Digital elevation model quality on digital soil mapping prediction accuracy
Texto
Imagem


Documentos relacionados
The objective of this study was to predict the levels of organic carbon (OC), clay, and extractable phosphorus (P), from the spectral responses of soil samples in the visible and
ma-se como um organismo que, quer a montante quer a jusante, articula com os mais diversos ser- viços: Centros de Emprego, Centros de Forma- ção Profissional, Serviços de
In this context, the main objective of this research was to assess the use of DSM techniques for mapping soils in western Haiti, specifically by assessing the importance
This study aimed to determine equations to estimate soil moisture using variables of color spaces obtained from images of a portable digital camera.. Material
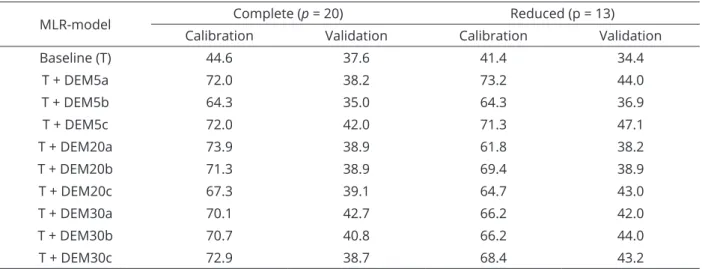
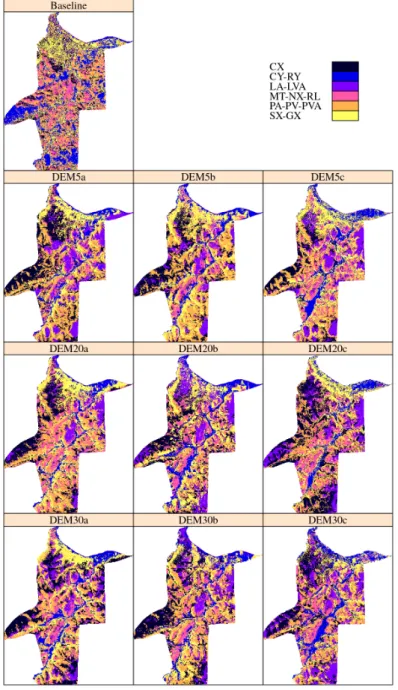
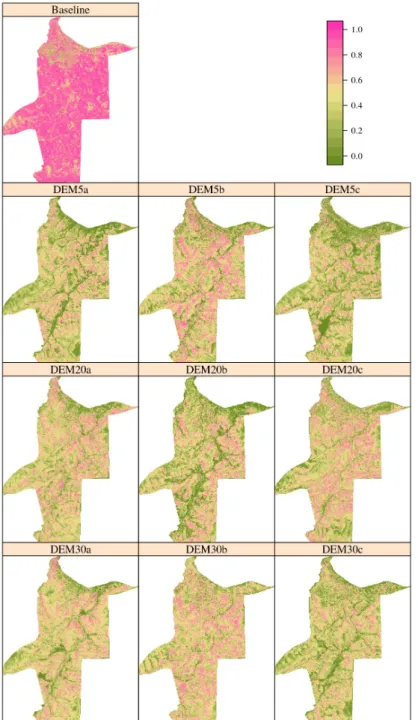
The aim of this study was to map local soil classes by computer-assisted cartography (CAC), using several combinations of topographic properties produced by GIS (digital
In this context, this study differs from previous work in its objective to compare the efficiency of the two prediction methods (ANNs and MLC) for digital soil mapping, using
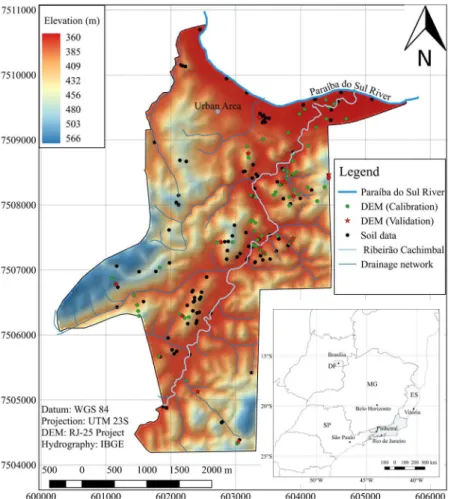
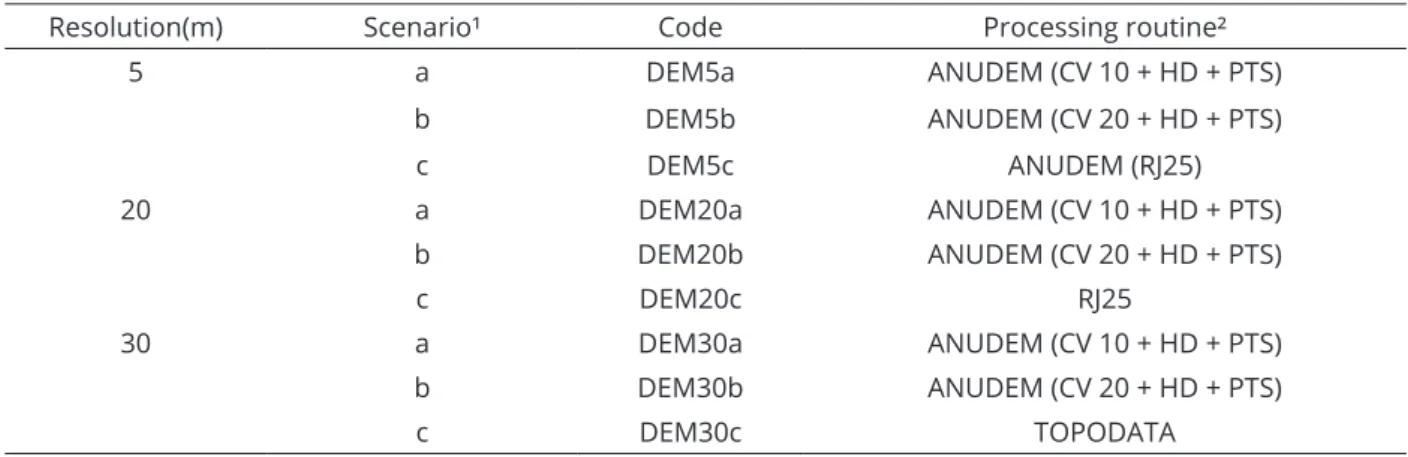
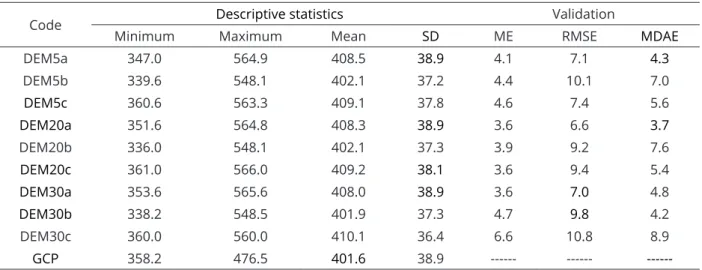
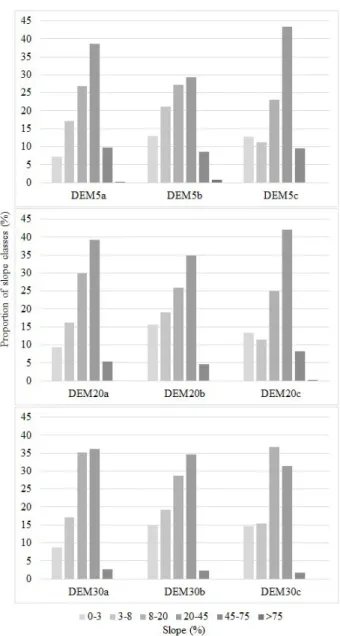
precision elevation by statistical tests based on field reference points, the root mean square error (RMSE), identification of the number and size of spurious depressions, and
There is no straightforward decision on whether to use ordinary kriging or regression kriging for mapping soil properties, because the quality of predictions depends on
