by comparing the content of the document being written in to that of similar pub-lished documents on the field. In this context, a study on Natural Language Processing (NLP) techniques used in the creation of models for representing the document and its subjects was performed. NLP provides the tools for creating models to represent the documents and identify their topics. The main concepts include n-grams and topic modeling. The study included also an analysis of some works performed in the field of academic writing. The structure and contents of this type of documents, the presentation of some of the characteristics that are common to high quality articles, as well as the tools developed with the objective of helping in its writing were also subject of analysis.
The developed algorithm derives from the combination of several tools backed up by a collection of documents, as well as the logic connecting all components, implemented in the scope of this Master’s. The collection of documents is constituted by full text of articles from different areas, including Computer Science, Physics and Mathematics, among others. The topics of these doc-uments were extracted and stored in order to be fed to the algorithm. By comparing the topics extracted from the document under analysis with those from the documents in the collection, it is possible to select its closest documents, using them for the creation of suggestions. The
algorithm is capable of proposing suggestions for word replacements which are more commonly utilized in a given field of knowledge through a set of tools used in syntactic analysis, synonyms search and morphological realization.
Both objective and subjective tests were conducted on the algorithm. They demonstrate that, in some cases, the algorithm proposes suggestions which approximate the terms used in the doc-ument to the most utilized terms in the state-of-the-art of a defined scientific field. This points towards the idea that the usage of the algorithm should improve the quality of the documents, as they become more similar to the ones already published. Even though the improvements to the documents are minimal, they should be understood as a lower bound for the real utility of the algorithm. This statement is partially justified by the existence of several parsing errors both in the training and test sets, resulting from the parsing of the pdf files from the original articles, which can be improved in a production system.
The main contributions of this work include the presentation of the study performed on the state of the art, the design and implementation of the algorithm and the text editor developed as a proof of concept. The analysis on the specificity of the context, which results from the tests performed on different areas of knowledge, and the large collection of documents, gathered during this Master’s program, are also important contributions of this work.
Keywords
Language Tool, Latent Dirichlet Allocation, LDA, Natural Language Processing, NLP, N-gram, Papers, Quality, Scientific Documents, Suggestions, Wordnet.
Contents
1 Introduction 1
1.1 Motivation and Scope . . . 1
1.2 Problem Statement and Objectives . . . 3
1.3 Adopted Approach for Solving the Problem . . . 3
1.4 Main Contributions . . . 4
1.5 Dissertation Organization . . . 5
2 State of the Art 7 2.1 Introduction . . . 7
2.2 General Language Modeling . . . 7
2.2.1 N-grams . . . 7
2.2.2 Smoothing . . . 10
2.2.3 Performance Evaluation . . . 14
2.3 Topic Modeling . . . 14
2.3.1 Plate Notation and Terminology . . . 15
2.3.2 Generative Probabilistic Topic Modeling . . . 15
2.3.3 Estimation methods . . . 18
2.3.4 Number of Topics and Evaluation . . . 19
2.3.5 Document Comparison . . . 19
2.4 Scientific Text Standards . . . 20
2.4.1 Structure . . . 20
2.4.2 Quality . . . 22
2.4.3 Tools . . . 23
2.5 Conclusion . . . 24
3 Design and Implementation 27 3.1 Introduction . . . 27
3.2 Context and Similar Documents . . . 27
3.3 Corpus . . . 28
3.4 Context Based Suggestions . . . 32
3.4.1 Synonyms . . . 32
3.4.2 N-grams . . . 33
3.4.3 Previous and Next Words . . . 33
3.4.4 Morphological Realization . . . 33
3.5 Used Tools . . . 34 3.5.1 MALLET . . . 34 3.5.2 LanguageTool . . . 35 3.5.3 Wordnet - JWI . . . 35 3.5.4 Stanford Parser . . . 35 3.5.5 Other Tools . . . 36 3.6 Algorithm . . . 36
3.6.1 Context and Similar Documents . . . 36
3.6.2 Sentence Level . . . 37
3.6.3 Word Level . . . 37
3.7 Conclusion . . . 39
4 Tests and Prototype 43 4.1 Introduction . . . 43 4.2 Objective Testing . . . 43 4.2.1 Evaluation . . . 43 4.2.2 Discussion of Results . . . 44 4.2.3 Failed Cases . . . 47 4.3 Subjective Testing . . . 47 4.4 Proof of Concept . . . 50 4.5 Conclusion . . . 52
5 Conclusions and Future Work 53 5.1 Objectives . . . 53
5.2 Results and Conclusions . . . 54
5.3 Future Work . . . 55
Bibliography 57 A Software Engineering 63 A.1 Introduction . . . 63
A.2 Requirement Analysis . . . 63
A.2.1 Functional Requirements . . . 63
A.2.2 Non-functional Requirements . . . 64
A.3 Use Cases . . . 65
A.3.1 Open, Edit and Save Text Files . . . 65
A.3.2 Change Proximity Level . . . 65
A.3.3 Interact with Suggestions . . . 66
A.3.4 Force Analysis . . . 67 xviii
A.4 Activity Diagrams . . . 67
A.5 Class Diagrams . . . 68
B Results 71 B.1 Introduction . . . 71
B.2 Parameters . . . 71
B.3 Objective Tests . . . 71
List of Figures
2.1 Graphical model representation of Probabilistic Latent Semantic Indexing (PLSI). 16
2.2 Graphical model representation of Latent Dirichlet Allocation (LDA). . . 17
2.3 Graphical model representation of Hierarchical Dirichlet Processes (HDP). . . 17
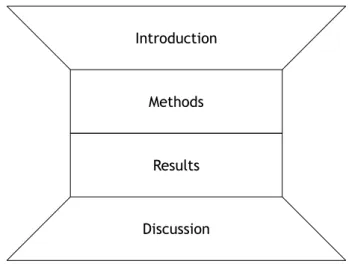
2.4 Representation of the IMRAD organization. . . 22
3.1 Context and Similar Documents sub-algorithm. . . 28
3.2 General procedure to analyze a document. . . 40
4.1 Screenshot of the text editor developed in the scope of this project. . . 51
A.1 Representation of the use case for opening, editing and saving files. . . 65
A.2 Representation of the use case for changing the proximity level of similar docu-ments. . . 66
A.3 The use case for the user interaction with a suggestion. . . 66
A.4 A representation of the use case for forcing an analysis. . . 67
A.5 Activity diagram representative of the activities responsible for the main functions provided by the system. . . 68
A.6 Class diagram for the system from an implementation perspective. . . 70
B.1 Probability of the Computer Science and Mathematics validation sets for different number of topics. . . 71
List of Tables
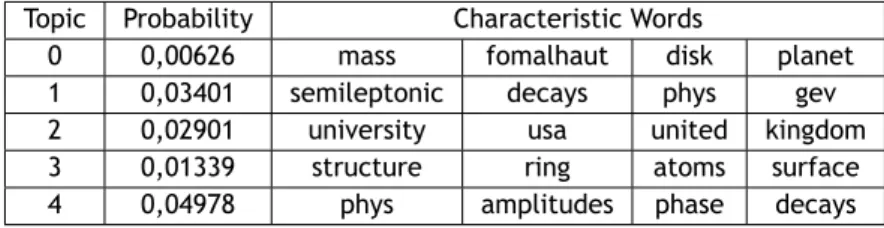
3.1 Document distribution for each area of knowledge in the corpus. . . 30 3.2 N-grams obtained from the Example 4. . . 31 3.3 Example of five topics extracted from the physics documents of the corpus. . . . 34 3.4 N-grams obtained from the Example 8. . . 38 4.1 Results for the tests with 1030 documents from Mathematics using themath table,
with a document threshold of 6.0. . . . 45 4.2 Results for the tests with 1103 documents from Computer Science using thecsTotal
table. . . 46 4.3 Results for 1031 documents from Mathematics using the3gram table. . . 46 4.4 Results for 1031 documents from Mathematics using thecsCut table. . . 46 4.5 Summary of the results for the automatic tests. . . 47 4.6 Results for the subjective testing of the suggestions proposed by the algorithm. . 50 A.1 A description of the use case for opening, editing and saving files. . . 65 A.2 Description of the use case for changing the proximity level of similar documents. 66 A.3 Description of the user interaction with a suggestion. . . 67 A.4 Description of the use case for forcing a new analysis . . . 67 A.5 Description of the main activity diagram. . . 68 B.1 Results for the tests with 1104 documents from Computer Science using the cs
table. . . 72 B.2 Results for the tests with 1103 documents from Computer Science using thecsTotal
table. . . 72 B.3 Results for the tests with 1103 documents from Computer Science using thecsCut
table. . . 72 B.4 Results for the tests with 1103 documents from Computer Science using themath
table. . . 72 B.5 Results for the tests with 1105 documents from Computer Science using themathTotal
table. . . 72 B.6 Results for the tests with 1103 documents from Computer Science using themathCut
table. . . 72 B.7 Results for the tests with 1103 documents from Computer Science using the3gram
table. . . 72 B.8 Results for the tests with 1029 documents from Mathematics using the cs table.
B.9 Results for the tests with 1031 documents from Mathematics using thecsTotal table. . . 73 B.10 Results for the tests with 1031 documents from Mathematics using thecsCut table. 73 B.11 Results for the tests with 1030 documents from Mathematics using themath table.
with a document threshold of 6.0. . . . 73 B.12 Results for the tests with 1033 documents from Mathematics using themath table.
with a document threshold of 5.0. . . . 73 B.13 Results for the tests with 1033 documents from Mathematics using themath table.
with a document threshold of 4.0. . . . 73 B.14 Results for the tests with 1035 documents from Mathematics using themath table.
with a document threshold of 3.0. . . . 73 B.15 Results for the tests with 1030 documents from Mathematics using themathTotal
table. . . 74 B.16 Results for the tests with 1029 documents from Mathematics using themathCut
table. . . 74 B.17 Results for the tests with 1031 documents from Mathematics using the3gram table. 74
Acronyms
ACM Association for Computing Machinery
AES Automatic Essay Scoring
API Application Programming Interface
CARS Create A Research Space
CCS Computing Classification System
COCA Corpus of Contemporary American English
DBMS Database Management System
DP Dirichlet Process
EM Expectation Maximization
HDP Hierarchical Dirichlet Processes
HTML5 HyperText Markup Language 5
IMRAD Introduction Methods Results and Discussion
JWI Java Wordnet Interface
KL Kullback Leibler
LDA Latent Dirichlet Allocation
MALLET MAchine Learning for LanguagE Toolkit MCMC Monte Carlo Markov Chain
MIT Massachusetts Institute of Technology
ML Maximum Likelihood
MRR Mean Reciprocal Rank
NLP Natural Language Processing
OS Operating System
PEG Project Essay Grade
PLSI Probabilistic Latent Semantic Indexing
TEM Tempered Expectation Maximization
TNG Topical N-Gram
UBI Universidade da Beira Interior
XIP Xerox Incremental Parser
Nomenclature
DT Determiner
IN Preposition or subordinating conjunction
JJ Adjective
NN Noun, singular or mass
NNS Noun, plural
NNP Proper noun, singular
VBG Verb, gerund or present participle VBN Verb, past participle
VBP Verb, non-3rd person singular present VBZ Verb, 3rd person singular present WDT Wh-determiner
Chapter 1
Introduction
This document concerns the work performed under the scope of the project for attaining a Master’s degree in Computer Science and Engineering at the Universidade da Beira Interior (UBI). The main subject of the dissertation is the study and development of an algorithm to assist in the writing of scientific documents. As a proof of concept, the implementation of the algorithm was included in a very simple text editing tool, analyzed later in the document. The subsequent sections of the chapter describe the scope of this dissertation, the motivation that led to the realization of the project, the associated problem and the fundamental objectives. Afterwards, the chapter includes a description of the adopted approach, main contributions and a section with the organization of the remaining parts of the document.
1.1
Motivation and Scope
Societies evolve through the creation, gathering and use of knowledge. This knowledge can then be levered to create tools and develop ideas that sometimes improve quality of life. The main point of origin for this knowledge is the scientific community and its experiments, which are performed with the goal of testing an idea, proving a theoretical result, searching for new algorithms, tools or novel adaptations for using old tools, among others. When an experiment presents promissory results, a scientific paper describing the main findings, ideas and proce-dures that led to such development is written and submitted to scrutiny. By submitting these documents to scientific journals and magazines of the area, the work gets analyzed by scientific committees that verify the novelty, scientific correctness, and quality of writing of the proposed text. If accepted, the publication results in the sharing of the experiment with the remaining scientific community, allowing for other investigators to work on those findings and improving that work, or taking inspiration for new developments in that or different areas. This process results in a cycle of information sharing responsible for speeding up the progress of science and ensuring the correctness of the work performed.
“Research writing is classified as a type of academic writing. Therefore, it is considered for-mal writing.” [NSH12]. Learning to write in this context is a challenging task [RKEO15], since there are many important factors that should be thoroughly considered, including the selec-tion of appropriate vocabulary, correct use of grammar and following a strict writing struc-ture. These factors and the writing of persuasive arguments, necessary for effectively con-veying information, are specially hard for beginners [UU15, LS15] and non-native English
re-searchers [NSH12, CK11, LS15].
Since the time humans realized the true potential of computers to these days, we have been restricted to a set of predefined interactions with machines. These interactions are usually per-formed through the selection of options or done by the introduction of very specific instructions. Deviating from these interactions results in failing to perform the desired actions. The objec-tive of Natural Language Processing is to retrieve information from a natural language input. In theory, this could allow a user to introduce text or speak to a machine, without restrictions, and the machine would be capable of identifying the intention of the user and responding accord-ingly. This scenario would provide users with major improvements both in terms of comfort as well as effectiveness in terms of response. These serve as motivation for abundant researches and studies in this area, each tackling a different task, including analysis on the semantic and extraction of the syntactic structure of an input. However, due to the complexity inherent to the study of natural languages, the creation of a model capable of capturing a natural language in its entirety is still an utopia, continuing limited to smaller tasks. Polisemy, which is the pos-sibility of words having more than one meaning, depending on the context, and ambiguity of interpretation are just some examples of problems that investigators have to face in this field of expertise, justifying the limitations in progress made so far.
In this context and while fully understanding natural language is still just an idea, suggestions have been introduced as a way of improving humans interaction both in speed and efficiency, as in the cases of word completion and prediction available in most mobile devices [vdBB08]. Their utilization can also impact effectiveness, by providing users with what they most likely need or want, as is the case of search engines. These advantages have molded the human mind into accepting suggestions as a beneficial tool for their interactions, paving the way for new tools and technologies that implement this sort of techniques.
The aforementioned reasons are on the basis of the proposal for the development of an algo-rithm designed to provide the user with suggestions for improvements in academic texts. The suggestions should include corrections for grammatical errors, such as orthographic errors, syn-tax and semantics, already provided by some tools. Nonetheless, the main focus of this work concerns the misuse of terms in a specific field of knowledge. This algorithm, and its inher-ent study, should improve the understanding on the specificity of the syntactic structures in academic writing.
The area that best describes the scope of this Computer Science and Engineering Master’s project is natural language processing, as it focuses on presenting suggestions for possible improvements to the text being written in the academic field. Under the 2012 version of the ACM Computing Classification System (CCS), the de facto standard for Computer Science, the scope of this dis-sertation can be described by the following topics:
• Computing methodologies~Natural language processing; • Information systems~Language models;
• Information systems~Document topic models; • Applied computing~Text editing.
1.2
Problem Statement and Objectives
The problem addressed in this dissertation is closely related with the difficulties that investi-gators have to face when writing scientific documents. A major difficulty is ensuring that a sentence conveys the exact meaning the author intends to. Since natural languages are in-trinsically ambiguous and imprecise, words can have multiple interpretations depending on the context. Correctly selecting the appropriate words requires experience and knowledge on the language being used. This knowledge is something most non-native English speakers lack, mak-ing them more susceptible to incorrectly select words which have a meanmak-ing that, in the given context, is different from the one intended.
The terminology is yet another difficulty faced when entering a new area of expertise. Each area makes use of specialized terms and expressions, which are used in detriment of others with a similar meaning. These words and expressions evolved alongside the area, and now provide a very specific meaning, which is difficult to express in a different way. Failing to use them creates inconsistent manuscripts, hardly publishable or accepted by other investigators, since they transmit the image of an unprofessional investigation.
Given the problem statement, the main objectives proposed for this dissertation are:
1. The development of an algorithm for assisting the writing of scientific documents. The algorithm can be divided into two sub-algorithms: one should be capable of identifying the context of a document and searching for related sources; and the second should cre-ate suggestions for term replacement and correction of text, according to the context recovered by the first one;
2. The next objective is the evaluation of the performance and fine tuning of the algorithm; 3. The final objective serves as a proof of concept, which is the development of a simple text
editing tool with the integration of the aforementioned algorithm.
1.3
Adopted Approach for Solving the Problem
The approach taken to solve this problem and meeting the objectives, included the following steps:
1. The first step was to study the state of the art, including NLP concepts, techniques and technologies. This was followed by a study into the specific area of academic writing, analyzing the work of other investigators and gathering the knowledge which could be levered for the current research;
2. The study mentioned in the previous step, allowed for a better understanding on which techniques and technologies could be used for each of the desired purposes. With this knowledge, the design of the algorithm became the next step;
3. Both the language modeling and the topics modeling, used in the extraction of the context of a document, required a corpus of scientific documents. To fulfill this need the next step became the search for a corpus with the desired characteristics;
4. After a thorough search without obtaining a viable corpus, an alternative procedure con-sisting of gathering enough documents for the creation of a corpus that could fit the spe-cific needs of this work was pursued;
5. With the corpus complete, the next step was to study the extraction of n-grams from the collection of scientific papers, and, subsequently, to calculate and store the extracted n-grams;
6. The exploration of tools that implemented the techniques and technologies defined in the design of the algorithm formed the next steps;
7. The remaining step for completing the implementation of the algorithm was the combina-tion of all the selected tools;
8. The eighth step was the testing and, after analyzing the results, fine-tunning of the algo-rithm;
9. The next to last step consisted on the software engineering process for the implementation of a text editor that would integrate the developed algorithm;
10. The final step was the implementation of the text editor with the inclusion of simple functions common to most text editors.
1.4
Main Contributions
The work and research performed within the context of this project resulted in a set of contri-butions for the advance of scientific knowledge, which can be summarized as follows:
• The first contribution is the presentation of a brief study on the related work. This study features general concepts related to NLP theory and techniques, including a discussion about n-grams and smoothing techniques. A second section presents topic modeling algo-rithms used in the extraction of topics from a collection of documents. Given the nature 4
of the dissertation the study then shifts to the specific realm of academic writing, with a more refined development;
• The sub-algorithm developed for the identification of a context and finding related sources and the sub-algorithm that calculates suggestions, according to the defined context, are another important contribution. The complete source code of the text editing tool will be open source, allowing for the study and improvement of the algorithm by the community; • The delivery of an application capable of assisting the users in the writing of scientific documents with some success, integrating the aforementioned algorithm, constitutes a contribution as well;
• The combination and analysis of the results provided by a system formed with several known techniques and tools for NLP is not described in the literature, to the best of the knowledge of the author;
• After the development of the algorithm, test suites were created with the purpose of refining the results. The tests suites included tests on a variety of tables, with n-grams extracted from different subsets of English. The aforementioned tables comprised: a table with one million of the most frequent trigrams from generic English, from the Corpus of Contemporary American English (COCA); and one set of tables for each of the contemplated disciplines, with the n-grams from the respective documents. The variety of contexts presented in the tables allowed studying the importance of the specificity of the context on academic writing.
The corpus of scientific documents is another contribution that resulted as a bi-product of this work. During the planning phase it became clear that the extraction of context from a docu-ment was necessary for providing appropriate suggestions. The use of topic modeling for this purpose required a corpus of scientific documents for the creation of topics. An extensive search for existing corpus proved unfruitful when the only corpus found, with the desired character-istics, SciTex [DOKLK+13], was unavailable for download. The solution followed was to create
a corpus by gathering documents from the electronic archive, arXiv [Lib98]. The corpus fol-lows an approximation to an uniform distribution over the areas contemplated, including over thirty thousand scientific documents from Computer Science, Mathematics, Physics, Statistics, Quantitative Biology and Quantitative Finance.
1.5
Dissertation Organization
The dissertation is divided into five main chapters and two appendices. Their contents can be briefly described as follows:
devel-opment of this work, the problem to be addressed and the proposed objectives. These sections are followed by the adopted approach for solving the problem, the main contri-butions to the advance of knowledge and the document organization;
• Chapter 2 — State of the art — presents concepts and techniques related to NLP. It then focuses on presenting some of the work done in the specific area of academic writing. A comparative analysis on similar tools and their functionalities is also included in this chapter;
• Chapter 3 —Design and Implementation — presents the developed algorithm, the com-ponents involved and how they interact with each other. The corpus is yet another subject contained within this chapter;
• Chapter 4 —Tests and Prototype — contains the specification of the tests performed to evaluate the algorithm and the discussion of the respective results. These are divided into objective and subjective test sets. The remaining parts of the chapter introduce the text editing tool and describes its functioning;
• Chapter 5 —Conclusions and Future Work — discusses the results, analyses the objectives that were accomplished, and presents some of the reasons that justify those that were not met. The chapter then concludes with the description of a small set of features and improvements that could be used to extend and improve this work;
• Appendix A — Software Engineering — describes the process of software engineering followed in the development of the text editing tool, used as a proof of concept for the developed algorithm. The appendix includes the requirement specification, use cases and both activity and class diagrams;
• Appendix B —Results — presents the results for all the tests performed on the algorithm, and the resulting sections used in the subjective testing.
Chapter 2
State of the Art
2.1
Introduction
This chapter presents the main methods and techniques related with this work. Helping authors achieve a high standard quality in terms of the linguistic constructions used was the primary con-cern and motivation for this work. Therefore, a study on NLP related issues, such as language
modeling and topic modeling, is presented along with its corresponding importance duly
justi-fied. The chapter starts with a general study on NLP, namely language modeling (Section 2.2). It then proceeds with the description of techniques used in topic modeling (Section 2.3) and with a study focused on scientific text standards (Section 2.4).
2.2
General Language Modeling
Language Modeling concerns mainly the knowledge and usage of language patterns in human lan-guage, which is a dynamic phenomenon, constantly evolving through time [Vog00]. For instance, the Portuguese language used by Luís de Camões, or the English language from William Shake-speare, are substantially different from their contemporary versions. Language is a communi-cation protocol grounded by social convention and community agreement. Language evolves over time. Even in a given time period, different language patterns are employed in different text genres, as one can easily recognize by comparing texts from soap operas with scientific texts. Even within the scientific domain, there are variations where different stylistic features and sentence patterns are more likely employed in certain areas than others. This work is es-pecially focused on the study and use of the linguistic features characterizing scientific text production, in order to assist an author in his or her work. The information presented in this section is primarily based on [CG96, JM00], following a similar structure and presentation.
2.2.1
N-grams
In general, language modeling is grounded on discovering the probability of a sequence of words in a predefined context. Considering a sentence s constituted of l words (w1w2. . . wl), by
fol-lowing the chain rule of probability, one could calculate the joint probability with:
P(s) = P(w1)P(w2|w1)P(w3|w1w2) . . .P(wl|w1. . . wl−1) = l
∏
i=1
which represents theP(s) as the product of the conditional probability of each word given every previous word.
Due to the practical difficulties in calculating the probability of every sequence necessary in the computation of larger sequences of text using Equation 2.1, a simplification was created based on the Markov Assumption [JM00]. The Markov Assumption determines that the probability of a future event (word) can be predicted by its nearest past, instead of its full past [JM00]. With this assumption, one may calculate the probability of a bigger sequence resorting only to the
n− 1 words previous to each word, instead of using all the previous words. These sequences of
nwords (wi plus the n− 1 previous words) used in the calculation of the probability of bigger
sequences are called n-grams, presenting the most widely-used language models [CG96] (where
nis the order of the model). The adaptation of Equation 2.1 with the use of n-grams is:
P(s) ≈
l
∏
i=n
P(wi|wi−n+1. . . wi−1). (2.2)
In Equation 2.2, i starts at n because n-grams are being used and, as such, an n-gram needs n−1 previous words, which do not exist before word n. To calculate the probability of a sentence starting with i = 1, one could consider the existence of n − 1 special words preceding the sentence. For similar reasons one may also consider adding special words after the sentence. In this context, word sequences of the type w1w2. . . wlare usually represented as wl1.
Given that with each operation the probability tends to reduce, using the Equation 2.2 in real situations would easily result in underflow. Considering the computational limitations, the prob-ability of an expression is usually calculated by the sum of the logarithm of the probprob-ability of each of its n-grams as in:
log(P(s)) ≈
l
∑
i=1
log(P(wi|wii−n+1−1 )). (2.3)
With Equation 2.3, one can compute the probability of large sequences of text based on the probability of n-grams, but notice that the definition of how to compute the probability of an n-gram was not yet presented. The probability of a given n-gram can be estimated by dividing the count of that n-gram in a collection (corpus) of texts by the count of its prefixed (n-1)-gram, previously computed [JM00], as in:
P(wi|wii−n+1−1 ) =
c(wi i−n+1)
c(wii−1−n+1), (2.4)
where c(wii−n+1−1 )is the count of the times the previous words occur in the corpus. This value is more commonly represented by ∑w
ic(w
i
i−n+1), in the sense that it can be the sum of the
counts for all n-grams where the previous words are wii−n+1−1 , with the advantage that this will 8
work even for unigrams. This form of estimation is called the Maximum Likelihood (ML), because it provides the highest possible probability for the data that appeared on the corpus (the training data) [CG96].
One is now capable of computing the probability of any sequence of text. As a toy example1,
consider that the text in Example 1 is the corpus and that the objective is to calculate the probability of the second sentence (They live in New York.) using trigrams (n-grams where
n = 3).
Example 1. We live in San Francisco, more precisely near San Francisco bay. They live in New York.
Their parents live outside, in the middle of the jungle.
Using Equation 2.2 the probability of the sentence can be written as:
P(s) = P(”in”|”T hey” ”live”)P(”New”|”live” ”in”)P(”Y ork”|”in” ”New”), whose individual values can be obtained resorting to Equation 2.4, as follows:
P(”in”|”T hey” ”live”) = c(”T hey live in”)
c(”T hey live”) = 1 1 = 1,
P(”New”|”live” ”in”) =c(”live in N ew”)
c(”live in”) = 1 2 = 0.5, P(”Y ork”|”in” ”New”) =c(”in N ew Y ork”)
c(”in N ew”) = 1 1 = 1. Replacing those values in the equation, the result is:
P(”T hey live in New Y ork.”)) = 1 ∗ 0.5 ∗ 1 = 0.5.
The n-gram probabilities are modeled from a training corpus, which makes the corpus a very important subject of study. Using a corpus too specific for the calculations may lead to failing to generalize the grams for new sentences. On the other hand, if the corpus is too broad, the n-grams may not capture the specificity of the domain one might be interested in modeling [JM00].
Even though language modeling through n-grams is a somewhat simple process, there are details that need to be adjusted depending on the context. Punctuation is one such example. Whether punctuation should be represented in the n-grams, or simply ignored, is highly dependent on the context. Author-identification and spelling error detection are just some of the examples where punctuation is fundamental to the process. The decision of whether the capture of n-grams
1
should be done in a case sensitive fashion, or not, is yet another important detail that needs to be accounted for. The representation of each word form of the same abstraction, separately or together, as for instancecat and cats, should also be considered given the resulting impact of such change [JM00].
2.2.2
Smoothing
The fact that the n-grams are calculated from a finite corpus results in many cases of n-grams which do not get represented, thus obtaining a probability of zero when they should not. This problem is called data sparsity.
Smoothing is a process used to assign a value to some of the n-grams with zero probability, re-evaluating and adjusting the probability of others with low and high incidence [JM00]. The simplest case of smoothing is the Add-One smoothing, which is the addition of one to the count of each n-gram in order to prevent n-grams from having zero probability. With these changes applied to Equation 2.4 the result is:
Padd(wi|wii−1−n+1) = 1 + c(wi i−n+1) |V | +∑wic(w i i−n+1) , (2.5) where wi
i−n+1are all the words from the n-gram. Adding one to the count of each n-gram would
result in an increase of the total probability of n-grams, which is balanced by adding|V | in the denominator. V denotes the vocabulary containing all the words that should be considered, and
|V | is the number of words in the vocabulary. Once again, considering that Example 1 is the
corpus, using the ML to estimate the probabilities of the 2-gramsin live and in middle would result in 0, while using Equation 2.5:
Padd(”live”|”in”) =
1 + c(”in live”) |V | + c(”in”) = 1 + 0 19 + 3= 1 23 = 1/22and
Padd(”middle”|”in”) =
1 + c(”in middle”) |V | + c(”in”) = 1 + 0 19 + 3 = 1 22 = 1/23.
This particular case of smoothing is actually worse than not using smoothing at all [JM00], mainly due to the fact that adding one to each n-gram represents a significant change in the mass, removing weight from the most important cases.
When the existing information on some n-gram is insufficient, resorting to lower order models might provide useful information on the higher order models [CG96]. Following upon this idea, some smoothing techniques use, for instance (n-1)-grams to help estimate the probability of some n-grams. This can be applied recursively, using the probability of (n-2)-grams to help estimate the probability of (n-1)-grams, and so on. There are two ways of resorting to this n-gram hierarchy [JM00], interpolation or backof. In the case of interpolation, the information
from the hierarchy is always used to estimate the probability of an n-gram as follows: Pinterp(wi|wii−1−n+1) = λP(wi|wii−n+1−1 ) + (1− λ)Pinterp(wi|wii−n+2−1 ). (2.6)
Interpolation continues until it reaches the unigram case, which is directly calculated from its probability. The value of λ≤ 1 is obtained from the training on held out data. Instead of using a single value for all n-grams, a specific value of λ for each (n-1)-gram (λwi−1
i−n+1) could provide a more refined calculation of the probability. However, training each individual value would require a large amount of data and, as such, in most cases, buckets are created, attributing the same values of λ to groups of n-grams.
As for backof, it only resorts to the hierarchy when the count for the n-gram is zero, which results in: P(wi|wii−n+1−1 ) = P(wi|wii−1−n+1), if P(wi|wii−1−n+1) > 0 α1P(wi|wii−1−n+2), if P(wi|wii−1−n+1) = 0 andP(wi|wii−1−n+2) > 0 .. . αn−1P(wi), otherwise, (2.7)
where the α values ensure that the probability distribution does not sum to more than one.
Jelinek-Mercer smoothing is the simple application of interpolation to the ML. Considering
once again that Example 1 is the corpus, one can estimate the probabilities of the same 2-grams in live and in middle, using Equation 2.6 with, for example λ = 0.5:
PJ M(”live”|”in”) = λPM L(”live”|”in”) + (1 − λ)PJ M(”live”) = 0.5∗ 0 + (1 − 0.5) ∗
3
26 = 3/52and PJ M(”middle”|”in”) = λPM L(”middle”|”in”)+(1−λ)PJ M(”middle”) = 0.5∗0+(1−0.5)∗
1
26 = 1/52, unlike the results using Add-one, this timein live receives a higher probability than in middle even without any of the sequences ever appearing on the corpus. This is a reflection of the higher number of occurrences oflive when compared to middle.
Absolute discounting also uses interpolation, but instead of multiplying the probability of the
n-gram by λ (or λwi−1
i−n+1) it subtracts a fixed discount D≤ 1 from each non zero count, resulting in: Pabs(wi|wii−1−n+1) = max{c(wi i−n+1)− D, 0} ∑ wic(w i i−n+1) + (1− λwi−1 i−n+1)Pabs(wi|w i−1 i−n+2), (2.8)
in which 1− λwi−1
i−n+1 is calculated from:
1− λwi−1 i−n+1 = D ∑ wic(w i i−n+1) N1+(wii−n+1−1 •), (2.9)
to ensure that the sum of the distribution is one. N1+(wii−1−n+1•) is the number of unique words
that follow the left context (or history (wi−1
i−n+1)) of the n-gram, formally defined as:
N1+(wii−1−n+1•) = |{wi: c(wii−n+1−1 wi) > 0}|, (2.10)
where the N1+denotes the number of words that have one or more counts, and the• a variable
that is summed over.
The value of D in Equation 2.8 is calculated from:
D = n1
n1+ 2n2
, (2.11)
where n1and n2denote the total number of n-grams with the count of one and two, respectively,
in the training data.
Kneser-Ney smoothing is an extension to the absolute discounting, based on the idea that
the probability of an n-gram should not be proportional to the number of occurrences, but proportional to the number of words it follows. Kneser-Ney smoothing formula uses backof and it can be calculated by:
PKN(wi|wii−1−n+1) = max{c(wi i−n+1)−D,0} ∑ wic(wii−n+1) , if c(w i i−n+1) > 0 γ(wii−1−n+1)PKN(wi|wii−1−n+2), if c(wii−n+1) = 0 , (2.12) where γ(wi−1
i−n+1)is chosen to make the distribution sum to one, using the right hand side from
Equation 2.9. For the case of the unigram: PKN(wi) =
N1+(•wi)
N1+(••)
, (2.13)
where N1+(•wi) is the number of words that appear in the corpus before the word wi, and
N1+(••) being the number of bigrams in the corpus. If Example 1 is the corpus and one wants
to estimate the probability of the 2-gramslive San and live Francisco using Equation 2.13, and given that neither of them appears the corpus (c(wi
i−n+1) = 0):
PKN(”San”|”live”) = γ(”live”)PKN(”San”),
where:
γ(”live”) = D
c(”live”)N1+(”live”•), 12
where: D = n1 n1+ 2n2 = 19 19 + 2∗ 2 = 19 23 = 19/23,
with n1 and n2 being the number of bigrams with count one and two, respectively. For the
calculation concerning the unigram, one should use:
PKN(”San”) = N1+(•”San”) N1+(••) = 2 21 = 2/21. Wrapping up everything: γ(”live”) = 19/23 3 ∗ 2 = 19∗ 2 23∗ 3 = 38/69, and finally:
PKN(”San”|”live”) = γ(”live”)PKN(”San”) = (38/69)(2/21)≈ 0.052.
For thelive Francisco 2-gram the calculation is similar:
PKN(”F rancisco”|”live”) = γ(”live”)PKN(”F rancisco”),
where: PKN(”F rancisco”) = N1+(•”F rancisco”) N1+(••) = 1 21 = 1/21, resulting in:
PKN(”F rancisco”|”live”) = γ(”live”)PKN(”F rancisco”) = (38/69)(1/21)≈ 0.026.
The only difference between the two n-grams is the second word and both words appear the same number of times in the corpus. Nonetheless,San is the successor of two different words whileFrancisco only follows one (San), justifying the obtained values.
Chen and Goodman [CG96] introduced a modified version of Kneser-Ney smoothing with three major differences:
• interpolation is used instead of backof;
• three discounts are used, one for counts of one, another one for counts of two and the third one for every other counts;
• discounts are estimated on held out data, instead of using a formula based on the training data (as in Equation 2.11).
which allow for a better understanding of the modified version Kneser-Ney smoothing provided that it is the one with the best performance [CG96]. Nonetheless, there is another version of the Kneser-Ney modified, in which the discounts are once more calculated from the formula used in the original algorithm on the training data, avoiding the optimization of these parameters with only a slight drop in performance [CG96].
There are other techniques with the purpose of solving the problem with sparse data besides smoothing. However, techniques such as word classing and decision-tree models assume the use of language models different from n-grams [CG96]. Given that the most common language model and the one used in this work are n-grams, these methods will not be further described or explained.
2.2.3
Performance Evaluation
Evaluating the performance of a language model means measuring how well the computed model represents the data under analysis. The most common metrics used for evaluating the perfor-mance of a language model are the probability, cross-entropy and perplexity. They are usually calculated on a set of held out test data [CG96]. The probability of a set of data is simply the product of the probability of all sentences in the set.
The cross entropy can be measured using:
Hp(T ) =−
1
WT
log2p(T ), (2.14)
where WT is the number of words of a text T and the result can be interpreted as the average
number of bits need to encode each word from the test data.
As for the perplexity (P Pp(T )), it can be calculated using Equation 2.15:
P Pp(T ) = 2Hp(T ). (2.15)
Models with lower cross entropies and perplexities are better. Depending on the type of text, cross entropies can be between 6 and 10 bits/word for English texts, corresponding to values of perplexity between 50 and 1000. [CG96].
2.3
Topic Modeling
Topic modeling algorithms are statistical methods that are used with the objective of finding the subjects (or topics) presented in a collection of documents [Ble12]. These algorithms resort to the words of each document, and the topics at which they are most commonly associated
with. For this reason, the analysis usually ignores the words belonging to a stop-words list2.
With the analysis complete, the result is a distribution over the topics for each document in the collection. Even though the topics associated with each document are the same, the differences between the probabilities in each distribution allow for a characterization of each document by its most probable topics.
The resulting distribution over the topics is a representation of the document in what is known as the latent semantic space. This representation presents a dimensionality reduction, when compared to the term frequencies vector, which is capable of more easily capturing the differ-ences and similarities between documents in a collection [Hof99b]. The idea “is that documents which share more frequently co-occurring terms will have a similar representation” [Hof99b] (distribution), even if they have no terms in common.
Topic modeling is used in this work with the objective of finding similar documents to the one being written, and then using their content to calculate suggestions of improvements.
2.3.1
Plate Notation and Terminology
Topic modeling formally defines: a word as the basic unit of data, an item from a vocabulary; a document as a sequence of N words; and a corpus as a collection of D documents [BNJ03].
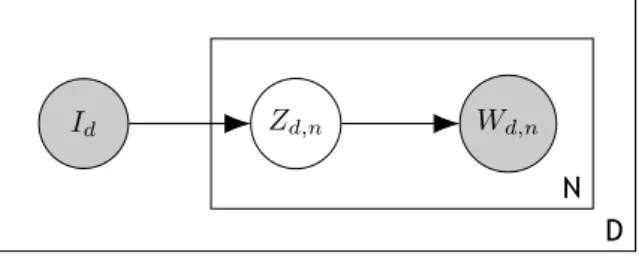
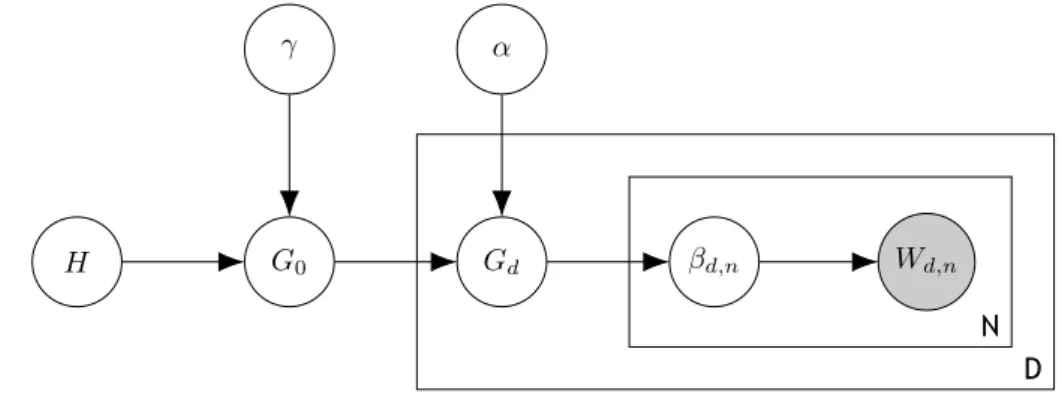
Plate notation is a graphical model for simplifying the process of representing variables that repeat themselves and their interdependencies (example in Figure 2.1). Each rectangle (or plate) groups a set of variables (circles) that are repeated, in the same context, a predefined number of times (in the case of both Zd,nand Wd,n, at Figure 2.1, they are repeated N times).
The color of the circle represents the visibility of the variable: white circles are hidden variables, while gray circles are observed variables. Each link that connects two variables represents a dependency. For instance, in Figure 2.1 Wd,n depends on Zd,n and Zd,ndepends on Id. When a
link crosses the border of a plate it means that the variable on the outside is connected to each of the instances of the variable on the inside (Idconnects to each Zd,i, i∈ [1, N]).
2.3.2
Generative Probabilistic Topic Modeling
Generative probabilistic topic modeling is a group of algorithms that find topics by considering that each document in the collection is created by a process called the generative process. This process considers the existence of a latent structure, also known as hidden. The objective of this set of algorithms is then to reconstruct the structure, resorting to the observed variables which are, in most cases, the words of each document in the collection. As for the hidden structure, it is composed of (latent) variables that vary from model to model but, that generally include a probability distribution over topics, when the model considers each document a mixture of topics, representing the possibility of each document depicting more than one topic. This
pro-2