Modelos flexíveis de sobrevivência com fração de cura: implementação computacional
Texto
Imagem
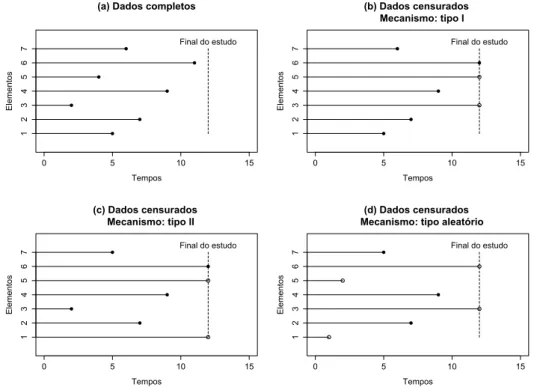
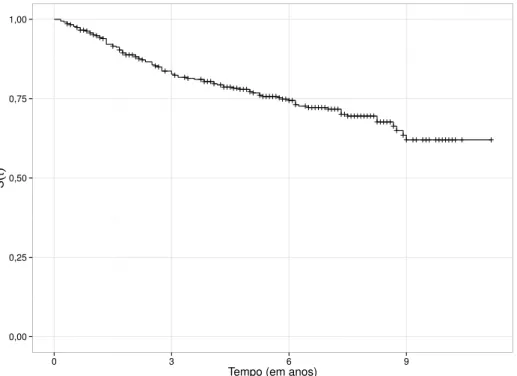
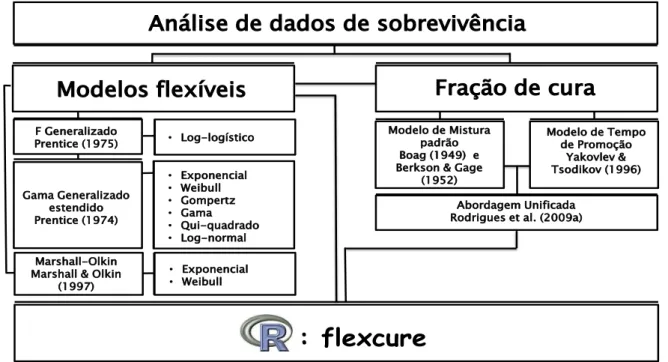
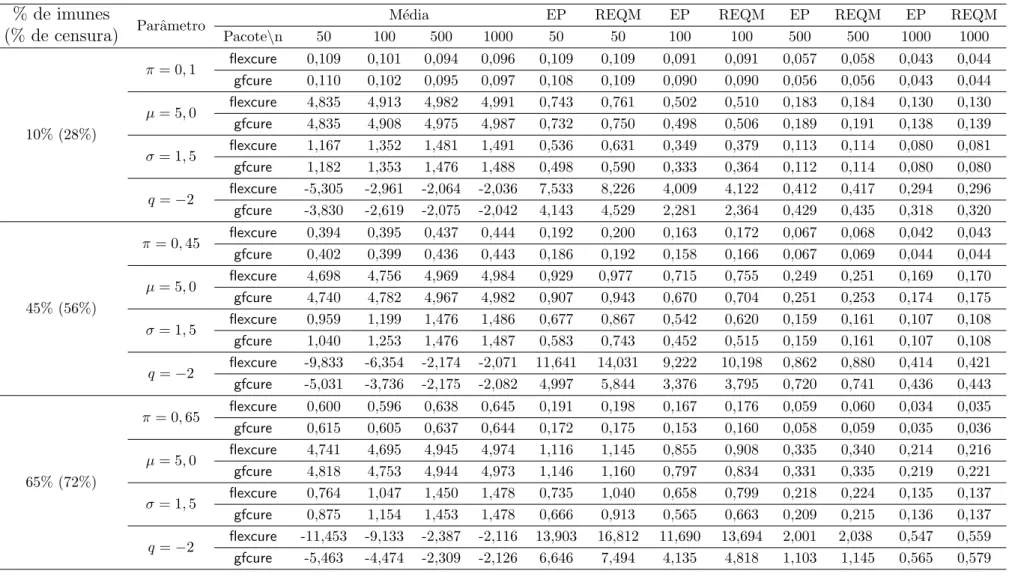
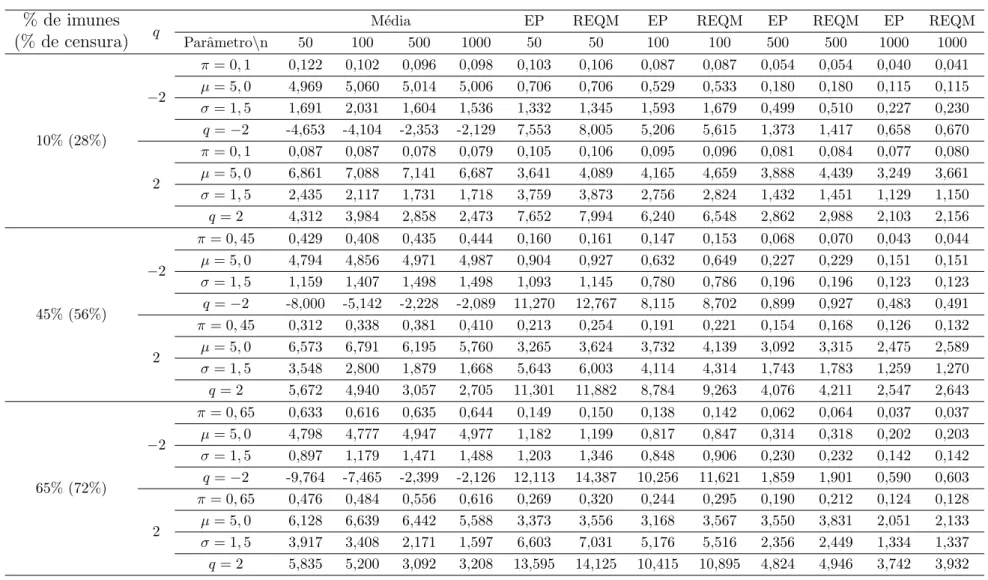
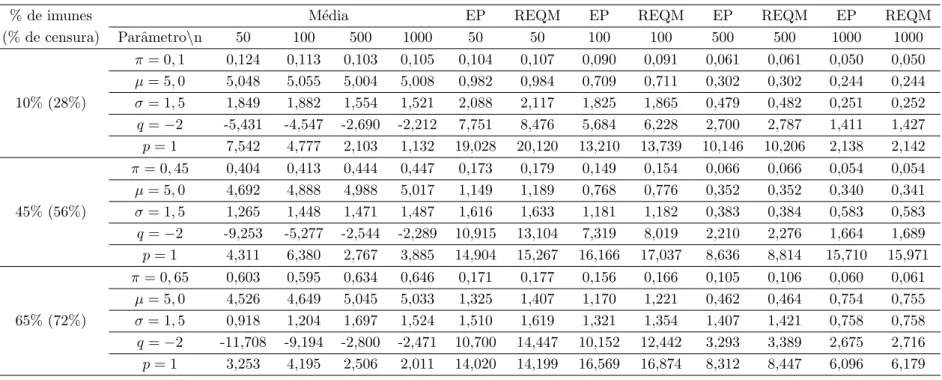
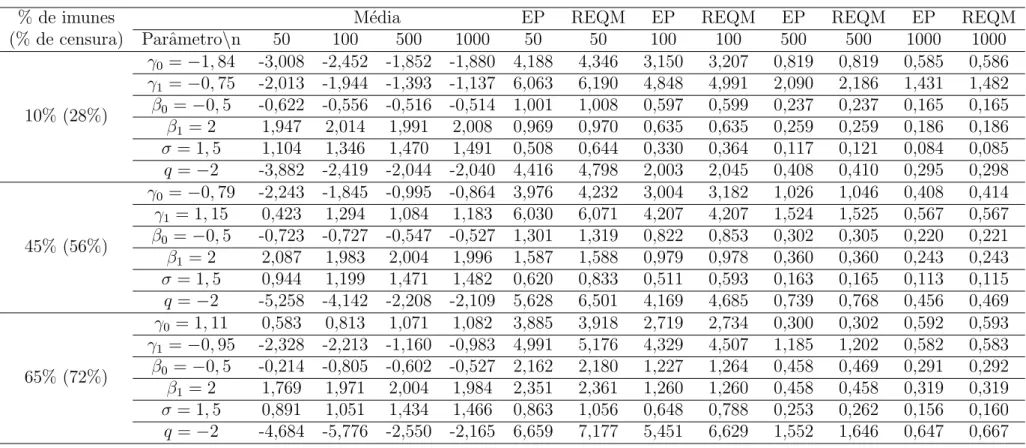
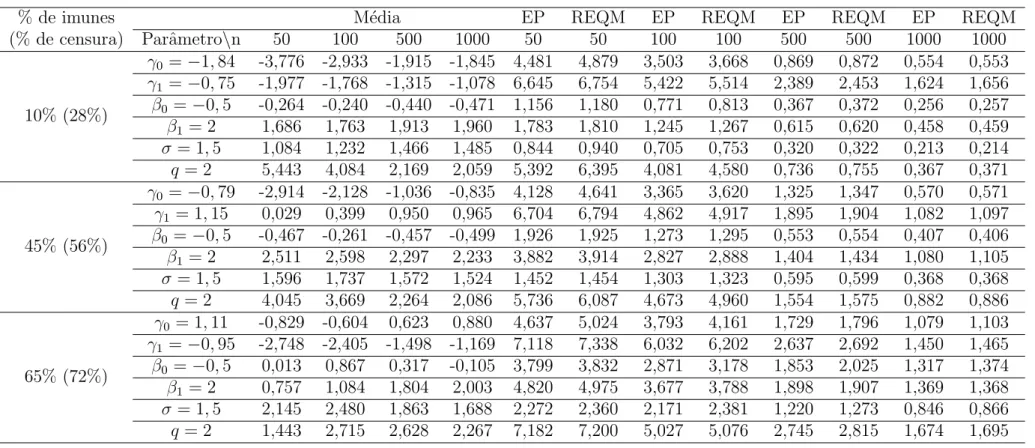
Documentos relacionados
Este artigo está dividido em três partes: na primeira parte descrevo de forma sumária sobre a importância do museu como instrumento para construção do conhecimento, destaco
In: VI SEMINÁRIO NACIONAL DE PESQUISADORES DA HISTÓRIA DAS COMUNIDADES TEUTO-BRASILEIRAS (6: 2002: Santa Cruz do Sul).. BARROSO, Véra Lúcia
Disto pode-se observar que a autogestão se fragiliza ainda mais na dimensão do departamento e da oferta das atividades fins da universidade, uma vez que estas encontram-se
Local de realização da avaliação: Centro de Aperfeiçoamento dos Profissionais da Educação - EAPE , endereço : SGAS 907 - Brasília/DF. Estamos à disposição
A estabilidade do corpo docente permanente permite atribuir o conceito muito bom, segundo os parâmetros da área, para o item 2.2 (pelo menos 75% dos docentes permanentes foram
De seguida, vamos adaptar a nossa demonstrac¸ ˜ao da f ´ormula de M ¨untz, partindo de outras transformadas aritm ´eticas diferentes da transformada de M ¨obius, para dedu-
• O material a seguir consiste de adaptações e extensões dos originais gentilmente cedidos pelo
Código Descrição Atributo Saldo Anterior D/C Débito Crédito Saldo Final D/C. Este demonstrativo apresenta os dados consolidados da(s)
