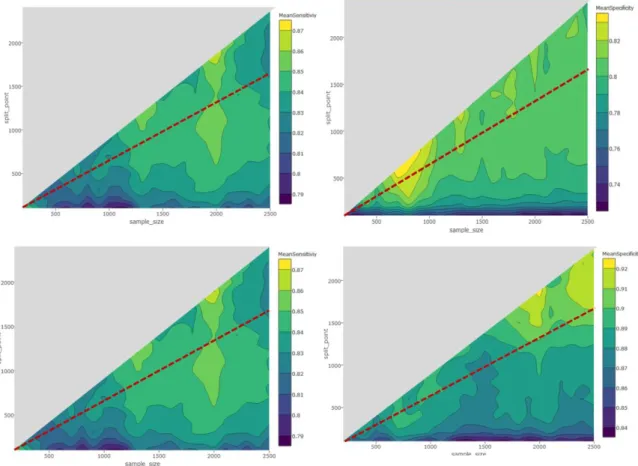
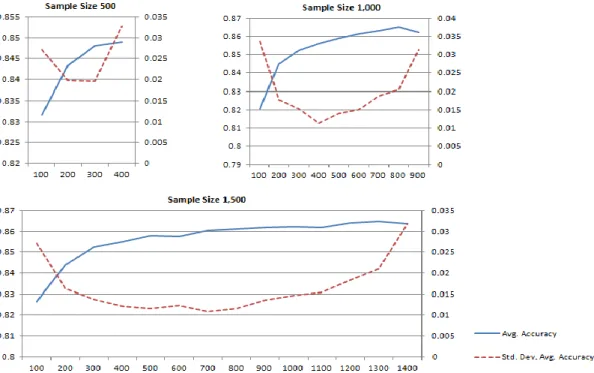
Shedding Light on the Role of Sample Sizes and Splitting Proportions in Out-of-Sample Tests: A Monte Carlo Cross-Validation Approach
Texto
Imagem


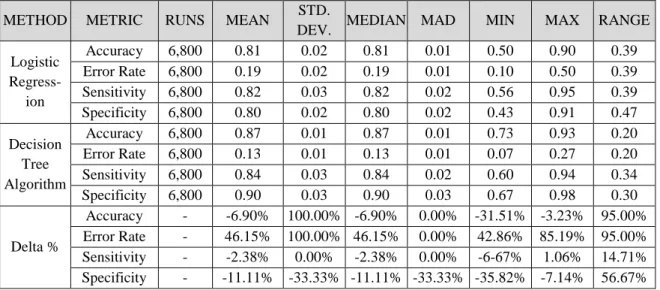

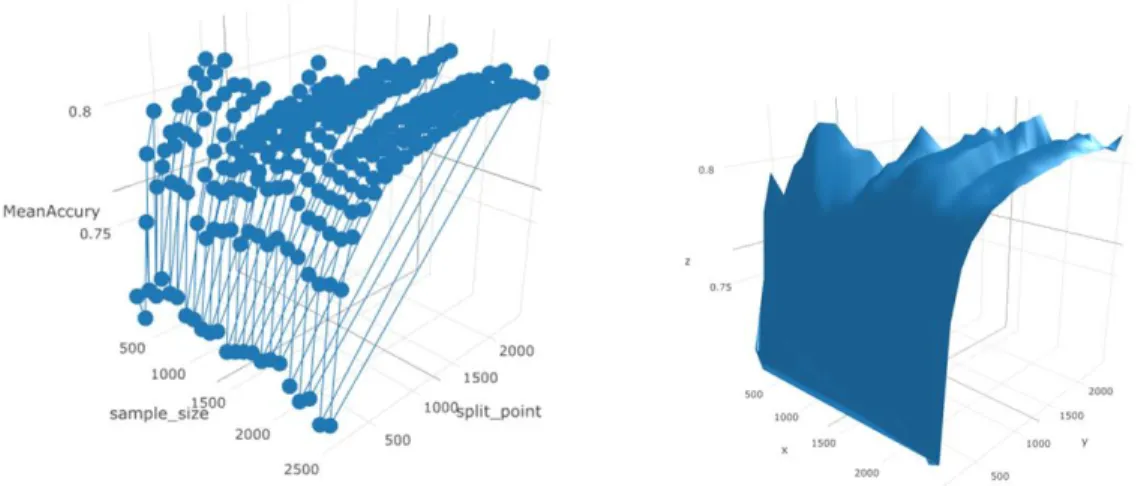
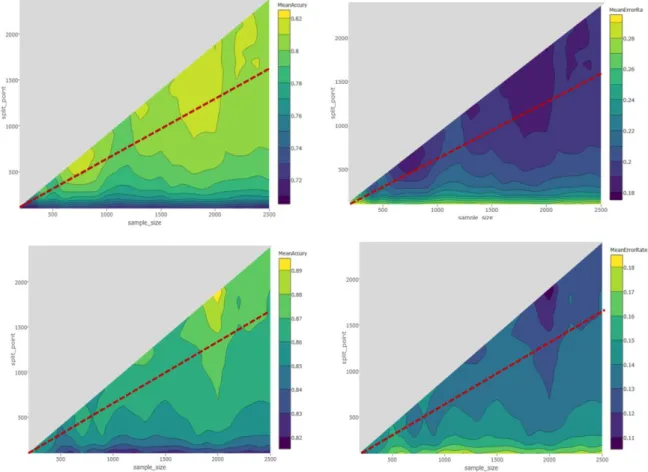
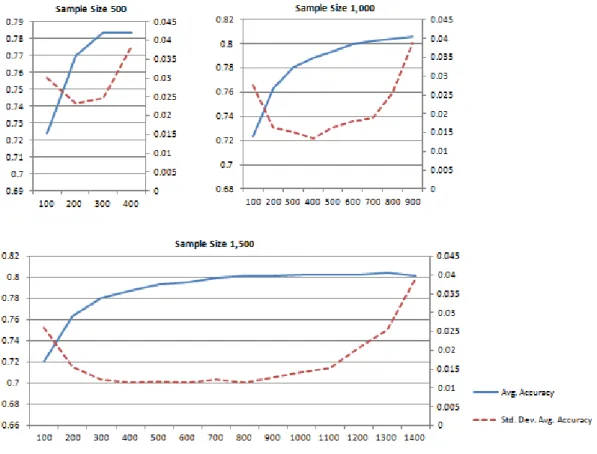
Documentos relacionados
Table 1 lists the root mean square error of calibration for cross validation (RMSECV) of the model, correlation coefficient (R), latent variable (LV) and root mean square error
Figure 6. Ordination diagram of the first two axis of the DCA based on species composition and abundance of Chironomidae larvae in the stations. Mean ± SE of the two-way ANOVA
Assim, como a quantidade de dados estruturados para análise continua a crescer, o MapReduce apresenta-se como adequado para o processamento deste tipo de análises, apesar
The number of individuals per population cross and the mean, the variance, and the components of the mean and the variance for the soybean rust severity scores of Caiapônia
Mean square of the genotype (MSg), mean square error between the plots (MSeb), mean square error within plots (MSew) and their degrees of freedom (DF), mean, selective accuracy
The sample size varies among species and characters, being necessary a larger sample size to estimate the mean in relation of the necessary for the coefficient of variation..
Estuda-se a importância dos bacharéis no pensamento constitucional brasileiro, com breves referências de sua importância para a atualidade, tais como o Poder Moderador e
Como foi anteriormente referido, este estudo exploratório foi concebido como uma etapa preparatória da investigação a desenvolver em profundidade no âmbito do
