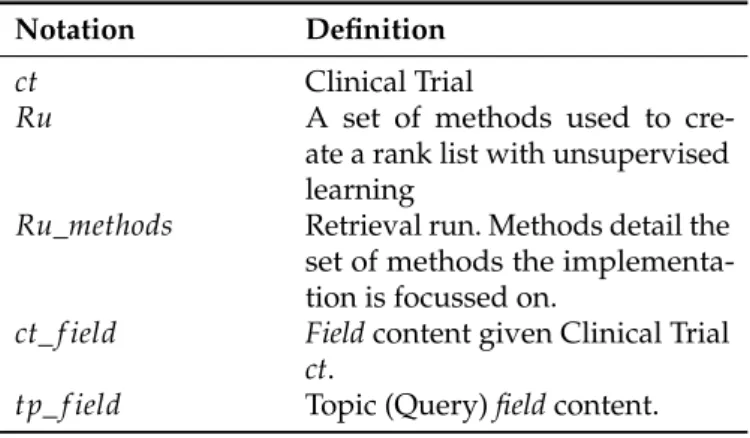
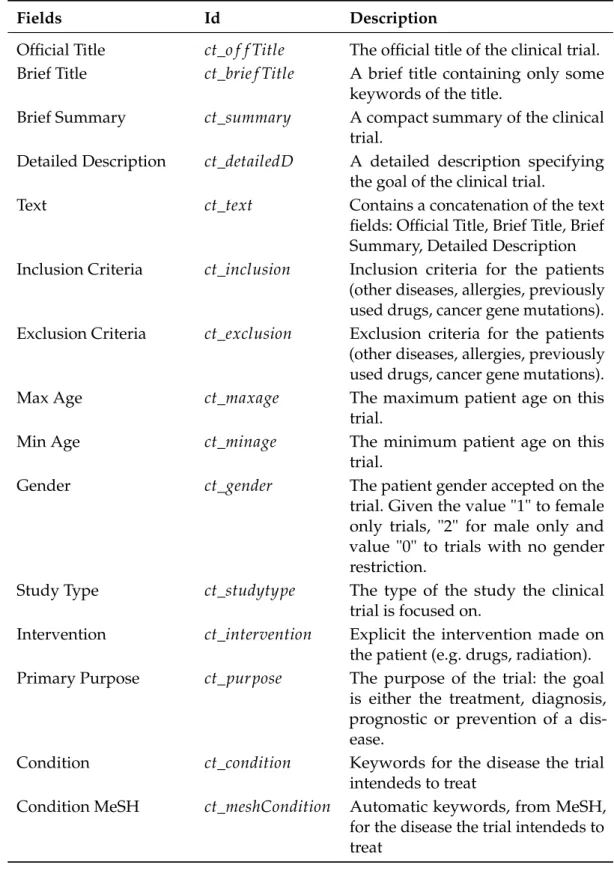
Biomedical information extraction for matching patients to clinical trials
118
0
0
Texto
Imagem
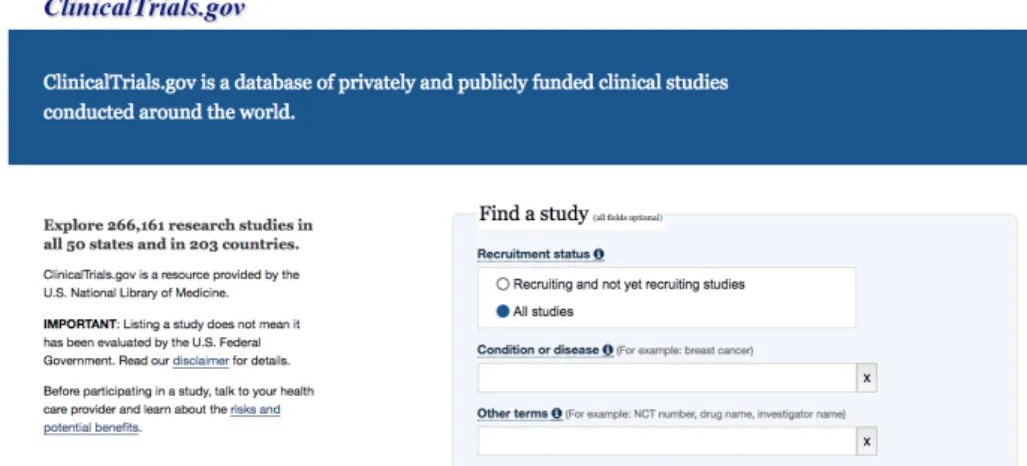
![Figure 2.1: All fundamental stages of cancer development. This image was extracted from [38].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19186048.947609/28.892.201.645.143.366/figure-fundamental-stages-cancer-development-image-extracted.webp)
![Figure 2.2: The clinical trial workflow, extracted from [65].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19186048.947609/30.892.270.582.212.883/figure-clinical-trial-workflow-extracted.webp)
+7

Documentos relacionados