RENATA ELEUTERIO DA SILVA
A
S
T
ECNOLOGIAS DA
W
EB
S
EM ÂNTICA NO
D
OM ÍNIO
B
IBLIOGRÁFICO
RENATA ELEUTERIO DA SILVA
A
S
T
ECNOLOGIAS DA
W
EB
S
EM ÂNTICA NO
D
OM ÍNIO
B
IBLIOGRÁFICO
M arília
2013
Dissert ação apresent ada a Universidade Est adual Paulist a “ Júlio de M esquit a Filho” - UNESP, Faculdade de Filosofia e Ciências, Cam pus de M arília, com o um dos requisit os para a obt enção do t ít ulo de M est re em Ciência da Informação.
Linha de pesquisa: Informação e Tecnologia
Orientadora:
Dra. Plácida L. V. Amorim da Cost a Sant os
Financiamento:
Silva, Renat a Eleut erio da S586t
As t ecnologias da Web Semânt ica no domínio bibliográfico / Renat a Eleut erio da Silva. – M arília, 2013.
134 f. : il.
Dissert ação (M est rado em Ciência da Informação) – Faculdade de Filosofia e Ciências, Universidade Est adual Paulist a “ Júlio de M esquit a Filho” , 2013.
Orient adora: Plácida Leopoldina Vent ura Amorim da Cost a Sant os 1. Web Semânt ica. 2. Cat alogação. 3. FRBR. 4. BIBFRAM E.
I. Aut or. II. Tít ulo.
FOLHA DE APROVAÇÃO
Renat a Eleut erio da Silva
A
S
T
ECNOLOGIAS DA
W
EB
S
EM ÂNTICA NO
D
OM ÍNIO
B
IBLIOGRÁFICO
Dissert ação apresent ada a Universidade Est adual Paulist a “ Júlio de M esquit a Filho” - UNESP,
Faculdade de Filosofia e Ciências, Campus de M arília, como um dos requisit os para a
obt enção do t ít ulo de M est re em Ciência da Informação.
Banca examinadora
________________________________________
Plácida L. V. Amorim da Cost a Sant os (orient adora)
Livre-docent e em Cat alogação – FFC/ UNESP/ M arília
________________________________________
M aria Elisabet e Cat arino
Dout ora em Tecnologias e Sist emas de Inform ação – UEL
________________________________________
Ricardo César Gonçalves Sant ’Ana
Dout or em Ciência da Inform ação – UNESP/ Tupã
AGRADECIM ENTOS
A Deus.
Aos meus pais, por acredit arem em mim e por sempre me apoiarem nas minhas decisões.
Aos amigos e colegas que est iveram present es (geograficament e ou não) na minha vida durant e t odo o mest rado, especialment e nesse últ imo ano, me dando forças para sempre acredit ar e seguir em frent e.
Aos docent es do Programa de Pós-Graduação em Ciência da Informação (PPGCI), da Faculdade de Filosofia e Ciências da UNESP, campus de M arília, em especial aos professores da linha de pesquisa Informação e Tecnologia, por t odo o conheciment o compart ilhado em sala de aula e fora dela.
À professora Dra. Plácida Leopoldina Vent ura Amorim da Cost a Sant os, por t odos os anos de orient ação em pesquisa, desde o início da graduação at é a finalização dest a pesquisa de mest rado. M uit o obrigada pelo incent ivo, pela paciência, pela confiança e por t oda cont ribuição ao desenvolviment o desde t rabalho. Agradeço muit o a oport unidade de poder finalizar mais essa fase sob seus ensinament os.
Aos professores Dr. Ricardo César Gonçalves Sant 'Ana e Dra. M aria Elisabet e Cat arino, pela disposição e cont ribuições feit as na qualificação e por aceit arem part icipar novament e da banca de defesa.
A t odos os int egrant es do Grupo de Pesquisa Novas Tecnologias em Informação (GP-NTI), por t odas as conversas, discussões, conheciment os gerados e compart ilhados em t odos esses anos.
SILVA, Renat a Eleut erio da. As tecnologias da w eb semântica no domínio bibliográfico. 134 f. 2013. Dissert ação (M est rado em Ciência da Informação) – Universidade Est adual Paulist a “ Júlio de M esquit a Filho” , Faculdade de Filosofia e Ciências, M arília, 2013.
RESUM O
A propost a de um a Web Sem ânt ica surgiu como uma alt ernat iva que possibilit aria a int erpret ação das informações por máquinas, permit indo assim maior qualidade nas buscas e result ados mais relevant es aos usuários. A Web Semânt ica pode ser ut ilizada at ualment e apenas em domínios rest rit os, como em sit es de comércio elet rônico, devido à dificuldade de represent ar ont ologicament e t oda a Web. Objet iva-se verificar como os conceit os, t ecnologias, arquit et uras de met adados ut ilizados pela Web Semânt ica podem cont ribuir à const rução, modelagem e arquit et ura de met adados de cat álogos bibliográficos, t omando por base os conceit os definidos no m odelo conceit ual desenvolvido para a represent ação do universo bibliográfico denom inado Funct ional Requirement s for Bibliographic Records (FRBR), além de explanar sobre a ut ilização do modelo conceit ual como recurso ont ológico. A propost a se paut a no est udo de arquit et uras de met adados semânt icas, de modo a ident ificar suas caract eríst icas, funções e est rut uras, além de est udar o modelo BIBFRAM E (Bibliographic Framew ork), que se configura como a iniciat iva mais recent e acerca da implement ação de t ecnologias da Web à área da Bibliot economia e Ciência da Informação. Est a pesquisa caract eriza-se por seu carát er t eórico-explorat ório e foi desenvolvida mediant e análise e revisão de lit erat ura sobre seus t emas. Os result ados apresent am as principais arquit et uras de met adados ut ilizadas no cont ext o da Web Semânt ica e uma abordagem sobre ont ologias, int eroperabilidade em sist emas de informação, modelagem de cat álogos online, além da apresent ação do modelo BIBFRAM E, com base em sua import ância para a cat alogação.
SILVA, Renat a Eleut erio da. The semantic w eb technologies in the bibliographic domain. 134 f. 2013. Dissert at ion (M ast er of Informat ion Science) – Universidade Est adual Paulist a “ Júlio de M esquit a Filho” , Faculdade de Filosofia e Ciências, M arília, 2013.
ABSTRACT
The proposal of a Semant ic Web has emerged as an alt ernat ive t hat w ould allow t he int erpret at ion of informat ion by machines, allowing higher qualit y in t he searches and more relevant result s t o users. Current ly, t he Semant ic Web can only be used in rest rict ed domains, such as e-commerce sit es, due t o t he difficult y of represent ing t he ent ire Web ont ologically. The object ive is t o see how t he concept s, t echnologies, archit ect ures, and met adat a used by t he Semant ic Web can cont ribut e t o build, m odel and met adat a archit ect ure of bibliographic cat alogs, based on t he concept s defined in t he concept ual model developed for t he represent at ion of t he bibliographic universe called Funct ional Requirement s for Bibliographic Records (FRBR), and explain about t he use of t he concept ual model and ont ological resource. The proposal is guided in t he st udy of semant ic met adat a archit ect ures, in order t o ident ify it s charact erist ics, funct ions and st ruct ures, in addit ion t o st udy t he model BIBFRAM E (Bibliographic Framew ork), w hich const it ut es t he most recent init iat ive on implement ing Web t echnologies t o t he Library and Informat ion Science field. This research is charact erized by it s t heoret ical and explorat ory charact er w as developed t hrough analysis and review of lit erat ure on t heir subject s. The result s show t he main archit ect ures used in t he met adat a cont ext of t he Sem ant ic Web and an approach t o ont ology, int eroperabilit y in informat ion syst ems, modeling cat alogs online, besides t he present at ion of t he model BIBFRAM E, based on t heir import ance t o t he Cat aloging.
LISTA DE FIGURAS
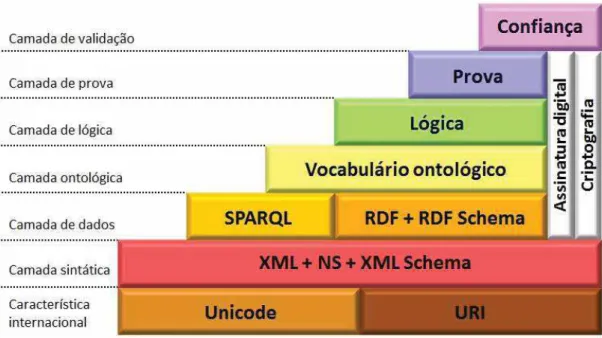
FIGURA 1 – Arquit et ura da Web Semânt ica ... 41
FIGURA 2 – Arquit et ura da Web Semânt ica em 2006 ... 43
FIGURA 3 – Element os da Web Semânt ica ... 45
FIGURA 4 – Exemplo de um grafo simples de uma t ripla ... 52
FIGURA 5 – Exemplo de um grafo simples de uma t ripla ent re recursos ... 52
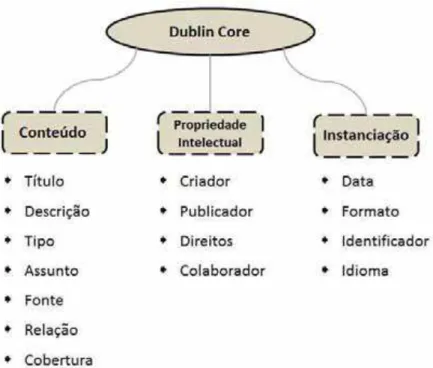
FIGURA 6 – Composição baseada no DCM I Element Set ... 65
FIGURA 7 – Relações primárias do Grupo 1 ... 84
FIGURA 8 – Relações de responsabilidade ent re as ent idades dos Grupos 1 e 2 ... 85
FIGURA 9 – Relações de assunt o ent re uma obra e as ent idades dos Grupos 1, 2 e3 ... 85
FIGURA 10 – Component es de um Sist ema de Bancos de Dados ... 88
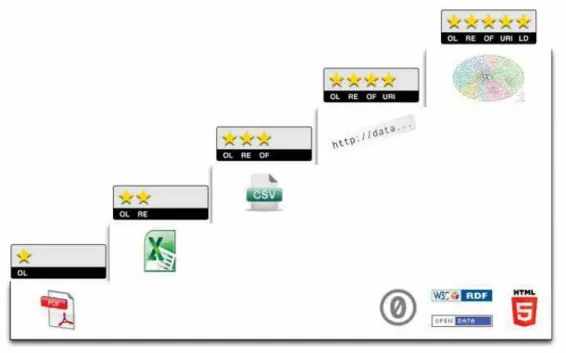
FIGURA 11 – 5 St ars Open Dat a ... 95
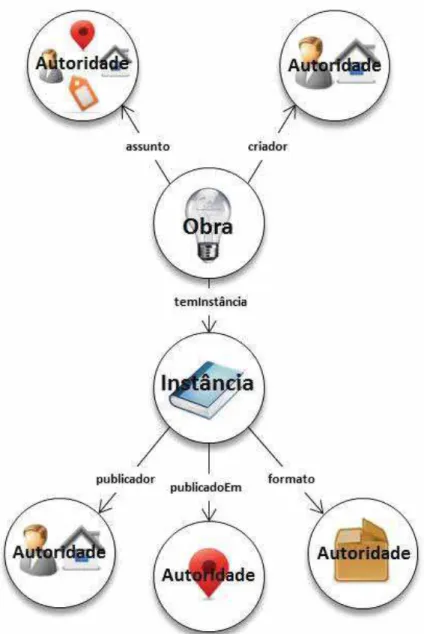
FIGURA 12 – Represent ação gráfica do modelo BIBFRAM E Linked Dat a definindo as relações exist ent es ent re os recursos Obra (Work) e Inst ância (Inst ance) e sua cont ext ualização a recursos de Aut oridade (Aut horit y) endereçáveis na Web... 98
FIGURA 13 – Represent ação gráfica do modelo BIBFRAM E no cont ext o de um fram ew ork flexível para anot ações. ... 100
FIGURA 14 – Regist ro de exemplo da Library of Congress ... 102
LISTA DE QUADROS
QUADRO 1 – Classes essenciais do RDF Schema ... 53
QUADRO 2 – Comparação ent re as linguagens OIL e DAM L ... 56
LISTA DE SIGLAS E ABREVIATURAS
AACR2 – Anglo-American Cat aloguing Code 2nd edit ion
BIBFRAM E – Bibliographic Framew ork
CERN – Cent re Européen de Recherches Nucléaires
CIDOC – Int ernat ional Commit t ee for Document at ion
CIDOC-CRM – Int ernat ional Commit t ee for Document at ion - Concept ual Reference M odel
DAM L – DARPA (Defense Advanced Research Project s Agency) Agent M arkup Language
DC – Dublin Core
DCM I – Dublin Core M et adat a Init iat ive
FRAD – Funct ional Requirement s for Aut horit y Dat a
FRBR – Funct ional Requirement s for Bibliographic Records
FRBRoo – Funct ional Requirement s for Bibliographic Records Object -Orient ed
FRSAD – Funct ional Requirement s for Bibliographic Aut horit y Dat a
HTTP – Hypert ext Transfer Prot ocol
IFLA – Int ernat ional Federat ion of Library Assossiat ions and Inst it ut ions
ILS – Int egrat ed Library Syst ems
IM CE – Int ernat ional M eet ing of Cat aloguing Expert s
IM E ICC – IFLA M eet ing of Expert s in a Int ernat ional Cat aloging Code
ISO – Int ernat ional Organizat ion of St andardizat ion
LC – Library of Congress
M ARC – M achine Readable Cat aloging
M EM EX – M emory Ext ension
M IT – M assachuset t s Inst it ut e of Technology
OIL – Ont ology Inference Layer
OWL – Web Ont ology Language
RDF – Resource Descript ion Framew ork
RDA – Resource Descript ion and Access
SGBD – Sist em a de Gerenciam ent o de Bancos de Dados
SHOE – Simple HTM L Ont ology Ext ension
SPARQL – Simple Prot ocol and RDF Query Language
TDI – Trat ament o Descrit ivo da Informação
TIC – Tecnologias de Informação e Comunicação
URI – Uniform Resource Ident ificat or
URL – Uniform Resouce Locat or
URN – Uniform Resource Name
W3C – World Wide Web Consort ium
WWW – World Wide Web
SUM ÁRIO
1 INTRODUÇÃO ... 14
1.1 Apresent ação do problema ... 21
1.2 Objet ivos ... 21
1.2.1 Objet ivo geral ... 22
1.2.1 Objet ivos específicos ... 22
1.3 Just ificat iva ... 22
1.4 M et odologia ... 23
1.5 Est rut ura do t rabalho ... 24
2 W EB:Trajetória ... 27
2.1 Cont ribuições pré-Web ... 29
2.1.1 Vannevar Bush ... 29
2.1.2 Theodor (Ted) Nelson ... 31
2.1.3 Douglas Engelbart ... 32
2.2 Da Web à Web Semânt ica ... 33
3 AS TECNOLOGIAS DA W EB SEM ÂNTICA ... 40
3.1 Est rut ura da Web Semânt ica ... 41
3.2 M et adados ... 45
3.3 Arquit et uras de met adados para a Web Semânt ica ... 50
3.3.1 RDF e RDF Schema ... 50
3.3.2 SHOE ... 53
3.3.3 OIL ... 54
3.3.4 DAM L ... 55
3.3.5 DAM L+OIL ... 56
3.3.6 OWL ... 57
3.4 Ont ologias ... 59
3.5 Int eroperabilidade em sist emas informacionais ... 62
4 DOM ÍNIO BIBLIOGRÁFICO: FUNDAM ENTOS DA CATALOGAÇÃO ... 67
4.1 A Cat alogação Descrit iva ... 68
4.3 As t arefas do usuário (User Tasks) ... 76
4.4 Requisit os Funcionais para Regist ros Bibliográficos (FRBR) ... 80
4.5 As bases est rut urais dos cat álogos aut omat izados ... 86
5 O M ODELO BIBFRAM E LINKED DATA ... 90
5.1 Linked Dat a ... 93
5.2 O modelo BIBFRAM E ... 95
5.2.1 Obras criat ivas BIBFRAM E ... 99
5.2.2 Inst âncias BIBFRAM E ... 99
5.2.3 Aut oridades BIBFRAM E ... 99
5.2.4 Anot ações BIBFRAM E ... 99
5.3 O vocabulário BIBFRAM E ... 101
6 CONCLUSÕES ... 109
REFERÊNCIAS ... 113
ANEXO A - THE BIBFRAM E M ODEL (VOCABULARY UPDATES) ... 121
1 INTRODUÇÃO
A Ciência da Informação caract eriza-se por seu carát er int erdisciplinar, t ant o no que
t ange ao desenvolviment o cient ífico da área, represent ado por meio da pesquisa, quant o
pela at uação prát ica de seus profissionais no mercado de t rabalho. Tal caract eríst ica permit e
que sejam desenvolvidas invest igações nos mais diversos cenários, já que a informação,
objet o da Ciência da Informação, est á cada vez mais present e nas mais variadas áreas do
conhecim ent o.
A const ant e evolução das Tecnologias de Informação e Comunicação (TIC) se dest aca
como fat or fundament al para o desenvolviment o das pesquisas na área da Ciência da
Informação, levando-se em cont a o fat o de que t ais t ecnologias avançam consideravelment e
em curt os períodos de t empo. Há, ent ão, a necessidade de pesquisar os impact os de t ais
t ecnologias, principalment e, no que se refere ao uso dest as na prát ica profissional,
moment o no qual o est udo da t eoria e a invest igação se configuram como et apas essenciais.
Sant ’Ana (2008, p. 145) afirma que “ com a adoção maciça das t ecnologias de
informação e comunicação, o volume de informações armazenadas e disponíveis para
acesso vem crescendo de forma exponencial” e segue afirmando que, para que essa grande
quant ia de informações seja t ransmit ida ao usuário da melhor forma, é necessário processos
de recuperação cada vez mais eficient es. Dest a forma, o aument o nos fluxos informacionais,
gerados pela evolução da Int ernet , t orna fundament al o desenvolviment o e a ot imização de
mecanismos de busca e recuperação nesses ambient es infor macionais. Tal cont ext o se
configura como um desafio para profissionais t ant o da área da Ciência da Comput ação
como, e principalment e, aos profissionais da Ciência da Informação.
Desde a criação dos primeiros códigos de cat alogação, especialist as e pesquisadores
buscam sua melhor ut ilização no Trat ament o Descrit ivo da Informação (TDI), levando em
consideração a eficácia da recuperação informacional nos ambient es informacionais. Novas
discussões surgem com o int uit o definir novos mét odos, regras e padrões de descrição.
Discut em-se os problemas encont rados e as suas possíveis soluções, t endo a finalidade de
evoluir a visão que se t em hoje do cat álogo, t ornando-o mais amigável aos olhos do usuário.
Em 1998, um grupo de est udos da IFLA (Int ernat ional Federat ion of Librarian
de 1992 e 1995, que ficou mundialment e conhecido no campo da cat alogação como os
FRBR, sigla para Funct ional Requirement s for Bibliographic Records, em port uguês,
Requisit os Funcionais para Regist ros Bibliográficos. Tais requisit os foram est ipulados para a
modelagem conceit ual de cat álogos bibliográficos, t razendo novos conceit os e formas de
pensar à área da cat alogação descrit iva, como uma forma de revolucionar os cat álogos,
t ornando-os muit o mais amigáveis aos usuários de bibliot ecas e out ras unidades de
informação. (IFLA STUDY GROUP..., 2009) De 1998 at é os dias at uais, os FRBR se
popularizaram na comunidade cient ífica, sendo foco de debat es e invest igações nacionais e,
sobret udo, int ernacionais. Porém, foram poucas as unidades de informação que, em t odos
esses anos, modificaram suas bases de dados a fim de adequá-las ao que o modelo
conceit ual da IFLA propôs. Isso se deve ao fat o de os FRBR, por si só , não serem
implement áveis, obrigando bibliot ecários cat alogadores a recorrerem a profissionais da
Ciência da Comput ação para sua efet iva implement ação.
No ano de 2005, foi apresent ada um a propost a no comit ê de revisão do Código de
Cat alogação Anglo-Americano (Joint St eering Commit t ee for Revision of Anglo-American
Cat aloguing Rules) de elaboração de um novo código de cat alogação que viesse a subst it uir
o at ual AACR2. Tal código ficaria conhecido como RDA – Resource Descript ion and Access –
sendo caract erizado pela flexibilidade, em relação a sua aplicação a qualquer ambient e
informacional (digit al ou analógico), e por ut ilizar os conceit os dos modelos conceit uais FRBR
(Requisit os Funcionais para Regist ros Bibliográficos) e FRAD (Requisit os Funcionais para
Dados de Aut oridade). (SANTOS; CORRÊA, 2009)
Levando em cont a as iniciat ivas da Bibliot economia no que diz respeit o à descrição
de recursos, dest acam -se out ros campos de est udo que t ambém se preocupam com a
represent ação e recuperação de recursos informacionais, sendo a mais popular delas a
Ciência da Comput ação e áreas afins, que t rabalham com t emát icas diret ament e ligadas à
Int ernet , mais especificament e à Web. Para o present e t rabalho, define-se “ recurso
informacional” como uma ent idade est rut urada que cont ém t ext o, gráfico, imagem, som,
que podem ser t rat ada, apreciada e arm azenada.
Sendo a Web um ambient e informacional t ipicam ent e het erogêneo, ou seja, que t em
necessidade de at ribuir t rat ament os descrit ivos eficient es para suas informações, para que
essas possam ser recuperadas.
Nesse cont ext o, a Web Semânt ica é um t ema de grande dest aque na at ualidade. A
recuperação da informação na Web se configura como um dos m aiores desafios aos
profissionais e pesquisadores da área, já que há um aument o exponencial de informações
que precisam ser descrit as e localizadas por mecanismos de busca. A Web Semânt ica é
considerada uma ext ensão da Web at ual, que busca int egrar significado aos cont eúdos Web.
(BERNERS-LEE; HENDLER; LASSILA, 2001)
O avanço das t ecnologias possibilit a aos pesquisadores da área de Ciência da
Informação a ampliação de seus horizont es de pesquisa, int egrando-a cada vez mais com
diversas out ras áreas do conheciment o, sem necessariament e perder sua essência. De
acordo com Grandmann (2005), as t ecnologias da Web Semânt ica e a est rut ura conceit ual
dos FRBR, apesar de pert encerem a domínios dist int os, podem int egrar bibliot ecários e
informações Web (em out ras palavras, a Ciência da Informação e a Ciência da Comput ação),
levando-os a produt ivament e int eragir nos paradigmas inovadores da modelagem de
informações.
A vast a quant idade de informações disponível na Web faz com que hoje em dia exist a
uma ampla mobilização de recursos humanos e financeiros envolvidos em desenvolver
maneiras de ot imizar a recuperação de t odas as informações dispost as nest a grande t eia. A
propost a de at ribuir significado ao cont eúdo das páginas Web para que sejam int erpret adas
por máquinas surgiu no ano de 2001, a part ir da publicação de um art igo na revist a
americana Scient ific American, cujo t ít ulo é: “ Web Sem ânt ica: um novo format o de cont eúdo
para a Web com significado para comput adores vai iniciar uma revolução de novas
possibilidades” . Tal art igo foi publicado por Tim Berners-Lee (diret or do W3C e pesquisador
do Inst it ut o de Tecnologias de M assachuset t s - M IT), James Hendler (professor da
Universidade de M aryland) e Ora Lassila (pesquisador e membro do W3C), e é at é hoje um
t ext o referência sobre Web Semânt ica, pois nele os aut ores definem seus principais
conceit os, est rut ura e ilust ram as sit uações que esse novo moment o da Web pode
proporcionar. (BERNERS-LEE; HENDLER; LASSILA, 2001)
Assim como se deu o desenvolviment o e cresciment o da W eb, nas bibliot ecas a
de t empo, levando em cont a o fat o de que as bibliot ecas exist em desde os períodos mais
remot os. O surgiment o dos microcomput adores e da Int ernet no fin al dos anos 80 do século
passado t eve grande dest aque nest e cresciment o, pois possibilit ou organizar de maneira
muit o mais eficient e os regist ros cat alográficos ant es elaborados manualment e e t ambém
aut omat izou os demais serviços da bibliot eca. O cat álogo aut omat izado foi, por sua vez,
evoluindo e sendo modificado, a princípio para o benefício maior do bibliot ecário
cat alogador, e, post eriorment e, a fim de se t ornar út il à recuperação das informações pelo
usuário final.
Um fat or relevant e a se dest acar é que os cat álogos, com o passar do t empo,
deixaram de ser locais onde era possível soment e localizar mat eriais bibliográficos.
At ualment e, os cat álogos de bibliot ecas podem ser grandes bases de dados aut omat izadas,
compost as por diversos serviços e sist emas est rut urados que, além de ret ornar a quest ão do
usuário com a localização do it em desejado, pode lhe t razer informações adicionais que
enriquecem suas buscas e lhe conferem muit o mais conheciment o, t ant o acerca do assunt o
pesquisado, como sobre mat eriais diferenciados que a unidade de informação possui sobre
est e.
Pensando em t odas as novas funcionalidades que os cat álogos passaram a t razer, são
divulgados em 1998 os FRBR: um modelo conceit ual para o universo bibliográfico, publicado
em um document o elaborado por especialist as da IFLA cuja finalidade era definir diret rizes
para a modelagem conceit ual de bases de dados de cat álogos de bibliot ecas, paut adas nas
t arefas do usuário definidas nos Princípios de Paris (1961), garant indo os requisit os
fundament ais para a descrição de recursos informacionais present es em bibliot ecas e out ras
unidades de informação. Como modelo conceit ual do t ipo ent idade-relacionam ent o, os
FRBR são compost os por ent idades, at ribut os e relacionament os. (TILLETT, 2004)
Os cat álogos podem ser ferrament as eficient es e efet ivas para a recuperação da
informação, cont udo, para que de fat o sejam, são necessários maiores invest iment os, no
que se refere a uma modelagem de dados corret a que t orne isso possível, além de uma
visão mais abrangent e de sua t écnica. Para uma maior compreensão dest e processo, Sant os
(2008, p. 165) define a cat alogação com o sendo:
em acervos, de modo a t ornar a unidade informacional única e mult iplicar os pont os de acesso para a sua ident ificação, localização e recuperação [...].
Algumas t ecnologias que passaram a ser divulgadas por meio do surgiment o da
Int ernet já t inham seus conceit os ut ilizados na prát ica bibliot econômica, como é o caso da
represent ação dos recursos informacionais em um cat álogo. Tal represent ação é o que ficou
conhecido na Ciência da Comput ação pelo t ermo “ met adado” . Breit man (2005, p 16), sobre
met adados e sua ut ilização na Ciência da Informação, afirma:
Apesar de não exist ir uma definição universal para o t ermo m et adado, o t ema ainda est á abert o a discussões nas várias comunidades onde ele é ut ilizado. No ent ant o, é import ant e not ar que a ut ilização de met adados não é novidade nem foi int roduzida por pesquisadores da W eb Semânt ica, pois se t rat a de um conceit o que vem sendo aplicado há cent enas de anos por bibliot ecários, museólogos, arquivist as e edit ores. Uma das consequências mais int eressant es da adoção de met adados no cont ext o da W eb Semânt ica é a de que a disciplina de Cat alogação, ant es percebida como algo arcano, prat icado apenas por curadores de museus e bibliot ecários, passou at ualm ent e para o prim eiro plano da pesquisa em Ciência da Informação.
Tant o na Ciência da Comput ação quant o na Ciência da Informação, não há um
consenso sobre como definir met adados. Uma definição at ual dada por Alves (2010), aut o ra
da área da Ciência da Informação, é:
M et adados são at ribut os que represent am uma ent idade (objet o do mundo real) em um sist ema de informação. Em out ras palavras, são elem ent os descrit ivos ou at ribut os referenciais codificados que represent am caract eríst icas próprias ou at ribuídas às ent idades; são ainda dados que descrevem out ros dados em um sist ema de informação, com o int uit o de ident ificar de forma única uma ent idade (recurso informacional) para post erior recuperação. (ALVES, 2010, p. 47)
Esses at ribut os são muit o import ant es no que se refere à recuperação da informação,
seja ela num cat álogo de bibliot eca ou na Web. No cont ext o dest a pesquisa, os met adados
serão um dos focos desse est udo, pois é por meio das arquit et uras est abelecidas para a
at ribuição de met adados que se pode conferir descrição e, mais exaust ivament e,
significados às informações a serem descrit as.
A Web Semânt ica, segundo Alves (2005), t em como propost a est rut urar e at ribuir
semânt ica aos dados represent ados com a finalidade de dim inuir problemas de recuperação
da informação na Web, apresent ando, para t al, uma est rut ura que permit irá a compreensão
do cont eúdo dos recursos informacionais, por meio da valorização semânt ica dest es
recursos e de agent es int eligent es capazes de processar informações e t rocá-las com out ros
Breit man (2005) dest aca as principais linguagens para a represent ação de ont ologias
relacionadas à Web Semânt ica, as quais serão abordadas nest a pesquisa: RDF; RDF-Schema;
SHOE; OIL; DAM L; DAM L-OIL; e OWL. Tais est rut uras são responsáveis por fornecer um
modelo formal de dados que possam codificar met adados a serem processados por
comput adores.
De acordo com Jorent e, Sant os e Vidot t i (2009, p. 18), o que se pret ende com a Web
Semânt ica é
[...] fazer com que cada vez mais as informações possam ser decodificadas e int er -relacionadas aut omat icament e, pela criação de ambient es em que os soft w ares leiam t ais codificações, cooperando com os usuários em função de capacit ar o ser humano como colet ividade.
Um dos element os essenciais para que a int eroperabilidade semânt ica ocorra ent re
sist emas de informação é a elaboração de ont ologias. O t ermo ont ologia, no cont ext o da
Web, represent a um “ document o ou arquivo que define formalment e as relações ent re
t ermos e conceit os” (SOUZA; ALVARENGA, 2004, p. 137).
Breit man (2005, p. 100) afirma que
[...] ont ologias t êm muit o em comum com out ras modelagens que ut ilizamos em nossa prát ica de soft w are. Exemplos são modelos de Análise Est rut urada, modelos de Ent idade Relacionament o, de Análise Essencial e Orient ação a Objet o. A const rução desses modelos, bem com o a de ont ologias, envolve processos de descobert a, modelagem, validação e verificação da informação.
O W3C pont ua que as ont ologias devem prover descrições para os conceit o s de
“ classes” (ou “ coisas” ), relacionament os ent re essas classes e propriedades (at ribut os).
(BREITM AN, 2005, p. 31) Com base nas semelhanças exist ent es ent re ont ologias e
modelagens de dados, como o aspect o conceit ual que possuem e a ut ilização de
relacionament os, evidenciam -se os esforços da criação de uma ont ologia baseada no
modelo conceit ual FRBR. Fusco (2010) afirma que, dent re as muit as possibilidades de usos
do modelo em quest ão, dest aca-se a iniciat iva dos est udos sobre FRBRoo, realizado pelo
CIDOC (Int ernat ional Commit t ee on Document at ion), a part ir do docum ent o já elaborado
CIDOC-CRM (Concept ual Reference M odel), em conjunt o com a IFLA, formando o
Int ernat ional Working Group on FRBR/ CIDOC CRM Harmonisat ion, responsável pela
elaboração de uma ont ologia formal dos FRBR para uso na alt ernat iva propost a da
Os recursos propost os para a Web Semânt ica e os esforços int elect uais
proporcionados pela Ciência da Informação por meio dos FRBR agindo conjunt ament e
poderão exercer t ransformações significat ivas no que t ange à represent ação e recuperação
de recursos na Web, possibilit ando, assim, cat álogos bibliográficos muit o mais eficient es e
amigáveis aos seus usuários, além de possibilit ar uma maior visibilidade aos recursos
informacionais.
1.1 APRESENTAÇÃO DO PROBLEM A
A divulgação, em novembro de 2012, pela Library of Congress (LC) de um framew ork
que t em por objet ivo empregar as t ecnologias da Web, diret ament e relacionadas às
iniciat ivas de Linked Dat a, no domínio bibliográfico, int it ulado BIBFRAM E, nort eou a
definição do problem a de pesquisa.
Um framew ork, de acordo com Zeng e Qin (2008, p. 273), pode ser considerado como
um “ esquelet o” que int egra vários objet os para um a dada solução. Segundo Fusco (2009),
framew orks são conjunt os de classes, int erfaces e padrões que incorporam um projet o
abst rat o para soluções de um grupo de problemas relacionados.
Considerando os FRBR e as propost as que a Web Semânt ica t em em relação à
recuperação da informação, se apresent a como o problema dest a pesquisa a seguint e
quest ão: as t ecnologias propost as para a Web Semânt ica podem cont ribuir para a
const rução de cat álogos bibliográficos mais eficient es, int uit ivos e int erat ivos, t endo por
base os conceit os abordados no modelo conceit ual FRBR e o framew ork bibliográfico
BIBFRAM E?
1.2 OBJETIVOS
1.2.1 Objetivo geral
Como objet ivo geral, busca-se ident ificar as cont ribuições que os conceit os e
t ecnologias ut ilizados pela Web Semânt ica podem oferecer à área da Ciência da Informação,
mais especificament e ao desenvolviment o, modelagem e arquit et ura de met adados
(ent endidas nest a pesquisa como padrões de met adados e linguagens para represent ação
de ont ologias) em cat álogos online, t endo por base os conceit os definidos nos Funct ional
Requirement s for Bibliographic Records (FRBR) e o framew ork bibliográfico BIBFRAM E.
1.2.2 Objetivos específicos
x
Ident ificar os principais aspect os da Web Semânt ica, dest acando suascaract eríst icas e conceit os que a fundament am;
x
Realizar um est udo acerca das arquit et uras de met adados ident ificadas (RDF;RDFS; SHOE; OIL; DAM L; DAM L-OIL; OWL);
x
Apresent ar o framew ork bibliográfico BIBFRAM E (BIBFRAM E Linked Dat a M odel),t endo como base as t ecnologias da Web Semânt ica.
1.3 JUSTIFICATIVA
A Web se apresent a, no cont ext o at ual, como o ambient e informacional que oferece
o maior número de recursos informacionais e se configura como o que necessit a de maiores
cuidados com o t rat ament o descrit ivo de suas informações.
Para que as informações dispost as na Web não fiquem perdidas e sem uso, exist em
est rut uras de met adados que as descrevem e mecanismos de busca que as recuperam para
o usuário que as necessit a. Ent ret ant o, t ais mecanismos não conseguem at ingir
det erminadas camadas da Web, o que t orna as informações localizadas nelas impossíveis de
serem recuperadas por est es buscadores. É o caso dos cat álogos de bibliot ecas. Todas as
informações cont idas nas bases de dados de bibliot ecas e out ras unidades de inform ação
soment e podem ser recuperadas por meio dos sist emas de busca específicos de seus
cat alográficos como document os soment e acessíveis em format o digit al, os quais acabam
ficando “ ent errados” nest a camada profunda da Web.
Levando em cont a esse cenário, o desenvolvim ent o da t em át ica abordada nest a
pesquisa se faz import ant e devido a grande quant idade exist ent e de regist ros e recursos
armazenados em bases de dados de bibliot ecas, ao t rat ament o que lhes é dado e às formas
de recuperá-los. A propost a de levant ar e de analisar as arquit et uras de met adados
ut ilizadas pela Web Semânt ica é uma forma de buscar informações sobre como modelar um
cat álogo online de bibliot eca que possa int eroperar suas informações com mot ores de
busca, t ornando suas informações possivelment e visíveis na Web. A ident ificação das
semelhanças ent re as t ecnologias ut ilizadas para a const rução de cat álogos e as t ecnologias
ut ilizadas na Web Sem ânt ica se faz im port ant e para verificar como t ais t ecnologias podem
ser ut ilizadas no domínio bibliográfico.
Os FRBR são import ant es nest a pesquisa devido à est rut ura que propõem à
modelagem dos cat álogos, o que é essencial para que est e se desenvolva de maneira
coerent e aos princípios da cat alogação e at inja seus objet ivos de modo eficient e. Além disso,
sua est rut ura de ent idades, at ribut os e relacionament os já é originalment e ont ológica, o que
possibilit a uma possível expressão de sua est rut ura em linguagens específicas de
represent ação de ont ologias. O est udo sobre o modelo BIBFRAM E é de grande import ância
para a apresent ação do modelo à comunidade bibliot ecária, sobret udo em âmbit o nacional,
t endo em vist a sua at ualidade e pert inência no cont ext o hist órico at ual.
A pesquisa é relevant e cient ificament e, pois pode servir de modelo para pesquisas
subsequent es que poderão ser realizadas a part ir do t rabalho aqui expost o, além de
cont ribuir com a produção cient ífica em Ciência da Informação na área de t ecnologias,
represent ação e recuperação da informação em ambient es informacionais digit ais.
1.4 M ETODOLOGIA
A pesquisa se caract eriza por seu carát er t eórico-explorat ório, realizando-se por meio
de análises descrit ivas sobre os assunt os que aborda, de modo a const ruir o conheciment o
t eórico sobre esses t emas, a part ir de uma revisão de lit erat ura, que, segundo Cresw ell
Para t ant o, o t rabalho foi desenvolvido por meio da pesquisa em livros e periódicos
da área de Ciência da Informação e Tecnologias, anais de congressos, t eses, dissert ações,
monografias, revist as elet rônicas, bases de dados t ext uais e referenciais, document os
elet rônicos disponíveis na Web, bibliografias e cat álogos.
Os crit érios para a localização das informações foram det erminados pelo uso, nas
buscas, das palavras-chave: cat alogação; met adados; arquit et ura de met adados; Web
Sem ânt ica; Web de dados; Linked Dat a; ont ologias; FRBR; BIBFRAM E. Variações dest es
t ermos t ambém foram ut ilizados (“ Funct ional Requirement s for Bibliographic Records” , por
exemplo), além de t ermos sinônimos ou que t iveram relação a est es. Foram buscados
mat eriais nos idiomas: Port uguês, Inglês e Espanhol. Não foi at ribuída limit ação cronológica
para a recuperação dos recursos informacionais, porém houve a preocupação com a
at ualidade do cont eúdo dos m at eriais.
1.5 ESTRUTURA DO TRABALHO
Nesse primeiro capít ulo apresent ou-se a int rodução e definições dos principais t emas
que serão abordados nessa dissert ação, demonst rando as quest ões relat ivas ao
desenvolviment o da pesquisa: seu problema, objet ivos (geral e específicos) que nort earam
seu desenvolviment o, a just ificat iva à escolha do t ema a ser pesquisado, a met odologia
ut ilizada e nest e t ópico será t radada a form a com o se est rut ura o t rabalho em quest ão.
Dest e modo, os capít ulos que seguirão est ão apresent ados da seguint e ordem:
Capítulo 2 - W eb: trajetória
Apresent a uma explanação t eórica sobre a Web, sua t rajet ória e as cont ribuições e
est udos desenvolvidos ant es de sua efet iva implement ação, que impulsionaram grandes
ment es a elaborarem a Web como ela é hoje, como poderia t er sido, ou como ainda será. O
capít ulo se embasa no pensament o e obra de t rês grandes nomes: Vannevar Bush, Theodor
Nelson e Douglas Engelbart .
Capítulo 3 – As tecnologias da W eb Semântica
Apresent a a Web Semânt ica ao leit or, t rat ando principalment e das quest ões relat ivas
met adados e ont ologias. São apresent adas informações que se referem às arquit et uras de
met adados ident ificadas na pesquisa: RDF, RDF Schema, as linguagens SHOE, OIL, DAM L,
DAM L+OIL e, finalment e, a OWL. Abordam -se t ambém quest ões relacionadas ao uso de
met adados, ont ologias e int eroperabilidade em sist emas de informação.
Capítulo 4 – Domínio bibliográfico: fundamentos da catalogação
O domínio bibliográfico é referido nessa dissert ação como o conjunt o de t odos os
recursos informacionais que podem fazer part e de uma coleção bibliográfica, ou seja, que é
passível de formar um acervo informacional. Como embasament o, ut iliza-se a Cat alogação,
sendo a área na qual são t rat ados os recursos informacionais e que dá as diret rizes para a
elaboração dos cat álogos bibliográficos. É apresent ada a Cat alogação Descrit iva, os objet ivos
e funções dos cat álogos, as t arefas do usuário, os Requisit os Funcionais para Regist ros
Bibliográficos (mais conhecidos pela sigla FRBR), uma reflexão sobre como são est rut urados
at ualment e os cat álogos aut omat izados.
Capítulo 5 – O modelo BIBFRAM E Linked Data
Aborda as principais caract eríst icas do framew ork bibliográfico BIBFRAM E, uma
iniciat iva da Library of Congress para modernização de acordo com as t ecnologias da Web e
Linked Dat a para as ferrament as ut ilizadas no domínio bibliográfico. São t rat adas, ent ão, as
quest ões relat ivas à sua est rut ura e caract eríst icas gerais do modelo BIBFRAM E.
Capítulo 6 – Conclusões
Apresent a as considerações finais acerca dos t emas abordados na pesquisa, com
base na sínt ese e reflexão sobre os assunt os t rat ados no decorrer da dissert ação,
coment ando os result ados obt idos.
Referências
List agem normalizada das obras ut ilizadas para a fundament ação t eórica da pesquisa.
Anexos
Informações ou mat eriais adicionais, de aut oria ext erna à pesquisa, ut ilizados como
C
APÍTULO
2
2 W EB: Trajetória
O paradigma digit al cont rapõe-se aos conceit os t radicionais e desfaz as concepções
pré-est ipuladas de t empo e, de forma nat ural, exclui as de espaço. " A nova configuração
social t em como base as Tecnologias de Informação e Comunicação que t êm seu significado
at relado à velocidade, à simult aneidade, ao t empo e ao espaço." (BARRETO, 2006, p. 117)
Tal afirm ação se faz t ot alm ent e pert inent e ao cont ext o at ual, em que quant o m ais se
desenvolvem as t ecnologias, mais rápida fica a comunicação e mais present e ela est á.
A evolução das Tecnologias de Informação e Comunicação (TIC) t rouxe consigo a
popularização da Int ernet nas últ imas décadas, pot encializado seus efeit os e as t ornando
part e do cot idiano urbano-social. As inform ações dispersas na Web mult iplicam -se a cada
dia e cada vez mais há uma necessidade de criar e implement ar padrões que permit am
organizá-las, para que possam ser post eriorment e recuperadas.
A propost a inicial da Web Semânt ica vai além das quest ões volt adas soment e e
diret ament e à organização e recuperação das informações na Web, focando t ambém no
papel fundament al que est a t eria em facilit ar as t arefas cot idianas das pessoas. No art igo
original sobre a Web Semânt ica (BERNERS-LEE; HENDLER; LASSILA, 2001), os aut ores
exemplificam como se daria o uso eficient e dest a Web propost a por meio de duas supost as
sit uações, adapt adas por Breit man (2005, p. 5):
Sit uação 1:
Lucy precisa marcar uma consult a médica com um ort opedist a e uma série de sessões de fisiot erapia para sua mãe. Como ela vai t er de levar sua mãe às consult as, é necessário que est as sejam marcadas em um horário em que Lucy est eja livre, de preferência em um local pert o da casa de sua mãe. Tant o o m édico quant o os fisiot erapeut as devem ser qualificados e fazer part e do plano de saúde da família. Lucy vai ut ilizar seu agent e, que funciona na Web Semânt ica, para achar a melhor solução.
Lucy requisit a a marcação da consult a ao agent e:
1. O agent e recupera o t rat am ent o prescrit o à mãe de Lucy do agent e do m édico que est á cuidando dela.
2. O agent e procura em várias list as de provedores de serviços médicos.
4. O agent e ent ão t ent a achar casament os ent re os horários disponíveis da agenda de Lucy e os horários vagos dos profissionais (disponibilizados pelos agent es ou sit e na Web)
Sit uação 2:
Pet er, o irmão de Lucy, at ende o t elefone. Imediat am ent e o est éreo abaixa o volum e. Em vez de t er que program ar cada um dos elet rodomést icos (TV, comput ador, vídeo, DVD, babá elet rônica, ent re out ros), ele poderia programar uma única função que fizesse com que qualquer disposit ivo com um cont role de volum e abaixasse seu volum e ao t oque do t elefone.
Ainda que, mesmo dez anos após sua idealização, a Web ainda não est eja in serida no
dia-a-dia das pessoas como os aut ores sugeriram, percebe-se que as t ecnologias
informacionais caminham para t al.
Perant e a complexidade idealizada para uma Web Semânt ica, o foco dest a pesquisa é
o carát er organizacional dest a nova fase, que busca organizar eficient ement e os cont eúdos
disponibilizados na Web, t endo em vist a uma recuperação mais adequada. O objet ivo da
Web Semânt ica é “ permit ir que máquinas façam o processament o que at ualment e [...] deve
ser realizado por seres humanos” (BREITM AN, 2005, p. 7). Cont udo, é válido enfat izar que os
agent es da Web Semânt ica não subst it uirão as pessoas, já que est es não serão capazes de
t omar decisões criat ivas. Suas funções serão as de “ reunir, organizar, selecionar e apresent ar
as informações” (BREITM AN, 2005, p. 8), para t omada de decisões.
O projet o da Web Semânt ica se paut a no desenvolviment o e implant ação de padrões
t ecnológicos que facilit em a int eroperabilidade de informações ent re agent es humanos e
não humanos, a part ir do est abeleciment o de linguagens, arranjos e relacionament os
apropriados para o compart ilhament o de dados ent re sist emas de informação.
O emprego de t ecnologias capazes de at ribuir semânt ica aos recursos informacionais
possibilit a uma recuperação mais eficient e no cont ext o digit al, permit indo, ent ão, que as
quest ões dirigidas a um sist ema por meio de um mecanismo de busca obt enham respost as
mais relevant es ao int eresse de seu usuário, levando em cont a não soment e a agilidade da
pesquisa e a quant idade dos recursos recuperados, mas sim a qualidade informacional
desses recursos e possível maior relevância a quem necessit a deles. É int eressant e ressalt ar,
porém, que a relevância informacional é sempre relat iva e envolve fat ores humanos, que
Adicionar semânt ica aos cont eúdos, de forma que as máquinas possam int erpret
á-las, leva à reflexão sobre como esse processo poderá ocorrer. Para que a Web Semânt ica
seja possível é necessário que diversas ferrament as t ecnológicas t rabalhem de forma
int egrada em sua est rut ura de implement ação. Esse capít ulo é dedicado, ent ão, a apresent ar
e explicar como surgiu a ideia da Web Semânt ica, part indo do princípio da Web, explorando
alguns conceit os que a permeiam, com base em t rabalhos realizados por grandes nomes da
área da Ciência da Informação e da Tecnologia, e abordando, por fim, como essa “ nova
Web” se est rut ura e quais são os element os essenciais ao seu funcionament o.
2.1 Contribuições pré-W eb
O ser hum ano evolui no m undo a part ir da mat uração da ment alidade que se t em em
um det erminado período. Ent ret ant o, a evolução de fat o ocorre a part ir da iniciat iva de uma
minoria que consegue, de cert a forma, prever, ou simplesment e, imaginar como poderá ser
o fut uro, sem necessariament e se paut ar no que já exist e ou é comum. As invenções e
inovações que deram base ao cresciment o da t ecnologia são frut o de pensament os que iam
sempre além da época em que se vivia.
Apresent am-se abaixo, algumas das cont ribuições e ideias que, diret a ou
indiret ament e, impulsionaram grandes ment es a pensarem uma Web como ela é hoje em
dia ou como ainda, possivelment e, virá a ser.
2.1.1 Vannevar Bush
Em seu t ext o “ As w e may t hink” , publicado no ano de 1945, Bush já demonst rava
preocupações quant o a assunt os que muit o se aproximam de abordagens at uais. Trat a de
assunt os que envolvem os avanços da ciência pós Segunda Guerra M undial, os benefícios da
ciência para o homem, t ant o em relação a bens mat eriais, quant o aos progressos nas áreas
da saúde. Para ele, a ciência promove uma maior comunicação ent re indivíduos.
Bush, há mais de seis décadas at rás, já t inha em sua ment e a import ância do
armazenament o, do t rat ament o e, sobret udo, da recuperação de informações, afirmando
principalment e consult ado (BUSH, 1945). Seus pensament os podem ser considerados
visionários, como no seguint e t recho, no qual se refere um novo suport e de arm azenam ent o
de informações, ainda não desenvolvido na época: “ Toda Enciclopédia Brit ânica poderia ser
reduzida ao volume de uma caixa de fósforos. Uma bibliot eca de um milhão de volumes
poderia caber no cant o de nossa mesa” (BUSH, 1945). Hoje, t ais afirmações se fazem reais se
comparadas ao uso de disposit ivos de memória flash, como os já populares pen drives e
cart ões de memória, que suport am grandes volumes de informação em um chip diminut o,
cujos circuit os podem ser t ão finos quant o fios de cabelo.
M uit o ant es de se começar a pensar na possibilidade da Int eligência Art ificial, Bush
fazia comparações ent re o pensament o humano e processos lógicos da arit mét ica e
est at íst ica. Discut ia a capacidade das máquinas de represent ar o pensament o por meio da
manipulação de números e equações, cont udo afirmava que “ se a racionalidade cient ífica se
reduzisse aos processos lógicos da arit mét ica, não iríamos muit o longe em nosso
conhecim ent o de mudar o m undo físico” (BUSH, 1945, t radução nossa).
Ao t rat ar da recuperação da informação, Bush fala das bibliot ecas, crit icando os
sist emas (cat álogos) da época e a forma como as informações são cat alogadas, classificadas
e indexadas, t raçando um paralelo com o raciocínio humano:
Quando se armazenam dados de qualquer classe, eles são post os em ordem alfabét ica ou numérica, e a inform ação pode ser localizada seguindo-se uma t rilha por meio de classes e subclasses. [...] Há cert as regras para localizá-la, regras est as que são incômodas e complicadas. E uma vez encont rado um dos elem ent os, deve-se sair do sist ema para t omar um novo rumo. (BUSH, 1945, t radução nossa)
E prossegue:
A m ent e humana não funciona dest a forma, ela opera por meio de associações. Quando um elem ent o est á ao seu alcance, salt a inst ant aneament e para o seguint e, que é sugerido pela associação de pensament os segundo um a int rincada rede de at alhos cont idas nas células do cérebro. (BUSH, 1945, t radução nossa)
Bush afirma, ent ão que os processos cognit ivos não serão reproduzidos e que não se
deveria esperar que as máquinas realizassem as associações ment ais com a mesma
velocidade e eficiência que os seres humanos, mas que poderiam ser superiores à ment e
humana em relação à permanência e clareza na recuperação de informações como, por
exemplo, em um acervo bibliográfico.
Sua principal ideia foi a do M EM EX. Como o próprio nome sugere, M emory Ext ension,
no qual seu propriet ário poderia arm azenar t odos os seus livros, arquivos, gravações, dent re
out ros. Seria como uma mesa mecânica pessoal cujos document os (recursos informacionais)
armazenados poderiam ser facilment e recuperados.
Ao falar sobre o M EM EX, Bush já fala em uma “ indexação associat iva” , que consist iria
em possibilit ar a cada element o localizar out ros element os relacionados au t omat icament e.
Discussões nesse âmbit o são realizadas at é os dias de hoje, no que se t rat a de ot imizar a
recuperação das informações, por meio do uso de t axonomias, folksonomias e ont ologias.
Em 1945, o projet o do M EM EX, indubit avelment e, era algo excênt r ico e genioso, que
serviu como prot ót ipo às primeiras ideias de comput adores pessoais. Os deskt ops ou
not ebooks at uais podem ser facilment e comparados ao M EM EX, não soment e em sua
ut ilidade e capacidade de armazenament o de informações midiát icas, mas t ambém em
relação a aspect os visuais e est rut urais. O projet o de Bush, apesar de sua grandiosidade para
a época, não saiu do papel. Ent ret ant o, foi um dos principais mot ivos pelo qual Vannevar
Bush é coment ado e est udado at é os dias de hoje. O M EM EX é um not ável exemplo de
inovação, que fugia aos padrões e máquinas da época e apresent ava uma propost a nova e
diferenciada frent e às máquinas e sist emas ut ilizados at é ent ão para armazenar e recuperar
informações.
2.1.2 Theodor (Ted) Nelson
Theodor Holm Nelson, ou simplesment e Ted Nelson, é conhecido por t er sido o
criador do hipert ext o e da hipermídia, ainda na década de 1960. Nelson desenvolve suas
pesquisas e projet os há mais de 40 anos, com o int uit o de poder criar uma int erface
t ot alment e int uit iva aos seus usuários, de modo a const ruir um sist ema elet rônico lit erário
de alcance profundo para uso global em sist emas de gerenciam ent o de dados organizados
de m aneira diferenciada do usual. Ele define o seu projet o Xanadu como sendo “ um
paradigma alt ernat ivo para o universo comput acional” (NELSON, 1999, p. 2)
Ao cont rário do que se pensa sobre seu projet o Xanadu, que deu origem ao conceit o
de hipert ext o, ele não foi uma t ent at iva de criar a Web como se t em hoje. Nelson afirma que
t em de hiperlink. Seu projet o serviu como base para Berners-Lee desenvolver a Web que se
t em at ualment e, mas, para Nelson, seus projet os e ideias são t ot alment e dist int os.
O projet o Xanadu t inha a ideia de cr iar uma est rut ura que pudesse redefinir os
soft w ares exist ent es hoje, de modo a quebrar o paradigma criado a part ir da invenção da
Web, sobre a qual t odas as novidades at uais são const ruídas. Ret omando a ideia de
Engelbart , o que Nelson visa com os seus projet os é romper a linha invisível que prende as
inovações aos modelos at uais e ir além.
Nelson (1999, p. 3) é bem claro em sua afirmação: “ a World Wide Web não era no
que est ávamos t rabalhando, era o que t ent ávamos prevenir” . Para ele, a Web é um recurso
limit ado, um fragment o do conceit o ideal que ele busca, que t eria por base o seu conceit o
consolidado de um hipert ext o, diferent e do que foi desenvolvido e se conhece como
hipert ext o, é algo muit o mais complexo, não só levaria o usuário a out ro espaço, mas
permit iria que est e navegasse no espaço e t raçasse t rilhas int uit ivas ent re os cont eúdos que
t ivessem relações ent re si.
Em uma ent revist a dada ao It aú Cult ural, no ano de 2007, Nelson afirma que “ [...] a
Web ficou cheia de lixo. Um pouco de lixo de propaganda, um pouco de lixo gráfico [...]” . Em
out ras palavras, Nelson é idealist a e ext remament e crít ico à Web criada e, sobret udo,
im plem ent ada por Berners-Lee.
2.1.3 Douglas Engelbart
Seguidor dos princípios de Nelson e inspirado nas ideias de Bush, Douglas Carl
Engelbart ficou conhecido por ser o invent or do mouse e por ser um dos primeiros a se
int eressar pelos est udos sobre a int eração ent re humanos e comput adores.
Barret o (2011), sobre a invenção de Engelbart , afirma que
O usuário, por meio do mouse foi colocado na t ela do comput ador e suas múlt iplas janelas de t rabalho com a possibilidade de manipular, com complexos arquivos de informação represent ados, um símbolo gráfico; pelas conexões associat ivas de grafos dinâmicos e o " processament o de ideias" .
Levando em cont a a forma como as informações eram apresent adas nos
comput adores ant es da implant ação da int erface gráfica, a invenção do mouse foi um a
Engelbart (2003) diz que “ os invest iment os em inovação são míopes e focados nas
coisas erradas” . Nesse t ext o, ele lança maneiras de ot im izar infraest rut uras que result em em
inovações capazes de mudar a comput ação e solucionar problemas por meio dela.
O pont o principal de sua fala e, coincident ement e, o que converge ent re as ideias de
Bush e Nelson t ambém, é just ament e a necessidade de inovar, t ema que Engelbart divide
ent re inovações cont ínuas e inovações descont ínuas. Para ilust rar esses dois conceit os, ele
cit a o exemplo: se t odos andassem em t riciclos, a inovação cont ínua seria responsável por
const ruir t riciclos cada vez melhores, mais eficient e e mais confort áveis; ent ret ant o, a
biciclet a nunca seria invent ada. Essa quebra de paradigma é chamada de inovação
descont ínua. Tal conceit o se faz ext remament e necessário e present e no desenvolviment o
de novas t ecnologias, que necessit am ser cada vez mais eficient es para que possam at ender
necessidades de qualquer nat ureza, de seus usuários. Engelbart , desde a criação do mouse,
demonst rou em seus t rabalhos perceber a im port ância das int erfaces gráficas e da
colaboração no ambient e digit al.
Nesse sent ido, pode-se pensar que as at uais m udanças no paradigm a da Web podem
ser consideradas, em cert a ót ica, inovações descont ínuas, se levado em cont a o fat o de a
Web t er passado de uma plat aforma est át ica, para um a t ot alm ent e dinâmica e int erat iva.
2.2 DA W EB À W EB SEM ÂNTICA
“ Da primeira comercialização (1995), passando pela sua consolidação (1996), at é sua
banalização (1998), a Web se convert eu no fenôm eno social mais import ant e do século XX.”
(ROBREDO, 2005, p. 248) O século XX foi marcado por grandes mudanças e acont eciment os
ocasionados pela relação dos seres humanos com a sua espécie e seu meio. Dent re os
muit os fat os ocorridos, um de grande dest aque foi a Guerra Fria, na década de 1960, ent re a
ext int a União Soviét ica (URSS) e os Est ados Unidos. Nesse período de guerras, a
comunicação era algo absolut ament e necessário, assim como o sigilo e segurança das
informações.
Nesse cont ext o, surge a ARPANET, uma rede com fins milit ares que possibilit aria a
descent ralização da comunicação e das informações mant idas nos bancos de dados
t ransmissão de pequenos pacot es de dados. Nessa época t ambém ficou marcada a primeira
comunicação feit a via e-mail.
A Web (t ermo ut ilizado para se referir à WWW – World Wide Web – a rede mundial
de comput adores) foi idealizada com base nos conceit os de hipert ext o e hipermídia,
propost os no projet o XANADU, de Ted Nelson, no ano de 1960. Tim Berners-Lee, por sua
vez, no ano de 1989, uniu os conceit os de Nelson com a Int ernet , criando ent ão a Web como
uma plat aforma, inicialment e, com fins acadêmicos. Com seus avanços, e a part ir da
popularização dos comput adores pessoais, t ornou-se possível a ut ilização dest a imensa rede
como um meio de comunicação, no qual o usuário passa a t er acesso a cont eúdos e at é
mesmo criar páginas, a priori, soment e informat ivas.
A Int ernet soment e permit ia int ercambiar mensagens por via elet rônica ou t ransferir
dados. Berners-Lee criou um programa que possibilit ava a criação de links ent re nós
aleat órios, sendo at ribuídos a cada um deles um t ít ulo, um t ipo e uma list a de links
bidimensionais t ipificados. Foi a part ir de um projet o de 1989 que sua pesquisa ganhou
visibilidade no CERN (Cent re Européen de Recherches Nucléaires), onde conseguiu
aut orização para o desenvolviment o e implant ação de uma nova versão de seu projet o, que
recebeu o nom e de “ World Wide Web” . Desde o seu surgiment o, a Web, vem se
desenvolvendo e se t ransformando no maior meio de comunicação que já exist iu em t oda a
hist ória humana.
Barret o (2011) sint et iza vários dos grandes acont eciment os t ecnológicos do últ imo
século nest e parágrafo:
A produção da informação se processa hoje, como uma cult ura de muit as vozes produzindo uma narrat iva int ert ext ual. Na hist ória da informação dos últ imos cinquent a anos vemos que ela se ent relaça com própria hist ória do século vint e. Dent ro do período acont eceram import ant es junções da informação com a inovação que viriam para mudar a face do mundo. É, part icularment e, not ável o período ent re 1945 at é 1948 quando uma bolha t ecnológica nos deu a fissão nuclear que produziu a primeira bomba at ômica, o Eniac e depois o Univac-1, os primeiros comput adores de aplicação geral, Alexander Fleming descobriu a Penicilina no em Londres, um avião voou mais rápido do que o som, foi invent ado o t ransist or, foi fundada a Unesco, Norbert Wiener publicou Cybernet ics, a t eoria mat emát ica da informação e Vannevar Bush publicou " As w e may t hink.”
A Web, t ermo pelo qual a Rede M undial de Comput adores ficou conhecida, passou
por diversos moment os, definidos, principalment e pelas mudanças t ranscorridas em sua
t ecnologias, que, a t odo inst ant e, t orna necessária a at ualização dos padrões e ferrament as
cada vez mais avançadas. Isso gerou, no ambient e Web, a nít ida divisão ent re a primeira fase
e a fase at ual, cham ada por Tim O’Reilly (2005) de Web 2.0, e assim se popularizou.
A Web deve ser ent endida como part e da Int ernet e não como um sinônimo dela. É
m uit o import ant e que haja dist inção ent re a Int ernet e a WWW: a primeira é uma rede de
milhões de comput adores int erligados, que compart ilham informações mediant e o uso de
prot ocolos comuns de comunicação; a segunda, conhecida pelo t ermo Web, é uma aplicação
da Int ernet , que permit e a disseminação e a t ransferência de informações e de cont eúdos
mult imidiát icos por meio da navegação por links hipert ext uais.
Em sua primeira fase, a Web t inha como caract eríst ica ser um ambient e digit al
hipert ext ual de t roca de informações. Idealizada para uso de especialist as e cient ist as, era
um meio de divulgação, não muit o diferent e dos meios de comunicação de massa já comuns
na época, como a t elevisão ou o rádio. Funcionava por meio do prot ocolo HTTP (Hypert ext
Transfer Prot ocol) e com o uso de um navegador simples podia acessar as páginas cujo
endereço fosse conhecido. Não havia int eração ent re o usuário leit or e o cont eúdo
apresent ado.
A Web passou a ser chamada de Web 2.0 a part ir da ut ilização de novas linguagens
de programação que permit iam ao usuário int eragir com os cont eúdos. Surgem ent ão
páginas Web de fácil manipulação: foram criados sit es cujo cont eúdo poderia ser coment ado
por seus leit ores, os chamados Blogs; surgiram os Wikis, páginas informat ivas de carát er
t ot alment e colaborat ivo; as Redes Sociais, páginas nas quais os usuários podem int eragir
at ivament e com out ros usuários da mesma ou de out ra rede, t rocando mensagens,
cont eúdos, imagens, sons e vídeos; os microblogs, que permit em post agens rápidas e
sucint as, como at ualizações de st at us e compart ilhament o de informações; dent re out ras
iniciat ivas que foram sendo criadas t endo por base o avanço das t ecnologias de informação
e comunicação (TIC).
A principal diferença ent re Web 1.0 e Web 2.0 é que a primeira era mais rest rit a, a
maior part e dos usuários era consumidor. Já na segunda dest aca-se por permit ir que
qualquer part icipant e possa ser um criador de cont eúdo. Diversos recursos t ecnológicos
foram criados para maximizar o pot encial dessa criação. A nat ureza democrát ica da Web 2.0
int eresses, que podem t rocar cont eúdos de qualquer t ipo (t ext o, áudio, vídeo , et c.), fazer
coment ários e compart ilhar links, t ant o para públicos rest rit os, como páginas de grupos,
como para o público em geral. (CORM ODE; KRISHNAM URTHY, 2008)
No cont ext o at ual, há uma int erligação das informações e dos serviços disponíveis na
Web: o chat , popularizado pelas salas de bat e-papo e programas específicos de comunicação
Web, é hoje incorporado às redes sociais e serviços de e-mail; post agens feit as em uma rede
social específica podem ser compart ilhadas e visualizadas em out ras que o usuário t enha
acesso, por exemplo, uma post agem feit a pelo Tw it t er1 pode facilment e ser disseminada no
Facebook2, LinkedIn3 ou out ra rede, e fot os post adas pelo aplicat ivo Inst agram4, para
smart phones, podem ser divulgadas e visualizadas em diversas redes sociais
simult aneament e.
A Web Semânt ica, por sua vez, se caract eriza por ser uma nova fase da Web, na qual
as informações dispersas na Int ernet são semant icament e descrit as de modo a serem
recuperadas com maior eficiência e relevância por mot ores de busca. A propost a de at ribuir
significado às páginas Web para que sejam int erpret adas por m áquinas surgiu no ano de
2001, a part ir da publicação de um art igo na revist a americana Scient ific American, cujo
t ít ulo é: “ Web Semânt ica: um novo format o de cont eúdo para a Web com significado para
comput adores vai iniciar uma revolução de novas possibilidades” . Tal art igo foi publicado
por Tim Berners-Lee (diret or do W3C e pesquisador do Inst it ut o de Tecnologias de
M assachuset t - M IT), James Hendler (professor da Universidade de M aryland) e Ora Lassila
(pesquisador e membro do W3C), e é at é hoje um t ext o referência sobre Web Semânt ica,
pois nele os aut ores definem seus principais conceit os, est rut ura e ilust ram as sit uações que
esse novo moment o da Web pode proporcionar. (BERNERS-LEE; HENDLER; LASSILA, 2001)
Sobre o W3C, Robredo (2005, p. 250) discorre:
O Consórcio W3 é financiado pelos vários cent ros das ent idades m embros em t odo o mundo. Sua missão essencial é produzir as normas t écnicas necessárias para a evolução [e] desenvolvim ent o harmônicos da Web. Os objet ivos principais visam o aprimorament o da acessibilidade, da eficiência e da qualidade.
1
Twitter. Disponível em: <http://twitter.com> Acesso em: 15 abr. 2013
2
Facebook. Disponível em: <http://facebook.com> Acesso em: 15 abr. 2013
3
LinkedIn. Disponível em: <http://linkedin.com> Acesso em: 15 abr. 2013
4
De acordo com Breit man (2005, p. 5), “ a ideia cent ral da Web Semânt ica é
cat egorizar a informação de maneira padronizada, facilit ando seu acesso” . Tais cat egorias
seriam semelhant es a classificações e t axonomias, ut ilizadas, por exemplo, por biólogos para
classificar os seres vivos. Classificações que fossem criadas e compart ilhadas por diversos
pesquisadores do m undo t odo, na int enção de est abelecer um modelo est rut urado para
organizar a bagunça informacional da Int ernet .
Para Robredo (2005, p. 252), a Web Semânt ica pode ser descrit a como “ algo capaz de
fazer para a represent ação do conheciment o o que a Web hipert ext ual fez para o
hipert ext o” , e complet a: “ faz part e do processo para complet ar o sonho original da Web.” :
um ambient e no qual se pode criar um espaço universal de acesso livre às informações.
Cont udo, ant es de aprofundar o assunt o da Web Semânt ica, os aut ores Heflin,
Hendler e Luke (2000, p. 1-2) dest acam algumas caract eríst icas que se deve t er em ment e ao
pensar sobre a Web, quest ões que envolvem t ant o o seu passado, como o seu fut uro:
x
A Web é dist ribuída. Uma vez que a Web é produt o da ação de muit as pessoas, ainexpressividade de um cont role cent ral apresent a grandes desafios de como lidar
com t oda a informação nela disponibilizada. Um primeiro desafio seria o seu uso por
diversas comunidades, o que implica no uso de diferent es vocabulários, causando
problemas de sinônimos e polissemia (o primeiro dizendo respeit o a palavras
diferent es que possuem o mesmo significado e o segundo, palavras idênt icas que
possuem significados diferent es). Um segundo desafio seria admit ir a inconsist ência
e inexat idão exist ent e nas informações Web, que não são necessariament e
int roduzidas por pessoas qualificadas, o que significa que cada página Web pode ser
quest ionada. Além disso, por não exist irem rest rições em relação à int egridade dos
cont eúdos, poderá haver conflit os ent re as informações (o que pode ocorrer devido a
múlt iplos fat ores, como discordâncias polít icas, religiosas, cult urais, et c.), e qualquer
t ent at iva de impedir t ais inconsist ências sempre irá favorecer a uma das opiniões
envolvidas.
x
A Web é dinâmica. As t ransformações da Web ocorrem em velocidade e rapidez quenem sempre os usuários ou mesmo agent es de soft w are conseguem acompanhar seu
desenvolviment o. Enquant o novas páginas são criadas, o cont eúdo das já exist ent es