PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
PUC-SP
Denise Delegá-Lúcio
A variação entre textos argumentativos e o material didático de
inglês: aplicações da análise multidimensional e do Corpus
Internacional de Aprendizes de Inglês (ICLE)
DOUTORADO EM LINGUÍSTICA APLICADA E ESTUDOS DA LINGUAGEM
SÃO PAULO
PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
PUC-SP
Denise Delegá-Lúcio
A variação entre textos argumentativos e o material didático de inglês:
aplicações da análise multidimensional e do Corpus Internacional de
Aprendizes de Inglês (ICLE)
DOUTORADO EM LINGUÍSTICA APLICADA E ESTUDOS DA LINGUAGEM
Tese apresentada à Banca Examinadora da Pontifícia Universidade Católica de São Paulo, como exigência parcial para obtenção do título de DOUTORA em Linguística Aplicada e Estudos da Linguagem, sob a orientação do Prof. Dr. Antônio Paulo Berber Sardinha.
SÃO PAULO
Tese defendida e aprovada em ___ / ___ / ___
Banca Examinadora
______________________________
______________________________
______________________________
______________________________
______________________________
______________________________
AGRADECIMENTOS
Antes de tudo, eu gostaria de agradecer aos meus irmãos, Douglas e Débora; nossos anos de convivência, em meio a dificuldades, brigas, amores, desamores, tempestades e bonanças, moldaram meu caráter e fizeram-me ter a determinação necessária para desenvolver uma tese como esta.
Agradeço ao meu pai, que sempre entendeu e “alimentou” meu lado geek/nerd
e, ainda por cima, orgulha-se disso.
Agradeço com todo o meu amor, carinho e respeito, ao meu marido, Rodrigo, e ao meu filho, Gabriel, pela imensa paciência, dedicação, abdicação e pelo encorajamento que me permitiram chegar aqui.
Agradeço ao Prof. Dr. Tony Berber Sardinha, meu caríssimo orientador, cujos ensinamentos, atenção e insights são um privilégio para poucos. Somente você,
Tony, com sua infinita paciência, para convencer uma pesquisadora rebelde como eu a realizar uma pesquisa tão minuciosa e detalhada como esta tese. Muito obrigada mesmo!
Agradeço ao Grupo de Estudos em Linguística de Corpus (Gelc) e todos os seus integrantes; sem seus questionamentos ora intrigantes, ora divertidos, ora perturbadores, minha pesquisa seria, sem dúvida, muito mais pobre. Cito, em especial, a Cristina Mayer Acunzo, a Maria Cecília Lopes, a Renata Condi de Souza, a Rosana de Barros Silva e Teixeira e a Telma de Lurdes São Bento Ferreira, pelo apoio de sempre.
Agradeço aos professores que participaram dos meus exames de qualificação e defesa: Profa. Dra. Maria Aparecida Caltabiano Magalhães Borges da Silva, Profa. Dra. Maria Cecília Lopes, Profa. Dra. Patrícia Bértoli-Dutra, Profa. Dra. Sandra Madureira, Prof. Eduardo de Carvalho Cassimiro, Profa. Dra. Solange Gervai, Profa. Dra. Renata Condi de Souza.
Agradeço aos meus colegas do curso Teachers’ Links: Profa. Dra. Solange Gervai, Prof. Dr. Francisco Estefogo, Profa. Dra. Andrea da Silva Marques Ribeiro, Profa. Dra. Maria Paula Wadt e Profa. Elizabeth Pow, que me incentivaram com carinho e gentileza.
tecnologia e por toda a atenção de seu grupo de pesquisa.
Agradeço, ainda, ao Evandro Lisboa Freire, do Grupo de Estudos de Linguística de Corpus (Gelc/Lael), pela criteriosa edição de texto desta tese e por todas as suas sugestões.
Fairy tales are more than true:
not because they tell us that dragons exist,
but because they tell us that dragons can be beaten.
(Neil Gaiman, Coraline)
I can’t go back to yesterday
SUMÁRIO
LISTA DE FIGURAS ... 13
LISTA DE GRÁFICOS ... 19
LISTA DE QUADROS ... 21
LISTA DE TABELAS ... 23
RESUMO ... 25
ABSTRACT ... 27
INTRODUÇÃO ... 29
Justificativa ... 36
Objetivos e perguntas de pesquisa ... 37
1. FUNDAMENTAÇÃO TEÓRICA ... 41
1.1. A Linguística de Corpus ... 42
1.1.1. Breve histórico da Linguística de Corpus ... 42
1.1.2. Estudos em outras áreas de pesquisa linguística ... 44
1.1.3. A Linguística de Corpus e o ensino de línguas ... 47
1.1.4. Corpus: definição, característica e tipos ... 50
1.1.5. Padrão, colocação, coligação e as concordâncias ... 52
1.2. A Linguística de Corpus de Aprendiz ... 54
1.3. A Análise Multidimensional ... 56
1.3.1. Breve histórico ... 56
1.3.2. Definições específicas ... 58
1.3.3. Características da Análise Multidimensional ... 61
1.3.3.1. AMD e as pesquisas no ensino ... 63
1.3.3.2. AMD e as pesquisas com corpora de aprendiz ... 66
1.4. Desenvolvimento de atividades didáticas ... 68
1.4.1. Ensino guiado pelos dados ... 70
1.4.1.1. Proposta de Ramos ... 71
1.4.1.2.1. Atividades com corpora
centradas nas concordâncias ... 74
1.4.1.2.2. Atividades com corpora centradas no texto ... 75
1.4.1.2.3. Atividades com corpora centradas em materiais multimídia e/ou multigêneros ... 76
2. REFERENCIAL TEÓRICO ... 79
2.1. A argumentação ... 79
2.2. Ensino aprendizado de línguas ... 83
2.2.1. Behaviorismo ... 83
2.2.2. As hipóteses de Krashen ... 85
2.2.3. O ensino comunicativo ... 87
2.2.4. O aprendizado consciente ... 88
3. METODOLOGIA ... 91
3.1. Descrição dos corpora ... 91
3.1.1. Corpora de estudo ... 92
3.1.2. Corpus de referência ... 94
3.2. Descrição dos programas computacionais utilizados ... 97
3.2.1. IBM SPSS Statistics, versão 20 ... 97
3.2.1.1. As janelas ... 97
3.2.1.2. O menu da tecla “analisar” ... 99
3.2.1.3. O menu da tecla “transformar” ... 99
3.2.2. O Bibber Tagger e a etiquetagem ... 100
3.2.3. O Biber Tag Count ... 102
3.2.4. O WordSmith Tools ……… 103
3.3. Procedimentos de análise ... 105
3.3.1. Mapeamento das dimensões de Biber ... 105
3.3.2. Extração de fatores para as dimensões das redações ... 108
3.3.3. Seleção de conteúdos das atividades didáticas e critérios adotados ... 111
4. ESTUDO PILOTO ... 123
4.1. Metodologia ... 123
4.3. Implicações ... 131
5. RESULTADOS ... 135
5.1. Mapeamento das dimensões ... 135
5.1.1. Mapeamento da dimensão 1 ... 135
5.1.2. Mapeamento da dimensão 2 ... 140
5.1.3. Mapeamento da dimensão 3 ... 144
5.1.4. Mapeamento da dimensão 4 ... 148
5.1.5. Mapeamento da dimensão 5 ... 152
5.2. Dimensões das redações argumentativas ... 156
5.2.1. A fatoração das variáveis ... 156
5.2.2. Interpretação dos fatores ... 166
5.2.2.1. Dimensão 1: “escrita letrada” versus “escrita narrativizada e oralizada” ... 173
5.2.2.2. Dimensão 2: “escrita com foco na descrição” versus “escrita com foco no agir” ... 178
5.2.2.3. Dimensão 3: “escrita com foco no pensamento e no relato” ... 181
5.2.2.4. Dimensão 4: “escrita qualificativa” ... 185
5.2.3. Aplicação da AMD em atividades didáticas ... 189
5.2.3.1. Seleção dos conteúdos para as atividades de familiarização ... 191
5.2.3.2. Seleção dos conteúdos para as atividades de detalhamento ... 198
5.3. Discussão dos resultados ... 209
REFERÊNCIAS ... 213
LISTA DE FIGURAS
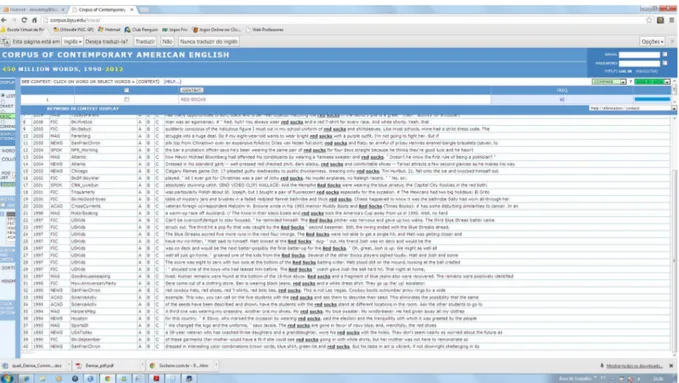
FIGURA 3.1 – Amostra de concordância no COCA: red socks ... 96
FIGURA 3.2 – A ferramenta Keyword in Context do COCA ... 96
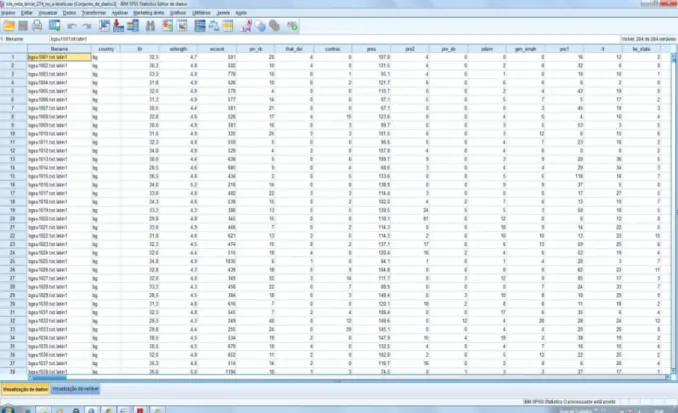
FIGURA 3.3 – Editor de dados do SPSS ... 98
FIGURA 3.4 – Visualizador do SPSS ... 98
FIGURA 3.5 – Escore positivo ... 113
FIGURA 3.6 – Escore negaitvo ... 114
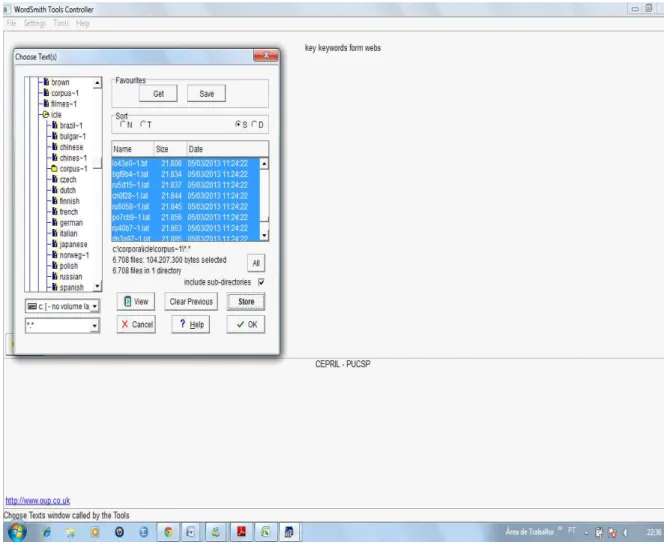
FIGURA 3.7 – Seleção de textos no WordSmith Tools ... 115
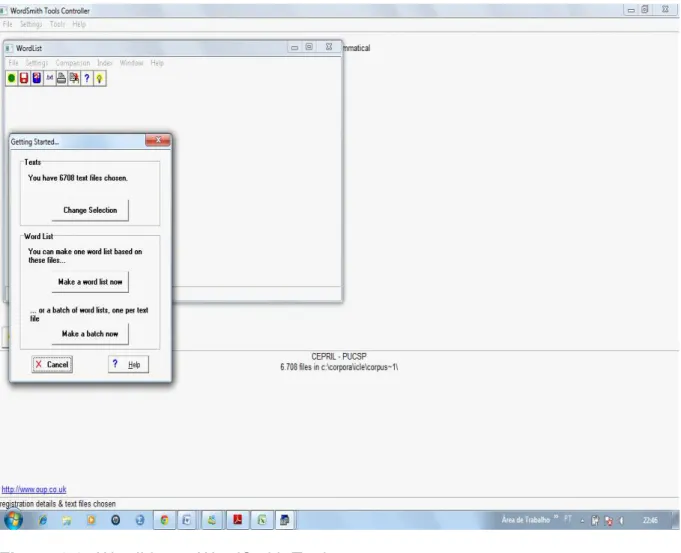
FIGURA 3.8 – WordList no WordSmith Tools ... 116
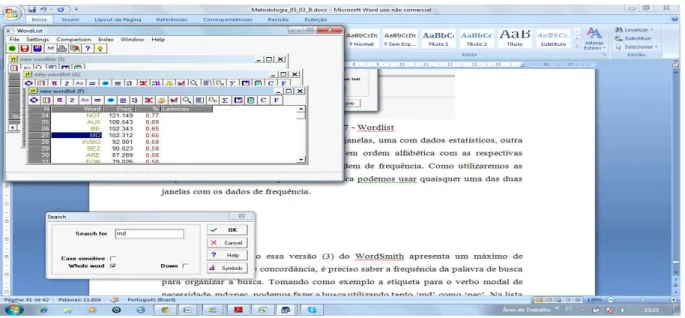
FIGURA 3.9 – Janelas do WordList no WordSmith Tools ... 117
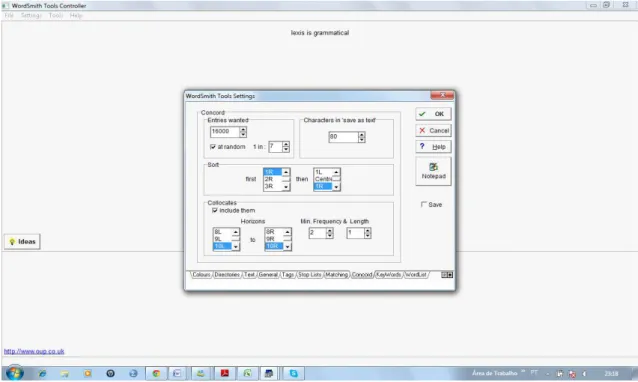
FIGURA 3.10 – Settings do Concord no WordSmith Tools ... 118
FIGURA 3.11 – Concordâncias com “md” no WordSmith Tools ... 118
FIGURA 5.1 – Extração inicial no SPSS ... 157
FIGURA 5.2 – Escolha de variáveis no SPSS ... 158
FIGURA 5.3 – Descritivos no SPSS ... 158
FIGURA 5.4 – Extração no SPSS ... 159
FIGURA 5.5 – Diagrama de sedimentação ... 163
FIGURA 5.6 – Proporção máxima ... 164
FIGURA 5.7 – Número fixo de fatores ... 165
FIGURA 5.8. Concordâncias para “nn” ... 201
FIGURA 5.9 – Colocados à direita de violence ... 205
LISTA DE GRÁFICOS
GRÁFICO 4.1 – Distribuição dos países na dimensão 1 ... 128
GRÁFICO 4.2 – Distribuição dos países na dimensão 4 ... 131
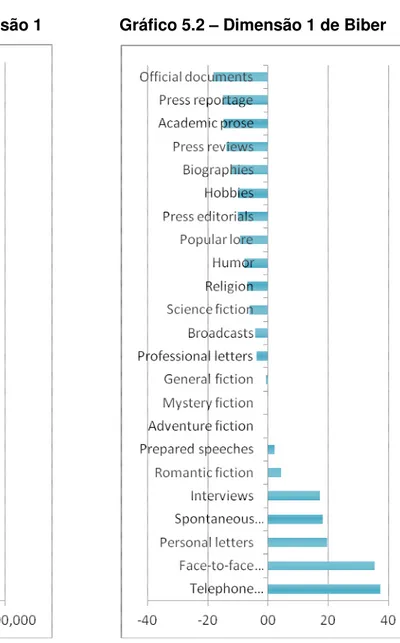
GRÁFICO 5.1 – Redações na dimensão 1 ... 136
GRÁFICO 5.2 – Dimensão 1 de Biber ... 136
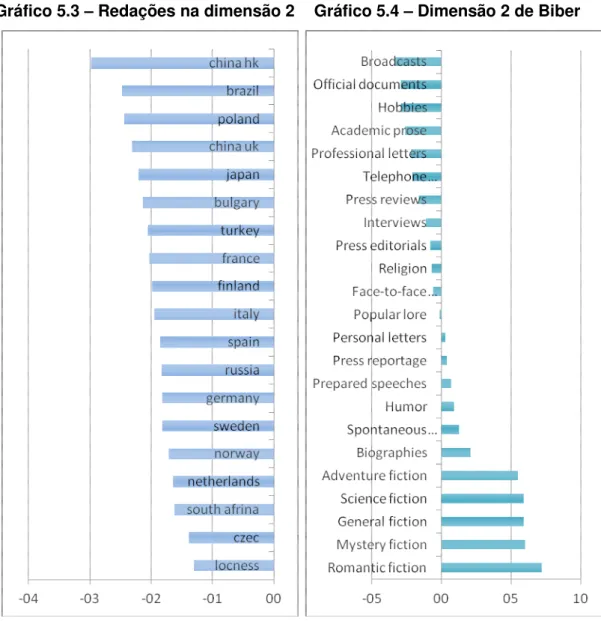
GRÁFICO 5.3 – Redações na dimensão 2 ... 141
GRÁFICO 5.4 – Dimensão 2 de Biber ... 141
GRÁFICO 5.5 – Redações na dimensão 3 ... 145
GRÁFICO 5.6 – Dimensão 3 de Biber ... 145
GRÁFICO 5.7 – Redações na dimensão 4 ... 149
GRÁFICO 5.8 – Dimensão 4 de Biber ... 149
GRÁFICO 5.9 – Redações na dimensão 5 ... 153
LISTA DE QUADROS
QUADRO 3.1 – Amostra de etiquetagem do VISL ... 100
QUADRO 3.2 – Amostra de etiquetagem do Tree Tagger ... 101
QUADRO 3.3 – Amostra de etiquetagem do Biber Tagger ... 101
QUADRO 3.4 – Concordâncias com must ... 119
QUADRO 3.5 – Concordâncias com must expandidas como sentença ... 120
QUADRO 3.6 – Concordâncias com must expandidas como parágrafo ... 120
QUADRO 4.1 – Redação com escores altos para envolvimento e conteúdo informacional: Japão ... 129
QUADRO 4.2 – Redação com escores altos para envolvimento e conteúdo informacional: China ... 129
QUADRO 5.1 – Amostra de redação de aluno russo ... 138
QUADRO 5.2 – Amostra de redação de aluno chinês ... 139
QUADRO 5.3 – Redação de aluno chinês ... 144
QUADRO 5.4 – Redação de aluno falante nativo de inglês ... 144
QUADRO 5.5 – Redação de aluno da África do Sul ... 148
QUADRO 5.6 – Redação de aluno falante nativo de inglês ... 148
QUADRO 5.7 – Redação de aluno turco (1) ... 151
QUADRO 5.8 – Redação de aluno turco (2) ... 152
QUADRO 5.9 – Texto com escore mais alto no polo negativo ... 155
QUADRO 5.10 – Texto com escore mais alto no polo positivo ... 156
QUADRO 5.11 – advérbios + to infinitivo ... 172
QUADRO 5.12 – Amostra de redações com alto e baixo escore individual ... 177
QUADRO 5.13 – Amostra de redações com alto e baixo escore individual (dimensão 2) ... 181
QUADRO 5.14 – Redação de aluno japonês ... 184
QUADRO 5.15 – Redação de aluno sul-africano ... 185
QUADRO 5.16 – Redação de aluno alemão ... 188
QUADRO 5.17 – Redação de aluno sul-africano ... 189
QUADRO 5.18 – Atividade 1 ... 191
QUADRO 5.20 – Atividade 2 ... 194
QUADRO 5.21 – Atividades 3, 4 e 5 ... 195
QUADRO 5.22 – Atividade 6 ... 196
QUADRO 5.23 – Etiquetas para as características da dimensão 1 ... 199
QUADRO 5.24 – Colocações mais frequentes acompanhando a etiqueta “nom” ... 202
QUADRO 5.25 – Lista das colocações mais frequentes de de “vbd” (verbos no passado) ... 203
QUADRO 5.26 – Lista de colocações de “pn” (pronomes indefinidos) ... 204
LISTA DE TABELAS
TABELA 3.1 – Subcorpora de estudo ... 94
TABELA 4.1 – Escores médios para a dimensão 1 ... 127
TABELA 4.2 – Escores médios para a dimensão 4 ... 130
TABELA 4.3 – Escores individuais das redações na dimensão 4 ... 132
TABELA 5.1 – Redações do polo negativo na dimensão 1 ... 138
TABELA 5.2 – Anova da dimensão 1 de Biber em relação ao ICLE ... 139
TABELA 5.3 – Anova da dimensão 2 de Biber em relação ao ICLE ... 141
TABELA 5.4 – Redações do polo negativo na dimensão 2 ... 142
TABELA 5.5 – Redações do polo positivo na dimensão 2 ... 143
TABELA 5.6 – Anova da dimensão 3 de Biber em relação ao ICLE ... 146
TABELA 5.7 – Redações do polo negativo na dimensão 3 ... 146
TABELA 5.8 – Redações do polo positivo na dimensão 3 ... 147
TABELA 5.9 – Redações do polo positivo na dimensão 3 ... 150
TABELA 5.10 – Redações do polo negativo na dimensão 4 ... 150
TABELA 5.11 – Redações do polo positivo na dimensão 4 ... 151
TABELA 5.12 – Anova da dimensão 5 de Biber em relação ao ICLE ... 154
TABELA 5.13 – Redações do polo negativo na dimensão 5 ... 154
TABELA 5.14 – Redações do polo positivo na dimensão 5 ... 155
TABELA 5.15 – Amostra das variáveis da primeira extração ... 160
TABELA 5.16 – Segunda extração no SPSS ... 161
TABELA 5.17 – Escolha de variáveis para os fatores eliminados ... 165
TABELA 5.18 – Variáveis do fator 1 e exemplos ... 167
TABELA 5.19 – Variáveis do fator 2 e exemplos ... 169
TABELA 5.20 – Variáveis do fator 3 e exemplos ... 170
TABELA 5.21 – Variáveis do fator 4 e exemplos ... 171
TABELA 5.22 – Escore médio por origem na dimensão 1 ... 174
TABELA 5.23 – Anova da dimensão 1 ... 175
TABELA 5.24 – Altos escores individuais das redações ... 176
TABELA 5.25 – Baixos escores individuais das redações ... 176
TABELA 5.27 – Anova da dimensão 2 ... 179
TABELA 5.28 – Escores altos (dimensão 2) ... 180
TABELA 5.29 – Escores baixos (dimensão 2) ... 180
TABELA 5.30 – Redações por origem na dimensão 3 ... 182
TABELA 5.31 – Anova da dimensão 3 ... 183
TABELA 5.32 – Escores altos (dimensão 3) ... 183
TABELA 5.33 – Anova da dimensão 3 ... 184
TABELA 5.34 – Escore médio por origem na dimensão 4 ... 186
TABELA 5.35 – Anova da dimensão 4 ... 187
TABELA 5.36 – Escores altos (dimensão 3) ... 187
TABELA 5.37 – Escores baixos (dimensão 3) ... 188
RESUMO
Esta tese tem por objetivo verificar o modo como textos argumentativos produzidos por alunos de inglês variam e, a partir desse conhecimento, sugerir procedimentos para o desenvolvimento de atividades para material didático de inglês. A pesquisa recorre ao arcabouço teórico da Linguística de Corpus, Linguística de Corpus de Aprendiz e Análise Multidimensional. Nossos corpora de estudo foram o International
Corpus of Learner English (ICLE), o Brazilian International Corpus of Learner English (BrICLE) e o Louvain Corpus of Native English Essays (LOCNESS). Na primeira fase desta pesquisa, verificamos o modo como a variação nas redações de aprendizes se distribuía nas dimensões de variação do inglês propostas por Biber (1988). Na segunda fase, identificamos as dimensões de variação específicas nas redações de aprendizes, o que resultou em 4 dimensões de variação: dimensão 1 – escrita letrada versus escrita narrativizada e oralizada; dimensão 2 – escrita com foco na
descrição versus escrita com foco no agir; dimensão 3 – escrita com foco no
pensamento e no relato; e dimensão 4 – escrita qualificativa. Na terceira fase, partimos das características linguísticas observadas na dimensão escrita letrada
versus escrita narrativizada e oralizada para encontrar conteúdos para as atividades
didáticas sobre a variação em textos. Além das atividades sugeridas, apresentamos os procedimentos necessários para utilizar resultados de pesquisas como esta para a produção de materiais didáticos para ensino de línguas.
ABSTRACT
This thesis aims to check the way how argumentative texts produced by English learners vary and, by means of this knowledge, suggest procedures for developing activities for English teaching material. The research resorts to the theoretical framework of Corpus Linguistics, Learner Corpus Linguistics, and Multidimensional Analysis. Our study corpora were the International Corpus of Learner English (ICLE), the Brazilian International Corpus of Learner English (BrICLE), and the Louvain Corpus of Native English Essays (LOCNESS). In the first phase of this research, we checked the way how variation in learner’s essays was distributed along the dimensions of English variation proposed by Biber (1988). In the second phase, we identified the specific variation dimensions in leaner’s essays, something which resulted in 4 dimensions of variation: dimension 1 – literate writing versus narrative-like and oral-narrative-like writing; dimension 2 – description-driven writing versus action-driven writing; dimension 3 – writing focused on thought and report; and dimension 4 – qualifying writing. In the third phase, we addressed the linguistic characteristics observed in the dimension literate writing versus narrative-like and oral-like writing to find contents for the teaching activities about variation in texts. In addition to the suggested activities, we present the procedures needed to use results from researches like this for producing language teaching materials.
INTRODUÇÃO
Ao longo da história do ensino/aprendizado de línguas, muitas foram as dúvidas, as dificuldades e os problemas que surgiram e surgem à medida que se procura novos caminhos. Em alguns momentos, há preocupação quanto ao modo como alguém aprende uma língua e, em outros, em relação ao modo como se ensina uma língua, com foco na oralidade ou na escrita, entre diversos outros aspectos.
Embora se possa observar a ocorrência de mudanças na metodologia de ensino, nos materiais didáticos e nos tipos de conteúdo utilizado, sempre surgem novos questionamentos e desafios com os quais os professores de línguas se deparam. Um dos problemas que persistem é a escrita do aluno de inglês. Apesar de os alunos aprenderem a escrever tipos variados de texto em inglês, eles ainda apresentam dificuldade para perceber que os diversos tipos de texto com os quais lidamos no dia a dia variam linguisticamente, dependendo das pessoas para as quais se destinam, do contexto e da situação em que são utilizados. Não se escreve ou se fala do mesmo modo o tempo todo, e, aparentemente, isso não é mostrado ou ensinado de modo claro aos estudantes, em especial estudantes de línguas estrangeiras. Esses alunos, apesar de produzir textos que, de alguma forma, variam entre si e em relação à variação do inglês, parecem não fazê-lo de modo consciente, ou seja, “escolhendo” as características que fazem com que um texto se mostre mais ou menos formal, mais ou menos argumentativo etc. para cumprir determinado propósito comunicativo. Em muitos casos, a variação tende a ocorrer por causa da mudança do tema, do vocabulário aprendido em certa unidade do livro didático ou porque os alunos se basearam em algum modelo de texto diferente. Nesta tese
denominamos variação linguística o conjunto de diferentes características
linguísticas (p. ex., adjetivos, pronomes, orações nominais etc.) que co-ocorrem em textos com registros distintos, conferindo-lhes certas funções comunicativas em determinado contexto de situação.
podem variar linguisticamente de acordo com o propósito comunicativo e/ou o contexto de situação, como já mencionado, portanto, não há uma “fórmula” correta para caracterizar a argumentação, o que, consequentemente, torna o ensino da
escrita de textos argumentativos uma tarefa árdua para professores e designers de
material didático. Os textos argumentativos são aqueles nos quais, de algum modo, é necessário convencer alguém sob determinado ponto de vista, opinião ou posicionamento, defendendo a ideia proposta (SCHAINIUKA, 2011). Além disso, a argumentação pode combinar a narração, a descrição etc. (SCHAINIUKA, 2011), o que também afeta suas características linguísticas e, assim, a variação entre textos argumentativos.
Para ilustrar como a variação linguística é comum e dependente das características linguísticas que co-ocorrem nos textos, mostram-se relevantes os resultados de Biber, Grieve e Iberri-Shea (2008), estudo no qual se constata que, ao longo dos tempos, ocorreu variação linguística nos registros do tipo reportagem de jornais e revistas, uma vez que surgiram novos estilos nas últimas décadas para proporcionar maior compactação da informação, que ocupa menor espaço. Neste estudo, os dados indicam que a nominalização, o uso de substantivos como pré-modificadores, e as orações nominais são recursos linguísticos que apresentam uso mais frequente por conta dessa compactação da informação e que são típicos dos registros analisados.
Nesta tese, o registro se refere a textos que apresentam características linguísticas semelhantes, co-ocorrentes, e que, em determinado contexto situacional, atendem a um propósito comunicativo. Os textos (redações) produzidos por estudantes de um idioma são analisados segundo critérios pré-determinados, como um registro, por constituírem tipos de texto que desempenham uma função comunicativa em um contexto situacional, ou seja, são produzidos por aprendizes, têm a função de expressar a posição do aluno diante do tema abordado e apresentam como contexto situacional o fato de ser produzidos como atividade de ensino para prática da escrita. O conjunto desses textos produzidos por alunos é
denominado corpus de aprendiz.
assim, pode-se encontrar variação linguística nos textos argumentativos desses alunos.
A partir dessa variação linguística, perguntamo-nos se não seria possível averiguar como os textos produzidos por alunos de inglês de nível avançado variam de modo sistemático; caso essa variação seja recorrente, a questão passa a ser se não haveria um modo de ensinar essa variação que ocorre nos textos. Diante da possibilidade de encontrar uma variação sistemática nos textos, ou seja, características linguísticas específicas que compõem essa variação, seria possível utilizá-las para o desenvolvimento de atividades didáticas para aperfeiçoar a produção escrita de alunos de inglês.
Acreditamos que ensinar como ocorre a variação linguística na escrita de alunos de língua possibilita ao aluno entender que há variação em textos de um mesmo registro e aprender a produzir um texto de acordo com o contexto e situação envolvidos.
A Linguística de Corpus (LC) tem obtido destaque por conta do uso de tecnologias inovadoras, principalmente programas computacionais, para a análise linguística. O uso de programas computacionais possibilita a análise automática de textos e o estudo de grandes quantidades de textos de modo ágil e preciso. O conjunto de textos, coletados segundo critérios pré-estabelecidos e armazenados
em formato legível por computador, é denominado corpus; a análise de um corpus
proporciona acesso a padrões de uso da linguagem. Os padrões de linguagem relacionam-se ao modo como as palavras se agrupam regularmente nos textos, conferindo a esses agrupamentos determinado significado e/ou característica.
Para estudar a variação nos textos produzidos por alunos de inglês, utilizamos os seguintes corpora: o International Learner Corpus (ICLE), o Brazilian International
Learner Corpus (BrICLE), um corpus de alunos cuja língua nativa é o inglês
estruturas gramaticais em sentenças isoladas (exercícios e atividades em sala de aula), mas não em um texto (GRANGER, 1999). Um fato relevante observado na LCA é que os diversos estudos, de uma forma ou de outra, demonstram que a escrita do aprendiz de inglês não é linear: todos os alunos não escrevem do mesmo modo, sua escrita varia em termos de escolhas léxico-gramaticais, o que reforça a hipótese da existência de variação na escrita argumentativa do aluno. Afinal, sob uma visão empírica da linguagem, a variação é natural.
Ainda no âmbito da LC, as pesquisas utilizam uma infinidade de metodologias distintas, uma característica da área, o que pode levar a resultados diferentes em estudos semelhantes, assim, o desenvolvimento ou a adoção de uma metodologia adequada é de suma importância. Em estudos sobre a variação entre registros, uma abordagem de destaque é a análise multidimensional (AMD), que é, segundo Biber (2004, p. 45, tradução nossa) “uma abordagem de pesquisa desenvolvida para descobrir e interpretar padrões de variação linguística encontrados em um corpus de
textos”. Essa abordagem, proposta por Biber (1988), tem sido utilizada em diversos estudos cujo objetivo é verificar como a linguagem varia sistematicamente em textos de diferentes registros em uma mesma língua. Por suas características, a AMD mostra-se uma abordagem plenamente adequada a esta tese.
A AMD é uma abordagem que tem contribuído em diversas áreas relacionadas à comunicação que visam a uma melhor compreensão da linguagem utilizada em diferentes situações e contextos. Sua principal contribuição para os estudos da linguagem, segundo Berber Sardinha (2000, p. 100), é:
[...] a possibilidade de se utilizar concomitantemente uma variedade de traços linguísticos empregados na análise textual e de se aplicar a codificação desses traços a um número de textos maior do que se poderia fazer manualmente [...], por meio do emprego de computadores e técnicas estatísticas.
Vários estudos que utilizam a abordagem da AMD partiram do estudo precursor de Biber (1988), que identificou as dimensões de variação do inglês: a) dimensão 1
– produção marcada pelo envolvimento versus informação; b) dimensão 2 –
preocupações narrativas versus não narrativas; c) dimensão 3 – referência explícita versus dependente de referência; d) dimensão 4 – persuasão explícita; e e)
Reppen (1994) descreveu como a linguagem nas redações de crianças da 3ª à 6ª série (de acordo com o sistema educacional americano) varia em relação à linguagem de livros didáticos e monólogos transcritos de crianças. Biber et al. (2004) apresentam um estudo dos registros falados e escritos da linguagem utilizada em universidade, como grupos de estudo, orientações, apostilas, catálogos, programa da universidade disponibilizado em seu site, entre outros, que, em geral, não são
abordados em exames de proficiência de língua que avaliam se o aluno é capaz de lidar com todas as obrigações de seu dia a dia na universidade. Esse estudo demonstra que alguns dos registros não são descritos e o estudante, nativo e não nativo, raramente aprende ou tem contato com essa linguagem, o que pode dificultar o bom aproveitamento no curso.
Antes do surgimento da AMD, estudos relativos à variação de registros eram realizados com base em apenas uma ou duas características linguísticas, sem associação entre um grupo de características. Muitas vezes, partia-se da função de um texto para, então, identificar algumas de suas características. Esses estudos não eram abrangentes e não correlacionavam características: examinavam a linguagem em registros variados, observavam apenas uma ou outra característica linguística ou analisavam poucos textos (BIBER, 1988). Em função dessas críticas, nas quais também acreditava, Biber (1988) desenvolveu um modo de examinar a variação linguística em diferentes registros levando em conta grande quantidade de características linguísticas e funcionais por meio de um programa de cálculos estatísticos e um programa de etiquetagem automática. Essa abordagem ficou conhecida como AMD. Vale dizer, aqui, que as características linguísticas mencionadas, também denominadas traços linguísticos (features), referem-se às
classes gramaticais, lexicais e semânticas identificadas nos textos incluídos nos
corpora pesquisados. Essas características constituem as variáveis analisadas na
AMD.
Na AMD, a variação nos textos é apresentada em dimensões. As dimensões de variação são um conjunto de características linguísticas (correlacionadas) subjacentes aos textos de um corpus que, geralmente, são responsáveis pelas
Quando o personagem aparece em outra dimensão, ainda guarda algumas de suas características (é possível reconhecê-lo, trata-se do mesmo personagem), no entanto, como há variáveis diferentes e que se correlacionam de modo diferente agindo nessa outra dimensão, ele executa outra função. Do mesmo modo, ao olhar as dimensões de variação do inglês propostas por Biber (1988), pode-se notar que os textos de um registro, por exemplo, a conversa telefônica na dimensão 1, apresentam características linguísticas que conferem uma função comunicativa ligada à fala, porém, na dimensão 2, embora continue sendo uma conversa telefônica, as características dessa dimensão conferem uma função não narrativa. Na ficção, em universos paralelos, essas dimensões coexistem. Do mesmo modo, nas dimensões de variação, os textos podem aparecer em uma dimensão como tipicamente pertencentes à fala e em outra dimensão, devido a diferentes variáveis que se relacionam (ainda que guardando as características de outra dimensão), esses textos aparecem como não narrativos, ou seja, as diferentes realizações dos textos coexistem, um mesmo texto pode ser falado e não narrativo.
As dimensões de variação da AMD, além de mostrar as várias realizações dos textos, trazem uma classificação não dicotômica desses registros. Essa classificação da AMD constituiu uma inovação em relação aos estudos de variação linguística, que apresentavam resultados classificatórios em dois polos distintos (oral ou escrito/formal ou informal). Na AMD, os resultados das pesquisas mostram como os textos ou registros de um corpus são distribuídos ao longo desses dois polos. Um
exemplo estudado por Biber et al. (2004) são os textos transcritos de explicações em aulas em universidade; esses textos, embora falados, também apresentam características da escrita e, por isso, aparecem entre um polo e outro, não como unicamente falados. Ao mesmo tempo, em outra dimensão (narrativa versus não
narrativa), as explicações em aula são um pouco narrativas (novamente entre um polo e outro). Considerando todas as dimensões de Biber et al. (2004), 4 no total, e que elas são padrões de medida por meio dos quais definimos algo, os textos explicativos em sala de aula apresentam-se mais ou menos conversacionais, mais ou menos narrativos, bastante dependentes da situação, um pouco persuasivos e um pouco impessoais.
de padrões textuais que não eram possíveis com outras abordagens. Com a AMD, combina-se o uso de tecnologia, a análise linguística e os estudos de variação linguística, mas ainda falta um quadro conceitual com procedimentos específicos para utilizar tais estudos como fonte de conteúdo ou indicação de conteúdo para materiais didáticos para o ensino de línguas. Muitos estudos em AMD (bem como na LCA) apresentam sugestões para o uso dos resultados em materiais didáticos, alguns, inclusive, desenvolvem um material didático, como, por exemplo, o Real grammar (BIBER; CONRAD, 2009), no entanto, não há indicação de qual caminho
seguir se o professor pesquisador e designer de material didático almejar aproveitar
resultados de pesquisa ou realizar pesquisas por conta própria com a finalidade de obter conteúdo para produzir material didático, assim, há, aqui, uma lacuna a ser preenchida.
Uma vez que nosso estudo que adota a abordagem da AMD tem relação com o ensino da escrita e almeja utilizar os resultados da pesquisa para o ensino, é necessário explicitar, ainda, o modo como é constituído o conteúdo de um material didático que se propõe a ensinar a variação nos textos argumentativos dos alunos. Em geral, para o ensino da escrita (nesse caso, em uma língua estrangeira, o inglês), o professor utiliza atividades didáticas que fazem parte de um material didático ou ele mesmo as produz. O problema é que, muitas vezes, esse material didático baseia-se na intuição ou experiência do professor ou do designer de
material didático e, portanto, abrange algumas necessidades dos alunos e alguns usos da língua, mas, em muitos casos, deixa de abordar itens e conteúdos relevantes. A intuição mostra-se deficiente quanto ao uso da língua ou mesmo em relação a o que e como ensinar, como diversas pesquisas com materiais didáticos sugerem (SUCCI JR., 2003; CAMPOS, 2007; CONTRERA, 2010; SÃO BENTO FERREIRA, 2010). Assim, observa-se que há certa carência de estudos que busquem estabelecer um elo entre a pesquisa linguística e o desenvolvimento de material didático.
Justificativa
Esta tese mostra-se relevante, em primeiro lugar, porque, como professora, pesquisadora e designer de material didático para o ensino de línguas, constatei que
práticas de ensino da escrita em inglês e no desenvolvimento de atividades didáticas. Sem compreender como os textos variam entre si, em termos de dimensões de variação, acredito não ser possível ensinar a variação ao aluno de modo abrangente e sistemático.
Em segundo lugar, os estudos sobre a variação na escrita dos alunos têm sido pouco explorados, tanto sob o ponto de vista de conhecer a variação nos textos argumentativos de alunos de inglês como do aspecto da apresentação de uma metodologia para uso dos resultados de pesquisas desse tipo para o desenvolvimento de materiais didáticos para o ensino de línguas. Os principais
estudos desenvolvidos com a abordagem da AMD e com corpora de aprendiz
identificados foram: Pacheco de Oliveira (1997), Shimazumi (1998), Conde (2002), Van Rooy e Terblanche (2009), Asencion-Delaney e Collentine (2011) e Aguado Jimenez, Pérez-Paredes e Sánchez (2012). No entanto, nenhum deles apresenta sugestões e procedimentos para uso dos resultados da pesquisa para o ensino de línguas.
Os estudos da LCA, em geral, têm por objetivo subjacente informar materiais didáticos ou material instrucional para professores de inglês, no entanto, eles têm a limitação de estudar separadamente as características linguísticas das redações produzidas por aprendizes; desse modo, não possibilitam observar a relação entre essas características ou o modo como o uso da linguagem do aprendiz varia. A abordagem da AMD possibilita lidar com ambos os objetivos.
Em terceiro lugar, sob o ponto de vista social, ao aprender, conhecer e compreender como os textos argumentativos variam, o aluno de inglês torna-se mais apto a agir no mundo, no que diz respeito à comunicação escrita.
Por conta da falta de procedimentos estabelecidos para utilizar pesquisas para o desenvolvimento de atividades didáticas, nesta tese almejo mostrar como obter conteúdos para elaborar atividades didáticas com base em pesquisa sobre a variação linguística. As atividades didáticas que utilizam as características linguísticas das dimensões de variação do inglês e das próprias redações visam a conscientizar o aluno de que há diferentes modos de construir uma argumentação e que essa diferença é decorrente da variação linguística. A partir dessa noção de variação, é possível aprender a lidar com ela para que seja utilizada quando e como necessário.
conteúdos para materiais didáticos, pois estes lidam com a linguagem e a linguagem é utilizada nos textos (falados, escritos e de diversos gêneros, tipos, estilos etc.). Assim, entendemos que se deve ensinar línguas com base em conhecimento empírico.
Um dos muitos modos de trazer pesquisa para a sala de aula é utilizar os resultados de pesquisas como a abordagem da AMD, que leva em consideração os diferentes registros, suas respectivas características e como essas características se correlacionam para atingir os propósitos comunicativos em questão, que constituem a necessidade básica do aprendizado de uma língua.
Os resultados de um estudo como esta tese podem proporcionar pistas para selecionar conteúdos a ser trabalhados nas atividades didáticas, pois, quando um texto se apresenta em determinada dimensão, isso significa que a linguagem utilizada naquele texto apresenta grande quantidade de características linguísticas relacionadas àquela dimensão, ao mesmo tempo que apresenta falta de outras características relacionadas a outras dimensões ou a outro polo da mesma dimensão. Essas características determinantes podem ser utilizadas para ensinar um aluno a escrever um texto mais informacional, por exemplo, utilizando adjetivos atributivos, orações preposicionais e coordenadas. Para reforçar a noção de que estudos com grande quantidade de texto e análise de variação são relevantes para o ensino de língua, recorremos a Biber, Gray e Poopon (2011, p. 17, tradução nossa):
A análise de corpus de grande escala é idealmente adequada à pesquisas desse tipo: um corpus fornece uma amostra muito mais representativa da língua do que aquelas tipicamente utilizadas em estudos de desenvolvimento; o uso de técnicas computacionais possibilita análise de grandes coleções de textos, fornecendo resultados que são generalizáveis em um público-alvo; e o uso de análises quantitativas permite descrever a real proporção na qual um padrão de uso é preferido em uma ou outra variedade de texto.
Objetivos e perguntas de pesquisa
Diante da problemática apresentada, esta tese tem por objetivos principais: a) mostrar que há variação entre os textos dos corpora estudados (ICLE, BrICLE e
AMD de corpora de aprendizes pode fornecer resultados aplicáveis ao design de
material didático para o ensino de inglês. Desse modo, combinamos a pesquisa linguística, mais especificamente a análise da variação linguística, ao uso de tecnologias (ferramentas computacionais para análise linguística) com aplicação ao desenvolvimento de materiais didáticos.
De modo mais específico: a) verificamos como as redações de alunos de inglês
de 18 origens1 diferentes variam em relação às dimensões do inglês apresentadas
em Biber (1988); e b) averiguamos quais são as dimensões de variação das redações desses alunos. Além disso, a partir das características linguísticas observadas nas dimensões de variação das redações, apresentamos procedimentos para a seleção de conteúdo por meio de resultados de pesquisa que possam informar atividades didáticas com base em corpus (e não na intuição).
Esta tese lida com as seguintes perguntas de pesquisa:
1. Como as redações de aprendizes de inglês de 18 origens diferentes e de estudantes nativos variam em relação às dimensões do inglês descritas por Biber (1988)?
2. Quais são as dimensões de variação específicas dos corpora de
aprendizes?
3. Dados os resultados obtidos na AMD dos corpora de aprendizes, como e
quais conteúdos podem ser extraídos para aplicação em atividades didáticas?
A maioria dos estudos em AMD apresenta resultados descritivos e indica como esses resultados podem ser utilizados. Dada a riqueza de detalhes e a especificidade quanto ao uso da linguagem neste ou naquele registro, os resultados desses estudos podem ser utilizados para informar materiais didáticos e para desenvolver programas para o ensino da escrita, a avaliação de textos etc.
Além disso, ao analisar os corpora de aprendizes selecionados para este
estudo, quais sejam, o ICLE, o BrICLE e o LOCNESS, temos em mãos a linguagem utilizada por aprendizes de inglês; por meio da abordagem da AMD, averiguamos os padrões de uso mais frequentes em cada variedade de texto em relação às
dimensões de variação estudadas e esses padrões podem indicar o conteúdo que alunos de inglês necessitam aprender para aperfeiçoar sua escrita.
Resta, ainda, esclarecer que utilizamos a linguagem produzida pelo aluno (nas redações) para ensinar porque ela representa o que o aluno sabe em termos de produção de texto e aproxima-se daquilo que os demais alunos podem produzir. Além disso, como o foco deste estudo são as redações, os resultados obtidos a partir da linguagem do aluno ilustram exatamente o ponto (i. e., as características linguísticas) que devemos ensinar. No entanto, para exemplificar as características linguísticas das dimensões de variação, trabalhamos com amostras de uso da língua provenientes do Corpus of Contemporary American English (COCA). Assim, podemos desenvolver atividades didáticas que partem de algo em relação ao qual o aluno apresenta conhecimento prévio, mas que, porém, é enriquecido com padrões de uso de linguagem autêntica.
Esta tese organiza-se da seguinte forma: no Capítulo 1 apresentamos sua fundamentação teórica, explicitando conceitos e características da LC, LCA, AMD, além de questões relativas ao desenvolvimento de material didático para o ensino de línguas. No Capítulo 2, relativo ao referencial teórico, apresentamos uma revisão de literatura relacionada à argumentação e ensino/aprendizado de línguas. No Capítulo
3, relativo à metodologia, apresentamos os corpora e as ferramentas computacionais
utilizadas neste estudo, bem como os procedimentos necessários para sua realização. No Capítulo 4 apresentamos o estudo piloto, preliminar à pesquisa em si. Por fim, no Capítulo 5 apresentamos os resultados, divididos em três partes: uma voltada à questão do mapeamento das dimensões do inglês; outra voltada à questão das dimensões de variação das redações; e a última voltada aos procedimentos para obtenção de conteúdos para materiais didáticos por meio dos resultados da análise.
1
FUNDAMENTAÇÃO TEÓRICA
Esta tese foi concebida e desenvolvida a partir de pressupostos teóricos e metodológicos da Linguística de Corpus (LC), da Linguística de Corpus de Aprendiz (LCA) e da Análise Multidimensional (AMD). Além desses pressupostos teórico-metodológicos relacionados à coleta, análise e interpretação dos dados, adotamos uma abordagem relativa ao desenvolvimento de materiais didáticos e ao aprendizado de línguas.
Primeiro, apresentamos os pressupostos teórico-metodológicos da LC no
âmbito dos estudos da linguagem e como diferentes tipos de corpora são utilizados
em diferentes tipos de pesquisa, segundo os objetivos e a metodologia adotados. Discutimos conceitos fundamentais da LC, tais como: frequência, padrões de linguagem, colocação, coligação, e pacotes lexicais. Nosso foco recai sobre as discussões relativas ao uso da LC para o ensino de línguas.
Em seguida, indicamos como a LCA tem contribuído para o desenvolvimento de estudos relacionados ao ensino de idiomas como língua estrangeira e segunda língua.
O próximo passo é a apresentação da AMD, abordagem que revolucionou os estudos da variação linguística relativos a diversas áreas, com discussão acerca de sua importância e relação com esta tese.
Por fim, discutimos quadros conceituais para a elaboração de atividades didáticas com base em abordagens voltadas ao desenvolvimento de materiais didáticos, e como essas estruturas relacionam-se com esta tese. Entre as abordagens disponíveis, optamos por discutir as seguintes estruturas: as atividades baseadas em tarefa, o aprendizado guiado pelos dados, a estrutura didática proposta por Ramos (2004) e a proposta de uso da LC de Berber Sardinha (2011). Esses quatro quadros conceituais apresentam características que possibilitam ao professor pesquisador e ao designer de material didático utilizá-las de modo
atividades multimídia, centradas em linhas de concordância e nos textos, propostas por Berber Sardinha (2011).
1.1. A Linguística de Corpus
A LC tem um longo histórico, que remonta a períodos remotos nos quais a coleta e o estudo de um corpus eram realizadas manualmente, por escrito, utilizando
fichas em papel. Muita coisa mudou com o advento do computador e da internet. A pesquisa em LC também avançou e passou a contribuir com estudos voltados ao uso da linguagem em diversas áreas do conhecimento; por isso, a LC prima pela interdisciplinaridade e apresenta características ligadas ao empirismo e ao uso de ferramentas computacionais. Segundo Teubert e Krishnamurthy (2007, p. 1, tradução nossa, grifo do autor):
A Linguística de Corpus é mais uma prática que uma teoria.
A Linguística de Corpus é o estudo da linguagem baseado em evidências de uma grande coleção de textos passíveis de ser lidos por computador com auxílio de ferramentas eletrônicas.
A Linguística de Corpus é uma nova e emergente estrutura empírica que combina um compromisso sério com métodos estatísticos rigorosos e perspectivas linguisticamente sofisticadas sobre a estrutura e o uso da linguagem.
A Linguística de Corpus é um termo relativamente moderno utilizado para referir-se à uma metodologia que é baseada em exemplos de linguagem em uso da “vida real”.
A Linguística de Corpus é uma área de pesquisa vital e inovadora.
Por se prestar a tantos usos e apresentar características que proporcionam abrangência e rigor metodológico, a LC traz perspectivas cada vez mais promissoras à pesquisa linguística. Apresentaremos a seguir um breve histórico da LC, discutindo seu uso em diversas áreas dos estudos da linguagem.
1.1.1. Breve histórico da Linguística de Corpus
O uso e a coleta de corpora são procedimentos antigos, que remontam aos
linguagem, tudo indica que se tratava de um sistema de arquivamento e manutenção de textos, como uma biblioteca.
As pesquisas em linguagem utilizando corpora só passaram a ganhar
importância a partir das ideias propostas por J. R. Firth em relação à visão de linguagem. Firth foi um dos primeiros linguistas a propor que a linguagem deve ser estudada a partir de seu uso e que o contexto situacional de uso influi no significado e na pronúncia das palavras. Além disso, Firth propunha que a linguagem é o meio pelo qual as pessoas funcionam na sociedade (MONAGHAN, 1979), ou seja, que diferentes funções ocasionam um leque distinto de escolhas (de palavras, de pronúncia etc.) na linguagem. Com essas ideias, Firth influenciou um grande número de alunos, dentre eles M. A. K. Halliday e J. Sinclair. Ambos desenvolveram estudos que se baseavam na observação da linguagem em uso; Halliday partiu para a criação de uma “gramática” da linguagem em uso, ao passo que Sinclair decidiu estudar os padrões de linguagem formados pela observação da linguagem em
corpus. Desse modo, Halliday propôs a noção de que uma língua é formada por
sistemas e que esses sistemas operam ao mesmo tempo, ou seja, a língua constitui uma gramática sistêmico-funcional (MONAGHAN, 1979), enquanto Sinclair (STUBBS, 1993) propôs as noções de frequência de uso de palavras e de léxico-gramática, ou seja, a gramática (padrão de linguagem) se forma a partir de escolhas lexicais e suas colocações e coligações, desenvolvendo a área de estudos que hoje denominamos LC. O ponto principal que persiste nas pesquisas atuais é que ambos os autores viam a língua como um sistema probabilístico, ou seja, um sistema no qual muitos traços linguísticos são possíveis, porém, não ocorrem com a mesma frequência e sua ocorrência não é aleatória, mas, sim, varia sistematicamente (BERBER SARDINHA, 2004), o que fez com que a ideia de “inventar” exemplos para estudar a língua caísse por terra, bem como a proposta de um eixo sintagmático e paradigmático que guia “unicamente” a estrutura e os significados de uma língua. Isso porque a compreensão de uma palavra em uma sentença ou em um texto pode ser muito mais afetada pelos colocados dessa palavra e pelo seu contexto imediato do que pela posição que ela ocupa no sintagma.
1.1.2. Estudos em outras áreas de pesquisa linguística
A LC insere-se no âmbito da Linguística Aplicada, e tem ganhado cada vez mais importância e que se destaca pelo uso de grandes quantidades de textos e de ferramentas computacionais em suas análises, pela observação empírica da linguagem em uso e pela análise dos padrões formados por essa linguagem. Na LC, acredita-se que não se deve confiar na intuição de um falante, gramático ou pesquisador para compreender ou estudar a língua, é mais seguro e preciso trabalhar com evidências linguísticas. Essas evidências são as amostras de
linguagem em uso obtidas por meio de um corpus.
Segundo Biber, Conrad e Reppen (1998, p. 4, tradução nossa), as
características essenciais de uma análise baseada em corpus são:
– ser empírica, analisando padrões reais de uso em textos naturais;
– utilizar uma grande e criteriosa coleção de textos naturais, conhecida como “corpus”, como base para análise;
– fazer uso extensivo de computadores para análise, utilizando tanto técnicas automáticas quanto interativas;
– necessitar de técnicas analíticas tanto quantitativas quanto qualitativas.
Por conta dessas características, a LC mostra-se fundamental nos estudos da linguagem por possibilitar maior versatilidade para o desenvolvimento de uma metodologia que sustente a proposta pelo pesquisador e por proporcionar dados empíricos para análise quantitativa, principalmente relacionada à frequência de uso de itens linguísticos. Assim, a abordagem da LC é utilizada em estudos voltados à análise de discurso, da metáfora, da tradução, do ensino de línguas etc.
Um grande número de estudos voltados à análise de discurso, entre eles os relacionados à gramática sistêmico-funcional, são desenvolvidos por meio da LC como metodologia de pesquisa. Nesse tipo de pesquisa, coleta-se um corpus,
levanta-se a frequência de uso das palavras nesse corpus, seleciona-se os aspectos
do texto a ser estudados e, a partir de linhas de concordância, interpreta-se os dados obtidos por meio de ferramentas computacionais. Santos (2011), por exemplo, propõe-se a analisar textos de jornais que fazem referência a jovens em condições de vulnerabilidade social para investigar quais são a vozes mais acessadas nesses
Tools (SCOTT, 1997) para identificar os itens relacionados às vozes e quantificá-los.
A interpretação desses dados, porém, não considera os padrões de linguagem observados nos dados, mas, sim, segue padrões e relações pré-estabelecidas na gramática sistêmico-funcional.
Estudos de análise de discurso, nos quais a LC não é utilizada apenas como metodologia, mas, sim, como abordagem teórica, também têm sido realizados; porém, há uma série de problemas metodológicos e de interpretação dos dados postulados por analistas do discurso. Segundo Virtanen (2008, p. 1043, tradução nossa), “a noção de contexto expandido costuma ser problemática em estudos com
corpus”. A noção de contexto expandido é problemática porque o analista tem uma
grande quantidade de co-texto para analisar sob a forma de linhas de concordância, obtidas por meio de programas, geralmente concordanciadores, porém, alguns aspectos do contexto situacional se perdem, impossibilitando uma interpretação de dados precisa. Outro problema revelado por Virtanen (2008) é que, na análise de discurso, a maioria dos estudos que utilizam a LC é baseada na frequência, porém, na análise de discurso, nem sempre o que é mais relevante é mais frequente. Apesar das dificuldades metodológicas postuladas por um lado, por outro, o uso de
corpora possibilita acesso rápido a conteúdos, palavras e colocações que se almeje
analisar e que são passíveis de ser estatisticamente quantificados. Por isso, estudos com base em corpora e análise de discurso continuam sendo desenvolvidos no
âmbito de quatro grandes áreas: organização do discurso e estrutura textual; aspectos pragmáticos do discurso da interação; colocações textuais e pragmáticas; e variação no discurso. Nesta última vertente, Virtanen (2008, p. 1057, tradução nossa) explica que:
[...] os corpora podem ser utilizados não só para investigar a variação e, até certo ponto, a variabilidade, em um grande corpus, mas, também, para revelar dimensões de variação não previstas antes da análise.
colocação observados nas linhas de concordância obtidas por meio do corpus. Em
estudo realizado por Mestriner (2009), por exemplo, utiliza-se um corpus de 1.687
pronunciamentos dos ex-presidentes George W. Bush (Estados Unidos) e Luiz Inácio Lula da Silva (Brasil) para averiguar os tipos de metáforas utilizadas por eles e como elas são expressas nos pronunciamentos. Para tanto, recorreu-se ao uso de um analisador de metáforas on-line e ao levantamento de linhas de concordância a partir das palavras identificadas com esse dispositivo para investigar quais significados os padrões de metáfora imprimiam aos textos. O mesmo tipo de estudo foi desenvolvido por Rodrigues (2007), porém, para a análise de metáforas observadas em discurso de liderança.
Em relação à tradução, os pressupostos teórico-metodológicos da LC e as ferramentas computacionais possibilitaram avanço significativo nas pesquisas, pois, além de facilitar a comparação dos mesmos textos em idiomas diferentes, com os
denominados corpora paralelos e comparáveis, as noções de padrão de linguagem
e colocação simplificaram a compreensão e interpretação de significados, tornando o trabalho do tradutor pesquisador mais preciso. Em estudos como o de Lopes (2010), além dos resultados da pesquisa, o desenvolvimento de uma metodologia específica para a tradução contribuiu de modo decisivo para a pesquisa nessa área; Lopes (2010) investigou como a imagem do Brasil é veiculada na imprensa internacional e se havia diferenças sutis entre o texto veiculado em inglês e sua tradução para o português. Ao utilizar os preceitos da LC, Lopes (2010) foi capaz de desenvolver uma metodologia que possibilitou identificar empírica e consistentemente como certos padrões léxico-gramaticais podem formar imagens sobre algo que se lê. Perrotti-Garcia (2009) também utilizou corpora comparáveis, de artigos científicos da
área médica, e constatou que médicos brasileiros empregavam a palavra em inglês “submit” de modo incorreto. Posteriormente, Perrotti-Garcia (2009) averiguou quais recursos lexicais são utilizados por médicos estrangeiros para se referir à palavra em português “submeter”, proporcionando ao tradutor (e ao professor de inglês instrumental que trabalha com médicos) um vasto leque de possibilidades quando necessita traduzir ou escrever textos dessa natureza.
conteúdos didáticos etc. Em pesquisas voltadas ao ensino, a abrangência da LC é ainda maior. Por conta disso, discutimos em maior profundidade as características dos estudos com esse propósito a seguir.
1.1.3. A Linguística de Corpus e o ensino de línguas
Há um grande número de pesquisas voltadas ao ensino de línguas desenvolvidas por meio do aporte teórico da LC; há estudos ligados à descrição da língua, à linguagem do aprendiz, à análise e desenvolvimento de material didático, entre outras questões. Esses estudos, em geral, buscam elucidar o tipo de linguagem presente ou necessária, além de informar e analisar conteúdos de materiais didáticos, atividades complementares e visam a contribuir para aumentar a eficácia do ensino de línguas. As metodologias desenvolvidas com base na LC também mostram-se úteis para estudos exploratórios da língua e contribuem para fazer com que o aprendiz se torne um pesquisador e passe a entender o funcionamento de uma língua a partir de exemplos reais de uso e de padrões que se formam nesses exemplos.
O ensino de línguas tem se beneficiado dos estudos em LC desde os primórdios dessa área, pois, por meio de um corpus, é possível descrever a
linguagem em uso e selecionar conteúdos que se aproximem da linguagem com a qual o aprendiz vai se deparar ao utilizar a língua que estuda.
Estudos como os de Sinclair (1996), Partington (1998), Beaugrande (2001), Biber e Reppen (2002), O’Keefe, McCarthy e Carter (2007), Lüdelling e Kyttö (2008) e Biber (2009), entre muitos outros apresentam descrições de corpora que podem
ser utilizados para informar materiais didáticos e sugerem meios para utilizar ferramentas computacionais no ensino, bem como atividades didáticas com base nos padrões de linguagem observados. No Brasil, as pesquisas e os trabalhos com
corpora para uso no ensino também têm se desenvolvido em grande número. Jacobi
(2001), Bértoli-Dutra (2002), Succi Jr. (2003), Ferreira (2004), Condi de Souza (2005), Diniz (2006), Vicentini (2006), Berber Sardinha (2010), Bissaco (2010), Viana e Tagnin (2011), Acunzo (2012) e Berber Sardinha et al. (2012) são exemplos de
pesquisas que propõem atividades didáticas baseadas em corpus ou trazem
materiais didáticos para averiguar a autenticidade dos textos empregados e a exatidão das propostas.
Todos esses estudos apresentam semelhanças e trazem uma série de ideias e conceitos relevantes para o desenvolvimento desta tese. Bissaco (2010), por exemplo, propõe o uso de atividades guiadas pelos dados (data driven learning)
para alunos de espanhol e observa como estes aprendem por meio da interação com linhas de concordância, com o propósito de investigar o uso de falsos cognatos e perceber como, por meio do co-texto, isto é, palavras que acompanham a palavra estudada, o aluno aprende a diferenciar seus significados. A pesquisadora também constatou que, apesar de dizer-se que as atividades guiadas pelos dados devem proporcionar autonomia de aprendizado ao aluno, algum tipo de mediação na organização de ideias e na interpretação das linhas de concordâncias mostra-se necessário. Em Viana e Tagnin (2011) são apresentadas atividades didáticas com base em linhas de concordância de corpora variados e em diferentes línguas, a
maioria delas com base no uso de colocações. Em Berber Sardinha (2010), o autor propõe usos variados do programa WordSmith Tools para o ensino, enquanto que
em Berber Sardinha et al. (2012) os autores apresentam atividades didáticas
baseadas em corpus, porém, com o uso de tecnologias e mídias variadas, tais como:
vídeos no YouTube, podcast, músicas, séries de TV e jogos eletrônicos.
Além dos estudos desenvolvidos para o uso pedagógico de corpora, deve-se
distinguir a aplicação direta e indireta de corpora no ensino, pois nossa proposta de
atividade, ao final deste estudo, envolve uso direto e indireto, porém, visando a preparar o aluno para aprender a pesquisar a língua de modo autônomo, como na aplicação direta de corpora no ensino.
A aplicação indireta de corpora no ensino tem a ver com a investigação da
linguagem com ferramentas computacionais disponíveis para selecionar conteúdos e fornecer ao aluno conteúdos e atividades com base nessa informação ou, como
explica Römer (2008, p. 113, tradução nossa): “corpora podem ajudar nas decisões
sobre o que ensinar e quando ensinar”. O uso indireto, via de regra, é o mais aplicado ao ensino. Neste estudo, na maior parte das atividades sugeridas, fazemos uso indireto de corpora, no entanto, algumas atividades envolvem o uso direto de corpora, que é explicado a seguir.
linguística do aluno para a noção de padronização da linguagem. Essa aplicação de
corpora está relacionada ao uso direto de corpora no ensino.
Na aplicação direta há duas formas de trabalhar: na primeira, os alunos
examinam o corpus por meio das linhas de concordância e da lista de frequência das
palavras e vão, aos poucos, descobrindo aspectos da língua que lhes interessam; na segunda, o professor seleciona palavras de busca, colocações e concordâncias para que o aluno investigue essa seleção em particular (RÖMER, 2008). A vantagem do primeiro tipo de aplicação é que o aluno explorará a língua e utilizará sua curiosidade, o que pode ser motivador (KETTEMANN, 1995). A desvantagem é que o aluno pode não conseguir identificar padrões ou encontrar sentido na atividade e o professor não tem controle sobre os caminhos escolhidos pelo aluno para auxiliá-lo. No segundo tipo de aplicação, o professor pode auxiliar seus alunos com maior facilidade na interpretação dos padrões apresentados nas concordâncias, no entanto, a motivação e a investigação movidas pela curiosidade do aluno podem ser comprometidas pela pré-determinação do que vai ser estudado (SINCLAIR, 2007).
Nesta tese, almejamos que as atividades tenham como ponto de partida os resultados obtidos no estudo da variação linguística nas redações dos alunos, o que indica, de antemão, os conteúdos necessários a ser estudados, portanto, as atividades guiadas pelos dados situam-se no segundo tipo de aplicação direta.
É necessário, ainda, esclarecer outras vantagens do trabalho com corpora em
sala de aula. Ao basear as atividades propostas nos resultados de uma pesquisa com corpora, fazemos com que as escolhas de conteúdo apresentem itens
linguísticos (palavras, expressões, estruturas frasais) relevantes para o aluno, isto é, aqueles que o aluno apresenta maior necessidade de utilizar ou aprender. O uso de linguagem autêntica e com foco nas necessidades do aluno torna o aprendizado mais significativo e proporciona informação mais confiável acerca da linguagem em uso. Afirmamos, aqui, que o foco das atividades são as necessidades do aluno
porque, ao estudarmos um corpus de aprendiz, identificamos o que o aluno é capaz
de fazer com o que já aprendeu, mas, também, aquilo que ele ainda necessita aprender.
Uma vez apresentadas as vantagens da abordagem da LC para o ensino de línguas, indicamos a seguir o que é um corpus, quais são suas características e
1.1.4. Corpus: definição, característica e tipos
A LC propõe-se a estudar a linguagem em uso a partir de um corpus, isto é, um
conjunto de textos considerados autênticos, legíveis por computador e coletados segundo critérios baseados no tipo de pesquisa que se almeja realizar. Por isso, há diversos tipos diferentes de corpus:
• Corpus especializado: formado por textos de um mesmo tipo, como, por
exemplo, editoriais, entrevistas, resenhas e resumos. Esse tipo de corpus é
utilizado, em geral, para analisar como um tipo de texto se caracteriza e quais são seus padrões de linguagem.
• Corpus geral: formado por textos de diversos tipos para representar
determinada língua. Ele é utilizado, principalmente, como parâmetro para estudos nos quais é necessário obter palavras-chave, como aqueles nos
quais se utiliza corpora especializados ou de aprendiz e, também, estudos
nos quais se almeja descrever uma língua, como no caso da AMD.
• Corpus de aprendiz: formado por textos produzidos por aprendizes de uma
língua e utilizados em estudos que visam a analisar como um aprendiz utiliza a língua que aprendeu ou está aprendendo, informar materiais
didáticos etc. Estudos realizados com corpora de aprendiz também
costumam utilizar um corpus de textos produzidos por falantes nativos da
língua em questão, como referência.
• Corpus comparável: formado por corpora de línguas diferentes ou
variedades diferentes de uma mesma língua, contendo textos alinhados do mesmo tipo em ambas as línguas ou variedades, e são utilizados para compará-las (HUNSTON, 2002, p. 15).
• Corpus paralelo: formado pelos mesmos tipos de texto, porém, em duas
línguas (ou mais) diferentes, sendo uma a língua na qual o texto foi escrito originalmente e a outra sua tradução. São muito utilizados em estudos e trabalhos ligados à tradução.
• Corpus monitor: formado por grandes quantidades de texto e atualizado
com frequência, para possibilitar a investigação de mudanças na língua, como, por exemplo, neologismos e também pode constituir um corpus de
conhecido é o Bank of English, que, atualmente, conta com mais de 650 milhões de palavras.
Diferentes tipos de corpora se prestam a diferentes tipos de pesquisa
(HUNSTON, 2002; BERBER SARDINHA, 2004). Nesta tese, utilizamos corpora de
aprendizes dos projetos International Corpus of Learner English (ICLE), Brazilian International Corpus of Learner English (BrICLE) e um corpus de estudantes nativos da língua inglesa chamado LOCNESS, além do Corpus of Contemporary American English (COCA), utilizado como referência no levantamento de concordâncias e exemplos para as atividades didáticas apresentadas.
O ICLE e o BrICLE são corpora de aprendizes per se, criteriosamente
coletados para representar a linguagem escrita em redações argumentativas de
aprendizes avançados de inglês como segunda língua. O LOCNESS é um corpus de
redações de falantes nativos desenvolvido para ser comparável ao ICLE e facilitar o
desenvolvimento de estudos com esses corpora. Os três corpora mencionados são
utilizados nesta pesquisa como corpora de estudo, pois são analisados para
identificar as diferentes dimensões de variação da escrita do aluno de inglês e averiguar como a escrita do aluno de inglês varia em comparação com as dimensões de diversos registros do inglês (BIBER, 1988). Justamente por ser
corpora de aprendizes, eles proporcionam informação sobre as características
linguísticas observadas na escrita do aluno, o que possibilitou a formulação de atividades que complementem o conhecimento do aluno para que ele possa variar seu estilo de escrita de acordo com sua necessidade.
Embora existam outros corpora de aprendizes, como o Louvain International
Database of Spoken English Interlanguage (LINDSEI), o Longman Learners’ Corpus, o Cambridge Leaner Corpus, apenas para mencionar alguns, optamos por trabalhar com o ICLE por ser um dos pioneiros para a pesquisa da linguagem de aprendizes, por seus critérios de coleta e por abordar a escrita argumentativa de alunos de inglês, foco de nosso estudo. Além disso, a escrita de alunos brasileiros, que muito nos interessa nesta tese, é abordada nos moldes do ICLE. O BrICLE ainda se encontra separado do ICLE, por não haver atingido o número mínimo de 200 mil palavras, no entanto, vem sendo coletado de acordo com o proposto no ICLE e é utilizado nesta pesquisa junto com o ICLE.