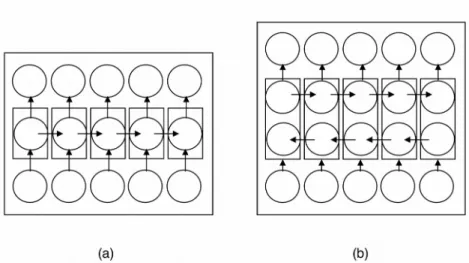
An important aspect currently missing is the identification of legislative modifications and their semantic components. In this dissertation we present an automated solution based on deep learning, in particular the BiLSTM architecture.
INTRODUCTION
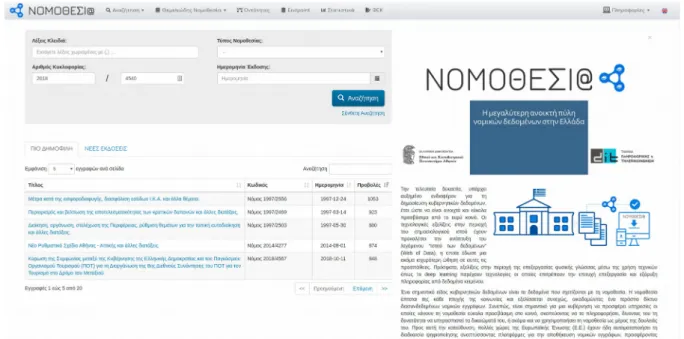
The European Union, in recognition of this growing need, created the European Legislation Identifier (ELI) 5 , a system for digital distribution of European legislation in a standardized format so that it can be accessed, exchanged and reused within all member states . ΝΟΜΟΘΕΣΙ@ inherits the ontology developed for ELI and aims to bring the same benefits to Greek law as well [4]. Every legal system in active use must evolve over time to keep pace with changes in the goals, social norms, or material conditions of the society for which it was written.
In the Greek legislative system, as well as in many other republics, there is no specific defined process to allow this. This makes the automatic recognition of legal amendments a non-trivial problem, and necessitates the development of specialized software. It is our goal in this thesis to present one such automated system that can recognize and annotate salient component parts of modifications with a sufficiently large success rate for useful application.
In this chapter we explained what problem we are trying to solve and why a solution would be valuable. In the next chapter we will define some fundamental concepts, summarize the work done in the field of computer science in solving similar problems, and describe the technological framework on which our project will be based.
PRIOR WORK
Background
- NLP
- Machine Learning
- Neural Networks
- Deep Neural Networks
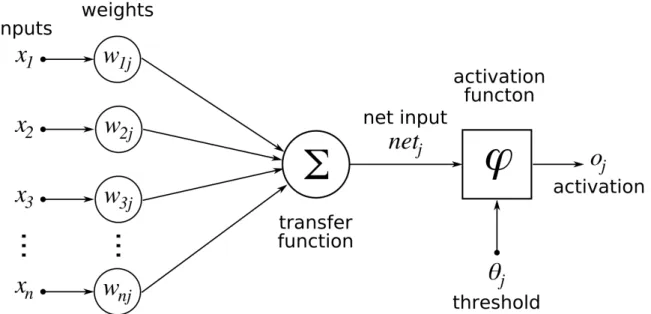
The result of the activation function is the output of the neuron, which can then be multiplied by a corresponding weight and propagated as input to one or more other neurons. By stacking several layers of such artificial neurons into a network and manipulating the weight of each input through a training process, we can create autonomous systems that can be used in a wide range of problems. In recent years, the increase in computing power has enabled the development of large, complex and multi-layer neural networks that enable a qualitative shift in their potential and range of applications.
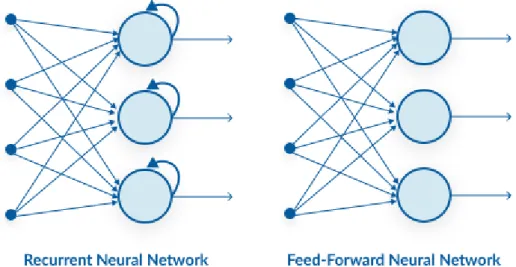
The two most common types of deep neural networks are convolutional neural networks (CNNs), which are mostly used in image processing, and recursive neural networks (RNNs), which are particularly suited to processing discrete-time signals such as natural language texts.
Neural Network Concepts
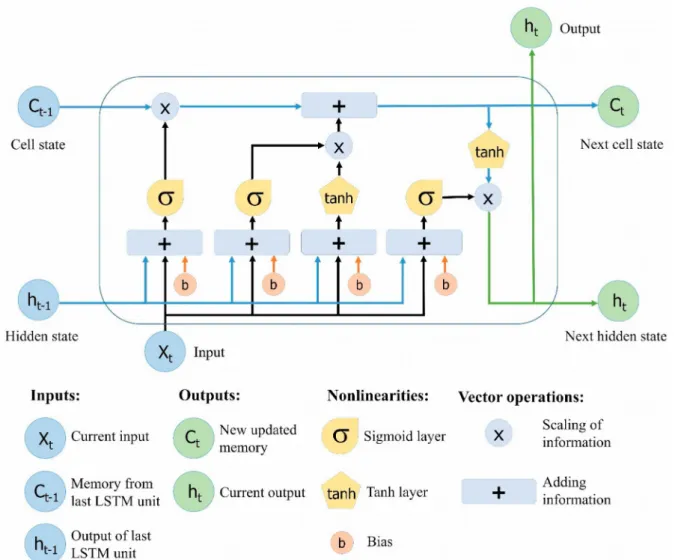
- LSTM
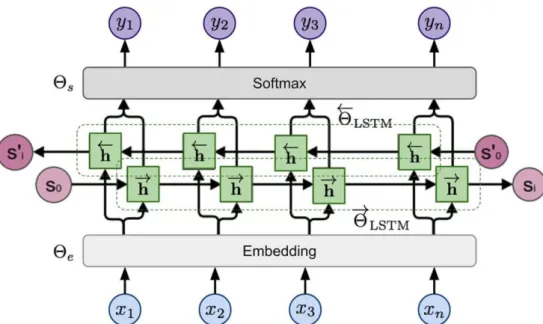
- BiLSTM
- Loss Functions
- Optimizers
- Gradient descent
- Batch gradient descent
- Stochastic gradient descent
- Mini-batch gradient descent
- Backpropagation
- Evaluation metrics
In this thesis, we will construct a BiLSTM-based deep neural network to fulfill our task, the annotation of the structural elements of Greek law changes, which we will specify in the following chapter. Typically, a loss function acts as a distance function that compares the output of the network to the correct output that has been annotated earlier during the creation of the training set. Through the optimization algorithm, the weight of the neural network is properly adjusted so that this distance is minimized.
Optimization algorithms (optimizers) help us minimize (or maximize) an objective function. This is a function that depends on the different trainable parameters of the model. Gradient descent is one of the most popular algorithms to perform optimization and by far the most common way to optimize neural networks. At the same time, every state-of-the-art Deep Learning library contains implementations of different algorithms to optimize gradient descent (e.g. lasagna's 6 , caffe's 7 and keras' 8 documentation).
Gradient descent is a method of minimizing an objective function parameterized by model variables by updating those variables in the opposite direction of the gradient of the objective function. The learning rate determines the size of the steps we take to reach the (local) minimum. There are three versions of gradient descent that differ in how much data is used to calculate the gradient of the objective function.
Depending on the amount of data, we make a trade-off between the accuracy of the parameter update and the time it takes to perform an update [13] [14]. The first variant, batch gradient descent (BGD), also known as vanilla gradient descent, calculates the gradient of the cost function with respect to the parameters of the entire data set. While batch gradient descent converges to the minimum of the basin the parameters are placed in, on the one hand, SGD's fluctuation enables it to jump to new and potentially better local minima.
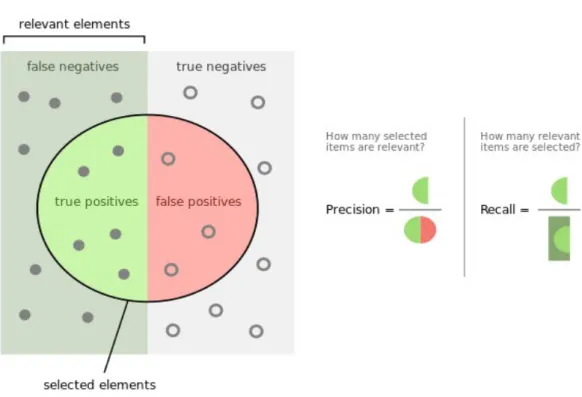
In this way, it reduces the variance of parameter updates, which can lead to more stable convergence; and can use the highly optimized matrix optimizations common to modern deep learning libraries that make the computation of the gradient in relation to a mini-batch very efficient. When the above equations are applied to modules in reverse order, from layer N to layer 1, all partial derivatives of the cost function with respect to all parameters can be calculated. Intuitively, it shows the ratio of correctly predicted positive observations (True Positives) to the total of corresponding observations.
Pre-processing
- Tokenization
- Word embeddings
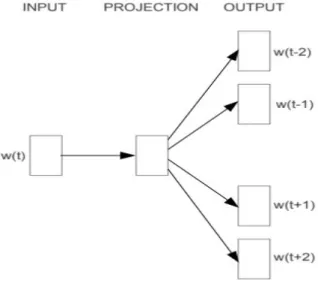
- Word2Vec
In this chapter, we introduced some concepts and used them to describe the previous work in the area related to our problem, on which we will base our work. In the next chapter, we begin to present our work, starting with a precise definition of our task.
TASK DEFINITION
Examples
- Addition
- Replacement
- Deletion
- Renumbering
- Combinations
To better demonstrate the labels and how we applied them to the text, we now cite some annotated examples of each change category. Because the text we worked on is written in Greek, the examples are cited in Greek. In this chapter we defined our conceptual model and the entities we want our neural network to recognize.
METHODOLOGY
Pre-processing
- Labeling
- Tokenization
- Vectorization
Since our goal was to annotate a large number of modification examples while working independently of each other, and these examples should be consistent in their method of labeling for smooth training of the neural network, we first set some labeling rules and annotated a few. example documents. We repeated this process and adjusted the rules until the identification of the labels we noted reached a satisfactory percentage (less than one discrepancy in twenty documents). Once we had collected a sufficient amount of recorded data (533 laws, containing 1548 changes and 6929 labels in total), we proceeded to the next phase.
The next step was to convert the dataset from string sequences to word sequences, thus properly translating any tag information we added during the annotation. We used the tokenizer developed for the ΝΟΜΟΘΕΣΙ@ project [19], including lists of word abbreviations corresponding to the same token. As the last step of the preprocessing phase, we converted the documents into sequences of vectors using the word2vec algorithm.
Here too we relied on the valuable work of the ΝΟΜΟΘΕΣΙ@ team, using a pre-trained model on the same corpus, i.e. the Greek legal text from the Government Gazettes.
Model Development
EXPERIMENTS
- Batch size and number of epochs
- Optimizer
- Initial weight values, weight constraints
- Number of neurons and dropout rate
- Final results
- Examples
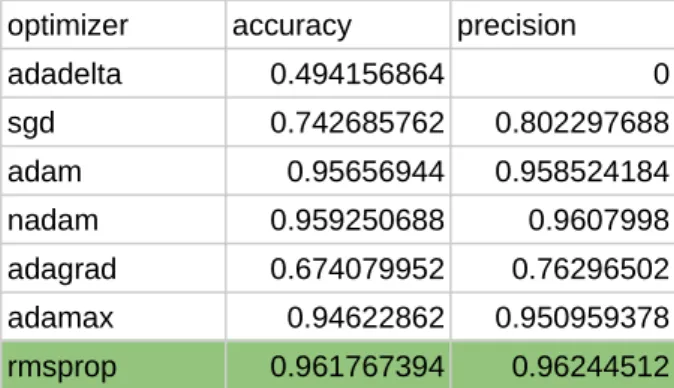
While the Adam optimizer and its derivatives are widely regarded as the best for related tasks, the RMSProp algorithm was shown to provide the best results with Nadam coming in second. The minimum and maximum weight normalization constraint functions seem to perform best, with glorot normal and glorot uniform being equivalent. We can see that 100 neurons in each layer is enough, and the performance even decreases when the number of neurons reaches 150.
In the end, we used the hyperparameters we arrived at during the tuning process to create a final model, trained on the full training and validation database, and used it to predict document labels in the test set. The table below is a classification report produced by the scikit-learn module, giving the precision, recall and f1 score per label, as well as the overall averages. ΚΑΤΑ ΤΗ ΔΙΑΡΚΕΙΑ ΤΟΥ ΕΛΕΓΧΟΥ , Η ΕΠΙΤΡΟΠΗ ΤΗΗS ΠΑΡΑΓΑΡΟΥ d , ΔΙΑ ΤΟΥ In this example we can see that the model successfully identifies all tags despite the fact that the text contains many different modifications to the same article.
Here we can see that the model correctly identifies the law under amendment and does not correctly name the other article mentioned. Despite the overall high success rate, the model here fails to identify either of the two modifications that occur. In this chapter, we have presented the results of our experiments in both fitting our various hyperparameters as well as those produced by our optimal model in a test data set.
CONCLUSION
ΣΥΝΤΟΜΟΓΡΑΦΙΕΣ-ΑΚΡΩΝΥΜΙΑ ΕΦΗΜΕΡΙΔΑ Εφημερίδα της Κυβερνήσεως Application Programming Interface API ELI European Legislation Identifier NLP Επεξεργασία Φυσικής Γλώσσας Deep Neural Network DNN. SGD Stochastic Gradient Descent MGD Mini-batch Gradient Descent PPV Προβλεπόμενη θετική τιμή TPR Αληθινός θετικός ρυθμός.